什么是 Context Engineering?——比 Prompt Engineering 更接近生产力的核心能力
前言
很多人刚开始用大模型时,最熟悉的词是 Prompt Engineering:怎么写提示词、怎么组织指令、怎么让模型更听话。
但一旦你开始做 RAG、做 AI Agent、做代码助手,很快就会遇到一个更本质的问题:模型不是不知道怎么回答,而是不知道此刻应该基于什么信息回答。
这时,真正决定效果的,往往不再是提示词本身,而是上下文构造能力。这就是 Context Engineering。
目录
三、为什么 Context Engineering 比你想象中更重要?
五、Context Engineering 和 Prompt Engineering 有什么区别?
1. Prompt Engineering 解决“怎么说”,Context Engineering 解决“给什么”
2. Prompt 更像话术优化,Context 更像信息系统设计
七、在 RAG 和 Agent 里,Context Engineering 长什么样?
八、为什么说 Context Engineering 更接近系统能力?
九、一个常见误区:Context Engineering 不是“塞更多上下文”
十、Context Engineering 的本质:为模型设计工作记忆
一、为什么 Prompt 写得再好,也可能不够?
1. 场景:模型很强,但还是答不对
假设你做了一个代码助手,用户问:
“为什么这个接口一直返回 500?”
你给模型写了一个很清楚的 Prompt:
- 让它分析问题;
- 让它给出根因;
- 让它不要胡乱猜测;
- 让它基于证据回答。
Prompt 看起来没有问题,但模型最后还是可能答偏。为什么?
因为它可能根本没看到真正关键的信息:
- 它没读到报错日志;
- 它没看到最近的提交记录;
- 它不知道这条接口依赖哪个配置;
- 它拿到的是旧版本代码;
- 它甚至没看到相关测试或调用链。
也就是说,问题并不在于“你怎么问”,而在于“你给了它什么材料”。
2. 模型的很多错误,本质上是上下文错误
在真实工程场景里,大模型出错很常见,但错误往往不只是“理解错了 Prompt”,更常见的是:
- 缺上下文:关键材料没给到;
- 脏上下文:混入了无关甚至误导信息;
- 过载上下文:给得太多,信噪比太差;
- 错时上下文:信息本身没错,但给的时机不对;
- 错形态上下文:模型拿到了信息,但形式不利于推理。
这些问题说明,单靠 Prompt Engineering 已经不足以解释大模型系统的好坏。
当系统进入真实任务场景时,上下文不再只是“输入的一部分”,而是系统设计的核心。
二、什么是 Context Engineering?
1. 一句话定义
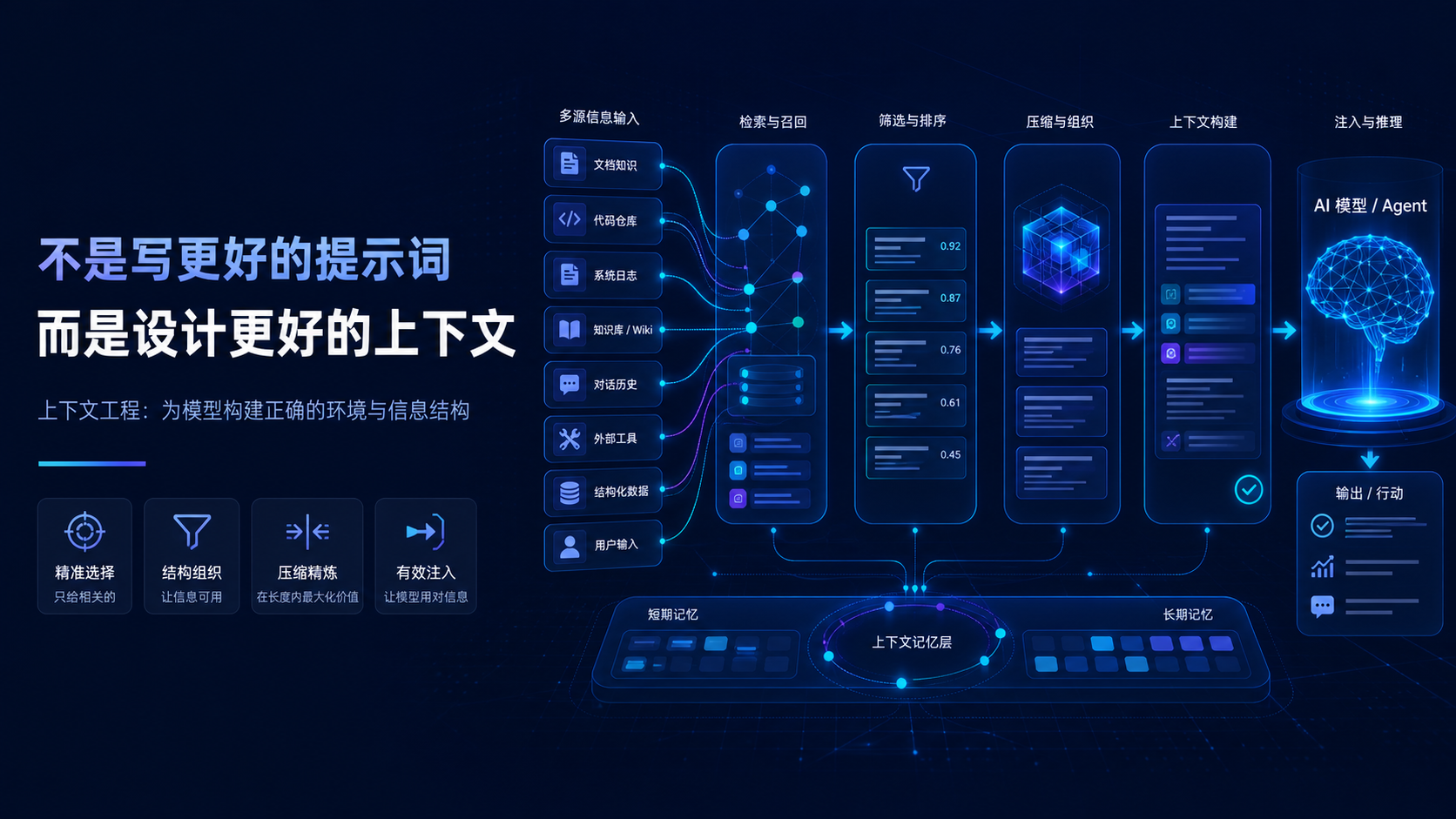
Context Engineering,就是围绕模型任务需求,系统性地收集、筛选、组织和提供上下文的工程能力。
它关心的不是“怎么写一句更漂亮的提示词”,而是:
- 现在这个任务到底需要哪些信息?
- 这些信息从哪里来?
- 哪些该给,哪些不该给?
- 应该按什么顺序给?
- 应该用什么结构给?
- 应该在哪一步给?
从这个角度看,Context Engineering 解决的是:
如何让模型在正确的信息基础上工作。
2. 它处理的不是“语言表达”,而是“认知输入”
Prompt Engineering 更多处理的是表达问题:你怎么描述任务、怎么约束模型、怎么控制输出。
Context Engineering 处理的则是认知问题:
模型要完成任务,它到底需要知道什么。
例如一个问题看似简单:
“这段逻辑为什么有 bug?”
在不同场景里,模型真正需要的上下文可能完全不同:
- 如果是代码调试,它需要相关文件、调用链、报错信息、最近变更;
- 如果是产品逻辑,它需要需求背景、用户预期、业务规则;
- 如果是线上故障,它需要日志、监控、配置、依赖状态。
所以,Context Engineering 的本质不是“多塞一些内容”,而是为当前任务构建最有用的认知输入环境。
三、为什么 Context Engineering 比你想象中更重要?
1. 因为模型不会自己“补齐现实世界”
很多人会默认觉得,大模型足够聪明,看到一部分信息就能推出来剩下的部分。
这在开放问答里有时成立,但在工程场景里往往不成立。因为模型不知道那些没有被显式提供的现实事实:
- 哪个文件是当前生效版本;
- 哪条规则是最新业务规则;
- 哪个日志是刚刚产生的;
- 这段代码是不是刚改过;
- 用户是不是有权限访问某个资源;
- 这个错误是不是已经被上游修过。
这些信息如果没进上下文,模型就只能猜。而工程系统最怕的,就是在缺事实时“猜得很像真的”。
2. 因为生产问题通常不是“不会回答”,而是“拿错材料”
在真实项目里,模型效果差经常不是因为模型太弱,而是因为上下文构造不好。例如:
- RAG 检索召回了不相关 chunk;
- Agent 没拿到任务约束;
- Coding assistant 读了错的目录;
- 知识库问答混入了旧版本规则;
- 多轮对话里保留了太多历史噪音。
这类问题,你再怎么调 Prompt,也只能缓解一部分,根本原因仍然在上下文工程上。
3. 因为上下文决定了模型“能看到的世界”
对模型来说,上下文就是它当前的世界模型边界。
你给它什么,它就只能在什么范围内推理;
你不给它什么,它就不可能基于那部分事实做判断。
所以很多时候,Prompt 像是在指导模型思考,
而 Context Engineering 像是在决定模型能思考什么。
这就是它比单纯 Prompt Engineering 更接近生产能力的原因。
四、Context Engineering 到底在做什么?
1. 不是简单拼接信息,而是做信息编排
很多人理解上下文工程时,容易把它想成“把相关材料都塞进去”。
但真正有效的 Context Engineering 远不止于此。
它通常包括四个动作:
- 收集:从工具、文档、日志、数据库、代码库等位置拿信息;
- 筛选:判断哪些信息和当前任务真正相关;
- 组织:把信息按模型容易理解的结构排列;
- 注入:在正确时机,以正确方式交给模型。
也就是说,Context Engineering 更像信息编排,而不是文本堆叠。
2. 它关心“什么该给”,也关心“什么不该给”
一个常见误区是:上下文越多越好。
事实上,很多系统效果变差,恰恰是因为给了太多不必要的信息。
例如在代码排障场景里:
- 给整仓库不如给关键模块;
- 给全部日志不如给相关时间窗口;
- 给所有历史对话不如给与当前任务直接相关的结论;
- 给完整文档不如给结构化摘要 + 原文片段。
好的上下文工程不是最大化信息量,而是最大化有效信息密度。
3. 它还关心“何时给、怎么给”
同样一份信息,放在不同阶段、用不同格式给模型,效果可能完全不同。
例如:
- 在任务开始时给系统约束;
- 在分析阶段给相关证据;
- 在决策阶段给候选方案;
- 在输出阶段给格式要求。
再比如同一份材料:
- 原始日志适合取证;
- 提炼后的摘要适合理解;
- 结构化字段适合对比;
- 时间线适合排障。
所以 Context Engineering 不只是内容选择问题,也是时序设计和表示设计问题。
五、Context Engineering 和 Prompt Engineering 有什么区别?
1. Prompt Engineering 解决“怎么说”,Context Engineering 解决“给什么”
这是两者最核心的区别。
- Prompt Engineering:强调任务指令、角色设定、约束表达、输出格式;
- Context Engineering:强调事实输入、信息筛选、上下文组织、时机控制。
可以简单类比为:
- Prompt 是你对模型说的话;
- Context 是模型在听你说话之前,已经被放到它面前的材料。
没有好的 Prompt,模型可能不知道你想让它做什么;
没有好的 Context,模型可能连做判断的依据都没有。
2. Prompt 更像话术优化,Context 更像信息系统设计
Prompt 优化经常带有“语言技巧”色彩:怎么措辞、怎么分段、怎么强调重点。
而 Context Engineering 更偏工程问题:
- 数据从哪来;
- 如何检索;
- 如何裁剪;
- 如何压缩;
- 如何排序;
- 如何跨步骤传递;
- 如何避免上下文污染。
所以,当系统从“演示用模型”走向“生产用 agent”,Context Engineering 的重要性会迅速上升。
3. 很多所谓的“模型不行”,其实是上下文系统不行
一个很现实的判断标准是:
如果你换个模型,效果提升有限;
但你换一种上下文构造方式,效果明显变好——
那问题大概率不在模型,而在上下文工程。
这也是为什么在很多成熟 AI 系统里,真正的竞争力不一定是“谁的 Prompt 更花”,而是“谁的上下文系统设计得更对”。
六、Context Engineering 的几个核心问题
1. 相关性:哪些信息和当前任务真正有关?
这是最基础、也最难的问题。
例如用户问:
“这个接口为什么超时?”
理论上相关的信息可能包括:
- 接口代码;
- 调用下游的逻辑;
- 最近的超时日志;
- 依赖服务状态;
- 相关配置;
- 最近一次改动记录。
但并不是每个任务都需要把这些全给。
Context Engineering 的第一层能力,就是判断当前任务的上下文边界。
2. 粒度:给文档、给摘要,还是给片段?
信息的粒度非常关键。
- 粒度太粗:上下文冗长、噪音大;
- 粒度太细:模型看不到完整语义;
- 粒度不稳:模型容易误判信息重要性。
这和 RAG 中的 chunking 很像:不是把内容切出来就够了,还要考虑它是否适合成为推理单元。
3. 时序:信息应该在哪一步进入?
并不是所有上下文都应该在一开始就提供。
一个更好的方式通常是分阶段注入:
- 先给任务目标和边界;
- 再给候选证据;
- 再根据模型中间判断,补充下一层上下文;
- 最后才给输出要求和格式约束。
这种“按步骤供给上下文”的方式,在 agent 系统中尤其重要。
4. 压缩:如何在有限窗口内保留最大价值?
上下文窗口始终有限,哪怕模型窗口变大,这个问题也不会消失。
因为真正的约束不只是“装不装得下”,还包括:
- 成本;
- 延迟;
- 推理稳定性;
- 干扰项控制。
所以 Context Engineering 往往要做大量压缩工作,例如:
- 摘要历史;
- 合并重复信息;
- 去掉无关片段;
- 提取结构化关键点;
- 用元数据代替大段原文。
七、在 RAG 和 Agent 里,Context Engineering 长什么样?
1. 在 RAG 里:它决定检索结果是否真的可用
RAG 看起来像“检索 + 生成”,但真正效果好的 RAG 系统,本质上都在做 Context Engineering。
例如一个成熟的 RAG 系统通常不会只做:
- 检索 Top-K 文本;
- 直接拼给模型。
它还会做很多上下文层面的设计:
- 根据 query 类型选择不同召回策略;
- 对结果做 rerank;
- 去重和去噪;
- 按文档结构重组;
- 把片段补齐为可理解语义单元;
- 给每段上下文加来源、时间、标题等元信息。
也就是说,RAG 的竞争力很大一部分不在“能不能检索”,而在“检索出来的内容能不能成为高质量上下文”。
2. 在 Agent 里:它决定任务链条能不能持续推进
Agent 系统的上下文问题更复杂,因为它不是一次注入,而是动态变化的。
一个 agent 在执行任务时,可能不断产生新的上下文:
- 刚读取的文件;
- 刚调用的工具结果;
- 中间推理结论;
- 执行失败信息;
- 用户补充约束;
- 状态更新。
这些信息如果不做管理,系统很快就会出现:
- 上下文过载;
- 关键结论丢失;
- 历史噪音堆积;
- 前后判断不一致。
所以 Agent 里的 Context Engineering,往往同时涉及:
- 状态记忆;
- 历史摘要;
- 工具输出筛选;
- 多步任务上下文拼装;
- 长流程中的上下文裁剪。
八、为什么说 Context Engineering 更接近系统能力?
1. 因为它直接连接模型与现实世界
Prompt 主要发生在模型内部交互层;
Context Engineering 则发生在模型与外部系统的交界处。
它要处理的是:
- 文档;
- 数据库;
- 日志;
- 代码库;
- 工具调用结果;
- 用户状态;
- 历史任务记录。
这些都不是“写一句话”能解决的,而是完整系统设计问题。
2. 因为它天然涉及架构、数据流和运行时策略
一旦认真做 Context Engineering,你就会发现它已经不只是 NLP 问题,而是软件工程问题:
- 如何构建信息通道;
- 如何管理上下文生命周期;
- 如何定义状态边界;
- 如何做缓存和失效;
- 如何避免脏数据污染;
- 如何控制不同阶段的上下文预算。
从这个角度看,Context Engineering 更像是 LLM 时代的运行时信息架构。
3. 因为它比模型本身更难被直接替代
模型在进步,窗口会变大,推理会增强。
但只要模型仍然无法自己接触真实世界,它就仍然需要一个系统去决定:
- 给它看什么;
- 什么时候看;
- 以什么形式看;
- 哪些不该看。
这也是为什么,随着模型变强,Context Engineering 不会消失,反而会更重要。
九、一个常见误区:Context Engineering 不是“塞更多上下文”
这是最值得单独强调的一点。
很多团队一开始做上下文优化时,会本能地认为:
模型答不对,那就再多给一点材料。
但现实里,更多上下文经常意味着:
- 更高成本;
- 更长延迟;
- 更多噪音;
- 更弱聚焦;
- 更不稳定的回答。
所以 Context Engineering 的目标,从来不是“让上下文变多”,而是:
让上下文变得更准、更干净、更有结构、更符合当前任务。
从某种意义上说,它是在做“认知带宽管理”。
十、Context Engineering 的本质:为模型设计工作记忆
如果把模型类比成人,那么 Context Engineering 做的事情,其实很像为一个高能力但短时记忆有限的专家设计工作台。
这个工作台要解决的问题是:
- 先把哪些材料摆上来?
- 哪些材料要放在最显眼的位置?
- 哪些需要折叠成摘要?
- 哪些应该暂时收起来,避免干扰?
- 哪些是背景知识,哪些是当前证据?
- 当任务推进时,工作台上的内容该如何更新?
这个比喻很重要,因为它说明:
Context Engineering 不是在给模型喂文本,而是在给模型搭工作记忆。
而工作记忆设计得好不好,直接决定了模型是像一个有条理的专家,还是像一个被资料淹没的实习生。
结语
在大模型应用的早期阶段,Prompt Engineering 足以解决很多问题,因为那时大家主要在探索“怎么和模型沟通”。
但当系统进入 RAG、Agent、代码助手、自动化工作流这些更复杂的场景后,真正拉开差距的,往往不再是提示词技巧,而是:
- 你如何收集上下文;
- 如何筛选上下文;
- 如何组织上下文;
- 如何在动态任务中持续管理上下文。
这就是 Context Engineering 的意义。
如果说 Prompt Engineering 解决的是“你怎么对模型说”,
那么 Context Engineering 解决的就是“你让模型基于什么世界来思考”。
而在生产环境里,后者往往更决定系统上限。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 7
7 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)