零起点Python机器学习快速入门【1.6】
第 5 章 Python 人工智能入门与实践
5.1 从忘却开始
广大初学者面对人工智能、机器学习这些高大上的概念,一方面,迫切希望能够掌握相关的知识;另一方面,面对各种层出不穷的概念,往往会眼花缭乱、无所适从。
目前 Python 已经是人工智能、机器学习的行业标准语言, TensorFlow、Torch 于 2015 年、 2016 年先后开放了 Python 语言接口。
Sklearn 是 Python 语言最重要的人工智能模块库,目前已经收入 Scikit套件,所以又称为 Scikit-Learn,不过通常还是简称为 Sklearn。
如图 5-1 所示是 Sklearn 官方网站的人工智能、机器学习知识图谱。
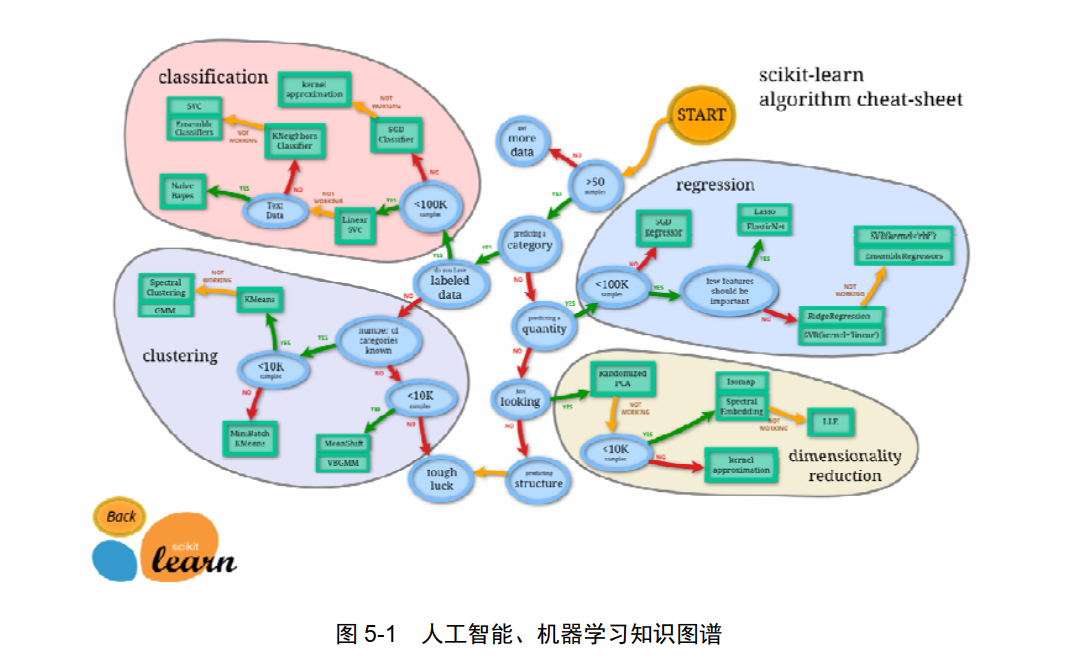
不知道各位读者对此图的感觉是什么,反正,笔者看到这幅图的第一反应是吓呆了,也明白了为什么这么多初学者对于人工智能望而生畏。
人工智能、机器学习、数据分析是笔者研究了多年的课题与领域, 20年前笔者最早的论文标题就是《人工智能与中文字型设计》,该论文还在暴雪(你没看错,就是做魔兽的暴雪)、宝洁等国际 500 强的知识产权案件中,被作为技术文献引用。
既然笔者的论文能够用于非常严肃的司法领域,那么在人工智能领域,笔者也可以算是根正苗红的学者了。
与普通理论学者不同的是,笔者始终认为自己是一名软件工程师或者程序员,也就是网络上常说的“码农”。
对于程序员而言: Talk is cheap, show me the code!
再多的理论也比不上几件成功的软件作品,笔者虽然谈不上有很多成功的软件作品,但也写过不少专业的程序,例如原生的 OCR 识别程序和英汉翻译程序。
所谓原生程序就是直接采用 C 语言、 Delphi 语言的标准函数库直接编写应用软件,没有采用任何第三方 AI 架构库,如 Sklearn、 TensorFlow 等AI 模块库。做过底层系统的程序员,以及阅读过 Linux、安卓系统、TensorFlow 系统源码的程序员,会明白其中的难度。
这种基于原生的开发,最大的好处是,无论采用何种编程语言、何种理论算法,最终的底层代码结构都差不多,就像电脑里面的 CPU,算得再快也不过是个“加法器”。
笔者曾经在博客《文科生、易经与大数据》中说过:
殊途同归,什么东西到了极致,其根源都是相通的。易经是纯文科的了,“字王小数据理论”“黑天鹅算法”的灵感就是来自易经、阴阳、八卦……
以量化投资为例,在进行大数据分析时,我们发现,所有的分析,抛开表象,到了最后,无非是两种选择:亏、赢。延伸一下,其他项目也是如此:
输、赢;正、负;胜、负;涨、跌;加、减;男、女;老、少;黑、白;取、舍。
这些正好对应易经的阴、阳。计算机的核心是 CPU,但 CPU 的本质不过是一个“加法器”。在 CPU 里面,其实加、减都是加法,因为减不过是加上一个负数符号。
这个加法器正好对应了易经里面的一生二:一( CPU 加法器)生二(加、减)。
明白了这点再看 Sklearn 的知识图谱,虽然表面看起来还是乱七八糟的,非常烦琐,但仔细梳理后,能够看出其核心其实只有两个字:分类( Type)。
将分类做好,其他匹配、识别都是简单的问题,只是贴上标签和加上备注。
国外也有专家认为,所有的人工智能、机器学习,本质上都是二元一次方程的寻优算法。笔者在博客中曾经也说过:
可以把人工智能、机器学习看成一个巨大的字符串 Find 查找算法,
只不过这个算法中的 keyword 关键词,与被查找的字符串的大小非常庞大,趋于无限长度。
众所周知,开源项目 70% 的问题都是卡在系统配置上,特别是对于国外的项目,存在语言障碍,文档不齐。
TopQuant.vip 极宽量化开源社区发布的集成式 Python 开发平台: zwPython,解压缩即用,无须安装;内置人工智能、机器学习所需的各种模块库,包括 NLTK、 Sklearn 以及最高大上的 TensorFlow,而且全功能、全免费、全开源,无须花费一分钱,是真正的零起点学 AI。
从某种程度上讲,能够下载 zwPython、解压缩并且运行内置的 hello程序,相对于传统的人工智能学习周期,大家就已经完成了 70%,并且拥有了专业级别的人工智能开发平台。
很多初学者,面对人工智能、机器学习往往连系统配置都玩不转,最基本的 hello 程序也无法运行。在《 zwPython 用户手册》里面,笔者曾经说过,虽然很多人认为Python 是面向对象的语言,但实践表明,忘记 OOP(面向对象编程)的概念,采用传统的 Basic 语言(面向过程)模式,学习效率可以提高 10倍以上。
这一点用过 zwPython 的用户都知道,笔者量化培训班的学员更是深有体会,许多 40 多岁金融一线的从业人员,完全没有编程基础,通常学习两个月,就可以自己修改 zwQuant 量化开源软件中的策略函数。
所以,学习人工智能,笔者的建议就是:从忘却开始,忘却各种乱七八糟的概念。
忘记这些概念之后,就会海阔天空,所谓的人工智能,不过是传统的Python 函数调用,而且只有寥寥无几的数个函数,在最简单的案例当中,甚至只需要 2~3 个 AI 相关函数。
需要说明的是,对于初学者而言,除了忘却之外,不要左顾右盼, MATLAB、 R 语言、 Torch、 TensorFlow、 NLTK……这些都想学,但或许都学不好。
以上这些名词、术语,看起来简单,但其实对于每一个名词术语,若没有一个专业的博士团队,都是无法完成的独立项目。
对于初学者而言,入门阶段就学习一个模块库: Sklearn。
Sklearn 模块库本身就是人工智能、机器学习的行业标准,该有的人工智能、机器学习经典算法它全部都有,其他的模块库无非是在局部进行了某些优化。
至于人工智能的进阶内容,大家不要着急,学会了 Sklearn 的人工智能入门内容后,再看 TensorFlow、 Torch 就不会有看天书的感觉了。
5.2 Iris经典爱丽丝
Iris 爱丽丝,是鸢尾属(拉丁学名: Iris L.)的单叶植物,与常见的百合花类似。
Iris 爱丽丝数据集是人工智能、机器学习最经典的数据集,全称是安德森鸢尾花卉数据集,是统计学习的必备数据集。
维基百科有专门的词条:
安德森鸢尾花卉数据集( Anderson’s Iris data set),也称鸢尾花卉数据集( Iris flower data set)或费雪鸢尾花卉数据集( Fisher’s Iris data set),是一类多重变量分析的数据集。它最初是埃德加·安德森从加拿大加斯帕半岛上的鸢尾属花朵中提取的地理变异数据,后由罗纳德·费雪作为判别分析的一个例子,并运用到统计学中。其数据集包含了 50 个样本,都属于鸢尾属下的 3 个亚属,分别是山鸢尾、变色鸢尾和维吉尼亚鸢尾。
其 4 个特征被用作样本的定量分析,即花萼和花瓣的长度和宽度。基于
这 4 个特征的集合,费雪发展了线性判别分析以确定其属种。
我们的目的就是通过编程,对这 3 个不同种类、 150 多组 Iris 爱丽丝植物的数据,采用专业的数据分析手段和人工智能算法,让程序自动判别植物的种类。
从本章开始是人工智能篇,程序编码重新采用 zai 开头,其中 ai 是人工智能的意思。
案例 5-1: Iris爱丽丝
案例 5-1 的文件名是 zai101_iris01.py,核心代码如下:
#1
fss='dat/iris.csv'
df=pd.read_csv(fss,index_col=False)
print('\n#1 df')
print(df.tail())
print(df.describe())
#2
d10=df['xname'].value_counts()
print('\n#2 xname')
print(d10)
第 1 组代码,运行结果如下:
x1 x2 x3 x4 name
145 6.7 3.0 5.2 2.3 virginica
146 6.3 2.5 5.0 1.9 virginica
147 6.5 3.0 5.2 2.0 virginica
148 6.2 3.4 5.4 2.3 virginica
149 5.9 3.0 5.1 1.8 virginica
x1 x2 x3 x4
count 150.000000 150.000000 150.000000 150.000000
mean 5.843333 3.054000 3.758667 1.198667
std 0.828066 0.433594 1.764420 0.763161
min 4.300000 2.000000 1.000000 0.100000
25% 5.100000 2.800000 1.600000 0.300000
50% 5.800000 3.000000 4.350000 1.300000
75% 6.400000 3.300000 5.100000 1.800000
max 7.900000 4.400000 6.900000 2.500000
第 2 组代码中的函数:
d10=df['xname'].value_counts()
对植物种类进行了简单的分类统计,共有 3 种,对应的输出信息如下:
#2 xname
versicolor 50
setosa 50
virginica 50
Name: xname, dtype: int64由输出信息可以看出, 3 种植物名称分别是:山鸢尾( Iris setosa)、变色鸢尾( Iris versicolor)和维吉尼亚鸢尾( Iris virginica)。
看完以上程序,很多人可能觉得过于简单。案例 5-1 作为人工智能的入门程序的确有些过于简单,但很多初学者就卡在这简简单单的入门案例上。
案例 5-1 看起来似乎很简单,但其实做了很多小优化和修改,比如取消了原始的数据列名称,用 x1~x4 代替,与 Top-AI 极宽的 AI 模块兼容,也更加符合人工智能、机器学习的本质。对于机器学习而言,无所谓采用什么名称,在内部都是数组矩阵。
此外,从输出信息来看,统计命令:
print(df.describe())
在对应的输出信息中没有 xname 的数据,因为 xname 字段是字符串,无法统计分析,需要先对其进行数字化处理,也就是常说的文字信息的矢量化运算。
全程采用 Pandas 学习 Sklearn 人工智能,可以说是笔者的一个微创新,方便初学者把握数据内部的结构与细节。
传统的 Sklearn 人工智能文档,大部分直接采用 Numpy 数组模块,而Numpy 是为了追求极限性能设计的模块库,很多算法函数非常复杂,不亚于汇编。
从某种程度上讲,绝大部分初学者的人工智能学习之路,在起步阶段就被 Numpy 这个模块库给吓退了。
虽然 Github 项目网站的 Pandas-Sklearn 项目已经启动,但这个项目为了提高效率,采用的是内部耦合,对初学者帮助不大。
本书全部采用现有的 Pandas 命令,从数据源对 Sklearn 进行整合,无须学习额外的语法,更加方便初学者入门。
案例 5-2:爱丽丝进化与文本矢量化
案例 5-2 的文件名是 zai102_iris02.py,将根据 xname 的植物名称,设置一个新的数据字段 xid,来完成这个文本信息的矢量化工作。
案例 5-2 很简单,下面我们分组逐一讲解。
第 1 组代码,读取 Iris 数据文件,并保存到 df 变量:
#1
fss='dat/iris.csv'
df=pd.read_csv(fss,index_col=False)
第 2 组代码,根据 xname 字段,按 1、 2、 3 分别设置 xid 字段,完成
读取 Iris 爱丽丝数据名称的矢量化操作。 xid 数据字段设置为 int 格式,并
保存到 iris2.csv 文件中。
#2
df.loc[df['xname']=='virginica', 'xid'] = 1
df.loc[df['xname']=='setosa', 'xid'] = 2
df.loc[df['xname']=='versicolor', 'xid'] = 3
df['xid']=df['xid'].astype(int)
df.to_csv('tmp/iris2.csv',index=False)
我们已经将 iris2.csv 文件复制到 dat 目录下, dat/iris2.csv,在后面的案
例中,大家可以直接使用这个文件作为数据源。
第 3 组代码,输出修改后的 df 数据信息:
#3
print('\n3#df')
print(df.tail())
print(df.describe())
对应的输出信息是:
x1 x2 x3 x4 xname xid
145 6.7 3.0 5.2 2.3 virginica 1
146 6.3 2.5 5.0 1.9 virginica 1
147 6.5 3.0 5.2 2.0 virginica 1
148 6.2 3.4 5.4 2.3 virginica 1
149 5.9 3.0 5.1 1.8 virginica 1
x1 x2 x3 x4 xid
count 150.000000 150.000000 150.000000 150.000000 150.000000
mean 5.843333 3.054000 3.758667 1.198667 2.000000
std 0.828066 0.433594 1.764420 0.763161 0.819232
min 4.300000 2.000000 1.000000 0.100000 1.000000
25% 5.100000 2.800000 1.600000 0.300000 1.000000
50% 5.800000 3.000000 4.350000 1.300000 2.000000
75% 6.400000 3.300000 5.100000 1.800000 3.000000
max 7.900000 4.400000 6.900000 2.500000 3.000000
第 4 组代码,输出 xname 方面的分类统计信息:
d10=df['xname'].value_counts()
print('\n3#xname')
print(d10)
对应的输出信息是:
4#xname
versicolor 50
setosa 50
virginica 50
Name: xname, dtype: int64
第 4 组代码,输出 xid 方面的分类统计信息:
d10=df['xid'].value_counts()
print('\n4#xid')
print(d10)
对应的输出信息是:
4#xid
3 50
2 50
1 50
Name: xid, dtype: int64
AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 8
8 0
0- 0



 已为社区贡献22条内容
已为社区贡献22条内容

所有评论(0)