【无标题】
文章目录
4. 【案例三】基于 LangGraph 实现的代理式 RAG(检索增强生成)系统
4.1 案例介绍
还记得我们在 LangChain 篇章中,编写过 LCEL 链式的 RAG 系统。整个系统就是一条直线:

它适合初学者,因为:
- 概念少:只需要理解 Runnable, StrOutputParser 等基础概念
- 逻辑简单:线性流程,易于理解和调试
- 代码直观:一眼就能看懂数据流动
- 快速上手:几分钟就能跑通整个流程
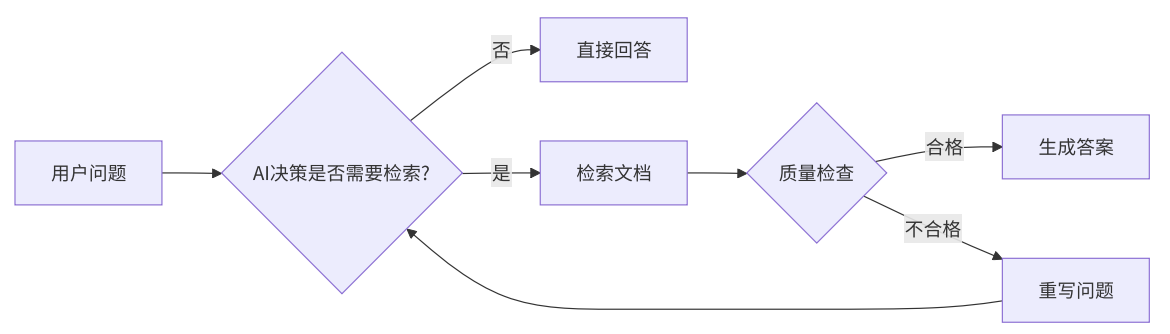
而在 LangGraph 篇章中,我们将会构建一个智能的文档问答系统(复杂版),它能够根据检索结果的质量动态调整查询策略。逻辑如下图所示:
举个例子:这里我们提供了后端开发相关的几篇技术文档,作为知识库:
- RPC 概念零基础到项目实战.md
- Protobuf 零基础到项目实战.md
- RPC、brpc、etcd、服务发现 — 从零开始理清楚.md
- Docker + Docker-Compose 零基础到项目实战.md
可以支持我们询问:
- “RPC解决什么问题”
- “protobuf和JSON有什么区别”
- “Docker解决了什么问题”
- “etcd在微服务中的作用是什么”
- …
当用户询问"RPC和brpc是什么关系"时,根据要求,会经历:
- 模型决定调用检索工具,搜索"RPC brpc 关系"
- 检索到相关文档后进行评估
- 如果文档相关,直接生成答案
- 如果文档不相关,重写问题后重新检索
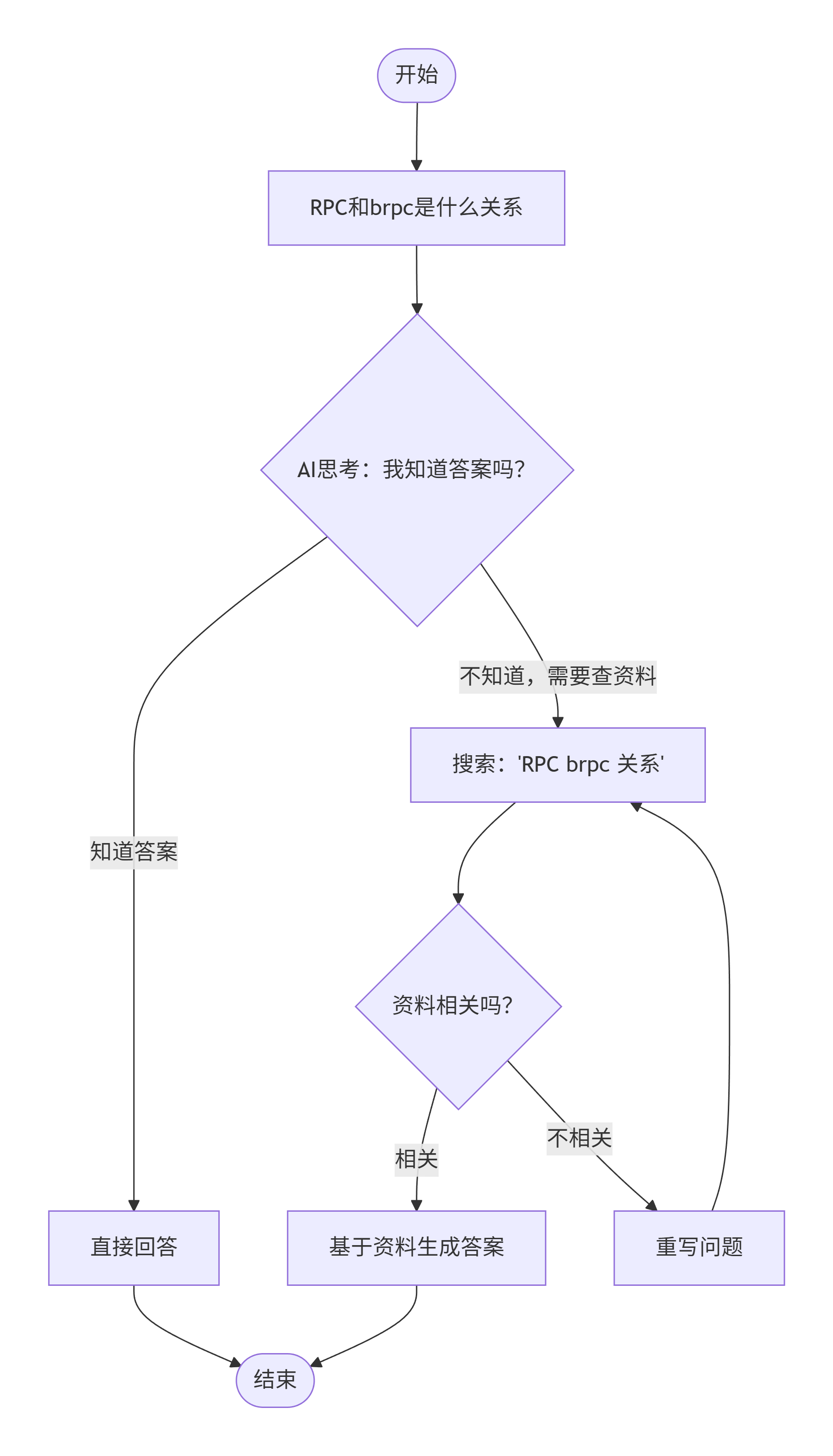
这个设计确保了即使初次检索不成功,系统也能通过重写查询来改进结果质量,比传统 RAG 系统更加鲁棒。
鲁棒性:是指系统在面对各种内外部干扰时,仍能保持其性能稳定的能力。具体来说:
- 它描述了系统在不确定性、噪声、误差或其他不利因素下的表现。
- 鲁棒性与稳定性不同,稳定性关注系统在扰动消失后的恢复,而鲁棒性关注在持续扰动下的表现。
- 在模型中,鲁棒性指的是模型在陌生环境或噪声干扰下依旧能够完成预期任务的能力。
因此,相较于 LangChain 篇章中链式的 RAG:“怎么让RAG跑起来”,该案例将学习"怎么让RAG跑得更好、更智能"!
4.2 编码思路
构建一个智能文档问答系统,我们要将复杂流程分解为离散步骤,且通过共享状态连接各个节点,核心设计思路如下:
- 模块化设计:每个节点只做一件事,职责清晰
- 质量闭环:检索 → 检查 → 优化 → 再检索,确保答案质量
- 智能路由:AI 自主决定下一步行动,无需人工干预
因此,我们需要:
- 第一步:准备"知识库"(数据加载与处理)
- 第二步:创建"检索工具"
- 第三步:设计"工作流程节点"
- 节点1:决策节点
generate_query_or_respond - 节点2:检索器工具节点
retrieve - 节点3:问题优化节点
rewrite_question - 节点4:答案生成节点
generate_answer
- 节点1:决策节点
- 第四步:组装"工作流水线"
- 条件边1:LLM 决策是否需要进行知识库检索
- 条件边2:检测【检索到的文档】是否与【问题】相关
最终 Graph 示意图: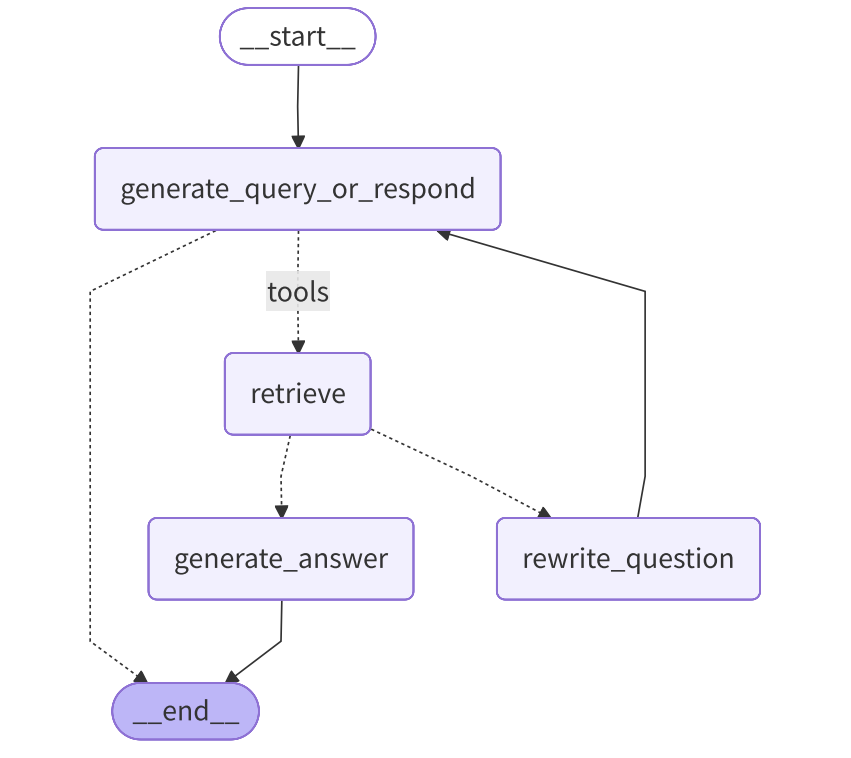
4.3 代码实现
4.3.1 步骤一:准备"知识库"并创建"检索工具"
from langchain.chat_models import init_chat_model
from langchain_core.messages import HumanMessage, filter_messages
from langchain_community.document_loaders import UnstructuredMarkdownLoader
from langchain_text_splitters import RecursiveCharacterTextSplitter
from langchain_core.vectorstores import InMemoryVectorStore
from langchain_ollama import OllamaEmbeddings
from langchain_classic.tools.retriever import create_retriever_tool
# 聊天模型与嵌入模型
model = init_chat_model("openai:mimo-v2.5-pro", temperature=0)
embeddings = OllamaEmbeddings(model="nomic-embed-text")
其中:
init_chat_model("openai:mimo-v2.5-pro", temperature=0):使用 mimo-v2.5-pro 作为聊天模型,temperature=0 表示输出更确定OllamaEmbeddings(model="nomic-embed-text"):使用本地 Ollama 运行的 nomic-embed-text 嵌入模型,免费且无需联网
# 加载文档列表
paths = [
"D:/aaa/一周项目总览/第一档知识/RPC 概念零基础到项目实战.md",
"D:/aaa/一周项目总览/第一档知识/Protobuf 零基础到项目实战.md",
"D:/aaa/一周项目总览/第一档知识/RPC、brpc、etcd、服务发现 — 从零开始理清楚.md",
"D:/aaa/一周项目总览/第一档知识/Docker + Docker-Compose 零基础到项目实战.md",
]
docs = [UnstructuredMarkdownLoader(path).load() for path in paths]
docs_list = [item for sublist in docs for item in sublist]
加载 4 个 Markdown 技术文档作为知识库。docs 是嵌套列表(每个文件一个子列表),用列表推导展平为 docs_list。
# from_tiktoken_encoder:使用 tiktoken 编码器来计算长度的文本分割器。
text_splitter = RecursiveCharacterTextSplitter.from_tiktoken_encoder(
encoding_name="cl100k_base",
chunk_size=1000,
chunk_overlap=50
)
doc_splits = text_splitter.split_documents(docs_list)
其中:
cl100k_base:GPT 系列使用的 tiktoken 编码器chunk_size=1000:每个片段最多 1000 tokenchunk_overlap=50:相邻片段重叠 50 token,防止语义被硬切断
# 使用内存中向量存储和本地 Ollama 嵌入
vectorstore = InMemoryVectorStore.from_documents(
documents=doc_splits,
embedding=embeddings
)
# 使用 LangChain 的预构建 create_retriever_tool 创建检索器工具:
retriever = vectorstore.as_retriever(search_kwargs={"k": 2})
retriever_tool = create_retriever_tool(
retriever,
"retrieve_knowledge",
"搜索并返回有关后端开发、RPC、Protobuf、Docker、服务发现等技术的知识。",
)
其中,create_retriever_tool() 用于创建一个基于文档检索的工具,参数说明:
retriever: BaseRetriever- 检索器实例,负责实际的文档检索name: str- 工具名称,传递给语言模型,需要唯一且具有描述性description: str- 工具描述,帮助语言模型理解何时使用该工具
该方法返回 Tool 对象,其继承了 BaseTool。BaseTool 是所有 LangChain 工具的基础类。执行工具时可使用 invoke() 方法,而执行参数则是检索器执行参数。
return Tool(
name=name,
description=description,
func=func,
coroutine=afunc,
args_schema=RetrieverInput,
response_format=response_format,
)
4.3.2 步骤二:设计"工作流程节点"
根据 Graph 示意图,设计出以下四个节点:
- 节点1:决策节点
generate_query_or_respond - 节点2:检索器工具节点
retrieve - 节点3:问题优化节点
rewrite_question - 节点4:答案生成节点
generate_answer
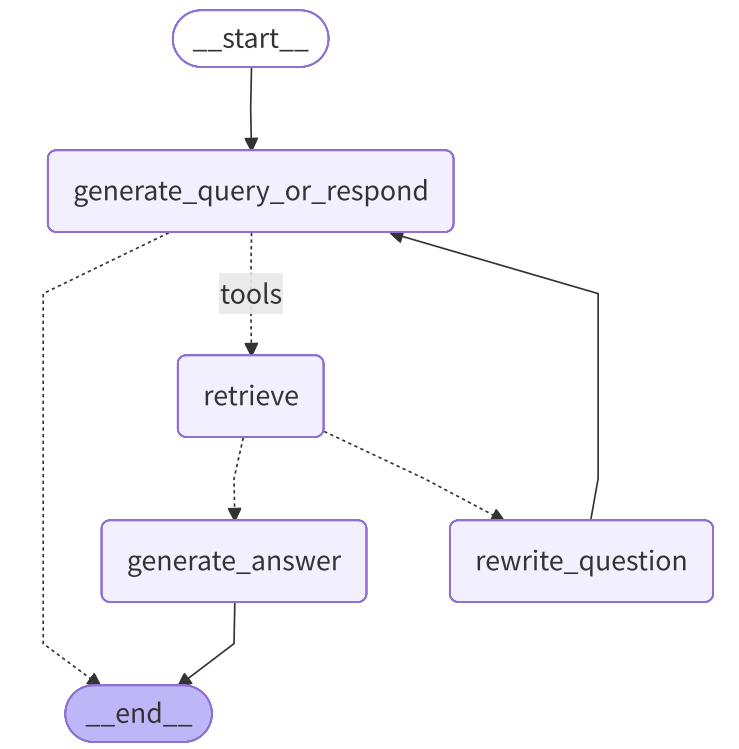
4.3.2.1 节点1:决策节点 generate_query_or_respond
该节点核心设计:
- 决定是直接回答还是检索文档
- 可以使用
model.bind_tools([retriever_tool])让模型能够调用检索工具
def generate_query_or_respond(state: MessagesState):
"""调用模型以基于当前状态生成响应。
给定问题,它将决定使用检索工具检索,或者简单的生成用户响应"""
result = model.bind_tools([retriever_tool]).invoke(state["messages"])
# result 是一个 AIMessage
return {
"messages": [result]
}
其中 MessagesState 是 LangGraph 中给我们写好只包含 messages 的 State,可以直接使用。其源码如下:
class MessagesState(TypedDict):
messages: Annotated[list[AnyMessage], add_messages]
测试 generate_query_or_respond 方法返回值:
# 测试generate_query_or_respond方法返回值
input_messages = {
"messages": [
{
"role": "user",
"content": "RPC和brpc是什么关系?",
}
]
}
generate_query_or_respond(input_messages)["messages"][-1].pretty_print()
# 打印:
# ================================== Ai Message =================================
# Tool Calls:
# retrieve_knowledge (call_xxx)
# Call ID: call_xxx
# Args:
# query: RPC brpc 关系
从结果看来,根据我们的输入:RPC和brpc是什么关系?,LLM 决定继续检索文档,且设置好了初次的查询字符串!
4.3.2.2 节点2:检索器工具节点 retrieve
前面已经创建好了检索器工具。对于节点,可以使用 ToolNode 类来定义:
from langgraph.prebuilt import ToolNode
retriever_node = ToolNode([retriever_tool])
ToolNode 用于创建 LangGraph 工作流程中执行工具的节点。
4.3.2.3 节点3:问题优化节点 rewrite_question
该节点主要负责当文档不相关时,重写问题以改进检索效果。
REWRITE_PROMPT = (
"查看输入并尝试推断潜在的语义意图/含义。\n"
"这是最初的问题:"
"\n ------- \n"
"{question}"
"\n ------- \n"
"提出一个改进后的问题:"
)
def rewrite_question(state: MessagesState):
"""重写原始用户问题"""
# state messages 包含 [H, A, T]
question = state["messages"][0]
prompt = REWRITE_PROMPT.format(question=question)
result = model.invoke([HumanMessage(content=prompt)])
# 把修改后的问题,设置为用户消息,在进行历史消息更新
return {
"messages": [HumanMessage(content=result.content)]
}
模拟【检索内容与原本问题不相关】的情况,测试一下:
from langchain_core.messages import convert_to_messages
input_messages = {
"messages": convert_to_messages(
[
{
"role": "user",
"content": "RPC和brpc是什么关系?",
},
{
"role": "assistant",
"content": "",
"tool_calls": [
{
"id": "1",
"name": "retrieve_knowledge",
"args": {
"query": "RPC brpc 关系"
}
}
]
},
{
"role": "tool",
"content": "你好",
"tool_call_id": "1"
}
]
)
}
rewrite_question(input_messages)["messages"][-1].pretty_print()
# 打印结果如下:
# 改进后的问题可以是:"我想了解RPC远程过程调用和brpc百度RPC框架之间的关系和区别。"
4.3.2.4 节点4:答案生成节点 generate_answer
该节点将基于相关文档生成最终答案:
# 生成答案
GENERATE_PROMPT = (
"你是负责回答问题的助手。 "
"使用以下检索到的上下文片段来回答问题。 "
"如果你不知道答案,就说你不知道。 "
"最多只用三句话,回答要简明扼要。\n"
"Question: {question} \n"
"Context: {context}"
)
def generate_answer(state: MessagesState):
"""生成答案"""
# state messages 包含 [H, A, T]
# 问题+检索结果
question = state["messages"][0].content
context = state["messages"][-1].content
prompt = GENERATE_PROMPT.format(question=question, context=context)
return {
"messages": [model.invoke([HumanMessage(content=prompt)])]
}
4.3.3 步骤三:组装"工作流水线"
根据下图,开始组装"工作流水线"。
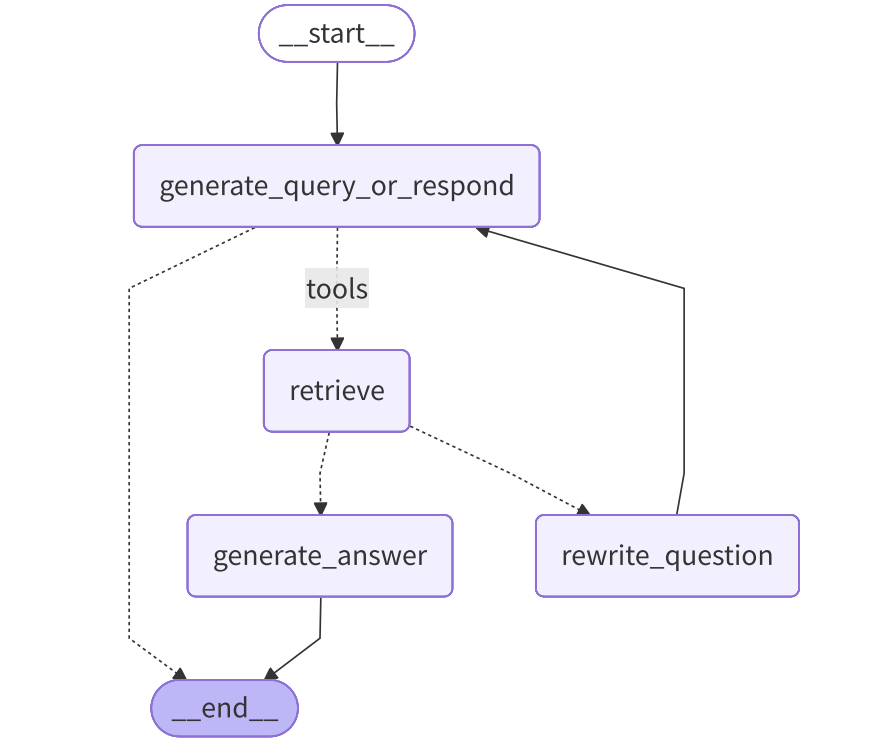
4.3.3.1 添加节点与入口点
# 组装Graph
from langgraph.graph import StateGraph, START, END
from langgraph.prebuilt import ToolNode, tools_condition
workflow = StateGraph(MessagesState)
workflow.add_node(generate_query_or_respond)
workflow.add_node("retrieve", retriever_node)
workflow.add_node(rewrite_question)
workflow.add_node(generate_answer)
workflow.add_edge(START, "generate_query_or_respond")
4.3.3.2 条件边1:LLM 决策是否需要进行知识库检索
第一条分支用来判断是否需要调用工具。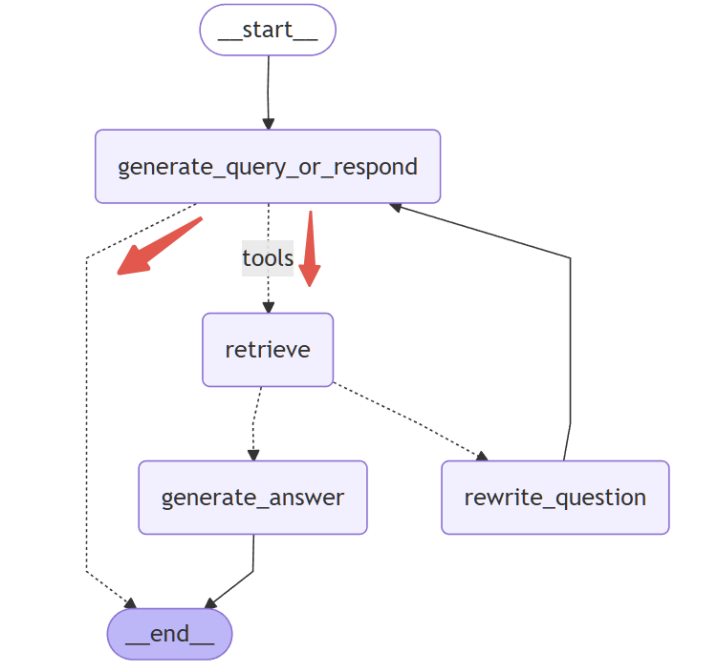
"是否需要调用工具"的判断,可以使用 tools_condition() 方法来决定工作流的路由(等价于手动写的 should_continue 方法),规则如下:
- 如果最后一条 AI 消息包含工具调用,则路由到工具执行节点;
- 否则,请结束工作流。
该方法返回类型为 Literal["tools", "__end__"],表示:
- 当最后一条 AI 消息包含工具调用,则返回
"tools" - 否则返回
"__end__"
workflow.add_conditional_edges(
"generate_query_or_respond",
# 评估 LLM 决策
tools_condition,
{
"tools": "retrieve", # 将条件输出转换为图中的节点
"__end__": END,
},
)
4.3.3.3 条件边2:检测【检索到的文档】是否与【问题】相关
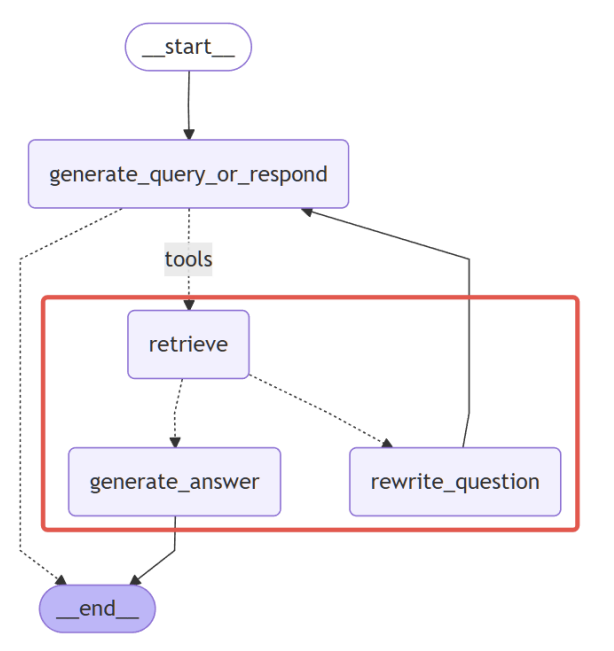
该条件边核心在于:
- 评估检索到的文档与问题的相关性
- 可以使用【结构化输出】模型返回二元评分
yes:表示检索到的文档与问题相关no:表示检索到的文档与问题不相关
- 返回下一步路由决策:
"generate_answer"或"rewrite_question"
# 对文档进行评估
from pydantic import BaseModel, Field
from typing import Literal
GRADE_PROMPT = (
"你是一个评分员,评估检索到的文档与用户问题的相关性。 \n "
"以下是检索到的文档: \n\n {context} \n\n"
"以下是用户的问题: {question} \n"
"如果文档包含与用户问题相关的关键字或语义,则将其评为相关。 \n"
"给出一个二元分数yes或no,以表明该文档是否与问题相关。"
)
class GradeDocuments(BaseModel):
"""使用二值评分进行相关性检查"""
score: str = Field(default="", description="相关性评分:如果相关则为yes, 不相关则为no")
answer: str = Field(default="", description="相关性评分:如果相关则为yes, 不相关则为no")
def grade_documents(state: MessagesState) -> Literal["generate_answer",
"rewrite_question"]:
"""确定检索到的文档是否与问题相关"""
# 问题+检索到的文档交给LLM来判断是否合格(yes, no)
# 拿到最新的 HumanMessage(filter)
user_messages = filter_messages(state["messages"], include_types="human")
question = user_messages[-1].content
tool_message = state["messages"][-1]
context = tool_message.content
prompt = GRADE_PROMPT.format(context=context, question=question)
result = (
model.with_structured_output(GradeDocuments).invoke(
[HumanMessage(content=prompt)]
)
)
if result.score == "yes" or result.answer == "yes":
return "generate_answer"
else:
return "rewrite_question"
workflow.add_conditional_edges(
"retrieve",
# 评估代理决策
grade_documents,
["generate_answer", "rewrite_question"],
)
注意:这里 GradeDocuments 定义了 score 和 answer 两个字段,是因为 mimo 模型的 structured output 返回的字段名是 answer 而不是 score,所以两个都定义上,确保兼容。
另外,使用 filter_messages(state["messages"], include_types="human") 来获取最新的用户消息,而不是直接用 state["messages"][0],是因为如果经过了重写循环,messages[0] 可能已经不是最新的用户问题了。
4.3.3.4 添加结束点并编译
workflow.add_edge("generate_answer", END)
workflow.add_edge("rewrite_question", "generate_query_or_respond")
graph = workflow.compile()
4.3.3.5 运行 RAG
for chunk in graph.stream(
{
"messages": [HumanMessage(content="RPC和brpc是什么关系?etcd在其中起什么作用?")]
}
):
for node, update in chunk.items():
print(f"由节点{node}更新消息")
update["messages"][-1].pretty_print()
print("\n\n")
结果如下:
由节点 generate_query_or_respond 更新消息:
================================== Ai Message =================================
Tool Calls:
retrieve_knowledge (call_xxx)
Call ID: call_xxx
Args:
query: RPC brpc etcd 关系
由节点 retrieve 更新消息:
================================= Tool Message =================================
Name: retrieve_knowledge
....(检索结果较长,省略显示)
由节点 generate_answer 更新消息:
================================== Ai Message =================================
RPC是一种远程过程调用的思想,brpc是百度实现的一个RPC框架。etcd是一个KV存储,
专门记录"谁在哪",用于服务注册和服务发现。user服务启动时把自己注册到etcd,
gateway启动时从etcd查询user服务的地址,实现动态服务发现。
4.4 mimo 模型踩坑点
在使用 mimo-v2.5-pro 时遇到的问题:
-
structured output 字段名不匹配:mimo 返回
{"answer": "yes"}而不是{"score": "yes"},需要在 Pydantic 模型中同时定义score和answer两个字段,并在判断时检查两个字段。 -
emoji 输出导致 GBK 编码错误:mimo 的回复可能包含 emoji,在 Windows 终端用
pretty_print()会报UnicodeEncodeError,需要设置PYTHONIOENCODING=utf-8环境变量。 -
中文引号混入代码:从 PDF 提取的内容中包含中文引号
"",会导致 Python SyntaxError,需要替换为英文引号。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 1
1 0
0- 0



 已为社区贡献28条内容
已为社区贡献28条内容

所有评论(0)