DreamVLA:世界知识驱动的视觉-语言-动作新范式
DreamVLA: A Vision-Language-Action Model Dreamed with Comprehensive World Knowledge
文章目录
- DreamVLA: A Vision-Language-Action Model Dreamed with Comprehensive World Knowledge
核心信息
| 项目 | 内容 |
|---|---|
| 论文ID | arXiv: 2507.04447 |
| 发表会议 | NeurIPS 2025 |
| 机构 | SJTU, EIT, THU, Galbot, PKU, UIUC, USTC |
| 通讯作者 | Xin Jin |
| 第一作者 | Wenyao Zhang |
| 代码 | GitHub |
| 项目页 | Project Page |
| 模型 | HuggingFace |
| 核心贡献 | 将VLA重新定义为感知-预测-行动模型,通过综合世界知识预测实现逆动力学建模 |
摘要翻译
最近在视觉-语言-动作(VLA)模型方面的进展展示了将图像生成与动作预测相结合以提高机器人操作泛化能力和推理能力的潜力。然而,现有方法局限于具有挑战性的基于图像的预测,存在冗余信息且缺乏全面且关键的世界知识,包括动态、空间和语义信息。为了解决这些局限性,我们提出了DreamVLA,一个新颖的VLA框架,集成了综合世界知识预测以实现逆动力学建模,从而建立操作任务的感知-预测-行动循环。具体来说,DreamVLA引入了动态区域引导的世界知识预测,结合空间和语义线索,为动作规划提供了紧凑而全面的表示。这种设计符合人类与世界交互的方式——先形成抽象的多模态推理链,然后再行动。为了减轻训练期间动态、空间和语义信息之间的干扰,我们采用了块状结构化注意力机制,屏蔽它们之间的相互注意力,防止信息泄漏并保持每个表示的干净和解耦。此外,为了建模未来动作的条件分布,我们采用基于扩散的Transformer将动作表示与共享潜在特征解耦。在真实世界和仿真环境上的大量实验表明,DreamVLA在真实机器人任务上达到76.7%的成功率,在CALVIN ABC-D基准上达到4.44的平均长度。
研究背景与动机
现有VLA模型的核心缺陷
现有VLA模型可以分为三种范式(见下图),每种都存在明确的局限性:
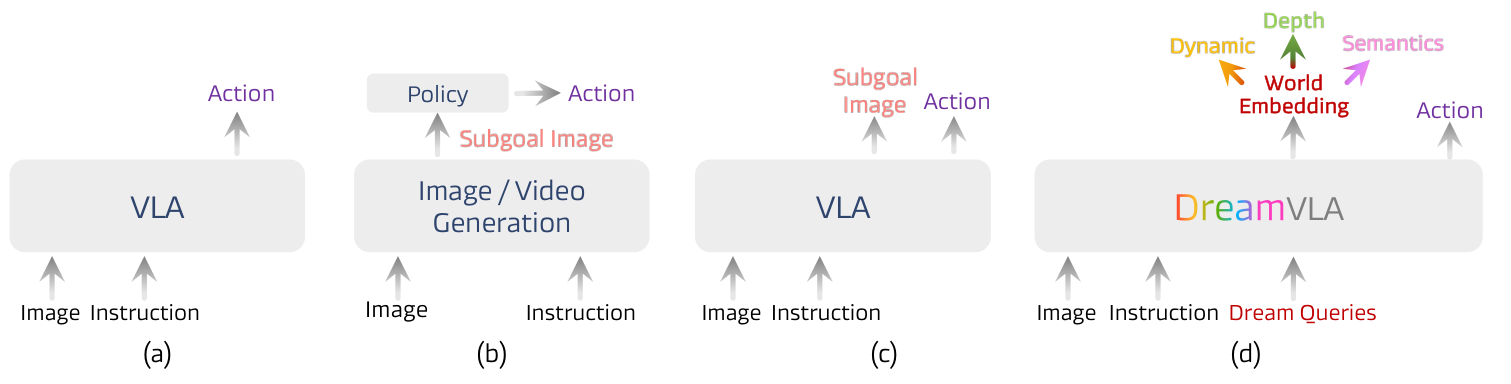
范式(a):直接映射 – 从观测直接映射到动作(如RT-2、OpenVLA),缺乏闭环预测能力,无法像人类那样对环境未来状态进行推理。
范式(b):副驾驶生成 – 使用外部生成模型产生未来帧/关键点,再基于目标图像预测动作(如Susie、CLOVER)。问题:需要额外生成模型,引入推理时间和计算开销。
范式©:联合像素预测 – 将像素级图像预测与动作预测整合在单一框架中(如Seer、UP-VLA、VPP)。问题集中在三点:
- 冗余像素信息:预测的未来图像与当前观测有大量重叠,效率低
- 缺乏空间信息:缺少环境的显式3D知识
- 缺乏高级知识预测:缺失对未来状态的高级理解(如语义信息)
核心洞察
论文的核心洞察来自人类认知方式:人类在与世界交互时,不会在脑中完整重构未来画面,而是先形成抽象的多模态推理链(哪里会动、空间结构如何变化、哪些物体将参与任务),然后再采取行动。DreamVLA正是将这一认知原则具象化——预测的不是完整的未来帧,而是紧凑而全面的世界知识。
研究问题
- 如何在VLA模型中有效引入未来世界知识预测,而不引入冗余的像素级重建?
- 如何将动态信息、空间信息、语义信息三种异构知识统一建模,同时防止它们之间的信息泄漏和表示污染?
- 如何在共享潜在空间中解耦世界知识与动作表示,实现有效的逆动力学推理?
- 预测性世界知识相比辅助重建任务,能否为动作规划提供更有效的信号?
方法概述
DreamVLA的整体架构如下图所示:
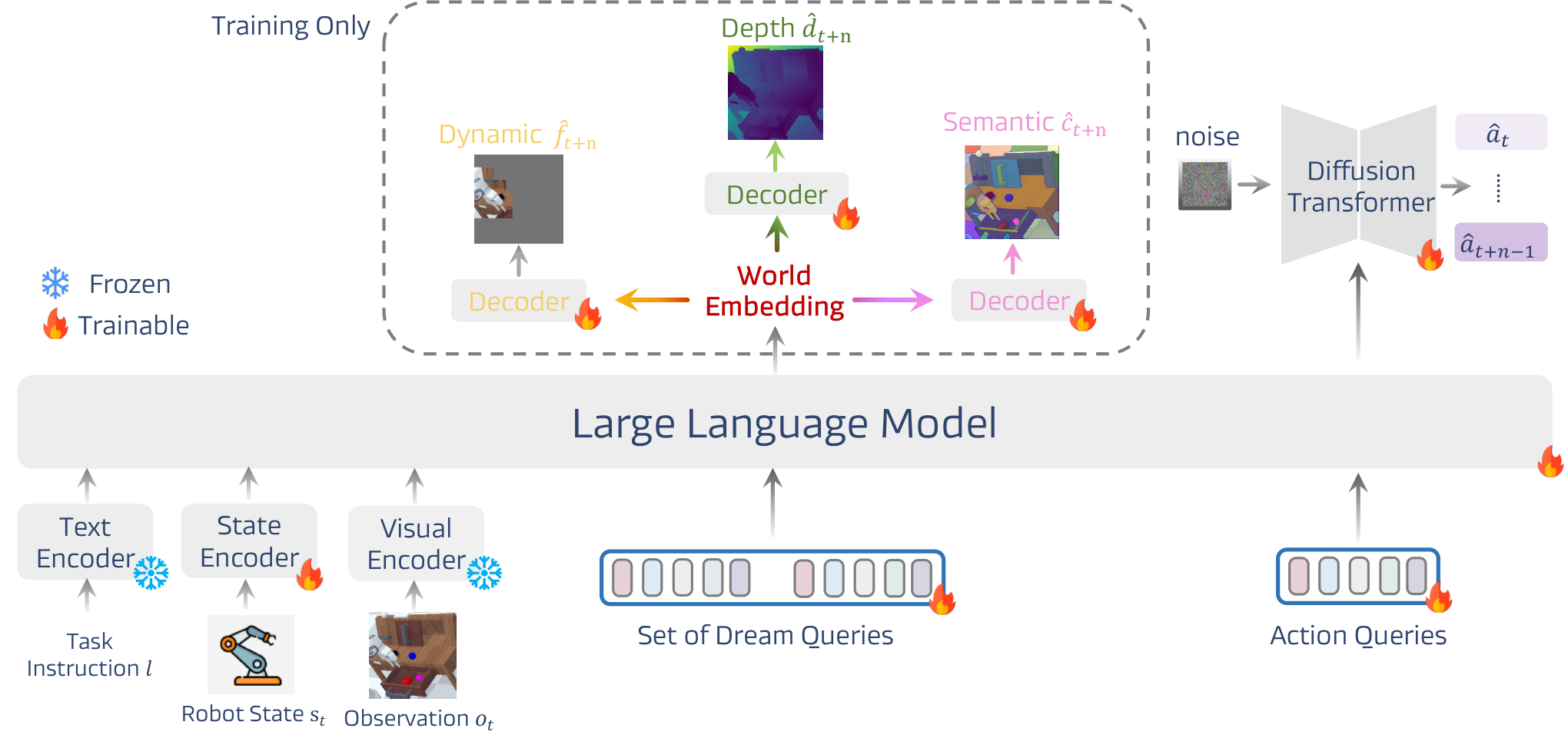
问题形式化:逆动力学建模
论文将VLA推理重新定义为逆动力学问题。在时间步 t t t,机器人接收语言指令 l l l、视觉帧 o t o_t ot 和本体感受状态 s t s_t st。通过 <dream> 查询token,统一模型 M \mathcal{M} M 将输入映射为紧凑的潜在表示——世界嵌入(world embedding):
$$
\mathbf{w}_{t+n} = \mathcal{M}(l, o_t, s_t | \text{})
$$
预测器 P \mathcal{P} P 外推 n n n 步得到综合世界知识:
$$
\hat{p}{t+n} = \mathcal{P}(\mathbf{w}{t+n}) = [\hat{f}{t+n}, \hat{d}{t+n}, \hat{c}_{t+n}]
$$
其中 f ^ t + n \hat{f}_{t+n} f^t+n 标记动态区域, d ^ t + n \hat{d}_{t+n} d^t+n 编码单目深度, c ^ t + n \hat{c}_{t+n} c^t+n 存储高级语义特征。
三大核心模块
1. 综合世界知识预测
动态区域预测(Motion-centric Dynamic Region)
- 使用CoTracker提取动态区域(跟随机器人末端执行器或可移动物体运动的像素)
- 不预测密集光流,也不合成完整未来帧,只重建动态区域
- 采用非对称tokenizer(dVAE)增强性能
- 损失函数: L dyn \mathcal{L}_{\text{dyn}} Ldyn 基于ELBO的动态区域重构损失
关键设计选择:用光流生成的二值mask代替直接预测光流场。消融实验证明,预测光流场会增加训练复杂度并降低多步成功率,而动态区域方法只需关注"哪里会发生相关运动"。
深度预测(Depth Prediction)
- 使用Depth-Anything生成伪真值深度标签(无深度传感器时)
- 尺度归一化的均方误差损失,消除单目方法的尺度模糊性
- L depth \mathcal{L}_{\text{depth}} Ldepth 保留有序深度关系,对抓取合成和碰撞检测至关重要
对比语义预测(Contrastive Semantic Forecasting)
- 预测未来DINOv2和SAM特征
- 使用InfoNCE损失:正确未来特征为正样本,空间偏移特征为负样本
- 鼓励模型在看似合理但错误的未来中辨别出正确的物体语义
2. 块状结构化注意力机制
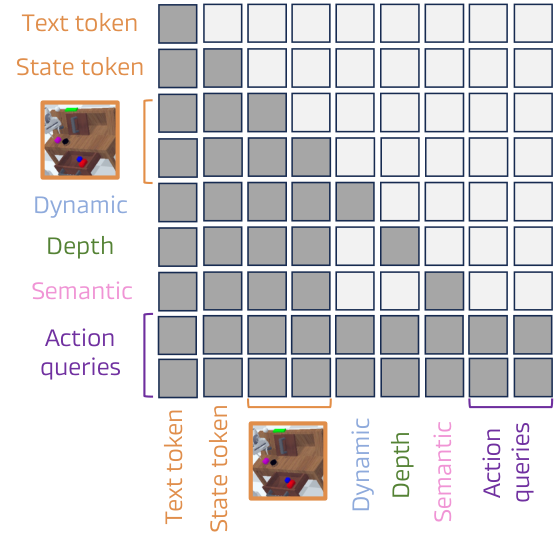
核心问题:如果动态、深度、语义三个 <dream> 子查询可以自由地相互注意力,高频光流细节会污染深度推理,语义线索会渗入运动特征,产生噪声混合表示。
解决方案:屏蔽子查询间的相互注意力,每个子查询只关注共享的视觉、语言和状态token,直接链接被禁用。
注意力结构:
<dream>和<action>查询使用因果注意力(只关注过去上下文)<dream>的三个子查询之间完全屏蔽- 类似MoE中的专家路由机制,避免跨模态泄漏
3. 基于去噪扩散Transformer的逆动力学
由于世界嵌入和动作嵌入占据同一潜在空间且共享相似统计量,简单MLP头部无法解耦模态特定信息。因此采用DiT(Denoising Diffusion Transformer)作为动作头部:
- 条件化于动作嵌入,DiT通过迭代自注意力和去噪融合感知预测与控制先验
- 将高斯噪声转化为 n n n 步轨迹 a t : t + n − 1 a_{t:t+n-1} at:t+n−1
- 损失函数:标准DDPM去噪损失 L DiT \mathcal{L}_{\text{DiT}} LDiT
推理效率:推理时跳过世界知识解码器,模型输出世界嵌入而非像素级重建,仅增加3ms推理开销(3.4%),整体91ms即可运行(11Hz)。
模型架构细节
| 组件 | 配置 |
|---|---|
| 文本编码器 | CLIP ViT-B/32 |
| 视觉编码器 | MAE预训练ViT-B + Perceiver Resampler |
| 语言模型 | GPT-2 Medium (345M参数, 24层, 1024隐藏维度) |
| 动作解码器 | DiT-B |
<dream> 查询 |
27 tokens (动态9 + 深度9 + 语义9) |
| 动作维度 | 7维 (6维末端执行器位移 + 1维夹爪) |
| 预测窗口 | K=2 (3帧预测) |
| 扩散步数 | 10 |
| 训练GPU | 8x A800 |
| 批大小 | 64 |
训练策略
- 首先在CALVIN无语言分割 + DROID数据集上预训练(预测完整帧)
- 然后在目标数据集上使用综合世界知识预测目标微调
总损失: L = 0.1 ⋅ L dyn + 0.001 ⋅ L depth + 0.1 ⋅ L sem + 1 ⋅ L DiT \mathcal{L} = 0.1 \cdot \mathcal{L}_{\text{dyn}} + 0.001 \cdot \mathcal{L}_{\text{depth}} + 0.1 \cdot \mathcal{L}_{\text{sem}} + 1 \cdot \mathcal{L}_{\text{DiT}} L=0.1⋅Ldyn+0.001⋅Ldepth+0.1⋅Lsem+1⋅LDiT
深度损失权重极小(0.001),因为深度回归损失量级远大于其他损失。
实验结果
CALVIN ABC-D基准
| 方法 | 1步 | 2步 | 3步 | 4步 | 5步 | Avg. Len. |
|---|---|---|---|---|---|---|
| Roboflamingo | 82.4 | 61.9 | 46.6 | 33.1 | 23.5 | 2.47 |
| GR-1 | 85.4 | 71.2 | 59.6 | 49.7 | 40.1 | 3.06 |
| OpenVLA | 91.3 | 77.8 | 62.0 | 52.1 | 43.5 | 3.27 |
| UNIVLA | 95.5 | 85.8 | 75.4 | 66.9 | 56.5 | 3.80 |
| Pi0 | 93.8 | 85.0 | 76.7 | 68.1 | 59.9 | 3.92 |
| UP-VLA | 92.8 | 86.5 | 81.5 | 76.9 | 69.9 | 4.08 |
| Seer | 96.3 | 91.6 | 86.1 | 80.3 | 74.0 | 4.28 |
| VPP | 95.7 | 91.2 | 86.3 | 81.0 | 75.0 | 4.29 |
| DreamVLA | 98.2 | 94.6 | 89.5 | 83.4 | 78.1 | 4.44 |
DreamVLA在CALVIN ABC-D上达到SOTA,平均长度4.44,相比Seer/VPP提升约3.5%。

LIBERO基准
| 方法 | Spatial | Object | Goal | Long | Average |
|---|---|---|---|---|---|
| Diffusion Policy | 78.3 | 92.5 | 68.3 | 50.5 | 72.4 |
| OpenVLA | 84.7 | 88.4 | 79.2 | 53.7 | 76.5 |
| CoT-VLA | 81.1 | 87.5 | 91.6 | 87.6 | 69.0 |
| DreamVLA | 97.5 | 94.0 | 89.5 | 89.5 | 92.6 |
LIBERO上平均92.6%,大幅领先。值得注意的是Goal维度略低于CoT-VLA(89.5 vs 91.6)。
真实世界实验
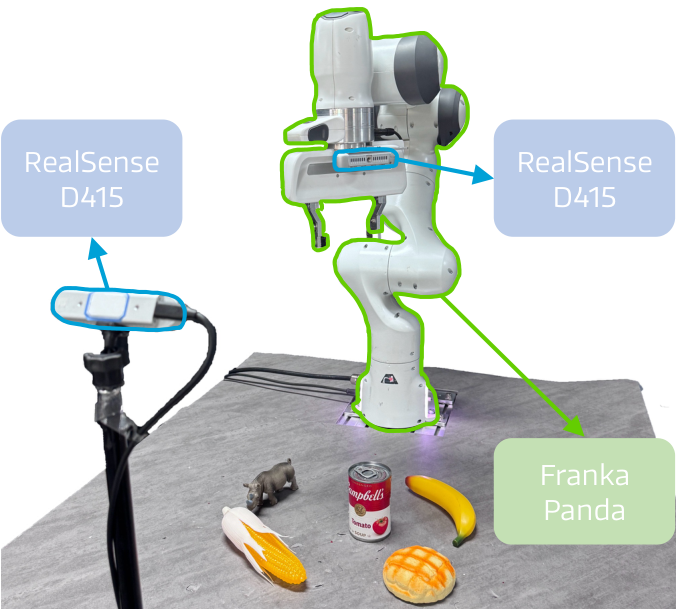
| 方法 | Pick(Avg) | Place(Avg) | Drawer(Avg) | Task Avg |
|---|---|---|---|---|
| Diffusion Policy | 60.0 | 55.0 | 37.5 | 50.8 |
| Octo-Base | 55.0 | 45.0 | 35.0 | 45.0 |
| OpenVLA | 45.0 | 25.0 | 35.0 | 35.0 |
| DreamVLA | 82.5 | 80.0 | 67.5 | 76.7 |
真实世界成功率76.7%,远超Diffusion Policy的50.8%和OpenVLA的35.0%。

消融实验
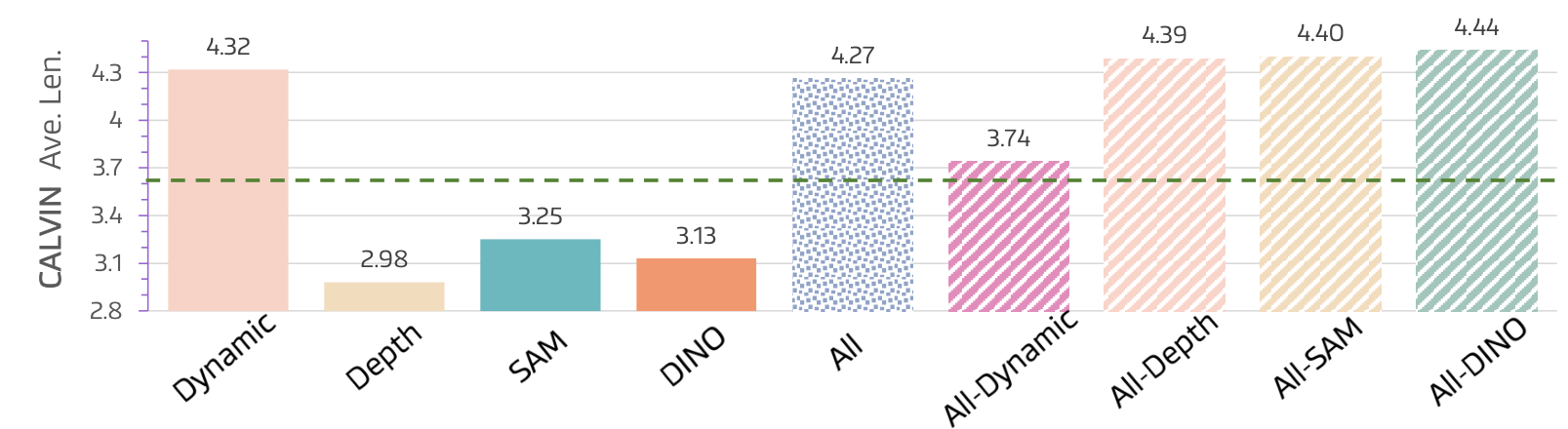
各知识模态的渐进贡献:
| 配置 | Avg. Len. |
|---|---|
| Vanilla VLA | 3.64 |
| + 动态区域 | 4.32 (+0.68) |
| + 深度 | 4.40 (+0.08) |
| + 语义 | 4.44 (+0.04) |
关键发现:
- 动态区域贡献最大(+0.68),因为动态mask显式标记即将变化的像素,与动作语义高度对齐
- 深度或语义单独使用反而会降低性能,因为它们引入大量噪声损失,在有限的注意力预算下稀释了任务相关特征
- 三者结合才能发挥最大效果,呈现递减收益模式
预测 vs 辅助重建:
| 方式 | Avg. Len. |
|---|---|
| 辅助重建 | 4.14 |
| 未来预测 | 4.44 |
预测性任务比辅助重建显著更优。重建仅回访背景细节,而预测提供了动作导向的信号。
光流 vs 动态区域:
| 方式 | Avg. Len. |
|---|---|
| 预测光流 | 4.23 |
| 动态区域 | 4.44 |
动态区域更简洁有效,避免预测完整光流场的训练复杂度。
结构化注意力 vs 因果注意力:
| 方式 | Avg. Len. |
|---|---|
| Vanilla因果 | 3.75 |
| 块状结构化 | 4.44 |
结构化注意力显著提升性能,确认阻隔子查询间泄漏的重要性。
共享查询 vs 分离查询:
| 方式 | Avg. Len. |
|---|---|
| 共享查询 | 4.17 |
| 分离查询 | 4.44 |
为每个模态分配独立查询保持表示解耦,效果更好。
查询数量影响:
| K值 | Avg. Len. |
|---|---|
| 4 | 4.32 |
| 9 | 4.44 |
| 16 | 4.33 |
K=9最优,K=4容量不足,K=16冗余token竞争注意力。
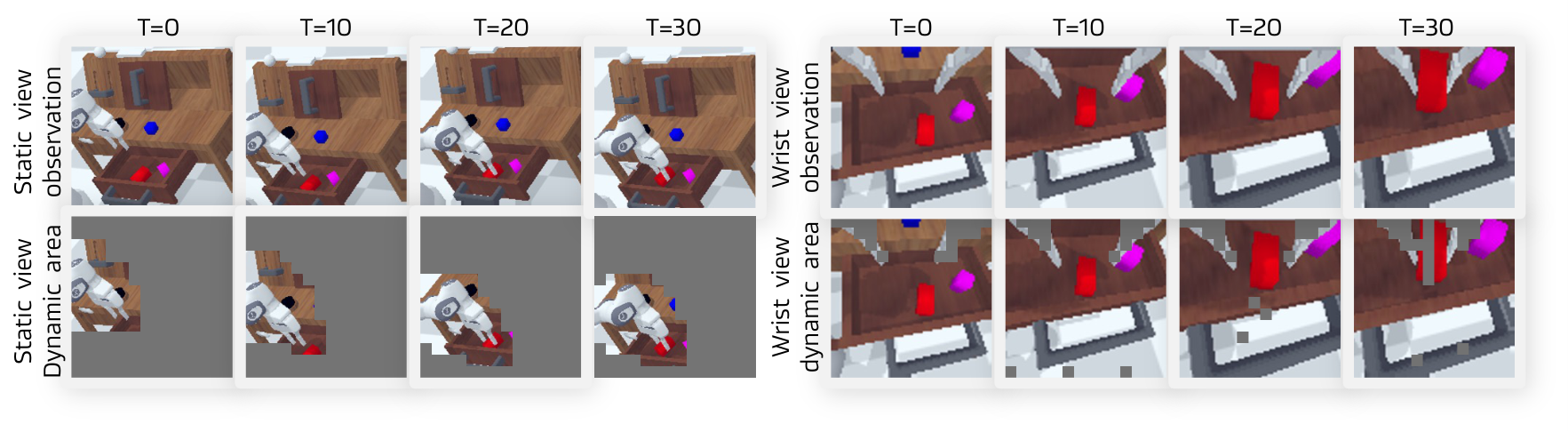
可视化分析


有趣发现:虽然监督仅应用于动态区域,DreamVLA仍能重建语义上有意义的完整场景表示。这归因于:
- 在长时序操作中,机器人手臂持续运动,大部分任务相关区域在某个时刻都变为动态的
- 输入帧包含全局视觉上下文,模型可利用其补全缺失细节
深度分析
核心创新点深度解读
1. 从"预测像素"到"预测知识"的范式转变
DreamVLA最深刻的贡献不是某个技术模块,而是概念上的重新定义:将VLA从"观测到动作的映射"转变为"感知-预测-行动"循环。这类似于认知科学中的前瞻性推理——人类执行动作前,脑海中形成的是对变化的抽象预期(“杯子会被推到这里”),而非完整的视觉画面。
2. 动态区域作为核心预测目标的设计哲学
选择动态区域而非完整光流场或未来帧,体现了"最小充分表示"的设计哲学。动态区域是连接感知和动作的关键桥梁:
- 它告诉模型"哪些区域即将变化"(与动作最相关的信息)
- 它避免了完整帧重建的冗余
- 二值mask的预测比密集光流更简单更稳定
3. 块状结构化注意力的理论动机
结构化注意力的设计源于一个深层问题:在多任务学习中,不同目标的梯度可能冲突。如果动态、深度、语义查询互相可见,高频的动态信息会主导梯度更新,抑制语义特征的精细学习。块状结构化注意力实质上是一种梯度隔离机制——每个子查询的梯度只通过共享的视觉/语言/状态token反传,确保各表示独立优化。
潜在局限与隐忧
-
GPT-2 Medium作为骨干的限制:345M参数的GPT-2在语言理解和推理能力上远不如现代LLM(如LLaMA-2/3),这限制了模型处理复杂语言指令的能力。论文也提到了探索更大语言模型的计划。
-
两阶段训练策略的必要性:先预训练预测完整帧,再微调预测世界知识。这种策略暗示直接从世界知识预测开始训练可能不稳定,增加了工程复杂度。
-
深度和语义单独使用时的负面效果:深度和语义预测单独使用会降低性能,这暴露了一个根本性张力——这些知识虽然对最终性能有帮助,但其梯度信号与动作目标存在冲突。论文通过权重调节缓解了这个问题,但并未从根本上解决。
-
真实世界实验规模有限:仅3类任务(Pick/Place/Drawer),每任务100条演示,与真实世界部署的多样性要求差距较大。
-
推理延迟:91ms的延迟中60ms来自动作头,在需要高频控制的场景下可能不够。10步扩散去噪是主要瓶颈。
训练效率分析
- 预计算SAM/DINOv2/Depth-Anything特征而非在线推理,节省训练时间和GPU显存
- 推理时跳过世界知识解码器,仅3ms额外开销
- 损失权重设计精细:深度损失权重0.001,远小于其他损失,反映其量级差异
- 8卡A800训练,batch size 64
与相关论文对比
| 对比维度 | DreamVLA | Seer | UP-VLA | VPP | 3D-VLA |
|---|---|---|---|---|---|
| 预测目标 | 动态区域+深度+语义 | 完整子目标图像 | 子目标图像 | 视频预测 | 3D未来状态 |
| 预测粒度 | 紧凑知识表示 | 像素级 | 像素级 | 像素级 | 3D点云 |
| 信息冗余 | 低 | 高 | 高 | 高 | 中 |
| 空间感知 | 有(深度预测) | 无 | 无 | 无 | 有(3D) |
| 语义推理 | 有(DINOv2/SAM) | 隐式 | 隐式 | 隐式 | 隐式 |
| 信息泄漏防护 | 块状结构化注意力 | 无 | 无 | 无 | 无 |
| 动作生成 | DiT扩散 | MLP | 扩散 | 扩散 | 扩散 |
| CALVIN Avg.Len. | 4.44 | 4.28 | 4.08 | 4.29 | – |
| 推理额外开销 | 3ms | 较大 | 较大 | 较大 | 中等 |
DreamVLA相对Seer/UP-VLA/VPP的核心优势在于:不预测冗余的像素级未来帧,而是预测紧凑的世界知识表示,同时通过结构化注意力保持表示的纯净性。
技术路线定位
DreamVLA在VLA发展脉络中的定位:
直接映射VLA (RT-2, OpenVLA)
|
v
加入未来预测
|-- 副驾驶生成 (Susie, CLOVER) -- 两阶段,额外模型
|-- 联合像素预测 (Seer, UP-VLA, VPP) -- 端到端但冗余
|
v
联合知识预测 (DreamVLA) -- 端到端 + 紧凑 + 全面
DreamVLA代表了VLA模型从"预测像素"到"预测知识"的关键转变,这可能会成为后续工作的重要方向。
未来工作建议
基于论文内容和消融实验发现的局限,建议以下研究方向:
-
扩大骨干规模:将GPT-2 Medium替换为更大的语言模型(LLaMA-2/3),评估语言理解能力对世界知识预测质量的影响
-
解决深度/语义单独使用时的梯度冲突:探索梯度调和策略(如PCGrad、GradNorm),使深度和语义预测能在不损害动作性能的前提下独立贡献
-
引入3D点云表示:结合点云或体素表示替代单目深度图,提供更丰富的3D空间信息
-
灵巧手操作扩展:从平行夹爪扩展到灵巧手操作,引入触觉信息
-
扩散步数优化:10步扩散去噪是延迟瓶颈,探索一致性模型或流匹配减少推理步数
-
层次化预测:当前预测窗口仅为2步,探索层次化预测架构处理更长的时序依赖
-
自适应查询数量:根据任务复杂度动态调整dream查询数量,简单任务减少开销
-
端到端世界知识预测训练:消除两阶段训练的必要性,研究从零开始训练世界知识预测的稳定策略
综合评价
优势
- 概念创新性强:将VLA重新定义为感知-预测-行动循环,从"预测像素"到"预测知识"的范式转变具有启发性
- 设计哲学清晰:动态区域+深度+语义的三维世界知识表示,符合人类认知中的前瞻性推理
- 工程实现精致:块状结构化注意力、分离查询、预计算特征等细节处理体现工程深度
- 实验全面:CALVIN/LIBERO/真实世界三重验证,消融实验覆盖6个研究问题
- 推理高效:仅3ms额外开销,11Hz实时运行
不足
- 骨干模型偏小:GPT-2 Medium限制了语言理解深度
- 深度/语义单独无效:暴露了多任务梯度冲突的根本问题,未完全解决
- 真实世界实验规模有限:仅3类任务,泛化性有待验证
- 两阶段训练增加工程复杂度:不够优雅
评分:8/10
DreamVLA在概念层面提出了一个重要的范式转变——从像素预测到知识预测,这一洞察对VLA领域的发展具有方向性指导意义。技术实现上,块状结构化注意力和动态区域预测是两个亮点设计。实验充分,在CALVIN上达到SOTA。主要扣分点在于:骨干模型能力限制、深度/语义预测的梯度冲突问题未根本解决、真实世界实验覆盖面偏窄。整体而言,这是一篇高质量的VLA论文,其核心思想"预测什么比预测像素更重要"很可能影响后续VLA模型的设计方向。
📝 本文为论文深度解读笔记,基于对原论文的系统性分析和思考撰写。
🏷️ 相关标签:VLA world-model diffusion-policy inverse-dynamics robot-manipulation dream-prediction structured-attention CALVIN LIBERO
💬 欢迎在评论区讨论交流!如果觉得有帮助,请点赞收藏~

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 0
0 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)