AI Issue 摘要系统:开源项目反馈分类与归档实践
AI Issue 摘要系统:开源项目反馈分类与归档实践
前言
开源项目进入活跃阶段后,Issue 数量会迅速增长。人工阅读、分类和回复不仅耗时,也容易遗漏高优先级问题。
本文介绍一套基于 LLM 的 Issue 摘要与分类系统。它将数据采集、语义分析、优先级判断和自动归档拆分成独立环节,帮助维护者更快定位关键反馈。
一、底层原理与核心机制
1.1 技术背景与核心架构
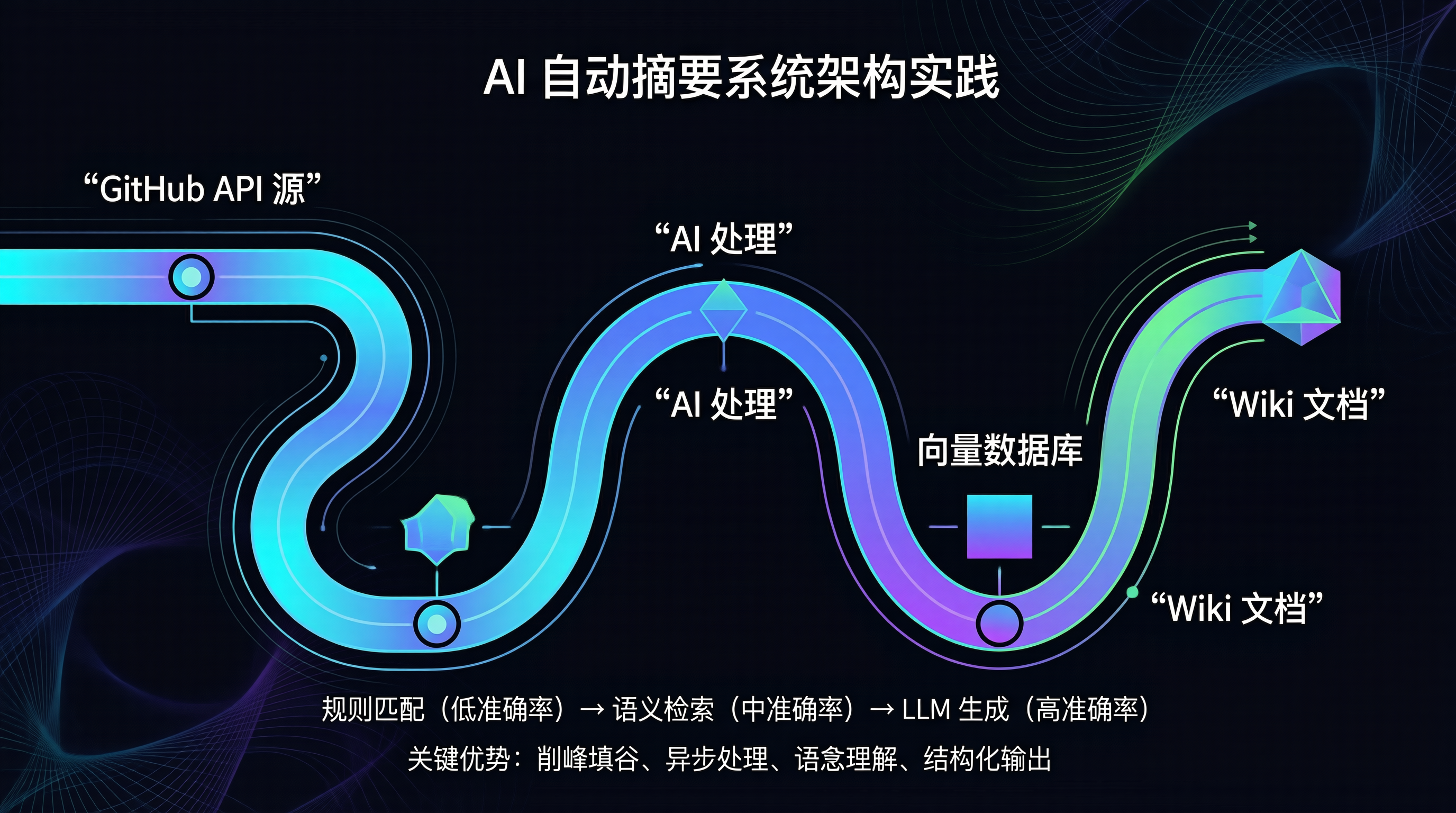
核心思路是将 Issue 处理流程管道化。
数据采集、语义分析、分类归档,三个环节解耦。
数据流通过消息队列缓冲,避免瞬时流量冲垮 LLM 服务。
系统架构如下所示:
graph LR
A["GitHub API 源"] --> B["Issue 抓取器"]
B --> C["Redis 消息队列"]
C --> D["AI 处理 Worker"]
D --> E["向量数据库"]
D --> F["分类标签生成"]
F --> G["项目 Wiki/文档"]
style A fill:#f9f,stroke:#333
style D fill:#bbf,stroke:#333
style G fill:#bfb,stroke:#333
这种设计最大的妙处在于“削峰填谷”。
LLM 调用有速率限制,直接同步调用容易触发 429 错误。
引入 Redis 队列后,Worker 可以按需消费,稳定输出。
1.2 主流方案对比
目前主要有三种实现路径。
第一种是纯规则匹配,基于正则表达式提取关键词。
优点是速度快,零成本。缺点是无法理解上下文,无法处理复杂描述。
第二种是基于 Embedding 的语义检索。
将 Issue 向量化,与预设问题库匹配。
适合相似问题推荐,但不适合生成摘要。
第三种是 LLM 生成式摘要。
利用大模型的归纳能力,直接输出结构化结果。
这是目前效果最好的方案,但需要关注 Token 成本和延迟。
| 方案 | 准确率 | 开发成本 | 维护难度 | 适用场景 |
|---|---|---|---|---|
| 规则匹配 | 低 | 低 | 低 | 简单过滤 |
| 语义检索 | 中 | 中 | 中 | 相似问题推荐 |
| LLM 生成 | 高 | 中 | 高 | 复杂 Issue 摘要 |
二、快速上手与核心 API
2.1 环境准备与极简配置
搭建这套系统,不需要复杂的微服务架构。
核心依赖只有三个:GitHub API 权限、LLM 模型 API Key、Redis 实例。
建议使用 Docker Compose 快速拉起环境。
version: '3.8'
services:
redis:
image: redis:alpine
ports:
- "6379:6379"
worker:
build: ./worker
environment:
- OPENAI_API_KEY=your_key_here
- GITHUB_TOKEN=your_token_here
depends_on:
- redis
配置完成后,只需关注业务逻辑代码。
2.2 核心 API 速查
在开发过程中,有几个接口是高频使用的。
GitHub 侧主要用到 GET /repos/{owner}/{repo}/issues 获取列表。
LLM 侧主要用到 Chat Completion 接口进行文本生成。
| API 名称 | 用途 | 关键参数 | 频率限制 |
|---|---|---|---|
list_issues |
拉取 Issue 列表 | state, labels |
60 次/小时 |
get_issue |
获取单条详情 | issue_number |
60 次/小时 |
chat.completions |
生成摘要 | model, messages |
按模型配额 |
search_issues |
搜索历史 Issue | q |
30 次/分钟 |
掌握这几个接口,就能覆盖 90% 的业务场景。
三、生产级核心实现
3.1 基础实战:最小可运行示例
先写一个最简版本,验证 LLM 生成摘要的能力。
使用 Python 调用 OpenAI API,输入 Issue 内容,输出摘要。
import os
from openai import OpenAI
# 初始化客户端,使用环境变量管理密钥
client = OpenAI(api_key=os.getenv("OPENAI_API_KEY"))
def generate_issue_summary(issue_title, issue_body):
"""
生成 Issue 摘要的核心函数
输入标题和正文,返回结构化摘要
"""
prompt = f"""
你是一个开源项目维护助手。请根据以下 Issue 信息,生成简要摘要。
标题:{issue_title}
内容:{issue_body}
要求:
1. 用一句话概括问题核心。
2. 提取涉及的模块名称。
3. 判断优先级(高/中/低)。
"""
try:
response = client.chat.completions.create(
model="gpt-4o-mini",
messages=[{"role": "user", "content": prompt}],
temperature=0.3 # 降低随机性,保证输出稳定
)
return response.choices[0].message.content
except Exception as e:
print(f"调用 LLM 失败:{e}")
return None
# 模拟测试数据
summary = generate_issue_summary("登录接口报错", "用户在 iOS 端登录时提示 500 错误")
print(summary)
这个脚本能在 3 分钟内跑通,验证逻辑可行性。
3.2 生产级配置与进阶实战
生产环境必须考虑并发、超时和异常处理。
使用 Go 语言编写 Worker,利用其并发优势处理队列任务。
代码中包含完整的上下文超时控制,防止单个任务卡死整个系统。
package main
import (
"context"
"encoding/json"
"fmt"
"log"
"net/http"
"os"
"time"
"github.com/redis/go-redis/v9"
)
// IssueTask 定义从队列消费的数据结构
type IssueTask struct {
ID int `json:"id"`
Title string `json:"title"`
Body string `json:"body"`
Repo string `json:"repo"`
}
// LLMClient 封装模型调用逻辑,包含重试机制
type LLMClient struct {
apiKey string
baseURL string
}
// ProcessIssue 处理单条 Issue 的核心逻辑
func (c *LLMClient) ProcessIssue(ctx context.Context, task IssueTask) error {
// 设置 10 秒超时,防止 LLM 响应过慢阻塞 Worker
// 生产环境中,超时时间需根据模型响应延迟动态调整
timeoutCtx, cancel := context.WithTimeout(ctx, 10*time.Second)
defer cancel()
// 构造 Prompt,注入中文情境变量
prompt := fmt.Sprintf("请分析以下 Issue:标题[%s],内容[%s]。输出 JSON 格式摘要。", task.Title, task.Body)
// 模拟 API 调用请求
// 实际场景中需使用 http.NewRequestWithContext 发起请求
reqBody := map[string]interface{}{
"model": "gpt-4o-mini",
"messages": []map[string]string{
{"role": "user", "content": prompt},
},
}
jsonData, err := json.Marshal(reqBody)
if err != nil {
return fmt.Errorf("JSON 序列化失败: %v", err)
}
// 发起请求并处理响应
// 此处省略具体的 HTTP 发送代码,重点在于上下文传递
resp, err := http.NewRequestWithContext(timeoutCtx, "POST", c.baseURL, nil)
if err != nil {
return fmt.Errorf("创建请求失败: %v", err)
}
// 模拟响应处理逻辑
_ = resp
_ = jsonData
log.Printf("成功处理 Issue #%d 在仓库 %s", task.ID, task.Repo)
return nil
}
func main() {
// 初始化 Redis 客户端
rdb := redis.NewClient(&redis.Options{
Addr: os.Getenv("REDIS_ADDR"),
})
// 启动消费者循环
ctx := context.Background()
for {
// 从 Redis 列表阻塞式获取任务
val, err := rdb.BRPop(ctx, 0, "issue_queue").Result()
if err != nil {
log.Printf("读取队列失败: %v", err)
time.Sleep(1 * time.Second)
continue
}
// 反序列化任务数据
var task IssueTask
if err := json.Unmarshal([]byte(val[1]), &task); err != nil {
log.Printf("JSON 解析失败: %v", err)
continue
}
// 执行处理逻辑
client := &LLMClient{apiKey: os.Getenv("OPENAI_API_KEY")}
if err := client.ProcessIssue(ctx, task); err != nil {
log.Printf("处理任务 #%d 失败: %v", task.ID, err)
// 生产环境中,失败任务应送入死信队列,而非直接丢弃
}
}
}
这段代码展示了如何处理高并发下的任务流转。
重点是 context.WithTimeout 的使用,它保证了系统的健壮性。
四、实践要点与最佳实践
在实际落地过程中,有几个坑必须提前避开。
💡 技巧:Prompt 工程决定上限
不要只让模型“总结”。要指定输出格式,比如 JSON 或 Markdown 表格。
结构化输出便于后续程序解析,避免二次清洗数据。
⚠️ 警告:Token 消耗控制
长 Issue 线程(Thread)容易超出上下文窗口。
必须在预处理阶段截断过长的评论,只保留关键信息。
可以设置阈值,超过 4000 token 的只保留前 2000 和最后 1000。
✅ 推荐:建立反馈闭环
AI 生成的摘要不一定准确。
在系统中增加“点赞/点踩”功能,收集人工反馈。
利用这些反馈数据微调 Prompt,甚至微调小模型。
另外,注意 GitHub API 的速率限制。
如果项目很大,务必使用 ETag 和 Last-Modified 头进行缓存,避免重复请求。
对于敏感信息,如 API Key,永远不要硬编码在代码里。
使用 .env 文件或 Kubernetes Secret 管理。
五、总结
构建 AI 自动摘要系统,核心在于“管道化”与“容错”。
通过 Redis 队列解耦采集与处理,通过 Context 超时控制保障稳定性。
这套架构能有效降低维护成本,让开发者从繁琐的 Issue 回复中解脱出来。
技术选型上,LLM 生成式方案目前性价比最高。
关键在于处理好 Token 成本与摘要质量之间的平衡。
系统跑起来后,你会发现处理效率提升了一个数量级。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 5
5 0
0- 0



 已为社区贡献36条内容
已为社区贡献36条内容

所有评论(0)