Flash-WAM:面向世界动作模型的模态-觉察蒸馏
26年6月来自美国东北大学、乔治亚大学和EmbodyX公司的论文“Flash-WAM: Modality-Aware Distillation for World Action Models”。
世界-动作模型(WAMs)通过迭代扩散联合生成未来视频和机器人动作,在操作基准测试中表现优异,但因需要数十个去噪步而无法实现实时控制。步-蒸馏(step distillation)是解决这一问题的自然方案,但现有方法在视频-动作联合生成的场景下往往失效,原因在于视频流和动作流采用不同的信噪比(SNR)偏移噪声调度,且训练时的边缘噪声分布存在显著差异——这种不对称性是单模态蒸馏方法无法处理的。为此,提出 Flash-WAM,这是一个受一致性蒸馏(consistency distillation)启发的模态-觉察步-蒸馏框架。该框架根据各模态的噪声特性选择相应的一致性函数:针对动作流的低噪声区间采用线性梯度缩放参数化,针对视频流的高噪声区间采用方差保持参数化;这种设计基于对一致性函数族(刻画一致性边界条件下可实现的梯度缩放)的结构分析。在 LingBot-VA 上应用时,Flash-WAM 将各模态的推理过程压缩至单步。在 RoboTwin 2.0 任务中,该方法使 NVIDIA L40S 上的单片段延迟从 8.1 秒降至 348 毫秒,实现 23 倍的加速,从而支持实时推理。Flash-WAM 在保持仿真基准测试任务成功率(RoboTwin 2.0 为 85.5%,LIBERO 为 95.7%)的同时,显著恢复真实世界中的性能(在 Unitree G1 人形机器人上平均成功率达 60%);相比之下,在相同的步预算下,朴素的一致性蒸馏方法的成功率仅为 24%。
如图1所示:(a) 单个 NVIDIA L40S 上的单块(per-chunk)推理延迟。Flash-WAM 将 WAM 推理延迟降低到实时控制的时限要求之内。(b) RoboTwin 2.0 上的平均成功率。现成的蒸馏方法性能大幅下降,而 Flash-WAM 则保持与教师模型相当的性能水平。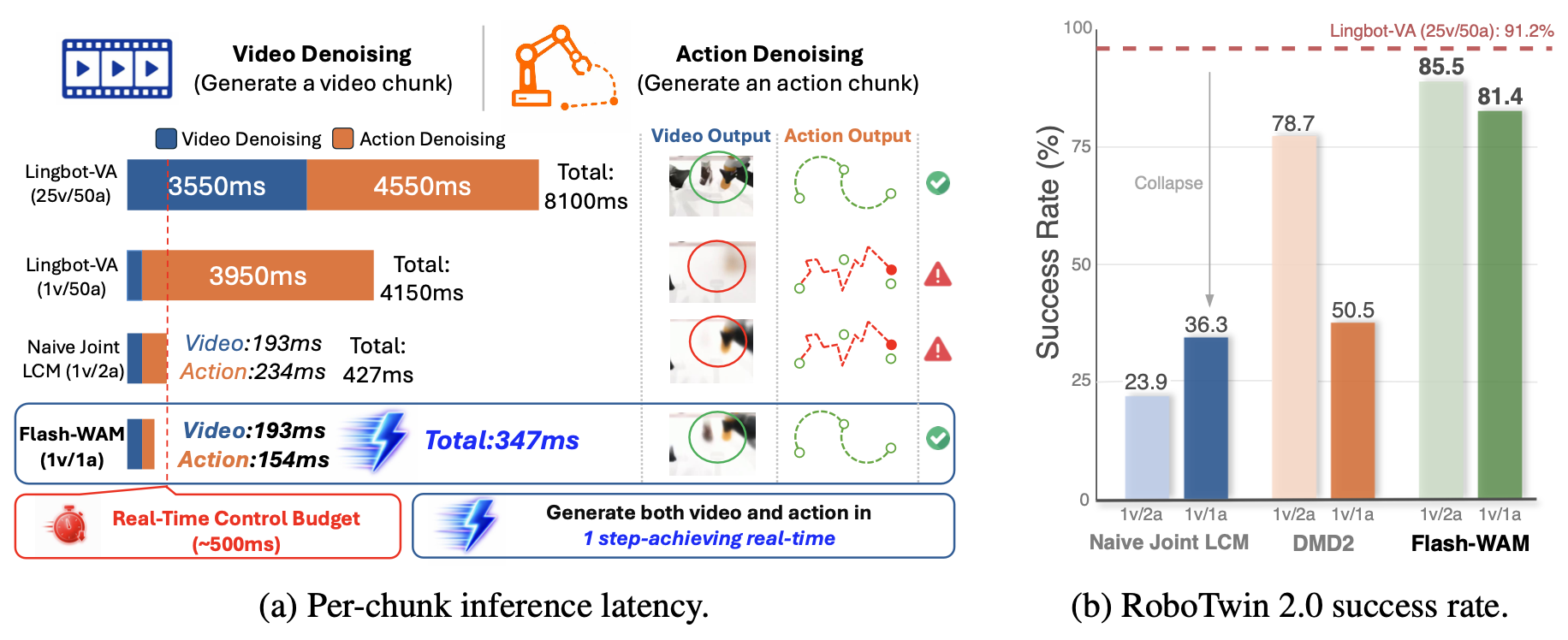
现代世界-动作模型利用“流匹配”(flow matching)——一种通过迭代去噪将噪声转化为数据的连续时间生成过程——来生成未来的视觉状态及相应的动作序列。由于该迭代过程计算成本高昂,研究人员提出“步蒸馏”(step distillation)技术,即训练一个学生模型 θ_S,使其能以更少的去噪步复现预训练教师模型 θ_T 的输出。
1 流匹配(Flow Matching)
流匹配 [19, 6] 是一种连续时间生成框架,旨在学习如何沿直线插值路径将样本从噪声分布“输运”至数据分布。
2 一致性蒸馏(Consistency Distillation)
一致性模型 [29, 22, 9] 通过强制执行一致性属性来加速采样:一致性函数 f(x_σ, σ) 将概率流常微分方程(ODE)轨迹上的任意点映射至其在 σ = 0 处的清晰终点。
3 问题表述
世界-动作模型(WAMs)将策略生成过程分解为两个相互耦合的阶段:一是视觉动力学预测,即预测世界在潜空间中如何演变;二是逆向动力学,即推导出与该预测演变相一致的动作。给定一个概括过往观测、过往动作及语言指令的上下文 C,WAM 联合采样一段包含 K 个未来视频潜向量 xv 的序列及其对应的动作序列 xa:
这种自回归分解将动作建立在预测的未来状态之上。两个阶段共享相同的 Transformer 参数 θ,且均通过流匹配(Flow Matching)实现:视觉动态通过对视频速度场 vv_θ 进行 Nv 步欧拉积分来采样,而逆向动态则通过对动作速度场 va_θ 进行 Na 步积分来采样。因此,生成一个片段需要进行 Nv + Na 次连续的 Transformer 前向传播,这构成了单片段延迟的主要部分,并阻碍了实时控制的实现。用简写 Nv_v / Na_a 来表示特定的函数评估次数(NFE)配置;例如,25v/50a 表示 25 步视频去噪和 50 步动作去噪。
通过步蒸馏降低分块去噪成本,是实现实时部署的必然途径。然而,视频-动作联合任务的设定,与蒸馏方法通常适用的单模态范式有所不同。遵循常规做法 [15, 35],这两个阶段采用相互独立的 SNR 偏移调度器,这反映出:高维且结构上存在冗余的视频潜变量(video latents)能够容忍每一步中较强的噪声,而低维且对精度要求极高的动作序列则需要更温和的调度策略。
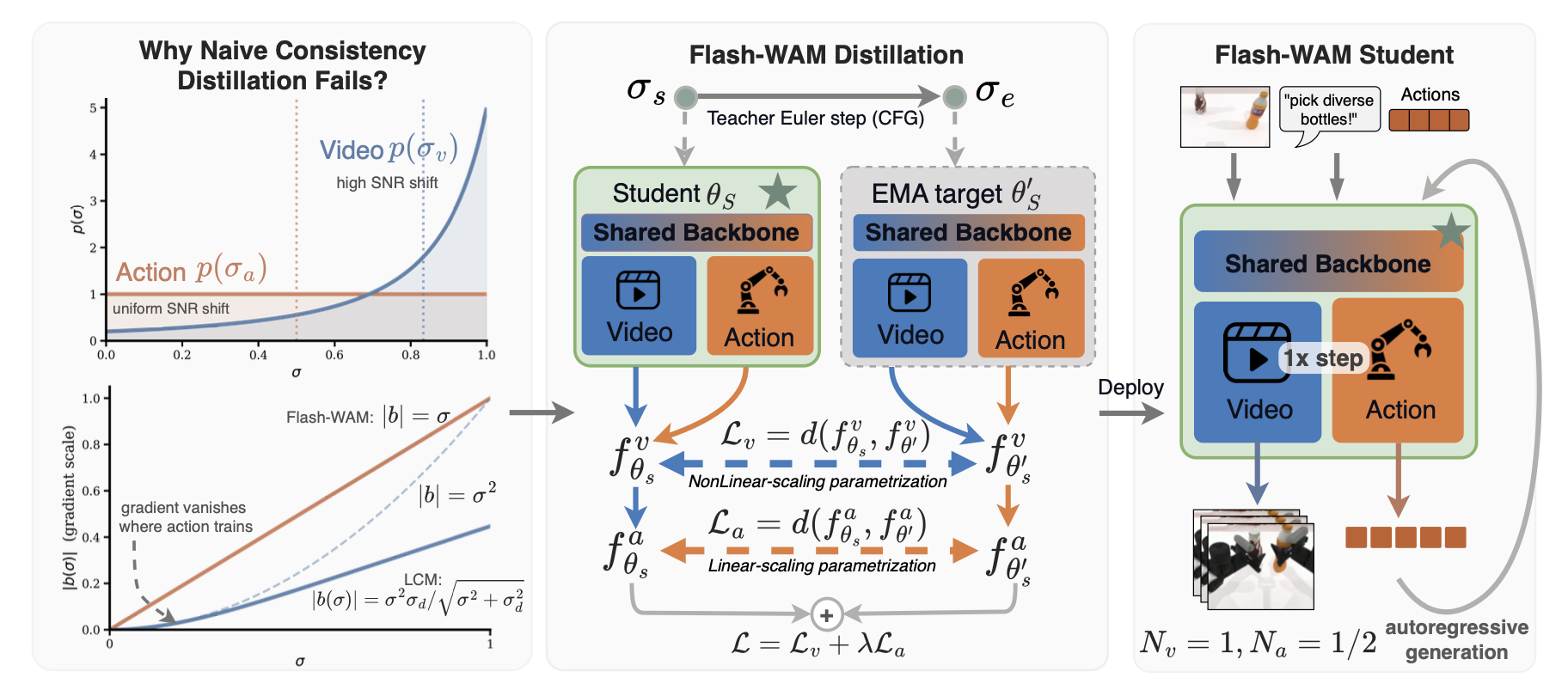
由于这两种调度器将训练权重集中在噪声调度过程的不同阶段,这两种模态在结构迥异的噪声区间内实现一致性蒸馏损失;因此,无法仅靠一个统一应用于两者的单一一致性函数 f (x_σ, σ) = a(σ)x_σ + b(σ)v_θ来同时满足两者的需求。这正是下面 Flash-WAM 所解决的核心难题。
Flash-WAM 是一种用于视频-动作联合扩散模型的分步蒸馏框架。在非对称噪声调度(sv>sas^v > s^asv>sa)下,两个分支在结构迥异的噪声区间内达到一致性蒸馏损失,因此必须针对各自的区间选择相应的一致性函数。
1 联合蒸馏机制
蒸馏联合视频-动作扩散模型最直接的方法,是对两种模态统一应用单一的一致性函数。然而,在定义的联合机制中,这一假设不再适用,因为两种模态在达到损失函数时,其各自的边缘 σ 分布存在显著差异。视频流集中在 [0, 1] 区间的上端,而动作流则分布在整个区间范围内,使得大量训练权重集中在低 σ 值区域。这种不对称性导致的是一种结构性的失效模式,而非仅仅是可通过参数调整来优化的效率低下问题;这促使构建一个能够针对每种模态的特定机制进行专门处理的框架。
这种失效归因于一致性损失在不同噪声水平下提供的梯度信号。任何有效的一致性函数都具有形式 f(x_σ , σ ) = a(σ )x_σ + b(σ )v_θ,并满足边界条件 a(0)=1, b(0)=0。由于 f 仅通过 v_θ 依赖于 θ,因此一致性损失关于θ 的梯度在逐点尺度上与 | b(σ)| 成正比:这意味着无论 v_θ 的预测质量如何,只要 |b(σ)| 很小,网络在噪声水平 σ 处接收到的学习信号就微乎其微。因此,b 的选择决定了模型能够在噪声调度(noise schedule)的哪个阶段进行有效学习。
命题 1(σ → 0 附近的最佳梯度缩放)。设 f(x_σ, σ) = a(σ)x_σ + b(σ)v_θ 为任意一致性函数,其中 a, b ∈ C1([0, 1]) 且满足 a(0) = 1, b(0) = 0。则当 σ → 0 时,|b(σ)| = O(σ),且该界限在且仅在 b′(0) ≠ 0 时达到。
2 模态-觉察一致性函数
动作流。构建与各模态噪声特性相匹配的一致性函数,首先从动作流入手。动作流将训练权重集中在低 σ 区间,而在该区间,命题 1 起着决定性作用。
视频流。作用侧的选择准则(即 σ = 0 附近的线性缩放)并不适用于视频流。当 s_v 较大时,视频分布集中在较大的 σ 区域,而 LCM 在该区域已能提供充足的梯度信号。在此情形下,Flash-WAM 的选择准则转而依赖于 Karras 参数化 [12] 所提供的高 σ 稳定性特性。
联合训练目标。训练学生同时满足两种模态下的一致性属性。每种模态利用其自身的一致性函数贡献一项一致性损失。
完整的 Flash-WAM 目标函数结合两项:L = Lv + λ_a La。
这两个一致性目标均基于每个模型的一次前向传播计算得出:将视频 token 和动作 token 拼接成预训练时使用的联合序列,并由采用 Flex Attention 机制的共享 Transformer 进行处理。因此,这种模态感知参数化仅影响各流(stream)对应的损失计算头,而模型架构及每步计算开销则与教师模型保持一致。
Flash-WAM 的贡献在于这种基于原则的选择:虽然各模态的参数化形式均属于众所周知的一致性函数族,但该框架明确阐述应在何处使用何种形式及其背后的原理。
其概览如图2 所示:
实验设置
将所提方法应用于已发布的 LingBot-VA 模型 [15](共享主干网络版本)。这是一款最先进的开源“世界-动作模型”(WAM),其参数量适中,适合在商用边缘设备上部署——而这正是“步蒸馏”(step distillation)技术最具实际应用价值的场景。其他近期的 WAM(如 Motus [1]、DreamZero [35])采用不同的架构设计,或在架构层面集成各自的推理优化方案,因此不在本文分析范围内。用单块 NVIDIA L40S GPU 测量分块(chunk)推理的延迟。尽管基于分块扩散(chunked diffusion)的实时操作尚无统一的阈值标准,但设定 500 毫秒(即 2 Hz 的分块处理频率)作为实时性指标,这与既有研究 [2, 30] 中报告的运行参数保持一致(见图 1)。
基准测试。在两个仿真基准和一个真实机器人场景中进行评估。RoboTwin 2.0 [4] 是一个双臂操作基准,涵盖 50 项任务,包含两种评估设置:“干净(Clean)”划分(初始配置固定)和“随机(Randomized)”划分(在评估时扰动物体位姿、光照和场景布局,以测试模型对分布偏移的鲁棒性)。LIBERO [20] 包含四个任务集——空间(Spatial)、物体(Object)、目标(Goal)和长程(Long-horizon)任务——每个任务集包含 500 条演示数据。在真实世界评估中,将模型部署在配备 Unitree Dex1-1 夹爪的 Unitree G1 人形机器人上,执行三项操作任务:(T1) 打开锅盖并将土豆放入锅中;(T2) 从包含黄色干扰瓶的场景中拾取红色瓶子;(T3) 拾取粉色物体并将其放置在标记的目标位置。针对每项任务,收集 50 条遥操作演示数据,并报告每种方法在每项任务中进行 10 次独立运行(rollout)的成功率。
基线方法。将 Flash-WAM 与针对联合视频-动作生成模型重新实现的现有步-蒸馏算法进行比较。“朴素联合 LCM”(Naive joint LCM)方法将标准的 LCM 一致性函数 [22] 统一应用于视频和动作流,是把本文所提方法的直接对照组。 DMD2 将“分布匹配蒸馏”(Distribution Matching Distillation,DMD)[36] 适配应用于 LingBot-VA 的视频流,并针对动作流引入流匹配正则化项,以稳定在蒸馏后视频输入下的动作行为。“仅视频 LCM”(Video-only LCM)方法仅对视频流进行蒸馏,而保持动作流不变。此外,还列出参考 VLA 基线模型(π0、π0.5、X-VLA、Motus),以便对照评估绝对任务性能。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 13
13 0
0- 0



 已为社区贡献138条内容
已为社区贡献138条内容

所有评论(0)