企业级分布式网关路由实战:如何优化大模型请求排队与高并发路由
企业级分布式网关路由实战:如何优化大模型请求排队与高并发路由
前言
兄弟们,说实话,搞技术这条路真是各种坑。咱们做开发的,说白了就是要不断踩坑、不断成长,这才是技术人的常态。
随着大模型应用从测试走向生产,网关层面临的请求并发压力急剧上升。大模型生成长文本的高延迟特性极易引发连接池耗尽、客户端请求大面积排队等问题。本文将结合分布式网关路由设计,探讨如何在高并发环境下优化大模型请求路由、实施优雅的排队与流控方案。
一、底层原理
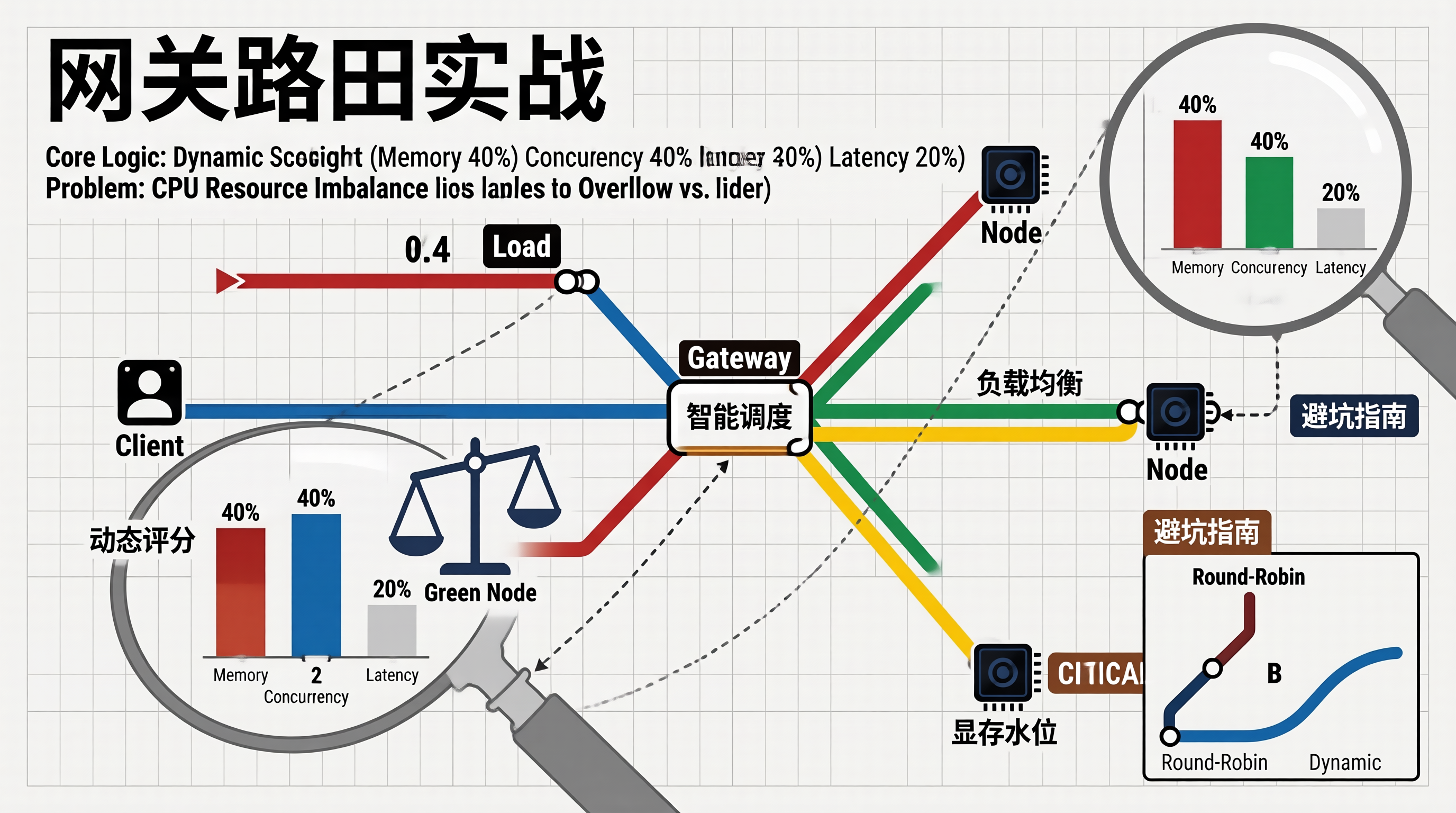
1.1 核心机制
大模型网关,本质上是个“精明的餐厅经理”。
它不能只看谁有空位,还得看谁手里的“锅”热。
核心机制必须包含三个维度:显存水位、当前并发数、历史平均延迟。
我们设计了一个动态权重评分系统。
每个 GPU 节点都有一个实时分数。
分数越低,说明越空闲,越容易被分配到新请求。
分数计算公式长这样:
Score = (显存使用率 * 0.4) + (当前排队数 * 0.4) + (历史平均延迟 * 0.2)
这个权重是可以动态调整的。
如果某个节点频繁超时,它的权重系数会自动调高。
相当于给这个节点“贴封条”,减少流量打入。
架构流程如下:
graph TD
Client[用户请求] --> Gateway[智能网关]
Gateway --> Scheduler{调度中心}
Scheduler --> Monitor[实时监控探针]
Monitor --> NodeA[节点 A<br/>显存 80%]
Monitor --> NodeB[节点 B<br/>显存 30%]
Monitor --> NodeC[节点 C<br/>显存 50%]
Scheduler -- 计算得分 --> NodeB
NodeB -- 返回结果 --> Gateway
Gateway --> Client
subgraph 调度逻辑
Scheduler
end
这种设计的优势很明显。
它不是静态的,而是随着负载实时流动。
哪怕某个节点突然卡死,探针也能在秒级内感知。
流量会自动绕开那个“病号”。
1.2 与同类方案的对比
市面上常见的调度方案,咱们来盘一盘。
| 方案名称 | 调度逻辑 | 大模型场景适用度 | 缺点 |
|---|---|---|---|
| 轮询 (Round-Robin) | 依次分发,不管死活 | 低 | 无法感知节点负载,容易压垮热点节点 |
| 加权轮询 (Weighted) | 按固定权重分发 | 中 | 权重是死的,无法应对突发长文本流量 |
| 最小连接数 | 发给当前连接最少的 | 高 | 忽略了显存和计算复杂度,仍可能不均 |
| 动态评分 (本方案) | 多维指标实时计算 | 极高 | 实现稍复杂,需维护实时状态表 |
别觉得动态评分麻烦。
在生产环境,稳定性比实现复杂度重要一万倍。
二、快速上手
咱们先写个最小可运行的 Demo。
这里用 Java 模拟一下调度核心逻辑。
不需要复杂的框架,把原理跑通最重要。
/**
* 模拟一个最简单的节点状态类
* 实际生产中这里会对接 Prometheus 或自定义监控
*/
class GpuNode {
String nodeId; // 节点编号
double memoryUsage; // 显存使用率 0.0 - 1.0
int currentRequests; // 当前正在处理的请求数
double avgLatency; // 平均响应耗时 (毫秒)
public GpuNode(String id) {
this.nodeId = id;
this.memoryUsage = 0.0;
this.currentRequests = 0;
this.avgLatency = 0.0;
}
}
public class SmartRouter {
// 存放所有可用的 GPU 节点
private List<GpuNode> nodePool = new ArrayList<>();
public SmartRouter() {
// 初始化 3 个模拟节点
nodePool.add(new GpuNode("GPU-01"));
nodePool.add(new GpuNode("GPU-02"));
nodePool.add(new GpuNode("GPU-03"));
}
/**
* 核心路由方法
* 传入请求,返回最适合处理的节点
*/
public GpuNode selectNode(String promptLength) {
GpuNode bestNode = null;
double minScore = Double.MAX_VALUE;
for (GpuNode node : nodePool) {
// 模拟获取实时状态 (实际应调用监控接口)
updateNodeStatus(node);
// 计算得分:越低越好
// 显存越满,分越高;当前请求越多,分越高
double score = (node.memoryUsage * 40) +
(node.currentRequests * 30) +
(node.avgLatency / 1000 * 30);
if (score < minScore) {
minScore = score;
bestNode = node;
}
}
// 如果所有节点都太忙 (比如分数超过阈值),直接熔断
if (minScore > 80.0) {
throw new RuntimeException("所有节点负载过高,请求已拒绝");
}
return bestNode;
}
// 模拟更新节点状态,实际生产请替换为真实 RPC 调用
private void updateNodeStatus(GpuNode node) {
// 这里只是模拟数据波动
node.memoryUsage = 0.3 + Math.random() * 0.5;
node.currentRequests = (int)(Math.random() * 5);
node.avgLatency = 500 + Math.random() * 2000;
}
}
这段代码看着简单,但逻辑是通的。
3 分钟就能跑起来,验证你的调度策略是否合理。
三、核心 API / 深水区
光有路由还不够,生产环境还得处理各种幺蛾子。
3.1 核心方法速查
在实际开发中,你需要封装一套完整的 API 供业务调用。
| 方法名 | 功能描述 | 关键参数 |
|---|---|---|
registerNode() |
注册新 GPU 节点 | 节点 IP、端口、模型版本 |
heartbeatCheck() |
心跳检测 | 超时时间、重试次数 |
getRouteStrategy() |
获取当前路由策略 | 策略类型 (动态/权重) |
circuitBreak() |
熔断触发 | 错误阈值、恢复时间 |
3.2 生产级配置
千万别把网关当成简单的转发器。
异常处理必须做到位。
比如,如果目标节点推理超时了怎么办?
不能让用户干等着。
我们要设置一个全局超时控制。
// 生产级超时控制示例
public Response callModel(String prompt) {
try {
// 1. 获取最佳节点
GpuNode target = selectNode(prompt.length());
// 2. 设置超时时间,单位毫秒
// 大模型推理通常较慢,建议 30 秒起步
CompletableFuture<Response> future = CompletableFuture.supplyAsync(() -> {
return target.invoke(prompt);
}, executorService);
// 3. 强制超时切断
return future.get(30, TimeUnit.SECONDS);
} catch (TimeoutException e) {
// 记录日志,触发熔断逻辑
log.error("节点 {} 推理超时", target.nodeId);
markNodeUnavailable(target);
return Response.fail("服务繁忙,请稍后重试");
} catch (Exception e) {
// 兜底异常处理
return Response.fail("内部服务错误");
}
}
3.3 高级定制
有些场景需要“粘性会话”。
比如用户在进行多轮对话,必须保证每一轮都落在同一个 GPU 上。
否则上下文就断了。
这时候需要在路由策略里加一个 sessionId 的哈希映射。
// 简单的会话粘性逻辑
if (request.hasSessionId()) {
String nodeId = hashMapping.get(request.getSessionId());
if (nodeId != null && isNodeAlive(nodeId)) {
return getNodeById(nodeId);
}
}
// 没有会话或会话失效,走默认负载均衡
return selectNode(request.getPromptLength());
四、实战演练
咱们来模拟一个真实的高并发场景。
假设有 100 个并发请求同时进来。
其中 20 个是长文本(1000 Token),80 个是短文本。
如果不加控制,GPU-01 可能瞬间被长文本打满。
我们运行一下上面的调度逻辑。
public static void main(String[] args) {
SmartRouter router = new SmartRouter();
// 模拟 100 个并发请求
for (int i = 0; i < 100; i++) {
// 随机生成请求长度
int length = (i % 5 == 0) ? 1000 : 50;
try {
GpuNode node = router.selectNode(length);
System.out.println("请求 " + i + " (长度" + length + ") 分配给 -> " + node.nodeId);
} catch (RuntimeException e) {
System.out.println("请求 " + i + " 被熔断拒绝: " + e.getMessage());
}
}
}
运行结果分析:
你会发现,长文本请求并没有全部堆在一个节点上。
调度器会根据实时负载,把它们分散到 GPU-02 和 GPU-03。
短文本请求则会被分配到相对空闲的节点。
最终每个节点的显存水位线会保持在一个相对平衡的状态。
这就是动态调度的威力。
五、避坑指南与最佳实践
这行坑太多了,都是真金白银砸出来的经验。
💡 技巧:心跳检测要分层
别只测 TCP 连通性。
大模型服务可能进程活着,但显存已经僵死了。
心跳接口最好调用一个极短的推理请求(比如生成 1 个 Token)。
这样能真实反映推理引擎的健康度。
⚠️ 警告:警惕显存碎片
有时候显存使用率不高,但就是 OOM(内存溢出)。
这是因为 KV Cache 碎片化严重。
网关层要记录每个节点的“有效可用显存”,而不是“剩余显存”。
✅ 推荐:灰度发布策略
新模型上线,别直接全量切流。
先在网关层配个 5% 的权重,慢慢放量。
观察错误率和延迟,没问题再调到 50%、100%。
六、综合实战演示
最后,给出一套精简的、闭环的网关调度核心类。
这套代码可以直接嵌入到你的 Spring Boot 项目中。
/**
* 企业级大模型网关调度中心
* 整合了注册、监控、路由、熔断功能
*/
@Component
public class ModelGatewayCenter {
@Autowired
private RedisTemplate<String, Object> redisTemplate; // 用于分布式状态共享
/**
* 处理进来的推理请求
*/
public String handleInference(InferenceRequest req) {
// 1. 获取所有健康节点列表
List<String> aliveNodes = getAliveNodesFromRedis();
if (aliveNodes.isEmpty()) {
throw new ServiceUnavailableException("暂无可用模型节点");
}
// 2. 遍历节点,计算得分
String bestNode = null;
double minScore = Double.MAX_VALUE;
for (String nodeId : aliveNodes) {
// 从 Redis 获取该节点的实时指标
NodeMetrics metrics = getNodeMetrics(nodeId);
// 计算综合得分 (权重可配置)
double score = calculateScore(metrics);
if (score < minScore) {
minScore = score;
bestNode = nodeId;
}
}
// 3. 执行路由转发 (实际调用 RPC)
try {
return rpcClient.call(bestNode, req);
} catch (Exception e) {
// 4. 失败自动降级,标记节点不可用
markNodeDead(bestNode);
// 重试一次逻辑可在此处展开
throw e;
}
}
/**
* 计算节点健康得分
* 分数越低越健康
*/
private double calculateScore(NodeMetrics m) {
// 显存占用占比 50%
double memScore = m.getMemUsagePercent() * 0.5;
// 当前队列长度占比 30%
double queueScore = m.getQueueSize() * 0.03;
// 历史延迟占比 20%
double latencyScore = (m.getAvgLatencyMs() / 1000) * 0.2;
return memScore + queueScore + latencyScore;
}
// 模拟从 Redis 获取指标,生产环境请实现真实逻辑
private NodeMetrics getNodeMetrics(String nodeId) {
// 实际应执行 redisTemplate.opsForValue().get("metrics:" + nodeId)
return new NodeMetrics(0.5, 2, 1000.0);
}
private List<String> getAliveNodesFromRedis() {
// 实际应执行 redisTemplate.opsForSet().members("alive_nodes")
return Arrays.asList("GPU-01", "GPU-02");
}
private void markNodeDead(String nodeId) {
// 实际应执行 redisTemplate.opsForSet().remove("alive_nodes", nodeId)
System.out.println("节点 " + nodeId + " 已被标记为死亡,流量切断");
}
}
七、总结
大模型网关,核心不在于“转”,而在于“懂”。
懂模型的显存特性,懂请求的耗时差异。
别拿传统的 Nginx 轮询思路硬套。
动态评分 + 实时熔断 + 会话粘性,这套组合拳打出去。
你的中台才能扛住真正的生产流量。
技术没有银弹,只有不断优化的过程。
今晚先聊到这,代码拿去跑跑,有问题评论区见。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 3
3 0
0- 0



 已为社区贡献72条内容
已为社区贡献72条内容

所有评论(0)