想要转型AI Agent开发?现在开始学,还不晚

一、为什么现在是转型 AI Agent 开发的好时机?
过去两年,AI 应用从「能用」走向「好用」,核心驱动力是 Agent 化,让 AI 不只是回答问题,而是能自主规划、调用工具、完成任务。市场上招的人多,但真正懂这套的人少。
为什么懂的人少
-
岗位薪资比传统后端高 30-60%,招聘却长期找不到合适的人
-
LangChain/LangGraph 2022-2023 年出现,到现在三四年,系统掌握的人依然不多
-
大多数"AI 工程师"只会调 API,不会设计和搭建复杂 Agent 系统
-
RAG + Agent 复合能力,市场缺口巨大
为什么机会多
-
几乎所有大厂都在做内部 AI 助手、知识库问答
-
传统软件公司纷纷把 AI 能力嵌入已有产品
-
AI Coding、AI 客服、AI 数据分析,每条赛道都缺 Agent 工程师
-
2026 年正是企业 AI Agent 从 POC 走向生产的节点,需求在这两年集中爆发
现在花 3-6 个月系统学习 AI Agent 开发,出去面试大概率能拿到比现在高 30% 以上的 offer。这个窗口期大约还有 1-2 年。
二、行业内公司都在用什么技术栈
按公司类型分布
|
公司类型 |
典型技术栈 |
AI 层语言 |
业务层语言 |
|---|---|---|---|
| AI 原生创业公司 |
Python + LangChain/LangGraph + FastAPI |
Python |
Python(全栈) |
| 大厂 AI 业务线 |
Python AI 服务 + Java/Go 业务系统,RPC 打通 |
Python |
Java / Go |
| 传统企业数字化 |
Dify / 扣子 低代码平台 + 已有 Java 系统 |
低代码/Python |
Java |
| 中小 SaaS 公司 |
Python + LangChain + OpenAI/国产模型 API |
Python |
Python / Node.js |
| toC 产品团队 |
Node.js(Vercel AI SDK)或 Python 后端 |
Python / TS |
TypeScript |
技术栈使用频率排行(2025-2026)
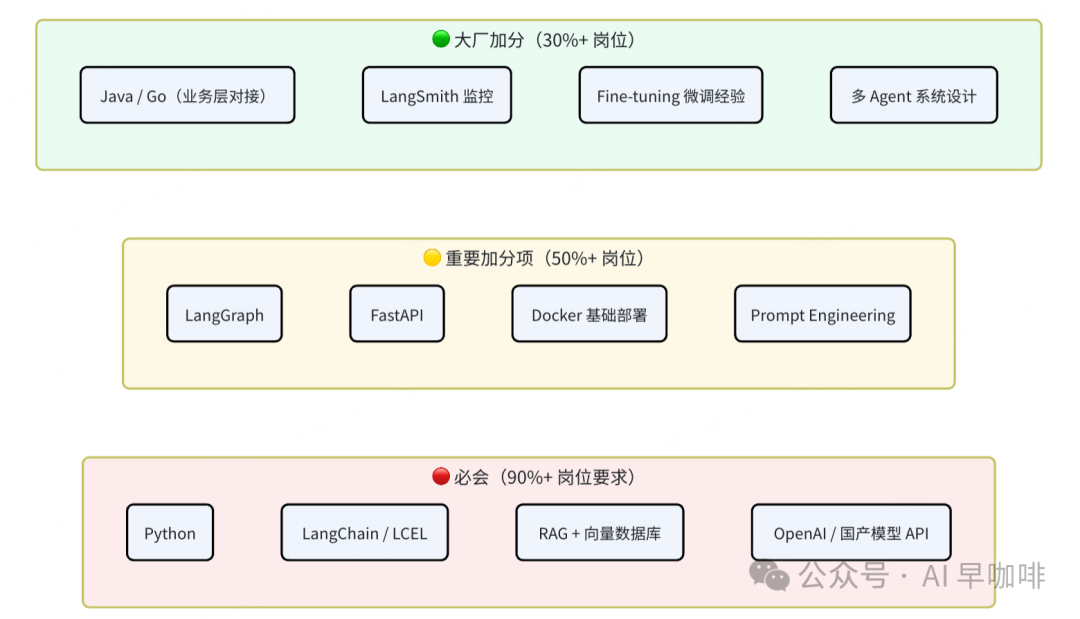
Python 没得选。LangChain 是目前最成熟的框架,会的人直接上手用。RAG 几乎每个岗位都要,没做过项目就会被面试追问到哑口无言。LangGraph 和 FastAPI 是进阶必会。Java 会的话加分,不会也不影响入门。
三、核心技术栈分层次解析
第一层:Python 基础能力
很多人以为"会 Python"就够了,但 AI Agent 开发对 Python 有特定的能力要求,不是会写 for 循环就行的。
|
能力项 |
具体要求 |
说明 |
|---|---|---|
| 类型注解 |
def fn(x: str) -> list[dict] |
LangChain 到处在用,不懂会看不懂源码 |
| Pydantic |
BaseModel、Field、数据校验 |
结构化输出的核心,几乎每个 Agent 项目都用 |
| 异步编程 |
async/await、asyncio |
流式输出、并发调用 LLM 必须 |
| 装饰器 |
@tool、@chain、自定义装饰器 |
LangChain 工具定义就靠这个 |
| 环境管理 |
venv / conda、.env 文件 |
API Key 管理,项目隔离 |
常见误区:从 Java 转来的同学容易把 Python 写成 Java 风,到处写 class,不用列表推导式,不懂 duck typing。AI Agent 开发里函数式风格更常见,这个要注意。
第二层:LangChain 核心体系
LangChain 是目前最成熟的 AI 应用开发框架,面试高频。核心模块:
LCEL(LangChain Expression Language)
用 | 管道符把组件串联成链,是 LangChain 现代写法的核心:
from langchain_openai import ChatOpenAI
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.output_parsers import StrOutputParser
# 三个组件用 | 串联 = 一条链
chain = ChatPromptTemplate.from_messages([
("system", "你是{role}"),
("user", "{question}"),
]) | ChatOpenAI(model="gpt-4o-mini") | StrOutputParser()
# 调用
result = chain.invoke({"role": "Python 专家", "question": "什么是装饰器?"})
# 流式输出(生产必备)
for chunk in chain.stream({"role": "Python 专家", "question": "什么是装饰器?"}):
print(chunk, end="", flush=True)
Tool(工具), 定义和使用工具
from langchain_core.tools import tool
from langchain_openai import ChatOpenAI
# 用 @tool 装饰器定义工具
@tool
def search_web(query: str) -> str:
"""搜索互联网获取实时信息。当需要最新数据时使用此工具。"""
# 实际接入 Tavily / Serper 等搜索 API
returnf"搜索结果:关于 {query} 的最新信息..."
@tool
def calculate(expression: str) -> str:
"""计算数学表达式,如 '2 + 3 * 4'"""
return str(eval(expression))
# 绑定工具到模型
tools = [search_web, calculate]
llm_with_tools = ChatOpenAI(model="gpt-4o-mini").bind_tools(tools)
# 模型会自动决定是否调用工具
response = llm_with_tools.invoke("今天上海天气怎么样?")
print(response.tool_calls) # [{"name": "search_web", "args": {...}}]
Memory(记忆),带记忆的对话
from langchain_core.chat_history import InMemoryChatMessageHistory
from langchain_core.runnables.history import RunnableWithMessageHistory
llm = ChatOpenAI(model="gpt-4o-mini")
store = {}
def get_session_history(session_id: str):
if session_id notin store:
store[session_id] = InMemoryChatMessageHistory()
return store[session_id]
# 包装成带记忆的链
chain_with_memory = RunnableWithMessageHistory(llm, get_session_history)
config = {"configurable": {"session_id": "user_001"}}
# 多轮对话,自动记忆上下文
chain_with_memory.invoke([{"role": "user", "content": "我叫小明"}], config=config)
r = chain_with_memory.invoke([{"role": "user", "content": "我叫什么?"}], config=config)
print(r.content) # "你叫小明"
第三层:RAG(检索增强生成)
RAG 是企业 AI 落地最多的场景。你去看招聘 JD,有 RAG 经验基本是标配要求。
RAG 完整流程
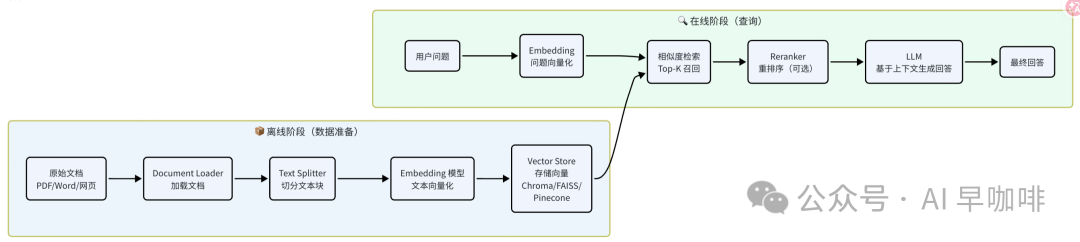
RAG 实现代码示例:
from langchain_community.document_loaders import PyPDFLoader
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain_openai import OpenAIEmbeddings, ChatOpenAI
from langchain_community.vectorstores import Chroma
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.output_parsers import StrOutputParser
from langchain_core.runnables import RunnablePassthrough
# ── 1. 加载并切分文档 ──────────────────────────────────
loader = PyPDFLoader("company_docs.pdf")
docs = loader.load()
splitter = RecursiveCharacterTextSplitter(
chunk_size=500, # 每块最多500字
chunk_overlap=50, # 块间重叠50字,防止语义断裂
)
chunks = splitter.split_documents(docs)
# ── 2. 向量化并存入数据库 ──────────────────────────────
embeddings = OpenAIEmbeddings(model="text-embedding-3-small")
vectorstore = Chroma.from_documents(chunks, embeddings, persist_directory="./chroma_db")
retriever = vectorstore.as_retriever(search_kwargs={"k": 4})
# ── 3. 构建 RAG Chain ─────────────────────────────────
prompt = ChatPromptTemplate.from_messages([
("system", """你是专业助手,根据以下上下文回答问题。
如果上下文中没有相关信息,如实说"我在文档中没有找到相关信息",不要编造。
上下文:
{context}"""),
("user", "{question}"),
])
def format_docs(docs):
return"\n\n".join(d.page_content for d in docs)
rag_chain = (
{"context": retriever | format_docs, "question": RunnablePassthrough()}
| prompt
| ChatOpenAI(model="gpt-4o-mini")
| StrOutputParser()
)
# ── 4. 查询 ───────────────────────────────────────────
answer = rag_chain.invoke("公司的退款政策是什么?")
print(answer)
向量数据库选型对比
|
数据库 |
类型 |
适用规模 |
推荐场景 |
|---|---|---|---|
| FAISS |
内存/本地 |
百万级以下 |
本地开发、快速原型、不需持久化 |
| Chroma |
本地持久化 |
百万级以下 |
单机部署、中小型知识库、入门首选 |
| Pinecone |
云端托管 |
亿级 |
生产环境、不想维护基础设施 |
| Weaviate |
自托管/云 |
亿级 |
需要混合检索(向量+关键词) |
| Milvus |
自托管 |
十亿级 |
大规模生产、国内企业常用 |
第四层:复杂 Agent 编排
去年还少有面试考 LangGraph,今年开始频繁出现,尤其稍微高级的岗位。它解决了 LangChain 普通 Agent 处理不了的问题:循环、条件分支、多步骤的复杂任务。
LangChain Agent vs LangGraph 的区别:
LangChain Agent:固定的 Thought→Action→Observation 循环,适合简单工具调用
LangGraph:自定义的状态图,可以有条件跳转、并行执行、人工审批节点,适合复杂业务流程
LangGraph:带条件路由的客服 Agent 代码示例:
from typing import TypedDict, Annotated, Literal
from langgraph.graph import StateGraph, END
from langgraph.graph.message import add_messages
from langchain_openai import ChatOpenAI
from langchain_core.messages import HumanMessage, AIMessage
# ── 1. 定义状态(贯穿整个图的共享数据)──────────────────
class CustomerServiceState(TypedDict):
messages: Annotated[list, add_messages] # 对话历史
intent: str # 用户意图:refund / complaint / inquiry
resolved: bool # 是否已解决
# ── 2. 定义节点函数 ──────────────────────────────────────
llm = ChatOpenAI(model="gpt-4o-mini")
def classify_intent(state: CustomerServiceState):
"""意图识别节点"""
last_message = state["messages"][-1].content
response = llm.invoke([
("system", "将用户问题分类为:refund/complaint/inquiry,只输出分类词"),
("user", last_message),
])
return {"intent": response.content.strip()}
def handle_refund(state: CustomerServiceState):
"""退款处理节点"""
response = llm.invoke([
("system", "你是退款专员,给出专业的退款流程指引"),
*state["messages"],
])
return {"messages": [AIMessage(content=response.content)], "resolved": True}
def handle_complaint(state: CustomerServiceState):
"""投诉处理节点"""
response = llm.invoke([
("system", "你是客服主管,先共情,再给出处理方案"),
*state["messages"],
])
return {"messages": [AIMessage(content=response.content)], "resolved": True}
def handle_inquiry(state: CustomerServiceState):
"""普通咨询节点"""
response = llm.invoke(state["messages"])
return {"messages": [AIMessage(content=response.content)], "resolved": True}
# ── 3. 路由函数(决定下一个节点)──────────────────────────
def route_by_intent(state: CustomerServiceState) -> Literal["refund", "complaint", "inquiry"]:
return state["intent"]
# ── 4. 构建图 ─────────────────────────────────────────────
graph_builder = StateGraph(CustomerServiceState)
# 添加节点
graph_builder.add_node("classify", classify_intent)
graph_builder.add_node("refund", handle_refund)
graph_builder.add_node("complaint", handle_complaint)
graph_builder.add_node("inquiry", handle_inquiry)
# 设置入口
graph_builder.set_entry_point("classify")
# 条件路由:classify 节点的输出决定走哪条边
graph_builder.add_conditional_edges(
"classify",
route_by_intent,
{"refund": "refund", "complaint": "complaint", "inquiry": "inquiry"},
)
# 所有处理节点都通向结束
graph_builder.add_edge("refund", END)
graph_builder.add_edge("complaint", END)
graph_builder.add_edge("inquiry", END)
graph = graph_builder.compile()
# ── 5. 运行 ───────────────────────────────────────────────
result = graph.invoke({
"messages": [HumanMessage(content="我买的课程不满意,想退款")],
"intent": "",
"resolved": False,
})
print(result["messages"][-1].content)
第五层:把 Agent 包成服务
企业里的 Agent 不可能在命令行跑,必须包成 HTTP 接口供前端或其他系统调用。FastAPI 是目前最主流的选择。
FastAPI 包装 Agent 的标准模式代码示例:
from fastapi import FastAPI
from fastapi.responses import StreamingResponse
from pydantic import BaseModel
from langchain_openai import ChatOpenAI
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.output_parsers import StrOutputParser
import asyncio
app = FastAPI(title="AI Agent API")
# ── 请求/响应模型 ──────────────────────────────────────
class ChatRequest(BaseModel):
message: str
session_id: str = "default"
# ── 初始化 Agent ───────────────────────────────────────
chain = (
ChatPromptTemplate.from_messages([
("system", "你是 AI 早咖啡的专业助手"),
("user", "{message}"),
])
| ChatOpenAI(model="gpt-4o-mini")
| StrOutputParser()
)
# ── 普通接口 ───────────────────────────────────────────
@app.post("/chat")
asyncdef chat(req: ChatRequest):
response = await chain.ainvoke({"message": req.message})
return {"reply": response}
# ── 流式接口(实时打字效果)────────────────────────────
@app.post("/chat/stream")
asyncdef chat_stream(req: ChatRequest):
asyncdef generate():
asyncfor chunk in chain.astream({"message": req.message}):
yieldf"data: {chunk}\n\n"# SSE 格式
yield"data: [DONE]\n\n"
return StreamingResponse(generate(), media_type="text/event-stream")
# ── 健康检查 ───────────────────────────────────────────
@app.get("/health")
asyncdef health():
return {"status": "ok"}
第六层:框架对比
面试官经常会问:"你为什么选 LangChain 而不是直接调 API?Dify 和 LangChain 有什么区别?" 能回答清楚这些,说明你真的理解了 AI 应用开发的本质。
|
维度 |
原生 API 调用 |
LangChain |
Dify / 扣子 |
AutoGen / CrewAI |
|---|---|---|---|---|
| 开发方式 |
纯代码 |
框架 + 代码 |
低代码/可视化 |
框架 + 代码 |
| 灵活性 |
⭐⭐⭐⭐⭐ 最高 |
⭐⭐⭐⭐ |
⭐⭐ |
⭐⭐⭐⭐ |
| 上手速度 |
慢(从零造轮子) |
中 |
⭐⭐⭐⭐⭐ 最快 |
中 |
| 适合场景 |
极致性能要求、特殊定制 |
大多数生产项目 |
快速验证、非技术团队 |
多 Agent 协作任务 |
| 生产可用性 |
高(但工作量大) |
高 |
中(扩展受限) |
中(稳定性一般) |
| 面试含金量 |
高 |
⭐⭐⭐⭐⭐ 最高 |
低(太简单) |
高(进阶) |
面试标准答案框架:
「原生 API 适合追求极致性能或不想引入依赖的场景,但要自己处理重试、流式、解析等所有基础设施。
LangChain 在生产项目中是最佳选择,它封装了大量最佳实践,支持 100+ 模型和数据源,LCEL 语法可读性强,生态成熟。
Dify 适合快速验证 POC 或非技术人员搭建,但深度定制时会遇到瓶颈,不适合作为生产系统核心。」
四、我的学习路线
下面这条路线是我按照最短时间拿到 offer设计的,不追求大而全,只追求面试够用 + 项目够用。
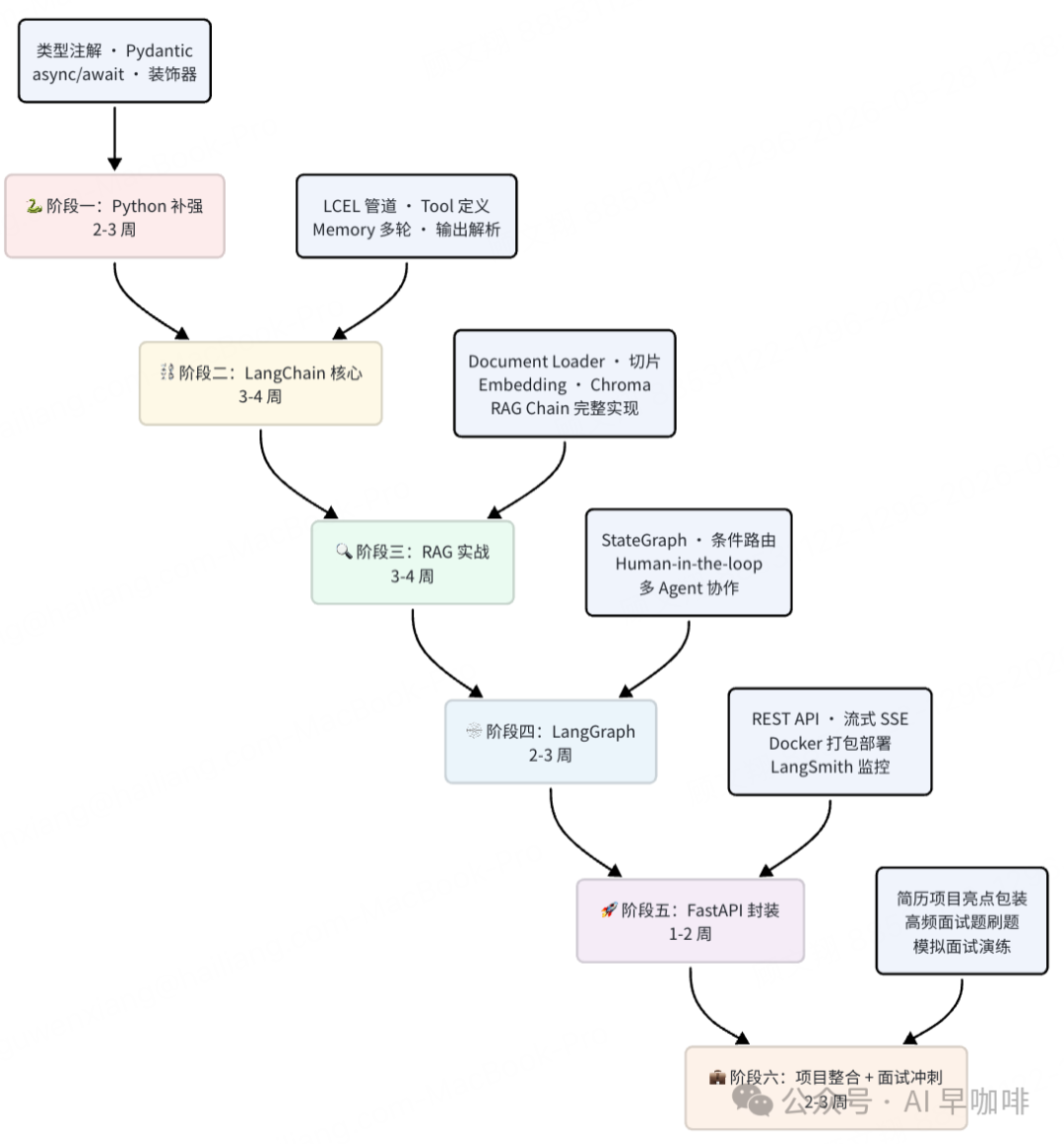
各阶段重点任务
|
阶段 |
时长 |
核心目标 |
完成标志 |
|---|---|---|---|
| Python 补强 |
2-3 周 |
打牢语言基础 |
能写 async 函数,能用 Pydantic 定义数据模型 |
| LangChain 核心 |
3-4 周 |
掌握框架范式 |
能用 LCEL 构建 Chain,能定义 Tool,能实现多轮对话 |
| RAG 实战 |
3-4 周 |
做出完整 RAG 项目 |
本地跑通 PDF 知识库问答,能解释每个环节原理 |
| LangGraph |
2-3 周 |
掌握复杂 Agent |
能画状态图,能写带条件路由的 Graph |
| FastAPI 封装 |
1-2 周 |
包成可部署服务 |
Agent 能通过 HTTP 调用,支持流式输出 |
| 项目 + 面试冲刺 |
2-3 周 |
准备好面试 |
有 1-2 个能讲清楚的项目,高频题都有答案 |

五、面试高频题库
这是我从真实面试中整理的高频题,分为三类:概念理解题、代码实现题、系统设计题。
1.概念理解题
|
面试题 |
标准答案要点 |
|---|---|
| RAG 和 Fine-tuning 有什么区别,什么时候用哪个? |
RAG:动态注入外部知识,知识可实时更新,无需训练,成本低,适合企业知识库;Fine-tuning:改变模型参数,让模型学会某种风格/领域知识,成本高,适合需要特定输出格式或行业术语的场景。两者可结合:Fine-tune 学风格,RAG 补知识。 |
| 什么是 Embedding?为什么 RAG 要用它? |
Embedding 是把文本转为高维向量(浮点数列表)的过程,语义相近的文本向量距离近。RAG 用 Embedding 的原因:用户问题和文档都转成向量后,可以用余弦相似度找到语义最相关的段落(而不是关键词匹配),实现"理解语义的搜索"。 |
| LangChain 的 LCEL 是什么?有什么优势? |
LCEL(LangChain Expression Language)是用 |
| LangGraph 和 LangChain Agent 有什么区别? |
LangChain Agent 是固定的 ReAct 循环(Thought→Action→Observation),适合简单工具调用;LangGraph 是用户自定义的状态图,支持条件分支、循环、并行、人工审批节点,适合需要复杂业务逻辑的生产 Agent。 |
| 向量数据库和关系数据库有什么区别? |
关系数据库按精确值查询(WHERE name='张三');向量数据库按相似度查询(找最接近这个向量的 Top-K 条记录)。向量数据库牺牲了精确匹配,换来了语义理解能力。两者常配合使用:向量数据库检索相关段落,关系数据库存用户信息和业务数据。 |
| RAG 效果不好怎么优化? |
①检索层:优化 chunk 大小和重叠度;加 Reranker 二次排序;混合检索(向量+关键词);②生成层:优化 Prompt 中上下文格式;加上"如果没有相关信息请如实说"的约束;③数据层:检查文档质量,清洗噪声;④评估:用 RAGAS 框架量化检索准确率和生成质量。 |
| 什么是 Tool Calling(Function Calling)? |
让 LLM 不只生成文字,还能输出"我要调用 X 工具,参数是 Y"的结构化指令,由外部系统执行后再把结果回传给 LLM。实现了 LLM 与真实世界(API、数据库、代码执行器)的交互。LangChain 的 @tool 装饰器就是对这个机制的封装。 |
2.代码实现题
面试技巧:代码题不要求从头背诵,但要能在白板/文档上写出大致框架,说清楚每行的作用。重点考察你是否真正用过,而不是只看过教程。
高频代码题 1:用 LCEL 写一个带结构化输出的 Chai
高频代码题 2:写一个带工具的 ReAct Agen
高频代码题 3:实现一个最简 RAG
from langchain_openai import ChatOpenAI
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.output_parsers import JsonOutputParser
from pydantic import BaseModel, Field
# 定义输出结构
class ProductReview(BaseModel):
sentiment: str = Field(description="情感:positive/negative/neutral")
score: int = Field(description="评分 1-5")
summary: str = Field(description="一句话总结")
# 构建链
parser = JsonOutputParser(pydantic_object=ProductReview)
chain = (
ChatPromptTemplate.from_messages([
("system", "分析以下商品评论,输出 JSON 格式。\n{format_instructions}"),
("user", "{review}"),
]).partial(format_instructions=parser.get_format_instructions())
| ChatOpenAI(model="gpt-4o-mini")
| parser
)
result = chain.invoke({"review": "东西不错,但物流太慢了,等了一周"})
# ProductReview(sentiment='negative', score=3, summary='商品质量好,但物流体验差')
from langchain_core.tools import tool
from langchain_openai import ChatOpenAI
from langgraph.prebuilt import create_react_agent
@tool
def get_weather(city: str) -> str:
"""获取指定城市的天气信息"""
# 实际接入天气 API
returnf"{city}:晴天,25°C,湿度 60%"
@tool
def calculate(expr: str) -> str:
"""计算数学表达式"""
return str(eval(expr))
# 用 LangGraph 的预置 create_react_agent 快速构建
agent = create_react_agent(
model=ChatOpenAI(model="gpt-4o-mini"),
tools=[get_weather, calculate],
)
result = agent.invoke({
"messages": [("user", "上海今天天气怎么样?如果温度超过28度,帮我算一下多少华氏度")]
})
print(result["messages"][-1].content)
from langchain_community.vectorstores import FAISS
from langchain_openai import OpenAIEmbeddings, ChatOpenAI
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.output_parsers import StrOutputParser
from langchain_core.runnables import RunnablePassthrough
# ── 构建知识库(离线)──────────────────────────
texts = [
"公司退款政策:购买7天内可无理由退款,超过7天不予退款",
"公司成立于2020年,总部位于上海",
"产品支持微信和支付宝支付",
]
vectorstore = FAISS.from_texts(texts, OpenAIEmbeddings())
retriever = vectorstore.as_retriever(search_kwargs={"k": 2})
# ── 构建 RAG Chain(在线)──────────────────────
prompt = ChatPromptTemplate.from_template("""
根据以下上下文回答问题,无相关信息就说不知道。
上下文:{context}
问题:{question}
""")
rag_chain = (
{"context": retriever | (lambda docs: "\n".join(d.page_content for d in docs)),
"question": RunnablePassthrough()}
| prompt
| ChatOpenAI(model="gpt-4o-mini")
| StrOutputParser()
)
print(rag_chain.invoke("退款需要几天内申请?"))
3.系统设计题
一般会出这类题:"如果让你设计一个企业级 AI 客服系统,你会怎么做?"

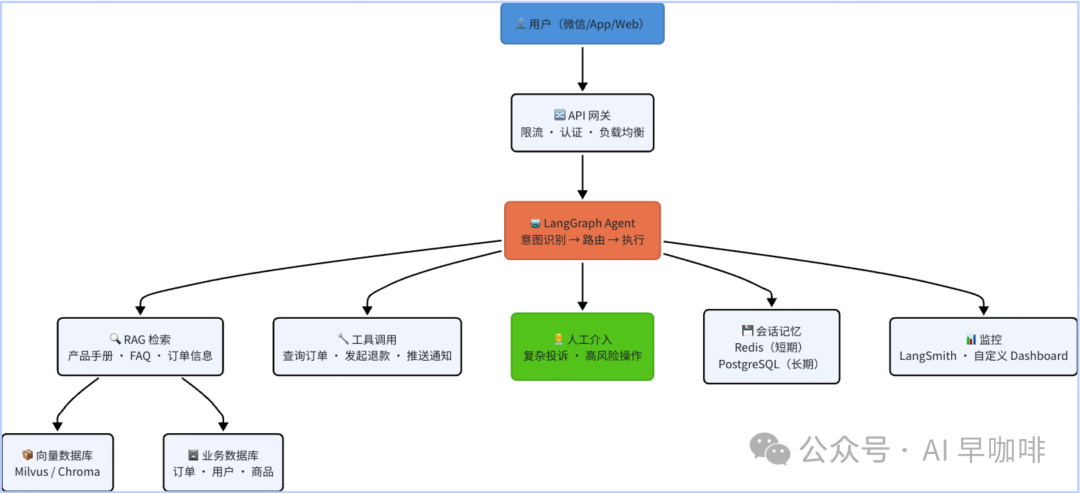
带人工介入的企业客服 Agent 代码示例:
from typing import TypedDict, Annotated, Literal
from langgraph.graph import StateGraph, END
from langgraph.graph.message import add_messages
from langgraph.checkpoint.memory import MemorySaver
class ServiceState(TypedDict):
messages: Annotated[list, add_messages]
intent: str # refund / complaint / inquiry / escalate
risk_level: str # low / medium / high
resolved: bool
def assess_risk(state: ServiceState) -> dict:
"""风险评估:高风险转人工"""
last = state["messages"][-1].content
# 简化:包含"律师""投诉""曝光"等词视为高风险
high_risk_keywords = ["律师", "投诉监管", "曝光", "起诉"]
risk = "high"if any(k in last for k in high_risk_keywords) else"low"
return {"risk_level": risk}
def route_by_risk(state: ServiceState) -> Literal["human", "ai_handle"]:
return"human"if state["risk_level"] == "high"else"ai_handle"
def human_escalation(state: ServiceState) -> dict:
"""转人工节点(实际会触发通知系统)"""
return {
"messages": [("assistant", "您的问题已转接至人工专员,预计3分钟内响应,感谢耐心等待。")],
"resolved": True,
}
# 构建带人工介入的图
builder = StateGraph(ServiceState)
builder.add_node("assess_risk", assess_risk)
builder.add_node("human_escalation", human_escalation)
# ... 其他节点省略
builder.set_entry_point("assess_risk")
builder.add_conditional_edges("assess_risk", route_by_risk, {
"human": "human_escalation",
"ai_handle": "classify_intent", # 继续 AI 处理流程
})
# 添加持久化 checkpoint(支持多轮对话恢复)
graph = builder.compile(checkpointer=MemorySaver())
六、精选学习资源
网上教程泛滥,我这里只列质量最高、最值得花时间的资源。
官方文档
|
资源 |
链接 |
重点看哪里 |
|---|---|---|
| LangChain 官方文档 |
https://python.langchain.com/docs/ |
Conceptual Guide(概念)+ How-to Guides(怎么用) |
| LangGraph 官方文档 |
https://langchain-ai.github.io/langgraph/ |
Tutorials 中的 Customer Support 完整案例 |
| LangSmith 使用指南 |
https://docs.smith.langchain.com/ |
Tracing、Evaluation 两个章节 |
| FastAPI 官方文档 |
https://fastapi.tiangolo.com/zh/ |
Tutorial(中文版),重点看 async、Pydantic、StreamingResponse |
| OpenAI Cookbook |
https://cookbook.openai.com/ |
RAG、Function Calling、Structured Output 示例 |
🎓 推荐课程和学习路径
|
资源名称 |
平台 |
推荐理由 |
|---|---|---|
| LangChain Academy |
https://academy.langchain.com/ |
LangChain 官方出品,从入门到 LangGraph 完整体系,代码可直接运行 |
| DeepLearning.AI LangChain 系列 |
https://www.deeplearning.ai/ |
吴恩达出品,与 LangChain 联合推出,覆盖 Tool、RAG、Agent,质量极高 |
| Fast.ai Practical Deep Learning |
https://course.fast.ai/ |
需要补 AI 基础原理时,比李宏毅课程更注重工程实践 |
| GitHub: langchain-ai/langchain |
GitHub |
直接读 /cookbook 和 /templates 目录,全是可运行的生产级示例 |
🛠️ 必备工具清单
开发环境
-
Python 3.11+:langchain 对低版本支持越来越弱
-
uv:比 pip 快 10-100 倍的包管理工具,现在主流选择
-
VS Code + Python 插件:或 PyCharm,任选其一
-
Jupyter Notebook:原型开发、调试 Prompt 的最佳环境
-
.env + python-dotenv:管理 API Key,永远不要 hardcode
调试 & 监控
-
LangSmith:官方调试工具,能看到每次 LLM 调用的完整 trace,免费版够用
-
Weave(W&B):开源替代,自托管友好
-
RAGAS:RAG 系统评估框架,量化检索准确率和生成质量
-
Chainlit:5 分钟搭出 ChatGPT 风格的 Agent Demo 界面,用于展示项目
🌐 值得关注的社区和信息源
| LangChain Discord |
官方社区,提问响应快,能看到最新版本的 breaking change 讨论 |
|---|---|
| r/MachineLearning |
Reddit 子版块,每周有高质量的 Paper 解读和工具推荐 |
| X(Twitter) |
关注 @hwchase17(LangChain 作者)、@AnthropicAI、@OpenAI,一手信息最快 |
七、避坑总结
坑 1:只看不练。看完三个教程觉得差不多懂了,但从没自己写过完整的 RAG Chain。面试时被追问细节就露馅了。我们可以每学完一个概念,就做一个最小可运行的 Demo。
坑 2:追新框架。AutoGen、CrewAI、MetaGPT……每周都有新框架出来,全都去学,结果哪个都没学深。应该把 LangChain + LangGraph 学精,其他框架触类旁通。
坑 3:忽视 Prompt Engineering。以为 RAG 搭好了效果自然就好,结果 Prompt 没写好,检索到了正确内容也被 LLM 答错了。Prompt 调优是系统工程,要单独投入时间。
坑 4:简历没有项目。学了三个月 LangChain,简历上只写「熟悉 LangChain」,没有项目经历。每个阶段结束时,整理一个项目放到 GitHub,哪怕是知识库问答也行。
坑 5:不会说 RAG 踩过的坑。面试必问「你在做 RAG 时遇到过什么问题」,没实际做过这道题必挂。可以在 RAG 阶段故意去测边界,比如长文档、多语言、表格内容,记录问题。
结语
AI Agent 开发不是什么神秘技能,它的核心是工程能力 + 对 LLM 特性的理解。有后端开发经验的程序员,4-5 个月内完全可以达到能独立承接项目的水平。
技术窗口期还在。现在开始学,还不晚。
如果这篇文章对你有帮助,欢迎收藏、分享给同样想转型的朋友。AI 早咖啡知识库会持续更新更多内容,一起跟上 AI 不掉队。
— AI 早咖啡出品 · 跟上 AI 不掉队 ☕ —

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 7
7 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)