NVIDIA AMPERE GA102 GPU ARCHITECTURE (2020) 学习:NVIDIA Ampere GA102 GPU 架构详解
代表显卡 RTX 3090
NVIDIA Ampere GA102 GPU 架构详解
从零理解:GA102 的六大核心特性逐一拆解
一、GA102 整体概览
GA102 是 NVIDIA Ampere 架构的旗舰消费级 GPU,也是 RTX 30 系列(如 RTX 3080、RTX 3090)的核心芯片。
1.1 基本参数
| 参数 | 数值 |
|---|---|
| 制造工艺 | 三星 8nm(NVIDIA 定制 8N 工艺) |
| 晶体管数量 | 283 亿个 |
| 芯片面积 | 628.4 mm2628.4\ \text{mm}^2628.4 mm2 |
| CUDA 核心(完整版) | 10752 个 |
| RT Core(第二代) | 84 个 |
| Tensor Core(第三代) | 336 个 |
1.2 GPU 内部的三类计算资源
GA102 和所有 GeForce RTX GPU 一样,内部有三种不同类型的计算单元,各司其职:
GA102 GPU 内部资源结构
┌───────────────────────────────────────────────┐
│ GA102 GPU │
│ │
│ ┌─────────────┐ ┌──────────┐ ┌──────────┐ │
│ │ CUDA Core │ │ RT Core │ │Tensor Core│ │
│ │(可编程着 │ │(光线追 │ │(AI 神经 │ │
│ │ 色核心) │ │ 踪加速) │ │ 网络加速)│ │
│ └─────────────┘ └──────────┘ └──────────┘ │
│ │
│ 通用图形渲染 光线求交 AI 推理 │
└───────────────────────────────────────────────┘
1.3 与上代 Turing 的性能对比
| 指标 | Turing(RTX 2080) | Ampere(RTX 3080) | 提升倍数 |
|---|---|---|---|
| 着色器 FP32 | 11 TFLOPS | 30 TFLOPS | 约 2.7x |
| RT Core 光线追踪 | 34 RT TFLOPS | 58 RT TFLOPS | 约 1.7x |
| Tensor Core(稀疏) | 89 TFLOPS(无稀疏) | 238 TFLOPS(稀疏) | 约 2.7x |
TFLOPS = Tera Floating-Point Operations Per Second,即每秒万亿次浮点运算。数字越大,计算能力越强。
二、2x FP32 处理能力
2.1 什么是 FP32?
FP32 = 32 位浮点数(单精度浮点),是图形渲染中最常见的数据类型。
每一个顶点坐标、颜色值、光照计算,几乎都是 FP32 运算。所以 FP32 吞吐量直接决定 GPU 的图形性能上限。
2.2 Turing SM 的结构(旧)
SM = Streaming Multiprocessor,流式多处理器,是 GPU 的基本计算单元,可以理解为 GPU 的"一个小 CPU 集群"。
Turing 的每个 SM 有 4 个处理块(Partition),每个处理块有两条数据通道:
Turing SM(一个处理块内部):
数据通道 A ──► FP32 运算 (可以做浮点加法/乘法)
数据通道 B ──► INT32 运算 (只能做整数运算,不能做 FP32)
问题:数据通道 B 的算力对 FP32 图形工作负载没有贡献,被浪费了
2.3 Ampere SM 的改进(新)
GA10x 让两条数据通道都支持 FP32:
Ampere SM(一个处理块内部):
数据通道 A ──► FP32 运算
数据通道 B ──► FP32 运算 (升级!现在也能做 FP32 了)
或 INT32 运算 (仍然兼容整数运算)
结果:同一个 SM,FP32 峰值吞吐量翻倍
2.4 性能数字
RTX 3090 的 FP32 峰值性能超过 35 TFLOPS35\ \text{TFLOPS}35 TFLOPS,相比 Turing 提升超过 2×2\times2×。
FP32 TFLOPS=CUDA 核心数×频率(GHz)×2\text{FP32 TFLOPS} = \text{CUDA 核心数} \times \text{频率(GHz)} \times 2FP32 TFLOPS=CUDA 核心数×频率(GHz)×2
(乘以 2 是因为每个 CUDA 核心每个时钟周期可以执行一次乘加运算,即 FMA,等效于 2 次浮点运算)
三、第二代 RT Core
3.1 RT Core 是做什么的?
光线追踪(Ray Tracing)的核心计算是:判断一条光线是否与场景中的三角形相交。
场景里可能有数百万个三角形,每帧要发射数百万条光线,暴力逐个判断完全来不及。
解决方案是 BVH(Bounding Volume Hierarchy,包围盒层次结构):
光线追踪时,先和大包围盒判断,如果不相交直接跳过整个子树,极大减少计算量。RT Core 就是专门做这个 BVH 遍历和光线/三角形求交的硬件单元。
3.2 第二代 RT Core 的改进
| 改进点 | 说明 |
|---|---|
| 吞吐量提升 | 光线/三角形求交速度是 Turing 的约 2x |
| 并发执行 | RT Core 可以和图形着色(或计算着色)同时运行 |
| 运动模糊加速 | 新增对光线追踪运动模糊的硬件支持,更快且更准确 |
并发执行是关键升级。Turing 的 RT Core 工作时,SM 上的着色器要等待;Ampere 的 RT Core 和 SM 可以同时工作,互不阻塞,流水线利用率大幅提升。
Turing(顺序执行):
时间轴:[RT Core 遍历 BVH] → [SM 着色] → [RT Core 求交] → [SM 着色] ...
(互相等待,流水线有空泡)
Ampere(并发执行):
时间轴:[RT Core 遍历 BVH]
[SM 着色 ] ← 两者同时进行,无等待
3.3 应用场景扩展
第二代 RT Core 不仅用于游戏,还覆盖:
- 电影级照片真实感渲染(物理精确的阴影/反射/折射)
- 建筑设计可视化
- 产品虚拟原型设计
- 配合 NVIDIA OptiX、Microsoft DXR、Vulkan 光线追踪 API
四、第三代 Tensor Core
4.1 Tensor Core 回顾
Tensor Core 专门做矩阵乘法,神经网络推理和训练的核心计算就是矩阵乘法:
Y=W⋅X+b\mathbf{Y} = \mathbf{W} \cdot \mathbf{X} + \mathbf{b}Y=W⋅X+b
其中 W\mathbf{W}W 是权重矩阵,X\mathbf{X}X 是输入,b\mathbf{b}b 是偏置。
4.2 两大核心新特性
4.2.1 稀疏性加速(Sparsity)
什么是稀疏神经网络?
训练好的深度神经网络权重矩阵中,很多值非常接近 0,对输出贡献极小。剪枝(Pruning)技术把这些接近 0 的权重直接置为 0,得到稀疏矩阵:
稠密权重矩阵(Turing 时代):
[ 0.3 -0.1 0.7 0.2 ]
[ 0.0 0.5 -0.3 0.0 ]
[ 0.8 0.0 0.1 -0.6 ]
稀疏权重矩阵(50% 稀疏,Ampere 支持):
[ 0.3 0.0 0.7 0.0 ] ← 只有非零元素参与计算
[ 0.0 0.5 0.0 0.0 ]
[ 0.8 0.0 0.0 -0.6 ]
GA102 的 Tensor Core 支持细粒度结构化稀疏:在 2:42:42:4 稀疏模式(每 4 个元素中有 2 个为零)下,跳过零值计算,吞吐量翻倍。
稀疏 Tensor TFLOPS=2×稠密 Tensor TFLOPS\text{稀疏 Tensor TFLOPS} = 2 \times \text{稠密 Tensor TFLOPS}稀疏 Tensor TFLOPS=2×稠密 Tensor TFLOPS
RTX 3080 稀疏 Tensor 性能:238 TFLOPS238\ \text{TFLOPS}238 TFLOPS(对比 RTX 2080 的 89 TFLOPS89\ \text{TFLOPS}89 TFLOPS,提升约 2.7×2.7\times2.7×)
4.2.2 TF32 精度(Tensor Float 32)
精度与速度的权衡:
| 数据类型 | 指数位 | 尾数位 | 精度 | 速度 |
|---|---|---|---|---|
| FP32 | 8位 | 23位 | 最高 | 最慢 |
| TF32(新增) | 8位 | 10位 | 接近 FP32 | 快 5x |
| FP16 | 5位 | 10位 | 较低 | 最快 |
TF32 保留了 FP32 的指数范围(8 位指数),但把尾数从 23 位压缩到 10 位,牺牲少量精度换取大幅提速。
对于 AI 训练来说,TF32 的精度足够,而速度是 FP32 的 5 倍。无需修改任何代码,框架自动使用 TF32。
4.3 第三代 Tensor Core 的应用
五、GDDR6X 与 GDDR6 显存
5.1 显存带宽为什么重要?
GPU 的计算单元(CUDA Core 等)速度再快,如果显存数据供不上,计算单元就会"饿着"等数据。显存带宽是数据从显存流向计算单元的"管道粗细"。
显存带宽=位宽(bit)÷8×速率(Gbps)\text{显存带宽} = \text{位宽(bit)} \div 8 \times \text{速率(Gbps)}显存带宽=位宽(bit)÷8×速率(Gbps)
5.2 GDDR6X:PAM4 调制
GDDR6X 相比 GDDR6 的核心升级:从 NRZ(Non-Return-to-Zero,每次信号只表示 0 或 1)升级为 PAM4(Pulse Amplitude Modulation 4-level,每次信号表示 4 个级别,即 2 位)。
NRZ(GDDR6):
信号电平: 高 低 高 高 低 低
表示数据: 1 0 1 1 0 0
每个时钟传输:1 bit
PAM4(GDDR6X):
信号电平: 最高 次高 次低 最低
表示数据: 11 10 01 00
每个时钟传输:2 bits (相同频率,传输量翻倍)
5.3 关键参数对比
| 显存规格 | 速率 | 位宽 | 带宽 | 使用产品 |
|---|---|---|---|---|
| GDDR6X 19 Gbps | 19 Gbps | 320-bit | ≈760 GB/s\approx 760\ \text{GB/s}≈760 GB/s | RTX 3080 |
| GDDR6X 19.5 Gbps | 19.5 Gbps | 384-bit | ≈936 GB/s\approx 936\ \text{GB/s}≈936 GB/s | RTX 3090 |
| GDDR6 | 16 Gbps | 384-bit | ≈768 GB/s\approx 768\ \text{GB/s}≈768 GB/s | RTX A6000 / A40(48 GB) |
RTX 3080 的显存带宽是 RTX 2080 Super 的 1.5×1.5\times1.5×。
5.4 专业卡的 NVLink 扩展
RTX A6000 和 A40 可以通过 NVLink 连接两块 GPU,显存从 48 GB 扩展到 96 GB,统一寻址,对大模型训练和超大场景渲染极为关键:
单卡: [A40 48GB] ──────────────────────────────
双卡: [A40 48GB] ──NVLink── [A40 48GB] = 96GB
└── 统一显存空间,程序看到一块 96GB 显存 ──┘
六、第三代 NVLink
6.1 NVLink 是什么?
NVLink 是 NVIDIA 的 GPU 间高速互联接口,相比 PCIe,带宽更高、延迟更低。
6.2 GA102 NVLink 参数
GA102 使用 4 条 x4 链路:
单向总带宽=4 条链路×14.0625 GB/s=56.25 GB/s(单向)\text{单向总带宽} = 4\ \text{条链路} \times 14.0625\ \text{GB/s} = 56.25\ \text{GB/s(单向)}单向总带宽=4 条链路×14.0625 GB/s=56.25 GB/s(单向)
双向总带宽=56.25×2=112.5 GB/s\text{双向总带宽} = 56.25 \times 2 = 112.5\ \text{GB/s}双向总带宽=56.25×2=112.5 GB/s
GPU A ←──────── 56.25 GB/s ────────► GPU B
──────── 56.25 GB/s ────────►
(4条链路,每条 14.0625 GB/s,双向合计 112.5 GB/s)
RTX 3090 也支持两卡 NVLink SLI(注意:不支持 3 路和 4 路 SLI)。
七、PCIe 4.0 接口
7.1 PCIe 的作用
PCIe(PCI Express)是 GPU 和 CPU 之间的数据通道。AI 训练需要不断从 CPU 内存把数据喂给 GPU,PCIe 带宽决定了这个"喂数据"的速度。
7.2 PCIe 3.0 vs 4.0
PCIe x16 带宽=16 条通道×单通道带宽\text{PCIe x16 带宽} = \text{16 条通道} \times \text{单通道带宽}PCIe x16 带宽=16 条通道×单通道带宽
| 版本 | 单通道速率 | x16 峰值带宽 |
|---|---|---|
| PCIe 3.0 | 8 GT/s | ≈16 GB/s\approx 16\ \text{GB/s}≈16 GB/s(单向) |
| PCIe 4.0 | 16 GT/s | ≈32 GB/s\approx 32\ \text{GB/s}≈32 GB/s(单向),64 GB/s64\ \text{GB/s}64 GB/s(双向峰值) |
GT/s = Giga-Transfers per second,即每秒十亿次数据传输。PCIe 4.0 带宽是 PCIe 3.0 的 2×2\times2×。
7.3 实际受益场景
- AI / 数据科学:大批量数据从内存搬到 GPU,PCIe 4.0 减少等待时间
- 直播广播:GPU Direct Memory Access(DMA)加速,视频数据直接从采集设备传入 GPU,减少 CPU 中转
八、GA102 全局架构总览
GA102 GPU 全局结构
┌──────────────────────────────────────────────────────────┐
│ GA102 芯片 │
│ 283 亿晶体管 | 628.4 mm² | 三星 8N 工艺 │
│ │
│ ┌────────────────────────────────────────────────────┐ │
│ │ GPU Processing Clusters (GPC) │ │
│ │ ┌──────────────────────────────────────────────┐ │ │
│ │ │ Texture Processing Clusters (TPC) │ │ │
│ │ │ ┌──────────────────────────────────────┐ │ │ │
│ │ │ │ Streaming Multiprocessor (SM) │ │ │ │
│ │ │ │ │ │ │ │
│ │ │ │ [CUDA Core x128] [RT Core x1] │ │ │ │
│ │ │ │ [Tensor Core x4] [LD/ST 单元] │ │ │ │
│ │ │ │ [L1 Cache / Shared Memory] │ │ │ │
│ │ │ └──────────────────────────────────────┘ │ │ │
│ │ └──────────────────────────────────────────────┘ │ │
│ └────────────────────────────────────────────────────┘ │
│ │
│ ┌──────────────┐ ┌──────────────┐ ┌───────────────┐ │
│ │ L2 Cache │ │ 显存控制器 │ │ NVLink 接口 │ │
│ │ (共享) │ │ 320/384-bit │ │ 4x 链路 │ │
│ └──────────────┘ └──────────────┘ └───────────────┘ │
│ │
│ ┌──────────────────────────────────────────────────┐ │
│ │ 外部接口:PCIe 4.0 x16 ── CPU/系统内存 │ │
│ └──────────────────────────────────────────────────┘ │
└──────────────────────────────────────────────────────────┘
九、六大特性综合对比
十、一句话总结各特性
| 特性 | 核心改进 | 受益最大的场景 |
|---|---|---|
| 2x FP32 | SM 双通道均支持 FP32 | 游戏渲染、3D 设计 |
| 第二代 RT Core | 并发执行 + 2x 吞吐 | 光线追踪游戏、电影渲染 |
| 第三代 Tensor Core | 稀疏加速 + TF32 精度 | AI 训练推理、DLSS 8K |
| GDDR6X | PAM4 调制 1.5x 带宽 | 高分辨率渲染、大显存场景 |
| 第三代 NVLink | 112.5 GB/s 双向带宽 | 多卡 AI 训练、超大场景 |
| PCIe 4.0 | 2x 于 PCIe 3.0 带宽 | AI 数据传输、直播采集 |
整体定位:GA102 是 NVIDIA 在游戏和专业计算两个方向上同时发力的旗舰芯片。FP32 翻倍服务游戏渲染,RT Core 提速服务实时光追,Tensor Core 加稀疏服务 AI,GDDR6X 高带宽保证数据供给,NVLink 和 PCIe 4.0 打通 GPU 间及 GPU-CPU 间的高速公路。
GA10x 第二代光线追踪引擎深度解析
从零理解:RT Core 工作原理、并发执行、运动模糊硬件加速
一、光线追踪是什么?为什么难?
1.1 从物理现实说起
现实世界中,光线从光源出发,碰到物体后:
- 反射:镜面、金属
- 折射:玻璃、水
- 漫反射:墙面、皮肤
- 被吸收:黑色物体
传统光栅化渲染(Rasterization)从物体出发投影到屏幕,不追踪光线的传播路径,所以反射、折射、软阴影这些效果要靠各种"作弊"技巧(Screen Space Reflections、Shadow Maps 等),结果不够真实。
光线追踪(Ray Tracing)从摄像机出发,向场景中投射光线,模拟光线与物体的真实交互:
屏幕上的一个像素
│
▼
向场景中射出一条"视线光线"(Primary Ray)
│
▼
光线碰到物体表面
├── 射出阴影光线(Shadow Ray)→ 检测是否在阴影中
├── 射出反射光线(Reflection Ray)→ 计算反射颜色
└── 射出折射光线(Refraction Ray)→ 计算折射颜色
│
▼
递归追踪,最终得到该像素的正确颜色
难点:场景中可能有数百万个三角形,每帧每个像素都要发射多条光线,每条光线要判断它与哪个三角形相交——暴力枚举代价不可接受。
1.2 BVH:加速求交的数据结构
BVH = Bounding Volume Hierarchy,包围盒层次结构。
把场景中的所有三角形组织成一棵树,每个节点是一个包围盒(Bounding Box,通常是轴对齐矩形体 AABB):
光线求交时,先测试大包围盒,如果光线不与它相交,整个子树跳过,大幅减少测试次数:
光线 vs 整个场景(100万三角形):
朴素枚举:100万次三角形测试
BVH 加速:约 20~30次包围盒测试 + 少数三角形精确测试
RT Core 专门负责 BVH 遍历和光线/三角形求交,把这个高频且规律的计算从 CUDA Core 上卸载。
二、第一代 vs 第二代 RT Core
2.1 两代 RT Core 功能对比
| 功能 | Turing(第一代)TU102 | Ampere(第二代)GA102 |
|---|---|---|
| 专用 RT Core 数量 | 72 个 | 84 个 |
| 光线/包围盒求交加速 | 有 | 有 |
| 光线/三角形求交加速 | 有 | 有 |
| BVH 树遍历加速 | 有 | 有 |
| Instance Transform 加速 | 有 | 有 |
| 专用 L1 接口 | 有 | 有 |
| RT 与着色同时执行 | 无 | 有 |
| 三角形位置插值单元 | 无 | 有(运动模糊专用) |
| 光线/三角形求交速率 | 1.0x(基准) | 2.0x |
| 整体 GPU 光追速度 | 1.0x | 2.0x |
2.2 RT Core 的工作流程
SM 和 RT Core 的分工:
SM(CUDA Core)的工作:
1. 生成光线(起点、方向、时间戳等参数)
2. 把光线"投递"给 RT Core
3. 等待 RT Core 返回结果
4. 根据"命中/未命中"结果执行着色计算
RT Core 的工作:
接收光线参数
│
▼
遍历 BVH 树(从根节点向下)
│
├── 光线与包围盒不相交 → 跳过整个子树
└── 光线与包围盒相交 → 继续向下
│
▼
到达叶节点:精确的光线/三角形求交测试
│
├── 未命中 → 继续遍历
└── 命中 → 记录命中信息(命中点、距离、三角形 ID)
│
▼
返回结果给 SM
关键点:RT Core 工作时,SM 上的 CUDA Core 不需要等待,可以同时处理其他工作(这是 Ampere 新增的并发能力)。
三、并发执行:Ampere 最重要的改进
3.1 Turing 的局限
Turing 的 Async Compute 支持计算和图形同时运行,但 RT Core 工作时,SM 必须等待(不能同时运行其他着色工作):
Turing 时间轴(一个 SM):
时间 ──►
[RT Core:BVH 遍历] [RT Core:三角形求交]
[SM:等待... ] [SM:等待... ] [SM:着色] ...
问题:SM 的 CUDA Core 在 RT Core 工作期间闲置
3.2 Ampere 的并发执行
GA10x 的每个 SM 可以同时运行:
- RT Core 工作 + 图形着色工作
- RT Core 工作 + 计算(Compute)工作
- 两个计算工作同时运行
Ampere 时间轴(一个 SM):
时间 ──►
[RT Core:BVH 遍历 + 三角形求交 ]
[SM CUDA Core:降噪着色 / 其他计算工作 ]
两者同时进行,互不阻塞
为什么 RT Core 密集时 SM 还有空闲?
RT Core 的工作(BVH 遍历、包围盒测试)主要消耗的是:
- 内存带宽(读取 BVH 节点数据)
- RT Core 专用电路
不需要 CUDA Core 参与。所以 SM 上的 CUDA Core 在 RT Core 工作时本来就是空闲的,Ampere 利用了这个空闲时间。
这相比没有专用 RT Core 的竞争架构有巨大优势:
没有专用 RT Core 的架构:
BVH 遍历 → 占用 CUDA Core + Texture Unit
三角形求交 → 占用 CUDA Core
着色计算 → 也需要 CUDA Core
三者争抢同一批 CUDA Core → 互相阻塞
GA10x:
BVH 遍历 → RT Core 专用电路(不占 CUDA Core)
着色计算 → CUDA Core
两者并行 → 互不干扰
3.3 实际帧时间数据(《德军总部:新血脉》)
| 渲染方式 | RTX 2080 Super(Turing) | RTX 3080(Ampere) |
|---|---|---|
| 仅 CUDA Core 着色 | 51 ms(约 20 FPS) | 更快 |
| + RT Core 加速光追 | 20 ms(50 FPS) | 更快 |
| + Tensor Core DLSS | 12 ms(约 83 FPS) | 6.7 ms(约 150 FPS) |
RTX 3080 最终帧时间仅 6.7 ms6.7\ \text{ms}6.7 ms,相比 RTX 2080 Super 的 12 ms12\ \text{ms}12 ms 提升约 1.8×1.8\times1.8×,相比纯 CUDA Core 渲染的 51 ms51\ \text{ms}51 ms 提升约 7.6×7.6\times7.6×。
四、运动模糊(Motion Blur)硬件加速
4.1 运动模糊是什么?
运动模糊是对现实相机曝光的模拟:
现实相机:
快门打开 ──────── 曝光时间 ──────── 快门关闭
光线持续照射胶片
快速移动的物体 → 在胶片上留下"轨迹" → 模糊效果
GPU 渲染(传统方法):
每帧只渲染一个时刻的快照
没有曝光时间的概念 → 运动物体看起来"瞬移" → 不真实
运动模糊在电影渲染中尤为重要:电影 24 FPS,没有运动模糊的画面会显得非常"抖动/不流畅"。
4.2 传统运动模糊的问题
传统实时运动模糊技巧(游戏中常用):
后处理运动模糊:
根据运动向量,把像素沿运动方向拉伸
问题:在反射/折射材质中缺失,边缘出现鬼影,有明显的"涂抹感"
多帧混合:
渲染多个时刻的帧然后混合
问题:计算量倍增,实时渲染难以承受
光线追踪运动模糊可以得到物理正确的结果,但挑战在于:
4.3 运动模糊的核心难题:三角形位置随时间变化
静态场景的 BVH(简单):
每个三角形有固定位置
BVH 节点包含固定的包围盒
光线测试:找到与光线相交的三角形
运动场景的 BVH(困难):
每个三角形的位置随时间变化
BVH 节点需要描述"在时间 t,这个三角形在哪里"
光线测试:每条光线有不同时间戳 t,需要求解该时刻三角形的位置,再测试相交
用公式表达:三角形顶点位置是时间的函数:
v(t)=(1−t)⋅v0+t⋅v1t∈[0,1]\mathbf{v}(t) = (1 - t) \cdot \mathbf{v}_0 + t \cdot \mathbf{v}_1 \quad t \in [0, 1]v(t)=(1−t)⋅v0+t⋅v1t∈[0,1]
其中 v0\mathbf{v}_0v0 是曝光开始时的顶点位置,v1\mathbf{v}_1v1 是曝光结束时的位置,ttt 是该光线的随机时间戳。
如果运动是曲线(如旋转的螺旋桨叶片),还需要更复杂的插值公式。
4.4 运动模糊光线追踪的算法流程
算法:随机时间戳光线采样(Stochastic Temporal Sampling)
1. 对每个像素,发射若干条光线
2. 每条光线随机分配一个时间戳 t ∈ [0, 1]
3. 光线携带时间戳进入 BVH
4. BVH 根据时间戳计算该时刻每个三角形的位置(插值)
5. 执行光线/三角形求交
6. 把不同时刻命中的结果混合 → 得到运动模糊效果
示意图(俯视):
时间 t=0.1 三角形在位置 A
时间 t=0.5 三角形在位置 B(中间)
时间 t=0.9 三角形在位置 C
光线1(t=0.1)命中 A 处三角形 → 采样点1
光线2(t=0.5)命中 B 处三角形 → 采样点2
光线3(t=0.9)命中 C 处三角形 → 采样点3
混合三个采样点 → 产生从 A 到 C 的运动模糊效果
位置 A ────────────────────► 位置 C
[命中1] [命中2] [命中3]
最终像素:A~C 路径上颜色的平均 = 模糊效果
4.5 GA10x 新增:三角形位置插值单元
Turing RT Core 没有专门的硬件来计算"时间 ttt 时刻的三角形位置",这个插值计算需要 SM(CUDA Core)来做,成为瓶颈。
GA10x RT Core 新增了 Interpolate Triangle Position 单元(三角形位置插值单元):
Turing RT Core 结构:
┌────────────────────────────────────────┐
│ BVH 遍历单元 │
│ 光线/包围盒求交单元 │
│ 光线/三角形求交单元(固定位置三角形) │
└────────────────────────────────────────┘
运动模糊的三角形位置插值 → 交给 SM 计算(慢)
GA10x RT Core 结构:
┌────────────────────────────────────────────────┐
│ BVH 遍历单元 │
│ 光线/包围盒求交单元 │
│ 光线/三角形求交单元(固定位置三角形) │
│ 【新】Interpolate Triangle Position 单元 │
│ 根据光线时间戳,硬件直接计算三角形插值位置 │
│ 再执行求交 → 全程在 RT Core 内完成 │
└────────────────────────────────────────────────┘
效果:运动模糊渲染速度最高提升 8 倍(相比 Turing)。
4.6 运动模糊实际性能数据
Blender 2.90 Cycles 渲染,4K 分辨率:
| 渲染任务 | RTX A6000(Ampere) | RTX 6000(旧 Turing) |
|---|---|---|
| 4K 无运动模糊 | 235 秒 | 291 秒 |
| 4K 有运动模糊 | 468 秒 | 841 秒 |
| 运动模糊额外耗时 | 233 秒 | 550 秒 |
| 运动模糊占总时间比 | 19% | 44% |
分析:
运动模糊性能提升=550 秒(旧)233 秒(新)≈2.4×\text{运动模糊性能提升} = \frac{550\text{ 秒(旧)}}{233\text{ 秒(新)}} \approx 2.4\times运动模糊性能提升=233 秒(新)550 秒(旧)≈2.4×
RTX 3080 vs RTX 2080 Super 在 Blender Cycles 运动模糊测试中:最高达到 5 倍加速。
旧 GPU(RTX 6000)运动模糊占用渲染时间的 44%,这意味着接近一半的时间花在运动模糊上。新 GPU(RTX A6000)将这一比例压低到 19%,说明运动模糊的硬件加速效果显著。
五、MIMD 架构:多条光线并行处理
GA10x 和 Turing 的 RT Core 都采用 MIMD 架构:
MIMD = Multiple Instruction Multiple Data(多指令多数据流)
SIMD(传统 CUDA Core 模式):
所有线程执行相同指令,处理不同数据
→ 适合规律性计算(矩阵乘法等)
MIMD(RT Core 模式):
不同光线可以处于 BVH 遍历的不同阶段
光线1:正在测试第3层包围盒
光线2:刚找到命中三角形,返回结果
光线3:正在做三角形精确求交
→ 各自独立执行,不需要同步
→ 适合光线追踪这种"每条光线路径不同"的计算
光线追踪本质上是不规律的(有的光线很快命中,有的需要穿越很多空包围盒),MIMD 正好适合这种不规则性。
六、完整光追渲染流程总览
七、关键数字汇总
| 指标 | 数值 | 说明 |
|---|---|---|
| RT Core 数量(GA102) | 84 个 | 每 SM 1 个,共 84 SM |
| 光线/三角形求交速率 | Turing 的 2.0x | 硬件电路改进 |
| 整体 GPU 光追速度 | Turing 的 2.0x | RTX 3080 vs RTX 2080 Super |
| 运动模糊加速(vs Turing) | 最高 8x | 新增插值单元 |
| Blender 运动模糊加速 | 约 5x | RTX 3080 vs RTX 2080 Super |
| 运动模糊占渲染时间(新) | 19% | RTX A6000 Blender 4K |
| 运动模糊占渲染时间(旧) | 44% | RTX 6000 Blender 4K |
八、支持的软件生态
GA10x 硬件加速运动模糊通过 NVIDIA OptiX 7.0 API 实现,已支持的软件:
Blender 2.90(Cycles 渲染器)
Chaos V-Ray 5.0
Autodesk Arnold
Redshift Renderer 3.0.x
API 支持历史:
- OptiX 5.0(2017):最早支持随机时间戳光线运动模糊
- OptiX 7.0:配合 GA10x 新硬件,开发者可指定几何体运动路径,为每条光线关联时间戳
一句话总结:GA10x 第二代 RT Core 的核心升级有两点。第一,并发执行——RT Core 工作时 SM 不再空闲,两者同时运行,消除了 Turing 时代的流水线气泡。第二,运动模糊专用硬件——新增的三角形位置插值单元把"根据时间戳计算三角形位置"这一高频且复杂的任务从 SM 卸载到 RT Core 内部,使运动模糊渲染速度最高提升 8 倍,让电影级运动模糊效果首次在实时渲染中变得可行。
GA10x 第三代 Tensor Core 与 GDDR6X 深度解析
从零理解:稀疏加速、新数据类型、DLSS 8K、PAM4 信号编码
一、Tensor Core 是什么?为什么需要它?
1.1 深度学习的核心计算
神经网络的训练和推理,本质上都是大量的矩阵乘法:
Y=W⋅X+b\mathbf{Y} = \mathbf{W} \cdot \mathbf{X} + \mathbf{b}Y=W⋅X+b
其中:
- W\mathbf{W}W 是权重矩阵(网络学到的参数)
- X\mathbf{X}X 是输入特征矩阵(一批数据)
- b\mathbf{b}b 是偏置向量
- Y\mathbf{Y}Y 是输出
推理(Inference):输入已知数据,网络给出结论(如:这张图是猫还是狗)。
训练(Training):输入大量样本,反复调整 W\mathbf{W}W 和 b\mathbf{b}b,让网络越来越准。
两者都依赖高速矩阵乘法。CUDA Core 能做矩阵乘法,但效率低。Tensor Core 是专门为矩阵乘法设计的硬件,速度快得多。
1.2 Tensor Core 的发展历史
1.3 图形领域的推理应用举例
| 推理应用 | 功能说明 |
|---|---|
| DLSS | 低分辨率输入 → AI 推理 → 高质量高分辨率输出 |
| AI 降噪 | 光线追踪噪点图 → AI 推理 → 干净图像 |
| RTX Voice | 语音信号 → AI 推理 → 去除背景噪音 |
| RTX Broadcast | 摄像头画面 → AI 推理 → 虚拟绿幕抠图 |
| AI Super Rez | 低分辨率视频 → AI 推理 → 高清视频 |
二、第三代 Tensor Core:结构改进
2.1 Turing vs GA10x Tensor Core 对比
Turing SM(TU102,RTX 2080 Super):
Tensor Core 数量:每 SM 8 个(第二代)
每个 Tensor Core:每时钟 64 次 FP16 FMA(Fused Multiply-Add)
整个 SM FP16 FMA:8 × 64 = 512 次/时钟(稠密)
GA10x SM(RTX 3080):
Tensor Core 数量:每 SM 4 个(第三代)
每个 Tensor Core:每时钟 256 次 FP16 FMA(稠密)/ 512 次(稀疏)
整个 SM FP16 FMA:4 × 256 = 1024 次/时钟(稠密)
4 × 512 = 2048 次/时钟(稀疏)
| 对比维度 | TU102 SM(Turing) | GA10x SM(Ampere) | 提升 |
|---|---|---|---|
| Tensor Core 数量 / SM | 8 个(第二代) | 4 个(第三代) | 数量减半 |
| 每 Tensor Core FP16 FMA | 64 次/时钟 | 256(稠密) / 512(稀疏) | 4~8x |
| 整 SM FP16 FMA(稠密) | 512 次/时钟 | 1024 次/时钟 | 2x |
| 整 SM FP16 FMA(稀疏) | 512 次/时钟 | 2048 次/时钟 | 4x |
数量减半,但每个功能翻倍,面积和功耗更优(Area-Optimized),来自 A100 数据中心 GPU 的精简版。
2.2 RTX 3080 整机算力
RTX 3080 共有 68 个 SM,Boost 频率 1710 MHz:
稠密 FP16 Tensor TFLOPS=68×1024×1710×106÷1012≈119 TFLOPS\text{稠密 FP16 Tensor TFLOPS} = 68 \times 1024 \times 1710 \times 10^6 \div 10^{12} \approx 119\ \text{TFLOPS}稠密 FP16 Tensor TFLOPS=68×1024×1710×106÷1012≈119 TFLOPS
稀疏 FP16 Tensor TFLOPS=68×2048×1710×106÷1012≈238 TFLOPS\text{稀疏 FP16 Tensor TFLOPS} = 68 \times 2048 \times 1710 \times 10^6 \div 10^{12} \approx 238\ \text{TFLOPS}稀疏 FP16 Tensor TFLOPS=68×2048×1710×106÷1012≈238 TFLOPS
对比 RTX 2080 Super(稠密 89 TFLOPS):稀疏模式下提升约 2.7×2.7\times2.7×。
三、支持的数据类型全解
3.1 各代 Tensor Core 支持的精度
3.2 各精度格式位结构对比
每种浮点格式由三部分组成:符号位(Sign)、指数位(Exponent)、尾数位(Mantissa)
FP32(IEEE 标准单精度):
[S:1位][指数:8位][尾数:23位] = 32位总计
精度最高,速度最慢,AI 训练传统默认格式
FP16(IEEE 半精度):
[S:1位][指数:5位][尾数:10位] = 16位总计
速度快,但指数范围小(容易数值溢出)
BF16(Brain Float 16,谷歌发明):
[S:1位][指数:8位][尾数:7位] = 16位总计
指数范围与 FP32 相同(不易溢出),精度略低于 FP16
TF32(Tensor Float 32,NVIDIA 专有):
[S:1位][指数:8位][尾数:10位] = 19位(内部格式)
指数范围与 FP32 相同,精度与 FP16 相同
读入 FP32 数据 → 内部用 TF32 计算 → 输出标准 FP32 结果
INT8:8 位整数,推理专用,精度最低但速度最快
INT4:4 位整数,更激进的量化
ASCII 对比图:
精度 ←────────────────────────────────── 高
速度 低 ────────────────────────────────► 高
FP32 ████████████████████████████████ 32位
TF32 ███████████████████ 19位(内部)
BF16 ████████████████ 16位
FP16 ████████████████ 16位
INT8 ████████ 8位
INT4 ████ 4位
3.3 TF32:AI 训练的革命性改进
旧流程(使用 FP32 训练,不用 Tensor Core):
FP32 权重 → FP32 矩阵乘法(CUDA Core 执行,慢)→ FP32 输出
开发者无需改代码,但 Tensor Core 闲置
新流程(GA10x 自动使用 TF32,无需任何代码修改):
FP32 权重(读入)
│
▼ Tensor Core 自动截断到 TF32 内部格式
TF32 矩阵乘法(Tensor Core 执行,速度是 FP32 的 2x)
│
▼
FP32 输出(标准 IEEE FP32,框架和应用看不到差异)
TF32 为什么精度够用?
指数范围(8位)与 FP32 相同 → 数值不会溢出
尾数(10位)与 FP16 相同 → 对神经网络训练的精度足够
实验验证:在视觉、目标检测、NLP 等数十种网络上,TF32 训练结果与 FP32 几乎一致。
3.4 BF16 vs FP16 的选择
| 对比 | FP16 | BF16 |
|---|---|---|
| 指数位 | 5位(范围小) | 8位(与 FP32 相同) |
| 尾数位 | 10位 | 7位 |
| 数值溢出风险 | 较高(梯度爆炸/消失) | 极低 |
| 精度 | 稍高 | 稍低 |
| 训练稳定性 | 需调超参数 | 更稳定 |
| Tensor Core 吞吐 | FP32 的 4x | FP32 的 4x |
两者都支持"混合精度训练"(Mixed Precision Training):前向传播用低精度,梯度存储用高精度,最终训练结果与纯 FP32 相当。
四、细粒度结构化稀疏(Fine-Grained Structured Sparsity)
4.1 为什么神经网络权重可以稀疏?
神经网络训练结束后,权重矩阵 W\mathbf{W}W 中很多元素的绝对值接近零,对输出的贡献极小。
直觉类比:一个班 40 个学生的成绩,对最终平均分影响最大的是少数几个极端值,大多数中间值的影响微乎其微。
剪枝(Pruning):把绝对值很小的权重直接置为 0,得到稀疏矩阵,精度几乎不损失。
4.2 2:4 结构化稀疏模式
NVIDIA 规定的稀疏格式:每连续 4 个权重中,恰好有 2 个为 0(50% 稀疏率)
稠密权重(训练完成):
[ 0.3 0.0 0.7 0.1 0.5 -0.2 0.9 0.0 ]
按 2:4 模式剪枝(每4个保留2个非零):
[ 0.3 0.0 0.7 0.0 | 0.5 0.0 0.9 0.0 ]
↑ ↑ ↑ ↑
保留 保留 保留 保留
压缩存储(只存非零值 + 索引):
数值:[ 0.3 0.7 0.5 0.9 ] (减少 50% 存储)
索引:[ 0 2 0 2 ] (记录位置)
4.3 硬件如何利用稀疏加速?
稀疏 Tensor Core 在做矩阵乘法时,自动跳过零值的乘法:
稠密计算(正常 Tensor Core):
[ a 0 b 0 ] × [ x1 ] = a*x1 + 0*x2 + b*x3 + 0*x4
[ x2 ] ^^^^ ^^^^
[ x3 ] 这两次乘法结果是 0,白做了
[ x4 ]
稀疏计算(Sparse Tensor Core):
[ a b ] × [ x1 ] = a*x1 + b*x3
[ x3 ] 只做 2 次有效乘法,跳过 2 次零乘法
(通过索引直接取 x1 和 x3,不读 x2 和 x4)
结果:同样时间内完成 2x 的有效工作量
稀疏 Tensor TFLOPS=2×稠密 Tensor TFLOPS\text{稀疏 Tensor TFLOPS} = 2 \times \text{稠密 Tensor TFLOPS}稀疏 Tensor TFLOPS=2×稠密 Tensor TFLOPS
4.4 稀疏化流程(工程实践)
关键结论:经过微调后,稀疏网络的推理精度与稠密网络几乎一致(在视觉、目标检测、分割、NLP、翻译等数十种网络上验证)。
4.5 稀疏的双重好处
存储/带宽:
权重数据量减少 50%(只存非零值)
→ 加载权重的显存带宽需求减半
→ 对显存带宽受限的推理场景收益尤其大
算力:
跳过零值乘法 → Tensor Core 吞吐 2x
五、DLSS 8K:第三代 Tensor Core 的旗舰应用
5.1 DLSS 工作原理回顾
DLSS(Deep Learning Super Sampling)= 用 AI 把低分辨率渲染结果"放大"并还原细节:
传统渲染 8K(7680×4320):
每帧着色 3318 万个像素 → 算力要求极高 → 帧率极低
DLSS 8K 模式:
以较低分辨率渲染(如 1440p)
│
▼ Tensor Core 执行 DNN 推理
AI 超分辨率:提取多帧特征 + 时序信息
│
▼
输出 8K 分辨率图像(视觉质量接近原生 8K)
5.2 9x 超分辨率缩放因子
Ampere 新支持 9x 超分辨率缩放(3×3\times3× 宽度 ×\times× 3×3\times3× 高度):
缩放比=9=3×(线性)\text{缩放比} = \sqrt{9} = 3\times \text{(线性)}缩放比=9=3×(线性)
例如:2560×14402560 \times 14402560×1440(约 368 万像素)→×9\xrightarrow{\times 9}×9 7680×43207680 \times 43207680×4320(约 3318 万像素)
以前的 DLSS 最多支持 4x 缩放(2×2\times2× 宽 ×\times× 2×2\times2× 高)。
5.3 RTX 3090 8K 60fps 实现路径
RTX 3090 渲染 8K 游戏画面(以 4K 光追 + DLSS 为例):
步骤1:以 ~1440p~2160p 分辨率渲染光线追踪场景
→ 着色像素数量:原生 8K 的 1/4 ~ 1/9
步骤2:Tensor Core 执行 DLSS 推理(约几毫秒)
→ 输出 8K 图像
步骤3:显示 8K 图像
整体帧率:在许多游戏中达到 60 FPS @ 8K
六、GDDR6X 显存:PAM4 信号技术
6.1 为什么需要更高带宽?
现代工作负载对显存带宽的需求:
高分辨率渲染:
8K 帧缓冲 ≈ 4 × 4K ≈ 每帧 ~200 MB(颜色+深度+法线等缓冲)
60 FPS → 约 12 GB/s 仅用于帧缓冲读写
光线追踪:
BVH 节点数据频繁读取 → 大量随机显存访问
AI 推理(DLSS):
DNN 权重数据、激活值 → 持续显存读写
纹理:
8K 游戏场景纹理 → 每帧大量纹理采样
以上叠加 → 显存带宽需求数百 GB/s 量级
6.2 GDDR6 的信号方式(NRZ)
GDDR6 使用 NRZ(Non-Return-to-Zero,不归零码),也称 PAM2:
NRZ 信号(每时钟传 1 bit):
电压
高 ─┐ ┌───┐ ┌─
│ │ │ │
低 └───┘ └───┘
代表:1 0 1 0
每个时钟上升沿和下降沿各传 1 bit
→ DDR(双数据率)= 每时钟周期 2 bits
6.3 GDDR6X 的 PAM4 信号方式
PAM4(Pulse Amplitude Modulation 4-level,4电平脉冲幅度调制):
PAM4 信号(每次电平跳变传 2 bits):
电压(4个等级,步进 250 mV):
最高 ─────────────
次高 ─────────────
次低 ─────────────
最低 ─────────────
每个电平代表的 2 位数据:
最高 = 11
次高 = 10
次低 = 01
最低 = 00
PAM4 信号示例:
电压 最高 次低 次高 最低
传输数据:11 01 10 00
每个时钟边沿传 2 bits(NRZ 的 2 倍)
→ 相同频率下,带宽翻倍
→ 或者相同带宽下,频率减半(信号质量更好)
形象类比:
NRZ:一条车道,只有"通行"或"停止"两种状态
PAM4:一条车道,有"快速/较快/较慢/停止"四种速度状态
→ 信息密度翻倍
6.4 PAM4 带来的挑战:SNR(信噪比)
PAM4 的代价:4 个电压等级区分更难,噪声容忍度更低。
NRZ 电压区分:
高电压(>阈值)= 1
低电压(<阈值)= 0
只需区分 2 级,噪声容忍度大
PAM4 电压区分(250 mV 步进):
00 │ 01 │ 10 │ 11
───┼────┼────┼───
每两个相邻电平之间只有 250 mV 间隔
噪声 > 125 mV 就可能误判
6.5 MTA 编码:解决 PAM4 的信噪比问题
MTA = Maximum Transition Avoidance(最大跳变规避)
问题根源:PAM4 信号从最高电平(11)直接跳到最低电平(00)时,或反向,跳变幅度最大(3×250 mV=750 mV3 \times 250\ \text{mV} = 750\ \text{mV}3×250 mV=750 mV),在高速信号线上会产生严重的电磁干扰(EMI)和信号完整性问题。
MTA 的解决方案:禁止最高电平(11)和最低电平(00)之间的直接跳变。
禁止跳变(MTA 规避):
11 → 00(禁止)
00 → 11(禁止)
允许跳变(幅度适中):
11 → 10 → 01 → 00(逐级跳变,幅度小)
以及其他非极端跳变
通过精心选择编码字(Codeword),用时间交织的方式,在不传输"禁止跳变"的前提下编码所有数据。
6.6 GDDR6X 性能数字
带宽=位宽(bit)8×数据速率(Gbps)\text{带宽} = \frac{\text{位宽(bit)}}{8} \times \text{数据速率(Gbps)}带宽=8位宽(bit)×数据速率(Gbps)
以 RTX 3090 为例(384-bit 位宽,19.5 Gbps):
带宽=3848×19.5=48×19.5=936 GB/s\text{带宽} = \frac{384}{8} \times 19.5 = 48 \times 19.5 = 936\ \text{GB/s}带宽=8384×19.5=48×19.5=936 GB/s
| 产品 | 数据速率 | 位宽 | 带宽 |
|---|---|---|---|
| RTX 2080 Ti(GDDR6) | 14 Gbps | 352-bit | 616 GB/s |
| RTX 3080(GDDR6X) | 19 Gbps | 320-bit | 760 GB/s |
| RTX 3090(GDDR6X) | 19.5 Gbps | 384-bit | 936 GB/s |
对比 RTX 2080 Ti:936/616≈1.52×936 / 616 \approx 1.52\times936/616≈1.52×,提升超过 52%。
这是10 年来显存带宽最大的一次代际飞跃(自 GeForce 200 系列以来)。
6.7 GDDR6X 对光线追踪的特殊帮助
GDDR6X 采用伪独立内存通道设计:
BVH 遍历的访存特点:
随机访问(不同光线访问 BVH 树的不同节点)
小块数据频繁读取(每个 BVH 节点几十字节)
对带宽和延迟都敏感
伪独立通道:
将 384-bit 总线拆分为多个相对独立的子通道
多条光线的 BVH 请求可以并行发往不同子通道
→ 减少访存冲突,BVH 遍历效率提升
七、全局技术协同
RTX 3080 渲染一帧 8K 光追游戏画面时,各组件协同工作:
场景数据(BVH + 几何体)──► GDDR6X(760 GB/s)
│ 高速读取
▼
┌──────────────────────────────────────────────┐
│ GA10x SM(×68 个) │
│ │
│ CUDA Core(2x FP32) │
│ 负责:主要着色计算、光线生成 │
│ │
│ RT Core(第二代) │
│ 负责:BVH 遍历 + 三角形求交 │
│ 与 CUDA Core 并发运行 │
│ │
│ Tensor Core(第三代) │
│ 负责:DLSS 推理、AI 降噪 │
│ 支持稀疏:238 TFLOPS(FP16) │
└──────────────────────────────────────────────┘
│
▼
┌───────────────────────────┐
│ DLSS 8K 输出(9x 缩放) │
│ 60 FPS @ 8K(RTX 3090) │
└───────────────────────────┘
八、关键数字速查
| 指标 | 数值 | 对比 |
|---|---|---|
| GA10x Tensor Core 稠密 FP16(per SM) | 1024 FMA/时钟 | Turing 512,2x |
| GA10x Tensor Core 稀疏 FP16(per SM) | 2048 FMA/时钟 | Turing 512,4x |
| RTX 3080 稠密 FP16 Tensor TFLOPS | 119 | RTX 2080 Super 89 |
| RTX 3080 稀疏 FP16 Tensor TFLOPS | 238 | RTX 2080 Super 89,约 2.7x |
| TF32 vs FP32 速度 | 2x | 无需改代码 |
| BF16/FP16 vs FP32 速度 | 4x | Tensor Core 执行 |
| GDDR6X 最高数据速率(RTX 3090) | 19.5 Gbps | GDDR6 通常 14~16 Gbps |
| RTX 3090 显存带宽 | 936 GB/s | RTX 2080 Ti 616 GB/s,+52% |
| DLSS 最高缩放比(Ampere) | 9x(3×33\times33×3) | 旧版最高 4x |
总结:GA10x 第三代 Tensor Core 的核心进步是"两把刀":第一把是稀疏加速,通过跳过训练后权重矩阵中 50% 的零值,吞吐量翻倍,几乎没有精度代价;第二把是新数据类型,TF32 让 AI 训练自动用上 Tensor Core 而无需改代码,BF16 提供更稳定的混合精度训练。GDDR6X 通过 PAM4 四电平信号编码,在相同频率下带宽翻倍,配合 MTA 编码解决信噪比问题,成为过去十年显存带宽最大的一次代际飞跃,为光线追踪和 8K DLSS 提供了充足的数据供给。
NVIDIA RTX IO 详细解析
一、背景:游戏存储的历史演变
1.1 游戏越来越大
现代游戏体积膨胀非常快。得益于摄影测量技术(用真实照片扫描建模),游戏里的世界越来越像真实世界。最大的游戏已经超过 200 GB,和四年前相比大了 3 倍,而且还会继续变大。
1.2 存储设备的读取速度对比
不同存储设备的读取速度差异巨大:
| 存储设备 | 读取速度 |
|---|---|
| 机械硬盘(HDD) | 50 ~ 100 MB/s |
| SATA 固态硬盘(SSD) | ~500 MB/s |
| M.2 PCIe Gen4 固态硬盘 | 高达 7 GB/s |
也就是说,最新的固态硬盘读取速度比机械硬盘快了大约 70 倍。
二、传统 I/O 的数据流程(旧方案的问题)
2.1 传统流程示意
图1(Image 1)展示了传统存储架构下的数据流动方式:
存储设备(HDD/SSD)
|
NIC
|
PCIe 总线
/ \
CPU GPU
+ 系统内存 + 显存
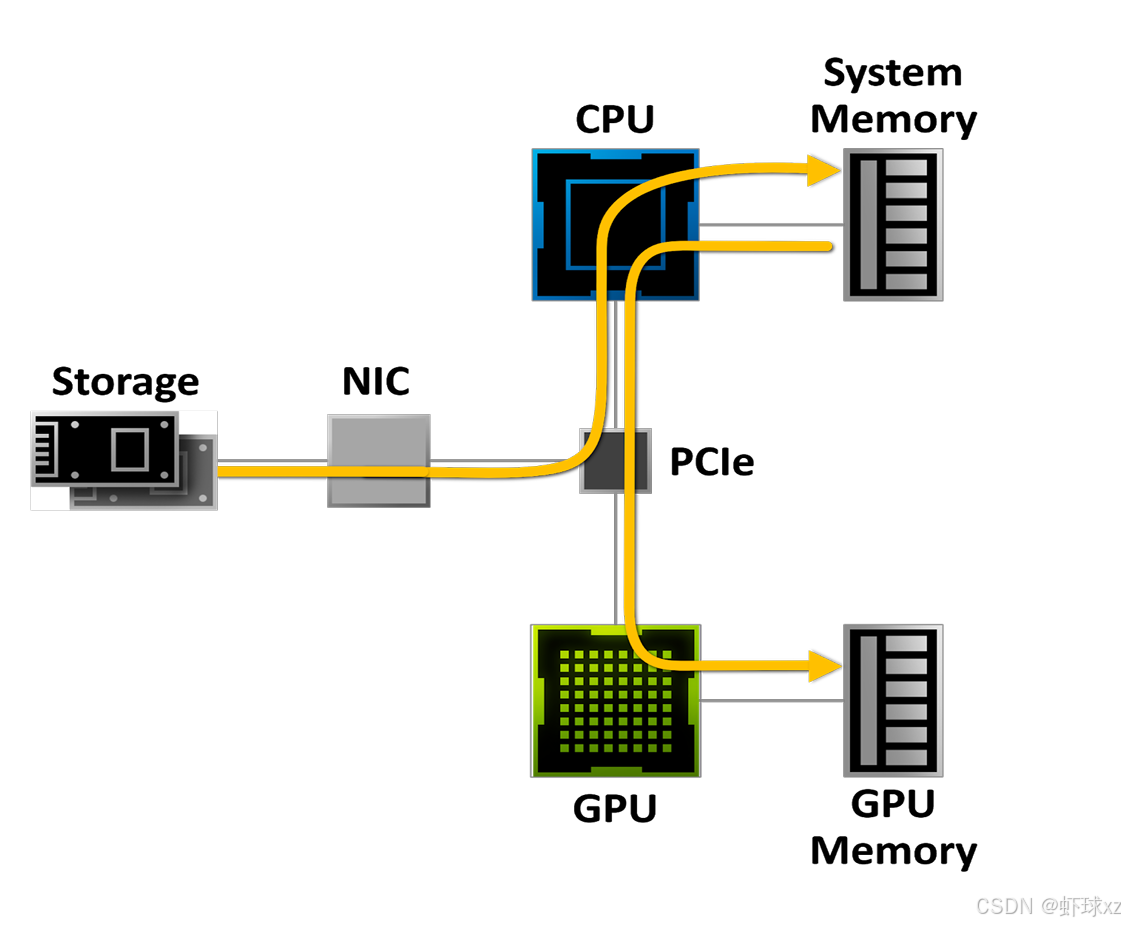
完整流程描述:
- 游戏数据从硬盘读取
- 数据经过 PCIe 总线传送给 CPU
- CPU 负责解压缩(把压缩格式还原成原始数据)
- 解压后的数据存入系统内存(RAM)
- 再从系统内存传给 GPU 显存,GPU 才能使用
2.2 问题在哪里?
关键瓶颈:CPU 解压缩跟不上快速固态硬盘的速度。
举个例子来理解:
- 从机械硬盘读数据(100 MB/s)→ 解压只需要几个 CPU 核心,完全没问题
- 从 PCIe Gen4 固态硬盘读数据(7 GB/s)→ 解压需要超过 20 个 AMD Ryzen Threadripper 3960X CPU 核心!
一台高端电脑的 CPU 总共才 24 个核心,解压就把它们全占满了,游戏主逻辑、AI、物理计算全都没资源可用了。
用一个比喻来理解:
就像水龙头(固态硬盘)的水流速度从"毛毛细流"变成了"消防水管喷射",但是你用来盛水的手(CPU)根本接不住这么多水。
三、RTX IO 是什么?它怎么解决这个问题?
3.1 核心思路
把 CPU 的解压工作,转移给 GPU 来做。
GPU 拥有数千个计算核心,非常擅长大量数据的并行处理(比如解压缩)。CPU 只有几十个核心,相比之下做解压其实是"大材小用"但又力不从心。
3.2 RTX IO 的技术定义
NVIDIA RTX IO 是一套技术方案,配合微软的 DirectStorage API,实现:
- 数据从固态硬盘读出后,保持压缩状态直接传到 GPU
- 由 GPU 负责解压缩,而不是 CPU
- CPU 释放出来,可以专注游戏逻辑
3.3 新的数据流程(RTX IO 方案)
图2(Image 2)展示了 RTX IO 的架构变化:
存储设备(NVMe SSD)
|
NIC
|
PCIe 总线
\
GPU(负责解压缩)
+ 显存
CPU ←→ 系统内存(只做轻量调度)
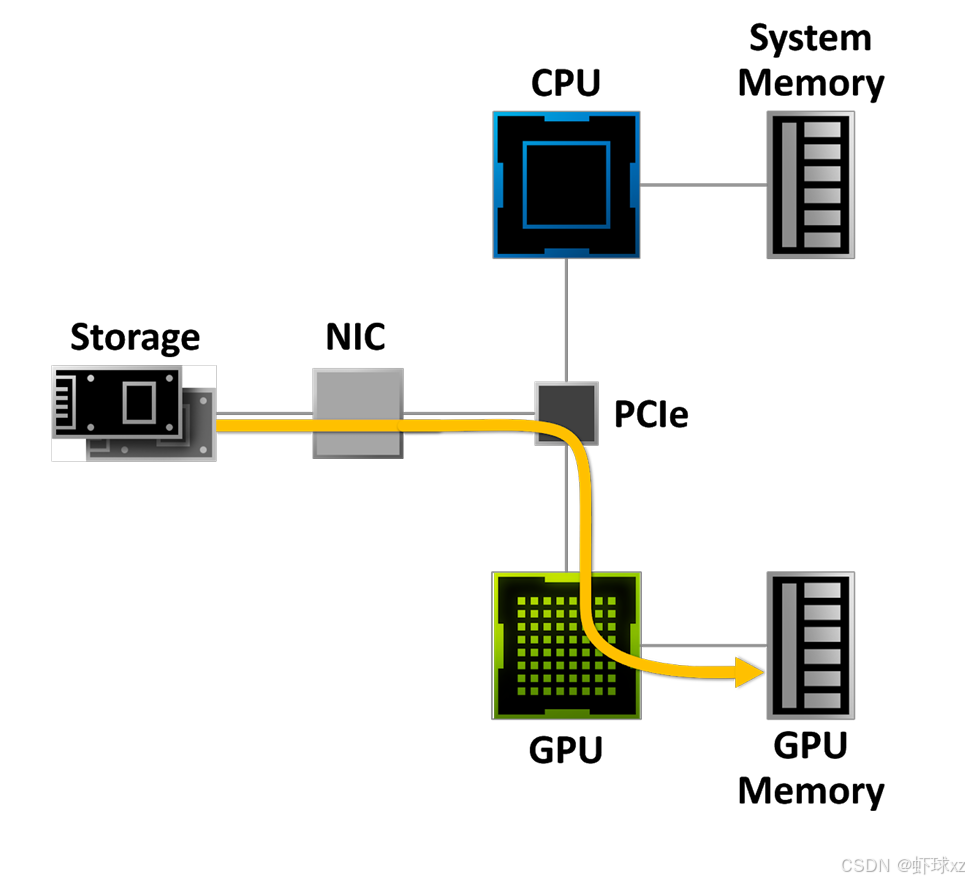
关键变化:数据绕过 CPU,直接从 SSD 经 PCIe 送到 GPU,GPU 解压后放入显存,CPU 负担大幅降低。
四、性能对比数据(图表详解)
4.1 图表说明(图3 / Image 3)
图3中有两种信息叠加在一个柱状图上:
- 灰色/绿色柱:数据传输速率(GB/s)
- 蓝黑色小方块:所需的 CPU 核心数量
| 存储方案 | 读取带宽 | 所需 CPU 核心数 |
|---|---|---|
| 机械硬盘 HDD | 0.1 GB/s | 少量(约1个) |
| SATA SSD | 0.2 GB/s | 少量(约1个) |
| Gen4 NVMe SSD | 7 GB/s | ~2个 |
| Gen4 SSD + 压缩(传统方案) | 24 GB/s(等效) | ~24个(全部!) |
| RTX IO | 24 GB/s(等效) | ~0.5个(极少!) |
4.2 性能提升总结
与机械硬盘 + 传统 API 相比,RTX IO:
- 吞吐量提升高达 100 倍(0.1 GB/s → 24 GB/s 等效)
- CPU 占用降低 20 倍(24 核心 → 约 0.5 核心)
4.3 为什么压缩后带宽更高?
这是一个重要的概念:
数据在硬盘上是压缩存储的,假设压缩比为 rrr(即原始数据大小 / 压缩后大小)。
那么从存储设备实际读取的字节数是:
实际读取量=原始数据大小r\text{实际读取量} = \frac{\text{原始数据大小}}{r}实际读取量=r原始数据大小
固态硬盘的物理带宽是固定的(设为 BBB),那么单位时间内能传入 GPU 的等效原始数据量为:
等效吞吐量=B×r\text{等效吞吐量} = B \times r等效吞吐量=B×r
例如 Gen4 SSD 物理带宽 B=7 GB/sB = 7\ \text{GB/s}B=7 GB/s,压缩比 r≈3.4r \approx 3.4r≈3.4,则等效吞吐量约为:
7 GB/s×3.4≈24 GB/s7\ \text{GB/s} \times 3.4 \approx 24\ \text{GB/s}7 GB/s×3.4≈24 GB/s
这就是图表中 “Gen4 SSD Compressed” 显示 24 GB/s 的原因——并不是硬盘真的能跑 24 GB/s,而是压缩后每读取 1 GB 的压缩数据,GPU 解压出约 3.4 GB 的原始数据。
五、RTX IO 的技术实现细节
5.1 DirectStorage API
RTX IO 需要配合微软的 DirectStorage for Windows API 才能工作。
DirectStorage 是专为 NVMe SSD 设计的新一代存储接口,主要特点:
- 减少了 I/O 调用的 CPU 开销
- 允许同时发起大量异步读取请求(并行化)
- 专门优化了游戏场景的访问模式
5.2 GPU 无损解压缩
RTX IO 实现的解压缩是无损的(lossless),也就是说:
- 解压后的数据和原始数据完全一致,没有任何质量损失
- 这对游戏纹理、模型数据非常重要(不像图片可以用有损压缩)
解压缩通过 GPU 的高性能计算内核(Compute Kernel) 实现,并且是异步调度的——GPU 可以一边渲染画面,一边在后台解压数据,两件事不互相阻塞。
5.3 依赖的 GPU 硬件特性
RTX IO 依赖 Turing(图灵)和 Ampere(安培)架构 GPU 上的以下硬件单元:
GPU 内部参与 RTX IO 的模块:
┌─────────────────────────────────────┐
│ GPU │
│ ┌─────────┐ ┌─────────────────┐ │
│ │ DMA 引擎 │ │ Copy Engine │ │
│ │(直接内存│ │ (数据复制专用) │ │
│ │ 访问) │ └─────────────────┘ │
│ └─────────┘ │
│ ┌─────────────────────────────────┐ │
│ │ SM(流式多处理器) │ │
│ │ 高级指令集 + 大量 CUDA 核心 │ │
│ │ 负责实际解压缩计算 │ │
│ └─────────────────────────────────┘ │
└─────────────────────────────────────┘
- DMA 引擎:负责在不经过 CPU 的情况下,把数据从 PCIe 总线直接搬到 GPU 显存
- Copy Engine:专用的数据复制硬件,不占用通用计算资源
- SM 的高级指令集:用于高效执行解压缩算法
5.4 两种工作场景
场景一:关卡加载(突发大量数据)
加载模式=高 GPU 计算利用率+最大 I/O 吞吐\text{加载模式} = \text{高 GPU 计算利用率} + \text{最大 I/O 吞吐}加载模式=高 GPU 计算利用率+最大 I/O 吞吐
- 此时 GPU 暂时不渲染,把全部计算资源用于解压
- 实现极快的关卡加载速度
场景二:游戏运行中的流式加载(Streaming)
流式模式=少量 I/O 带宽+GPU 异步计算(几乎不影响渲染)\text{流式模式} = \text{少量 I/O 带宽} + \text{GPU 异步计算(几乎不影响渲染)}流式模式=少量 I/O 带宽+GPU 异步计算(几乎不影响渲染) - 玩家在世界中移动时,不断有新区域的数据需要加载
- 所需带宽只是 GPU 能力的极小一部分
- GPU 的异步计算能力保证解压和渲染同时进行,互不影响
六、RTX IO 带来的游戏体验改变
6.1 对玩家的直接好处
- 近乎即时的游戏加载:从点击"开始游戏"到进入游戏世界的时间大幅缩短
- 减少"贴图突然弹出"现象(pop-in):以前高速奔跑时,远处物体的高清贴图来不及加载,只能先显示模糊版本,RTX IO 解决了这个问题
- 减少卡顿(stutter):流式加载不再占用 CPU,游戏帧率更稳定
- 安装包更小:游戏文件使用无损压缩存储,下载和安装体积减小
6.2 对开放世界游戏的意义
以前的开放世界游戏要在玩家看不到的地方偷偷"隐形加载",很多细节不得不牺牲。RTX IO 相当于给游戏引擎装上了一个超高速数据传送带,让设计师可以放心地做超大、超精细的世界。
七、RTX IO 在专业工作场景的应用
RTX IO 不仅仅对游戏有帮助,对专业创作也很有价值:
| 应用场景 | 具体收益 |
|---|---|
| 复杂 CAD 模型渲染 | 更快加载大型工程模型文件 |
| 3D 科学可视化 | 快速加载 GB 级数据集 |
| 虚拟现实(VR)协作设计 | 支持高分辨率、高帧率 VR 画面 |
| 电影/广告渲染农场 | 减少每帧渲染前的数据准备时间 |
以渲染农场为例:每个渲染任务开始前,需要把几 GB 的纹理和模型数据加载到 GPU。传统方式这个过程很慢,GPU 在等待数据时是"空转"的。RTX IO 可以按需快速加载每帧实际用到的数据,GPU 利用率大幅提升。
八、整体架构对比(Mermaid 流程图)
8.1 传统 I/O 流程
8.2 RTX IO 流程
九、关键概念速查表
| 术语 | 解释 |
|---|---|
| RTX IO | NVIDIA 的 GPU 加速 I/O 技术方案 |
| DirectStorage | 微软为 NVMe SSD 设计的新存储 API |
| 无损压缩 | 压缩和解压后数据完全一致,无质量损失 |
| DMA 引擎 | 允许外设直接访问内存,绕过 CPU |
| 异步计算 | GPU 同时做多件事,互不阻塞 |
| PCIe Gen4 | 第四代 PCIe 总线,带宽约为 Gen3 的两倍 |
| Pop-in | 游戏中贴图/物体突然"弹出"出现的现象 |
| Streaming | 游戏运行时持续动态加载所需数据 |
十、总结
RTX IO 解决的核心矛盾是:固态硬盘越来越快,但 CPU 解压缩跟不上。
解决方案非常优雅:
CPU 解压(慢、耗核心)⏟旧方案⟶GPU 解压(快、并行强)⏟RTX IO 方案\underbrace{\text{CPU 解压(慢、耗核心)}}_{\text{旧方案}} \longrightarrow \underbrace{\text{GPU 解压(快、并行强)}}_{\text{RTX IO 方案}}旧方案
CPU 解压(慢、耗核心)⟶RTX IO 方案
GPU 解压(快、并行强)
通过把解压缩任务从 CPU 转移到 GPU,RTX IO 实现了:
- 吞吐量提升 100 倍
- CPU 占用降低 20 倍
- 为下一代超大型开放世界游戏打开了大门
NVIDIA Ampere 显示与视频引擎 详细解析
一、显示输出技术概览
GPU 不只是"算画面",还要把画面传输到显示器。这需要专门的显示输出接口。本文涉及两种主流接口:DisplayPort 和 HDMI,以及让它们支持超高分辨率的关键压缩技术 DSC。
二、DisplayPort 1.4a + DSC 1.2a
2.1 什么是 DisplayPort?
DisplayPort(简称 DP)是一种视频信号传输接口,用来连接 GPU 和显示器。就像水管传水,DisplayPort 传输的是视频数据,管子越粗(带宽越大),能传的分辨率和刷新率就越高。
2.2 各版本规格对比
| 版本 | 总带宽 | 每通道带宽 | 支持的最高规格 |
|---|---|---|---|
| DisplayPort 1.2 | 21.6 Gbps | 5.4 Gbps | 4K @ 60Hz |
| DisplayPort 1.3 | 32.4 Gbps | 8.1 Gbps | 8K @ 60Hz(需 4:2:0) |
| DisplayPort 1.4a | 32.4 Gbps | 8.1 Gbps | 4K @ 120Hz / 8K @ 60Hz(需 DSC) |
注意:DP 1.3 和 1.4a 总带宽相同,但 1.4a 靠 DSC 压缩支持更高规格。
2.3 为什么带宽不够用?
来算一笔账。一帧 8K 画面(7680×4320)需要传多少数据?
每个像素用 RGB 三通道,每通道 10 bit,则单帧数据量为:
单帧大小=7680×4320×3×10 bit=995,328,000 bit≈0.93 Gbit\text{单帧大小} = 7680 \times 4320 \times 3 \times 10\ \text{bit} = 995,328,000\ \text{bit} \approx 0.93\ \text{Gbit}单帧大小=7680×4320×3×10 bit=995,328,000 bit≈0.93 Gbit
以 60Hz 刷新率计算,每秒需要传输:
所需带宽=0.93 Gbit×60=55.8 Gbps\text{所需带宽} = 0.93\ \text{Gbit} \times 60 = 55.8\ \text{Gbps}所需带宽=0.93 Gbit×60=55.8 Gbps
而 DisplayPort 1.4a 只有 32.4 Gbps,远远不够。这就是为什么需要 DSC 压缩。
2.4 DSC(Display Stream Compression)是什么?
DSC(显示流压缩)是 VESA 组织制定的一种视觉无损压缩标准。
"视觉无损"的意思是:压缩后的画面和原始画面,人眼看不出区别,但数据量大幅减小。这和照片的 JPEG 压缩类似,但专门针对实时显示优化,延迟极低。
DSC 1.2a 的典型压缩比约为 3:13:13:1,即数据量压缩到原来的 13\frac{1}{3}31。
压缩后所需带宽变为:
压缩后带宽=55.8 Gbps3≈18.6 Gbps\text{压缩后带宽} = \frac{55.8\ \text{Gbps}}{3} \approx 18.6\ \text{Gbps}压缩后带宽=355.8 Gbps≈18.6 Gbps
这就在 32.4 Gbps 的限制内了,所以 DP 1.4a + DSC 1.2a 可以支持 8K@60Hz。
2.5 Ampere GPU 的显示能力
NVIDIA Ampere 架构 GPU 可以同时驱动两块 8K@60Hz 显示器,每块显示器只需一根 DP 1.4a 线缆。
三、HDMI 2.1 + DSC 1.2a
3.1 HDMI 各版本规格对比
HDMI 是家用电视和显示器最常见的接口。Ampere GPU 是首批支持 HDMI 2.1 的独立显卡。
| 版本 | 总带宽 | 每通道带宽 | 支持的最高规格 |
|---|---|---|---|
| HDMI 1.4 | 10.2 Gbps | 3.4 Gbps | 4K @ 30Hz |
| HDMI 2.0b | 18 Gbps | 6 Gbps | 4K @ 60Hz / 8K @ 30Hz(需 4:2:0) |
| HDMI 2.1 | 48 Gbps | 12 Gbps | 4K @ 240Hz + HDR / 8K @ 60Hz + HDR(需 DSC) |
HDMI 2.1 的带宽从 18 Gbps 大幅提升到 48 Gbps,是原来的 2.67 倍,同时支持动态 HDR(高动态范围)格式。
3.2 HDCP 内容保护
Ampere GPU 还支持 HDCP 2.3 和 HDCP 1.x 两个版本的内容保护协议。
HDCP(高带宽数字内容保护)的作用是:防止通过 HDMI/DP 接口录制受版权保护的内容(如蓝光电影、流媒体)。就像给数据传输加了一把"锁",只有认证过的显示设备才能接收和显示。
四、视频解码:NVDEC(第五代)
4.1 为什么要硬件解码?
播放视频时,视频文件是压缩存储的(否则一部 4K 电影要几百 GB)。播放时需要"解压"还原成画面,这个过程叫解码。
解码有两种方式:
软件解码(Software Decode):
CPU 负责所有解码计算
优点:通用,支持所有格式
缺点:消耗大量 CPU 资源,高分辨率时 CPU 可能不够用
硬件解码(Hardware Decode,即 NVDEC):
专用解码芯片负责,CPU 几乎不参与
优点:速度快,功耗低,CPU 可以做其他事
缺点:只支持特定格式
4.2 NVDEC 支持的视频格式
GA10x GPU 的第五代 NVDEC 支持以下格式的硬件加速解码:
| 编码格式 | 说明 | 色彩模式支持 |
|---|---|---|
| MPEG-2 | 经典格式,DVD时代 | - |
| VC-1 | Windows Media Video | - |
| H.264 (AVCHD) | 最广泛使用的格式 | 4:2:0,8 bit |
| H.265 (HEVC) | H.264 的继任者,压缩率更高 | 4:2:0 / 4:4:4,8/10/12 bit |
| VP8 | Google 开发的格式 | - |
| VP9 | Google 开发,YouTube 主力格式 | 4:2:0,8/10/12 bit |
| AV1 | 最新一代开放格式(重点) | 4:2:0,8/10 bit |
4.3 色彩子采样是什么?
上表中的 4:2:0、4:4:4 等是色彩子采样(Chroma Subsampling)格式,理解它需要知道人眼的特性:
人眼对亮度(Y) 的分辨率远高于对色度(Cb/Cr) 的分辨率。因此可以把色彩信息"偷工减料"地存储。
4:4:4 —— 每个像素都有完整的亮度+色度信息(最高质量)
Y Y Y Y
C C C C
4:2:0 —— 每 2×2 个像素共享一组色度信息(最节省空间)
Y Y Y Y
C C
4:2:2 —— 每行每2个像素共享一组色度(NVDEC 不支持硬件加速)
Y Y Y Y
C C C C(横向减半)
bit 深度代表每个分量能表达多少种数值:
- 8 bit → 28=2562^8 = 25628=256 级
- 10 bit → 210=10242^{10} = 1024210=1024 级(HDR 视频常用)
- 12 bit → 212=40962^{12} = 4096212=4096 级
五、AV1 硬件解码(重点新特性)
5.1 AV1 是什么?
AV1 是由 AOM(开放媒体联盟) 开发的免版权费的视频编码格式,成员包括 Google、Netflix、Amazon、Microsoft 等大公司。
它的目标是:在同等画质下,比 H.264 节省 50~55% 的带宽。
用公式表示:
AV1 所需码率≈H.264 码率×0.45∼0.50\text{AV1 所需码率} \approx \text{H.264 码率} \times 0.45 \sim 0.50AV1 所需码率≈H.264 码率×0.45∼0.50
这对互联网视频传输意义重大——同样的网络带宽,可以传输质量更高的视频。
5.2 AV1 的问题:解码太耗性能
AV1 压缩率高的代价是:解码计算量非常大。
测试数据对比(8K 60fps HDR 视频,Intel i9-9900K CPU):
| 解码方式 | 平均帧率 | CPU 占用 |
|---|---|---|
| 软件解码(CPU) | 28 FPS(卡顿!) | >85% |
| NVDEC 硬件解码 | 流畅 8K 60fps | ~4% |
差距非常惊人:CPU 占用从 85% 降到 4%,同时帧率从卡顿的 28fps 变成流畅的 60fps。
5.3 GA10x 的 AV1 解码规格
- Profile 0:支持单色(monochrome)和 4:2:0 色彩,8/10 bit 位深
- 最高支持到 Level 6.0(不含大型分块模式)
- 分辨率范围:128×128128 \times 128128×128 到 8192×81928192 \times 81928192×8192
- 最高支持 8K @ 60Hz 硬件解码
- 支持 DX9、DX11、DX12 接口
- 支持胶片颗粒合成(Film Grain Synthesis)——某些 AV1 内容会在编码时去除胶片颗粒,然后在解码时重新合成,节省码率同时保留电影质感
六、视频编码:NVENC(第七代)
6.1 编码 vs 解码
解码(Decode):压缩视频 --> 还原成原始画面(播放视频用)
编码(Encode):原始画面 --> 压缩成视频文件(录制/直播用)
NVENC 是 GPU 上专门负责编码的硬件单元,与渲染引擎完全独立,不抢占渲染资源。
6.2 实际应用场景
以游戏直播为例,传统方案 vs NVENC 方案:
传统方案(x264 软件编码):
┌────────────┐ ┌──────────────────────────────┐
│ CPU │ → │ 既要跑游戏逻辑,又要压缩视频 │
└────────────┘ └──────────────────────────────┘
结果:游戏帧率下降,或画质很差
NVENC 方案:
┌────────────┐ ┌──────────────┐
│ GPU 渲染 │ → │ 游戏画面 │ ←── 互不干扰
└────────────┘ └──────────────┘
┌────────────┐ ┌──────────────┐
│ NVENC 单元│ → │ 直播视频流 │
└────────────┘ └──────────────┘
结果:游戏帧率不受影响,画质更好
6.3 NVENC 编码质量对比
x264 是 CPU 软件编码中最常用的方案,有不同速度档位(preset):
| 编码方案 | 质量 | CPU 占用 | 备注 |
|---|---|---|---|
| x264 Fast(快速档) | 一般 | 较低 | 单 PC 可用 |
| x264 Medium(中速档) | 较好 | 高 | 通常需要双 PC 方案 |
| GA10x NVENC | 高于 Fast,相当于 Medium | 极低 | 单 PC 即可 |
GA10x NVENC 可以在单台电脑上,以接近 x264 Medium 的质量进行直播,而 CPU 占用极低。
6.4 NVENC 支持的最高编码规格
- H.264:最高支持 4K 编码
- HEVC(H.265):最高支持 8K 编码
七、整体架构图:显示与视频引擎
八、关键概念速查表
| 术语 | 解释 |
|---|---|
| DisplayPort 1.4a | 视频输出接口,总带宽 32.4 Gbps |
| HDMI 2.1 | 家用视频接口,总带宽 48 Gbps |
| DSC 1.2a | 视觉无损显示压缩,约 3:1 压缩比 |
| 4:2:0 | 色彩子采样,减少色度数据量 |
| AV1 | 开源免版权视频格式,比 H.264 节省 ~50% 码率 |
| NVDEC | GPU 硬件视频解码单元(第五代) |
| NVENC | GPU 硬件视频编码单元(第七代) |
| HDR | 高动态范围,更宽的亮度和色彩表现 |
| HDCP 2.3 | 数字内容版权保护协议 |
| 硬件解码 | 专用芯片解码,CPU 占用极低 |
| 软件解码 | CPU 解码,高分辨率时占用率高 |
九、总结
本章涵盖了 Ampere GPU 在"画面输出"和"视频处理"两大方向的核心能力:
显示输出方面,通过 DP 1.4a + DSC 1.2a 和 HDMI 2.1 + DSC 1.2a,Ampere GPU 可以驱动 4K@120Hz 或 8K@60Hz 的超高规格显示器,物理带宽不足的问题由 DSC 视觉无损压缩来弥补:
实际所需带宽=原始带宽需求DSC 压缩比≈55.8 Gbps3≈18.6 Gbps\text{实际所需带宽} = \frac{\text{原始带宽需求}}{\text{DSC 压缩比}} \approx \frac{55.8\ \text{Gbps}}{3} \approx 18.6\ \text{Gbps}实际所需带宽=DSC 压缩比原始带宽需求≈355.8 Gbps≈18.6 Gbps
视频处理方面,NVDEC 和 NVENC 是两个独立的专用硬件单元,把 CPU 从繁重的视频解码/编码工作中解放出来。特别是 AV1 硬件解码——这是业界首次在 GPU 上实现,把 CPU 占用从 85% 降到 4%,同时实现流畅的 8K 60fps 播放。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 1
1 0
0- 0



 已为社区贡献83条内容
已为社区贡献83条内容

所有评论(0)