ASIO异步通信——多线程模型
为了提升网络io并发处理的效率,设计多线程模式下asio的使用方式。总体来说asio有两个多线程模型,第一个是启动多个线程,每个线程管理一个iocontext。第二种是只启动一个iocontext,被多个线程共享。
┌── AsioIOServicePool(多 io_context 模式)──┐
│ │
│ io_0.run() io_1.run() io_2.run() │
│ ▲ ▲ ▲ │
│ │ │ │ │
│ [线程0] [线程1] [线程2] │
│ ▲ ▲ ▲ │
│ │ round-robin 外部轮询 │ │
│ └──────────┬──┴──────────────┘ │
│ GetIOService() │
└─────────────────────────────────────────────┘
┌── AsioThreadPool(单 io_context 模式)──────┐
│ │
│ _service.run() │
│ ▲ │
│ ┌────────┼────────┬────────┐ │
│ │ │ │ │ │
│ [线程0] [线程1] [线程2] [线程3] │
│ ▲ ▲ ▲ ▲ │
│ └────────┴────────┴────────┘ │
│ 内部互斥锁竞争取任务 │
│ │
│ GetIOService() → 永远返回同一个 │
└─────────────────────────────────────────────┘
IOServicePool
一个IOServicePool开启n个线程和n个iocontext,每个线程内独立运行iocontext, 各个iocontext监听各自绑定的socket是否就绪,如果就绪就在各自线程里触发回调函数。为避免线程安全问题,我们将网络数据封装为逻辑包投递给逻辑系统,逻辑系统有一个单独线程处理,这样将网络IO和逻辑处理解耦合,极大的提高了服务器IO层面的吞吐率。
单线程和多线程对比
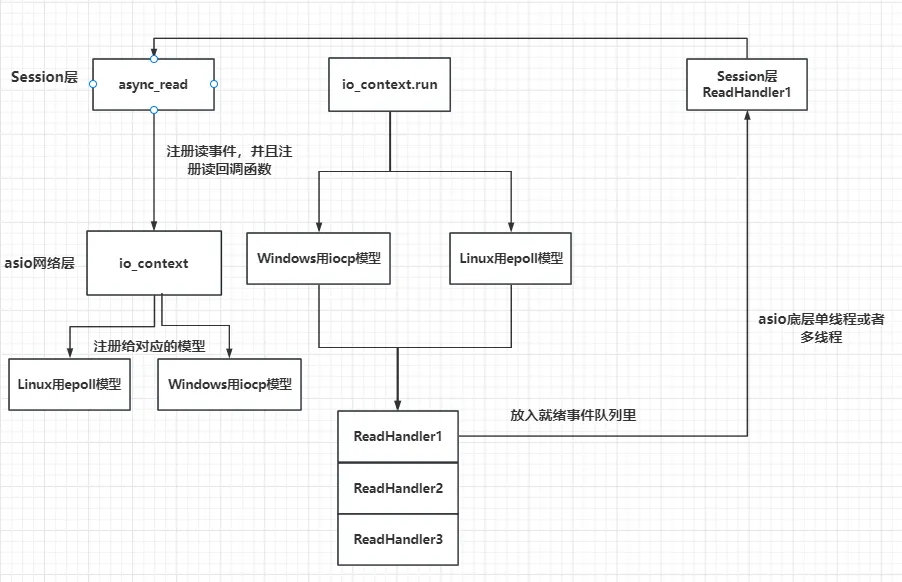
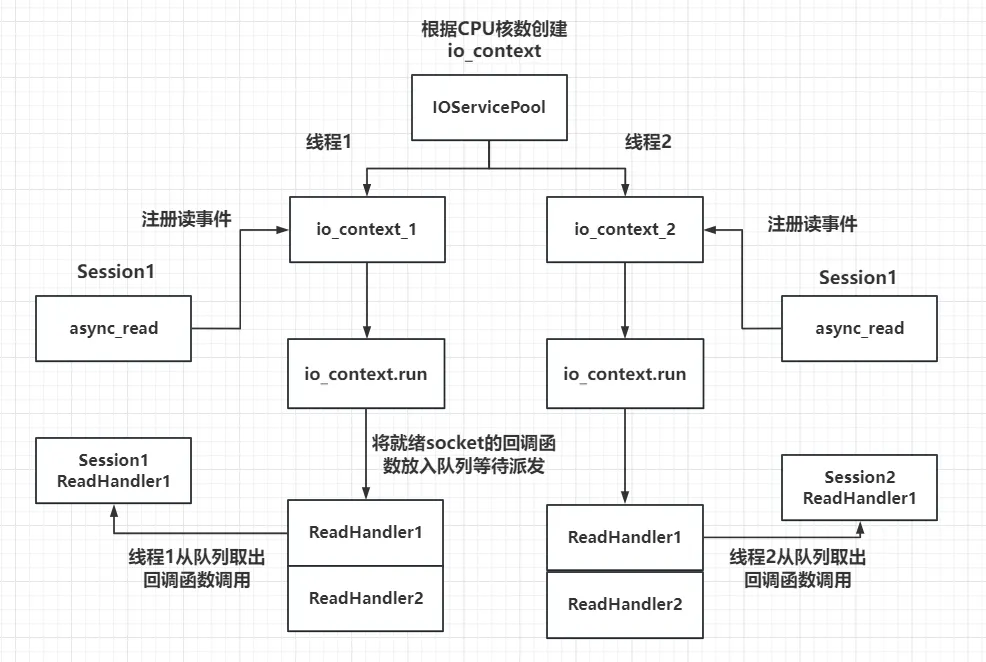
- 每一个io_context跑在不同的线程里,所以同一个socket会被注册在同一个io_context里,它的回调函数也会被单独的一个线程回调,那么对于同一个socket,他的回调函数每次触发都是在同一个线程里,就不会有线程安全问题,网络io层面上的并发是线程安全的。
- 但是对于不同的socket,回调函数的触发可能是同一个线程(两个socket被分配到同一个io_context),也可能不是同一个线程(两个socket被分配到不同的io_context里)。所以如果两个socket对应的上层逻辑处理,如果有交互或者访问共享区,会存在线程安全问题。
-
- 比如socket1代表玩家1,socket2代表玩家2,玩家1和玩家2在逻辑层存在交互,比如两个玩家都在做工会任务,他们属于同一个工会,工会积分的增加就是共享区的数据,需要保证线程安全。可以通过加锁或者逻辑队列的方式解决安全问题,我们目前采取了后者。
- 多线程相比单线程,极大的提高了并发能力。
-
- 单线程仅有一个io_context服务用来监听读写事件,就绪后回调函数在一个线程里串行调用, 如果一个回调函数的调用时间较长肯定会影响后续的函数调用,毕竟是串行调用。
- 采用多线程方式,可以在一定程度上减少前一个逻辑调用影响下一个调用的情况,比如两个socket被部署到不同的iocontext上,但是当两个socket部署到同一个iocontext上时仍然存在调用时间影响的问题。不过我们已经通过逻辑队列的方式将网络线程和逻辑线程解耦合了,不会出现前一个调用时间影响下一个回调触发的问题。
IOServicePool实现
IOServicePool本质上是一个线程池,基本功能就是根据构造函数传入的数量创建n个线程和iocontext,然后每个线程跑一个iocontext,这样就可以并发处理不同iocontext读写事件了。
/**
* @class AsioIOServicePool
* @brief Boost.Asio IO 服务线程池,继承自单例模板
*
* 该类负责管理一组 boost::asio::io_context 对象及其对应的工作线程。
* 每个 io_context 都绑定了一个 work 对象,防止在没有任务时 io_context 退出。
* 通过 round-robin(轮询)策略对外分配 io_context,实现负载均衡。
*
* 使用方式:
* auto& pool = AsioIOServicePool::GetInstance();
* auto& ios = pool.GetIOService(); // 获取一个可用的 io_context
* // ... 在 ios 上投递异步任务 ...
* pool.Stop(); // 程序退出前停止所有服务
*/
class AsioIOServicePool : public Singleton<AsioIOServicePool>
{
// 允许 Singleton 基类访问私有构造函数
friend Singleton<AsioIOServicePool>;
public:
// ======================== 类型别名 ========================
/// boost::asio::io_context — 异步 IO 事件循环核心
using IOService = boost::asio::io_context;
/// io_context::work — 保活令牌,构造时阻止 io_context::run() 在无任务时退出
using Work = boost::asio::io_context::work;
/// Work 的独占所有权智能指针,确保 work 对象的生命周期由池统一管理
using WorkPtr = std::unique_ptr<Work>;
// ======================== 生命周期 ========================
/**
* @brief 析构函数
*
* 确保在对象销毁前停止所有 io_context 并 join 所有工作线程,
* 防止资源泄漏和线程残留。
*/
~AsioIOServicePool();
// ======================== 禁止拷贝 ========================
/// 删除拷贝构造函数 — 单例对象不允许拷贝
AsioIOServicePool(const AsioIOServicePool&) = delete;
/// 删除拷贝赋值运算符 — 单例对象不允许赋值
AsioIOServicePool& operator=(const AsioIOServicePool&) = delete;
// ======================== 公共接口 ========================
/**
* @brief 获取一个可用的 io_context
*
* 采用 round-robin(轮询)算法,每次调用返回池中下一个 io_context,
* 循环往复。这使得异步任务被大致均匀地分发到各个工作线程上。
*
* @return boost::asio::io_context& 当前轮到的 io_context 引用
*/
boost::asio::io_context& GetIOService();
/**
* @brief 停止整个线程池
*
* 依次执行:
* 1. 销毁所有 work 对象(移除保活令牌)
* 2. 等待所有工作线程退出(join)
*
* 调用后线程池不可再使用。
*/
void Stop();
private:
// ======================== 构造 ========================
/**
* @brief 私有构造函数(单例模式要求)
*
* 初始化指定数量的 io_context、对应的 work 保活令牌以及工作线程。
* 每个线程调用自己绑定的 io_context::run(),进入事件循环。
*
* @param size 线程数量,默认值为 std::thread::hardware_concurrency()
* (即 CPU 逻辑核心数,通常是最优选择)
*/
AsioIOServicePool(std::size_t size = std::thread::hardware_concurrency());
// ======================== 成员变量 ========================
/**
* @brief io_context 容器
*
* 每个元素是一个独立的异步事件循环实例。
* 使用值存储(非指针),利用 vector 的连续内存提高缓存局部性。
*/
std::vector<IOService> _ioServices;
/**
* @brief work 保活令牌容器
*
* 每个 io_context 需要一个关联的 work 对象。
* 只要 work 存在,io_context 就不会因为没有待处理任务而提前退出 run()。
* 使用 unique_ptr 确保所有权唯一,销毁时自动清理。
*/
std::vector<WorkPtr> _works;
/**
* @brief 工作线程容器
*
* 每个线程运行一个 io_context::run()。
* 线程数量与 _ioServices 大小一致(通过构造函数参数指定)。
*/
std::vector<std::thread> _threads;
/**
* @brief 轮询索引
*
* 记录下一次 GetIOService() 应该返回的 io_context 下标。
* 每次调用后自增并取模,实现 round-robin 分发。
*/
std::size_t _nextIOService;
};
/**
* @brief 构造函数 — 初始化指定数量的 io_context、work 保活令牌及工作线程
*
* 初始化流程分为三步:
* 1. 为每个 io_context 创建 work 保活令牌,防止 io_context 在无任务时退出
* 2. 为每个 io_context 启动一个独立的工作线程
* 3. 线程执行 io_context::run(),进入阻塞式事件循环,等待异步任务投递
*
* @param size 线程池大小(io_context 与线程数量一致)
* 默认值 std::thread::hardware_concurrency()
* 取值建议:CPU 密集型用 `cores`,IO 密集型可用 `2 * cores`
*/
AsioIOServicePool::AsioIOServicePool(std::size_t size)
// ────────────────── 初始化列表 ──────────────────
: _ioServices(size) // 构造 size 个默认的 io_context 对象(值语义,连续内存)
, _works(size) // 预分配 size 个空 unique_ptr<Work>,后续逐个填充
, _nextIOService(0) // 轮询索引初始为 0,第一次 GetIOService() 返回第一个
{
// ======================== 第一步:创建 work 保活令牌 ========================
//
// 关键设计:必须为每个 io_context 绑定一个 work 对象。
//
// 原理说明:
// io_context::run() 在没有待处理任务时会立即返回(退出事件循环)。
// io_context::work 相当于一个"占位任务"——只要 work 存活,
// io_context 就认为自己还有"工作"没做完,从而 run() 持续阻塞等待。
// 当需要关闭线程池时,只需销毁 work 对象,io_context 便能自然退出。
//
// 简单类比:work 就像给事件循环插了一根"勿退出"的占位符。
//
for (std::size_t i = 0; i < size; ++i) {
// unique_ptr 不允许拷贝构造,无法使用 `_works[i] = make_unique<Work>(...)`
// 因此这里显式 new 并用原始指针构造 unique_ptr
_works[i] = std::unique_ptr<Work>(new Work(_ioServices[i]));
}
// ======================== 第二步:启动工作线程 ========================
//
// 遍历每个 io_context,为其创建一个独立线程。
// 每个线程进入 io_context::run() 事件循环,阻塞等待异步任务。
//
for (std::size_t i = 0; i < _ioServices.size(); ++i) {
// emplace_back:直接在 vector 末尾原地构造线程对象,避免额外的移动/拷贝开销
//
// lambda 捕获说明:
// [this, i] — 捕获 this 指针(访问成员 _ioServices)
// — 按值捕获 i(每个线程绑定自己对应的 io_context 索引)
//
// ⚠ 注意:此处必须按值捕获 i,不能用 [&] 或 [this, &i]。
// 循环变量 i 在每个迭代中变化,若按引用捕获,线程启动延迟时
// i 可能已经变为下一个值甚至超出范围,导致线程绑定错误的 io_context。
// 按值捕获确保每个线程拿到 i 在本轮迭代中的"快照"。
//
_threads.emplace_back([this, i]() {
// 线程主循环:阻塞式运行 io_context 事件循环
// 直到 work 被销毁 + 所有投递任务都执行完毕,run() 才会返回,线程退出
_ioServices[i].run();
});
}
}
/**
* @brief 使用 round-robin(轮询)策略获取一个 io_context
*
* 每次调用取当前索引指向的 io_context,然后索引前移一位。
* 当索引到达末尾时回绕到 0,形成闭环轮询。
*
* 线程安全说明:
* 本方法未加锁,设计意图是将其作为"无锁读写"的热路径。
* 调用方应保证多线程访问时外部加锁,或者所有 GetIOService() 调用
* 发生在同一个线程中(例如在 Acceptor 线程中统一分配)。
*
* @return 当前轮到的 io_context 引用
*/
boost::asio::io_context& AsioIOServicePool::GetIOService()
{
// -- 步骤 1:取出当前轮到的 io_context,并后移索引 --
//
// 后缀 ++ 的语义:
// _ioServices[_nextIOService] 先以 old_index 下标访问元素
// _nextIOService++ 再将索引 +1
//
// 两步合并在一行,简洁且避免了额外中间变量。
//
auto& service = _ioServices[_nextIOService++];
// -- 步骤 2:索引回绕 --
//
// 当索引走到容器末尾(等于 size)时,重置为 0。
// 形成 0 → 1 → 2 → ... → size-1 → 0 的循环。
//
// 等价写法(更紧凑但可能牺牲可读性):
// _nextIOService %= _ioServices.size();
//
// 选用 if 判断而非取模的原因:
// 取模运算涉及整数除法,CPU 开销略高于一次比较 + 赋值。
// 在热路径上,这种微优化有一定意义。
//
if (_nextIOService == _ioServices.size()) {
_nextIOService = 0;
}
// -- 步骤 3:返回引用 --
//
// 返回引用而非值拷贝,调用方拿到的就是池中真实的 io_context,
// 可以直接在其上投递异步任务(如 post、dispatch 等)。
//
return service;
}
/**
* @brief 优雅关闭整个 IO 线程池
*
* 关闭分两个阶段,顺序不可颠倒:
* 1. 销毁所有 work 保活令牌 → 让 io_context 有机会自然退出
* 2. 等待所有工作线程结束 → 回收线程资源
*
* 调用时机:
* 应在主线程退出前或不再需要异步 IO 服务时调用。
* 典型调用位置:析构函数中自动调用,或用户显式调用以提前关闭。
*
* 注意:
* 调用 Stop() 后线程池不可再使用。如需恢复,需重新创建实例。
*/
void AsioIOServicePool::Stop()
{
// ======================== 阶段一:销毁 work 保活令牌 ========================
//
// 遍历所有 work 对象,调用 unique_ptr::reset() 将其置为 nullptr,
// 底层 work 对象被析构。
//
// 关键原理:
// 每个 io_context 在 run() 时会检查"我是否还有工作要做?"
// — 有待处理的异步任务 → 继续运行
// — 有 work 对象存活 → 继续运行(即使没有实际任务)
// — 两者都没有 → run() 返回,事件循环退出
//
// 因此 reset() 是"通知"io_context 可以开始准备退出的信号。
//
// ⚠ 注意:work 销毁后,io_context 不会立即退出!
// 它还会继续把队列中已投递的剩余任务全部执行完毕,
// 然后 run() 才会返回。这是"优雅关闭"的保证。
//
for (auto& work : _works) {
work.reset(); // 析构底层 Work 对象,移除保活令牌
}
// ======================== 阶段二:等待所有工作线程退出 ========================
//
// 遍历所有线程,调用 std::thread::join() 阻塞等待线程完成。
//
// join() 的作用:
// 调用线程(通常是主线程)在此处阻塞,直到被 join 的那个线程
// 执行完 run() 并返回(即 io_context 事件循环完全退出)。
//
// 如果跳过 join() 直接析构 std::thread:
// std::thread 析构函数检测到线程仍处于 joinable 状态,
// 会调用 std::terminate() 导致程序崩溃。
//
// 顺序保证:
// 必须先 join,后析构 _threads 容器(析构函数隐式完成)。
// 如果 join 和 work reset 顺序颠倒(先 join 后 reset):
// → 线程死锁!因为 work 未销毁,io_context 认为工作未完成,
// run() 永不返回,join() 永久阻塞。
//
for (auto& t : _threads) {
t.join(); // 阻塞等待线程安全退出
}
}
两阶段关闭流程图
正常运行 阶段一 阶段二
┌──────────────┐ ┌──────────────────┐ ┌──────────────────┐
│ work 保活 │ │ work.reset() │ │ t.join() │
│ │ ──→ │ work 对象析构 │ ──→ │ 等待 run() 返回 │
│ io_context │ │ │ │ │
│ .run() 阻塞 │ │ 处理完剩余任务 │ │ 线程安全退出 │
└──────────────┘ └──────────────────┘ └──────────────────┘
▲ ▲ ▲
│ │ │
保活令牌存活 令牌移除, 线程回收完成
线程持续运行 允许自然退出 池彻底停止
/**
* @brief 服务器入口函数
*
* 整体流程:
* 1. 获取 IO 线程池单例(为服务器提供多线程异步处理能力)
* 2. 创建一个独立的 io_context 用于主循环(信号监听 + Acceptor)
* 3. 注册 SIGINT / SIGTERM 信号处理,实现优雅退出
* 4. 启动服务器,绑定端口 10086
* 5. 进入主线程事件循环(阻塞)
*
* 架构说明:
* 本例采用 "一主多从" 模式:
* — 主 io_context(main 函数中的局部变量)负责信号处理、接受新连接
* — 从 io_context(线程池中的那些)负责已建立连接的读写等耗时操作
* 这是 Boost.Asio 推荐的典型并发设计方案。
*/
int main()
{
try {
// ======================== 第一步:获取线程池单例 ========================
//
// GetInstance() 返回单例的引用。
// 构造函数按 std::thread::hardware_concurrency() 创建线程池,
// 所有工作线程已启动,各自阻塞在对应 io_context::run() 上。
//
// 注意:这里获取的是指针(pool 的实际类型取决于你的 Singleton 实现)。
// 如果 Singleton 返回的是引用,写法通常为:
// auto& pool = AsioIOServicePool::GetInstance();
//
auto pool = AsioIOServicePool::GetInstance();
// ======================== 第二步:创建主 io_context ========================
//
// 这个 io_context 独立于线程池中的任何 io_context,
// 专用于:
// — 监听操作系统信号(SIGINT/SIGTERM)
// — 在 CServer 内部用于 Acceptor 的初始化
//
// 为什么需要独立的 io_context?
// 信号处理需要在自己的线程中运行,与连接处理逻辑分离,
// 可以安全地调用 io_context::stop() 来中止主循环。
//
boost::asio::io_context io_context;
// ======================== 第三步:注册信号处理 ========================
//
// signal_set 封装了对 POSIX 信号的异步监听。
// 这里监听两个典型的终止信号:
// SIGINT — 用户按下 Ctrl+C(终端中断)
// SIGTERM — 系统请求进程终止(如 kill 命令不带 -9 时)
//
// 注意:在 Windows 平台上,这两个信号的行为受限于 Win32 API。
// 若要跨平台,可额外监听 SIGBREAK。
//
boost::asio::signal_set signals(io_context, SIGINT, SIGTERM);
// async_wait 注册一个异步回调——程序不会在这里阻塞。
// 当操作系统投递 SIGINT 或 SIGTERM 时,io_context 的事件循环
// 会调用此 lambda,在 io_context::run() 所在线程中执行。
//
// lambda 参数说明:
// auto error — boost::system::error_code,信号等待是否出错
// auto signal_number — 触发此回调的信号编号(SIGINT=2 / SIGTERM=15)
// 两者都用 auto 简化声明,避免书写冗长的 boost 类型。
//
signals.async_wait([&io_context, pool](auto /*error*/, auto /*signal_number*/) {
// ---- 步骤 A:停止主 io_context ----
//
// io_context::stop() 会强制让所有在其上调用 run() 的线程
// 尽快返回(退出事件循环)。
//
// 区别:
// stop() → 立即停止,丢弃未完成的任务
// work 销毁 → 等待所有已投递任务执行完毕才退出(优雅)
//
// 这里使用 stop() 是合理的:信号到来意味着进程即将终止,
// 不需要等待主循环上剩余的任务完成。
//
io_context.stop();
// ---- 步骤 B:停止线程池 ----
//
// 线程池的 Stop() 是优雅关闭:先销毁 work 令牌,
// 等待各 io_context 上已有的任务执行完毕,再 join 线程。
// 这保证了所有正在处理中的客户端请求不会中途被截断。
//
// 顺序很重要:先 stop 主循环,再 pool->Stop() 停止工作线程,
// 最后 main 函数退出,进程结束。
//
pool->Stop();
});
// ======================== 第四步:创建并启动服务器 ========================
//
// CServer 构造函数内部:
// — 使用 pool->GetIOService() 获取一个线程池中的 io_context
// — 在该 io_context 上创建 acceptor,绑定端口 10086
// — 发起第一个异步 accept 调用
//
// 因此新连接会由线程池中的某个工作线程来处理 accept 完成回调,
// 具体是 GetIOService() round-robin 返回的那个。
//
// 端口 10086 是中国移动的客服号,这里只是用作示例端口。
// 小于 1024 的端口在 Linux 上需要 root 权限。
//
CServer s(io_context, 10086);
// ======================== 第五步:启动主事件循环 ========================
//
// 当前线程(主线程)进入阻塞式事件循环,负责:
// — 等待信号回调被触发(SIGINT/SIGTERM)
// — 处理 Acceptor 相关的事件
//
// run() 的退出条件:
// 正常情况:io_context 无事可做且无 work 令牌 → run() 返回
// 本例情况:信号到达 → async_wait 回调中调用 io_context.stop()
// → 强制让 run() 返回
//
// CServer 内部将 Acceptor 绑定在 pool 的 io_context 上,
// 而非此处的 io_context,所以主循环的退出不影响 Acceptor 行为,
// Acceptor 的 io_context 的 run() 在线程池的工作线程中运行。
//
io_context.run();
}
catch (std::exception& e) {
// 捕获标准异常并输出错误信息
// 常见异常:
// boost::system::system_error — 端口被占用、地址无效等
// std::bad_alloc — 内存不足
std::cerr << "Exception: " << e.what() << std::endl;
}
// main 函数结束:
// — 局部变量 io_context 被析构
// — pool 指针释放(但单例池本身不会被销毁,除非 Singleton 实现了特殊管理)
// — 进程退出(操作系统回收所有线程和资源)
}
架构总览图
main() 主线程
┌─────────────────────────────────┐
│ io_context (局部变量) │
│ ├── signal_set (SIGINT/SIGTERM) │
│ └── CServer (Acceptor 初始化) │
│ │ │
│ io_context.run() ← 阻塞 │
│ │ │
│ 收到 Ctrl+C │
│ io_context.stop() │
│ pool->Stop() │
└─────────────────────────────────┘
│
┌─────────────────────────┼─────────────────────────┐
│ │ │
▼ ▼ ▼
┌──────────┐ ┌──────────┐ ┌──────────┐
│ 工作线程1 │ │ 工作线程2 │ │ 工作线程N │
│ io_0.run │ │ io_1.run │ │ io_n.run │
│ │ │ │ │ │
│ 处理连接 │ │ 处理连接 │ │ 处理连接 │
└──────────┘ └──────────┘ └──────────┘
AsioIOServicePool 线程池(N = 逻辑核心数)
负责已建立连接的异步读写操作(round-robin 分发)
IOThreadPool
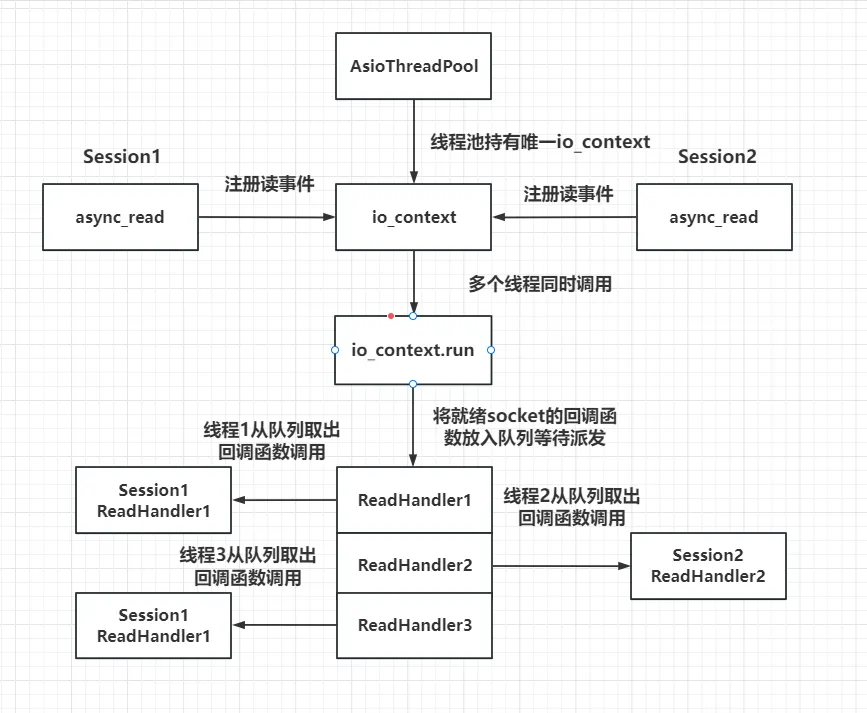
只初始化一个iocontext用来监听服务器的读写事件,包括新连接到来的监听也用这个iocontext。只是我们让
<font style="color:#DF2A3F;">iocontext.run</font>在多个线程中调用,这样回调函数就会被不同的线程触发,从这个角度看回调函数被并发调用了。
结构图
IOThreadPool 实现
/**
* @class AsioThreadPool
* @brief 基于单 io_context + 多线程的 IO 线程池,继承自单例模板
*
* 与 AsioIOServicePool(多 io_context 各一线程)不同,本类采用
* "单 io_context 多线程"模式:
* — 整个池共用一个 boost::asio::io_context
* — 多个工作线程同时调用同一个 io_context::run()
* — io_context 内部使用互斥锁保证线程安全
* — 任务分发由 io_context 内部的调度器自动完成
*
* 两种模式的对比:
* ┌────────────────────┬──────────────────────┬──────────────────────┐
* │ │ AsioIOServicePool │ AsioThreadPool │
* ├────────────────────┼──────────────────────┼──────────────────────┤
* │ io_context 数量 │ N 个(各一个线程) │ 1 个(N 个线程) │
* │ 分发策略 │ 外部 round-robin │ io_context 内部调度 │
* │ 锁竞争 │ 无(每个独立运行) │ 有(单队列多消费者) │
* │ 任务亲和性 │ 强(任务绑定线程) │ 弱(任意线程取任务) │
* │ 代码复杂度 │ 较高 │ 较低 │
* └────────────────────┴──────────────────────┴──────────────────────┘
*
* 适用场景:任务执行时间较短、对锁竞争不敏感、希望简化代码时。
*/
class AsioThreadPool : public Singleton<AsioThreadPool>
{
public:
// 允许 Singleton 基类访问私有构造函数
friend class Singleton<AsioThreadPool>;
// ======================== 生命周期 ========================
/**
* @brief 析构函数(空实现)
*
* 注意:析构函数为空体,关闭逻辑应通过显式调用 Stop() 完成。
* 这是因为 Singleton 的析构时机不可控(可能在全局变量析构阶段),
* 此时 join 线程可能引发未定义行为。
*/
~AsioThreadPool() {}
// ======================== 禁止拷贝 ========================
/// 删除拷贝赋值运算符 — 单例对象不允许赋值
AsioThreadPool& operator=(const AsioThreadPool&) = delete;
/// 删除拷贝构造函数 — 单例对象不允许拷贝
AsioThreadPool(const AsioThreadPool&) = delete;
// ======================== 公共接口 ========================
/**
* @brief 获取唯一的 io_context 引用
*
* 池中只有一个 io_context,所有线程共享。
* 调用方直接在此 io_context 上投递任务,由 Boost.Asio 内部
* 调度器将任务分发给空闲的工作线程。
*
* 因为只有一个 io_context,不需要 round-robin 等外部分发策略。
*
* @return boost::asio::io_context& 共享的 io_context 引用
*/
boost::asio::io_context& GetIOService();
/**
* @brief 停止整个线程池
*
* 执行顺序:
* 1. 销毁 work 保活令牌(让唯一的 io_context 可以自然退出)
* 2. 等待所有工作线程退出(join)
*
* 由于所有线程运行的是同一个 io_context::run(),
* work 销毁后,当所有已投递任务执行完毕,所有线程的 run() 会一起返回。
*/
void Stop();
private:
// ======================== 构造 ========================
/**
* @brief 私有构造函数(单例模式要求)
*
* 初始化流程:
* 1. 创建 work 保活令牌
* 2. 启动指定数量的工作线程,每个线程调用 _service.run()
* 多个线程运行同一个 io_context 是 Boost.Asio 官方支持的用法。
*
* @param threadNum 工作线程数量,默认值为 std::thread::hardware_concurrency()
* 建议不超过 CPU 逻辑核心数(纯计算场景),
* IO 密集型可适当增大(如 2 × cores)。
*/
AsioThreadPool(int threadNum = std::thread::hardware_concurrency());
// ======================== 成员变量 ========================
/**
* @brief 唯一的 io_context 实例
*
* 所有工作线程共享这一个事件循环。
* io_context 内部的线程安全保证:
* — poll() / run() 可以被多个线程同时调用
* — 提交任务的函数(post/dispatch/defer)线程安全
* — 完成处理器可能在不同线程中并发执行
*
* 注意:虽然任务提交和调度是线程安全的,但各个完成处理器
* 之间没有自动同步,多个 handler 可能并发访问共享数据,
* 需要用户自行用 strand(串行化)或互斥锁保护。
*/
boost::asio::io_context _service;
/**
* @brief work 保活令牌(唯一指针)
*
* 作用同 AsioIOServicePool 中的 work:
* 只要此对象存在,_service.run() 就不会因无任务而返回。
*
* 使用 unique_ptr 管理生命周期:
* 构造时 new,Stop() 时 reset(),析构时自动清理(若未手动 reset)。
*/
std::unique_ptr<boost::asio::io_context::work> _work;
/**
* @brief 工作线程容器
*
* 所有线程执行相同的操作:调用 _service.run()。
* 不同之处在于它们并发地 poll 同一个内部任务队列。
*
* 线程模型示意:
* _threads[0] ─┐
* _threads[1] ─┤──→ _service.run() ← 同一个 io_context
* _threads[2] ─┤ │
* ... ─┘ 内部互斥锁 + 条件变量
* 取出任务并执行 handler
*/
std::vector<std::thread> _threads;
};
/**
* @brief 构造函数 — 创建 work 保活令牌并启动指定数量的工作线程
*
* 与 AsioIOServicePool 的关键区别:
* AsioIOServicePool:N 个 io_context,每个绑一个线程
* AsioThreadPool: 1 个 io_context,N 个线程共享
*
* 后者省去了 round-robin 分发逻辑,任务调度完全交给 Boost.Asio 内部处理。
*
* @param threadNum 工作线程数量,默认值 std::thread::hardware_concurrency()
*/
AsioThreadPool::AsioThreadPool(int threadNum)
// ────────────────── 初始化列表 ──────────────────
: _work(new boost::asio::io_context::work(_service))
// ↑
// 在 _service 上创建 work 保活令牌。
// 由于 _service 只有一个,只需要一个 work 对象就能拴住所有线程。
//
// 原理回顾:
// io_context::run() 在没有任务且没有 work 时立即返回。
// 有了 work,即使没有用户投递的任务,run() 也会一直阻塞。
// 等 Stop() 中 reset() 掉 work,所有线程的 run() 才能返回。
//
// 写法说明:
// 这里用初始化列表直接构造 unique_ptr,避免先默认构造再赋值。
// new Work(_service) 是 C++11 时代的写法,
// C++14 及以后可改为 std::make_unique<Work>(_service)。
{
// ======================== 启动工作线程 ========================
//
// 创建 threadNum 个工作线程,全部执行同一个 _service.run()。
//
// Boost.Asio 官方文档明确支持多线程运行同一个 io_context:
// — 多个线程并发调用 run() 时,它们共享同一个任务队列
// — 内部使用互斥锁保护队列操作
// — 每个就绪的完成处理器只会被一个线程取出执行
// — 不同处理器可能在不同线程中并发执行
//
// 并发安全注意事项:
// 虽然任务调度本身是线程安全的,但各个 handler(完成回调)
// 之间没有自动同步。如果多个 handler 访问同一共享数据,
// 需要自行加锁或使用 strand 串行化执行。
//
for (int i = 0; i < threadNum; ++i) {
// emplace_back:在 vector 末尾原地构造 std::thread 对象
//
// lambda 捕获说明:
// [this] — 只捕获 this 指针,即可访问成员 _service
//
// 与 AsioIOServicePool 不同,这里不需要捕获循环变量 i,
// 因为所有线程都调用同一个 _service.run(),没有"绑定索引"的概念。
// 这是单 io_context 设计的简化优势之一。
//
_threads.emplace_back([this]() {
// 进入 io_context 事件循环,阻塞等待任务。
//
// 多个线程同时执行这一行,io_context 内部负责:
// 1. 从任务队列取就绪的 handler
// 2. 调用该 handler(完成回调函数)
// 3. 重复,直到 work 被销毁 + 队列为空 → run() 返回
//
// 如果 run() 抛出异常(来自某个 handler),
// 异常会在线程中传播,导致 std::terminate() 终止进程。
// 生产代码建议在 handler 内部捕获异常,避免影响线程池。
//
_service.run();
});
}
}
/**
* @brief 获取唯一的 io_context 引用
*
* 永远返回同一个 _service,调用方直接在其上投递任务即可。
*
* 与 AsioIOServicePool::GetIOService() 的差异:
* — AsioIOServicePool:需要 round-robin 循环选择不同的 io_context
* — AsioThreadPool: 直接返回唯一的 _service,无需任何索引逻辑
*
* 这种简洁性正是单 io_context 模式的主要优势:
* 外部无需关心线程池内部结构,像使用普通 io_context 一样使用即可。
*
* @return boost::asio::io_context& 唯一的 _service 引用
*/
boost::asio::io_context& AsioThreadPool::GetIOService()
{
return _service;
}
/**
* @brief 优雅关闭线程池
*
* 两阶段关闭流程(顺序不可颠倒):
* 1. 销毁 work 保活令牌 → 允许所有线程的 run() 自然返回
* 2. join 所有工作线程 → 等待各线程完全退出
*
* 为什么先 reset 后 join?
* 如果反过来(先 join 后 reset):
* → work 未销毁,_service.run() 认为工作未完成
* → 所有线程的 run() 永远阻塞
* → join() 永远不返回
* → 死锁!
*
* 为什么一个 reset() 能影响所有线程?
* 所有线程运行的是同一个 _service.run()。
* work 是 _service 上的保活令牌,只要它存在,_service 就处于"有工作"状态。
* reset() 销毁 work 后,_service 在队列清空后通知所有线程退出。
* 各个线程在 flush 完最后一个 handler 后,run() 陆续返回。
*/
void AsioThreadPool::Stop()
{
// ======================== 阶段一:销毁 work 保活令牌 ========================
//
// unique_ptr::reset() 将内部指针置为 nullptr,
// 原指向的 work 对象被析构。
//
// 效果:_service 失去保活令牌,当所有已投递任务完成后,
// 所有调用 run() 的线程可以退出。
//
// ⚠ 注意:reset() 不会立即中断正在执行的 handler。
// 已在执行中的 handler 会正常运行完毕。
// 只有那些还在等任务(阻塞在 run() 内部的条件变量上)的线程
// 才会因为 work 消失而醒来并返回。
//
_work.reset();
// ======================== 阶段二:等待所有线程退出 ========================
//
// 遍历所有线程,调用 join() 阻塞等待。
//
// join() 的必要性:
// 如果不 join 而让 std::thread 直接析构:
// → 线程处于 joinable 状态(尚未 detach 也未 join)
// → std::thread 析构函数调用 std::terminate()
// → 程序崩溃
//
// try-catch 考虑:
// 如果某个线程因 handler 抛出异常而已经终止,
// join() 仍能正常返回(join 已经结束的线程是安全的)。
//
for (auto& t : _threads) {
t.join(); // 阻塞等待线程 t 完全退出
}
// 所有线程 join 完成后,线程池处于彻底停止状态。
// _threads 容器中的 std::thread 对象此时均为"不可 join"状态,
// 后续析构 _threads 是安全的。
}
:::danger
构造函数中实现了一个线程池,线程池里每个线程都会运行_service.run函数:
_service.run函数内部就是从iocp或者epoll获取就绪描述符和绑定的回调函数,进而调用回调函数,因为回调函数是在不同的线程里调用的,所以会存在不同的线程调用同一个socket的回调函数的情况。_service.run内部在Linux环境下调用的是epoll_wait返回所有就绪的描述符列表,在windows上会循环调用GetQueuedCompletionStatus函数返回就绪的描述符,二者原理类似,进而通过描述符找到对应的注册的回调函数,然后调用回调函数。
:::
1 创建完成端口(iocp)对象
2 创建一个或多个工作线程,在完成端口上执行并处理投递到完成端口上的I/O请求
3 Socket关联iocp对象,在Socket上投递网络事件
4 工作线程调用GetQueuedCompletionStatus函数获取完成通知封包,取得事件信息并进行处理
1 调用epoll_creat在内核中创建一张epoll表
2 开辟一片包含n个epoll_event大小的连续空间
3 将要监听的socket注册到epoll表里
4 调用epoll_wait,传入之前我们开辟的连续空间,epoll_wait返回就绪的epoll_event列表,epoll会将就绪的socket信息写入我们之前开辟的连续空间
利用strand改进
:::color4
🔥**隐患**
IOThreadPool模式有一个隐患,同一个socket的就绪后,触发的回调函数可能在不同的线程里,比如第一次是在线程1,第二次是在线程3,如果这两次触发间隔时间不大,那么很可能出现不同线程并发访问数据的情况,比如在处理读事件时,第一次回调触发后我们从socket的接收缓冲区读数据出来,第二次回调触发,还是从socket的接收缓冲区读数据,就会造成两个线程同时从socket中读数据的情况,会造成数据混乱。
:::
对于多线程触发回调函数的情况,我们可以利用asio提供的串行类strand封装一下,这样就可以被串行调用了,其基本原理就是**在线程各自调用函数时取消了直接调用的方式,而是利用一个strand类型的对象将要调用的函数投递到strand管理的队列中,再由一个统一的线程调用回调函数,调用是串行的,解决了线程并发带来的安全问题**。

为了让回调函数被派发到strand的队列,我们只需要在注册回调函数时加一层strand的包装即可。
strand<io_context::executor_type> _strand;
/**
* @brief CSession 构造函数 — 初始化一个客户端会话
*
* 每个 CSession 对象代表一个与客户端建立的独立连接,负责该连接上的
* 全部网络通信(接收、解析、发送)。构造函数完成以下初始化:
* 1. 绑定 socket 到指定的 io_context
* 2. 记录所属服务器指针
* 3. 初始化会话状态标志
* 4. 创建 strand 以保证 handler 串行执行
* 5. 生成全局唯一的会话 ID(UUID)
* 6. 预分配存放消息头的接收缓冲区
*
* @param io_context 用于异步 IO 操作的 io_context(由线程池提供)
* @param server 指向所属 CServer 的指针,用于回调(如断开通知)
*/
CSession::CSession(boost::asio::io_context& io_context, CServer* server)
// ────────────────── 初始化列表 ──────────────────
: _socket(io_context)
// ↑ TCP socket 绑定到指定的 io_context。
// socket 的构造函数接受 io_context& 作为唯一必需参数,
// 实际的连接由 acceptor 在 accept 时自动赋值(move 语义)。
//
, _server(server)
// ↑ 记录所属服务器指针。
// 当 session 需要通知服务器(如连接断开、统计数据更新)时使用。
// 注意:_server 的生命周期由调用方保证(通常是 main 中的 CServer 对象),
// 其生命周期长于所有 CSession,因此裸指针是安全的。
//
, _b_close(false)
// ↑ 会话关闭标志,初始为 false(会话处于活跃状态)。
// 当设置为 true 时,表示该连接已进入关闭流程,
// 后续的回调函数应检查此标志,避免重复关闭或非法操作。
//
, _b_head_parse(false)
// ↑ 消息头解析完成标志,初始为 false。
//
// 自定义协议通常采用 "定长头 + 变长体" 结构:
// ┌──────────────┬─────────────────────┐
// │ HEAD (固定长度) │ BODY (长度由头部指定) │
// └──────────────┴─────────────────────┘
//
// 接收流程分两步:
// 第一步:读取 HEAD_TOTAL_LEN 字节到 _recv_head_node → 解析头部
// 第二步:根据头部中的 body 长度,读取变长的消息体
//
// _b_head_parse 为 false 时,接收的是头部;
// 当头部完整接收并解析完毕后,置为 true,接收后续的消息体。
//
, _strand(io_context.get_executor())
// ↑ 创建一个 strand(串行执行器),与当前 io_context 关联。
//
// strand 的作用:
// 保证投递到同一个 strand 上的多个 handler 不会并发执行。
// 即:对于同一个 CSession,不会有两个 handler 同时运行,
// 从而避免了对 _socket、_recv_msg_node 等成员变量的竞态条件。
//
// 为什么需要 strand?
// 在多线程池模式下,同一个 io_context 的完成回调可能跑在
// 不同线程中。若不加 strand,两个回调可能同时操作 socket,
// 导致数据错乱。strand 就像一个 "逻辑单线程",序列化了回调。
//
// 使用方式(在后续 async_read/async_write 中):
// 不直接写 `boost::asio::async_read(socket, ...)`,
// 而写 `boost::asio::async_read(socket, strand.wrap(...))` 或
// 使用 bind_executor(strand, handler)。
{
// ======================== 生成会话唯一标识 UUID ========================
//
// Boost.UUID 生成一个 v4 随机 UUID(128 位),然后转换为标准格式字符串。
//
// 两步操作:
// 1. random_generator()() 构造一个随机生成器 + 调用 operator() 生成 UUID
// 2. to_string(a_uuid) 转为 "xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxxx" 格式
//
// UUID 的用途:
// — 日志追踪:在多线程环境下,用 UUID 标识每个连接,方便问题排查
// — 会话管理:可以用 <UUID, CSession*> 的 map 管理所有连接
// — 返回给客户端:客户端可持此 ID 用于断线重连等场景
//
// 为什么用 UUID 而非自增整数?
// — 全局唯一,多服务器场景下不冲突
// — 不可预测,防止客户端枚举连接 ID
//
boost::uuids::uuid a_uuid = boost::uuids::random_generator()();
_uuid = boost::uuids::to_string(a_uuid);
// ======================== 预分配消息头接收缓冲区 ========================
//
// MsgNode 是一个封装了缓冲区的消息节点,构造函数参数为缓冲区大小。
// HEAD_TOTAL_LEN 是协议定义的消息头固定长度(如 sizeof(消息头结构体))。
//
// _recv_head_node 始终用于接收每个消息的头部:
// 接收完 HEAD_TOTAL_LEN 字节 → 解析头部 → 得知 body 长度 →
// 分配 body 缓冲区 → 继续接收 body → 完整消息就绪。
//
// 使用 shared_ptr 而非 unique_ptr 的原因:
// 异步回调可能持有 MsgNode 的引用(通过 lambda 捕获 shared_ptr),
// 需要确保在回调执行期间 MsgNode 不被释放。
// shared_ptr 的引用计数机制完美适配这种异步生命周期管理。
//
_recv_head_node = make_shared<MsgNode>(HEAD_TOTAL_LEN);
}
初始化列表一览
初始化值 类型 职责
┌──────────────────────┬──────────────────┬──────────────────────────────┐
│ _socket(io_context) │ tcp::socket │ 与该客户端通信的 TCP socket │
│ _server(server) │ CServer* │ 所属服务器回指针 │
│ _b_close(false) │ bool │ 会话关闭标志 │
│ _b_head_parse(false) │ bool │ 消息头是否已解析 │
│ _strand(...) │ strand<executor> │ 串行化 handler 执行 │
│ _uuid (函数体内) │ std::string │ 全局唯一会话 ID │
│ _recv_head_node(...) │ shared_ptr<MsgNode>│ 头接收缓冲区(定长) │
└──────────────────────┴──────────────────┴──────────────────────────────┘
:::info
可以看到_strand的初始化是放在初始化列表里,利用io_context.get_executor()返回的执行器构造strand。
因为在asio中无论iocontext还是strand,底层都是通过executor调度的,我们将他理解为调度器就可以了,如果多个iocontext和strand的调度器是一个,那他们的消息派发统一由这个调度器执行。我们利用iocontext的调度器构造strand,这样他们统一由一个调度器管理。在绑定回调函数的调度器时,我们选择strand绑定即可。
:::
void CSession::Start(){
::memset(_data, 0, MAX_LENGTH);
_socket.async_read_some(boost::asio::buffer(_data, MAX_LENGTH),
boost::asio::bind_executor(_strand, std::bind(&CSession::HandleRead, this,
std::placeholders::_1, std::placeholders::_2, SharedSelf())));
}
同样的道理,在所有收发的地方,都将调度器绑定为**<font style="color:#1DC0C9;">_strand</font>**。
auto& msgnode = _send_que.front();
boost::asio::async_write(_socket, boost::asio::buffer(msgnode->_data, msgnode->_total_len),
boost::asio::bind_executor(_strand, std::bind(&CSession::HandleWrite, this, std::placeholders::_1, SharedSelf()))
);
回调函数的处理部分也做对应的修改即可。
性能对比
比较两种服务器多线程模式的性能,客户端每隔10ms建立一个连接,总共建立100个连接,每个连接收发500次,总计10万个数据包,测试一下性能。
#include <iostream>
#include <boost/asio.hpp>
#include <thread>
#include <json/json.h>
#include <json/value.h>
#include <json/reader.h>
#include <chrono>
using namespace std;
using namespace boost::asio::ip;
const int MAX_LENGTH = 1024 * 2;
const int HEAD_LENGTH = 2;
const int HEAD_TOTAL = 4;
std::vector<thread> vec_threads;
int main()
{
auto start = std::chrono::high_resolution_clock::now(); // 获取开始时间
for (int i = 0; i < 100; i++) {
vec_threads.emplace_back([]() {
try {
//创建上下文服务
boost::asio::io_context ioc;
//构造endpoint
tcp::endpoint remote_ep(address::from_string("127.0.0.1"), 10086);
tcp::socket sock(ioc);
boost::system::error_code error = boost::asio::error::host_not_found; ;
sock.connect(remote_ep, error);
if (error) {
cout << "connect failed, code is " << error.value() << " error msg is " << error.message();
return 0;
}
int i = 0;
while (i < 500) {
Json::Value root;
root["id"] = 1001;
root["data"] = "hello world";
std::string request = root.toStyledString();
size_t request_length = request.length();
char send_data[MAX_LENGTH] = { 0 };
int msgid = 1001;
int msgid_host = boost::asio::detail::socket_ops::host_to_network_short(msgid);
memcpy(send_data, &msgid_host, 2);
//转为网络字节序
int request_host_length = boost::asio::detail::socket_ops::host_to_network_short(request_length);
memcpy(send_data + 2, &request_host_length, 2);
memcpy(send_data + 4, request.c_str(), request_length);
boost::asio::write(sock, boost::asio::buffer(send_data, request_length + 4));
cout << "begin to receive..." << endl;
char reply_head[HEAD_TOTAL];
size_t reply_length = boost::asio::read(sock, boost::asio::buffer(reply_head, HEAD_TOTAL));
msgid = 0;
memcpy(&msgid, reply_head, HEAD_LENGTH);
short msglen = 0;
memcpy(&msglen, reply_head + 2, HEAD_LENGTH);
//转为本地字节序
msglen = boost::asio::detail::socket_ops::network_to_host_short(msglen);
msgid = boost::asio::detail::socket_ops::network_to_host_short(msgid);
char msg[MAX_LENGTH] = { 0 };
size_t msg_length = boost::asio::read(sock, boost::asio::buffer(msg, msglen));
Json::Reader reader;
reader.parse(std::string(msg, msg_length), root);
std::cout << "msg id is " << root["id"] << " msg is " << root["data"] << endl;
i++;
}
}
catch (std::exception& e) {
std::cerr << "Exception: " << e.what() << endl;
}
});
std::this_thread::sleep_for(std::chrono::milliseconds(10));
}
for (auto& t : vec_threads) {
t.join();
}
// 执行一些需要计时的操作
auto end = std::chrono::high_resolution_clock::now(); // 获取结束时间
auto duration = std::chrono::duration_cast<std::chrono::seconds>(end - start); // 计算时间差,单位为微秒
std::cout << "Time spent: " << duration.count() << " seconds." << std::endl; // 输
getchar();
return 0;
}
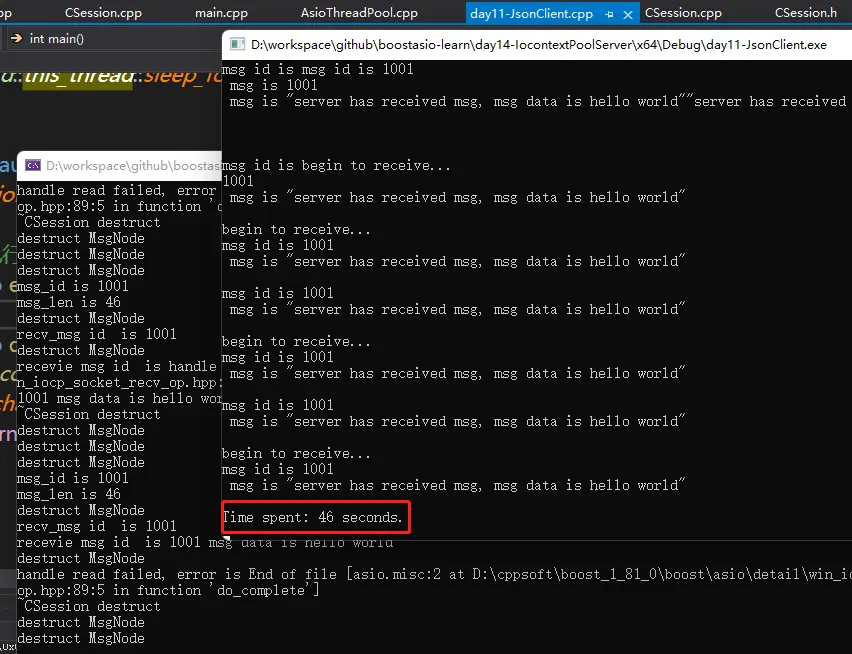
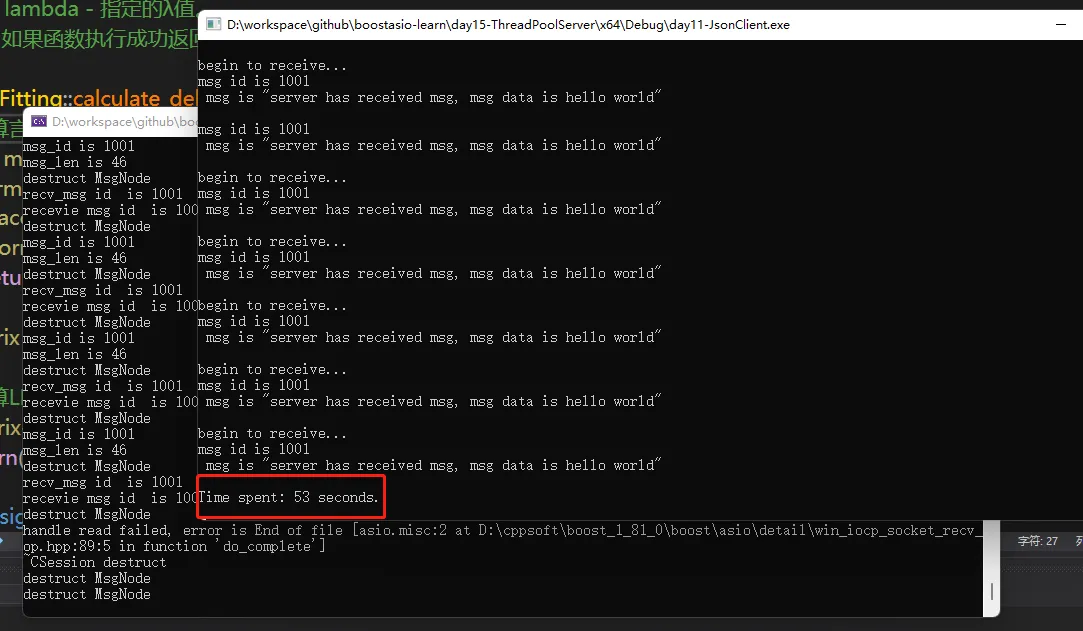
可以看到后者比前者较慢。
🔊**实际的生产和开发中,我们尽可能利用C++特性,使用多核的优势,将iocontext分布在不同的线程中效率更可取一点,但也要防止线程过多导致cpu切换带来的时间片开销,所以尽量让开辟的线程数小于或等于cpu的核数,从而利用多核优势。**

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 19
19 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)