清华WorldVLN:首个自回归世界动作模型!零样本迁移真实无人机,成功率+12%

「先预测世界,再决策动作」
目录
(二)两阶段训练框架:监督打底+强化对齐,兼顾稳定性与目标性
过去的 VLA 模型,本质是“看到什么就做什么”,不建模动作之后世界会变成什么样。视频生成类世界模型呢?能预测未来画面,但它的目标是“画面逼真”,不是“动作可执行”,而且生成一整段视频的方式不适合闭环导航。
基于此,清华大学、山东大学等机构联合推出WorldVLN——首个面向空中VLN的自回归世界动作模型(WAM)。

▲WorldVLN模型
它不做“观测→动作”的直接映射,而是先预测“做了这个动作后世界会变成什么样”,再从预测结果里解码出无人机该飞的航点。
自回归、闭环、从潜在空间直接解码动作——一套组合下来,在室内外仿真基准上成功率比最强基线高出12%以上,并且零样本迁移到真实无人机,不需要额外微调。
01 自回归世界建模+动作直解码
WorldVLN的核心创新,是将潜在自回归视频骨干与导航动作解码深度融合。
它不做“观测→动作”的直接映射,也不生成完整视频帧,而是在压缩后的潜在空间里自回归预测短视界的世界变化,再通过一个轻量的动作解码器输出 4自由度航点(三维位移+偏航角)。
整个系统是闭环的:预测 → 解码动作 → 执行 → 新观测 → 替换预测 → 再预测。
自回归 + 闭环校准,从根上解决了长序列漂移问题。
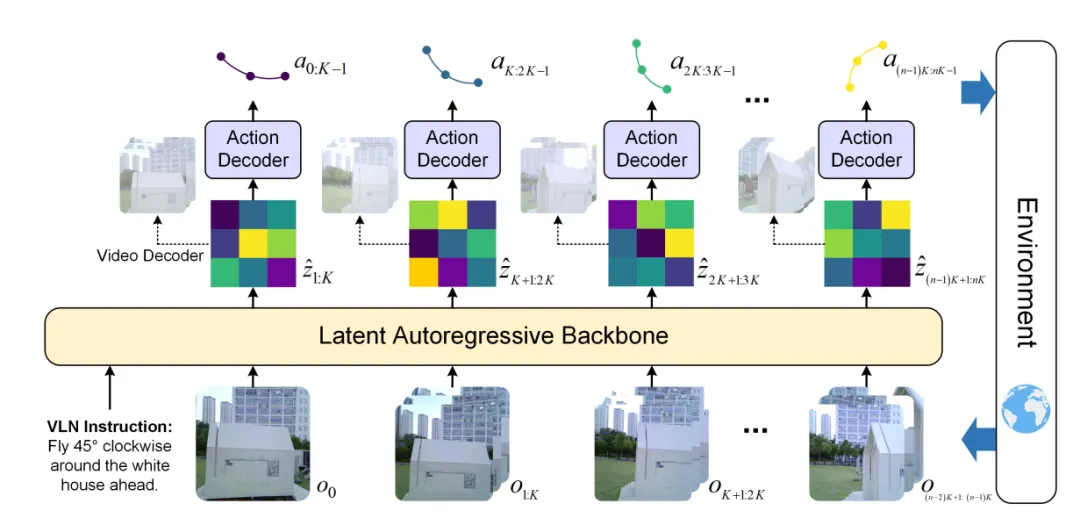
(一)基础架构:四大模块构建闭环世界-动作链路
WorldVLN架构由文本编码器、视频VAE编码器、潜在自回归Transformer骨干、动作解码器四大核心模块组成,整体遵循“先编码、再预测、直解码、强闭环”的逻辑。
图| WorldVLN 整体架构图
1. 双编码器:统一语言与视觉表征
a. 文本编码器:将自然语言指令(如“绕汽车左侧绕行”)编码为语义向量,捕捉指令的目标、动作、空间关系;
b. 视频VAE编码器:将无人机实时单目RGB观测(历史帧序列)压缩为潜在空间表征,过滤冗余视觉信息,保留视角变化、空间结构、运动趋势等核心时序特征。
2. 潜在自回归Transformer骨干:预测短视界世界状态过渡
该骨干采用预训练的InfinityStar潜在自回归视频模型,是WorldVLN的“世界模拟器”。其核心功能是:基于语言指令表征与历史观测潜在序列,自回归预测未来短视界(K帧)的潜在世界状态,而非生成完整视频帧。
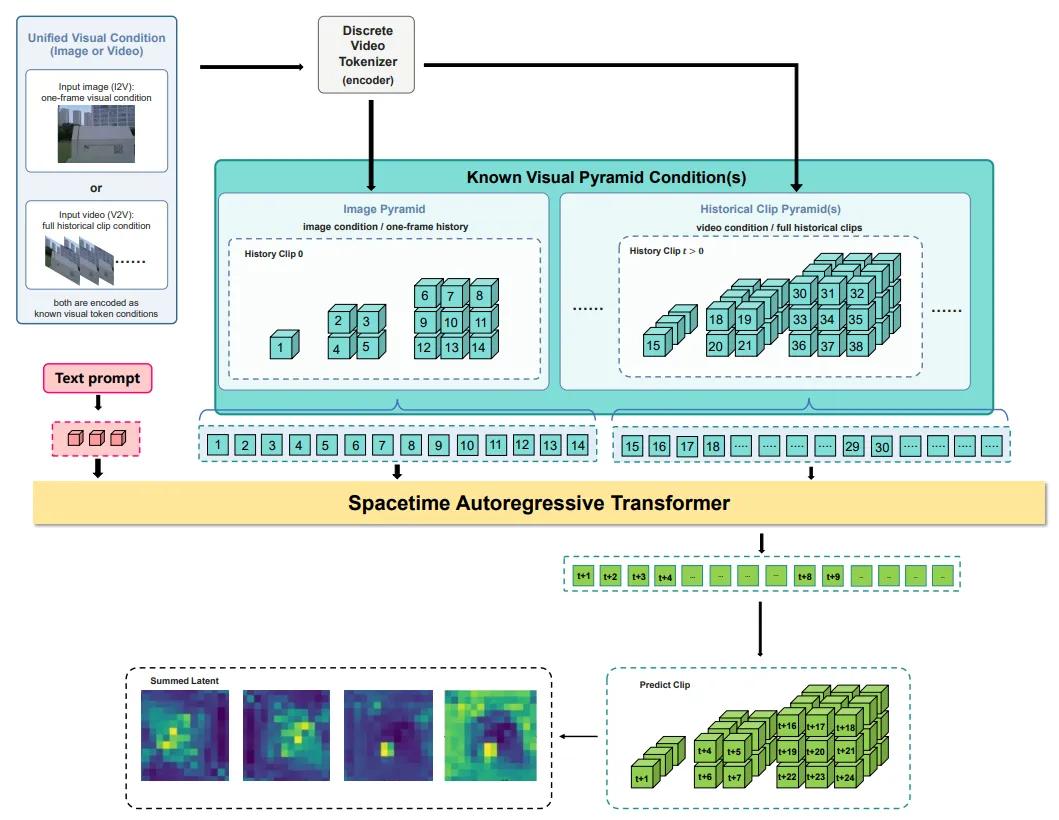
图| 潜在空间时空自回归世界骨干网络架构
这里的“自回归”是关键——每预测一段潜在状态,就用真实执行后的新观测更新上下文,再预测下一段,彻底适配导航的因果闭环需求,避免双向模型的时序混乱。
3. 动作解码器:从潜在状态直解码航点动作
这是WorldVLN区别于传统世界模型的核心设计。传统视频模型会将预测的潜在状态解码为RGB帧,而WorldVLN的动作解码器直接将未来潜在世界状态过渡,映射为无人机可执行的4自由度航点动作。
航点动作定义为:,其中
是三维相对位移,
是偏航角变化,直接对应无人机的飞行控制指令,无需额外转换。
4. 闭环更新机制:真实观测校准世界预测
无人机执行航点动作后,会获取新的视觉观测,经视频VAE编码器压缩为真实潜在状态,替换模型预测的潜在状态,输入自回归上下文,开启下一轮预测-执行循环。这种设计能实时纠正预测误差,避免长序列导航中的误差累积,大幅提升稳定性。
(二)两阶段训练框架:监督打底+强化对齐,兼顾稳定性与目标性
为让世界模型的视觉先验适配导航任务,同时让动作决策贴合指令目标,WorldVLN设计了两阶段训练框架,先通过监督学习“打基础”,再用定制化强化学习“调优化”。
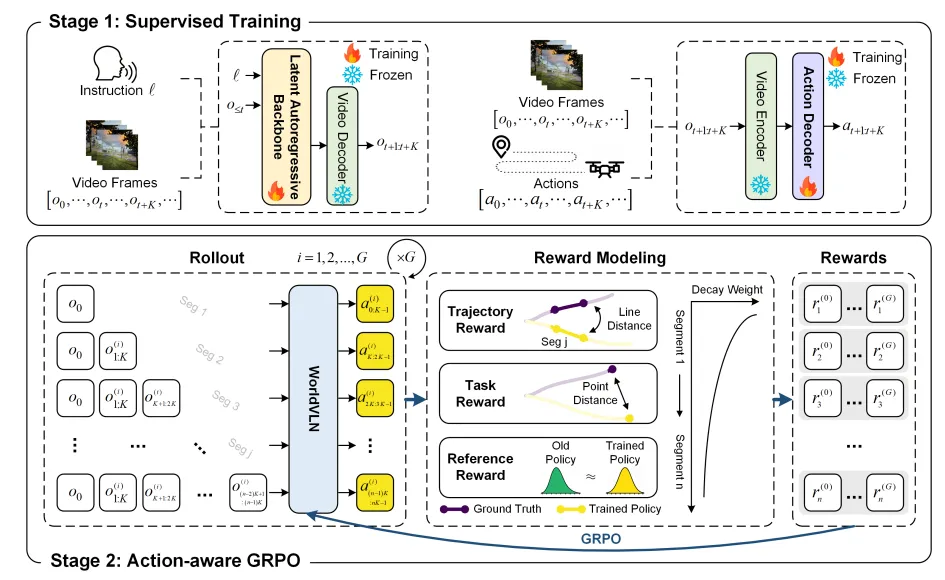
图| WorldVLN 两阶段训练框架
第一阶段:监督训练——锚定视频先验,学会从视觉到动作
此阶段目标是让骨干模型理解“语言指令+视觉观测→世界状态变化”的关联,同时让动作解码器学会从潜在状态恢复专家航点动作。
- 骨干模型训练:输入“语言指令+对应导航视频”,训练模型从指令与历史潜在状态,预测未来真实潜在状态,损失函数为对数概率损失,本质是让视频模型“看懂导航动态”。
- 动作解码器训练:输入“导航视频+专家航点轨迹”,将视频编码为潜在状态,训练解码器输出与专家动作一致的航点,损失函数为均方误差,确保解码动作可执行、贴合人类操控逻辑。
第二阶段:Action-aware GRPO——强化动作后果对齐,优化目标导向决策
监督学习只能让模型“模仿专家”,无法适配动态环境、优化长期目标。为此,WorldVLN提出首个面向自回归WAM的强化学习方法——Action-aware GRPO,核心是通过在线轨迹推演,用动作的实际后果优化决策。
其核心设计包括三点:
- 多维度奖励函数:同时考虑轨迹奖励(与专家动作的几何相似度)、任务奖励(最终是否到达目标)、参考奖励(避免模型偏离监督学习学到的世界先验),兼顾短期动作精度与长期目标达成。
- 时序衰减权重:早期决策对后续轨迹影响更大,因此给早期动作更高奖励权重,倒逼模型重视初始决策的准确性,减少长序列误差。
- 分段式优化:模型每次生成一段(K帧)动作,执行后计算奖励,更新模型参数,实现“边执行、边学习、边优化”,贴合真实导航的闭环场景。
02 零样本迁移真实无人机
WorldVLN在室外UAV-Flow、室内IndoorUAV-VLA两大主流空中VLN基准上,实现了对现有VLA模型的全面超越,且在真实无人机上完成零样本部署,验证了模型的有效性与泛化性。

▲室内模拟(室内无人机)
(一)仿真基准:成功率提升12%+,复杂场景优势更显著
1. 室外基准UAV-Flow
该基准包含接近、降落、绕行、升降等12类典型室外无人机任务,分为固定模板指令与开放词汇指令两类测试场景。
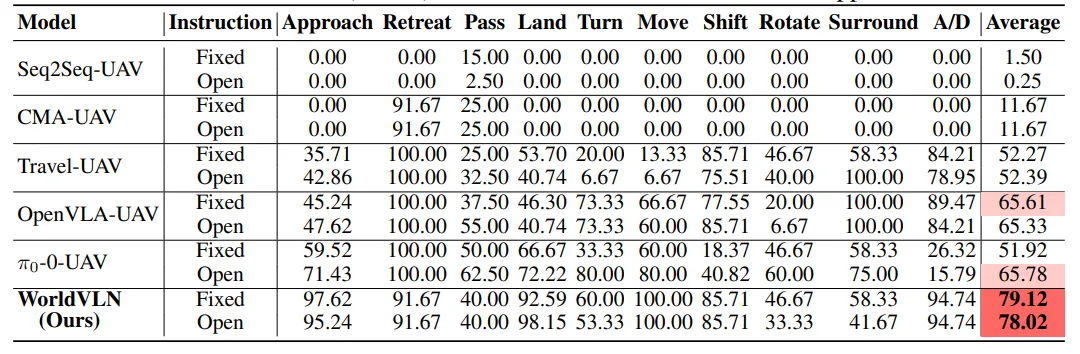
图| UAV-Flow-Sim 测试集成功率(SR)
- 核心结果:WorldVLN平均成功率达79.12%(固定指令)、78.02%(开放指令),比最强VLA基线(OpenVLA)高出13.51、12.24个百分点,比π₀模型高出19.72个百分点。
- 优势场景:在接近、降落、精准移动等对空间精度要求高的任务中,成功率超90%;开放词汇指令下性能几乎无下降,证明模型能理解多样化语言表达。
2. 室内基准IndoorUAV-VLA
室内场景空间狭窄、障碍物密集、视角变化剧烈,分为简单、中等、困难三个难度等级,核心指标为成功率(SR)与轨迹相似度(NDTW)。
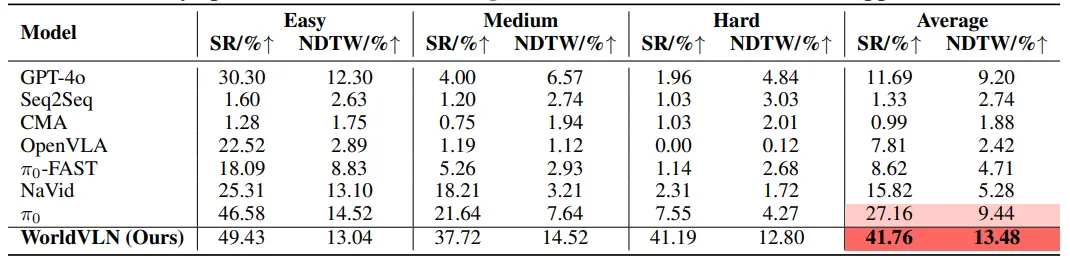
图| IndoorUAV-VLA 基准测试结果
- 核心结果:WorldVLN全测试集成功率达41.76%,比最优基线(π₀)高出14.60个百分点;困难场景下成功率达41.19%,比基线高出33.64个百分点,难度越高,优势越明显。
- 关键结论:自回归世界建模能有效捕捉室内狭小空间的几何约束与动态变化,强化学习则让模型在多步骤复杂动作组合中,保持精准的空间定位与姿态控制。
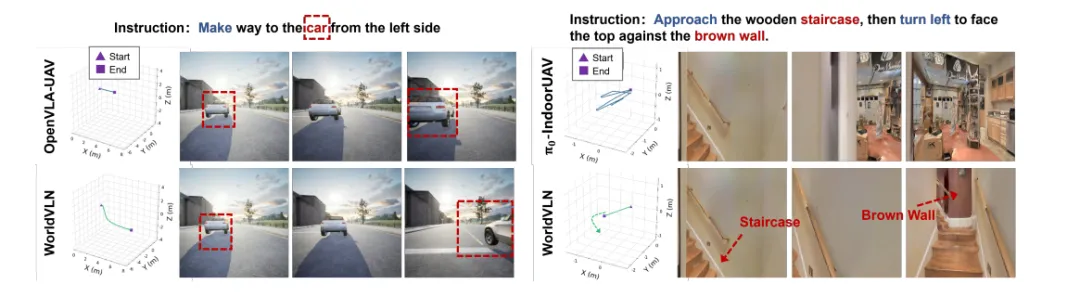
图| 室外 / 室内场景案例对比
(二)消融实验:三大设计缺一不可,验证核心创新价值
为拆解各模块的贡献,研究团队开展了系统性消融实验,核心结论如下:
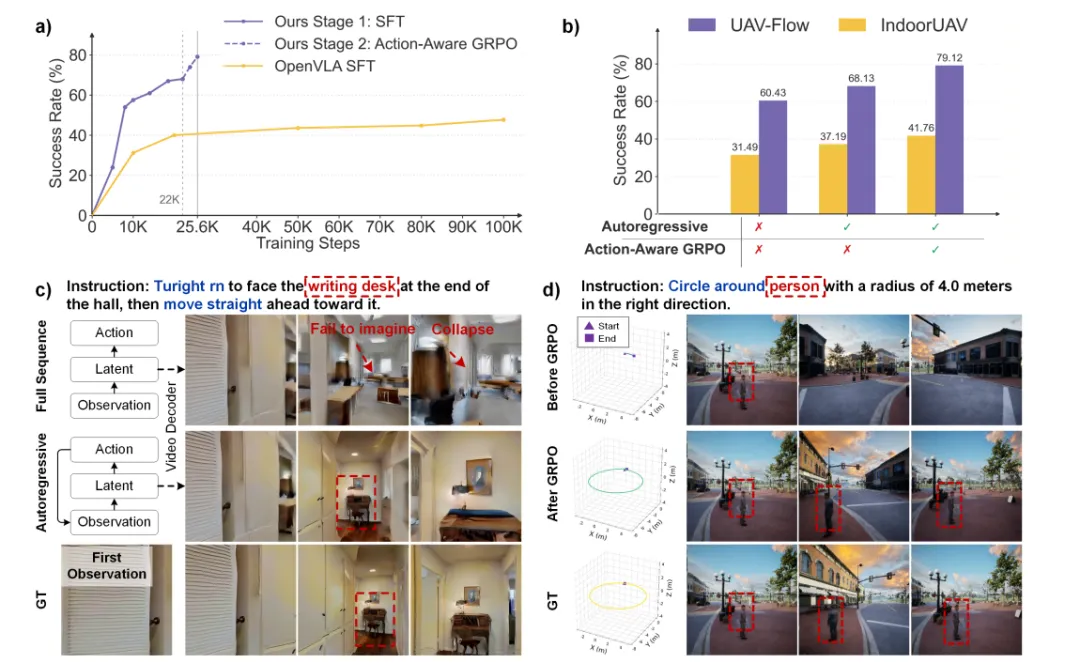
图| 消融实验结果(训练曲线、自回归、GRPO)
1. 自回归预测是性能核心:对比全序列预测(一次性生成所有潜在状态),自回归预测使成功率提升5.7个百分点以上,且能避免语义漂移、场景崩溃,保持视觉-空间表征的连贯性。
2. Action-aware GRPO是优化关键:仅用第一阶段监督训练,性能会饱和;加入强化学习后,成功率再提升10个百分点以上,且能生成更贴合指令的几何轨迹(如圆形绕行)。
3. WAM范式优于VLA:相同训练步数下,WorldVLN的学习效率远高于OpenVLA,证明“预测世界状态再解码动作”的范式,比“直接映射观测到动作”更适配空中VLN任务。
(三)真实无人机部署:零样本迁移,仿真到现实无缝衔接
最具突破性的是,WorldVLN仅用仿真数据训练,即可零样本部署到真实四旋翼无人机,无需额外微调
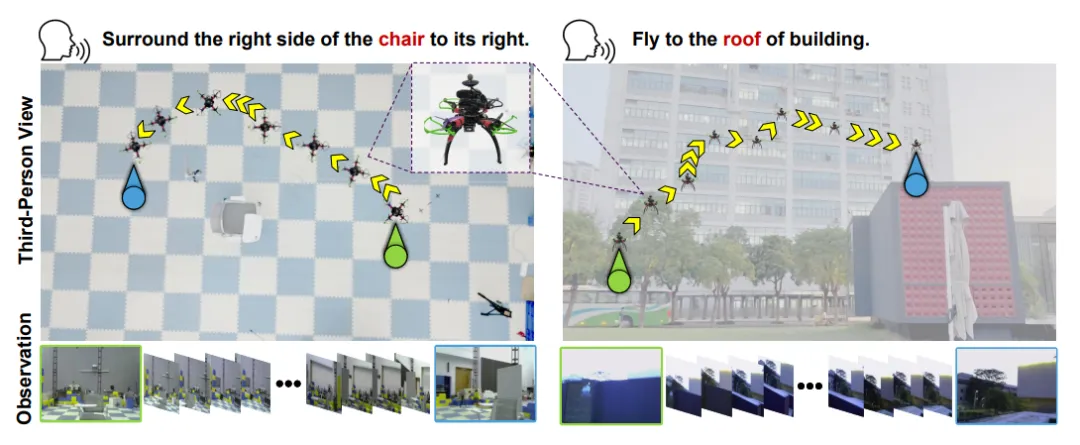
图| 真实无人机部署案例
- 硬件配置:250mm轴距四旋翼,搭载Logi C270 RGB相机、Jetson Orin NX机载电脑、CUAV PX4飞控,模型推理在远程服务器完成,无人机负责感知与执行。
- 测试场景:
室内:10m×15m×3m场地,14相机动作捕捉系统定位,完成“靠近目标物体、对齐姿态”等任务;
室外:开阔场地,GPS+激光雷达定高,完成“绕建筑飞行、垂直升降”等任务。
- 核心结论:模型能直接理解自然语言指令,生成平滑、精准的航点轨迹,适应真实世界的光照变化、噪声干扰与动力学约束,证明世界动作表征具备极强的跨环境泛化能力。

▲户外真实世界部署展示
03 世界模型不应止步于画面生成
客观而言,WorldVLN仍处于技术探索阶段,存在三大核心局限:
1. 长时序任务适配不足:当前仅验证了短距离、短视界的导航任务,长距离、多阶段复杂指令(如“从A点起飞→绕B建筑→降落C点”)的性能尚未验证,长时序误差累积问题仍需解决。
2. 推理依赖服务器:骨干模型参数规模较大,当前真实部署需依赖远程服务器推理,无法实现无人机端侧实时运行,限制了极端环境(如无信号区域)的应用。
3. 动态环境鲁棒性不足:训练与测试场景以静态环境为主,对动态障碍物、极端天气、强光照变化等真实复杂场景的适配性未充分验证。
但不可否认的是,WorldVLN为空间动作任务提供了极具潜力的技术路径,也为具身智能的发展注入了新的思路。
世界模型不应止步于画面生成,而应服务于动作决策。
未来,随着模型优化与技术迭代,这类预测驱动的世界动作模型,或将成为无人机、机器人等智能体语言指令化操控的主流方案。
Ref
论文标题:WorldVLN: Autoregressive World Action Model forAerial Vision-Language Navigation
论文链接:https://arxiv.org/pdf/2605.15964v1
项目链接:https://embodiedcity.github.io/WorldVLN/

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 5
5 0
0- 0



 已为社区贡献68条内容
已为社区贡献68条内容

所有评论(0)