GLM-5.1 开发轻量级opencode会话提取工具,让对话更有价值
一个提示词模板,粘贴即用——从 OpenCode SQLite 数据库提取开发素材,过滤平台噪音,压缩工具调用,输出干净素材文件。全程 GLM-5.1 开发,经历 11 次调整修改。
完整提示词模板见 六、使用方法
前言:AI 编程的对话里到底有什么
用 AI 写代码的人都有个感受:最有价值的东西不在代码里,在对话里。 为什么要选方案 A 不选方案 B、踩过什么坑怎么解决的、某个功能的设计思路是什么——这些全藏在会话记录中,我们只能手动复制或者在会话中翻找。但会话一压缩,之前的对话就只存在于数据库中了,无法直接查看。
现在 AI 编程工具对"会话"的处理,有两种成熟方案:
第一种:会话状态持久化——让 AI 接着聊。 OpenCode 的 --continue、Claude Code 的 /resume、Cursor 的侧边栏历史。它们保存对话状态,让 AI 下次能接上。但解决的是"连续性"问题,不是"知识提取"问题。
第二种:知识记忆持久化——让 AI 记住项目。 Claude Code 的 MEMORY.md、GitHub Copilot Memory、OpenCode 的 opencode-mem 插件。它们帮 AI 记住项目模式、用户偏好、架构决策。但存的是摘要片段,原文细节全丢了。面向的是 AI,不是人。
第三种:对话知识提取——从对话中提取人能读、能复用的开发素材。
这第三种,目前没人做
| 能力 | OpenCode 原生 | Claude Code | 记忆插件 | 导出工具 | 我们的模板 |
|---|---|---|---|---|---|
| 保留完整对话 | ✅ | ✅ | ❌ 只存摘要 | ✅ 原样导出 | ✅ |
| 过滤工具调用噪音 | ❌ | ❌ | ❌ | ❌ | ✅ |
| 工具调用做摘要 | ❌ | ❌ | ❌ | ❌ | ✅ |
| 按对话回合结构化 | ❌ | ❌ | ❌ | ❌ | ✅ |
| 过滤平台注入前缀 | ❌ | ❌ | ❌ | ❌ | ✅ |
| 无需安装,粘贴即用 | — | — | ❌ 需装插件 | ❌ 需装工具 | ✅ |
OpenCode 的 SQLite 数据库里存着完整的对话数据(用户消息、助手回复、每个工具调用的输入输出),但自带的导出功能输出的是原始数据——一条 bash 命令几 KB、工具调用的完整输出全混在一起,几千行根本没法看。Claude Code 的 /export 也是同样的问题。
记忆插件(opencode-mem、context-bank)面向 AI 存储,自动将对话压缩为 2-4 句摘要注入未来会话,原文细节不会在记忆召回时使用。导出工具(cctrace、claude-trace)只搬运不过滤。
我们需要的是:从完整对话中提取结构化开发素材,过滤噪音,压缩冗余,输出一份人能读、能复用、能写文档的素材文件。 这就是本文介绍的工具做的事。
一、痛点:AI 编程会话的信息黑洞
每天和 AI 对话几百条——功能怎么实现的、踩过什么坑、为什么选方案 A 不选方案 B——全在会话里。
但是想要翻找指定对话,整理会话内容,复盘错误,整合开发经验,都是个麻烦事。
我试过直接让 AI 把会话所有对话内容整理成文档,会出现两种情况,AI搜索大量信息导致上下文撑爆并消耗海量Token,或者提炼成功但是损失了用户原话、决策过程、错误现场中的关键细节。
所以需要两步走:先收集素材(原样保留),再根据自己的具体需求整理文档(只提炼一次)。
但原始数据库里有三种东西混在一起,直接用不了:
-
有用的:用户指令、助手回复、代码改动、决策过程
-
噪音:平台注入的
[search-mode]前缀、<system-reminder>通知、MANDATORY续文 -
膨胀:工具调用的完整输入输出(一条 bash 几 KB)
这个工具做的事:提取 1,洗掉 2,压缩 3,输出一份干净的开发素材文件。然后再用素材根据需求整理成文档,只提炼一次,自己决定保留哪些细节。
二、效果:提取的素材长什么样
先看结果,再讲过程。
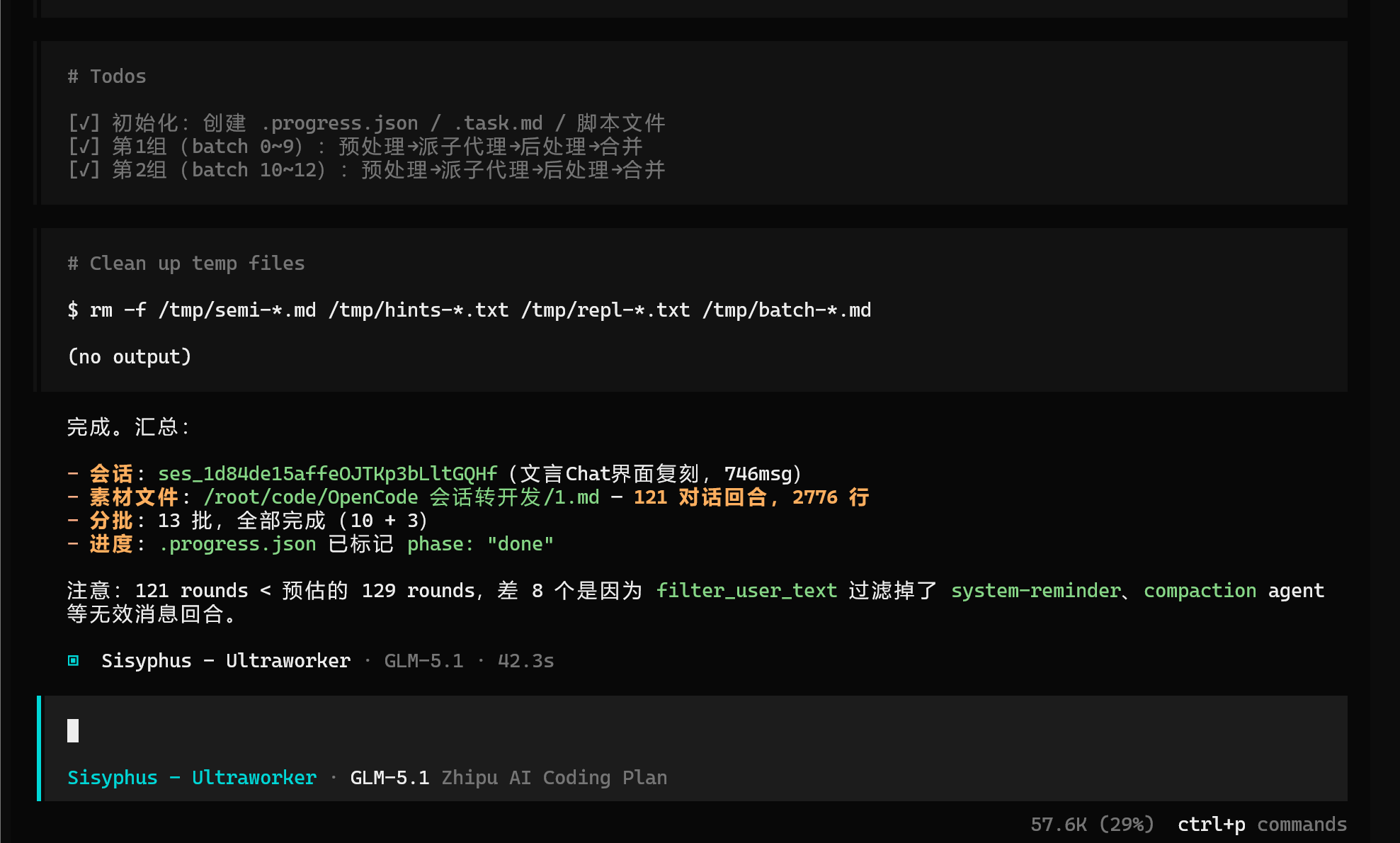
以一个 896 条消息的 文言Chat界面复刻会话为例,耗时10分钟,提取后得到 3,999 行素材文件,覆盖 121 个对话回合,57127词,913 个工具调用全部做了摘要。
素材文件中每个回合的格式:
用户消息和助手回复全文原样保留,只在工具调用上做摘要。这样后续整理文档时有一手原始数据,只提炼一次不丢细节。
三、整体设计思路
一句话:主代理(GLM-5.1)调度 + 子代理(DeepSeek V4 Flash + MiniMax)逐批提取 + SQLite 直查数据库。
为什么这样设计:896 条消息超出上下文窗口,必须分批。按 parentID 分组(每组 = 一个完整对话回合),每批 ~150 parts,不会在回合中间切断。
┌──────────┐ ┌───────────────┐ ┌──────────┐ ┌──────────┐ │ 列出会话 │────▶│ 分析结构分批 │────▶│ 子代理 │────▶│ 合并素材 │ │ (SQLite) │ │ (parentID) │ │ 逐批提取 │ │ → 最终md | │ │ │ │ │ (并行10批) │ │ | └──────────┘ └───────────────┘ └──────────┘ └──────────┘
以下进入 GLM-5.1 的完整开发流程,按 v1 → v11 的时间线讲述。
四、开发过程
v1→v2:数据源选型
v1:session_read 方案——失败了
第一版用 OpenCode 自带的 session_read API 读取历史会话。看起来合理,实际跑起来暴露三个问题:
1. 没有 offset 参数,无法分页
提示词里写了 session_read(session_id, limit=50, offset=实际起点),但 session_read 根本没有 offset 参数。GLM-5.1 花了 3 轮工具调用才确认这件事——limit=50 总是从第一条开始读,要读后面的消息只能加大 limit,每批都重复读前面已处理的消息。
2. 工具调用细节全部丢失
session_read 把工具调用压缩成 [tool: bash],看不到命令内容、参数和返回值。"AI 跑了什么命令、得到了什么结果"是最关键的信息,这一丢素材就只剩文字对话。
3. 搜索质量差
session_search 按关键词匹配消息片段,不支持精确匹配会话标题。每次给一个很明确的会话名字,搜索一大圈还是找不到。
GLM-5.1 在这里做了什么:它尝试了 limit=50、limit=100、limit=200 三种策略,每次都从第一条开始读。确认没有 offset 后,主动提出"去数据库直接查"的方案。
v2:SQLite 直查——成功
GLM-5.1 发现了 OpenCode 的底层数据库 /root/.local/share/opencode/opencode.db,三张核心表:
| 表 | 存什么 |
|---|---|
session |
会话元数据(id、title、创建时间) |
message |
每条消息(role、parentID、data JSON) |
part |
消息组成部分(type="text"/"tool"/"reasoning",含完整 input/output) |
对比测试:
| 维度 | session_read | SQLite 数据库 |
|---|---|---|
| 工具调用细节 | 全部丢失 | 完整可见 |
| 信息密度 | 100 条 → 258 行 | 20 条 → 229 行 |
| 分页能力 | 无 offset | SQL LIMIT/OFFSET |
SQLite 每条消息平均 11 行素材,session_read 只有 2.6 行。
跑通流程,4 批成功提取 781 行素材。质量满意,但慢——每批子代理要花 2-3.5 分钟。
v3→v4:子代理调度架构 + 第一次失败
v3:架构设计
GLM-5.1 自主设计了主代理 + 子代理的调度架构:
-
主代理(GLM-5.1):负责调度和进度管理,维护
.task.md(任务指令)和.progress.json(进度文件) -
子代理(DeepSeek V4 Flash Free):逐批提取,每个处理约 20 条消息
-
三文件冗余:
.task.md+.progress.json+ 素材文件末尾,任何一个丢了都能从其他两个恢复
这个架构不是我先设计好再让 GLM-5.1 执行的——是它分析完上下文限制后直接提出的。
v4:第一次大失败
用精简版提示词在新会话测试,结果完全不能用——子代理把脚本的原始输出直接塞进了素材文件:
- **bash** `npx asar list /mnt/d/bilidown/resources/app.asar 2>/dev/null | head -20 ...` → /0.js /2.js /3.js /assets/css/... - **bash** `cd /tmp/bilidown-src && npx asar extract-file ...` → grep: No such file or directory
完整的 bash 命令和 output 原样拼在一起,完全没有做"工具调用→摘要"的转换。
根因:子代理 prompt 只写了"读 .task.md 获取完整指令"——假设 DeepSeek V4 Flash 会主动去读。实际上它大概率没读,或者读了没严格照做。
GLM-5.1 在这里做了什么:它分析了失败素材文件,定位到问题出在子代理 prompt 太简略——弱模型需要更明确的指令。由此发明了"填空题级别 prompt":
# ❌ 旧:让子代理自己去读
你是素材收集器。
1. 读 .task.md 获取完整指令
2. 按 .task.md 的规则处理
# ✅ 新:内联关键规则(填空题级别)
【格式模板】
## 对话回合#{序号}
### 用户 / ### 助手 / ### 工具调用
【提取规则】
- bash: 用一句话描述意图,不贴完整命令
✅ bash 重新提取纯净源码。→ 386KB, 10642 行
❌ bash `npx asar extract /mnt/d/bilidown/...` → /0.js /2.js/...
【禁止】
- 不要粘贴完整 bash 命令(含管道、重定向、长路径)
- 不要粘贴完整 output(文件列表、几 KB 代码)
经验:弱模型 + 超详细 spec > 强模型 + 粗略 spec。
v5→v7:棘手问题——用户消息被注入了指令前缀
这是整个开发过程中最棘手的问题。GLM-5.1 花了 3 轮调整才彻底解决。
问题
OpenCode 的 oh-my-opencode 插件会在用户消息前面注入指令块。用户输入的是"怎么了,你刚刚改动之后好像卡住了",数据库里存的却是:
[analyze-mode] ANALYSIS MODE. Gather context before diving deep: ... *** MANDATORY delegate_task params: ALWAYS include load_skills=[] ... *** 怎么了,你刚刚改动之后好像卡住了,在检查什么吗
v4 的过滤逻辑是 startswith('[analyze-mode]') 一刀切——整条消息都扔了。但这条消息后面明明有用户的实际输入。
三版过滤逻辑的迭代
第一版:找最后一个 \n---\n 分隔线,取后面的内容。
失败:用户输入内容本身也可能包含 ---(比如粘贴的提示词模板),取"最后一个"会把用户输入切成两半。
第二版:遍历所有分隔线,检查每段首行是否以指令关键词(MANDATORY、ANALYSIS MODE、MAXIMIZE 等)开头。
问题:关键词列表永远不全,而且 ANALYSIS MODE 等其实不会出现在分隔线后面(它们在第一个 --- 之前)。
第三版:GLM-5.1 去查了 oh-my-opencode 源码,确认了注入模板的精确格式。结论:分隔线后面的注入段只有三种开头——MANDATORY、[search-mode]、[analyze-mode]。不需要更多关键词。
核心逻辑:
_SKIP_PREFIXES = ('MANDATORY delegate_task', '[search-mode]', '[analyze-mode]')
segs = raw_text.split('\n---\n')
for i, seg in enumerate(segs):
first_line = seg.strip().split('\n')[0]
if any(first_line.startswith(sp) for sp in _SKIP_PREFIXES):
continue
# 找到第一个非注入段 → 后面全是用户输入(用 join 拼回,不截断用户内容中的 ---)
text_content = '\n---\n'.join(segs[i:]).strip()
break
极端 case:双前缀嵌套
GLM-5.1 在这里做了什么:它在分析 106 条前缀消息时,发现了双前缀消息——
[search-mode]+ MANDATORY +[analyze-mode]+ MANDATORY + 用户输入,全挤在一条消息里。有些极端消息中,用户输入被追加到了 MANDATORY 模板的 Example 行末尾(Example: delegate_task(...)怎么了)。这种极端情况人类很难预见到,是 GLM-5.1 从数据库中挖掘出来的。
致命 bug:过滤做了但没用上
用 DeepSeek V4 Pro review 代码时发现:过滤逻辑只在 text_content 变量中做了清洗,但脚本输出部分仍然直接打印原始 p["text"]——过滤白做了。典型的"单元测试过了,集成没跑"。
最终修复:106 条前缀消息全量测试,0 条泄漏,0 条误丢。
v8:关键转折——GLM-5.1 自主优化执行策略
前面 4 批用旧版提示词跑的,效果还行但速度慢。我直接在新会话里跑了一版旧提示词,没想到效果出奇地好——112 个回合、3999 行素材,25 批全部完成,工具调用摘要清晰规范。
为什么好?不是随机性
去数据库里查了那个成功会话的完整执行记录。GLM-5.1 主代理自行做了 3 件提示词没要求的事:
1. 自己创建了查询脚本
不是让子代理自己写 python3 内联代码,而是 GLM-5.1 先生成了 /tmp/bilidown-query.py,子代理只需 python3 /tmp/bilidown-query.py OFFSET COUNT。
2. 从串行改为并行+临时文件+合并
25 个批次分成 5 组,每组 5 个子代理并行执行,每个写独立临时文件,主代理用 cat 合并。
3. 自适应精简子代理 prompt
观察到前几批成功后,主动降低了后续批次的 prompt 粒度:
| 批次 | 模型 | Prompt 长度 | 每批耗时 |
|---|---|---|---|
| 1-5 | GLM-5.1 | ~2100 chars | 2m49s ~ 7m29s |
| 6-10 | DeepSeek | ~1100 chars | 48s ~ 1m53s |
| 11-15 | DeepSeek | ~610 chars | 同上 |
| 16-25 | DeepSeek | ~360 chars | 同上 |
效果好的根因不是提示词本身,而是执行提示词的主代理能力。
从成功经验中提炼改动
分析完成功会话后,提示词做了以下改动:
-
查询方式:session_search → 直查数据库(一条 SQL 列出主代理会话)
-
查询脚本:内联 python3 代码 → 预先生成独立脚本文件
-
并行策略:串行追加 → 每组 10 批并行(5 个 DeepSeek V4 Flash + 5 个 MiniMax 交替),独立临时文件再合并
-
子代理 prompt:依赖读 .task.md → 填空题级别内联(格式模板+正反例+禁止项)
-
.task.md:140 行子代理指令手册 → 12 行主代理备忘录
-
消除重复:摘要模板、格式模板、查询代码各只保留一份
v9→v11:性能优化——脚本替代 AI
v10 质量满意但慢。优化目标:不降质量,提速。
核心思路
v10 中子代理要做的机械工作太多了:解析消息结构、按回合分组、Markdown 防护(标题降级、围栏闭合、分隔线替换)、格式化输出。这些全是不需要 AI 判断的固定逻辑。
GLM-5.1 在这里做了什么:它设计了三阶段流水线,把机械工作全部交给 Python 脚本,AI 只做"摘要"这一件事。
┌──────────────┐ ┌───────────┐ ┌──────────┐ │ format_batch │────▶│ AI 子代理 │────▶│ merge │ │ (Python) │ │ (摘要) │ │ (Python) │ │ DB → semi.md │ │ hints.txt │ │ semi.md │ │ + hints.txt │ │ ↓ │ │ + repl │ │ 解析字段→ │ │ repl.txt │ │ = batch │ │ 按字段截断 │ │ │ │ 替换占位 │ └──────────────┘ └───────────┘ └──────────┘
-
format_batch.py:DB → semi.md(工具调用位置留
[待摘要:N]占位符)+ hints.txt(工具调用关键内容,按字段截断) -
AI 子代理:只读 hints.txt → 输出 repl.txt(工具调用摘要)
-
merge_batch.py:semi.md + repl.txt → batch.md(机械替换占位符)
上下文缩减 70%
| 部分 | v10 AI 读取 | v11 AI 读取 |
|---|---|---|
| 用户消息 | 全读 | 不读(Python 直接写 semi.md) |
| 助手消息 | 全读 | 前 200 字符(hints.txt 里) |
| 工具调用 | 全读 | 按字段截断后的关键内容 |
| 合计 | ~1230 KB | ~367 KB |
不同工具按字段截断到不同长度(都是实测出来的):
| 工具 | 保留什么 | 截断后 |
|---|---|---|
| edit | filePath + newString[:2000] | ~2000 字符 |
| background_output | task_id + output[:1500] | ~1500 字符 |
| bash | cmd[:150] + desc + output[:300] | ~450 字符 |
| read | filePath + output[:300] | ~300 字符 |
五、GLM-5.1 开发体验总结
11 次调整全程使用 GLM-5.1 作为主模型,搭配 DeepSeek V4 Flash + MiniMax 做执行层。
它擅长的
架构设计:从 v1 的 session_read 单体方案到 v3 的主代理+子代理架构,是 GLM-5.1 自己提出的。v9 的三阶段流水线(format_batch → AI 摘要 → merge)也是它设计的。
复杂调试:从数据库 106 条前缀消息中挖掘出双前缀嵌套的极端 case,定位到 oh-my-opencode 的 keyword-detector 注入逻辑。
自主优化:在 v8 的实际运行中,GLM-5.1 自行做了 3 件提示词没要求的事(创建脚本、并行化、自适应精简 prompt),说明它不只是执行指令,能主动改进方案。
它的短板(夹带私货)
Lite套餐生成速度慢:从0开始思考并生成500 行代码 20 分钟起步,30 分钟超时会导致丢失所有进度。
上下文限制:GLM-5.1 上下文长度只有200k,经常触发压缩
分流策略
GLM-5.1 做规划和调度("怎么干"),5个DeepSeek V4 Flash + 5个MiniMax M3做具体执行("照着干")。速度远快于 GLM-5.1一个模型执行,且质量一致——关键是 GLM-5.1 给了它们"填空题级别"的详细 spec(内联提示词模版)。
🙋蹲队友拼智谱 Coding Plan!
🧩国内顶流编程大模型,20+主流工具全适配,性价比拉满,
👉立即参与「拼好模」:https://www.bigmodel.cn/glm-coding?ic=LJEKCPOQLP
六、使用方法
3 步使用:
-
新建 OpenCode 会话 → 复制阶段一提示词 → 替换
{花括号}→ 粘贴发送 -
等跑完 → 翻阅素材文件确认无遗漏
-
复制阶段二提示词 → 粘贴发送 → 生成开发文档(阶段二的提示词只是示例,每个人需求不同,可以自行调整)
前置条件:WSL下的OpenCode + oh-my-opencode + SQLite 数据库
完整提示词模板:session-doc-prompt/session-doc-prompt-v1.1.md at main · ssbh163/session-doc-prompt · GitHub
注意:目前提示词仅适配 WSL 下的 OpenCode,其他平台使用的 OpenCode 或终端 Agent 需要调整opencode实际数据库所在位置(/root/.local/share/opencode/opencode.db)。
七、总结
核心观点:AI 编程的工作成果不只体现在代码里,更体现在对话中。会话素材收集是填补"AI 编程文档空白"的第一步。
可改进方向:
-
适配更多 AI 编程工具:目前仅适配 WSL 下的 OpenCode(SQLite 数据库路径固定)。Cursor、Claude Code、Windsurf 等工具也有本地数据存储,理论上可以复用相同的"直查数据库 → 三阶段流水线 → 结构化输出"架构,只需适配数据源。
-
封装为 OpenCode 插件或 Skill:当前形态是提示词模板,优点是零门槛粘贴即用,缺点是每次都要等 AI 自己生成 Python 脚本。封装成插件后脚本内置,省掉重复生成环节,速度和稳定性都会提升。
-
批量提取 + 主题聚合:目前一次提取一个会话。实际开发中一个功能可能跨 3-5 个会话,后续可以支持批量提取后按主题自动聚合,把分散在多个会话中的同一功能开发过程合并成一份完整素材。
-
素材去重:同一个问题在不同会话中反复出现(比如"怎么配路由"问了 3 遍),提取后应标记去重,避免文档冗余。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 8
8 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)