6.3.2RAG--存储(向量库)
·
上文我们介绍了向量的部分概念和如何生成向量,那么对于RAG来说最后的检索是在知识库中进行检索,我们就要利用向量库去存储生成的好的语义向量。
1.前置知识
1.1向量数据库
向量数据库是专门存储和管理向量的一种介质。
其核心任务是解决传统数据库(如MySQL)不擅⻓的问题:基于内容的相似性搜索(Similarity Search),⽽不是基于精确匹配的查询。
1.2核心机制
1.2.1专门的索引--ANN
这是向量数据库的灵魂。预先为所有向量构建⼀种特殊的索引结构。常见方法ANN(近似最近邻搜索),牺牲些许精度,以相似向量,通过聚类、分层、压缩等算法找几个候选集范围进行查询。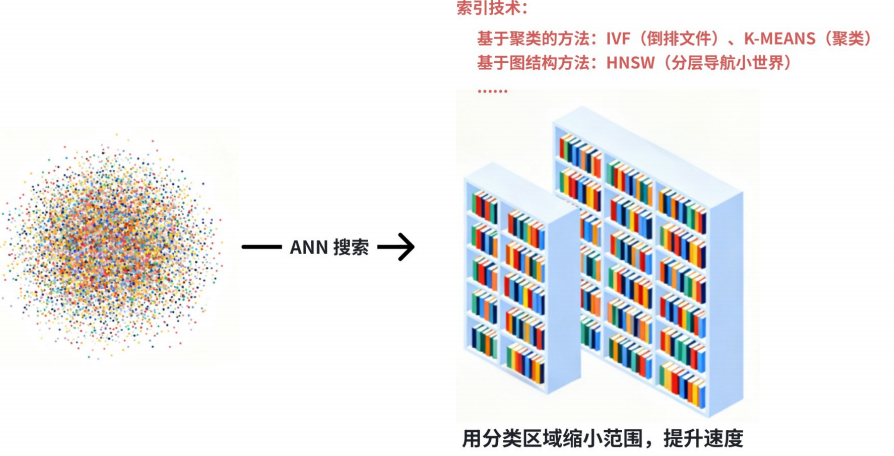
1.2.2向量相似度计算优化
充分利⽤了 CPU 的 SIMD 指令集和 GPU 的并⾏计算 能⼒,让⼤规模的向量计算速度极快。能够快速处理⼤规模数据,并且⽀持在⾼维空间中进⾏相似性搜索SIMD 指令集指 “ 单指令多数据流 ” 技术,是⼀种采⽤⼀个控制器来控制多个处理器,本质上⾮常类似⼀个向量处理器,可对控制器上的⼀组数据(⼜称“数据向量”) 同时分别执⾏相同的操作从⽽实现空间上的并⾏。简单来说,就是⼀个指令能够同时处理多个数据。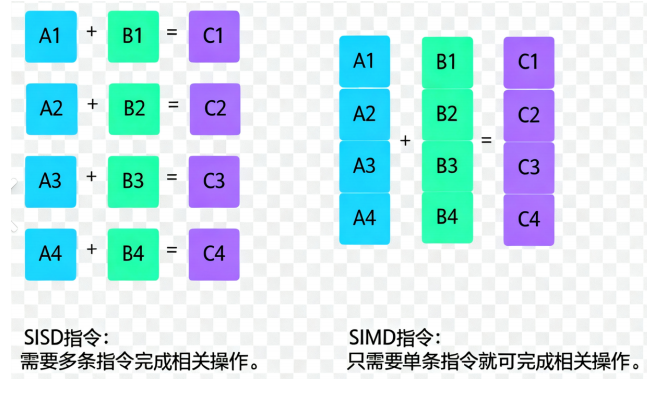
1.2.3数据管理
(1)CRUD 操作:⽀持增删改查,可以动态地更新向量数据。(2)元数据过滤:即条件筛选,利用数据的原生字段进行初步的检索过滤。(3)可扩展性与持久化:它们可以轻松地分布式部署,处理海量数据;同时保证数据持久化,不像纯内存⽅案⼀样断电丢失。(4)集成⽅便:提供友好的API(如gRPC, RESTful),使得像 LangChain 这样的框架可以轻松地与之集成,开发者⽆需关⼼底层细节。
2.介绍三种向量存储
2.1内存存储
我们将使⽤ LangChain 的InMemoryVectorStore来实现向量的内存存储
(1)初始化
LangChain 中的⼤多数向量在初始化向量存储时接受嵌⼊模型作为参数
from langchain_openai import OpenAIEmbeddings
from langchain_core.vectorstores import InMemoryVectorStore
# 定义嵌⼊模型
embeddings = OpenAIEmbeddings(model="text-embedding-3-large")
# 内存存储初始化
vector_store = InMemoryVectorStore(embedding=embeddings)(2)添加文档
我们可以使⽤ add_documents ⽅法,向内存存储中去添加⽂档。要注意的是,该⽅法会为添加的⽂档编排索引,索引列表随着该⽅法返回。这也就是在前⽂中,我们⼀直在提的:当我们想对某⽂本进⾏【数据检索】时的两个步骤:•编制索引: ⽤于从源中摄取数据并为其编制索引。•检索和⽣成 :接受⽤⼾查询并从索引中检索相关数据,然后将其传递给模型
from langchain_community.document_loaders import UnstructuredMarkdownLoader
from langchain_text_splitters import CharacterTextSplitter
# ⽣成分割器
text_splitter = CharacterTextSplitter.from_tiktoken_encoder(
encoding_name="cl100k_base", chunk_size=200, chunk_overlap=50
)
# 加载⽂档
data = UnstructuredMarkdownLoader("../Docs/Markdown/xxx.md").load()
# 分割⽂档
documents = text_splitter.split_documents(data)
# 添加⽂档
ids = vector_store.add_documents(documents=documents)
print(f"共编排了{len(ids)}个⽂档索引")
print(f"前3个⽂档的索引是:{ids[:3]}")(3)获取文档
doc_3 = vector_store.get_by_ids(ids[:3])
print(f"{[doc.page_content for doc in doc_3]}")(4)删除文档
doc_3 = vector_store.get_by_ids(ids[:3])
print(f"{[doc.page_content for doc in doc_3]}")(5)向量检索
相似性
search_docs = vector_store.similarity_search(
query="数据库表怎么设计的?",
k=2
)
for doc in search_docs:
print("*" * 30)
print(doc.page_content)元数据过滤
我们给搜索⽅法加⼊了 filter 参数,它接收⼀个 bool 值,表⽰我们可以根据条件选择是否过滤某些⽂档。因此我们定义了⼀个 _filter_function 过滤函数,可以根据⽂档元数据先过滤出⽂档,再去进⾏搜索。
from langchain_core.documents import Document
def _filter_function(doc: Document) -> bool:
return doc.metadata.get("source") == "hahaha"
search_docs = vector_store.similarity_search(
query="数据库表怎么设计的?",
k=2,
filter=_filter_function
)
for doc in search_docs:
print("*" * 30)
print(doc.page_content)2.2Redis向量存储
2.2.1RedisSearch
Redis被用于存储向量,因为其速度快、拥有庞⼤的客⼾端库 ⽣态系统,并且多年来已被众多⼤型企业采⽤。从本质上讲,Redis 是⼀种键值型的 NoSQL 数据库, 除了传统⽤例之外,Redis 还提供了诸如搜索和查询功能等额外能⼒,允许⽤⼾在 Redis 内创建⼆级索引结构。这使得 Redis 能够以缓存的速度充当向量数据库
为使其具有高性能的搜索和全文索引的功能,官方开发了RediSearch引擎模块。
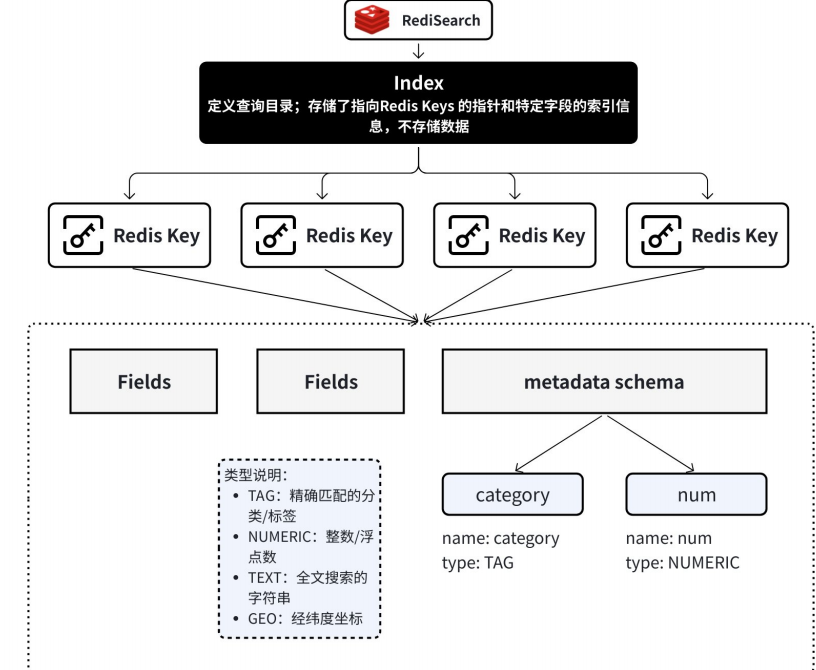
该引擎模块将存储分成三层架构,利用索引和分类达到高效的存储和检索
Index
Index是一个总的用于查询的目录结构,是引擎模块的一个概念。
Index 是⼀个独⽴的数据结构,它建⽴在多个 Redis Keys (Hash 类型)之上,这专⻔为了极速执⾏⽂本搜索、过滤和聚合⽽设计。它 本⾝不存储数据,⽽是存储了指向其他 Redis Keys 的指针,和这些 Keys 中特定字段的索引信 息。类似Mysql中的B+树索引。Index Fields
Index Fields(索引字段) 是创建索引时,明确指定的那些需要被索引的字段。它们定义了索引的“结构”或“蓝图”,告诉 RediSearch:“请针对这些字段的内容,以其特定的⽅式为我构建快速搜索的能⼒。”类似与利用片段中的关键字段建立索引并生成索引ID进行该片段的存储。
Metadata schema
metadata schema 则⽤来描述元数据的结构声明。这⾥的元数据是指我们将来要嵌⼊⽂档的元数据。因为对于⽂档元数据来说,它在存⼊ Redis 后,就被定义成了索引字段。对于⽂档元数据来说,⾥⾯存放的就是⼀些⽂档属性值,如 source 表⽰⽂档来源。我们还可以⼿动加⼊其他元数据,这需要设置每个字段的声明: name 表⽰字段名, type 表⽰字段类型。其作用就是便于条件筛选检索
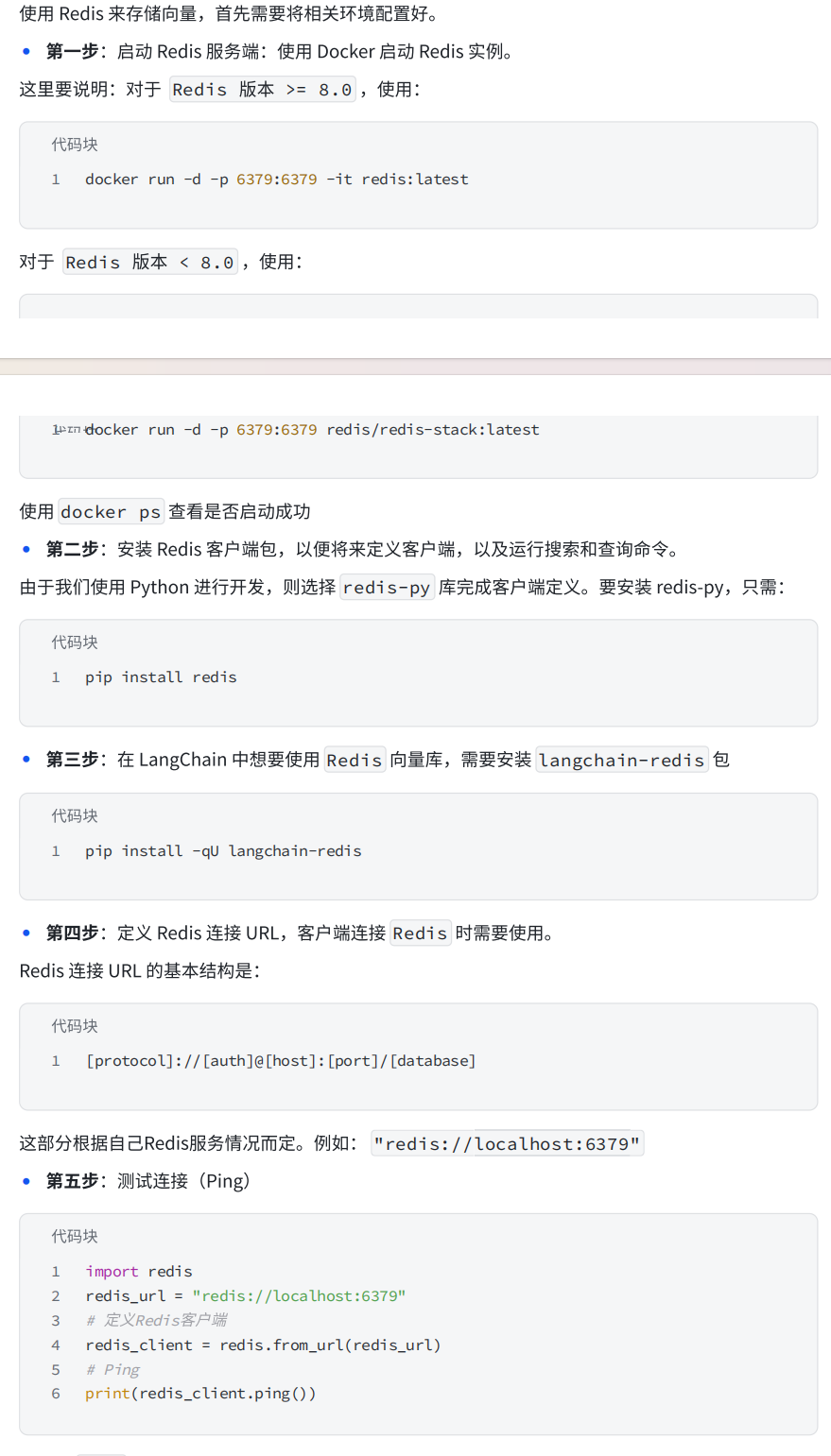
2.2.2环境配置
# Redis
from langchain_openai import OpenAIEmbeddings
from langchain_redis import RedisConfig, RedisVectorStore
# 定义嵌⼊模型
embeddings = OpenAIEmbeddings(model="text-embedding-3-large")
# 配置 Redis 客⼾端
redis_url = "redis://xxx.xxx.xxx:xxx"
config = RedisConfig(
index_name="qa",
redis_url=redis_url,
metadata_schema=[
{"name": "category", "type": "tag"},
{"name": "num", "type": "numeric"},
],
)
# Redis 存储初始化
vector_store = RedisVectorStore(embeddings, config=config)
from langchain_text_splitters import CharacterTextSplitter
# ⽣成分割器
text_splitter = CharacterTextSplitter.from_tiktoken_encoder(
encoding_name="cl100k_base", chunk_size=200, chunk_overlap=50
)
# 加载⽂档
data = UnstructuredMarkdownLoader("../Docs/Markdown/xxx.md", category="QA").load()
# 分割⽂档
documents = text_splitter.split_documents(data)
# 为⽂档添加元数据
for i, doc in enumerate(documents, start=1): #枚举
doc.metadata["category"] = "QA"
doc.metadata["num"] = i
ids = vector_store.add_documents(documents=documents)
print(f"共编排了{len(ids)}个⽂档索引")
print(f"前3个⽂档的索引是:{ids[:3]}")
ids = [":01K4Q0A3DSQVZBRFKJD5MS25HJ", ":01K4Q0A3DSQVZBRFKJD5MS25HK",":01K4Q0A3DSQVZBRFKJD5MS25HM"]
# 获取索引
doc_3 = vector_store.get_by_ids(ids)
print(f"{[doc.page_content for doc in doc_3]}")
# 删除
# 删除指定内容
vector_store.index.drop_keys(["qa::01K4Q0A3DSQVZBRFKJD5MS25HJ"])
# 全量删除,删除索引
vector_store.index.delete(drop=True)
# 检索
category_is_qa = Tag("category") == "qa"
num_is_under_50 = Num("num") < 50
filter_condition = category_is_qa & num_is_under_50
search_docs = vector_store.similarity_search(
query="数据库表怎么设计的?", #相似性检索
k=2, #返回检索结构数量
fetch_k = 10, #MMR初步候选集数量
filter = filter_condition, #元数据条件筛选
)
for doc in search_docs:
print("*" * 30)
print(doc.page_content)2.3Pinecone向量存储
要使用这个亚马逊这个云存储我们需要去其官网注册信息获得密钥,将密钥写进环境变量中进行使用。
from langchain_openai import OpenAIEmbeddings
from langchain_pinecone import PineconeVectorStore
from pinecone import Pinecone, ServerlessSpec
# 建⽴索引
pc = Pinecone()
index_name = "qa"
if not pc.has_index(index_name):
pc.create_index(
name=index_name, # 索引名称
dimension=3072, # 尺⼨,表⽰向量维度,需要和嵌⼊模型维度⼀致
metric="cosine", # 度量⽅式,cosine 表⽰余弦相似度
spec=ServerlessSpec(
cloud="aws", # 亚⻢逊云
region="us-east-1" # 区域
),
)
# 定义嵌⼊模型
embeddings = OpenAIEmbeddings(model="text-embedding-3-large")
# 获取索引
index = pc.Index(index_name)
# 定义 Pinecone 向量存储
vector_store = PineconeVectorStore(embedding=embeddings, index=index)
# ⽣成分割器
text_splitter = CharacterTextSplitter.from_tiktoken_encoder(
encoding_name="cl100k_base", chunk_size=200, chunk_overlap=50
)
# 加载⽂档
data = UnstructuredMarkdownLoader("../Docs/Markdown/xxx.md", category="QA").load()
# 分割⽂档
documents = text_splitter.split_documents(data)
# 为⽂档添加元数据
for i, doc in enumerate(documents, start=1):
doc.metadata["category"] = "QA"
doc.metadata["num"] = i
ids = vector_store.add_documents(documents=documents)
print(f"共编排了{len(ids)}个⽂档索引")
print(f"前3个⽂档的索引是:{ids[:3]}")
# 全量删除
vector_store.delete(delete_all=True)
# 删除指定id的⽂档列表
delete_ids = []
vector_store.delete(ids=delete_ids)
search_docs = vector_store.similarity_search(
query="数据库表怎么设计的?",
k=2,
filter={"category": "QA"},
)
for doc in search_docs:
print("*" * 30)
print(f"Content: {doc.page_content[:100]}...")
print(f"Metadata: {doc.metadata}")
AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 18
18 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)