BFM-Zero: 一种用于人形机器人控制的可提示行为基础模型【文献解读】
BFM-Zero: 一种用于人形机器人控制的可提示行为基础模型【文献解读】
论文标题:BFM-Zero: A Promptable Behavioral Foundation Model for Humanoid Control Using Unsupervised Reinforcement Learning
作者:Yitang Li¹, Zhengyi Luo¹, Tonghe Zhang¹, Cunxi Dai¹, Andrea Tirinzoni², Anssi Kanervisto², Haoyang Weng¹, Kris Kitani¹, Mateusz Guzek², Ahmed Touati², Alessandro Lazaric², Matteo Pirotta², Guanya Shi¹
机构:¹Carnegie Mellon University, ²Meta
发表信息:arXiv:2511.04131v1, Nov 6 2025
项目网站:https://lecar-lab.github.io/BFM-Zero/
一、关键科学问题与技术挑战
1.1 核心问题
如何构建一个可提示(promptable)的、能够在真实人形机器人上零样本执行多种下游任务的行为基础模型(Behavioral Foundation Model, BFM)? 本文从无监督强化学习(unsupervised RL)角度出发,解决人形机器人全身上下文中任务统一表示与策略泛化的根本难题。
1.2 技术挑战
-
人形机器人行为基础模型的缺失:在机器人操作领域,视觉-语言-动作(VLA)模型已可通过行为克隆从人类演示中学习通用策略。但对于人形机器人全身上下控,不存在现成的关节级动作标签,也无法通过遥操作大规模采集演示数据。这导致行为基础模型在人形机器人领域的发展严重滞后。
-
现有RL方法的任务特定性与非适应性:当前最先进的人形机器人RL策略(如基于PPO的运动跟踪)存在三大局限:
- 任务特定:每个策略仅针对单个运动捕捉片段或单个任务训练,无法泛化
- 非自适应:训练完成后无法通过微调或组合来执行新任务
- 缺乏统一接口:没有可解释的目标规格化方法,人类操作者难以直接引导机器人
-
无监督RL应用于真实人形机器人的可行性未知:
- 大多数真实机器人部署依赖在线策略(on-policy)训练(主要是PPO),离线无监督RL在真实人形机器人上的应用尚无先例
- 无监督RL算法能否处理sim-to-real差距和动态扰动,在仿真训练和真实推理中保持鲁棒性,尚未被验证
-
仿真到真实的迁移障碍:
- 仿真环境中的特权信息(完整状态)在真实机器人上无法获取
- 物理参数(质量、摩擦、关节偏移等)存在不确定性
- 需要设计合适的奖励正则化,避免关节限位、危险动作等损害硬件
二、研究方法与算法原理
2.1 整体技术路线
pipeline:
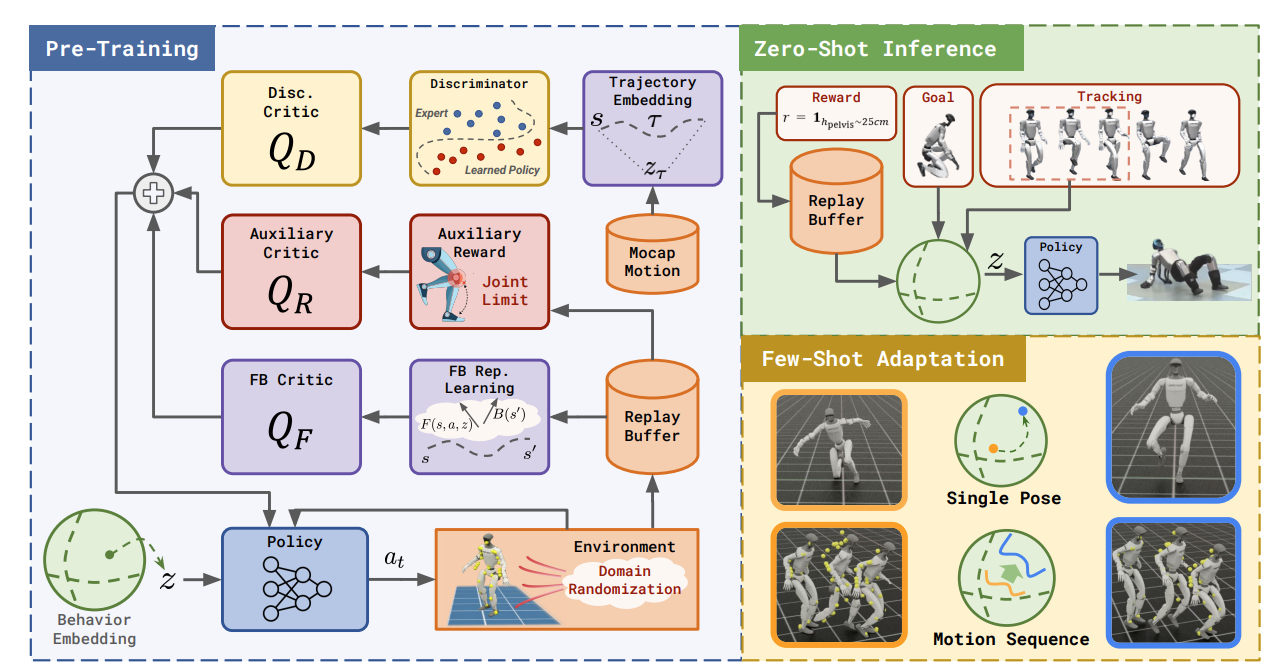
┌─────────────────────────────────────────────────────────────────┐
│ 预训练阶段(仿真) │
│ ┌─────────────────────────────────────────────────────────┐ │
│ │ 输入:无标签运动数据集 M = {轨迹} + 在线交互数据 │ │
│ └─────────────────────────────────────────────────────────┘ │
│ ↓ │
│ ┌─────────────────────────────────────────────────────────┐ │
│ │ FB-CPR算法(前向-后向表示 + 策略正则化) │ │
│ │ ├─ 学习前向映射 F(s,a,z) 和后向映射 B(s) │ │
│ │ ├─ 构建共享潜在空间 Z ⊆ R^d(d维) │ │
│ │ ├─ 训练潜在条件策略 π(a|o_H, z) │ │
│ │ └─ 使用判别器正则化策略行为,接近运动捕捉数据 │ │
│ └─────────────────────────────────────────────────────────┘ │
│ ↓ │
│ ┌─────────────────────────────────────────────────────────┐ │
│ │ 关键技术设计 │ │
│ │ ├─ 非对称训练:策略仅观测历史,Critic使用特权信息 │ │
│ │ ├─ 大规模并行环境(数千个)+ 大回放缓冲区 │ │
│ │ ├─ 域随机化(质量、摩擦、关节偏移、扰动、传感器噪声) │ │
│ │ └─ 奖励正则化(关节限位、安全约束) │ │
│ └─────────────────────────────────────────────────────────┘ │
└─────────────────────────────────────────────────────────────────┘
↓
┌─────────────────────────────────────────────────────────────────┐
│ 零样本推理(真实机器人) │
│ ┌─────────────────────────────────────────────────────────┐ │
│ │ 任务规格化方法(无需重训练) │ │
│ │ ├─ 奖励优化:给定奖励函数 r(s) = φ(s)^T z,求解最优z │ │
│ │ ├─ 目标到达:给定目标状态 s_goal,求解对应的z │ │
│ │ └─ 运动跟踪:给定运动片段,求解对应轨迹的嵌入z │ │
│ └─────────────────────────────────────────────────────────┘ │
└─────────────────────────────────────────────────────────────────┘
↓
┌─────────────────────────────────────────────────────────────────┐
│ 少样本适应(可选) │
│ └─ 通过采样优化在潜在空间Z中搜索更好的z,仅需少量环境交互 │
└─────────────────────────────────────────────────────────────────┘
2.2 算法原理:前向-后向表示(Forward-Backward Representations)
2.2.1 核心数学框架
BFM-Zero 建立在前向-后向表示(FB representations)的理论基础上。该框架学习一个低秩近似策略的动态转移核。
基本分解:学习两个映射函数
- 前向映射 F:S×A×Rd→RdF: \mathcal{S} \times \mathcal{A} \times \mathbb{R}^d \to \mathbb{R}^dF:S×A×Rd→Rd:给定状态-动作和潜在变量 zzz,预测后续特征
- 后向映射 B:S→RdB: \mathcal{S} \to \mathbb{R}^dB:S→Rd:从状态中提取后向特征
使得折扣访问概率分解为:
Mπz(ds′∣s,a)≃F(s,a,z)⊤B(s′)ρ(ds′)M^{\pi_z}(ds' | s, a) \simeq F(s, a, z)^\top B(s') \rho(ds')Mπz(ds′∣s,a)≃F(s,a,z)⊤B(s′)ρ(ds′)
其中 Mπz(s′∈X∣s,a):=∑tγtPr(st∈X∣s,a,πz)M^{\pi_z}(s' \in X | s, a) := \sum_t \gamma^t \Pr(s_t \in X | s, a, \pi_z)Mπz(s′∈X∣s,a):=∑tγtPr(st∈X∣s,a,πz) 表示从 (s,a)(s,a)(s,a) 出发、遵循策略 πz\pi_zπz 时,折扣访问概率。
任务特征:定义 ϕ(s):=(Eρ[B(s)B(s)⊤])−1B(s)\phi(s) := (\mathbb{E}_\rho[B(s)B(s)^\top])^{-1}B(s)ϕ(s):=(Eρ[B(s)B(s)⊤])−1B(s),则 ϕ(s)\phi(s)ϕ(s) 构成任务特征函数。
线性奖励族:每个 z∈Zz \in \mathbb{Z}z∈Z 定义线性奖励函数 rz(s)=ϕ(s)⊤zr_z(s) = \phi(s)^\top zrz(s)=ϕ(s)⊤z,对应的策略 πz\pi_zπz 最大化:
Eρ[∑tγtϕ(st)⊤z∣πz]=F(s,a,z)⊤z\mathbb{E}_\rho\left[\sum_t \gamma^t \phi(s_t)^\top z \mid \pi_z\right] = F(s, a, z)^\top zEρ[t∑γtϕ(st)⊤z∣πz]=F(s,a,z)⊤z
这意味着 F(s,a,z)⊤zF(s,a,z)^\top zF(s,a,z)⊤z 就是策略 πz\pi_zπz 在奖励 rzr_zrz 下的 Q 值函数。
2.2.2 FB-CPR 算法
FB-CPR 是 FB 框架的在线、离线策略扩展,专为物理角色动画设计,具有以下特点:
- 在线训练:与环境实时交互,不断收集数据
- 离线策略学习:利用回放缓冲区提高样本效率
- 判别器正则化:引入潜在条件判别器,使策略行为接近运动捕捉数据集 M\mathcal{M}M 中的演示
训练目标:最小化时序差分损失,同时通过判别器损失约束策略生成的轨迹与运动数据分布一致。
2.3 BFM-Zero 预训练的关键设计
为实现真实人形机器人的 sim-to-real 迁移,本文引入了四个关键设计:
2.3.1 非对称训练(Asymmetric Training)
| 组件 | 观测信息 | 作用 |
|---|---|---|
| 策略 π\piπ | 历史观测 ot,Ho_{t,H}ot,H(部分可观测) | 模拟真实机器人的感知限制 |
| Critic(F, B) | 历史观测 + 特权状态 sts_tst | 利用仿真中的完整状态提供精确值估计 |
优势:缩小策略与 Critic 之间的信息差距,在域随机化下提高策略鲁棒性。
观测定义:
- 可观测状态 ot={qt−qˉ,q˙t,ωroott/4,gt}∈R64o_t = \{q_t - \bar{q}, \dot{q}_t, \omega_{\text{root}}^t/4, g_t\} \in \mathbb{R}^{64}ot={qt−qˉ,q˙t,ωroott/4,gt}∈R64
- 历史窗口 ot,H={ot−H,at−H,…,ot}∈R93⋅H+64o_{t,H} = \{o_{t-H}, a_{t-H}, \ldots, o_t\} \in \mathbb{R}^{93 \cdot H + 64}ot,H={ot−H,at−H,…,ot}∈R93⋅H+64
- 特权状态 st∈R463s_t \in \mathbb{R}^{463}st∈R463(包含根高度、身体姿态、根旋转、线速度和角速度等)
2.3.2 大规模并行训练
- 环境数量:数千个并行仿真环境
- 大回放缓冲区:存储大量离线策略交互数据
- 高 UTD 比率(Update-to-Data):每次环境步对应多次网络更新
- 目标:高效训练多样化的策略族,同时保持训练稳定性
2.3.3 域随机化(Domain Randomization)
为防止过拟合仿真动力学,随机化以下物理参数:
- 连杆质量
- 摩擦系数
- 关节偏移
- 躯干质心位置
- 外加扰动和传感器噪声
2.3.4 奖励正则化
引入辅助奖励项避免危险行为:
- 关节限位惩罚
- 异常姿态惩罚
- 硬件安全约束
2.4 零样本推理方法
预训练完成后,BFM-Zero 支持三种零样本任务规格化方式:
| 任务类型 | 输入 | 方法 | 输出 |
|---|---|---|---|
| 奖励优化 | 任意奖励函数 r(s)r(s)r(s) | 寻找 zzz 使得 r(s)≈ϕ(s)⊤zr(s) \approx \phi(s)^\top zr(s)≈ϕ(s)⊤z | 执行策略 πz\pi_zπz |
| 目标到达 | 目标状态 sgoals_{\text{goal}}sgoal | 找到 zzz 最大化 ϕ(sgoal)⊤z\phi(s_{\text{goal}})^\top zϕ(sgoal)⊤z | 执行策略 πz\pi_zπz |
| 运动跟踪 | 运动片段 τ\tauτ | 计算轨迹嵌入 zzz | 执行策略 πz\pi_zπz |
2.5 少样本适应
当零样本策略表现不满足要求时,通过采样优化在潜在空间 Z\mathcal{Z}Z 中搜索更优的 zzz:
- 仅需少量环境交互(few episodes)
- 无需重训练网络参数
- 可用于适应未见过的、难以通过零样本覆盖的任务
2.6 实验设计
2.6.1 机器人平台
- 硬件:Unitree G1 人形机器人(29-DoF)
- 控制:PD 控制器目标位置作为动作空间
2.6.2 仿真实验
- 基线对比:与现有运动跟踪RL方法对比
- 消融实验:验证非对称训练、域随机化、奖励正则化等设计选择的必要性
- 评估指标:跟踪误差、成功率、鲁棒性
2.6.3 真实机器人实验
验证以下能力(如图1所示):
- 目标到达:零样本到达指定姿态
- 运动跟踪:跟踪未见过的运动片段
- 奖励优化:在给定奖励下优化行为
- 自然恢复:大扰动后的自主恢复
- 少样本适应:4kg 负重等新条件下的快速适应
- 未见运动:零样本执行训练中未见的全身运动
三、主要创新点与学术贡献
3.1 创新点总结
创新点一:首个可零样本提示的真实人形机器人行为基础模型
核心思想:通过无监督RL学习一个共享潜在空间 Z\mathcal{Z}Z,将运动、目标、奖励统一嵌入该空间,使单一策略可通过不同的任务规格化方式零样本执行多种下游任务。
创新价值:
- 首次证明离线无监督RL可以在真实人形机器人上工作
- 提供统一的、可解释的任务接口(奖励/目标/运动均可转换为 zzz)
- 无需为每个新任务重新训练策略
创新点二:前向-后向表示与运动数据正则化的深度融合
核心思想:在FB-CPR算法基础上,通过潜在条件判别器使无监督RL学习到的策略行为接近运动捕捉数据,避免产生不自然或不可行的动作。
创新价值:
- 解决了无监督RL策略可能产生“不类人”行为的问题
- 将物理角色动画中的成功经验引入真实机器人领域
创新点三:针对sim-to-real的系统性工程设计
核心思想:结合非对称训练、大规模并行训练、域随机化和奖励正则化四项关键技术,弥合仿真与真实之间的差距。
创新价值:
- 非对称训练:策略仅使用历史可观测信息,Critic使用特权信息,兼顾真实部署可行性与值估计准确性
- 大规模并行:实现高效的无监督预训练
- 域随机化:提升对物理参数不确定性的鲁棒性
- 奖励正则化:保护硬件安全
创新点四:零样本+少样本的双阶段适应机制
核心思想:零样本推理快速执行新任务;当零样本性能不足时,通过在潜在空间 Z\mathcal{Z}Z 中采样优化进行少样本适应,仅需少量环境交互。
创新价值:
- 结合了零样本的速度和少样本的适应性
- 适应过程不修改网络权重,仅搜索 zzz,计算效率高
3.2 主要学术贡献
-
开创性:首次在真实人形机器人上实现基于无监督RL的行为基础模型,扩展了RL在机器人领域的应用范式。
-
统一性:提供了一个统一的框架,使同一策略可以通过奖励、目标状态、运动片段三种方式被提示执行不同任务,无需重训练。
-
鲁棒性:通过域随机化和非对称训练,策略能够从大扰动中自然恢复(如Fig.1D),并在4kg负重等新条件下通过少样本适应快速调整(如Fig.1E)。
-
可扩展性:算法设计支持大规模并行训练,为未来扩展到更复杂的人形机器人和更多任务奠定了基础。
3.3 与现有工作的对比
| 特性 | 传统RL方法(如PPO运动跟踪) | 操作领域VLA模型 | BFM-Zero |
|---|---|---|---|
| 任务特定性 | 任务特定,每个策略一个任务 | 可提示,零样本 | 可提示,零样本 |
| 训练数据 | 仿真RL交互 | 人类遥操作演示 | 无标签运动数据+在线交互 |
| 人形机器人适用性 | 是(但单任务) | 否(无动作标签) | 是 |
| 真实部署验证 | 有限 | 广泛(操作) | 首次(人形全身上下) |
| 少样本适应 | 需重训练 | 需微调 | 潜在空间搜索 |
四、技术路线总结
┌─────────────────────────────────────────────────────────────────────────────┐
│ BFM-Zero 技术架构 │
├─────────────────────────────────────────────────────────────────────────────┤
│ 输入空间 │
│ ├─ 无标签运动数据集 M = {轨迹(观测+特权状态)} │
│ └─ 在线仿真交互(域随机化环境) │
├─────────────────────────────────────────────────────────────────────────────┤
│ 核心算法:FB-CPR │
│ ├─ 学习前向映射 F(s,a,z) 和后向映射 B(s) │
│ ├─ 构建任务特征 φ(s) = (E[B(s)B(s)^T])^{-1}B(s) │
│ ├─ 定义线性奖励族 r_z(s) = φ(s)^T z │
│ ├─ 训练潜在条件策略 π(a|o_H, z) │
│ └─ 判别器正则化:使策略接近运动数据分布 │
├─────────────────────────────────────────────────────────────────────────────┤
│ 关键工程设计 │
│ ├─ 非对称训练:策略用历史可观测,Critic用特权完整状态 │
│ ├─ 大规模并行:数千环境,大回放缓冲区,高UTD │
│ ├─ 域随机化:质量/摩擦/关节偏移/质心/扰动/噪声 │
│ └─ 奖励正则化:关节限位、安全约束 │
├─────────────────────────────────────────────────────────────────────────────┤
│ 推理阶段 │
│ ├─ 零样本:将任务(奖励/目标/运动)编码为z → 执行π_z │
│ └─ 少样本:在Z中采样优化z,仅需少量环境交互 │
├─────────────────────────────────────────────────────────────────────────────┤
│ 验证平台:Unitree G1 人形机器人(29-DoF) │
│ ├─ 目标到达 ✓ 运动跟踪 ✓ 奖励优化 ✓ │
│ ├─ 自然恢复 ✓ 未见运动 ✓ 少样本适应(4kg负重)✓ │
└─────────────────────────────────────────────────────────────────────────────┘
五、局限性与未来方向
-
潜在空间的语义可解释性仍需提升:虽然论文声称Z空间是平滑且具有语义的,但如何让人类操作者直观地指定一个zzz来生成期望行为,仍然是一个开放问题。
-
运动数据的依赖性:BFM-Zero依赖无标签运动捕捉数据集来正则化策略行为。对于缺乏此类数据的机器人形态,该方法可能需要额外的数据收集。
-
计算资源需求:大规模并行训练(数千环境)需要大量计算资源,可能限制部分研究者的复现能力。
-
任务复杂性边界:当前验证的任务主要集中于运动类任务(跟踪、到达、简单奖励优化),对于需要长期规划或与物体交互的复杂操作任务,框架的适用性尚待验证。
-
未来方向:
- 将视觉观测集成到框架中,实现视觉-语言-动作的统一行为基础模型
- 探索更高效的潜在空间表示,支持更高维度的任务规格化
- 扩展到双足/四足等多种形态,构建跨形态的行为基础模型
- 结合大语言模型自动将自然语言指令映射到zzz,实现真正的“可提示”人形机器人

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 4
4 0
0- 0



 已为社区贡献32条内容
已为社区贡献32条内容

所有评论(0)