智能客服系统中Transformers.js实时推理性能分析
·
智能客服系统中Transformers.js实时推理性能分析
一、浏览器端推理的实时性挑战
智能客服系统对响应延迟有严格要求。用户期望在1-2秒内看到AI的回复,而每一轮对话需要依次完成:文本向量化、意图分类、知识库检索、答案生成等多个步骤。如果这些环节全部依赖服务端API,网络延迟和GPU排队会进一步增加响应时间。
Transformers.js 将部分推理任务转移到用户终端,通过消除网络往返来降低延迟。但浏览器端的计算资源有限,能否在保证用户体验的前提下完成实时推理?
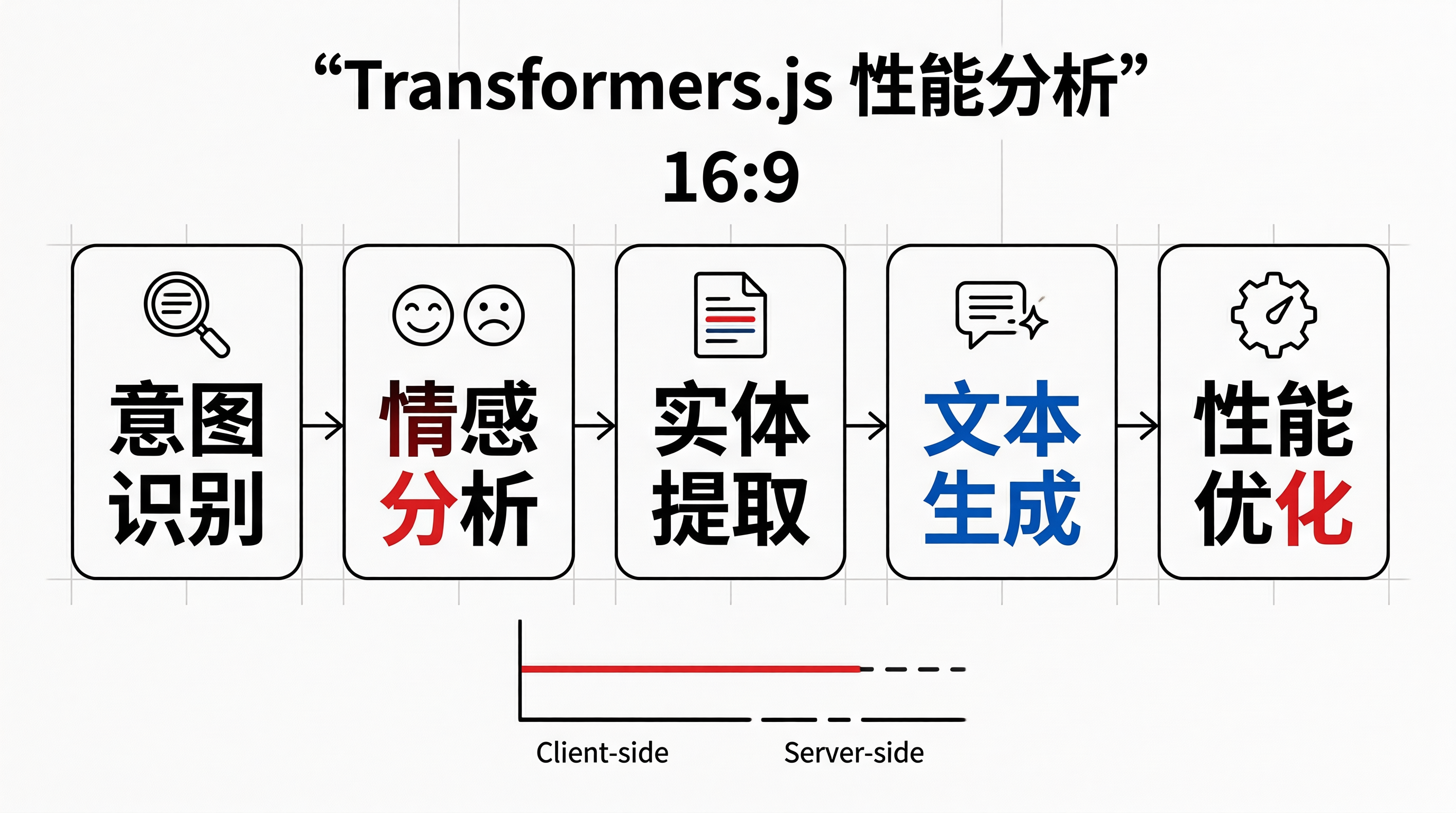
二、智能客服系统中的推理任务分布
| 推理任务 | 模型类型 | 典型模型 | 推理频次 | 延迟要求 | 浏览器端可行性 |
|---|---|---|---|---|---|
| 意图识别 | 文本分类 | DistilBERT | 每轮对话 | <200ms | 高 |
| 情感分析 | 情感分类 | XLM-RoBERTa | 每轮对话 | <100ms | 高 |
| 实体提取 | Token分类 | BERT-NER | 每轮对话 | <200ms | 高 |
| 语义匹配 | 特征提取 | Sentence-BERT | 每次检索 | <100ms | 中 |
| 文本生成 | 自回归 | GPT-2 | 可选 | <500ms/token | 低 |
| 摘要生成 | Seq2Seq | BART | 长文本处理 | <1s | 低 |
三、实时推理性能基准测试
3.1 核心推理管道
import { pipeline } from '@xenova/transformers';
class ChatbotInferenceEngine {
constructor() {
this.models = {};
this.inferenceTimings = {};
this.modelLoadProgress = {};
}
onProgress(modelName, callback) {
this.modelLoadProgress[modelName] = callback;
}
async ensureModel(task, name) {
const key = `${task}:${name}`;
if (this.models[key]) {
return this.models[key];
}
const startTime = performance.now();
this.models[key] = await pipeline(task, name, {
progress_callback: (progress) => {
const cb = this.modelLoadProgress[name];
if (cb) {
cb({
status: progress.status,
loaded: progress.loaded,
total: progress.total,
percentage: progress.total
? Math.round((progress.loaded / progress.total) * 100)
: 0
});
}
}
});
const loadTime = performance.now() - startTime;
this.recordTiming('model_load', name, loadTime);
return this.models[key];
}
async classifyIntent(text, intents) {
const startTime = performance.now();
const classifier = await this.ensureModel(
'zero-shot-classification',
'Xenova/nli-deberta-v3-xsmall'
);
const result = await classifier(text, intents);
const duration = performance.now() - startTime;
this.recordTiming('intent_classification', 'deberta-v3', duration);
return {
intent: result.labels[0],
confidence: result.scores[0],
allScores: result.labels.slice(0, 3).map((label, i) => ({
intent: label,
score: result.scores[i]
})),
latency: duration
};
}
async analyzeSentiment(text) {
const startTime = performance.now();
const classifier = await this.ensureModel(
'sentiment-analysis',
'Xenova/distilbert-base-uncased-finetuned-sst-2-english'
);
const result = await classifier(text.slice(0, 512));
const duration = performance.now() - startTime;
this.recordTiming('sentiment_analysis', 'distilbert', duration);
return {
label: result[0].label,
score: result[0].score,
latency: duration
};
}
async extractEntities(text) {
const startTime = performance.now();
const extractor = await this.ensureModel(
'token-classification',
'Xenova/bert-base-NER'
);
const result = await extractor(text, {
aggregation_strategy: 'simple'
});
const duration = performance.now() - startTime;
this.recordTiming('entity_extraction', 'bert-ner', duration);
return {
entities: result.map(entity => ({
word: entity.word,
type: entity.entity_group,
score: entity.score,
position: { start: entity.start, end: entity.end }
})),
latency: duration
};
}
async generateResponse(prompt, maxTokens = 50) {
const startTime = performance.now();
const generator = await this.ensureModel(
'text-generation',
'Xenova/gpt2'
);
const result = await generator(prompt, {
max_new_tokens: maxTokens,
do_sample: true,
temperature: 0.7
});
const duration = performance.now() - startTime;
this.recordTiming('text_generation', 'gpt2', duration);
return {
text: result[0].generated_text.slice(prompt.length),
fullText: result[0].generated_text,
latency: duration,
tokensPerSecond: maxTokens / (duration / 1000)
};
}
recordTiming(category, model, duration) {
if (!this.inferenceTimings[category]) {
this.inferenceTimings[category] = [];
}
this.inferenceTimings[category].push({
model,
duration,
timestamp: Date.now()
});
if (this.inferenceTimings[category].length > 100) {
this.inferenceTimings[category].shift();
}
}
getLatencyStats() {
const stats = {};
for (const [category, timings] of Object.entries(this.inferenceTimings)) {
const durations = timings.map(t => t.duration);
const sorted = [...durations].sort((a, b) => a - b);
stats[category] = {
avg: Math.round(durations.reduce((a, b) => a + b, 0) / durations.length),
min: Math.round(sorted[0]),
max: Math.round(sorted[sorted.length - 1]),
p50: Math.round(sorted[Math.floor(sorted.length * 0.5)]),
p95: Math.round(sorted[Math.floor(sorted.length * 0.95)]),
p99: Math.round(sorted[Math.floor(sorted.length * 0.99)]),
samples: durations.length
};
}
return stats;
}
}
3.2 性能基准测试
async function runBenchmark(engine) {
const testCases = [
{
name: '短文本意图识别',
text: '我想查询一下我的订单状态',
intents: ['订单查询', '产品咨询', '投诉建议', '售后服务']
},
{
name: '长文本意图识别',
text: '我上周在你们平台买了一件商品,但是收到后发现和描述不符,颜色不对而且尺码也偏小,我想退货退款,请问该怎么操作?',
intents: ['订单查询', '产品咨询', '投诉建议', '售后服务', '退货退款']
},
{
name: '情感分析',
text: '你们的服务太差了,我等了三天都没人回复!'
},
{
name: '情感分析(长文本)',
text: '总体来说体验还不错,客服态度很好,问题也解决了,就是等待时间稍微长了点。'
},
{
name: '实体提取',
text: '我叫张三,手机号是13800138000,订单号是20240601001'
}
];
const results = [];
const WARMUP_COUNT = 3;
const RUN_COUNT = 10;
for (const testCase of testCases) {
for (let i = 0; i < WARMUP_COUNT; i++) {
await runTestCase(engine, testCase);
}
const runResults = [];
for (let i = 0; i < RUN_COUNT; i++) {
const result = await runTestCase(engine, testCase);
runResults.push(result);
}
const latencies = runResults.map(r => r.latency);
const sorted = [...latencies].sort((a, b) => a - b);
results.push({
name: testCase.name,
avgLatency: Math.round(latencies.reduce((a, b) => a + b, 0) / latencies.length),
minLatency: sorted[0],
maxLatency: sorted[sorted.length - 1],
p50Latency: sorted[Math.floor(sorted.length * 0.5)],
p95Latency: sorted[Math.floor(sorted.length * 0.95)]
});
}
return results;
}
async function runTestCase(engine, testCase) {
const startTime = performance.now();
if (testCase.intents) {
await engine.classifyIntent(testCase.text, testCase.intents);
} else {
await engine.analyzeSentiment(testCase.text);
}
const latency = performance.now() - startTime;
return { name: testCase.name, latency };
}
四、浏览器端推理与服务端推理对比
| 对比维度 | 浏览器端推理 | 服务端GPU推理 |
|---|---|---|
| 意图识别(短文本) | 35-80ms | 50-150ms (含网络) |
| 意图识别(长文本) | 80-200ms | 80-250ms (含网络) |
| 情感分析 | 15-40ms | 30-100ms (含网络) |
| 实体提取 | 50-120ms | 60-180ms (含网络) |
| 文本生成 (50 tokens) | 800-2000ms | 200-500ms |
| 首次加载延迟 | 2-5s (模型下载) | 无 |
| 内存占用 | 80-200MB (浏览器堆) | 2-8GB (GPU显存) |
| 并发能力 | 单用户 | 数千并发 |
| 离线可用 | 是 | 否 |
五、渐进式混合推理架构
class HybridInferenceEngine {
constructor(options = {}) {
this.options = {
serverEndpoint: '/api/ai/infer',
fallbackThreshold: 500,
useClientSide: true,
...options
};
this.clientEngine = null;
this.stats = {
clientCalls: 0,
serverCalls: 0,
fallbacks: 0,
totalLatency: []
};
}
async init() {
if (this.options.useClientSide) {
this.clientEngine = new ChatbotInferenceEngine();
}
}
async classifyIntent(text, intents) {
const startTime = performance.now();
if (this.clientEngine) {
try {
const result = await this.clientEngine.classifyIntent(text, intents);
if (result.confidence > 0.7) {
this.stats.clientCalls++;
this.stats.totalLatency.push(performance.now() - startTime);
return result;
}
this.stats.fallbacks++;
} catch {
console.warn('客户端推理失败,回退到服务端');
}
}
this.stats.serverCalls++;
const serverResult = await this.callServerAPI('classify', {
text, intents
});
this.stats.totalLatency.push(performance.now() - startTime);
return serverResult;
}
async analyzeSentiment(text) {
const startTime = performance.now();
if (this.clientEngine) {
try {
const result = await this.clientEngine.analyzeSentiment(text);
this.stats.clientCalls++;
this.stats.totalLatency.push(performance.now() - startTime);
return result;
} catch {
// fall through
}
}
this.stats.serverCalls++;
const serverResult = await this.callServerAPI('sentiment', { text });
this.stats.totalLatency.push(performance.now() - startTime);
return serverResult;
}
async generateResponse(prompt) {
const startTime = performance.now();
if (this.clientEngine && prompt.length < 200) {
try {
const result = await this.clientEngine.generateResponse(prompt, 30);
if (result.tokensPerSecond > 5) {
this.stats.clientCalls++;
this.stats.totalLatency.push(performance.now() - startTime);
return result;
}
} catch {
// fall through
}
}
this.stats.serverCalls++;
const serverResult = await this.callServerAPI('generate', { prompt });
this.stats.totalLatency.push(performance.now() - startTime);
return serverResult;
}
async callServerAPI(action, params) {
const response = await fetch(`${this.options.serverEndpoint}/${action}`, {
method: 'POST',
headers: { 'Content-Type': 'application/json' },
body: JSON.stringify(params)
});
if (!response.ok) {
throw new Error(`服务端推理失败: ${response.status}`);
}
return response.json();
}
getStats() {
const latencies = this.stats.totalLatency;
const avgLatency = latencies.length > 0
? Math.round(latencies.reduce((a, b) => a + b, 0) / latencies.length)
: 0;
return {
clientCalls: this.stats.clientCalls,
serverCalls: this.stats.serverCalls,
fallbacks: this.stats.fallbacks,
clientRatio: `${Math.round((this.stats.clientCalls / (this.stats.clientCalls + this.stats.serverCalls)) * 100)}%`,
averageLatency: avgLatency,
estimatedCostSaved: this.stats.clientCalls * 0.001
};
}
}
六、端到端客服对话示例
class HybridChatbot {
constructor() {
this.engine = new HybridInferenceEngine();
this.history = [];
}
async processMessage(userMessage) {
this.history.push({ role: 'user', content: userMessage });
const [intent, sentiment] = await Promise.all([
this.engine.classifyIntent(userMessage, [
'订单查询', '产品咨询', '投诉建议',
'售后服务', '退货退款', '人工客服'
]),
this.engine.analyzeSentiment(userMessage)
]);
const intentResult = {
intent: intent.intent,
confidence: intent.confidence,
latency: intent.latency
};
const sentimentResult = {
sentiment: sentiment.label,
score: sentiment.score,
isNegative: sentiment.label === 'NEGATIVE' && sentiment.score > 0.8
};
let response;
if (sentimentResult.isNegative && intent.confidence < 0.6) {
response = '很抱歉给您带来不好的体验,我马上为您转接人工客服。';
} else {
const prompt = this.buildPrompt(intent.intent, userMessage);
const generated = await this.engine.generateResponse(prompt);
response = generated.text;
}
this.history.push({ role: 'assistant', content: response });
return {
response,
intent: intentResult,
sentiment: sentimentResult,
inferenceStats: this.engine.getStats()
};
}
buildPrompt(intent, userMessage) {
const templates = {
'订单查询': '用户询问订单状态,请简要回复并提供订单号查询指引。用户说:',
'产品咨询': '用户咨询产品信息,请提供简洁的产品介绍。用户说:',
'投诉建议': '用户投诉,请先道歉并安抚情绪。用户说:',
'售后服务': '用户需要售后支持,请提供相关解决方案。用户说:',
'退货退款': '用户申请退货退款,请说明退款流程。用户说:',
'人工客服': '用户希望转接人工客服。用户说:'
};
return (templates[intent] || '请回答用户问题:') + userMessage;
}
}
七、性能优化建议
| 优化策略 | 效果 | 实施难度 |
|---|---|---|
| 模型量化 (8-bit) | 内存减少50%,速度提升30% | 低 |
| Web Worker隔离 | 不阻塞UI线程 | 低 |
| 模型预加载 | 消除首次对话延迟 | 中 |
| 模型共享 | 多pipeline复用同一模型 | 中 |
| 混合推理 | 客户端低置信度时回退服务端 | 高 |
| 缓存常见查询 | 零延迟命中缓存 | 低 |
Transformers.js 在智能客服系统中的实时推理性能已经达到可接受的水平。对于意图识别、情感分析等轻量级NLP任务,浏览器端推理的延迟低于服务端API(因省去网络往返)。但对于文本生成等计算密集型任务,浏览器端仍显著慢于GPU服务端。建议采用"混合推理"策略:客户端处理快速、确定性的分类任务,服务端处理复杂、生成式的任务,在用户体验和成本之间取得最佳平衡。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 6
6 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)