别再直接给ai发PDF了!本人用过效果最好的PDF 转 Markdown 工具: Marker,太适合把科研论文喂给大模型了,支持提取图片和本地部署,准确率高到离谱
最近看了别人的博客才知道 直接给大模型 发科研论文的Latex源码或者md格式解析效果会更好。
然后有的论文找不到公开的latex源码,就在GitHub上找到个这个开源项目:Marker(datalab-to/marker: Convert PDF to markdown),可以把PDF转成高质量的Markdown格式,同时能保留论文中的图片(本人觉得这点超赞,对比了几个网站都觉得没有这个效果好),也支持本地部署。
适用场景
- 从网页下载的论文想转成 Markdown 做笔记
- 技术文档是 PDF 格式,想整理成博客
- 参考文献里的表格和公式复制出来就乱码
- 网上那些转换工具要么收费,要么要上传文件,不适合隐私数据
🎯 什么是 Marker?
Marker 是一个本地运行的 PDF 转 Markdown 工具,支持多种输出格式(Markdown、HTML、JSON、Chunks)。
它的核心特点:
🔒 本地运行:所有处理都在本地,不用上传文件
🌍 多语言支持:支持全球几乎所有语言 OCR
📐 精准识别:表格、公式、代码块完美保留
🖼️ 图片提取:自动提取文中图片
使用教程
1. 直接安装Python第三方库
tips:需要Python 3.10以上 和 PyTorch
pip install marker-pdf如果除PDF还需要处理更多的格式(PPTX、DOCX等),安装这个完整版:
pip install marker-pdf[full]💻 快速上手
方法一:命令行转换单个文件
marker_single /path/to/your/file.pdf方法二:批量转换文件夹
marker /path/to/pdf/folder方法三:图形界面(推荐新手)
pip install streamlit streamlit-ace
marker_gui⚠️(一定要勾选debug,才会保存输出的md文件和图片到debug_data/目录下)
🛠️ 常用参数详解
# 指定输出目录
marker_single file.pdf --output_dir ./output
# 指定页码范围
marker_single file.pdf --page_range "0,5-10,20"
# 强制 OCR(适合文字提取混乱的 PDF)
marker_single file.pdf --force_ocr
# 使用 LLM 提升准确率
marker_single file.pdf --use_llm
# 输出格式选择
marker_single file.pdf --output_format markdown # 可选:markdown/json/html/chunks
# 启用调试模式(保存中间结果)
marker_single file.pdf --debug2. 从GitHub上下载源码,然后用Python运行
下载项目源码:
git clone https://github.com/datalab-to/marker转换单个文件:
python convert_single.py /Users/.../pdf/"XXX.pdf" --output_dir /Users/.../output批量转换文件夹:
python convert.py /path/to/pdf/folder🔥 实测案例
我用一篇 arXiv 论文(9 页,含公式和表格):
转换前:
- 复杂的学术论文格式
- 包含多栏布局
- 有内联公式和表格
转换后:
- Markdown 格式整洁
- 表格完整保留
- 公式用 LaTeX 格式 $...$ 包裹
- 图片自动提取到单独文件夹
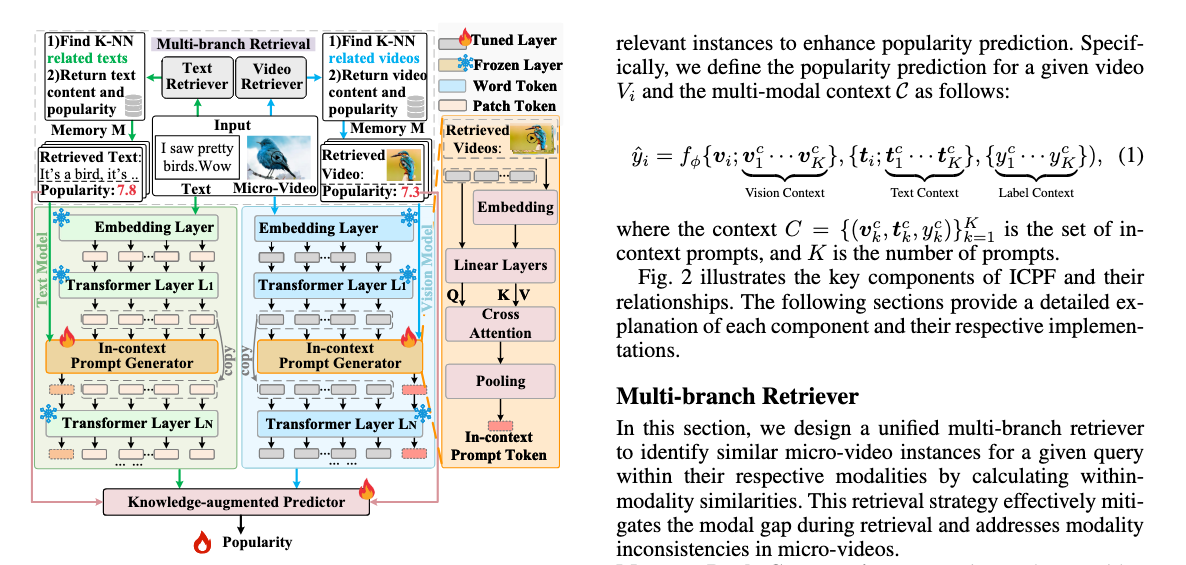
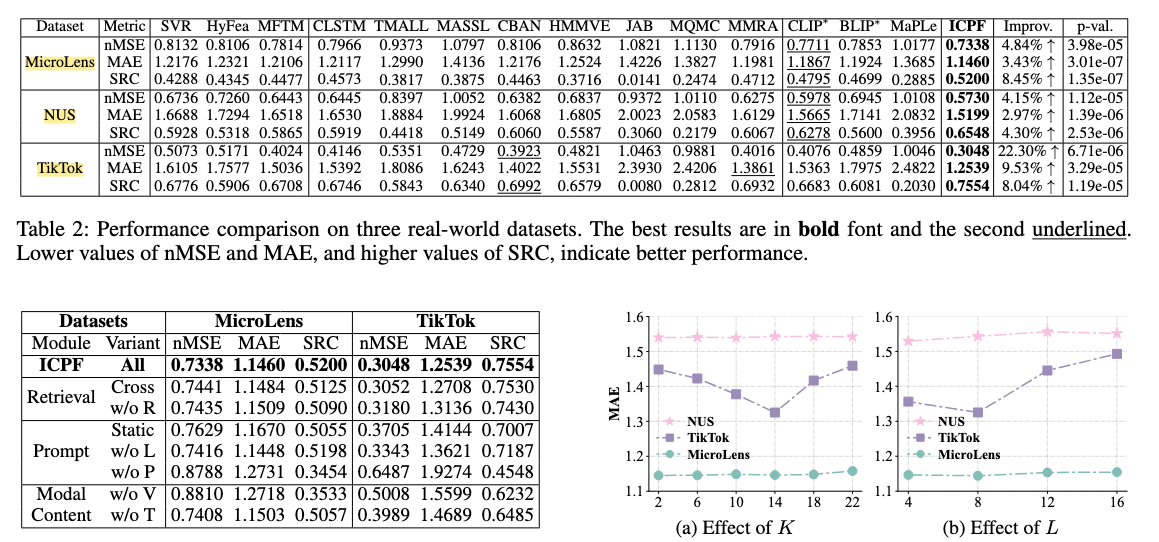
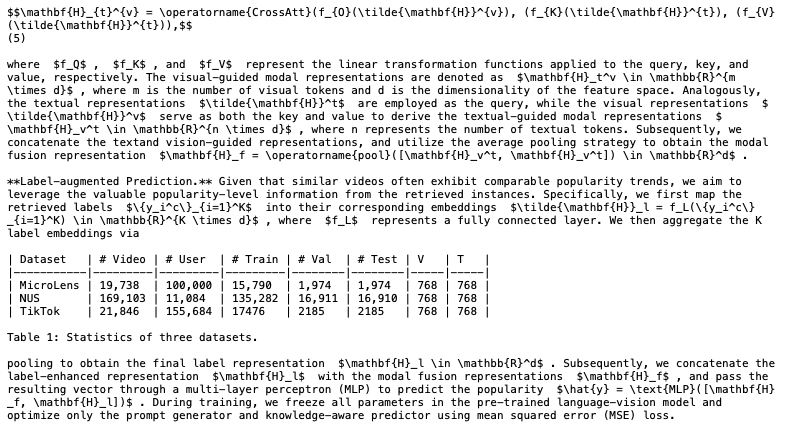
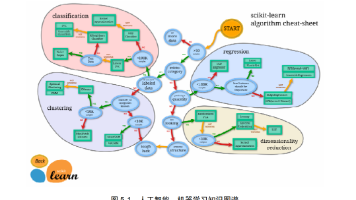
图片、表格、公式都能完美提取和转换:
💡 进阶用法
使用 LLM 提升质量
marker_single file.pdf --use_llm需要配置 Gemini API 密钥或 Ollama 本地模型。
🔗 相关资源
GitHub: https://github.com/VikParuchuri/marker
文档:https://documentation.datalab.to

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 0
0 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)