计算机毕业设计之基于LSTM的新闻情感分析应用
本研究设计并实现了一个基于长短期记忆网络(LSTM)的新闻情感分析应用,旨在自动识别和分类新闻文本及评论的情感倾向。该应用包含管理员端和用户端,分别服务于平台管理和用户交互。管理员端具备系统首页、用户管理、新闻信息管理、评论信息管理、情感分析管理、评论预测管理以及个人中心等功能模块,支持对用户、新闻及评论数据的全面管理,并能监控情感分析模型的运行状态和预测效果。用户端则提供系统首页、新闻信息浏览、评论信息查看、情感分析结果展示、评论预测以及个人中心等功能,使用户能够便捷地获取新闻内容、发表评论,并实时查看情感分析结果和预测的评论倾向。
在技术实现上,本研究采用LSTM模型来捕捉新闻文本中的上下文信息和时间序列特征,通过训练数据集进行模型训练和优化,最终实现对新闻及评论情感的准确分类。实验结果表明,该应用能够有效识别积极、消极和中性情感,为用户提供了有价值的情感参考,并帮助管理员更好地理解用户反馈和市场趋势。该应用的成功开发不仅提升了新闻平台的互动性和用户体验,也为情感分析技术在新闻领域的应用提供了新的思路和实践案例。未来,随着模型的不断优化和用户数据的积累,该应用将进一步提升情感分析的准确性和可靠性,为新闻媒体和社交媒体的情感分析提供有力支持。
基于LSTM的新闻情感分析应用系统,如图所示,主要包括以下几个部分:
数据采集:系统首先需要从腾讯新闻社交媒体平台抓取海量新闻数据。这通常涉及到编写爬虫程序来模拟浏览器行为,访问目标网站,解析网页内容,并下载所需的数据。为了提高效率,可能还需要采用分布式爬虫架构和多线程等技术手段。
数据处理:由于原始数据往往存在噪声和不完整等问题,因此需要对数据进行清洗和预处理。这可能包括去除重复项、填充缺失值、统一格式化文本等步骤。此外,为了提高后续分析的准确性,还需要对数据进行特征工程,例如提取关键词、计算TF-IDF权重等。
LSTM模型训练:利用处理好的数据集,项目可以开始训练LSTM模型了。首先需要定义网络的层数、每层的神经元数量以及激活函数类型等超参数。然后使用梯度下降法最小化损失函数,并通过反向传播算法更新网络权重。经过多次迭代后,当模型达到预定精度要求时即可停止训练。
评论预测:除了对单篇新闻进行分类外,还可以利用LSTM模型的时间序列特性来预测一段时间内某个特定话题的热度变化情况。
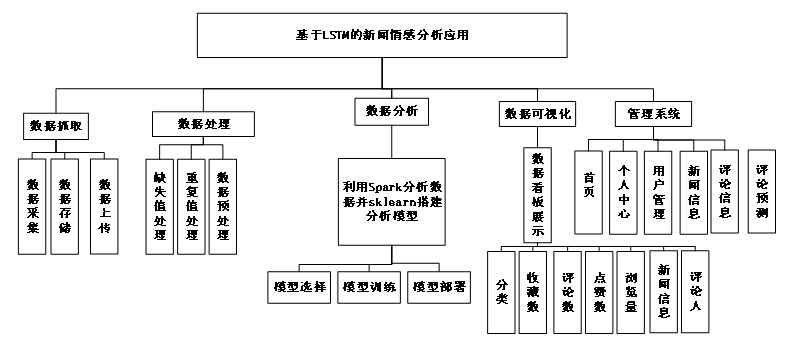
图3-1 系统功能模块图
管理员在点击新闻信息管理模块可以看到分类、标题、图片、地址等信息,可以对其进行查看、添加、删除、修改、数据爬取等操作,数据爬取采用Python的爬虫框架,Scrapy结合HTTP请求库从网站等目标源获取数据。爬取过程中,通过设置合理的爬取频率和遵守robots.txt规则,确保数据获取的合法性和效率。获取原始数据后,进入数据清洗阶段,利用Python的Pandas库对数据进行预处理,包括去除空值、异常值,格式统一,以及处理重复数据。此外,通过正则表达式对文本数据进行清洗,提取有用信息。数据清洗还涉及数据类型转换、缺失值填充等操作,确保数据的质量和一致性。最终,清洗后的数据存储于数据库,为后续的数据分析和业务应用提供准确、可靠的数据基础。新闻信息管理模块具体实现图如图5-7所示:
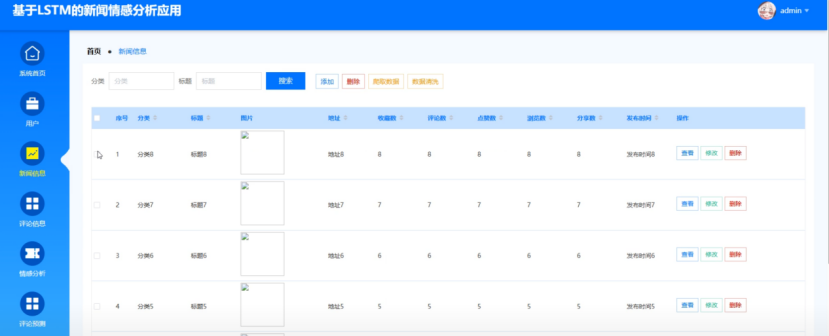
图5-7 新闻信息管理

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 2
2 0
0- 0



 已为社区贡献8条内容
已为社区贡献8条内容

所有评论(0)