Xanylabeling標註軟件研究
背景說明
在做一個具體的行為識別項目的時候,因為後期要根據上線測試反饋不斷去優化模型,采集了一些補充視頻數據,需要更新數據集。我現在的數據集有點大,我想使用半自動化標註,最好是支持多類的,假如我新采集的圖片中有三類需要補充標註(實際我要實現的是12類,但是打算先標註後再去寫程序批處理那個標註文件),比如我標註完第一張,然後一下就能給我完成剩下100張左右圖片的標註,請問有什麼辦法可以實現,我可以等標註完之後我再微調,我知道有sam2工具,但是那個每次只能實現一個類別的標註,對於多類的標註,實現起來就比較費勁了,如何實現多個類別的標註呢 ?
問題分析
經過自己上網不斷查資料分析發現 SAM 2 (Segment Anything Model 2) 確實是目前的核彈級工具,而且我發現:SAM 2 其實是完美支持「多類別、多目標」同時追蹤標註的,但是,回到自己的需求「標註第一張,自動完成剩下 100 張多類別類似圖片的標註」的終極需求,在工業界我們通常不會只靠單一工具,而是使用 「AI 輔助標註 (AI-Assisted Labeling)」 或 「主動學習 (Active Learning)」 的工作流。
常見的有3 個最有效、支持多類別的半自動化標註方案,從開箱即用的軟體到自己寫腳本都有:
🥇 方案一:使用神級開源工具 X-AnyLabeling (最推薦!)
如果熟悉本地開發,推薦立刻放棄老舊的 LabelImg,改用 X-AnyLabeling。這是一款整合了目前地表最強 AI 模型(包含 SAM 2、YOLOv8、YOLOv10)的現代化標註軟體。
-
如何解決多類別問題: X-AnyLabeling 內建了強大的 AI 引擎。你可以載入一個基礎的 YOLO 模型或 SAM 2。
-
SAM 2 多目標追蹤模式: 如果你把這 100 張圖片當作「一個連續的影片幀(Sequence)」載入,你只需要在「第 1 張圖」對著黑泡棉點一下(設為 Class A)、對著白泡棉點一下(設為 Class B)、對著天線點一下(設為 Class C)。然後按下 「開始追蹤 (Track)」,SAM 2 就會自動幫你把剩下 99 張圖裡面的這三個類別全部標註好,連多邊形 Mask 和 Bounding Box 都一次搞定!你只需要在幾張圖微調就好。
🥈 方案二:大廠標準工作流「自己的模型自己標」 (Active Learning Loop)
如果你的場景比較特殊(例如前面提到的左邊/右邊黑泡棉干擾),通用的 SAM 模型可能會抓錯。這時候最工業級的做法是「用魔法打敗魔法」:
-
手動爆肝期 (20% 數據): 你先咬牙手動標註 20~30 張包含這三個類別的圖片。
-
訓練「迷你模型」: 拿這 30 張圖,丟進你現在寫好的 YOLO 腳本裡,跑個短短的 50 個 Epoch(用最輕量的模型,例如 YOLOv8n,大概只要訓練 5 分鐘)。
-
AI 幫你標 (80% 數據): 寫一段簡單的 Python 腳本,用這個剛訓練好的「半成品模型」,去推論剩下的 100 張圖,並把結果輸出成 YOLO 格式的
.txt檔案。 -
人工驗收微調: 把這 100 張圖和 AI 生成的
.txt丟回標註軟體打開。你會發現框都已經畫好、類別也分好了(3 種類別都有),你只需要微調那些 AI 沒對準的框,速度至少提升 5 倍!
🥉 方案三:雲端 SaaS 平台 (如 Roboflow 或 CVAT)
如果你不想在本地搞這些環境設定,你可以把圖片上傳到 Roboflow 或 CVAT。
-
Roboflow: 它們有內建的 Label Assist 功能。你標完一個批次,點擊「訓練模型」,它就會在雲端幫你訓練,然後你點擊「Auto-Label」,剩下的圖片就會瞬間被標註上多個類別。
-
CVAT: 這是 Intel 開源的老牌標註工具,完美支援多類別 AI 輔助標註,可以串接你自己的模型當作後端。
👨💻 附贈:方案二的「AI 自動標註」代碼片段
因為你已經寫了很棒的後台推理程式了,如果你選擇 方案二,這裡送你一段腳本概念。只要幾行程式碼,就能讓 YOLO 把預測結果轉成標註檔:
from ultralytics import YOLO
import os
# 1. 載入你剛用 30 張圖訓練出來的「半成品」模型
model = YOLO('runs/detect/train/weights/best.pt')
# 2. 指定未標註圖片的資料夾
unlabeled_dir = 'path/to/your/100_images/'
# 3. 執行推論,神奇的參數 save_txt=True 登場!
# 它會自動把預測到的 多類別 Bounding Box 存成標註軟體能讀取的 .txt 檔
results = model.predict(
source=unlabeled_dir,
conf=0.3, # 信心度設低一點,寧可多標也不要漏標
save_txt=True, # 儲存 YOLO 格式的標註檔
save_conf=False, # 標註檔不需要信心度分數
device=0
)
print("🎉 自動標註完成!請用標註軟體打開微調!")總結建議: 如果你想要體驗最極致、最偷懶的標註感,請去 GitHub 搜尋下載 X-AnyLabeling,直接體驗它的 SAM 2 批量追蹤功能。如果你追求絕對的領域準確度,請使用我給你的 「迷你模型 + save_txt=True」 代碼流,這會讓你未來的標註工作輕鬆無比!
資源分享
不同版本的打包軟體下載鏈接如下:
https://github.com/CVHub520/X-AnyLabeling/releases界面如圖:
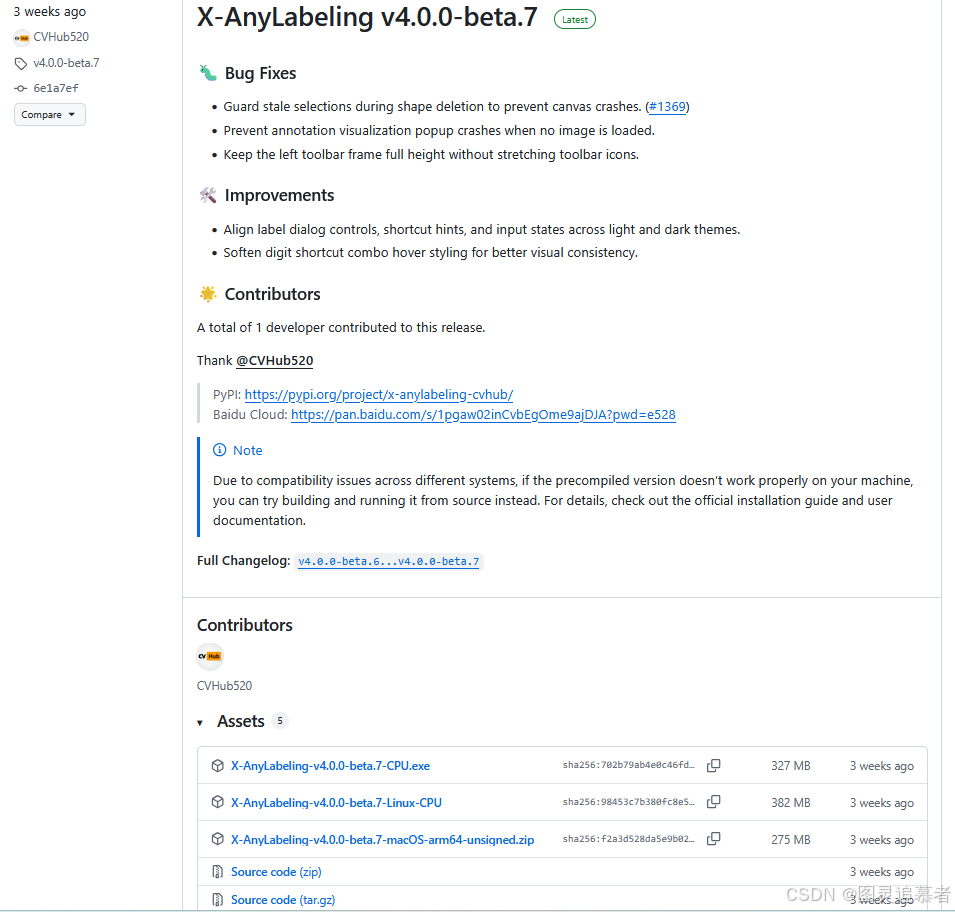
模型倉庫鏈接如下:
https://github.com/CVHub520/X-AnyLabeling/blob/main/docs/zh_cn/model_zoo.md界面如圖:
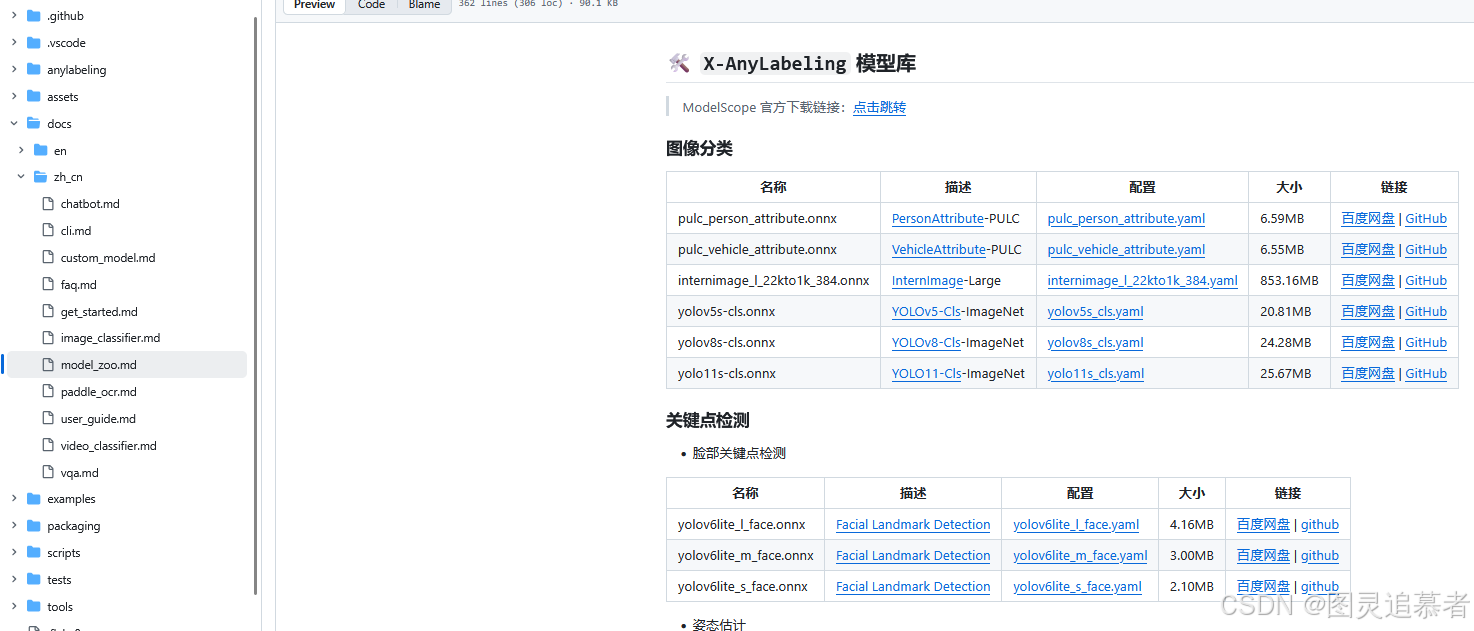
在線模型名稱參考鏈接:
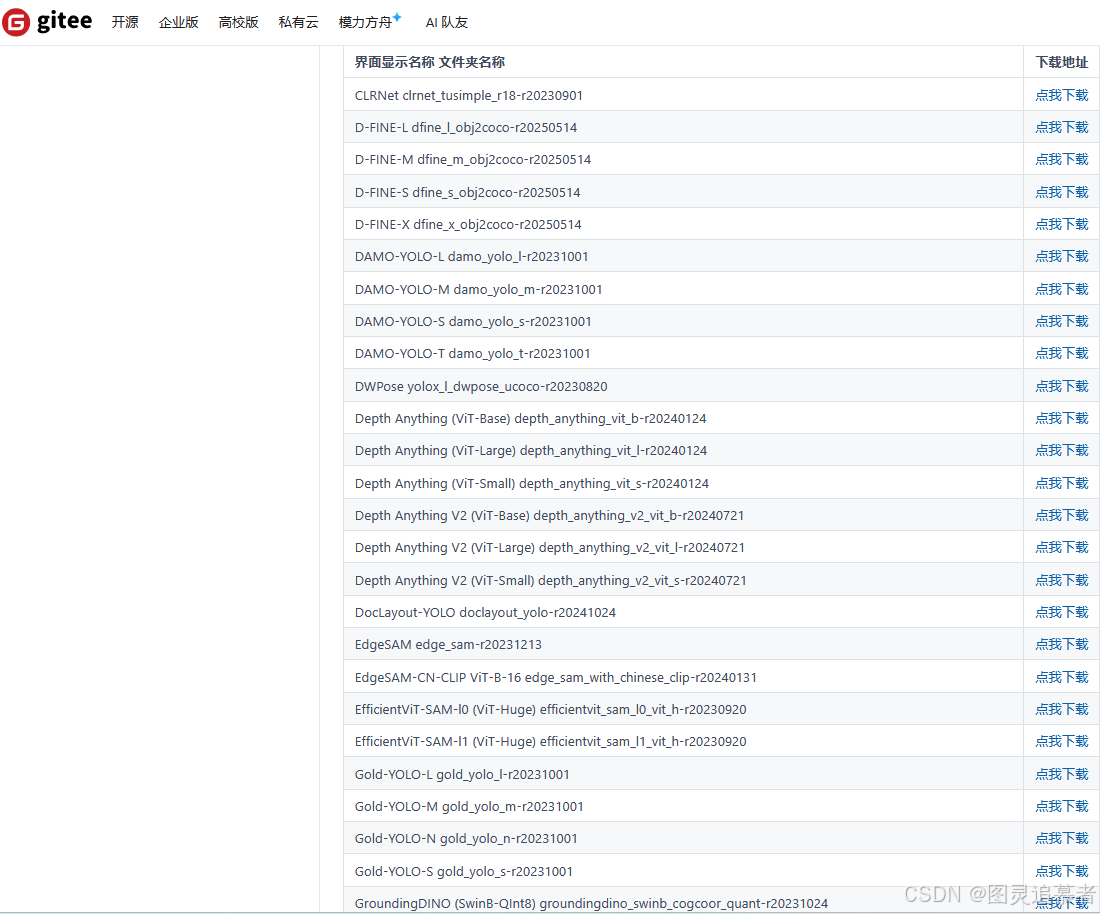
https://gitee.com/FIRC/xanylabeling_data_cn_mirror網址如下(遺憾的是,這個是收費的,但是可以告訴我們每個模型的名字叫啥):

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 7
7 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)