大模型SFT监督微调完全解析:原理、数据集、训练流程、实战调优、避坑指南
前言
很多人疑惑:
开源大模型(Llama、Qwen、ChatGLM)原生已经具备海量知识,为什么还要额外做微调?
答案很简单:
预训练大模型,只会“被动识字”;SFT微调后的模型,才会“主动干活”。
预训练让模型学习全网通用知识、语法、语义;
SFT(监督微调)是大模型落地的第一道工序,也是所有企业定制模型、行业模型、对话模型的必经之路。
不管是后续的RLHF人类对齐、Agent智能体、行业私有化模型,全部依赖高质量SFT底座。
今天一文吃透SFT核心原理、工业级训练流程、数据集规范、参数调优、实战避坑,帮你彻底搞懂大模型落地最核心的基础技术。
一、什么是SFT(监督微调)
1. 官方定义
SFT(Supervised Fine-Tuning)监督微调:
基于预训练底座大模型,使用高质量人工标注指令数据集,以有监督学习的方式,让模型学习「用户指令 → 标准回答」的映射关系。
2. 通俗理解
• 预训练:让模型读完全网书籍,拥有通识知识;
• SFT微调:手把手教模型怎么听懂指令、怎么正确回答、怎么遵守格式。
预训练 = 有知识的学生
SFT微调 = 训练成会做题、懂规矩的员工
二、为什么必须做SFT?原生模型有什么缺陷?
原生开源预训练模型直接上线,会出现大量问题:
1. 无法精准跟随指令,经常答非所问、缺题漏答;
2. 回答句式混乱、格式不统一、忽长忽短;
3. 不会多轮对话,上下文衔接极差;
4. 不懂行业话术、不懂业务规范;
5. 容易续写文本,而不是回答问题。
SFT的核心目标只有三个:
• 学会理解用户意图
• 学会标准输出格式
• 学会稳定完成任务
SFT 不追求提升知识量,只提升任务执行能力。
三、预训练、SFT、RLHF 三者层级关系(核心重点)
大模型工业级训练三板斧,顺序绝对不能乱:
1. 预训练 Pretrain
海量无标注数据,习得知识、语言、逻辑
解决:看得懂、有知识
2. SFT 监督微调(必经阶段)
指令标注数据,习得指令跟随、任务能力、输出规范
解决:听得懂、会干活
3. RLHF 人类反馈强化学习(进阶对齐)
人类偏好排序,习得优质审美、安全合规、自然对话
解决:答得好、听话、三观正
总结一句话:
没有SFT的RLHF毫无意义,SFT是大模型一切能力的地基。
四、SFT 标准工业级训练全流程
一套可直接落地的企业级SFT流程,分为6步:
1. 场景需求定位
明确模型微调方向:
• 通用对话、企业话术、行业问答、文案写作、代码能力、结构化输出
2. 高质量数据集构建(70%效果取决于这里)
标准SFT数据格式:
instruction指令 + input上下文 + output标准答案
数据类型:
• 单轮问答
• 多轮对话
• 任务指令(总结、改写、翻译、分析)
• 行业专属问答
3. 数据清洗与去重
剔除:重复数据、错误数据、歧义数据、脏数据、违规数据。
劣质数据 = 模型退化、逻辑错乱、答非所问
4. 模型训练(主流LoRA微调)
企业现在100%使用 LoRA-SFT
• 冻结底座模型
• 仅训练低秩矩阵
• 低成本、不污染原模型、可随时插拔
5. 训练监控
监控训练集Loss、验证集Loss:
• 双Loss平稳下降:训练正常
• 训练Loss降、验证Loss升:过拟合,立即停止
6. 模型合并与效果测评
合并LoRA权重,多维度测试:
指令跟随、格式稳定性、业务准确率、对话流畅度
五、SFT 黄金数据集标准(实战干货)
1. 数据数量
• 通用风格微调:500~2000条
• 垂直行业微调:5000~20000条
• 复杂任务(代码/结构化输出):2W+
2. 数据质量四大原则
1. 指令清晰无歧义
2. 答案标准、唯一、规范
3. 句式风格统一
4. 样本多样性充足,避免单一模板
3. 数据配比
• 通用能力 30%
• 行业专项能力 70%
六、SFT 核心超参数调优(企业通用参数)
适合所有主流模型:Qwen、Llama、ChatGLM、InternLM
1. 学习率 lr:1e-4 ~ 2e-4
过大发散,过小收敛太慢
2. Epoch:3~5轮
超过8轮大概率过拟合
3. BatchSize:4/8/16
根据显存自适应
4. LoRA Rank:16/32
行业最优性价比
5. 上下文长度:2048/4096
七、SFT 实战高频踩坑 & 解决方案
坑1:训练后模型只会套模板,死板僵硬
原因:数据单一、模板化严重
解决:增加多样化真实场景数据
坑2:微调后通用能力下降
原因:过拟合、行业数据占比过高
解决:降低Epoch、增加通用数据、早停机制
坑3:回答残缺、截断严重
原因:max_length设置过小
解决:提升上下文长度、优化数据截断策略
坑4:训练Loss不下降、不收敛
原因:学习率异常、数据格式错误
解决:核对JSON格式、重置学习率
坑5:多轮对话混乱
原因:多轮数据过少、上下文标注不规范
解决:补充高质量多轮SFT数据
八、SFT、RAG、RLHF 落地组合方案
企业级AI落地黄金组合:
方案1:轻量化落地(中小企业)
RAG + 简易SFT
• RAG 负责新知识、私有知识、消除幻觉
• SFT 负责统一输出风格、规范格式
方案2:高阶落地(大厂/垂直行业)
SFT + RLHF + RAG
• SFT:打好任务底座
• RLHF:对齐人类偏好、提升体验、安全合规
• RAG:实时知识更新、解决模型滞后
九、总结
1. SFT 是大模型从“能用”到“好用”的第一道门槛;
2. 预训练学知识,SFT学任务,RLHF学审美;
3. SFT效果核心不在于参数,而在于高质量、高纯净数据集;
4. 所有私有化行业模型、企业专属模型,必须经过SFT训练;
5. 工程落地最优解:SFT定风格,RAG补知识,RLHF提体验。
SFT是大模型工程落地最基础、最重要、最常用的技术,掌握SFT,才算真正入门大模型微调落地。
后续我会更新:《SFT数据集制作手把手教程》《LoRA-SFT从零训练实战代码》,感兴趣可以点赞收藏!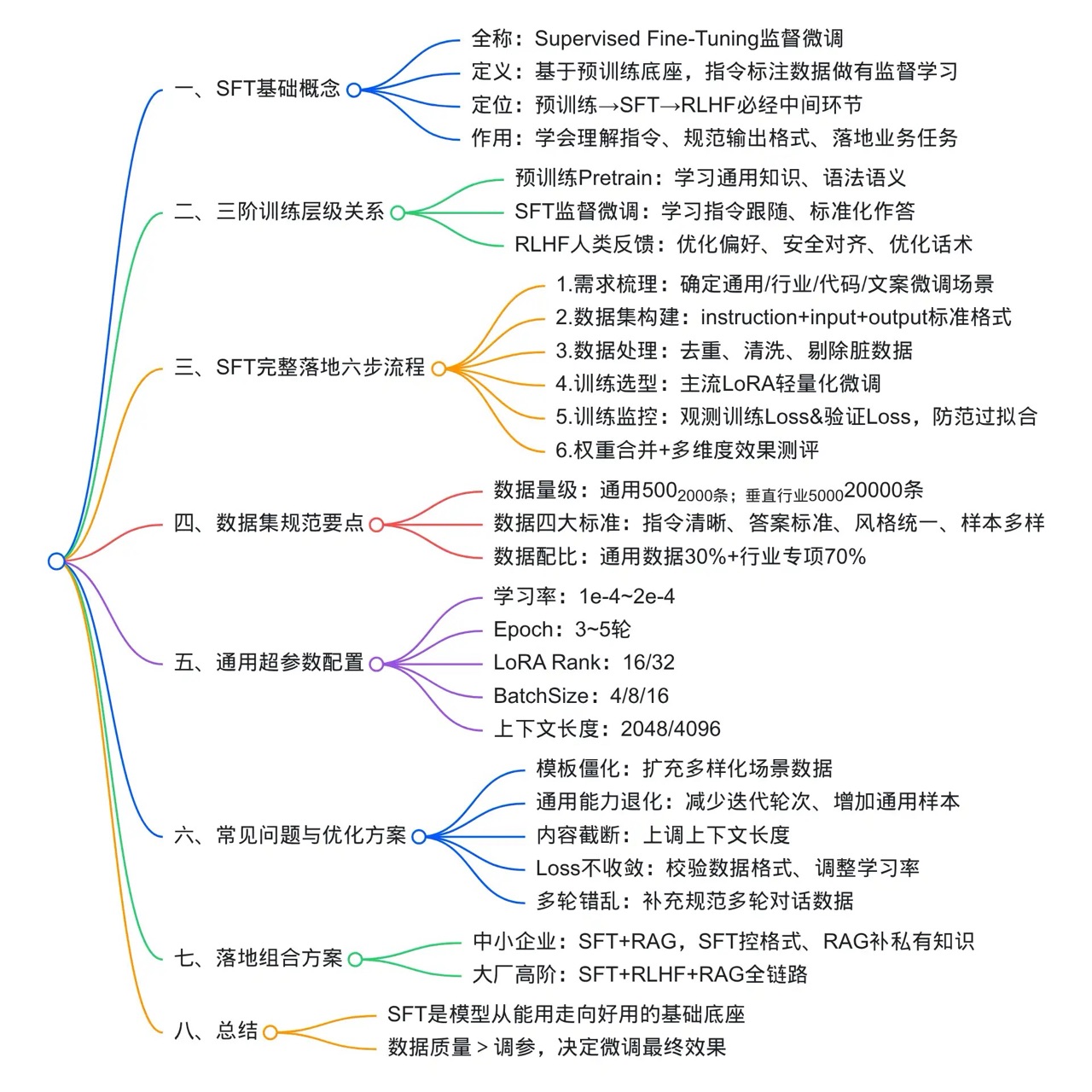

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 6
6 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)