扣子工作流踩坑实录:5 个让人崩溃的坑和解决方案
一、先说结论
扣子工作流(Coze)确实降低了 AI 自动化的门槛——拖拽节点、连线、发布,零代码也能跑。但扣子工作流真正从"Hello World"进入到真正有用的场景时,坑就来了。
本文 5 个坑,每个都是我(和社群学员)真实踩过的。不列入门教程(那种文章一搜一大堆),只讲出问题的时候怎么修。
二、坑 1:变量名写错,调试半小时
问题
扣子工作流跑着跑着突然报错:变量未定义。你明明在上一个节点定义了 username,下一个节点引用却找不到。
原因
扣子的变量名区分大小写,而且不同节点的输出变量名由你手动设置,没有自动补全。
| 节点 A 输出 | 节点 B 引用 | 结果 |
|---|---|---|
| userName | username | ❌ 找不到 |
| user_name | user-name | ❌ 找不到 |
| result | Result | ❌ 找不到 |
解决
- 统一命名规范,建议全小写 + 下划线:user_name、ai_response
- 每个节点设置变量名后截图,回头排查时对照
- 扣子工作流跑通后第一时间导出备份,作为"已知正常版本"

三、坑 2:大模型节点输出不稳定
问题
同一个 prompt,有时候返回完美 JSON,有时候返回一段废话,有时候直接超时。扣子工作流下半段依赖这个输出做分支判断,一不稳定全链路崩溃。
原因
扣子的大模型节点调用的是云端模型(GPT / Claude / 豆包等),输出天然有随机性。你没有做输出约束。
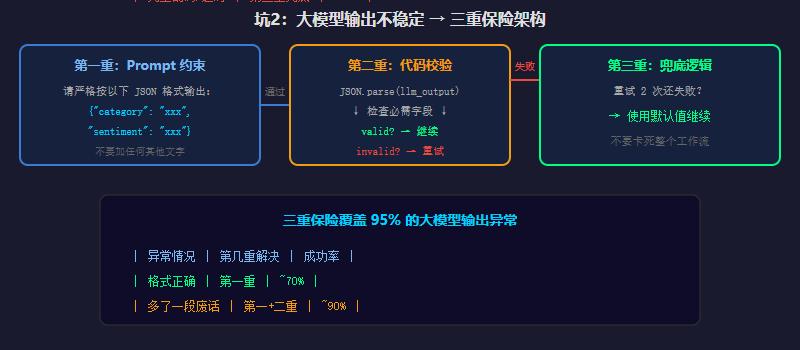
解决:三重保险
第一重:Prompt 加格式约束
不只是说"返回 JSON",要给出具体格式:
你是一个内容分类助手。请严格按以下 JSON 格式输出,不要加任何其他文字:
{
"category": "技术教程",
"sentiment": "正面",
"keywords": ["关键词1", "关键词2"]
}第二重:加代码节点做校验
在大模型节点后接一个代码节点:
// 代码节点:校验大模型输出
try {
const parsed = JSON.parse(llm_output);
if (!parsed.category || !parsed.sentiment) {
return { valid: false, error: "字段缺失", raw: llm_output };
}
return { valid: true, data: parsed };
} catch (e) {
return { valid: false, error: "JSON 解析失败", raw: llm_output };
}第三重:加分支节点做兜底
校验失败 → 触发"重试"分支(重新调用大模型,换个 prompt 角度)。重试 2 次还失败 → 走兜底逻辑(用默认值继续,不要卡死整个工作流)。

四、坑 3:节点执行超时
问题
扣子工作流跑着跑着突然停了,日志显示"节点执行超时"。最常见于大模型节点和 HTTP 请求节点。
原因
扣子工作流对不同节点类型有执行时间上限。大模型节点约 60 秒,HTTP 请求节点约 30 秒。超过直接中断,不会自动重试。
解决
- HTTP 请求节点设置合理的 timeout(建议 15 秒,提前失败好过卡住)
- 如果一次大模型调用可能超时,把长 prompt 拆成两个短 prompt,两个大模型节点串联
- 在代码节点里加超时重试逻辑
// 代码节点:HTTP 请求重试
async function fetchWithRetry(url, options, retries = 2) {
for (let i = 0; i <= retries; i++) {
try {
const controller = new AbortController();
const timeout = setTimeout(() => controller.abort(), 15000);
const resp = await fetch(url, { ...options, signal: controller.signal });
clearTimeout(timeout);
if (resp.ok) return await resp.json();
} catch (e) {
if (i === retries) throw e;
}
}
}五、坑 4:大模型返回的 JSON 解析失败
问题
Prompt 写了"返回 JSON",但大模型偶尔会在 JSON 前后加一段话。比如:
好的,根据你的要求,分类结果如下:
```json
{"category": "技术教程"}希望这对你有帮助!
代码节点 `JSON.parse()` 直接报错。
### 解决
代码节点做**清洗 + 容错**:
```javascript
function extractJSON(text) {
// 1. 去掉 markdown 代码块标记
let cleaned = text.replace(/```json\s*/gi, "").replace(/```\s*/g, "");
// 2. 提取第一个 { 到最后一个 } 之间的内容
const start = cleaned.indexOf("{");
const end = cleaned.lastIndexOf("}");
if (start === -1 || end === -1) return null;
cleaned = cleaned.slice(start, end + 1);
// 3. 尝试解析
try { return JSON.parse(cleaned); } catch { return null; }
}
const result = extractJSON(llm_output);
return result || { error: "JSON 提取失败", raw: llm_output };这个函数能处理 90% 的大模型输出异常。
六、坑 5:并发触发导致的限流
问题
扣子工作流(Coze)被外部触发(比如用户连续点击、定时任务并发),短时间内大量请求涌入,扣子平台返回"请求过于频繁"。
原因
扣子工作流对单个工作流有并发限制。免费版通常 5-10 并发,超过直接拒绝。没有排队机制。
解决
方案 A:加延时节点
在工作流开头加一个延时节点,设置随机 1-3 秒。多个并发请求错开执行时间。
方案 B:代码节点做限流
// 代码节点:简单计数限流
const MAX_CONCURRENT = 3;
const store = globalThis._coze_store || { count: 0, queue: [] };
globalThis._coze_store = store;
store.count++;
if (store.count > MAX_CONCURRENT) {
return { blocked: true, message: "当前并发过高,请稍后重试" };
}
// ... 执行业务逻辑
// 结束后 store.count--方案 C:架构层面用消息队列
如果是生产级应用,不要直接触发扣子工作流。前端请求 → 你的服务器 → 消息队列 → 控制并发 → 逐个触发扣子 API。
七、总结
- 变量命名统一规范,做完截图备份
- 大模型输出做三重保险(Prompt 约束 + 代码校验 + 分支兜底)
- 超时问题用重试 + 拆分 prompt 解决
- JSON 解析做清洗容错,不要信大模型的格式承诺
- 高并发场景用延时 + 限流 + 消息队列三层防护
这 5 个坑修完后,扣子工作流基本就稳了。
📚 相关文章
- 编辑扣子工作流零基础搭建:5 个节点搞定内容生成全流程 — 入门必读
- 编辑AI 聚合平台选型实战:3 个关键维度帮你避开 90% 的坑 — 模型 API 怎么选
参考资料
- 扣子官方文档 — 工作流节点参考
📌 米核 AI 易山联合创始人。想系统学习扣子工作流?全网搜索「米核 AI 易山」,从入门到进阶手把手教。API 聚合平台:miheaii.com
本文部分内容由 AI 辅助完成。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 3
3 0
0- 0



 已为社区贡献27条内容
已为社区贡献27条内容

所有评论(0)