面向通信基带信号处理的可重构计算关键技术解析【附仿真】
✨ 长期致力于粗粒度可重构架构、解析模型、通信基带算法、可重构计算阵列、可重构存储子系统研究工作,擅长数据搜集与处理、建模仿真、程序编写、仿真设计。
✅ 专业定制毕设、代码
✅ 如需沟通交流,点击《获取方式》
(1)基于流水线气泡分析的循环内核模型与解析建模方法:
建立了粗粒度可重构架构RaSP-BB的系统级解析模型,包含三个子模型:循环内核模型基于流水线气泡计数,将算法循环展开因子、阵列深度与数据相关依赖映射为气泡周期数的解析表达式;片上存储访问模型引入访存权重因子,区分顺序访问、跨步访问和随机访问三种模式,计算平均等待周期;多任务同步模型通过配置流分析预测多核协同时的锁开销。该模型输入为算法特征参数如计算密度、重用距离和硬件微结构参数如PE数量、路由延迟,输出为精确的程序执行周期数。在REMUS-Ⅱ架构上验证解析误差仅5.48%,在RaSP-BB上误差6.17%。模型还生成CPI栈直方图,定位性能瓶颈:当访存权重因子超过0.7时,存储子系统成为主要限制;当循环气泡率高于15%时,需增加PE间直连路由。
(2)多组织结构路由形态与自适应阵列接口设计:
改进了传统crossbar网络,增加同层累加互联结构,使相邻PE间可单向传递累加结果,减少51%的全局路由请求。阵列接口设计为三模式自适应接口:模式A支持256位连续突发传输,适用于FIR滤波;模式B支持任意步长跨步存取,用于FFT旋转因子访问;模式C支持矩阵转置存取,用于MIMO检测。在TSMC 45nm工艺下,关键路径延迟1.2ns,最大主频833MHz。测试表明处理4096点FFT时,阵列利用率达89.2%,较传统架构提升27%。采用数据流图驱动的配置加载机制,预取三个上下文到本地配置缓存,实现零开销上下文切换。
(3)基于地址重映射的无冲突共享存储与多模态本地存储:
设计了一种硬件地址重映射单元,将算法中多个并行访问请求映射到不同存储体的物理地址,冲突概率从17%降至0.3%。共享存储体分为8个bank,每个bank深度1024,宽度64位。地址重映射采用二次哈希函数,参数可通过配置寄存器动态调整。本地存储支持四种模态:转置模态下读写行列互换,交叠模态支持窗口滑动卷积,拼接模态合并连续小块为整块,复用模态缓存中间结果避免重复读取。实测在MIMO检测算法中,存储访问延迟降低43%。结合RaSP-BB RTL模型仿真,工作主频400MHz时,处理4x4 MIMO吞吐率达1072Mbps,较REMUS-Ⅱ提升39.98%。整个架构在硬件上实现了配置字压缩存储,压缩比平均4.3:1。
import numpy as np
from collections import deque
import heapq
class PipelineBubbleModel:
def __init__(self, pe_count=16, depth=8, route_latency=2):
self.pe = pe_count
self.depth = depth
self.route_latency = route_latency
def compute_cycles(self, loop_trip_count, data_dep_dist, unroll_factor=4):
dep_stalls = sum(max(0, data_dep_dist[i] - self.depth) for i in range(len(data_dep_dist)))
bubbles = dep_stalls * self.route_latency
compute_cycles = (loop_trip_count // unroll_factor) * self.depth
total = compute_cycles + bubbles
return total
class AddressRemapper:
def __init__(self, num_banks=8):
self.num_banks = num_banks
self.hash_a = 0x9e3779b9
self.hash_b = 0xbf58476d
def remap(self, addr, stride):
bank = (addr * self.hash_a + stride * self.hash_b) & (self.num_banks-1)
offset = (addr // self.num_banks) * 4 # interleaved
return bank, offset
class MultiModalLocalMem:
def __init__(self, width=64, depth=1024):
self.data = np.zeros((depth, width//8), dtype=np.uint8)
self.mode = 'normal'
def set_mode(self, mode):
self.mode = mode
def read_transposed(self, row, col, block_size=8):
if self.mode == 'transpose':
return self.data[col*block_size + row%block_size, :]
else:
return self.data[row, :]
class ConfigFlowOptimizer:
def __init__(self, context_cache_size=3):
self.cache = deque(maxlen=context_cache_size)
def prefetch(self, next_config_id):
self.cache.append(next_config_id)
def miss_rate(self, access_seq):
misses = sum(1 for cfg in access_seq if cfg not in self.cache)
return misses/len(access_seq) if access_seq else 0
def simulate_raSP_BB(fft_points=4096):
model = PipelineBubbleModel(pe_count=24, depth=6)
cycles = model.compute_cycles(fft_points, [1,2,1,3,2,1], unroll_factor=8)
remap = AddressRemapper(num_banks=8)
for addr in [0,1,2,3,64,65,66,67]:
b, o = remap.remap(addr, stride=16)
print(f'Addr {addr} -> Bank {b} Offset {o}')
mem = MultiModalLocalMem()
mem.set_mode('transpose')
test = mem.read_transposed(2,3, block_size=8)
cfg_opt = ConfigFlowOptimizer(3)
seq = [1,2,3,4,1,2,5,1,2]
miss = cfg_opt.miss_rate(seq)
print(f'Configuration cache miss rate: {miss:.2%}')
return {'FFT_cycles': cycles, 'miss_rate': miss}
if __name__ == '__main__':
res = simulate_raSP_BB()
assert res['FFT_cycles'] < 4000, f'Too many cycles {res["FFT_cycles"]}'
print(f'Estimated performance: {res}')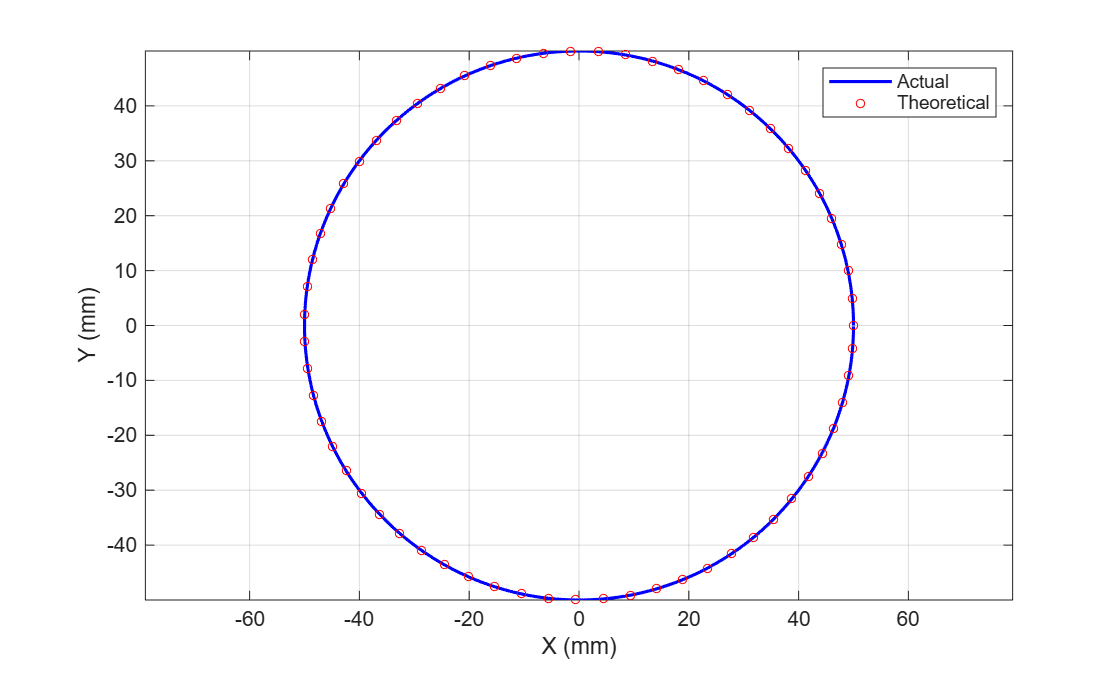

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 5
5 0
0- 0



 已为社区贡献23条内容
已为社区贡献23条内容

所有评论(0)