从支付宝60万行巨石应用,来看AI重构如何保证质量
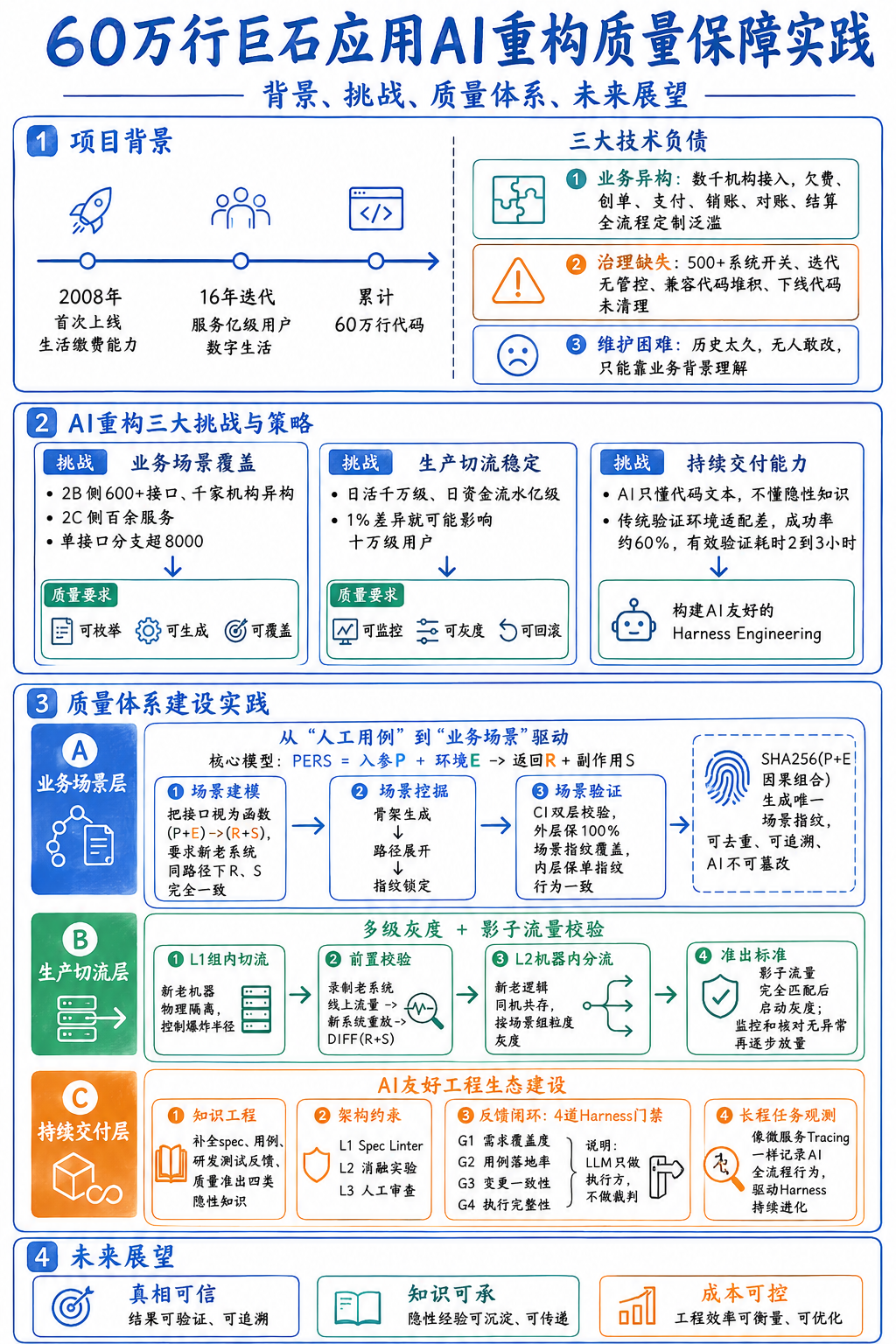
背景
| 维度 | 详情 |
| 业务历程 | 2008年上海首次上线缴电费,发展至今为亿级用户数字生活服务,系统迭代16年 |
| 技术负债 | 累计60万行代码,存在三大核心问题: 1. 业务异构:对接数千家机构,欠费/创单/支付/销账/对账/结算全流程逻辑定制泛滥 2. 治理缺失:500+系统开关、迭代无管控、历史兼容代码堆积、下线业务代码未清理 3. 维护困难:时间久远无人敢改动,仅能通过业务背景理解逻辑 |
核心挑战与整体策略
| 挑战维度 | 具体问题 | 质量要求 |
| 业务场景覆盖 | 2B侧600+技术接口、千家机构异构;2C侧百余项服务;单接口分支超8000个,多维度组合场景无法穷举 | 可枚举、可生成、可覆盖 |
| 生产切流稳定 | 日活千万级、日资金流水亿级,民生基建级应用,容错窗口极窄(1%差异影响十万级用户,单笔资损即事故) | 可监控、可灰度、可回滚 |
| 持续交付能力 | AI仅能看到代码文本,无法感知团队约定/历史故障/口头共识等隐性知识;传统验证环境AI适配性差,验证成功率仅~60%,有效验证耗时2-3小时 | 构建AI友好的工程体系(Harness Engineering) |
AI重构质量体系建设实践
业务场景层:从「人工用例」到「业务场景」驱动
核心思路:定义-挖掘-验证GoldenSet场景集,基于PERS模型(入参P+环境E→返回R+副作用S)落地
| 环节 | 方法 |
| 场景建模 | 将被测接口视为函数(P+E)→(R+S),单个测试用例对应决策路径上的一次PERS采样,要求新老系统同路径下R、S完全一致 |
| 场景挖掘 | 1.骨架生成:解析被测代码决策树,叶子节点对应独立业务场景,标注因果维度+等价类 2. 路径展开:按因果维度等价类组合筛选路径(非笛卡尔积,避免无效场景) 3. 指纹锁定:用SHA256(P+E因果组合)生成场景唯一指纹,同指纹去重、失败可追溯,指纹由骨架锁定AI不可修改 |
| 场景验证 | CI环境循环校验:外层保障100%场景指纹覆盖,内层保障单指纹下新老系统行为一致 |
生产切流层:多级灰度+影子流量校验
| 切流阶段 | 策略 |
| L1组内切流 | 新老机器物理隔离,控制爆炸半径 |
| L2机器内分流 | 新老逻辑同机共存,按场景组粒度灰度 |
| 前置校验 | 线上录制老系统流量→新系统重放→DIFF(R+S),通过后放行L2分流 |
| 准出标准 | 1. 影子流量阶段:新老DIFF完全匹配后启动L2灰度 2. 灰度阶段:新系统监控+核对无异常后逐步扩大比例 |
持续交付层:AI友好工程生态建设
(1)知识工程:补全AI隐性知识缺口
梳理全流程关键知识类型,覆盖4类核心环节:
| 环节 | 知识类型示例 |
| spec生成&审查 | 业务流程图、规则、时序图、领域模型、接口契约 |
| 用例生成&审查 | 用例schema、逻辑分支、测试数据、历史缺陷、准出标准 |
| 研发测试反馈 | 编码规范、架构约束、异常排查手册 |
| 质量准出验收 | 验证报告、发布计划、监控核对规则、应急预案 |
(2)架构约束:三层兜底保障Spec质量
| 层级 | 校验方式 | 作用 |
| L1 Spec Linter | 机器静态质检,秒级反馈 | 保障Spec规范可运行,避免矛盾/无效内容 |
| L2 消融实验 | A/B对照(有Spec vs 无Spec)验证信息量 | 避免Spec形式主义,保障内容可执行、完备 |
| L3 人工审查 | 核心场景覆盖&业务合理性校验 | 兜底业务正确性,解决AI无法判断的“应该是什么”问题 |
(3)反馈闭环:独立确定性门禁
设置4道Harness门禁,LLM不参与裁判,仅作为执行方:
| 门禁项 | 校验规则 | 级别 |
| 需求覆盖度(G1) | 场景是否覆盖全部需求点 | - |
| 用例落地率(G2) | 生成的用例是否全部可执行 | - |
| 变更一致性(G3) | 代码变更与用例是否匹配 | - |
| 执行完整性(G4) | 用例总数=0、失败数>0、报告超7天均阻断;跳过用例数>0告警 | BLOCK/WARN |
(4)长程任务观测
类比微服务Tracing,记录AI全流程行为,作为Harness自我进化的反向燃料,推动AI从“能跑”到“敢用”。
实战PERS
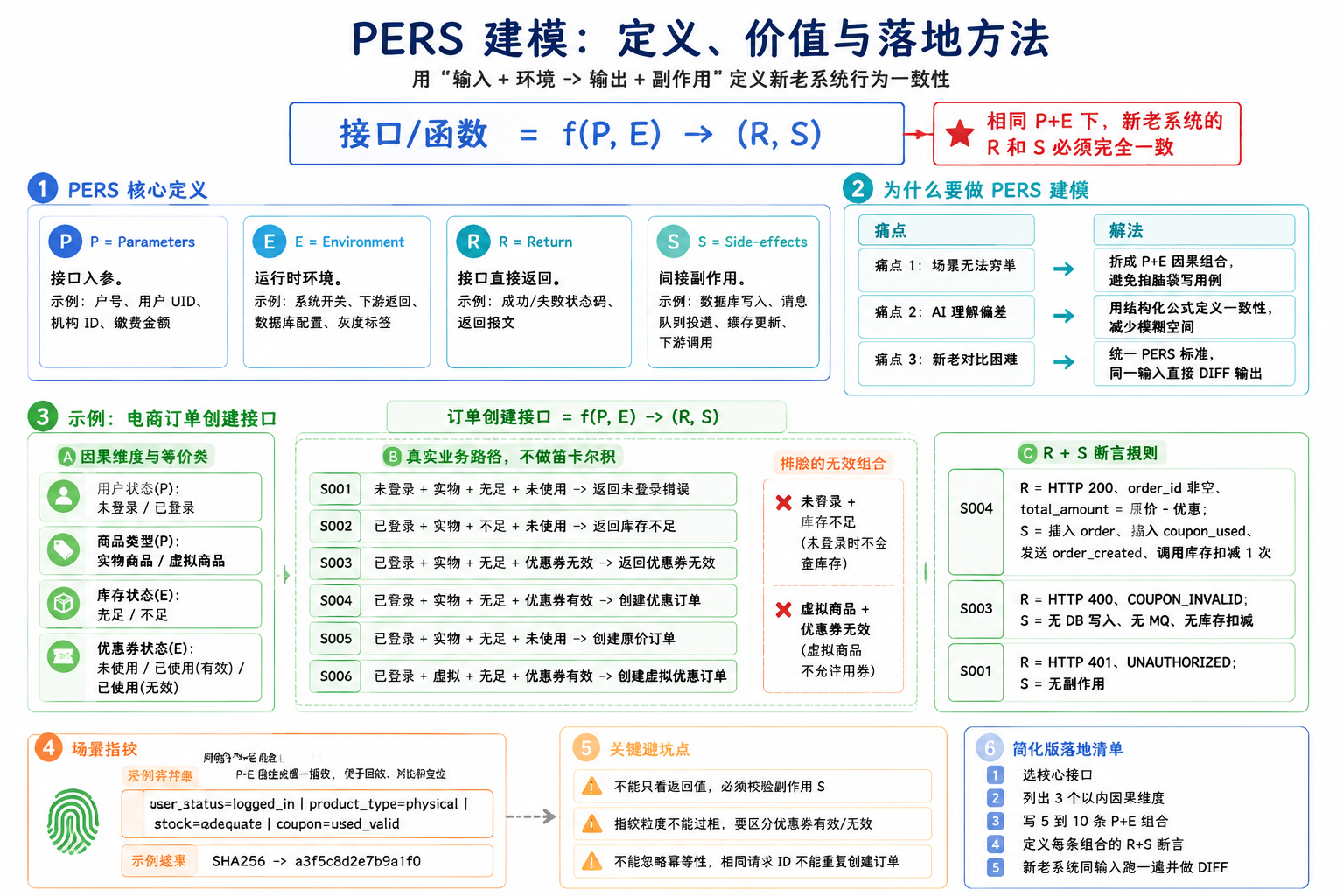
定义
PERS是把接口/函数行为标准化的建模公式,本质是用「输入+环境→输出+副作用」的因果关系,定义「新老系统行为一致」的判断标准:
| 字母 | 全称 | 含义 | 示例(生活缴费户号添加接口) |
| P | Parameters | 接口入参 | 户号、用户UID、机构ID、缴费金额 |
| E | Environment | 运行时环境 | 系统开关状态、下游依赖返回值、数据库配置、灰度标签 |
| R | Return | 接口直接返回 | 添加成功/失败状态码、返回报文 |
| S | Side-effects | 间接副作用 | 数据库写入记录、消息队列投递、缓存更新、调用下游接口 |
✅ 核心判断规则:相同P+E下,新老系统的R和S必须完全一致,否则判定为重构不一致。
为什么要做PERS建模?
针对60万行巨石应用的三大痛点:
| 痛点 | PERS的解法 |
| 场景无法穷举 | 把复杂业务拆解为「P+E因果组合」,避免拍脑袋写用例 |
| AI理解偏差 | 用结构化公式定义「什么是一致」,不给AI留模糊空间 |
| 新老对比困难 | 统一PERS标准,新老系统跑同一套输入,直接DIFF输出 |
简单实操
假设这是一个迭代了5年的老系统,正在做AI重构,我们要确保新老系统行为一致。
Step 1:抽象为 PERS 函数
订单创建接口 = f(P, E) → (R, S)
Step 2:绘制决策树骨架(简化版)
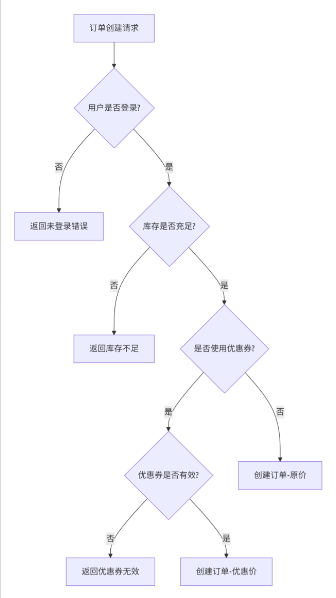
Step 3:标注因果维度 & 等价类
| 因果维度 | 等价类划分 | 说明 |
| 用户状态(P) | {未登录, 已登录} | 来自请求Header的Token |
| 库存状态(E) | {充足(>=购买数量), 不足(<购买数量)} | 来自库存服务返回值 |
| 优惠券状态(E) | {未使用, 已使用(有效), 已使用(无效)} | 来自优惠券服务返回值 |
| 商品类型(P) | {实物商品, 虚拟商品} | 影响是否需要物流 |
Step 4:路径展开生成 P+E 组合(非笛卡尔积)
我们只选真实存在的业务路径,排除无效组合:
| 场景ID | P:用户状态 | P:商品类型 | E:库存状态 | E:优惠券状态 | 预期决策路径 |
| S001 | 未登录 | 实物 | 充足 | 未使用 | 返回未登录错误 |
| S002 | 已登录 | 实物 | 不足 | 未使用 | 返回库存不足 |
| S003 | 已登录 | 实物 | 充足 | 已使用(无效) | 返回优惠券无效 |
| S004 | 已登录 | 实物 | 充足 | 已使用(有效) | 创建优惠订单 |
| S005 | 已登录 | 实物 | 充足 | 未使用 | 创建原价订单 |
| S006 | 已登录 | 虚拟 | 充足 | 已使用(有效) | 创建虚拟优惠订单 |
❌ 排除的无效组合:未登录+库存不足(未登录时不会查库存)、虚拟商品+优惠券无效(虚拟商品不允许用券)
Step 5:生成场景指纹(SHA256示例)
# P+E因果组合字符串 pe_combo = "user_status=logged_in|product_type=physical|stock=adequate|coupon=used_valid" # 生成指纹(取前16位) fingerprint = hashlib.sha256(pe_combo.encode()).hexdigest()[:16] # 结果示例: a3f5c8d2e7b9a1f0
Step 6:定义 R+S 断言规则(新老系统必须一致)
| 场景 | R(返回值)必须一致 | S(副作用)必须一致 |
| S004 | HTTP 200, order_id非空, total_amount=原价-优惠 | 1. DB插入order记录(status=待支付) 2. DB插入coupon_used记录 3. MQ发送order_created事件 4. 库存服务扣减库存接口调用1次 |
| S003 | HTTP 400, error_code=COUPON_INVALID | 无任何DB写入,无MQ发送,库存不扣减 |
| S001 | HTTP 401, error_code=UNAUTHORIZED | 无副作用 |
关键避坑点(结合订单场景)
| 坑点 | 正确做法(订单场景) |
| 忘记校验副作用S | 必须校验「优惠券是否被锁定」「库存是否预扣」,否则会出现超卖 |
| 指纹粒度太粗 | 不要把「优惠券有效/无效」合并为一个维度,否则无法区分S003/S004 |
| 忽略幂等性 | 同一个P+E组合(相同请求ID),新老系统都必须返回相同order_id,不能重复创建 |
简化版落地清单(中小团队可用)
1. 选核心接口:订单创建 2. 列3个以内因果维度:用户登录态、库存状态、优惠券状态 3. 写5-10条P+E组合(覆盖正常/异常路径) 4. 定义每条组合的R+S断言 5. 新老系统跑一遍,对比DIFF
实战影子流量
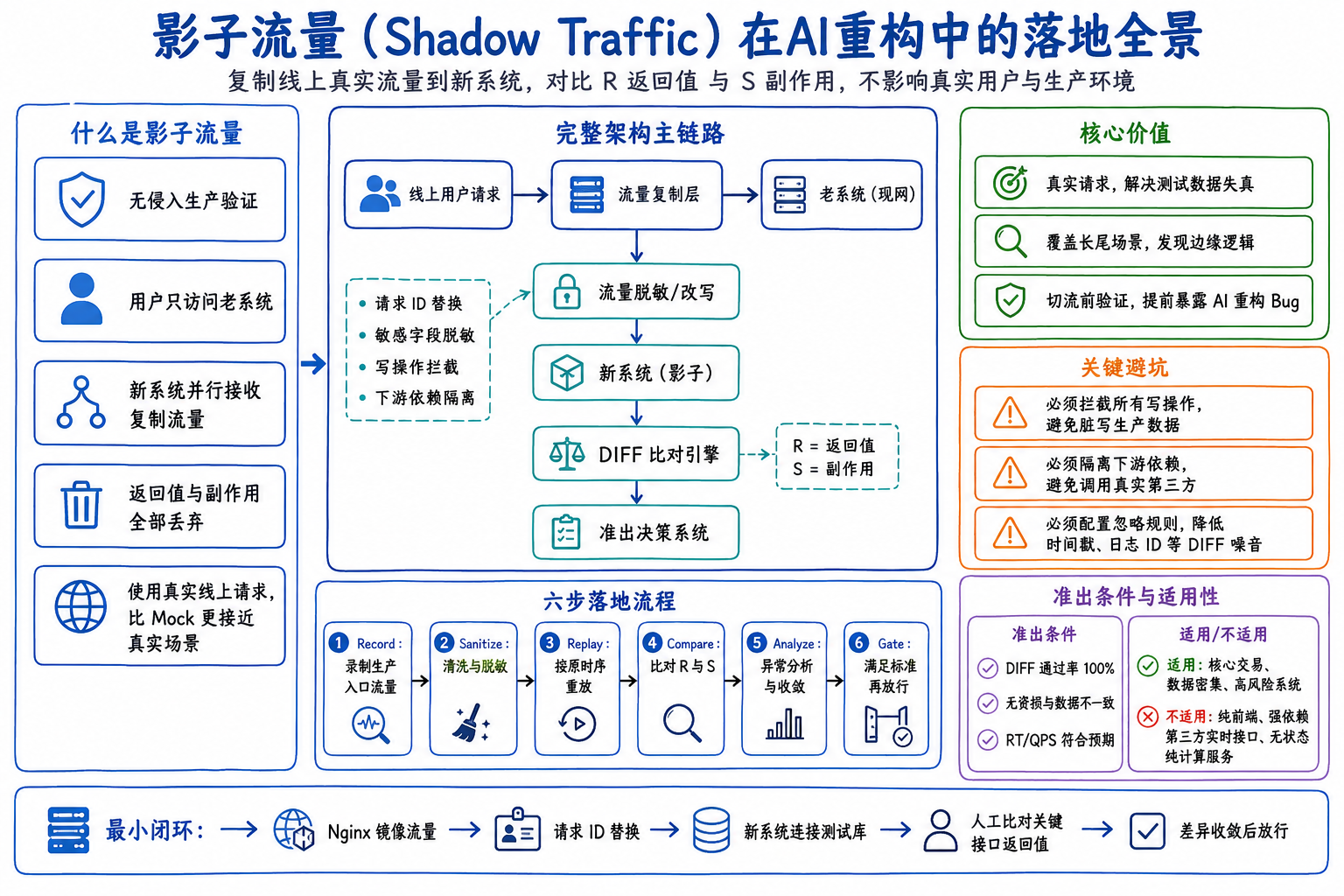
定义
影子流量(Shadow Traffic) 是一种无侵入的生产环境验证技术:将线上真实用户流量复制一份,悄悄发送给待上线的新系统,对比新老系统的处理结果(R+S),但不影响真实用户的正常请求和业务流程。
| 核心特征 | 说明 |
| 无感知 | 真实用户只和老系统交互,完全不知道新系统在并行运行 |
| 零风险 | 新系统的返回值和副作用全部丢弃,不写入生产库、不发送真实通知 |
| 真实性 | 用的是线上真实请求和数据,比Mock测试更接近真实场景 |
影子流量在AI重构中的核心价值
针对60万行巨石应用+AI重构的特殊性,解决三大痛点:
| 痛点 | 影子流量的解法 |
| 测试环境数据失真 | 直接用线上真实请求,避免测试数据覆盖不全导致的漏测 |
| 长尾场景无法枚举 | 线上流量天然包含所有边缘场景(比如某小众机构的特殊逻辑) |
| 切流前无法验证 | 重构上线前就能验证新系统处理能力,提前发现AI重构引入的bug |
┌─────────────────┐ ┌─────────────────┐ ┌─────────────────┐ │ 线上用户请求 │────▶│ 流量复制层 │────▶│ 老系统(现网) │ └─────────────────┘ └─────────────────┘ └─────────────────┘ │ ▼ ┌─────────────────┐ ┌─────────────────┐ │ 流量脱敏/改写 │────▶│ 新系统(影子) │ └─────────────────┘ └─────────────────┘ │ ▼ ┌─────────────────┐ │ DIFF比对引擎 │ └─────────────────┘ │ ▼ ┌─────────────────┐ │ 准出决策系统 │ └─────────────────┘
| 坑点 | 解法 |
| 影子流量写脏生产数据 | 必须在应用层或中间件层做写操作拦截,所有写请求路由到影子表/影子队列 |
| 新系统调用下游影响第三方 | 必须做下游依赖隔离,要么Mock下游,要么转发到影子下游环境 |
| DIFF结果噪音太大 | 配置忽略规则,排除日志ID、时间戳、非核心统计字段等无关差异 |
简单实操
步骤1:流量录制(Record)
-
录制对象:生产环境老系统的入口流量(HTTP/RPC请求)
-
录制方式:
-
方式1:负载均衡层镜像流量(推荐,无侵入)
-
方式2:应用层埋点复制请求(需要改代码)
-
-
录制范围:按场景组灰度录制,比如先录「电费缴费」场景,再扩到「水费」「燃气费」
步骤2:流量清洗与脱敏(Sanitize)
这是最关键的一步,防止影子流量污染生产环境:
| 处理项 | 操作 | 示例 |
| 请求ID替换 | 生成新的影子请求ID,避免和真实请求冲突 | 原请求ID=123 → 影子ID=shadow_123 |
| 敏感字段脱敏 | 替换手机号、身份证号等隐私数据 | 手机号=138****1234 |
| 写操作改写 | 拦截新系统的所有写操作 | SQL INSERT→INSERT INTO shadow_table |
| 下游调用隔离 | 将新系统的下游调用转发到影子环境 | 调用支付接口→调用影子支付环境 |
步骤3:流量重放(Replay)
-
将清洗后的流量发送给同机部署的新系统(文档中L2阶段策略)
-
保持请求的原始时序和并发度,模拟真实流量压力
-
新系统的返回结果全部丢弃,不返回给用户
步骤4:DIFF比对(Compare)
核心比对PERS模型中的R和S:
| 比对项 | 具体内容 | 比对规则 |
| R(返回值) | HTTP状态码、响应体JSON结构、字段值 | 完全一致,允许配置忽略字段(如timestamp) |
| S(副作用) | DB写入记录、MQ消息、Redis Key、下游调用参数 | 影子表和影子队列的数据与老系统预期一致 |
步骤5:异常分析与收敛
-
对DIFF结果进行分类:
-
预期差异:比如新系统日志格式变化、非核心字段调整
-
非预期差异:业务逻辑错误、资损风险、数据不一致
-
-
优先解决高优先级差异,直到DIFF通过率达到准出标准
步骤6:准出决策(Gate)
只有满足以下条件,才允许进入L2机器内分流阶段:
-
影子流量DIFF通过率=100%(文档要求0差异)
-
无资损类、数据不一致类异常
-
性能指标(RT/QPS)符合预期
AI工程化
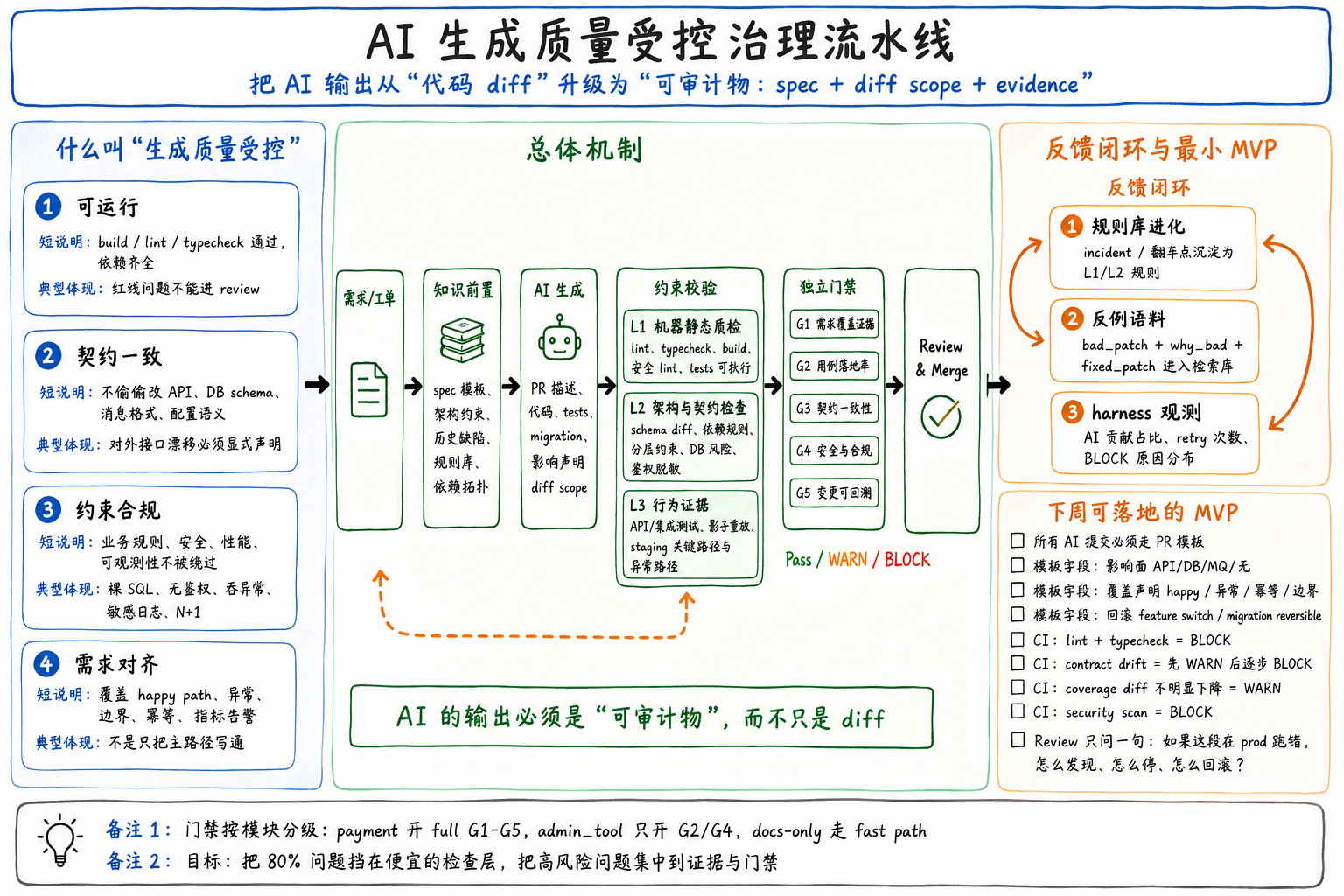
先把目标定义成可执行的:什么叫“生成质量受控”?
建议你把“质量”拆成 4 件事(这也是后面门禁的来源):
| 维度 | 说明 | 典型体现 |
| 可运行 | 编译/类型检查/静态分析通过、依赖齐全 | build/lint/typecheck 红就是红线 |
| 契约一致 | 不改不该改的接口、DB schema、消息格式、配置语义 | 对外 API / SDK / 事件 schema 被悄悄改掉 |
| 约束合规 | 业务规则/安全/性能/可观测性不被绕过 | 裸 SQL、无鉴权、吞异常、N+1、超长锁、敏感日志 |
| 需求对齐 | 真正覆盖需求点,不是只把 happy path 写出来 | 缺异常分支、缺幂等、缺边界、缺指标/告警 |
总体架构:知识前置 → 生成 → 约束校验 → 独立门禁 → 反馈闭环
用一张“流水线视角”描述(它不一定是某个平台功能,更多是你们的组织机制):
需求/工单 │ ▼ [知识前置] ← spec模板 / 架构约束 / 历史缺陷/规则库 / 依赖拓扑 │ ▼ [AI生成] PR描述 + 代码 + tests + migration + 影响声明(diff scope) │ ▼ [约束校验] L1 lint/类型/build → L2 架构&契约检查 → L3 行为证据(API/集成/影子) │ ▼ [独立门禁] Coverage/契约漂移/安全/影响面/证据齐备 → Pass / WARN / BLOCK │ ▼ Review & Merge → 观测 → 把“翻车点”回填进知识库/规则库
关键词:AI 的输出要变成“可审计物”(spec + diff scope + 证据),而不只是 diff。
知识前置:别让 AI “猜业务”,要把上下文喂成结构化材料
这一步的价值是:降低歧义 → 减少后续校验要抓的“隐形bug”数量。
至少前置 5 类“可长期维护”的知识
| 类别 | 放什么 | 怎么供给给 AI |
| 接口/数据契约 | OpenAPI/Proto/JSON Schema、消息 event schema、DB 公共表字段注释 | 作为 pinned context / 检索语料;强制生成物引用 schema |
| 架构约束(Do/Don’t) | 分层规则、依赖方向、哪些包不能直连 DB、必须用 DAO/Repository、事务边界在哪里 | 规则文件 .archguard/, ARCH.md,并在 review prompt 里显式引用 |
| 业务规则片段 | 状态机(订单/审核/退款等)、枚举合法值、幂等与重试语义、结算口径 | 用 DSL/表格/状态图而不是长段散文;最好绑定到 module |
| 安全&合规基线 | 敏感字段清单、日志脱敏规则、鉴权切面、SQL 注入/SSRF 禁止模式 | 作为 lint/正则规则 + 例子;AI 看到“会被扫描”就会收敛 |
| 历史事故/反例库 | 过去踩过的坑:某接口不能加字段、某表不能随便建索引、某种写法会引发慢查询 | 用“反例 + 修正写法”喂给 AI,生成时直接压住高频复发 bug |
实践中最有效的不是“一股脑塞 system prompt”,而是:
把知识绑到路径/模块:
module/orders/**自动带订单状态机;/pay/自带资金安全规则。
约束校验:三层(L1/L2/L3)把 80% 问题挡在 cheap 的地方
这套分层本质上和前面说的“Spec三层兜底”一脉相承,只是对象从“重构规格”变成了“PR/MR”。
L1:机器静态质检(秒级,必须过)
目的只有一个:不让“低级错误”进人工眼裡。
-
编译 / typecheck / 格式化
-
语言 lint + 安全 lint(secrets、硬编码 token、危险 eval/exec)
-
测试是否可执行:
tests 不为空且至少一个 assert且没只 print 不 assert -
生成物必须附带:受影响的对外契约清单(哪怕只写“无”)
原则:L1 失败 = 直接 BLOCK,不等 review。 AI 可以自动 retry fix(见闭环),但不能 bypass。
L2:架构 & 契约漂移检查(便宜但很关键)
这一层防的是 AI 最容易犯的“偷偷改边界”:
-
契约漂移检测:API response schema 新增/删除/改类型;消息字段语义变化;错误码新增未登记
-
分层/依赖违规:service 直接 import dao 包、跨域 import、domain 依赖 infra 细节
-
数据库变更风险:migration 是否 drop column、是否加锁表、是否有 missing index 风险(可用规则库近似判)
-
横切合规:新增接口是否有鉴权注解/切面;敏感字段是否走脱敏;是否出现裸 SQL 在不该出现的地方
落地方式通常是:
-
ArchUnit / custom rules / 依赖图 diff / schema diff 工具
-
输出一份 Impact Statement(影响声明):这次改动可能影响哪些接口、哪些 topic、哪些表
L2 的核心不是“全自动化证明正确”,而是把可疑的结构性变化标红让人/二次校验聚焦。
L3:行为证据(更贵,但对关键路径值得做)
对资金/订单/支付这类“错一点就资损”的路径,最好再要一层:
-
单测/集成测试必须 cover 的关键路径(见后面门禁 G1/G2)
-
影子重放/对比(如果你有流量):老逻辑结果 vs 新逻辑结果,diff 规则可配置
-
或者至少在 staging 跑一遍:端到端 happy path + 关键异常 path(幂等重复、并发、超时)
注意:L3 不是要求“全系统走影子”。而是 “标红模块(支付/结算/履约)→ 必须出示行为证据”。
独立门禁:让 LLM 不当裁判,做成硬指标
把质量准出写成 不依赖 AI 主观打分 的规则,CI 可算、可阻断。
推荐的 5 个门禁(可按模块分级)
| 门禁 | 算什么 | 动作 |
| G1 需求覆盖证据 | PR 描述/checklist 里是否声明覆盖了哪些 case(happy/异常/边界/幂等) | 缺声明 → WARN;关键模块缺 → BLOCK |
| G2 用例落地率 | tests 存在、可执行、不是假通过;coverage diff 不下降太多(例如 -2% 阈值) | 用例为空 / 明显假绿 → BLOCK |
| G3 契约一致性 | 对外 API/消息 schema 是否漂移;是否有“未审批的新错误码/新字段” | 漂移且无注解 → BLOCK |
| G4 安全&合规 | secret、脱敏、鉴权、SQL injection pattern、权限切面 | 命中规则 → BLOCK |
| G5 变更可回溯 | 每个非 trivial PR 必须带:影响面声明 + 回滚方案/开关策略(哪怕一句) | 关键模块缺 → WARN/BLOCK |
关键点:门禁是分级的。
module=payment开 full(G1–G5)
module=admin_tool只开 G2/G4
docs-only走 fast path
反馈闭环:让“生成→校验→翻车→改进”可积累
否则你会永远停留在“AI 写得快,人修得更累”。要把三样东西持续回流:
-
规则库进化:每次 production incident / PR 翻车 → 提炼成一条 L1/L2 规则或 lint 或 prompt 约束
-
反例语料:
(bad_patch, why_bad, fixed_patch)进检索库,让后续生成更少复发
例如:“上次在 orders 里直接改 status 没走状态机,导致补偿重复发货 → 加规则:status 变更必须走 state machine”
-
生成 harness 自身观测:记录每个 PR 的 AI 贡献占比、retry 次数、BLOCK 原因分布,用它决定哪里该强化知识前置、哪里该放宽噪音规则
一个最小闭环 MVP(你下周就能试的那种)
如果你想先“低成本验证这套思路行不行”,别上来搞平台,先做这条线:
-
约定:所有 AI 辅助提交必须走 PR 模板
## 影响面:API / DB / MQ / 无## 覆盖声明:happy / 异常(哪类) / 幂等 / 边界## 回滚:feature switch / migration reversible?
-
CI 里加:
-
lint + typecheck(BLOCK)
-
契约 drift diff(WARN 先,逐步 BLOCK)
-
覆盖率 diff 不掉太多(WARN)
-
G4 security-scan(BLOCK)
-
-
Review 时只问一个问题:“如果这段在 prod 跑错,你怎么知道、怎么停、怎么回滚?”(这句话能把 90% 危险 PR 逼出真信息)

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 11
11 0
0- 0



 已为社区贡献75条内容
已为社区贡献75条内容

所有评论(0)