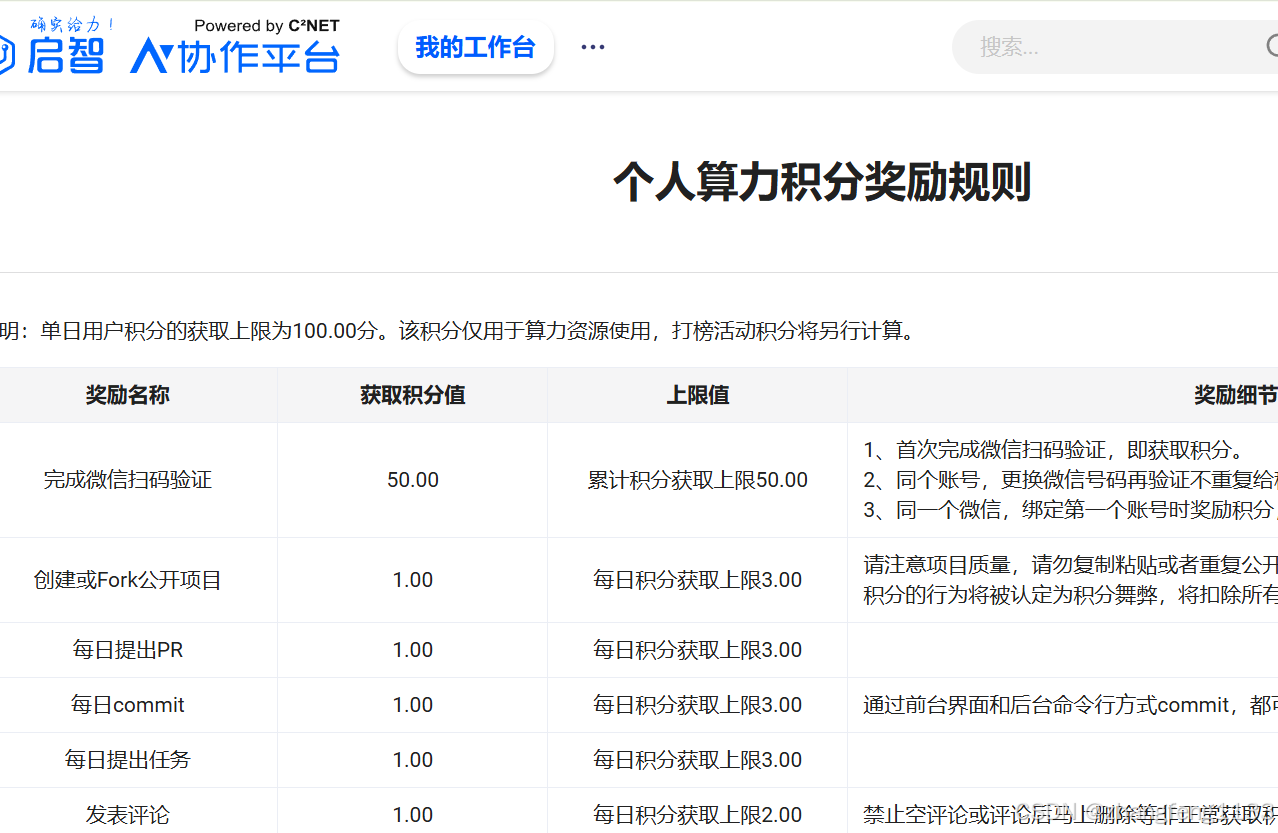
白嫖 启智社区(OpenI)50点卡(优惠卡有50卡时)的方法 支持各个国产算力卡 和nvidia的卡
开源项目
https://www.deepspark.org.cn/
https://github.com/Deep-Spark/
启智社区(OpenI)的官方网站地址是:天数智芯天垓100算力租借,国产算力平台
https://www.openi.org.cn
启智云脑(提供天垓100等国产算力)的入口通常在官网内,具体算力平台地址为:
https://cloud.openi.org.cn
启智算力平台 送50卡时(50积分,有些卡没有50卡时) https://www.openi.org.cn/
注册地址
您的好友正在邀请您加入OpenI启智AI协作平台,畅享充沛的普惠算力资源(GPU/NPU/GCU/GPGPU/DCU/MLU)。
注册地址:https://openi.pcl.ac.cn/user/sign_up?sharedUser=yanggg1133
推荐人:yanggg1133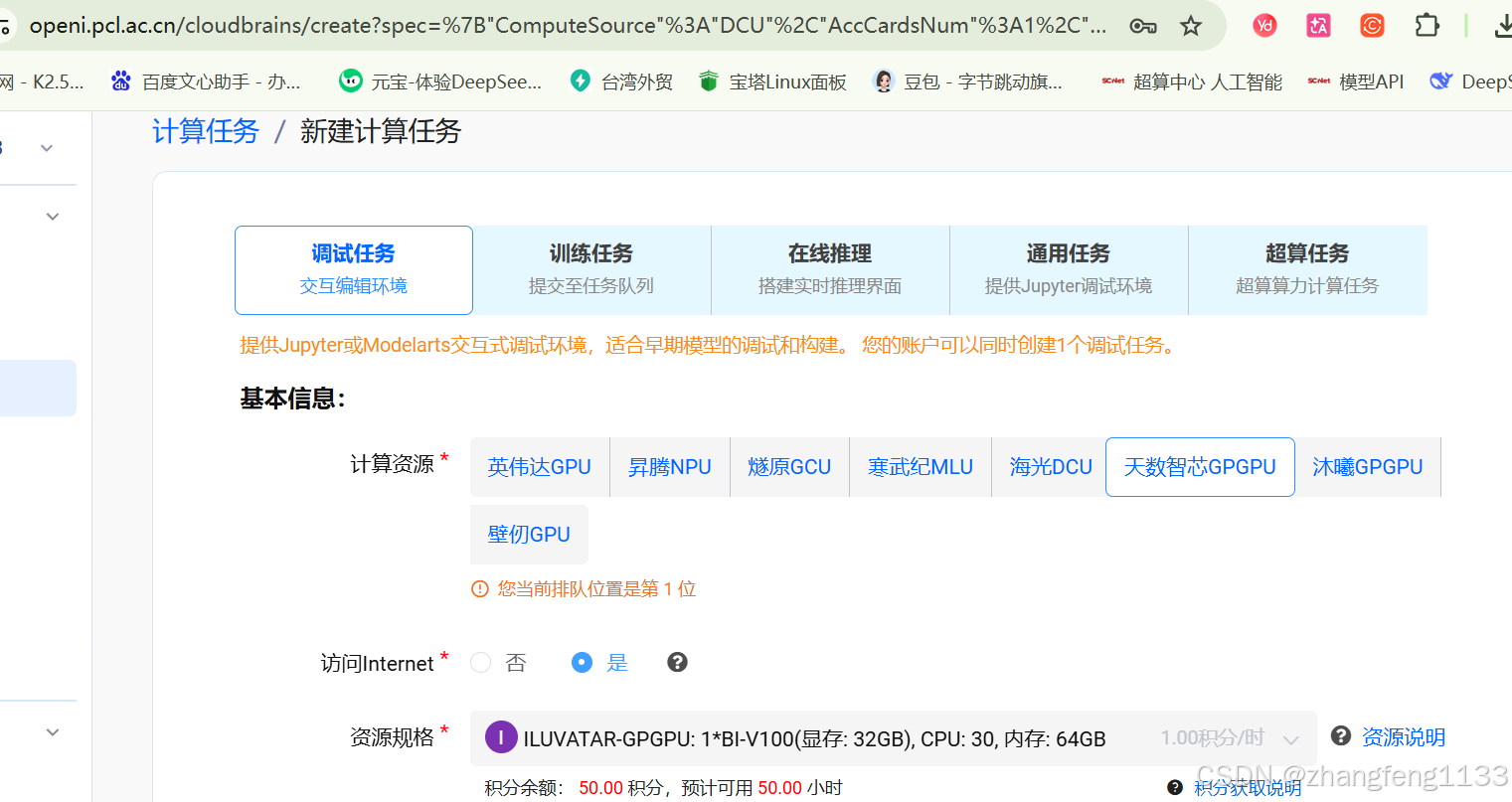

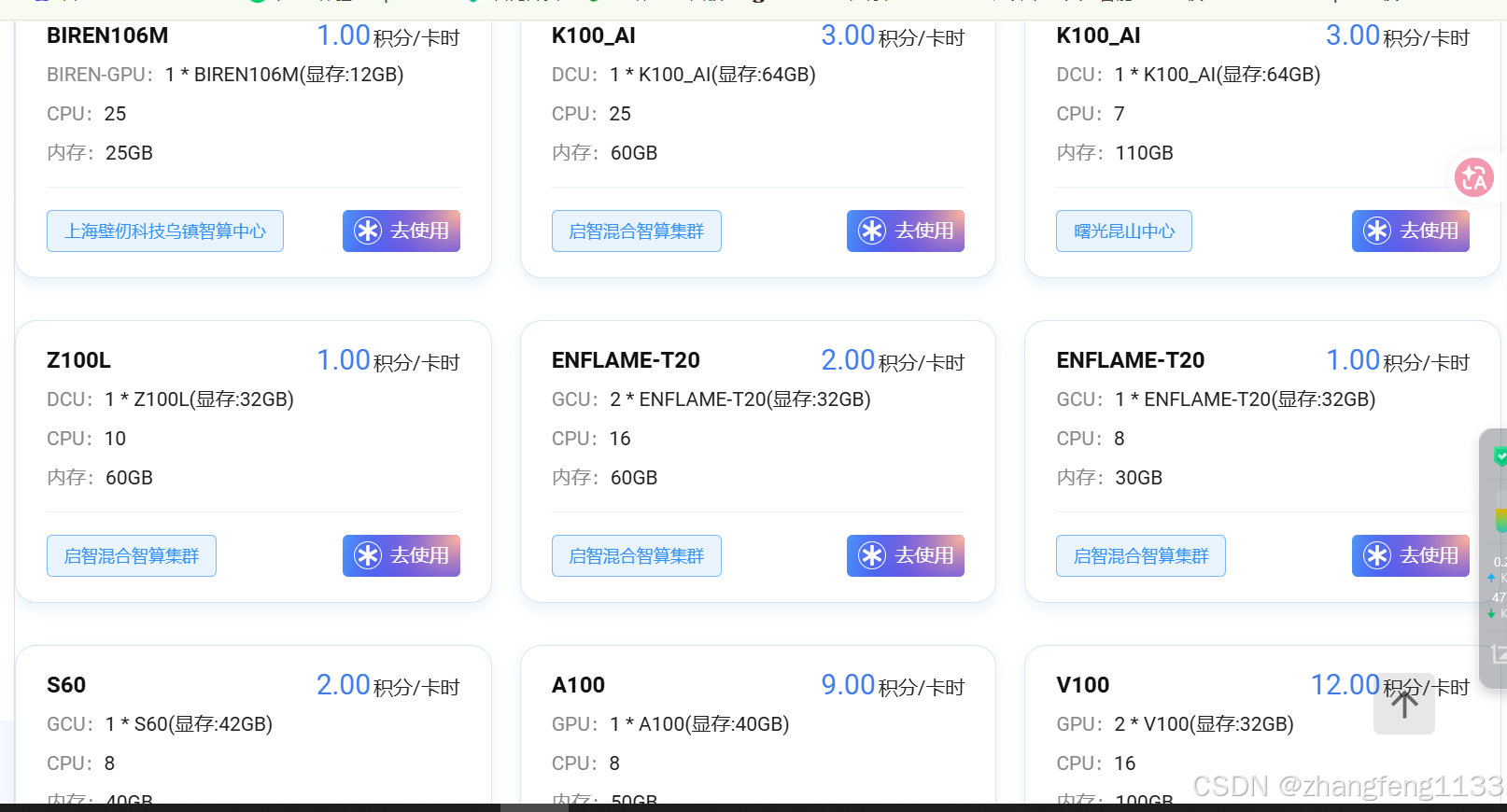

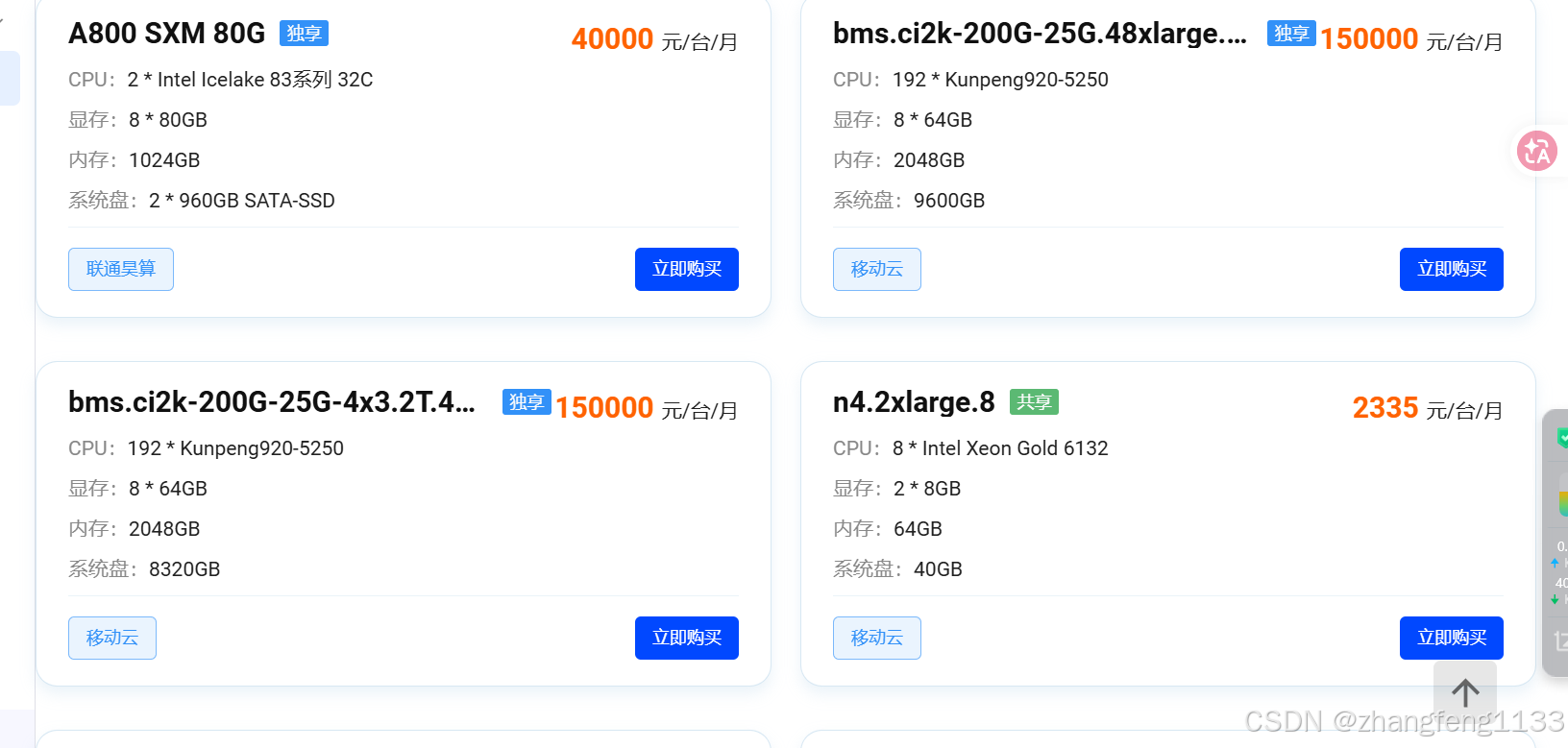
全机型算力卡详细介绍(按清单顺序,分国产自研芯片+英伟达GPU两大阵营,标注算力中心、计价、显存、适用场景)
一、壁仞BIREN106M|壁仞BR106系列(上海壁仞·乌镇智算中心|1积分/卡时)
- 硬件规格:1×BIREN106M(BR106),12GB显存、绑定CPU25核、内存25GB,国产壁仞自研GPGPU架构(7nm芯粒工艺)
- 算力参数:FP32≈24TFLOPS、BF16/FP16≈96TFLOPS、INT8≈192TOPS;原生BIRENSUPA软件栈,类CUDA兼容PyTorch/TensorFlow/PaddlePaddle全框架
- 特色:支持GPU虚拟化切分4个算力实例,自带硬编解码(32路H.265编码、256路解码),国产高性价比入门卡
- 适用:7B及以内大模型微调、LLM推理、CV检测、短视频转码,1积分成本极低,新手练手首选
二、海光K100_AI(DCU深度计算单元|启智混合/曙光昆山,3积分/卡时,两套配置)
K100_AI是海光旗舰AI DCU,国产对标A100主力训练卡,64GB HBM2超大显存
①启智集群版:1×K100_AI|CPU25核、内存60GB|3积分/时
②曙光昆山版:1×K100_AI|CPU7核、内存110GB|3积分/时(超大主机内存,大模型加载优势)
- 核心参数:64GB HBM2显存、带宽1200GB/s;FP32=49TFLOPS、BF16/FP16=192TFLOPS、INT8=384TOPS、TF32=96TFLOPS,TDP300W,PCIe4.0
- 软件:DTK工具链,高度兼容CUDA生态,Pytorch/Transformers原生适配,不用深度移植代码
- 适用:13B/34B大模型全参数微调、LoRA微调、文生图大模型训练、批量离线推理;昆山版超大内存适合加载超大权重、多Batch并发推理
三、海光Z100L DCU|启智混合智算|1积分/卡时
- 规格:1×Z100L,32GB HBM2显存、CPU10核、内存60GB,海光中端DCU(Vega20授权架构)
- 算力:FP32≈23.2TFLOPS、FP16≈185TFLOPS、INT8≈370TOPS,显存带宽1024GB/s,性价比国产平替单卡V100
- 适用:7B-13B模型微调、SD绘画训练、小模型推理、传统机器学习,1积分低价主力日常算力
四、燧原ENFLAME-T20(GCU|燧原自研训推一体芯片|启智集群,2档规格)
燧原云燧T20,国产训练GCU,自研TopsRider驭算软件栈
①双卡版:2×ENFLAME-T20|单卡32GB显存、合计64GB、CPU16核、内存60GB|2积分/时
②单卡版:1×ENFLAME-T20|32GB显存、CPU8核、内存30GB|1积分/时
- 参数:单卡32GB HBM,FP16≈128TFLOPS、INT8≈256TOPS,双卡自带片间高速互联,多卡训练友好
- 适用:双卡:13B模型微调、批量SD炼丹;单卡:7B推理、小模型微调、CV项目,国产性价比首选
五、燧原S60 GCU|启智混合|2积分/卡时
- 规格:1×S60、42GB HBM显存、CPU8核、内存40GB,燧原主打训推一体中端卡
- 定位:推理优先、兼顾轻量训练;INT8优化极强,42GB显存可直接单卡放下13B量化模型(GPTQ/AWQ)
- 适用:大模型线上API推理、批量量化部署、小模型快速微调、语音ASR推理
六、英伟达A100 40GB|启智混合|9积分/卡时(国际顶级训练卡,Ampere架构)
- 规格:1×A100 PCIe、40GB HBM2e、CPU8核、内存50GB
- 算力:FP32=19.5TFLOPS、BF16/FP16=312TFLOPS、INT8=624TOPS、支持TF32混合精度;支持MIG显存切分(单卡拆7块10GB虚拟卡)
- 优势:CUDA原生完美适配所有开源项目、生态最全,大模型训练标杆
- 适用:34B/70B大模型微调、千亿级预训练、高精度文生图训练、科研实验(积分成本高,重度训练使用)
七、英伟达V100 Volta架构(三档规格|启智集群,6/12/1积分三档)
V100是经典数据中心GPU,HBM2 32GB,老一代AI训练标杆,生态全兼容
- 双V100版:2×V100(单卡32GB)、CPU16核、内存100GB|12积分/时:双卡NVLink互联,适合13B~34B多卡并行微调
- 单V100版:1×V100 32GB、CPU8核、内存50GB|6积分/时:7B~13B全参数微调、SD大炼丹
- 零卡轻量化版:0×V100、CPU4核、内存32GB|1积分/时:纯CPU算力,仅用于数据预处理、数据集清洗、代码调试,无GPU加速
单V100算力:FP16=130TFLOPS、INT8=260TOPS,HBM2带宽900GB/s
八、壁仞ILUVATAR系列(天数云机房,BI-V100/BI-V150/MR-V100,壁仞沐曦联合定制GPGPU,类V100/A100对标)
1.BI-V100双卡:2×BI-V100(32GB)|CPU60核、内存128GB|2积分/时
双32GB合计64GB显存,超大CPU内存,多并发推理、批量微调,国产平替双V100
2.BI-V100单卡:1×BI-V100(32GB)|CPU30核、内存64GB|1积分/时
入门国产32GB卡,对标单V100,7B推理、LoRA微调性价比之王
3.BI-V150单卡:1×BI-V150(64GB)|CPU10核、内存40GB|2积分/时
64GB超大显存国产卡,对标K100/A100入门,单卡直跑34B量化模型、13B全参数微调
4.MR-V100四卡:4×MR-V100(32GB)|CPU28核、内存160GB|4积分/时
4张32GB合计128GB显存,多卡高速互联,集群化训练34B~70B大模型、批量SD集群炼丹
选型速记
- 练手/低成本推理(1积分):BIREN106M、Z100L、单T20、单BI-V100、无GPU版V100
- 常规微调7B13B(23积分):S60、双卡T20、K100全系列、BI-V150、双卡BI-V100
- 中大模型34B+训练(4~12积分):MR-V100四卡、单/双V100、A100
- 国产优先避英伟达:壁仞+海光+燧原全系列;CUDA原生无脑选:A100/V100
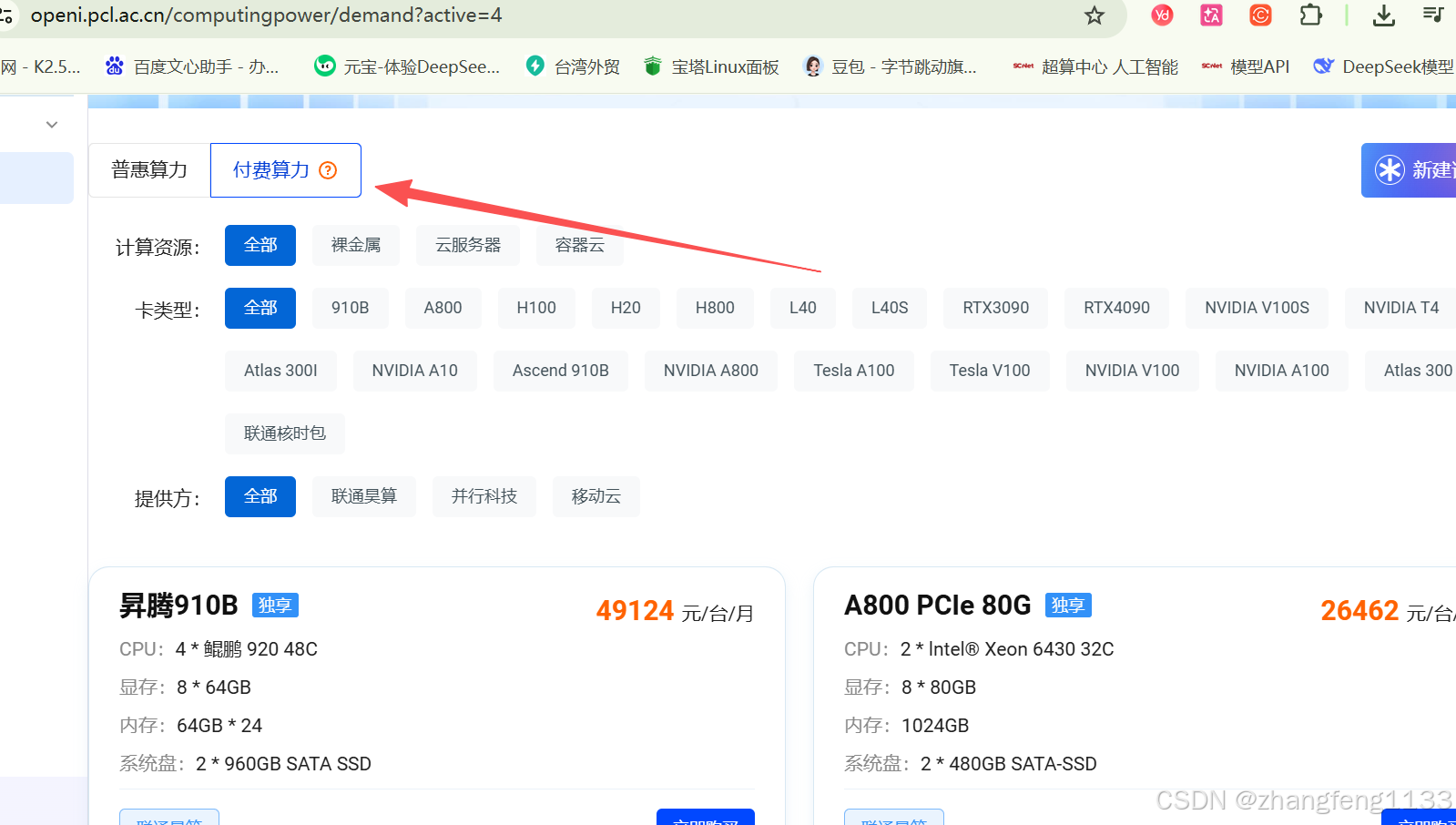
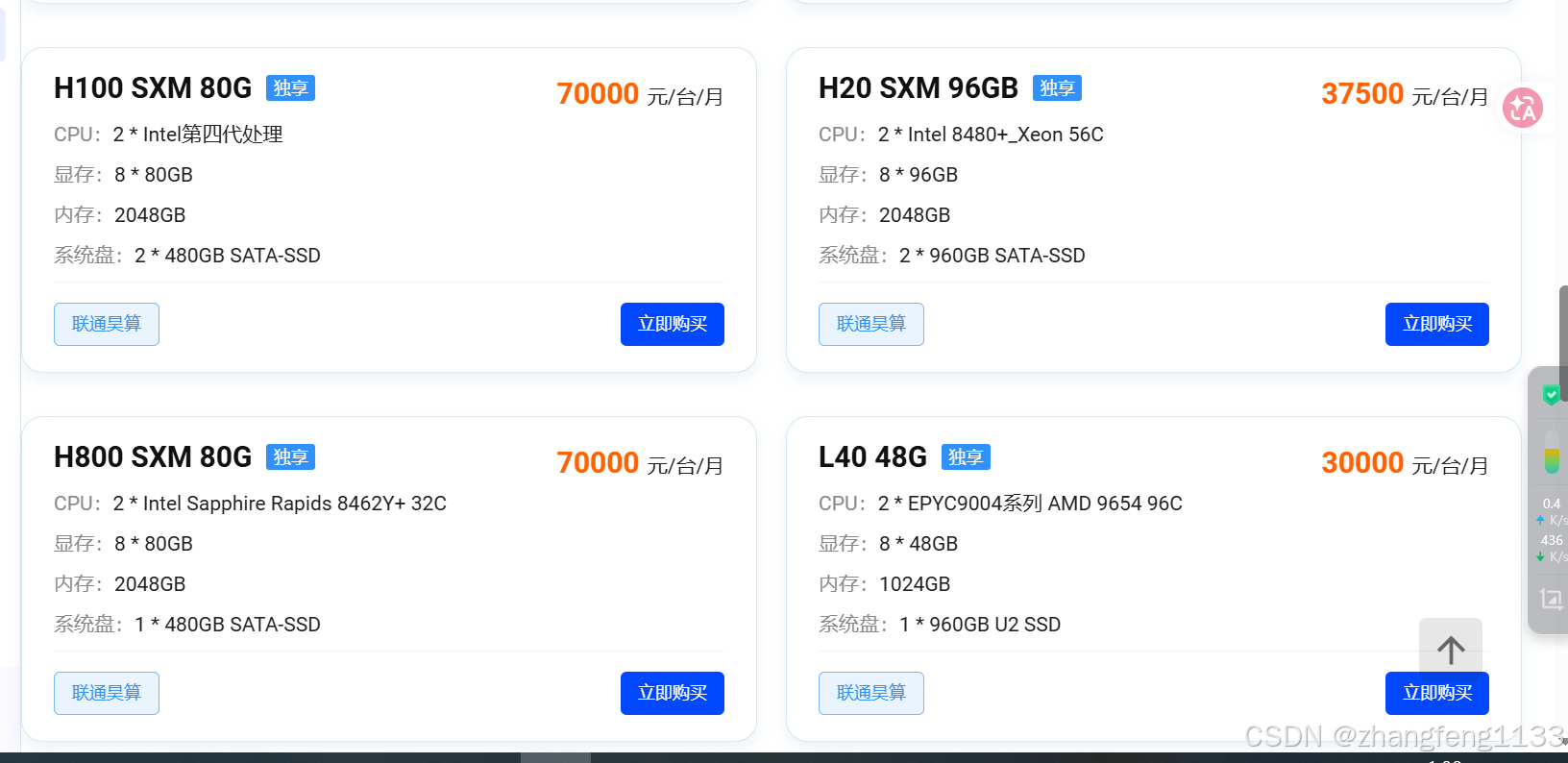
还可以直接租用服务器

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 13
13 0
0- 0



 已为社区贡献58条内容
已为社区贡献58条内容

所有评论(0)