复旦大学SFF方法:先插值再微调,提升时序大模型可训练性!
两篇 ICLR 2026 论文都围绕大规模时序基础模型的高效使用展开:论文1关注预训练模型微调时的非凸损失景观与过拟合问题,通过参数插值先“平滑”再微调;论文2则质疑“模型越大越好”,提出由多个小型专家模型组成的模型组合,在测试时进行模型选择或集成,以更低推理成本达到接近大型单体模型的预测效果。两者共同指向:时序模型部署不只靠扩大规模,更需要优化微调与推理策略。
另外我整理了时序大模型微调解决方案资料包,感兴趣的自取,希望能帮到你!具体资料如下:
SFF & Chroma 原理解析+理论证明
基于PyTorch和GluonTS的可复制代码
超参数调优指南与决策树
两大顶级会议论文原文及代码仓库
一、论文1:(ICLR 2026 / 复旦大学)Lost in the Non-Convex Loss Landscape: How to Fine-tune the Large Time Series Model?
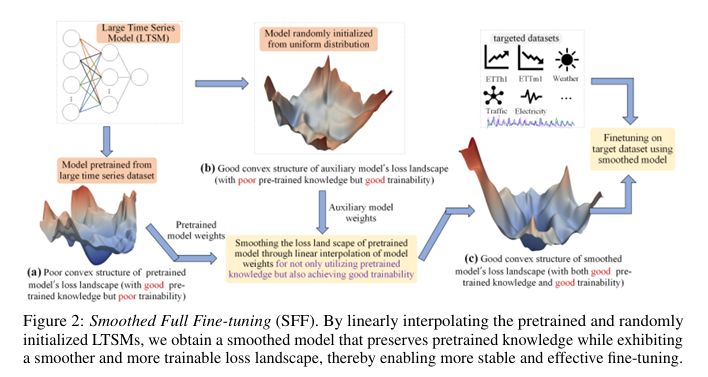
方法:
- 提出Smoothed Full Fine-tuning(SFF):先构造一个随机初始化的辅助大时序模型,再与预训练模型做线性参数插值,得到损失景观更平滑的模型,随后进行全量微调,从而改善可训练性并保留预训练知识。
关键公式如下:
Θ 3 = α Θ 1 + ( 1 − α ) Θ 2 \Theta_3=\alpha \Theta_1+(1-\alpha)\Theta_2 Θ3=αΘ1+(1−α)Θ2
f ( X , Θ 3 ) = G ( X , α Φ 1 + ( 1 − α ) Φ 2 ) T ( α W h e a d 1 + ( 1 − α ) W h e a d 2 ) f(X,\Theta_3)=G(X,\alpha\Phi_1+(1-\alpha)\Phi_2)^T(\alpha W_{head1}+(1-\alpha)W_{head2}) f(X,Θ3)=G(X,αΦ1+(1−α)Φ2)T(αWhead1+(1−α)Whead2)
创新点:
-
首次从损失景观平滑角度解释大时序模型微调困难,指出预训练模型可能陷入尖锐极小值;用随机初始化模型的平坦区域扰动尖锐区域,实现“保知识、提可训练性”,且不增加额外训练/推理开销。
-
代码链接:https://github.com/Meteor-Stars/SFF
-
论文链接:https://openreview.net/pdf?id=8o4t5DHaE1
二、论文2:(ICLR 2026 )Test-Time Efficient Pretrained Model Portfolios for Time Series Forecasting
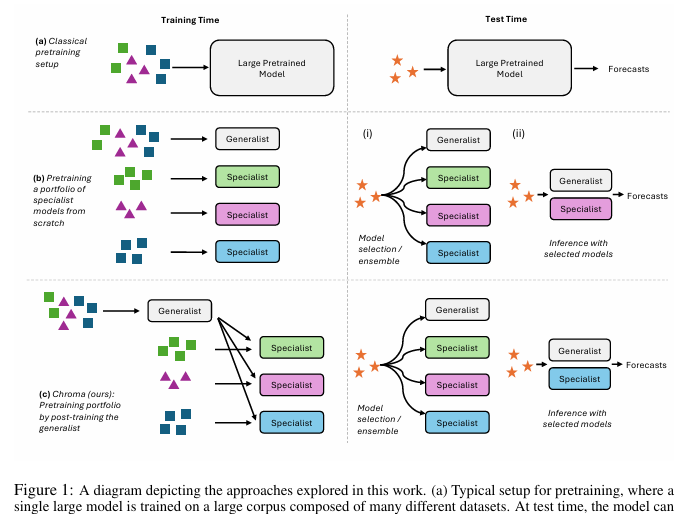
方法:
- 提出 Chroma:先训练一个小型通用模型,再按频率或应用领域对数据划分,对通用模型进行短步数后训练得到多个专家模型;测试时通过模型选择或贪心集成组合专家预测。
关键公式如下:
p θ ( x C + 1 : C + H ∣ x 1 : C ) ≈ p ( x C + 1 : C + H ∣ x 1 : C ) p_\theta(x_{C+1:C+H}\mid x_{1:C})\approx p(x_{C+1:C+H}\mid x_{1:C}) pθ(xC+1:C+H∣x1:C)≈p(xC+1:C+H∣x1:C)
y ^ e n s = ∑ m = 1 M w m ⋅ y ^ m \hat{y}_{ens}=\sum_{m=1}^{M}w_m\cdot \hat{y}_m y^ens=m=1∑Mwm⋅y^m
创新点:
-
反驳单纯“越大越好”的路径,证明小型预训练模型组合可接近大型单体模型效果;提出用后训练高效构造多样化专家,训练成本约降一个数量级,并在测试时比微调更省计算。
-
论文链接:https://openreview.net/pdf?id=iqUMjxfDNH

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 0
0 0
0- 0



 已为社区贡献16条内容
已为社区贡献16条内容

所有评论(0)