【Agent Loop|基座】从单代理到自我进化系统的14步路线
🌈个人主页:一条泥憨鱼(欢迎各位大佬莅临)
![]()
前言:
所有人都在谈循环。没人谈循环跑在什么东西上面。
十个开发者有九个用 Claude Code 连默认设置都没改过——没有规则文件,没有子代理,没有钩子,没有记忆。然后他们想不通为什么循环产出的全是垃圾。
真相很简单:循环的上限,是它脚下那个基座决定的。
这是搭基座的 14 步路线图。从一个光杆代理开始,最后变成一套会自我进化的系统。
循环工程火了,但基座没人提
"循环工程"这个月吸引了所有目光——搭一个定时唤醒代理的系统,让它自己跑。Addy Osmani 在那篇长文里特意指出了下面那一层:
循环比基座高一层。基座是一个代理单次运行的环境。循环就是基座加了定时器、会自己衍生帮手、会自己给自己喂料。
基座工程就是设计这个环境。模型、工具、权限、上下文、记忆。
它是最不起眼的那一层,偏偏决定上层一切能不能跑通。一个精妙的循环架在烂基座上,唯一的本事就是把垃圾大规模量产。

第一部分:基座是什么
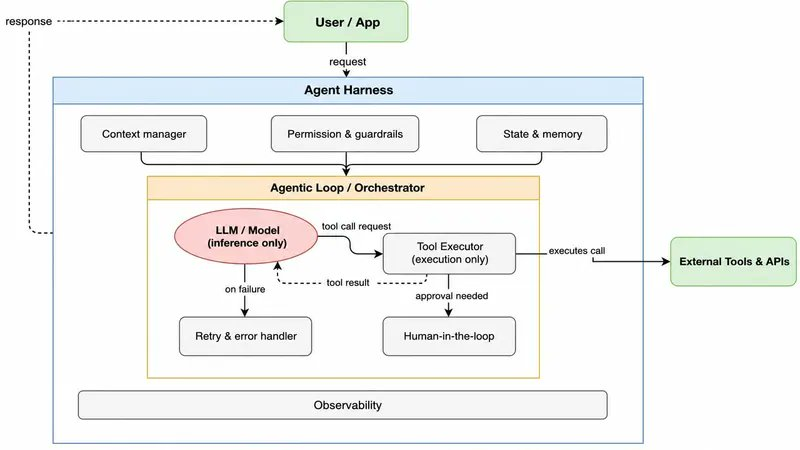
01. 基座就是一个代理运行的环境
剥掉术语,基座就四样东西:干活的模型、能调用的工具、工具上的权限、每次启动时读取的上下文。
就这些。其余一切——子代理、钩子、记忆——都是对这四样东西的塑形。
02. 同一个模型,不同基座,两个代理
基座定义了有哪些工具、代理能做什么、启动时知道什么。同一个模型塞进不同的基座,出来的是两个完全不同的代理。
所有塑造你代理的东西,都躺在项目根目录的一个文件夹里。记住下面这个结构,你就能一眼看懂任何人的基座:
.claude/
├── CLAUDE.md # 上下文(每次会话都读)
├── settings.json # 权限和模型配置
├── agents/ # 子代理定义
├── skills/ # 可复用技能
├── hooks/ # 强制执行钩子
└── agent-memory/ # 持久状态03. 好基座的分界线
一条规则:保持足够精简,让你能说清楚每个文件为什么存在。解释不了的东西,删掉。
大多数"配置一团糟"的问题,都源于把三层搞混了:
- 常量放上下文
- 强制规则放钩子
- 操作流程放技能
- 隔离任务放子代理
把强制规则塞进 CLAUDE.md,或者让操作流程把上下文撑爆——这就是代理行为不稳定、成本居高不下的根。
04. 默认基座是个空壳
装上 Claude Code,打开一个文件夹,你已经有一个基座了。只不过是个空壳。
默认配置给了你一个能打的模型、内置工具(读、写、bash、搜索),所有有风险的操作都要手动确认。没有项目上下文,没有自定义子代理,没有记忆。
一次性任务够用了。但任何你要反复做的事,代理每次会话都从头推导你的项目,安全操作也要你点头,终端一关它就忘光。
接下来十步,就是来补这个窟窿的。
第二部分:打造基座
05. CLAUDE.md:代理的常驻记忆
CLAUDE.md 在每次会话开始时被读取。它是代理对你项目的认知——规范、架构、那些"为什么不这样做,因为出过那档子事"。
最常见的错误:让它膨胀成巨型流程文档,每次会话拖着一大坨上下文。
每天跑这套东西的人有个共识:主记忆文件控制在 500 token 以内。固定事实放这里。
多步骤流程放技能(第 8 步)。特定路径的行为放 rules/,限定生效范围。如果 CLAUDE.md 里某个段落已经从"事实"变成了"流程",它该搬家了。
把你的 CLAUDE.md 念出声来。每行应该是一个代理每次会话都需要知道的事实(比如"我们用 pnpm,不是 npm")。如果某一行是流程("加功能的话,先……"),挪到技能里。如果是针对某个文件夹的规则,挪到 rules/。
06. settings.json:权限与型号
默认基座每次有风险的操作都问你。你人在旁边盯着的时候挺好,人不在就坏事了。settings.json 让你把安全操作预先放行、危险操作直接拦住、顺便选好跑哪个模型。
判断什么该自动放行:这事搞砸了,回滚有多难?回滚成本低就自动放行。回滚成本高(强制推送、删文件、碰密钥)就永远拒绝,至少弹窗确认。中间地带可以在有日志记录的前提下自动放行。
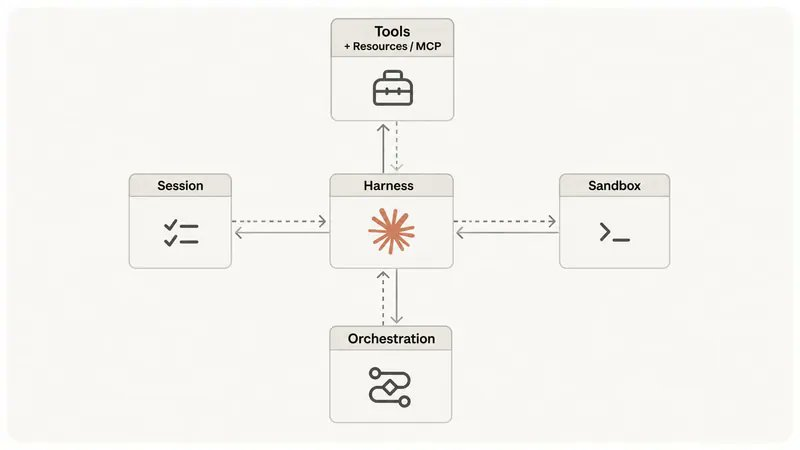
07. 子代理:隔离噪音,保护主上下文
子代理是从主会话启动的独立 Claude 会话——有自己的上下文窗口,自己的工具列表。它的意义不是并行,是把噪音挡在主上下文外面。
一个要读 40 个文件的研究任务、一个需要全新视角的审查、一个产生满屏日志的评估——都该丢给子代理,别污染主线程。
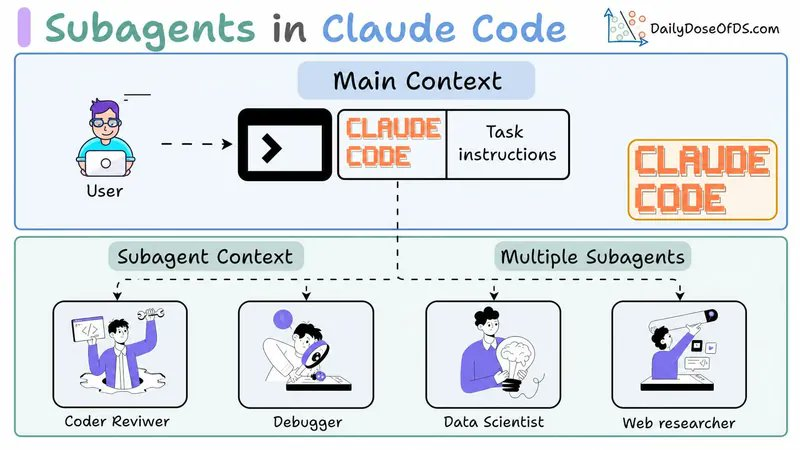
任何基座里最有价值的子代理,是那个检查主代理干活质量的。一个模型审查自己的输出对自己太宽容了。一个带着全新上下文窗口的独立审查者,能逮住写的人自我说服的那些盲区。这就是写手与审查者的分工——让基座之上每一个循环都值得信赖。
08. 技能:可复用的指令单元
一个技能就是一个 SKILL.md 文件。你可以用 /skill-name 手动调用,也可以让它在任务匹配描述时自动触发。

和子代理不同,技能跑在同一个上下文窗口里。它只是一组可复用的指令,成为当前会话的一部分。
什么时候该建一个技能:当你发现自己每次开新对话都在粘贴同一段指令。那就是一个技能在等你。PR 检查清单、评估流程、发布流程——写一次,永远调用。
技能是基座随时间进化的关键:每次流程以新方式失败,把教训加到技能里,下一次运行自动继承。
09. 钩子:强制执行
前面所有东西都依赖模型理解你的指令。钩子不依赖。
钩子是一个 shell 命令,在代理生命周期固定节点触发——工具调用前、文件变更后、会话结束时——它的退出码可以直接拦截操作。钩子是强制执行,CLAUDE.md 只是建议。
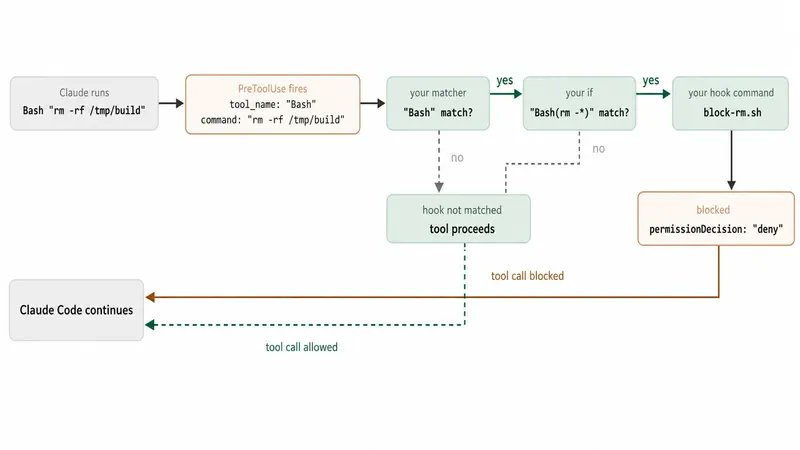
几乎每个基座都该有两个钩子。一个用来拦截不该发生的事(安全、格式化、审计日志)。不要用钩子做判断型决策,那是模型该干的。好基座有一两个锋利的钩子,不是二十个。
10. 循环:让基座自己运转
一个配置好的基座还是在等你敲键盘。循环让它自己转起来。
最简单的版本就是 Claude Code 的 /loop——一个按节奏重复执行的 prompt。搭配 /goal,循环会一直跑到客观条件满足为止,而且由独立的评分者判断,不是代理自己给自己打分。
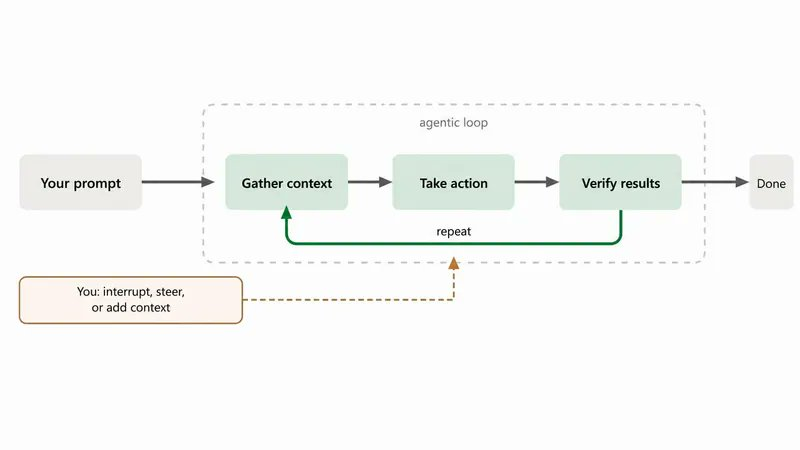
注意刚才发生了什么:循环没有凭空增添智能。它复用了基座里的一切——规则、审查子代理、安全钩子。好基座让循环变得微不足道。这就是先打地基的全部意义。
11. 动态工作流:编排子代理与技能
单循环搞不定的任务——高度并行、高度结构化、需要对抗性验证——Claude 可以即时写 JavaScript 编排。
这就是动态工作流:agent() 衍生子代理,parallel() 扇出,pipeline() 流水线。它把基座里定义的子代理组合成各种模式。
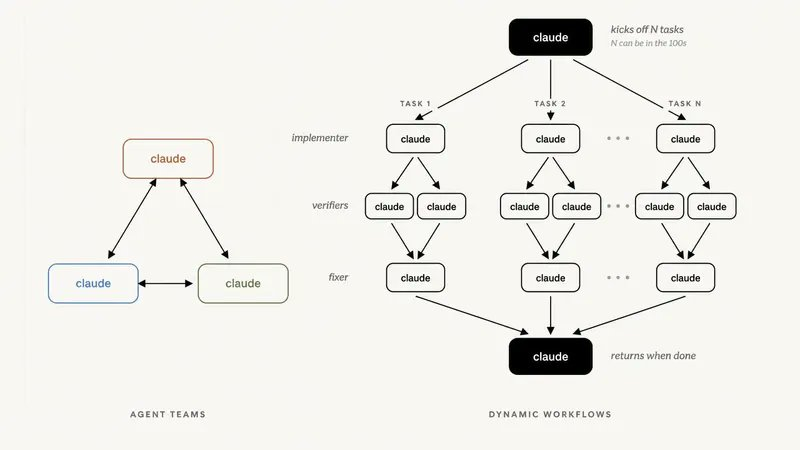
上限取决于它能调用的子代理和技能的质量。基座里有一个锋利的审查子代理和一个好用的评估技能,工作流就有零件可编排。基座是空的,工作流就无米下锅。
工作流是指挥,基座是乐团。
第三部分:自我进化
12. 状态文件:基座不用忘
这一步,把配置好的基座变成真正会进化的系统。
代理每次运行之间忘得一干二净。基座不用忘。
一个状态文件——agent-memory/ 里的 markdown 文件,或者一个 Linear 看板——记录了什么被尝试过、什么管用、什么翻车了、什么规则经受住了考验。
13. 自我进化回路
到了这一步,三层终于卡在一起,变成能自我进化的东西。
每次运行产生输出。审查子代理(第 7 步)检查它。结果——哪些过了、哪些挂了、学到了什么——写入记忆(第 12 步)。通用的教训提炼成技能(第 8 步)。下一次运行继承更锋利的技能和更丰富的记忆。
模型始终没变。它周围的基座越来越锋利。这就是"自我进化"的诚实含义——不是模型在学习,是基座在累积。
14. 打包成插件:从个人配置到共享基础设施
一个项目上跑通的基座是一笔资产。把技能、子代理和规则打包成插件,整个团队一步安装同样的配置——同样的规范、同样的安全钩子、同样的审查者。
好基座上的循环会滚雪球。烂基座上的循环只是加速失血。
总结
循环享受聚光灯,基座在幕后干活。但循环不过是加了个定时器的基座。决定产出是精品还是垃圾的一切都在下面那一层:你选的模型、你放行的工具、你写的上下文、你加的审查者、你留存的记忆。把这一层造好,上面的一切都跟着滚雪球。
自我进化从来不是模型本身的属性。它是你在模型周围搭建的东西的属性。
今天就从你还没做的里面挑一样——大概率是审查子代理、安全钩子或状态文件——加上去。保持精简到你能解释清楚每一个文件为什么存在。然后套一个循环,看地基替你干活。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 14
14 0
0- 0



 已为社区贡献18条内容
已为社区贡献18条内容

所有评论(0)