CPT306 Principles of Computer Games Design 电脑游戏设计原理 Pt.10 Advanced Game Tech(高级游戏技术)
文章目录
1. 渲染
我们上一章介绍了渲染。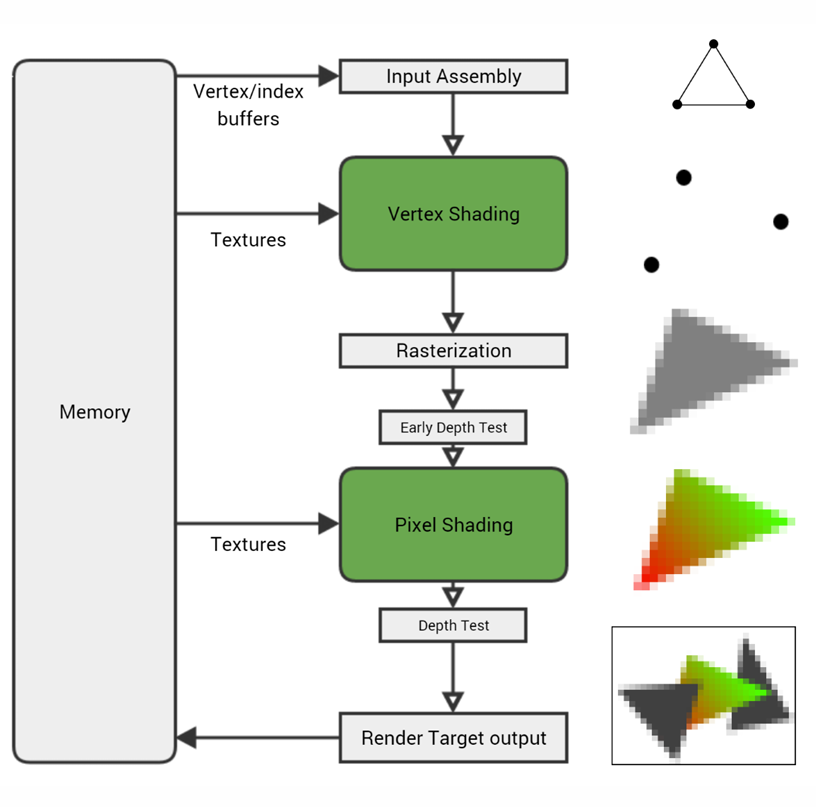
游戏中的模型、贴图、光照、摄像机信息,会经过 GPU 的一系列步骤,最终生成屏幕上的画面。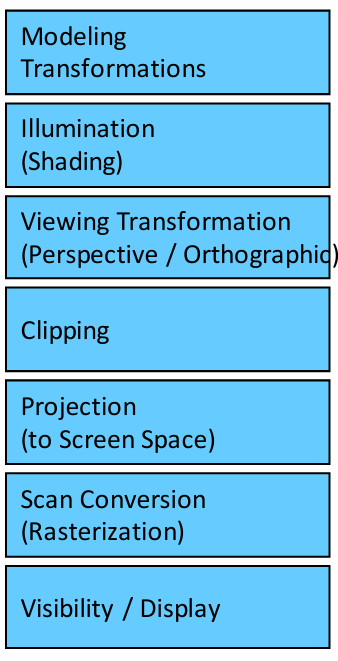
| 英文 | 中文 | 意思 |
|---|---|---|
| Modeling Transformations | 模型变换 | 把模型从自身坐标放到世界场景中 |
| Illumination / Shading | 光照 / 着色 | 计算物体在灯光下的颜色和明暗 |
| Viewing Transformation | 观察变换 | 根据摄像机位置决定看到什么 |
| Clipping | 裁剪 | 把摄像机看不到的部分去掉 |
| Projection | 投影 | 把 3D 空间投影到 2D 屏幕 |
| Scan Conversion / Rasterization | 扫描转换 / 光栅化 | 把三角形转换成像素 |
| Visibility / Display | 可见性 / 显示 | 判断遮挡关系并显示最终图像 |
这里不再过多叙述,这一章要介绍的是现代游戏技术。
现代游戏技术主要追求两件事:
画面更真实,同时运行更流畅。
1.1 新型渲染方式
现代游戏渲染正在从“传统 GPU 按规则画像素”,转向“AI 参与理解/推断场景”的新型渲染方式。
过去游戏画面主要靠 GPU 把几何体、贴图、光照一步步算成像素;
现在越来越多技术会让 AI 参与渲染,用 AI 去预测、补全、重建或推断画面。
例如把 AI Tensor Cores 直接整合到光栅化渲染循环中,形成一种“神经网络 + 传统渲染(Neural-Hybrid)”的混合管线。
Tensor Cores 可以理解为 GPU 里专门加速 AI 计算的硬件单元。
神经渲染通过训练 AI 模型,让它根据数据预测像素颜色和光照行为,而不是直接用物理公式计算光线传播。
神经网络可以直接从图像中学习复杂几何结构和材质外观。所以它不一定需要人工完整建立精确的 3D 模型,也不一定需要手动设置所有材质参数。
它可以模拟以前计算成本太高的复杂光照、复杂场景和复杂材质交互。
对于复杂材质,神经渲染可以减少显存占用和数据传输带宽。
我们上一章用 PBR 解决渲染问题,它依赖于 Albedo Map、Normal Map、Metallic Map、Roughness Map、AO Map。这些组合起来才能形成一个复杂表面。
而现在 Neural Materials/Shading 的思路是用一个 AI 网络来表示这些复杂材质,而不是显式存储大量贴图和复杂 shader 规则。这样可以简洁地表示复杂的材料特性。
用 AI 学习复杂表面外观,把原本复杂、多层的 shader 代码压缩成小型神经网络,从而实现更快的实时渲染。
神经材质(Neural materials)会根据光照方向、观察方向和隐变量编码(latent codes),让神经网络计算材质颜色,而不是依赖复杂明确的 shader graph。
因此传统材质计算大概是:
贴图 + shader 节点 + 光照公式 → 像素颜色。
现在神经材质大概是:
光照方向 + 观察方向 + 材质编码 → 神经网络 → 像素颜色。
- lighting direction(光照方向)
就是光从哪里照过来。光照方向不同,材质的明暗、反射、高光都会变化。 - viewing direction(观察方向)
就是摄像机从哪个角度看这个表面。比如金属和玻璃从不同角度看,反射会明显不同。 - latent codes(隐变量编码)
这个比较抽象,可以理解为:
AI 内部用来表示材质特征的一组数字。
它不是人直接写出来的参数,而是神经网络训练过程中学出来的压缩表示。
1.1.1 神经渲染(Neural Rendering)
AI 超分辨率与图像生成(AI Upscaling & Generation):像 NVIDIA DLSS 这样的技术,会先让游戏用较低分辨率渲染画面,然后用 AI 把它放大成高分辨率画面。
比如游戏原本如果直接渲染 4K,会很耗性能。DLSS 的思路是:
先渲染一张较低分辨率的图,比如 1080p 或 1440p,
再用 AI 推断出接近 4K 的清晰画面。
这样可以减少 GPU 的计算压力,同时让玩家看到接近高分辨率的画面。
DLSS 全称是:Deep Learning Super Sampling,(深度学习超级采样)。
它是一种 NVIDIA 的 AI 渲染技术,目标是:
提高游戏帧率,同时尽量保持甚至提升画面质量(enhance gaming performance and visual quality)。
DLSS 会使用 NVIDIA 显卡中的 Tensor Cores。
DLSS 可以带来:
- 更高帧率;
- 更清晰图像;
- 更流畅的游戏体验;
- 同时尽量不明显增加输入延迟。
比如不开 DLSS 时,游戏可能只有 45 FPS;开 DLSS 后,可能提升到 70 FPS、90 FPS 或更高。
它不是简单“降低画质换帧率”,而是先降低实际渲染成本,再用 AI 恢复或增强画面。
需要注意的是 RTX 指的是光线追踪,开启后场景中的光照、阴影、反射会更真实。
因此 RTX 光线追踪很耗性能,而 DLSS 可以帮助弥补性能损失。
所以两者经常一起出现。
但其实两者不一样,RTX 更偏向:
用光线追踪提升真实光照效果。
DLSS 更偏向:
用 AI 提升分辨率和帧率。
1.1.1.1 DLSS
DLSS 是一整套 AI 渲染技术,不只是“把画面放大”这么简单。它包括:AI 放大分辨率、AI 生成帧、AI 重建光线追踪画面、AI 抗锯齿 等功能。
- DLSS Multi Frame Generation(DLSS 多帧生成。)
它用 AI 在真实渲染出来的一帧之间,额外生成多帧画面。
传统情况是:
GPU 渲染 1 帧 → 显示 1 帧
DLSS Multi Frame Generation 的思路是:
GPU 渲染 1 帧 → AI 额外生成几帧 → 显示更多帧
这样可以显著提高 FPS,让游戏看起来更流畅。
不过要注意:AI 生成的帧不是游戏引擎真正计算出来的完整物理帧,而是根据前后画面、运动信息、深度信息预测出来的中间帧。 - DLSS Dynamic Multi Frame Generation(动态多帧生成)
它会根据不同游戏、不同场景的复杂程度,自动调整生成帧的数量。
比如:
场景简单、运动稳定时,可以多生成一些帧;
场景复杂、快速移动时,可能少生成一些帧,避免画面出错;
目标是让整体画面更平滑,同时减少伪影。
所以它比固定生成帧更加灵活。 - DLSS Frame Generation(DLSS 帧生成)
用 AI 生成额外的游戏帧,提高帧率,同时尽量保持操作响应速度。
例如原来游戏真实渲染只有 60 FPS,开启帧生成后,显示出来可能接近 100 FPS 或更高。
但是这里要理解一个关键点:
Frame Generation 提高的是“显示帧率”,不完全等于游戏逻辑真的运行得更快。
所以它主要改善视觉流畅度,对操作延迟的改善不像真正提高原生帧率那么直接。 - DLSS Ray Reconstruction(DLSS 光线重建)
它主要服务于 Ray Tracing(光线追踪)。
光线追踪很真实,但很耗性能。为了实时运行,游戏通常不会发射特别多光线,所以原始结果可能有噪点、不稳定、不清晰。
传统方法会用人工设计的 denoiser(去噪器)处理这些噪点。
DLSS Ray Reconstruction 是用 AI 替代传统手工去噪器,在光线追踪采样不足的情况下,预测出更高质量的光照、反射和阴影像素。 - DLSS Super Resolution(DLSS 超分辨率)
这是最经典的 DLSS 功能。
它的思路是:
游戏先用较低分辨率渲染,再用 AI 输出更高分辨率画面。
例如:
内部实际渲染 1080p,最后 AI 输出接近 4K 的画面。
这样可以在减少 GPU 渲染压力的同时,生成更清晰的图像。
这就是为什么 DLSS 经常可以做到:
帧率提高,但画面仍然接近高分辨率渲染效果。 - Deep Learning Anti-Aliasing(DLAA,深度学习抗锯齿)
它和 DLSS Super Resolution 的区别是:
DLSS Super Resolution:低分辨率 → AI 放大到高分辨率。
DLAA:原生分辨率 → AI 抗锯齿,不主要追求提帧。
所以 DLAA 更偏向提升画质,而不是提升性能。
它可以减少边缘锯齿、闪烁、画面抖动、远处细节不稳定。
总结一下:
| 技术 | 主要作用 |
|---|---|
| DLSS Super Resolution | 低分辨率渲染后 AI 放大,提高帧率 |
| DLSS Frame Generation | AI 生成中间帧,提高显示帧率 |
| DLSS Multi Frame Generation | 一帧基础上生成更多帧,让画面更流畅 |
| DLSS Ray Reconstruction | AI 重建光追像素,提高光追画质 |
| DLAA | 原生分辨率下 AI 抗锯齿,提高画面稳定性 |
1.1.1.2 DLSS 发展史
现在 DLSS 已经从最初的 1.0 发展到了 5.0,其的任务也从“补像素”发展成了“AI 帮游戏创造更真实、更流畅的画面”。
换句话说 AI 不只是放大已有像素,而是在生成原本没有被真正渲染出来的画面内容。
- DLSS 1.0:Spatial Inference(空间推理)
它使用CNN来升级较低分辨率的图像。
但是 DLSS 1.0 有两个问题:
第一,它需要针对不同游戏单独训练,不够通用。
第二,它缺少 temporal awareness(时间感知)。
也就是说,它主要看单张图,不太理解前后帧之间的连续运动,所以可能出现:画面模糊、细节不稳定、运动时闪烁、时间连续性差。 - DLSS 2.0:Temporal Breakthrough(时间突破)
DLSS 2.0 是一个重要转折点。它不再只是看当前帧,而是会利用前几帧的信息。
这叫 Temporal Feedback(时间反馈)。
其是一种广义上的人工智能模型。AI 不只看现在这一张图,还会参考之前几帧画面,判断物体是怎么移动的,从而生成更稳定、更清晰的结果。
这样做的好处是:不再需要每个游戏单独训练;画面稳定性更好;运动时不容易模糊;抗锯齿效果更好;细节保留更好。
所以说 DLSS 2.0 是真正让 DLSS 变得实用和成熟的关键版本。 - DLSS 3.0:Frame Generation(帧生成)
DLSS 3.0 的核心变化是:
不只是生成像素,而是生成完整的新帧。
以前 DLSS 主要是:
低分辨率画面 → 高分辨率画面。
DLSS 3.0 开始可以:
已有帧 A 和帧 B → AI 生成中间帧。
传统游戏里,通常是:
游戏引擎计算一帧 → GPU 渲染一帧 → 显示器显示一帧。
但是 DLSS Frame Generation 出现后:
游戏引擎可能只真实计算了 60 帧,AI 额外生成一些中间帧,显示器可能显示 100 多帧。
所以它打破了原来的 1:1 关系。
不过需要注意的与前面提到的相同,AI 生成帧提高的是视觉流畅度,不代表游戏逻辑、物理模拟、玩家输入也都真的按同样帧率运行。
DLSS 3 利用了 Optical Flow Accelerator(光流加速器)来分析连续两帧之间的运动关系,然后生成中间帧。 - DLSS 3.5:Ray Reconstruction(光线重建)
DLSS 3.5 的重点从“帧率提升”转回到“纯画质提升”。
以前开启光线追踪时,因为实时游戏不可能像电影那样发射大量光线,所以画面容易有噪点。传统方法会用人工设计的 denoiser(去噪器)去处理。
在 Ray Reconstruction 中 用 AI 替代传统手写去噪器,根据空间信息和时间信息,重建更准确的光照、反射、阴影和颜色溢出效果。
所以它不是简单“去噪”,而是 AI 试图判断光线追踪没采样到的地方,真实光照应该是什么样。 - DLSS 4.0:Transformer Architecture
DLSS 4 把底层 AI 模型从传统 CNN 换成了 Transformer 模型。
CNN 更擅长局部图像特征,比如边缘、纹理、小范围结构。
而 Transformer 更擅长看整体关系。它有 attention mechanism 注意力机制,可以判断画面中哪些区域更重要、哪些区域更复杂,然后把更多计算资源放到关键地方。
所以 DLSS 4 的意义是 AI 模型从“局部图像增强”升级到“更全局、更稳定的画面理解”。 - DLSS 5.0:Neural Material Reconstruction
DLSS 5 不再完全依赖传统 PBR 数学公式去计算光线和材质,而是使用实时神经渲染模型。
也就是说,AI 不只是放大图像,也不只是生成帧,而是开始参与判断:
皮肤应该如何透光;
布料应该有什么细微光泽;
头发和光线如何交互;
材质在不同光照下应该呈现什么质感;
场景整体应该如何接近照片级真实感。
NVIDIA 对 DLSS 5 的官方描述是:它使用实时神经渲染模型,把照片级光照和材质注入到画面中,并且保持与游戏原始 3D 内容和艺术风格一致。
总结一下:
DLSS 1/2:把 AI 当作“图像放大器(Upscaler)”。(Spatial + Temporal data)
DLSS 3/4:把 AI 当作“动画师(Animator)”,因为它们开始生成新帧。 (Optical Flow + Transformers)
DLSS 3.5/5:开始让 AI 更深入地参与着色、光照和材质表现。 (Ray Reconstruction + Neural Materials)
1.1.1.3 3D Gaussian Splatting(3DGS)
传统游戏场景通常由三角形网格组成;
3D Gaussian Splatting 不用三角形表示场景,而是用大量“3D 高斯椭球”来表示场景,然后把这些高斯投影到屏幕上形成图像。
准确的来说是,从离散的多边形结构,也就是三角形,转向连续的、概率式的体积场表示。
3D Gaussian Splatting 是用很多个 3D 高斯椭球表示一个真实场景,然后把它们投影到 2D 屏幕上,合成最终图像。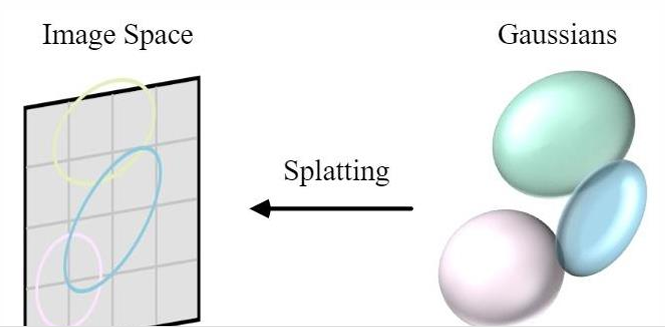
所以现在场景不是由固定的顶点组成,而是由几百万个 3D 高斯分布组成。
这个过程通常从一个稀疏点云开始,这个点云一般由 SfM 算法通过分析多张 2D 照片生成。
训练时,系统会把自己渲染出来的图像和真实照片进行比较。
在细节不够、误差较大的地方,系统会自动复制或分裂高斯。
系统会删除多余的,或者几乎完全透明的高斯。
最后每个 3D 高斯在屏幕上会变成一个 2D 椭圆,然后很多椭圆叠加起来,形成完整画面。
我们将这种技术与原来的技术进行对比:
| 传统渲染 | 3D Gaussian Splatting |
|---|---|
| 用三角形表示物体表面 | 用大量高斯椭球表示场景 |
| 需要建模、UV、贴图、材质 | 可以从多张照片中训练出来 |
| 更适合游戏引擎可控资产 | 更适合真实场景重建 |
| 表面边界明确 | 表示更连续、更柔和 |
| 适合动画、交互、物理碰撞 | 更适合新视角合成和照片级重建 |
3DGS 可以被放进实时引擎和数字内容创作工具中使用。例如 Blender、Maya、3ds Max 中。
3DGS 希望超越传统摄影测量,不一定要先生成三角形网格,而是直接用高斯椭球来表示真实场景。
场景不是用多边形网格渲染,而是用几百万个透明的、有颜色的椭球渲染,从而可以以显著降低的渲染开销实现现实世界位置的即时、电影级的数字双胞胎。
2. 角色动画
传统角色动画需要大量人工制作,而现在高级游戏技术正在用 AI 和计算机视觉减少人工工作,让角色动画更自动、更智能。
传统流程大概是:建角色模型→绑定骨骼(Rigging)→刷权重(Weighting)→制作关键帧(Keyframing)→清理修正(Cleanup)。
2.1 Intent-Based Animation(基于意图的动画)
以后动画系统不一定要手动定义角色每个关节怎么动,而是告诉系统“角色想完成什么目标”。
几个关键技术如下:
- Neural Rigging(神经网络自动绑定骨骼)
用 AI 自动构建角色的骨骼结构。
以前骨骼绑定需要人工做,现在 AI 可以根据角色模型自动判断:
头在哪里;
手臂在哪里;
腿在哪里;
关节应该放在哪里;
骨骼层级怎么连接。
这样可以大幅减少手工 rigging 的时间。 - Generative Motion(生成式动作)
输入文字,AI 生成动作。
比如输入:
一个角色疲惫地走路
AI 就可以生成一个比较符合描述的走路动作。
再比如:
角色快速拔剑并后退一步
AI 可以直接生成对应动作。
这和现在的文生图、文生视频类似,只不过这里是文本生成动作。 - Markerless Capture(无标记动作捕捉)
传统动作捕捉需要演员穿动捕服,身上贴很多 marker 标记点,然后用专业摄像机捕捉。
现在不需要穿昂贵的动捕服,也不需要贴标记点,只用普通摄像机或视频,通过计算机视觉识别人体动作。
比如用视频直接识别:
人的骨架;
关节位置;
姿态变化;
行走、跳跃、挥手等动作。
2.1.1 Neural Rigging(神经自动绑定)
传统角色动画第一步要人工给角色加骨骼、刷权重、修变形;
Neural Rigging 用 AI 自动分析 3D 模型,自动生成骨骼、权重和修正变形,大幅减少人工工作。
角色绑定,也叫骨骼动画,是让数字角色动起来的第一步。
一个 3D 角色模型本身只是一个“静态外壳”,比如人形网格。如果想让它抬手、转头、走路,就要给它加一套内部骨架。
我们会把角色模型绑定到一套有层级关系的骨骼系统上。
例如人体骨骼有层级:
骨盆
└── 脊柱
├── 头
├── 左臂
└── 右臂
└── 左腿
└── 右腿
当你旋转上臂骨骼时,前臂和手也会跟着移动。
这就是 skeletal hierarchy(骨骼层级)。
2.1.1.1 Automated Anatomical Weighting(自动解剖权重分配)
像 MetaHuman Creator 这样的工具可以用深度学习分析原始 3D 网格,并在几秒内生成可用于生产的角色绑定系统。
Topology Analysis(拓扑分析):AI 会根据模型网格的体积和密度,识别关节中心位置。
Auto-Weighting(自动权重):不再需要人工刷权重,而是由神经网络根据学到的人体结构规律(anatomical priors)预测蒙皮权重(skinning weights)。
Corrective Blendshapes(纠正混合形状):AI 自动生成修正形变(joint collapsing),用来修复关节弯曲时塌陷或扭曲的问题。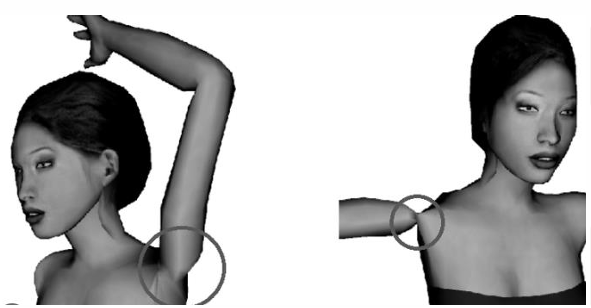
2.1.1.2 蒙皮(Skinning)
角色模型有了骨骼以后,还要把“皮肤表面”绑定到骨骼上,让角色运动时表面能自然变形。传统方法便宜但不够真实,神经蒙皮希望用 AI 来学习更自然的变形方式。
蒙皮(Skinning)就是把 3D 角色的表面网格绑定到骨骼上。
比如一个角色抬手时,不能只是骨骼动,外面的皮肤、衣服、肌肉表面也要跟着变形。
神经蒙皮想要替代传统的线性混合蒙皮(Linear Blend Skinning,LBS)。
传统的线性混合蒙皮(Linear Blend Skinning,LBS)的优点在于计算简单,但是物理上不够真实(准确)。
v i ′ = ∑ j w i j T j v i v_i' = \sum_j w_{ij} T_j v_i vi′=∑jwijTjvi
一个顶点的新位置,是多个骨骼变换结果按照权重加权求和得到的。
比如一个手肘处的顶点可能是:60% 跟随上臂骨骼;40% 跟随前臂骨骼。
那它变形后的位置就是:新位置 = 0.6 × 上臂变换结果 + 0.4 × 前臂变换结果。
神经蒙皮层不再把皮肤看成一堆带权重的离散顶点,而是把皮肤看成一个连续的变形场(Neural Skinning Layers treat skin as a continuous field rather than a set of weighted vertices)。
因此神经蒙皮的思路更像是 AI 学习整个身体表面在不同姿势下应该如何连续变形。
2.1.1.3 AI-Driven Inverse Kinematics(AI 驱动的反向运动学)
角色动画里,控制身体关节有两种基本方式:
FK(正向运动学):从根部关节往末端推。
IK(反向运动学):先指定末端目标,再反推关节角度。
AI-driven IK 就是用 AI 让这个反推过程更自然、更智能。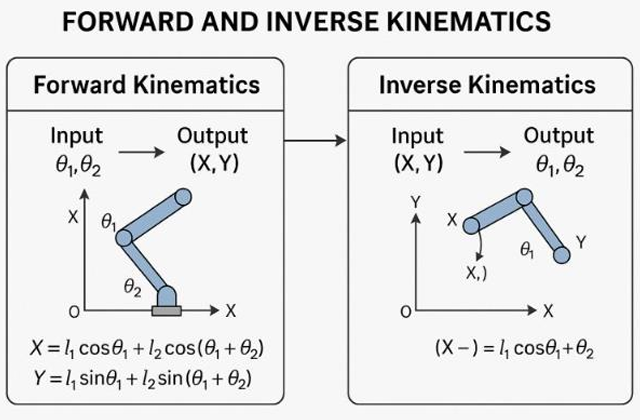
Forward Kinematics(FK,正向运动学)是从根部关节开始,一节一节往末端计算姿势。
也就是说,你控制的是关节角度,最后得到手的位置。
FK 适合比较自由摆动的动作,比如:走路时手臂自然摆动;挥剑;挥拳;摆尾巴;披风或手臂弧线运动。
因为这类动作更关注运动的弧线和姿态,而不是末端必须精确到某个位置。
Inverse Kinematics(IK,反向运动学)是先指定末端目标位置,然后系统反过来计算关节应该怎么弯。
也就是说,IK 控制的是末端位置,系统自动求关节角度。
IK 适合有明确约束的位置动作,比如:脚必须踩在地面上;在不平地形上行走;手必须抓住梯子;双手必须握住一把武器;手必须碰到按钮;角色要扶墙;脚不能穿进地面。
比如角色走在斜坡上,如果只用 FK,脚可能会悬空或者插进地面。
用 IK 就可以让脚自动贴合地面。
用 IK 的话,你移动手的位置,整条手臂会自动跟着调整。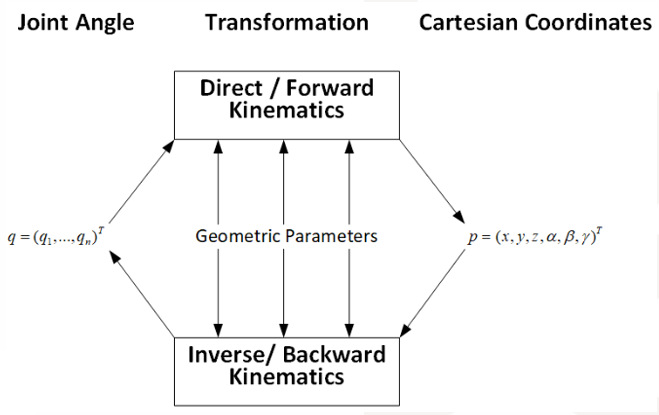
这张图说明了 FK 和 IK 的输入输出关系。
FK:Joint Angle → Transformation → Cartesian Coordinates(关节角度 → 变换 → 空间坐标)
也就是知道关节怎么转→算出手、脚、末端在哪里
IK:Cartesian Coordinates → Transformation → Joint Angle
空间目标坐标 → 反推 → 关节角度、
也就是:知道手或脚要到哪里→反推出关节应该怎么转
动画师在做角色动画时,通常会在同一个角色绑定系统里混合使用 FK 和 IK。当肢体需要自由摆动时,用 FK。当肢体必须固定到某个目标时,用 IK。
AI-Driven IK 带来了一个范式转变。
传统 IK 求解器只关心能不能到达目标,不关心最终姿势像不像人。
AI 驱动 IK 不再只依赖纯几何计算,而是加入深度学习。
AI-Driven IK 会用大量 MoCap (Motion Capture,动作捕捉)数据训练神经网络,让模型学会:真人在完成某个动作目标时,通常会怎么调整全身姿态。
所以 AI IK 更像是在学习“人类动作规律”。
当角色伸手去够门把手时,传统 IK 可能只计算肩膀、手肘、手腕怎么转,才能让手碰到门把手。
但 AI-Driven IK 会推断:人类伸手够门把手时,身体通常会微微前倾,脊柱会弯一点,重心会向前移动。
AI IK 解决的不是单纯坐标问题,而是动作意图问题。
因此,对比如下:
| 类型 | 关注点 | 结果 |
|---|---|---|
| 传统 IK | 手脚是否到达目标点 | 可能姿势不自然 |
| AI-Driven IK | 动作目标 + 人体自然姿态 | 更像真人动作 |
| 传统动画师 | 手动调 FK/IK 混合 | 质量高但耗时 |
| AI IK | 自动学习动作规律 | 更智能、更省人工 |
2.1.2 Generative Motion(生成式动作)
输入一句话,AI 自动生成角色动画。这里AI 生成的不是图片,而是一段角色骨骼动作。
传统动画依赖预先制作好的动作、关键帧、动作库或人工设定。
文本生成动作技术用 Motion Diffusion Models 和 Diffusion Transformers 取代传统固定动作库。
主要过程如下:
- Text Embedding(嵌入向量):首先,大语言模型读取你的文字提示,然后把文字转换成数学向量。
- Latent Space Traversal(遍历动作潜在空间):系统不是去已有动作库里搜索一段录好的动作。这个空间里包含很多动作规律,比如:走;跑;跳;蹲;挥手;打斗;转身;情绪化动作。
AI 会在这个空间中找到符合文字描述的位置,然后生成对应动作。 - Denoising / Diffusion(去噪/扩散):系统一开始从纯随机噪声出发,然后一帧一帧地去噪,逐渐生成符合文字描述的动作。
这里的 denoise(去噪)不是去除图像噪声,而是把随机动作逐渐变成有意义的动作。 - Physics Priors(物理先验),现代动作生成模型会加入物理先验,让生成动作更符合物理规律。
因为 AI 生成动作时可能会出现不合理情况,比如:脚滑;身体飘起来;重心不稳;膝盖反向弯曲;手穿过身体;动作不符合人体力学。
Physics priors(物理先验)就是告诉模型一些基本物理规律,例如:脚踩地时不能滑动;身体重心要合理;关节不能超过正常活动范围;人不能无原因漂浮;动作要满足平衡和惯性。
这样生成出来的动作才更像真实角色动画。
2.1.2.1 工具
这些工具可以帮助游戏开发者、动画师更快地生成角色动画,而不是完全手工做关键帧或依赖传统动捕。
- Nvidia Kimodo 是一种运动扩散模型,它使用大量光学动作捕捉数据训练,可以生成高质量的人类或机器人动作。
- Unity Muse Animate 是 Unity 的 AI 动画工具,可以直接集成在 Unity 编辑器里使用。
- Ai4AnimationPy 是一个用神经网络做角色动画的工具包。它可以用于:动作捕捉数据处理;AI 动作模型训练;动作生成推理;动画工程实验;角色运动控制研究。
它更像是研究和开发工具,不只是一个简单的动画软件。
2.1.3 Markerless Capture(无标记动作捕捉)
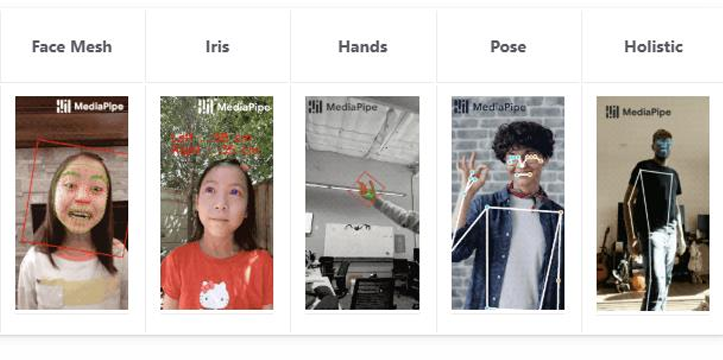
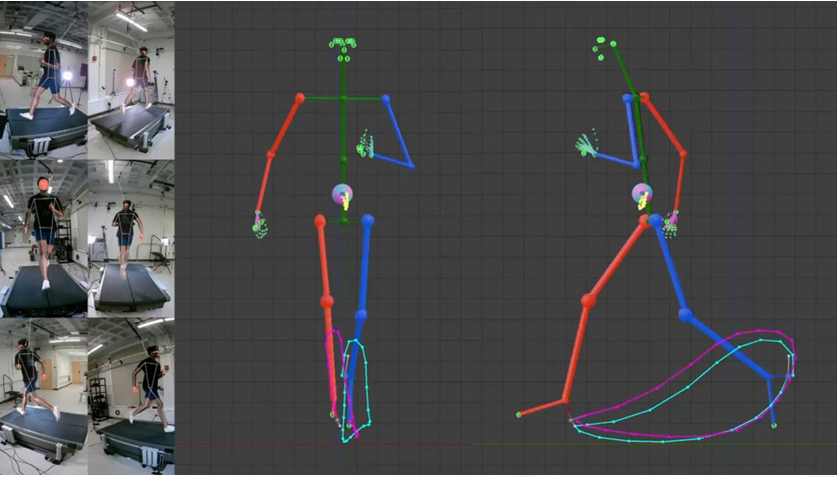
无标记动捕已经逐渐成为新的主流方式。它利用计算机视觉和人工智能,直接从普通 2D 视频中提取 3D 运动学数据。
例如:
- Google MediaPipe:它是 Google 的一个跨平台机器学习框架,可以做实时人体识别和姿态估计。
- FreeMoCap:它是一个开源的无标记动作捕捉工具。它的目标是让用户用普通摄像机甚至低成本设备完成动作捕捉。
3. PCG(Procedural Content Generation,程序化内容生成)和 AIGC(AI Generated Content,人工智能生成内容)
PCG 是一种成熟方法,它用算法系统创建游戏资源和内容,范围可以从简单图像纹理到完整游戏环境。
PCG 不是新概念,游戏行业很早就在用。
例如:
- 自动生成地形;
- 自动生成迷宫;
- 自动生成地下城;
- 自动生成树木和植被;
- 自动生成星球;
- 自动生成城市道路;
- 自动生成材质纹理。
像一些开放世界、沙盒游戏、Roguelike 游戏,经常使用 PCG。
游戏内容制作正在从手工建模、手动摆放,转向“提示词生成资产”和“规则生成世界”。
AI 或 PCG 可以生成的不只是图片,而是很多游戏开发内容,包括:
| 内容 | 中文意思 |
|---|---|
| 3D Models | 3D 模型 |
| 2D textures | 2D 贴图 |
| Animation | 动画 |
| Codes | 代码 |
| Game AI | 游戏 AI 行为 |
| Levels | 关卡 |
| Gameplay | 玩法机制 |
例如 3D 模型生成:把概念图输入 API 来生成模型。这些系统不只是输出几何形状,还会自动处理重新网格化、拓扑优化,并自动应用 PBR 材质。
3.1 AI 世界模型(AI World Model),AI 游戏引擎(AI Game Engine)
未来的游戏引擎可能不再完全依赖传统的“输入 → 物理计算 → 渲染”流程,而是让 AI 像“世界预测器”一样,根据玩家输入和场景状态预测接下来会发生什么。
传统游戏引擎,比如 Unreal 或 Unity,使用确定性的循环。例如:
玩家输入→游戏逻辑更新→物理引擎计算碰撞、重力、刚体运动→动画系统更新角色动作→渲染器绘制三角形 / 光线追踪→输出画面
AI World Model 是一种通过大量视频、空间数据和游戏画面训练出来的 AI 系统。
它不是像传统引擎那样直接画三角形,而是学习:
- 物体之间的空间关系;
- 角色和环境如何互动;
- 物体被遮挡后是否仍然存在;
- 重力、碰撞、破碎等物理规律;
- 玩家输入后画面会如何变化;
- 游戏场景下一帧应该长什么样。
它不是传统意义上逐个渲染多边形,而是像一个巨大的预测引擎一样,预测接下来的视频帧或 3D 状态。
你给 AI 一个输入,比如:让角色向前移动
然后 AI 根据当前场景和输入预测:
- 下一帧画面是什么;
- 角色应该移动到哪里;
- 周围物体有没有变化;
- 角色是否碰到障碍物;
- 镜头中应该出现什么内容;
- 场景的 3D 状态应该如何更新。
因此 AI 要理解物体之间的位置关系,否则生成的画面就会有问题。
还需要注意 object permanence(物体恒常性 / 物体持续存在性)一个物体即使暂时被遮挡,它也应该仍然存在。
比如角色走到柱子后面,传统引擎知道角色还在那里,只是被遮住了。
如果没有 object permanence,AI 可能会在下一帧把物体忘掉、变形或生成到错误位置。
当然需要注意原本应有的物理规则。
这种 AI 引擎不一定使用传统物理引擎,比如 Havok 那样的碰撞和刚体求解器。
比如玻璃瓶掉到地上:
传统引擎会计算:瓶子速度、碰撞点、冲击力、材料破碎模型、碎片运动。
AI World Model 可能是:它见过很多玻璃瓶掉落破碎的视频。所以它预测:瓶子掉地上会碎裂。
这就是所谓的 latent physics(潜在物理)。
3.1.1 例子
Google DeepMind Genie 3:只需要开发人员或玩家可以向引擎提供单个2D概念草图或文本提示。引擎立即生成3D世界。
Google 官方也把 Genie 3 描述为一种 general-purpose world model,可以用简单文字生成可实时探索的环境;Project Genie 是一个实验性原型,可以用文字和图片创建、探索和 remix 交互式世界。
当用户向前走,或者和物体互动时,Genie 会实时生成用户周围的世界,同时保持时间一致性(Temporal consistency)和物体记忆(Object memory)。
这里的两个概念我们前面提到过。
时间一致性(Temporal consistency):例如前一秒有一棵树,下一秒这棵树不应该突然变成房子
物体记忆(Object memory):例如你刚才看到一个木屋,走开再回来,系统应该记得那个木屋还在那里。
AI 不只是看按键,而是会推断玩家想做什么动作。
AI 要理解这背后的动作意图,并预测环境应该如何反应。
它不是传统物理引擎那样一步步精确算力和碰撞,而是通过世界模型预测“这样做之后世界应该变成什么样”。
SEELE AI 是另一个 AI 游戏生成平台例子。
用一个提示词生成游戏相关内容,比如 3D 资产、代码、纹理、音频、场景布局,甚至完整可玩的游戏。
SEELE 官方介绍称,它可以从单个 prompt 生成图像、视频、3D 资产、代码和完整游戏。
3.2 “神经网络 + 传统引擎”的混合架构(“Neural-Hybrid” architecture)
现在还不是完全用 AI 替代 Unreal 或 Unity,而是出现一种“神经混合架构”。、
传统的方式带来的是确定性逻辑(deterministic logic):同样的输入,在同样
这类核心玩法不能完全交给 AI 随机生成,否则游戏会不公平、不稳定、难调试。的状态下,结果应该是确定的、可重复的。
因此核心玩法这些仍然要靠传统引擎的确定性逻辑。
但是开发者可以用 AI 世界模型实时生成远处背景或玩家无法到达的区域。
这样可以节省:硬盘空间;内存;显存;美术制作成本;场景加载压力。
除了娱乐游戏,定制化世界模型还可以生成大量极端情况,用来训练自动 AI 智能体和机器人。
极端情况比如:
- 突然暴雨;
- 极端大风;
- 道路塌陷;
- 建筑物倒塌;
- 车辆突然失控;
- 行人突然冲出;
- 机器人搬运物体时地面打滑;
- 自动驾驶遇到罕见交通事故。
这些情况在现实中很危险、很难大量采集,也不适合拿真实机器人反复试错,因为这样会损伤设备。
用 AI 世界模型模拟,就可以先在虚拟环境中训练,这样更安全,也更便宜。
4. 练习
我们用一些问题来复习一下这章的知识。
- 简单介绍一下什么是 DLSS/3DGS/RIgging/IK。
DLSS 是 NVIDIA 的 AI 渲染技术,核心作用是用 AI 提高画质和帧率。它可以把低分辨率画面重建成高分辨率画面,也可以生成额外帧、做光线重建和 AI 抗锯齿。
3DGS,3D Gaussian Splatting 是一种新的 3D 场景表示方法。传统模型用三角形网格表示物体,而 3DGS 用大量带有颜色、透明度、大小和方向的 3D 高斯椭球表示场景,再把这些高斯投影到屏幕上生成图像。
Rigging 是角色绑定,就是给 3D 角色模型加骨骼和控制器,使角色可以摆姿势和做动画。没有 rig,角色模型只是静态网格,不能自然运动。
IK(Inverse Kinematics,反向运动学)是先指定手、脚等末端目标位置,再反向计算肩膀、手肘、膝盖等关节角度。比如让角色的脚踩在地面上,或者让手抓住门把手,就常用 IK。 - DLSS 4.0 与之前版本的核心数学变化是什么
DLSS 4.0 与之前版本的数学差异在于,它从以局部卷积为主的 CNN 结构,转向基于 Transformer 的注意力机制。CNN 主要处理局部像素关系,而 Transformer 可以建模更大范围的空间和时间关系,因此在稳定性、抗锯齿、细节重建和运动画面中表现更好。 - AI驱动的IK如何改进传统IK solvers?
AI-driven IK 改进传统 IK 的地方在于,它不仅让手脚到达目标点,还会根据人体动作数据推断自然的全身姿态,使动作更符合人体结构、重心变化和动作意图。 - 像Google MediaPipe或FreeMoCap这样的系统是如何执行无标记捕获的?
MediaPipe / FreeMoCap 通过计算机视觉识别人体关键点,比如头、肩、肘、手、膝、脚等位置;然后根据单目或多目视频估计这些关键点的 3D 坐标,重建人体骨架运动,最后把这些运动数据绑定或重定向到游戏角色骨骼上。 - 传统游戏引擎和人工智能世界模型之间的核心区别是什么?
传统游戏引擎通过规则、物理求解器和渲染器精确计算游戏世界;AI World Model 则通过神经网络学习世界规律,并根据玩家输入预测下一帧画面或下一步 3D 状态。前者更确定、可控、可调试;后者更偏生成式、预测式和数据驱动。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 7
7 0
0- 0



 已为社区贡献8条内容
已为社区贡献8条内容

所有评论(0)