AI 产品逻辑重构:从传统搜索到生成式搜索的 PMF 校验与商业闭环设计
AI 产品逻辑重构:从传统搜索到生成式搜索的 PMF 校验与商业闭环设计
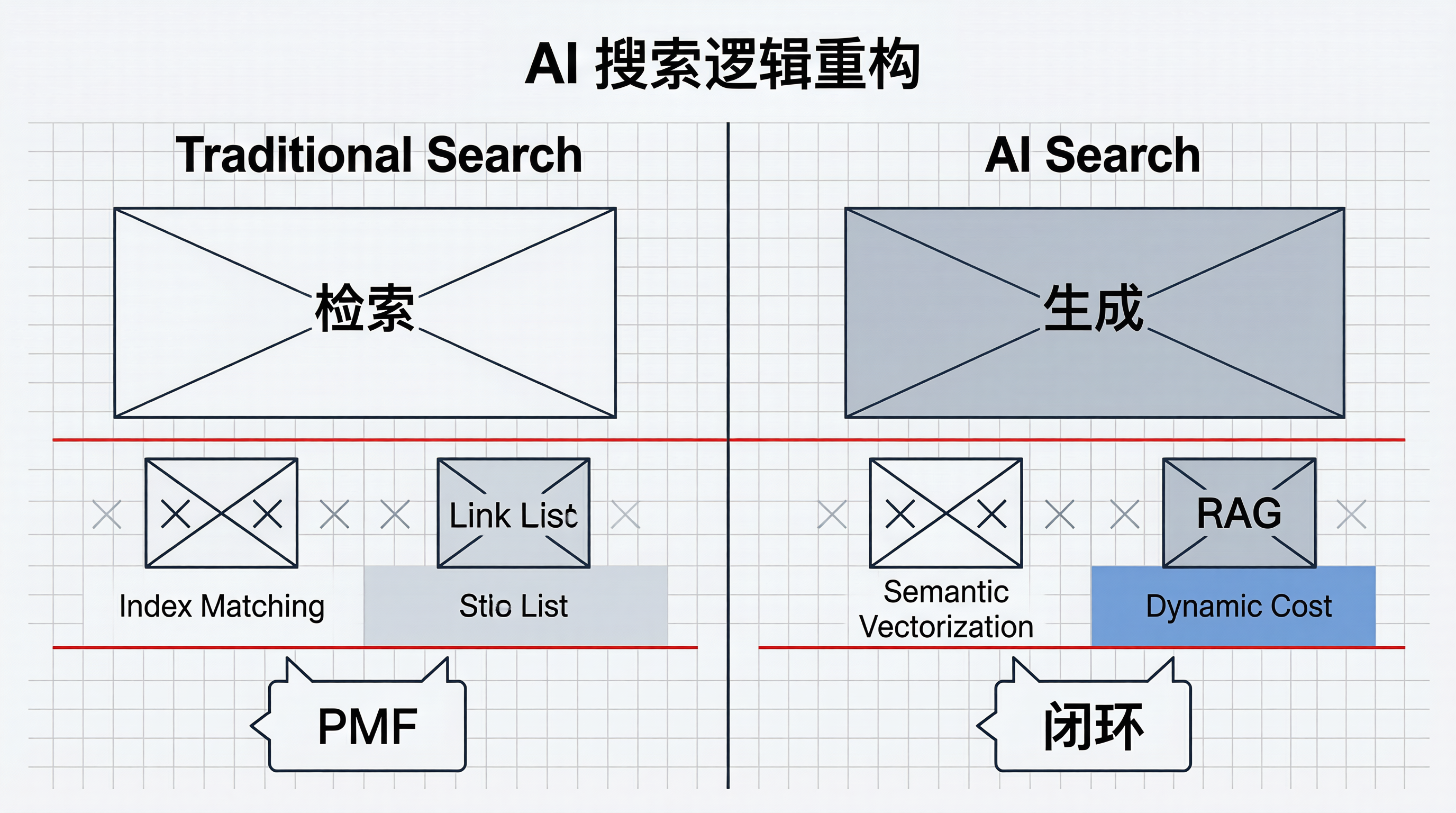
作为一位从底层技术转型的 AI 创业者,我深知搜索产品重构的挑战。在产品从 0 到 1 的过程中,搜索逻辑的范式转移往往决定着产品的成败。传统搜索引擎基于倒排索引和关键词匹配,本质是信息的“搬运工”;而 AI 搜索基于大语言模型的语义理解与生成,本质是知识的“ synthesizer(合成者)”。
在系统开发中,良好的架构可以提高系统的吞吐量。在 AI 产品领域,良好的产品逻辑可以提高用户的任务完成率。今天,我们就来深入探讨 AI 搜索与传统搜索的本质差异,从技术原理到 PMF 校验,再到商业回本指标的设计方案。
一、产品逻辑的本质差异:从“检索”到“生成”
作为一名深耕操作系统和嵌入式开发的工程师,我深知 IO 路径优化的重要性。在传统搜索中,IO 路径是“用户查询 -> 索引匹配 -> 返回链接列表”。而在 AI 搜索中,IO 路径变成了“用户查询 -> 语义向量化 -> 检索增强生成 (RAG) -> 大模型推理 -> 返回结构化答案”。
这种底层逻辑的改变,直接影响了前端交互和后端资源调度。
1.1 核心机制对比
| 维度 | 传统搜索引擎 (Traditional Search) | AI 生成式搜索 (AI Search) |
|---|---|---|
| 核心算法 | BM25, TF-IDF, 倒排索引 | Embedding, RAG, LLM Inference |
| 输出形式 | 10 个蓝色链接 (Blue Links) | 直接答案 + 引用来源 + 多模态内容 |
| 用户意图 | 信息导航 (Information Navigation) | 任务解决 (Task Completion) |
| 延迟敏感 | 低延迟 (毫秒级),追求并发 | 高延迟 (秒级),追求准确率 |
| 成本结构 | 存储与带宽为主 | Token 计算与 GPU 算力为主 |
| 反馈机制 | 点击率 (CTR), 跳出率 | 点赞/点踩, 答案采纳率, 追问率 |
从创业者的角度来看,传统搜索的设计思路与企业管理中的“流程标准化”有着密切的联系,而 AI 搜索则更接近于“专家决策系统”。
- 核心词:索引 vs 上下文:传统搜索依赖预构建的静态索引,如同企业的 SOP 流程;AI 搜索依赖动态的上下文窗口,如同专家根据现场情况灵活决策。
- 核心词:召回率 vs 准确率:传统搜索追求召回所有相关文档,如同企业追求信息收集的全面性;AI 搜索追求答案的精准度,如同企业追求决策的正确性。
- 核心词:链接跳转 vs 任务闭环:传统搜索需要用户二次点击,存在流失风险;AI 搜索力求在对话框内完成闭环,降低用户认知负荷。
- 核心词:静态成本 vs 动态成本:传统搜索边际成本趋近于零;AI 搜索每次生成都消耗 Token,边际成本随用户量线性增长,这对商业模型提出了巨大挑战。
二、PMF 校验:如何验证 AI 搜索的市场契合度
PMF (Product-Market Fit) 是创业初期的生死线。对于 AI 搜索产品,不能仅看 DAU,必须关注“任务完成率”和“幻觉控制”。
2.1 核心校验指标
在 Linux 内核中,我们关注系统调用效率和上下文切换开销。在 AI 搜索中,我们关注的是“用户意图达成效率”。
- 答案采纳率 (Answer Acceptance Rate):用户是否直接复制了 AI 生成的答案,或者在生成答案后没有进行二次搜索。
- 引用准确率 (Citation Accuracy):AI 生成的答案中,引用的来源链接是否真实存在且支持该观点。这是防止“幻觉”的关键。
- 平均对话轮数 (Average Turn Count):解决一个复杂问题需要几轮对话。轮数越少,效率越高。
- 负反馈率 (Negative Feedback Rate):用户点踩或举报的比例。
- Token 消耗 per Session:单次会话的平均 Token 消耗,直接关联成本。
2.2 实战校验流程
- 定义核心场景:不要试图覆盖所有搜索场景。先聚焦于“长尾知识问答”或“复杂代码生成”等高价值场景。
- A/B 测试设计:将 50% 流量导向传统搜索结果页,50% 导向 AI 生成答案页。
- 数据埋点:在答案生成区域增加“复制”、“引用跳转”、“点踩”事件埋点。
- 阈值设定:设定 PMF 阈值。例如,当答案采纳率 > 40% 且 负反馈率 < 5% 时,视为初步 PMF 达成。
- 用户访谈:对点踩用户进行回访,收集具体的“幻觉”案例,用于微调 RAG 检索策略。
三、商业回本指标设计方案:算清 Token 账
作为前内核开发者,我习惯用资源调度视角来看待商业模型。AI 搜索的商业化核心在于平衡“用户体验(生成质量)”与“算力成本(Token 支出)”。
3.1 单位经济模型 (Unit Economics)
我们需要建立一个公式来计算单用户生命周期价值 (LTV) 与获客成本 (CAC) 的比率,同时引入 Token 成本系数。
$$ LTV_{AI} = (ARPU \times Retention) - (Avg_Token_Cost \times Price_Per_Token) $$
其中:
- ARPU:每用户平均收入(订阅费或广告收入)。
- Retention:用户留存周期。
- Avg_Token_Cost:单次会话平均消耗 Token 数。
- Price_Per_Token:模型供应商的单价(如 $0.0001 / 1K tokens)。
3.2 成本控制策略
在内核优化中,我们通过减少中断来降低开销。在 AI 搜索中,我们通过优化 Prompt 和缓存来降低 Token 消耗。
- 结果缓存 (Result Caching):对于高频重复查询(如“今天天气”、“公司股价”),直接返回缓存结果,不调用 LLM。
- 小模型路由 (Small Model Routing):简单问题使用 7B 参数模型,复杂问题使用 70B 参数模型。
- Prompt 压缩:精简 System Prompt,去除冗余指令,减少输入 Token。
- 流式输出优化:前端先展示部分结果,若用户中途关闭,后端及时终止推理,节省算力。
- 用户分级:免费用户限制每日 Token 额度,付费用户享受无限或高优先级队列。
四、实战落地:指标监控与成本分析脚本
为了将上述理论落地,我们需要一套可执行的监控方案。以下是一个基于 Shell 和 Python 的简易脚本,用于模拟计算每日的 Token 成本与 ROI 校验。
4.1 场景说明
假设我们运营一个 AI 搜索 SaaS 服务,需要每日监控 Token 消耗是否超出预算,并计算当日 ROI。
4.2 监控脚本示例
#!/bin/bash
# ai_search_cost_monitor.sh
# 功能:每日监控 AI 搜索 Token 消耗与预估收入,计算 ROI
# 配置参数
TOKEN_PRICE_PER_1K=0.0005 # 每 1K Token 成本 (美元)
ARPU_DAILY=0.50 # 每用户日均收入 (美元)
BUDGET_LIMIT=5000 # 每日成本预算上限 (美元)
# 模拟数据获取 (实际场景中应从数据库或 API 获取)
TOTAL_SESSIONS=$(cat /var/log/ai_search/sessions_count.txt)
AVG_TOKEN_PER_SESSION=2000 # 平均每次会话消耗 Token
# 计算总消耗
TOTAL_TOKENS=$((TOTAL_SESSIONS * AVG_TOKEN_PER_SESSION))
TOTAL_COST=$(echo "scale=2; $TOTAL_TOKENS * $TOKEN_PRICE_PER_1K / 1000" | bc)
TOTAL_REVENUE=$(echo "scale=2; $TOTAL_SESSIONS * $ARPU_DAILY" | bc)
# 计算 ROI
if [ "$TOTAL_COST" -gt 0 ]; then
ROI=$(echo "scale=2; $TOTAL_REVENUE / $TOTAL_COST" | bc)
else
ROI=0
fi
# 输出报告
echo "=========================================="
echo "AI 搜索每日成本与 ROI 分析报告"
echo "日期:$(date +%Y-%m-%d)"
echo "=========================================="
echo "总会话数:$TOTAL_SESSIONS"
echo "总 Token 消耗:$TOTAL_TOKENS"
echo "预估总成本:\$$TOTAL_COST"
echo "预估总收入:\$$TOTAL_REVENUE"
echo "当前 ROI:$ROI"
echo "=========================================="
# 预算预警
if (( $(echo "$TOTAL_COST > $BUDGET_LIMIT" | bc -l) )); then
echo "[WARNING] 成本超出预算上限 (\$$BUDGET_LIMIT)!"
echo "建议:立即触发限流策略或切换至小模型路由。"
# 模拟触发告警命令
# curl -X POST http://internal-alert-system/webhook -d '{"msg": "Cost Overrun"}'
else
echo "[OK] 成本控制在预算范围内。"
fi
4.3 数据埋点与日志分析
在后端日志中,我们需要记录每一次推理的详细元数据,以便后续分析。
# logger_config.py
import logging
import json
def log_inference_event(session_id, query, token_input, token_output, latency_ms, citation_count):
"""
记录 AI 搜索推理事件,用于后续 PMF 与成本分析
"""
event_data = {
"timestamp": time.time(),
"session_id": session_id,
"query_hash": hash(query), # 脱敏处理
"tokens": {
"input": token_input,
"output": token_output,
"total": token_input + token_output
},
"performance": {
"latency_ms": latency_ms,
"ttft_ms": latency_ms * 0.3 # 模拟首字延迟
},
"quality": {
"citation_count": citation_count,
"user_feedback": None # 待用户交互后更新
}
}
# 写入 JSON 日志文件,便于 ELK 或 Splunk 采集
with open('/var/log/ai_search/inference_events.jsonl', 'a') as f:
f.write(json.dumps(event_data) + '\n')
4.4 最佳实践清单
- 建立基线:上线前必须跑通基准测试,确定不同模型在不同问题类型下的 Token 消耗基线。
- 动态熔断:当 ROI 低于 1.0 时,自动触发熔断机制,暂停非核心功能的 AI 生成,降级为传统搜索。
- 用户教育:在产品界面明确告知用户“生成内容可能包含错误”,降低法律与声誉风险。
- 持续评估:每周进行一次人工抽检,评估答案的准确性和引用质量,防止模型漂移。
- 成本分摊:将 Token 成本精确分摊到每个功能模块,识别出“高成本低价值”的功能并及时砍掉。
五、总结与展望
工作也要流程化,PMF 校验就像是系统中的中断处理机制,它确保了产品能够及时响应市场的真实需求,而不是在自嗨中消耗资源。在实际应用中,我们需要精细化的成本核算与动态的资源调度,以实现系统的最佳性能和可靠性。
这就是生机所在,通过深入理解和应用 AI 搜索技术,我们不仅可以构建更高效、更可靠的系统,也可以从中汲取企业管理的智慧,为创业之路增添一份技术的力量。
创业是一场长跑,PMF 校验与商业回本只是其中的一个环节。但恰恰是这些细节,决定了产品从优秀到卓越的跨越。希望今天的分享能给同样在 AI 创业路上的你一些启发。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 1
1 0
0- 0



 已为社区贡献60条内容
已为社区贡献60条内容

所有评论(0)