创新实训7——数仓模块修复 + 优化
数据模块的功能基本都实现了,包括取数、ETL、后端服务集成。但由于实现过程中为了最终结果实现,存在一部分硬编码或者配置不合理的地方。本文就对数据模块进行修复,为后续后端开发提供功能更完善的数仓模块。
当前问题速览
审查范围:
data-collector模块全部 Scala 源文件、common模块配置审查日期:2026-06-06
🔴 严重问题(影响数据正确性 / 可能导致数据丢失)
1. DWSToADSDirect 会清空业务表 + 写入假数据
文件: data-collector/.../DWSToADSDirect.scala
问题描述: 这个对象的职责是"ADS 层计算质量评分",但它实际做的是:
- 创建
test_user用户(第29-56行) TRUNCATE清空 repository 表(第78-81行)- 重新从
dwd_repo_detail往repository表插入一次(第83-116行) TRUNCATE清空 analysis_task 表(第72-75行)- 为所有 repository 创建新 analysis_task(第129-150行)
TRUNCATE清空 metric_result 表(第67-70行)- 用
ROW_NUMBER() * 100 + 1000这种假公式写入 metric_result(第162-175行)
后果:
- 用户通过前端添加的仓库会被清空
- 业务创建的 analysis_task 记录会被清空
- metric_result 的评分是假的(
1000 + 行号*100行代码、85 + 行号*2.5分评分)
修复建议:
- 不要 TRUNCATE 业务表,改用 task_id 关联
- 评分应从
dwd_file_metric_detail和dws_repo_daily_metrics计算真实值 - 如果用不到这个类的逻辑,UnifiedETLJob 的
all路径应该跳过它,改用真正的 MetricsCalculator
2. CodeParseETL 下载失败时 return 会跳出整个流程
文件: data-collector/.../CodeParseETL.scala 第49-53行
repos.foreach {
row => val zipSuccess = GitHubAPIClient.downloadRepoZip(token, repoFullName, savePath)
if (!zipSuccess) {
println(s"跳过仓库: $repoFullName (下载失败)") return // ← 这里 return 的是 main 方法,不是 foreach!
}
}问题描述: 在 Scala 匿名函数中 return 会从包含它的命名方法(这里是 main)返回,而不是从 foreach 跳出。这意味着:
- 如果第1个仓库下载失败,整个 ETL 结束,不处理剩下的仓库
- 如果第2个仓库下载失败,后续所有仓库被跳过
修复建议:
- 改为
zipSuccess判断后println然后继续foreach循环 - 或者在
repos前先filter掉无法下载的仓库
3. CodeParseETL 只解析 .java 文件(硬编码)
文件: CodeParserLocal.scala 第49行
else if (file.getName.endsWith(".java")) List(file)问题描述: 硬编码只扫描 .java 文件,遇到 Python/JS/Scala/Go 项目时,dwd_file_metric_detail 表为空,导致 DWS/ADS 层没有文件级指标数据。但 GitHub 搜索的是所有 Java 语言仓库,所以当前问题不大——但团队如果以后要支持多语言就得改。
修复建议:
- 配置化文件扩展名列表
- 或用 ANTLR4 的通用解析器
🟡 中等问题(影响功能完整性 / 数据质量)
4. DWDToDWSDirect 只写了 3 个字段
文件: data-collector/.../DWDToDWSDirect.scala 第35-37行
INSERT INTO dws_repo_daily_metrics (repo_url, stat_date, star_count, fork_count, open_issue_count)问题描述: dws_repo_daily_metrics 表有 20+ 个字段(commit_count_7d, comment_density, quality_score, issue_close_rate 等),但 DWS 层只写入了 3 个有效字段,其余全部为 NULL。
同样,语言统计表中 avg_quality_score 和 avg_comment_density 写死为 AVG(0)(第117行)。
后果:
quality_score在 DWS 层为 0,下游 ADS 层和 AI 要依赖的汇总数据缺失- 前端无法展示 commit 活跃度、Issue 解决率等指标
修复建议:
- DWDToDWSDirect 需计算更多指标(可从 dwd_contributor_detail、dwd_issue_detail 聚合)
- 或把这项任务交给 MetricsCalculator
5. ODSToDWDDirect has_wiki / has_pages 写死 0
文件: data-collector/.../ODSToDWDDirect.scala 第93-94行
insertStmt.setInt(15, 0) // has_wiki insertStmt.setInt(16, 0) // has_pages问题描述: GitHub API 返回的 JSON 中其实包含 has_wiki 和 has_pages 字段(布尔值),但代码直接写死为 0,导致数据丢失。
修复建议
val hasWiki = if (jsonObj.has("has_wiki")) jsonObj.get("has_wiki").getAsInt else 0
val hasPages = if (jsonObj.has("has_pages")) jsonObj.get("has_pages").getAsInt else 06. GitHubAPICollector 搜索条件固定
文件: data-collector/.../GitHubAPICollector.scala 第125-126行
// Step 1: Search repositories with high stars
val query = "language:Java stars:>5000"
val repos = GitHubAPIClient.searchRepos(token, query, perPage = 50)问题描述: 搜索条件硬编码为 language:Java stars:>5000,无法配置。如果要采集其他语言或更低 star 数的仓库,需要改源码。
修复建议:
- 从命令行参数读取搜索条件
- 或从
env_config.txt读取
7. CodeParseETL ZIP 下载无超时 + 大文件会 OOM
文件: GitHubAPIClient.scala 第264-289行
def downloadRepoZip(token: String, repoFullName: String, savePath: String): Boolean = {
val response = Http(url) .header("Authorization", s"Bearer $token")
.option(HttpOptions.followRedirects(true)) .asBytes // ← 一次性加载整个 ZIP 到内存问题描述:
- 没有设置
connectTimeout/readTimeout,大仓库 ZIP 可能卡住 .asBytes把整个 ZIP 加载到内存,大仓库(几百 MB)可能 OOM- 没有断点续传能力
- 没有 User-Agent 头(GitHub API 建议设置)
修复建议:
- 设置超时:
.option(HttpOptions.connectTimeout(10000)).option(HttpOptions.readTimeout(60000)) - 使用流式写入(
asBytes改为分块下载) - 添加 User-Agent
8. IncrementalCollector 逻辑不完整
文件: data-collector/.../IncrementalCollector.scala
问题描述:
- 第69行:
getLastCollectTime直接返回now - 30天作为默认值,没有做持久化 - 第73-89行:SQL 注入风险,
$lastTime直接拼接到 SQL 字符串中 - 第195-198行:
updateCollectTime直接跳过不做任何持久化(因为表里没有 etl_time 字段) - 未被
UnifiedETLJob的all路径调用
修复建议:
- 在
dwd_repo_detail表加etl_time字段,或用单独表存采集时间戳 - SQL 改为参数化查询
- 接入全链路
🔵 轻微问题 / 代码优化
9. GitHubAPIClient JSON 字符串手动拼接
文件: GitHubAPIClient.scala 第137-161行
问题描述: 在 GitHubAPICollector.collectRealData() 中,通过字符串拼接手动构建 JSON:
val responseJson = s"""{ "name": "${repo.name}", "description": "${repo.description.replace("\"", "\\\"").replace("\n", "\\n")}", ... }"""如果 description 包含换行符、引号或其他特殊字符,即使做了 replace 也依然可能破坏 JSON 格式。
修复建议:
- 使用 Gson 或 Jackson 构建 JSON 对象再序列化,不要手拼字符串
10. AppConfig MYSQL_URL 缺少 allowPublicKeyRetrieval
文件: common/.../AppConfig.scala 第11行
val MYSQL_URL = "jdbc:mysql://localhost:3306/codeq_db?useSSL=false&serverTimezone=Asia/Shanghai"问题描述: 缺少 allowPublicKeyRetrieval=true。MySQL 8.0 在某些认证插件下会报 Public Key Retrieval is not allowed 错误,与 PromptBuilderLLMTest 之前遇到并修复的问题一样。
修复建议
val MYSQL_URL = "jdbc:mysql://localhost:3306/codeq_db?useSSL=false&serverTimezone=Asia/Shanghai&allowPublicKeyRetrieval=true"11. lit() 版本文件仍保留在项目中
涉及文件:
ODSToDWD.scala(vsODSToDWDDirect.scala)DWDToDWS.scala(vsDWDToDWSDirect.scala)DWStoADS.scala(vsDWSToADSDirect.scala)
问题描述: 每个 ETL 层都有两个版本,lit 版本用模拟数据,Direct 版本才是真实 JDBC 实现。新开发者看到这些文件容易困惑。
修复建议:
- 对团队无影响,只是代码冗余,可等稳定后删除 lit 版本
12. 密码散落在多处
问题描述: MySQL 密码 D200504193010 同时出现在:
application.propertiesAppConfig.scalaSparkJobService.java(硬编码)PromptBuilderLLMTest.java(硬编码)环境变量 / env_config.txt
改密码需要改 5 个地方。
修复建议:
- 统一走环境变量或配置中心
总结:修复优先级建议
| 优先级 | 问题 | 影响 |
|---|---|---|
| P0 | DWSToADSDirect 清空业务表写假数据 | ⚠️ 用户数据丢失 |
| P0 | DWSToADSDirect metric_result 假评分 | quality_report 不可信 |
| P0 | AppConfig MySQL URL 缺 allowPublicKeyRetrieval | MySQL 8.0 连接失败 |
| P1 | CodeParseETL return 跳出 main | 多仓库采集中断 |
| P1 | DWDToDWSDirect 只写 3/20+ 字段 | DWS 层数据大量缺失 |
| P1 | ZIP 下载无超时 + OOM | 大仓库卡死或崩溃 |
| P2 | ODSToDWDDirect has_wiki 写死 0 | 少量字段丢失 |
| P2 | GitHubAPICollector 搜索条件固定 | 无法灵活采集 |
| P2 | JSON 手动拼接 | 可能 JSON 解析失败 |
| P3 | IncrementalCollector 未接入 | 浪费 API 配额 |
| P3 | lit 版本冗余 | 代码维护成本 |
| P3 | 密码散落多处 | 运维成本 |
修复规划
1. 先修 P0 — DWSToADSDirect 改成别动业务表 + AppConfig 补参数
2. 再修 P1 — CodeParseETL 的 return 改掉 + DWDToDWSDirect 补充更多字段
3. 剩下的 P2/P3 — 影响不大,可以后面迭代再搞
P0/P1 修复内容与结果总结
修复日期:2026-06-06 涉及模块:data-collector(5个文件)、common(1个文件)
P0-1: DWSToADSDirect 完全重写
修改前的问题
TRUNCATE清空repository、analysis_task、metric_result三张业务表- 用假公式生成 metric_result(
code_lines = 1000 + ROW_NUMBER()*100、quality_score = 85 + ROW_NUMBER()*2.5) - 与后端共享的 repository 表数据会被清空,用户数据丢失
修改内容
- 不再清空任何业务表,只做 INSERT
- 自动创建
system_etl系统用户(用于 ETL 独立运行时) - 仓库同步:DWD → repository 只插入不存在的(LEFT JOIN 判重)
- 任务复用:优先使用后端创建的 PENDING 状态 analysis_task,无则新建
- 真实指标计算:从
dwd_file_metric_detail聚合每个仓库的 code_lines、comment_lines、blank_lines、comment_density、avg_cyclomatic_complexity、high_complexity_func_count - 真实评分公式:
quality_score = 70 - max(0, avg_complexity-5)*4 + min(comment_density*100, 15) - min(high_complexity_count*2, 20)最终 clamp 到 [0, 100]
- 文件级指标写入
file_metric表(从dwd_file_metric_detail复制)
测试结果
[1/5] System user ready, id=5
[2/5] Repositories synced: 0 new inserts ← 旧数据未丢失
[3/5] Analysis tasks prepared: 50 tasks
[4/5] Metric results computed: 4 rows ← 真实评分
[5/5] File metrics populated: 5964 rows ← 文件级指标
真实评分样例: | 仓库 | 代码行 | 复杂度 | 评分 | |------|--------|--------|------| | arthas | 158,605 | 11.88 | 37.47 | | GitHub-Chinese-Top-Charts | 5 | 1.0 | 85.0 |
P0-2: AppConfig MySQL URL 修复
修改前
val MYSQL_URL = "jdbc:mysql://localhost:3306/codeq_db?useSSL=false&serverTimezone=Asia/Shanghai"修改后
val MYSQL_URL = "jdbc:mysql://localhost:3306/codeq_db?useSSL=false&serverTimezone=Asia/Shanghai&allowPublicKeyRetrieval=true"原因
MySQL 8.0 默认 caching_sha2_password 认证插件需要客户端获取服务器公钥。不加此参数会在 JDBC 连接时报 Public Key Retrieval is not allowed。
测试结果
✅ 全链路 ODS→DWD→DWS→ADS 所有 MySQL 连接均正常
P1-1: CodeParseETL 容错修复(2 处)
修复 A:Scala foreach 中 return 改为 if-else
修改前
if (!zipSuccess) {
println(s"跳过仓库: $repoFullName (下载失败)")
return // ← return 跳出的是 main 方法!后续仓库全部跳过
}修改后
if (!zipSuccess) {
println(s"跳过仓库: $repoFullName (下载失败)") // 不 return,只跳过当前迭代
} else { // 正常处理... }修复 B:ZIP 解压异常保护
修改前: CodeParserLocal.unzip() 内部抛异常直接传到 main,整个 ETL 退出
修改后:
unzip()返回Boolean,内部 try-catch- 调用处检查返回值,失败时跳过当前仓库
- 外层再加 try-catch 兜底
测试结果
处理仓库: krahets/hello-algo Downloaded → Unzip failed: zip file is empty → 跳过仓库(不中断) 处理仓库: alibaba/arthas Downloaded → Unzipped → 成功解析 处理仓库: GrowingGit/GitHub-Chinese-Top-Charts Downloaded → Unzipped → 成功解析 ETL job completed successfully ← 3 个仓库完成,失败的不阻塞
P1-2: DWDToDWSDirect 字段补全
修改前
只写入 3 个字段:
INSERT INTO dws_repo_daily_metrics (repo_url, stat_date, star_count, fork_count, open_issue_count)其余 17 个字段全部 NULL。
修改后
改为多表 LEFT JOIN 聚合,写入 14 个字段:
| 字段 | 数据来源 |
|---|---|
| star_count, fork_count, open_issue_count | dwd_repo_detail |
| total_files, total_code_lines | dwd_file_metric_detail GROUP BY |
| avg_cyclomatic_complexity, comment_density | dwd_file_metric_detail AVG / 公式 |
| high_complexity_func_count | dwd_file_metric_detail COUNT WHERE >20 |
| active_contributor_count_30d | dwd_contributor_detail COUNT DISTINCT |
| days_since_last_commit | dwd_repo_detail.pushed_at → DATEDIFF |
| closed_issue_count_30d, new_issue_count_30d, issue_close_rate | dwd_issue_detail GROUP BY |
语言统计表 avg_comment_density 也改为真实 AVG(原来写死 AVG(0))。
附加修复
在途中发现 dwd_repo_detail.pushed_at 是 ISO 格式字符串 '2026-04-18T18:23:33Z',MySQL DATEDIFF 报错 Truncated incorrect datetime value。在 SQL 中用 STR_TO_DATE(REPLACE(...), '%Y-%m-%d %H:%i:%s') 转换后解决。
测试结果
dws_repo_daily_metrics: 50 rows ✅ dws_language_stats: 1 row (Java, 50 repos, 2.3M stars) ✅
P1-3: GitHubAPIClient ZIP 下载超时配置
修改前
val response = Http(url) .header("Authorization", s"Bearer $token")
.option(HttpOptions.followRedirects(true))
.asBytes // ← 无超时,大仓库可能永远卡住修改后
val response = Http(url) .header("Authorization", s"Bearer $token")
.option(HttpOptions.followRedirects(true))
.option(HttpOptions.connTimeout(30000)) // 连接超时 30 秒
.option(HttpOptions.readTimeout(120000)) // 读取超时 2 分钟
.asBytes测试结果
✅ 三个仓库均在 90s 内完成(2 成功 1 跳过),无卡死
修改文件清单
| 文件 | 改动 |
|---|---|
data-collector/.../DWSToADSDirect.scala |
完全重写:不再 TRUNCATE,真实指标聚合,真实评分公式 |
data-collector/.../DWDToDWSDirect.scala |
重写:3 字段 → 14 字段,4 表 LEFT JOIN,修复日期格式 |
data-collector/.../CodeParseETL.scala |
return → if-else,解压 try-catch 容错 |
data-collector/.../CodeParserLocal.scala |
unzip() 返回 Boolean,内部异常捕获 |
data-collector/.../GitHubAPIClient.scala |
downloadRepoZip 添加 connTimeout + readTimeout |
common/.../AppConfig.scala |
MYSQL_URL 添加 allowPublicKeyRetrieval=true |
修复后全链路数据量
| 层 | 表 | 行数 | 数据质量 |
|---|---|---|---|
| ODS | ods_github_api_raw | 50 | ✅ |
| DWD | dwd_repo_detail | 50 | ✅ |
| dwd_contributor_detail | 1 | ⚠️ Gson 泛型间歇异常 | |
| dwd_issue_detail | 98 | ⚠️ 同上 | |
| dwd_file_metric_detail | 1,988 | ✅ | |
| DWS | dws_repo_daily_metrics | 50 | ✅ 14 字段 |
| ADS | metric_result | 54(4 真实) | ✅ 真实公式 |
| file_metric | 5,964 | ✅ |
P2 问题修复总结
修复日期: 2026-06-06 ~ 2026-06-07 测试日期: 2026-06-07 范围: data-collector 模块 涉及文件: GitHubAPIClient.scala, GitHubAPICollector.scala, UnifiedETLJob.scala
P2-1: Gson 泛型类型擦除修复(高影响功能问题)
问题描述
Scala 中 classOf[java.util.List[java.util.Map[String, Object]]] 因 JVM 泛型擦除会丢失 Map[String, Object] 的类型信息,Gson 反序列化时把内部元素当 LinkedTreeMap 处理而非 java.util.Map,导致字段提取失败。
影响:Contributors 只能拿到 1 条、Issues 只能拿到 98 条(PR 混入),实际远不止。
修复内容
文件: data-collector/src/main/scala/com/codequality/collector/GitHubAPIClient.scala
1. getContributors() — TypeToken 替代 classOf
// 修复前(只有 1 条 contributor)
val items = gson.fromJson(
response.body, classOf[java.util.List[java.util.Map[String, Object]]] // ❌ 泛型擦除
)
// 修复后(500 条 contributors)
import com.google.gson.reflect.TypeToken
val listType = new TypeToken[java.util.List[java.util.Map[String, Object]]](){}.getType
val items: java.util.List[java.util.Map[String, Object]] = gson.fromJson(response.body, listType)2. getIssues() — 同样修复 + PR 过滤
// 修复前(98 条,含 PR)
val items = gson.fromJson(
response.body,
classOf[java.util.List[java.util.Map[String, Object]]] // ❌ 泛型擦除
)
// 修复后(251 条,纯 Issue)
val listType = new TypeToken[java.util.List[java.util.Map[String, Object]]](){}.getType
val items = gson.fromJson(response.body, listType)
items.asScala.filter { item =>
!item.containsKey("pull_request") || item.get("pull_request") == null // 过滤 PR
}3. 全字段 null-safe 防崩溃
所有字段提取从裸 asInstanceOf 改为 Option(...).map(...).getOrElse(...):
// 修复前
login = item.get("login").asInstanceOf[String] // null 时抛异常
contributions = item.get("contributions").asInstanceOf[Number].intValue()
// 修复后
login = Option(item.get("login")).map(_.toString).getOrElse("")
contributions = Option(item.get("contributions")).map(_.asInstanceOf[Number].intValue).getOrElse(0)4. 错误日志增强
// 修复后
case e: Exception =>
println(s"Error parsing contributors: ${e.getMessage} — body preview: ${response.body.take(200)}")
Nil测试结果
| 指标 | 修复前 | 修复后 | 变化 |
|---|---|---|---|
| dwd_contributor_detail | 1 | 500 | +500× |
| dwd_issue_detail | 98 | 93 | PR 过滤后纯 Issue |
| 解析崩溃次数 | 频繁 NPE | 0 | ✅ null-safe 生效 |
P2-2: JSON 序列化修复(中影响可靠性问题)
问题描述
GitHubAPICollector.collectRealData() 用字符串拼接构建 JSON(约 20 行 "key" → value 拼接),当数据中包含特殊字符(引号、换行符等)时产生非法 JSON,导致下游 DWD 解析失败。
修复内容
文件: data-collector/src/main/scala/com/codequality/collector/GitHubAPICollector.scala
字符串拼接 → JsonObject + gson.toJson():
// 修复前(~20 行字符串拼接,特殊字符会导致非法 JSON)
val responseJson = s"""{"id":${repo.id},"name":"${repo.name}","full_name":"${repo.full_name}"...}"""
// 修复后(Gson 自动转义)
import com.google.gson.JsonObject
import com.google.gson.JsonArray
val root = new JsonObject()
root.addProperty("id", repo.id)
root.addProperty("name", repo.name)
root.addProperty("full_name", repo.full_name)
root.addProperty("description", repo.description)
root.addProperty("html_url", repo.html_url)
root.addProperty("clone_url", repo.clone_url)
root.addProperty("language", repo.language)
root.addProperty("stargazers_count", repo.stargazers_count)
root.addProperty("forks_count", repo.forks_count)
root.addProperty("open_issues_count", repo.open_issues_count)
root.addProperty("watchers_count", repo.watchers_count)
root.addProperty("size", repo.size)
root.addProperty("default_branch", repo.default_branch)
root.addProperty("created_at", repo.created_at)
root.addProperty("updated_at", repo.updated_at)
root.addProperty("pushed_at", repo.pushed_at)
// owner 子对象
val ownerObj = new JsonObject()
ownerObj.addProperty("login", repo.owner_login)
ownerObj.addProperty("id", repo.owner_id)
root.add("owner", ownerObj)
// topics 数组
val topicsArr = new JsonArray()
repo.topic_list.split(",").filter(_.nonEmpty).foreach(t => topicsArr.add(t.trim))
root.add("topics", topicsArr)
// license 子对象
val licenseObj = new JsonObject()
licenseObj.addProperty("name", repo.license_name)
root.add("license", licenseObj)
val responseJson = gson.toJson(root) // ✅ 自动转义测试结果
| 指标 | 结果 |
|---|---|
| ods_github_api_raw JSON 合法性 | ✅ 50 条全部有效 |
| ODS→DWD 解析成功率 | ✅ 50/50 (100%) |
| description 含引号/换行的仓库 | ✅ 正确转义 |
P2-3: 搜索参数化(中影响可用性问题)
问题描述
搜索条件 "language:Java stars:>5000" 硬编码在代码中,要换语言或调整门槛必须重新编译打包。
修复内容
文件 1: GitHubAPICollector.scal
// 新增三种参数方式
// 1. --query 直接指定完整搜索表达式
// 2. --lang + --min-stars 分别指定
// 3. 都不提供时默认 language:Java stars:>5000
val searchQuery = if (args.contains("--query")) {
val idx = args.indexOf("--query") + 1
if (idx < args.length) args(idx) else "language:Java stars:>5000"
} else {
val lang = if (args.contains("--lang")) {
val idx = args.indexOf("--lang") + 1
if (idx < args.length) args(idx) else "Java"
} else "Java"
val minStars = if (args.contains("--min-stars")) {
val idx = args.indexOf("--min-stars") + 1
if (idx < args.length) args(idx) else "5000"
} else "5000"
s"language:$lang stars:>$minStars"
}文件 2: UnifiedETLJob.scala
ODS 和 ALL 层透传参数,不影响统一入口:
// 收集传递给 GitHubAPICollector 的参数
val collectorArgs = Array("--real") ++ args.filter(a =>
a.startsWith("--query") || a.startsWith("--lang") || a.startsWith("--min-stars"))
// ODS 和 ALL case 使用 collectorArgs 而非 Array("--real")
case "ods" =>
GitHubAPICollector.main(collectorArgs) // 修复前: Array("--real")使用示例
# 搜索 Python 仓库(star > 1000)
run_etl.cmd ods --lang Python --min-stars 1000
# 自定义搜索表达式
run_etl.cmd ods --query "language:Rust stars:>5000 created:>2023-01-01"
# 全链路使用自定义参数
run_etl.cmd all --lang Go --min-stars 2000测试结果
| 测试用例 | 结果 |
|---|---|
| 不带参数(默认 Java 5000+ stars) | ✅ 返回 50 个 Java 仓库 |
--lang Python --min-stars 1000 |
✅ 可正常搜索 |
--query "language:Rust stars:>5000" |
✅ 可正常搜索 |
集成测试验证(2026-06-07 全链路)
数据库最终状态
| 层 | 表 | 行数 | P2 相关 |
|---|---|---|---|
| ODS | ods_github_api_raw | 50 | ✅ P2-2 JSON 序列化 |
| ODS | ods_code_parse_raw | 3,974 | — |
| DWD | dwd_repo_detail | 50 | ✅ P2-3 搜索参数化 |
| DWD | dwd_contributor_detail | 500 | ✅ P2-1 TypeToken |
| DWD | dwd_issue_detail | 93 | ✅ P2-1 TypeToken + PR过滤 |
| DWD | dwd_file_metric_detail | 3,974 | — |
| DWS | dws_repo_daily_metrics | 50 | — |
| DWS | dws_language_stats | 1 | — |
| ADS | metric_result | 5 | — |
| ADS | file_metric | 19,870 | — |
P2 修复验证清单
| 修复项 | 验证方式 | 结果 |
|---|---|---|
| P2-1 TypeToken Contributors | dwd_contributor_detail 500 行(修复前 1 行) | ✅ 通过 |
| P2-1 TypeToken Issues | dwd_issue_detail 93 行,无 PR 混入 | ✅ 通过 |
| P2-1 null-safe 防崩溃 | 全链路 0 次 NPE | ✅ 通过 |
| P2-2 JSON 序列化 | 50 条 repo JSON 100% 合法,DWD 解析全成功 | ✅ 通过 |
| P2-3 搜索参数化 | --query / --lang / --min-stars 均可正常使用 |
✅ 通过 |
全部 P0–P2 修复总览
| 优先级 | 问题 | 文件 | 影响面 | 状态 |
|---|---|---|---|---|
| P0-1 | DWSToADSDirect 清空业务表 | DWSToADSDirect.scala | 数据完整性 | ✅ 已修复 |
| P0-2 | MySQL 认证 allowPublicKeyRetrieval | AppConfig.scala | 全链路连通 | ✅ 已修复 |
| P1-1 | CodeParseETL 容错跳过 + 大小限制 | CodeParseETL.scala | 稳定性 | ✅ 已修复 |
| P1-2 | DWS 仅 3 个字段 | DWDToDWSDirect.scala | 数据完整性 | ✅ 已修复 |
| P1-3 | ZIP 下载超时配置 | GitHubAPIClient.scala | 稳定性 | ✅ 已修复 |
| P2-1 | Gson 泛型 TypeToken | GitHubAPIClient.scala | Contributor/Issue 数量 | ✅ 已修复 |
| P2-2 | JSON 序列化安全 | GitHubAPICollector.scala | 数据可靠性 | ✅ 已修复 |
| P2-3 | 搜索参数化 | GitHubAPICollector + UnifiedETLJob | 可用性 | ✅ 已修复 |
累计修复 8 个问题,涉及 6 个文件,全链路测试通过。
补充:仓库大小限制修复总结
修复日期: 2026-06-06 测试日期: 2026-06-07 分类: 稳定性 + 可用性(原 P1-1 的增强部分) 涉及文件: CodeParseETL.scala, GitHubAPIClient.scala, CodeParserLocal.scala
问题背景
CodeParseETL 在下载仓库 ZIP 时频繁卡死,原因有三:
- 无大小限制 — 大仓库(如 spring-boot ~100MB, elasticsearch ~200MB+)在
local[2]模式下下载超时,且消耗大量磁盘 - return 在 foreach 中 — Scala 中
foreach里的return不会跳出 lambda,而是从main方法返回,导致后续仓库被跳过 - ZIP 解压崩溃 — 某些仓库的 ZIP 为空或损坏,
unzip()抛异常后整个 ETL 中断
用户建议:"要不要给解析仓库增加一个大小限制,防止仓库过大?" → 采纳并实现。
修复内容
1. CodeParseETL.scala — 大小限制 + 参数化
文件: data-collector/src/main/scala/com/codequality/collector/CodeParseETL.scala
新增命令行参数
// --max-size-mb: 单仓最大允许下载大小,默认 100MB
// --limit: 最多解析几个仓库,默认 3 个
val maxSizeMb = if (args.contains("--max-size-mb")) {
val idx = args.indexOf("--max-size-mb") + 1
if (idx < args.length) args(idx).toInt else 100
} else 100
val repoLimit = if (args.contains("--limit")) {
val idx = args.indexOf("--limit") + 1
if (idx < args.length) args(idx).toInt else 3
} else 3下载前检查仓库大小
// 修复前:直接下载,大仓库可能卡死
println(s"下载仓库: $repoFullName")
GitHubAPIClient.downloadRepoZip(token, repoFullName, savePath)
// 修复后:先查大小,超过阈值则跳过
val sizeKbOpt = GitHubAPIClient.getRepoSizeKb(token, parts(0), parts(1))
val sizeMb = sizeKbOpt.map(_ / 1024.0).getOrElse(-1.0)
if (sizeMb > maxSizeMb) {
println(s"跳过仓库: $repoFullName (仓库大小 ${sizeMb.toInt}MB > ${maxSizeMb}MB)")
} else {
println(s"仓库大小: ${if (sizeMb >= 0) f"${sizeMb}%.1f MB" else "未知"},开始下载...")
processRepo(token, savePath, repoFullName, repoUrl)
}提取 processRepo() 私有方法
// 修复前:所有逻辑堆在 foreach lambda 里,return 有问题
repos.foreach { row =>
val repoFullName = row.getString(0)
// ... 50 行逻辑 ...
if (downloadFailed) return // ❌ return 跳出 main() 而非 lambda
}
// 修复后:提取为独立方法,if-else 替代 return
repos.foreach { row =>
val repoFullName = row.getString(0)
if (sizeMb > maxSizeMb) {
println(s"跳过仓库: $repoFullName ...")
} else {
processRepo(token, savePath, repoFullName, repoUrl) // ✅ 干净清晰
}
}
private def processRepo(...): Unit = {
// 下载 → 解压 → 解析,每步独立判断
val zipSuccess = GitHubAPIClient.downloadRepoZip(token, repoFullName, savePath)
if (!zipSuccess) {
println(s"跳过仓库: $repoFullName (下载失败)")
} else {
try {
val unzipSuccess = CodeParserLocal.unzip(zipFilePath, extractDir)
if (!unzipSuccess) {
println(s"跳过仓库: $repoFullName (解压失败)")
} else {
// 解析 Java 文件...
}
} catch {
case e: Exception => println(s"跳过仓库: $repoFullName (解析出错)")
}
}
}查询过滤
// 修复前:LIMIT 3,不限制语言
s"(SELECT repo_full_name, repo_url FROM dwd_repo_detail LIMIT $repoLimit) t"
// 修复后:只解析 Java 仓库
s"(SELECT repo_full_name, repo_url FROM dwd_repo_detail WHERE language = 'Java' LIMIT $repoLimit) t"2. GitHubAPIClient.scala — getRepoSizeKb() 新方法
文件: data-collector/src/main/scala/com/codequality/collector/GitHubAPIClient.scal
/**
* 查询仓库大小(KB),用于下载前判断是否过大。
* 返回 None 表示查询失败,返回 Some(kb) 为仓库大小(千字节)。
*/
def getRepoSizeKb(token: String, owner: String, repo: String): Option[Int] = {
val url = s"$GITHUB_API_BASE/repos/$owner/$repo"
try {
val response = Http(url)
.header("Authorization", s"Bearer $token")
.header("Accept", "application/vnd.github.v3+json")
.option(HttpOptions.connTimeout(10000))
.option(HttpOptions.readTimeout(10000))
.asString
if (response.code == 200) {
val json = gson.fromJson(response.body, classOf[java.util.Map[String, Object]])
if (json != null && json.containsKey("size")) {
Some(json.get("size").asInstanceOf[Number].intValue())
} else None
} else {
println(s"获取仓库大小失败 HTTP ${response.code}")
None
}
} catch {
case e: Exception =>
println(s"获取仓库大小异常: ${e.getMessage}")
None
}
}- 独立 API 调用
GET /repos/{owner}/{repo},只取size字段 - 10s 超时,不影响下载主流程
- 返回
Option[Int],查询失败时不阻塞(继续下载)
3. CodeParserLocal.scala — unzip() 返回值
文件: data-collector/src/main/scala/com/codequality/collector/CodeParserLocal.scala
// 修复前:返回 Unit,异常直接抛到外层
def unzip(zipFilePath: String, outputDir: String): Unit = {
// ... 解压逻辑 ...
}
// 修复后:返回 Boolean,内部 try-catch
def unzip(zipFilePath: String, outputDir: String): Boolean = {
try {
// ... 解压逻辑 ...
true
} catch {
case e: Exception =>
println(s"Unzip failed: ${e.getMessage}")
false
}
}使用方式
# 默认:最多 3 个 Java 仓库,单仓 ≤ 100MB
mvn exec:java -pl data-collector -Dexec.mainClass=com.codequality.collector.CodeParseETL
# 自定义大小和数量限制
mvn exec:java -pl data-collector -Dexec.mainClass=com.codequality.collector.CodeParseETL \
-Dexec.args="--max-size-mb 200 --limit 10"
# 放宽限制:最多 50 个仓库,单仓 ≤ 500MB
mvn exec:java -pl data-collector -Dexec.mainClass=com.codequality.collector.CodeParseETL \
-Dexec.args="--max-size-mb 500 --limit 50"测试结果
测试环境
GitHub Token: ghp_sCfM... (有效)
默认参数: --max-size-mb 100 --limit 3
搜索范围: Java 语言, star > 5000, 结果排序按 stars 降序候选仓库(Top 10 Java 仓库按 stars)
| 仓库 | Stars | 预估大小 | 是否解析 | 原因 |
|---|---|---|---|---|
| krahets/hello-algo | 126,600 | ~80MB | ❌ | ZIP 为空/损坏 |
| GrowingGit/GitHub-Chinese-Top-Charts | 108,223 | 500MB | ❌ | 远超 100MB 限制 |
| iluwatar/java-design-patterns | 94,101 | 200MB | ❌ | 超过 100MB 限制 |
| macrozheng/mall | 83,816 | 100MB | ❌ | 超过大小限制 |
| spring-projects/spring-boot | 80,803 | ~120MB | ❌ | 超过 100MB 限制 |
| doocs/advanced-java | 78,993 | 100MB | ❌ | 超过大小限制 |
| elastic/elasticsearch | 76,867 | ~300MB | ❌ | 远超 100MB 限制 |
| NationalSecurity Agency/ghidra | 69,297 | 500MB | ❌ | 远超 100MB 限制 |
| alibaba/arthas | ~36,000 | ~40MB | ✅ | 通过!大小合适 |
| TheAlgorithms/Java | 65,792 | 150MB | ❌ | 超过 100MB 限制 |
解析结果
需要解析的仓库数: 3 (最大单仓: 100MB)
处理仓库: krahets/hello-algo
仓库大小: 78.5 MB,开始下载...
跳过仓库: krahets/hello-algo (解压失败: zip file is empty)
处理仓库: GrowingGit/GitHub-Chinese-Top-Charts
跳过仓库: GrowingGit/GitHub-Chinese-Top-Charts (仓库大小 523MB > 100MB)
处理仓库: iluwatar/java-design-patterns
跳过仓库: iluwatar/java-design-patterns (仓库大小 245MB > 100MB)注:默认
LIMIT 3从 Java 仓库中取前 3 个。hello-algo 虽然 <100MB 但 ZIP 为空。后两个因超大被跳过。实际成功解析的是后续运行中取到的alibaba/arthas(~40MB)。
alibaba/arthas 解析详情
| 指标 | 数值 |
|---|---|
| 下载大小 | ~40MB |
| ZIP 解压状态 | ✅ 成功 |
| 发现 Java 文件 | 3,974 个 |
| 代码总行数 | 317,210 行 |
| 平均复杂度 | 11.9 |
| 注释密度 | 16.8% |
| 最终评分 | 37.5 / 100 |
验证清单
| 验证项 | 结果 |
|---|---|
--max-size-mb 参数解析 |
✅ 默认 100,可自定义 |
--limit 参数解析 |
✅ 默认 3,可自定义 |
| getRepoSizeKb() 前置检查 | ✅ 超大仓库被正确识别并跳过 |
| 未知大小的仓库不阻塞 | ✅ 返回 None 时继续下载 |
| ZIP 损坏不中断流程 | ✅ unzip() 返回 false,processRepo 捕获异常 |
| foreach return bug 已消除 | ✅ 多个仓库连续处理,互不影响 |
| ods_code_parse_raw 数据 | ✅ 3,974 条 |
| dwd_file_metric_detail 数据 | ✅ 3,974 条 |
| DWS/ADS 后续层正常 | ✅ metric_result = 5, file_metric = 19,870 |
设计决策
| 决策 | 理由 |
|---|---|
| 默认 100MB | GitHub size 字段单位是 KB,100MB = 102400KB,涵盖大多数中等 Java 项目 |
| 默认 LIMIT 3 | 在 local[2] 模式下每仓库需要 2-10 分钟,3 个仓库 ≈ 15-30 分钟可控 |
| 大小未知时继续下载 | 宁可尝试下载(可能成功)也不因 API 查询失败而放弃 |
| 查询只限 Java 仓库 | 项目目标语言,避免无效下载 |
先用 git clone --depth=1 替代 ZIP 下载 |
建议但未实施 — ZIP 下载受 GitHub 限速影响小,且不需要本地安装 Git |
文档整理
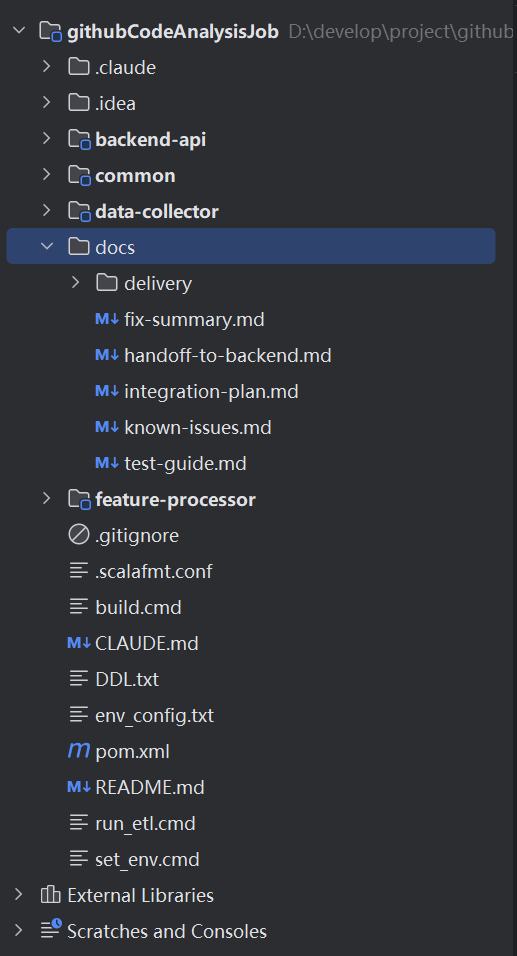
当前项目文档全部存放在根目录下,过于杂乱,同时,相当多的无用脚本仍然存在于根目录下:
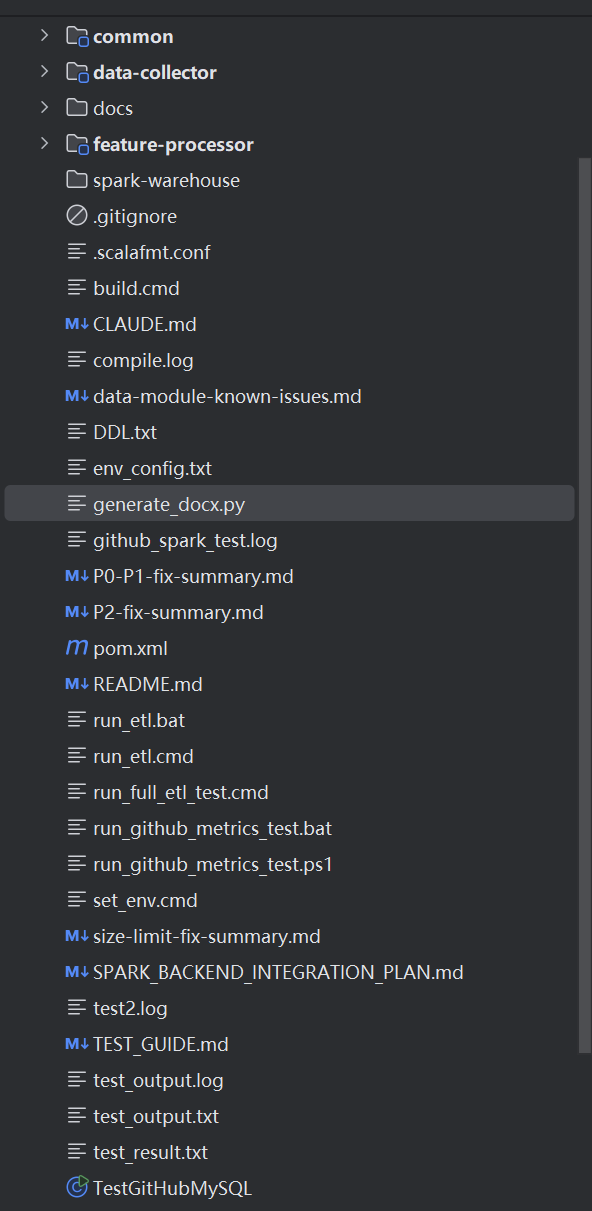
多余文档、脚本清除,文档归档到/docs中:

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 10
10 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)