约束驱动 Sign-off 方法论:从零散的约束到签核
前情提要:前面 16 篇文章覆盖了 SDC 全部命令、UPF 入门、CTS、MMMC、SPEF、库文件等。 但有一个问题一直没回答:所有的约束写完之后,怎么确认它们是对的?参数从哪来?报告怎么看? 本篇回答这三个问题。带上你的虚拟项目 digital_core 一起走一遍。
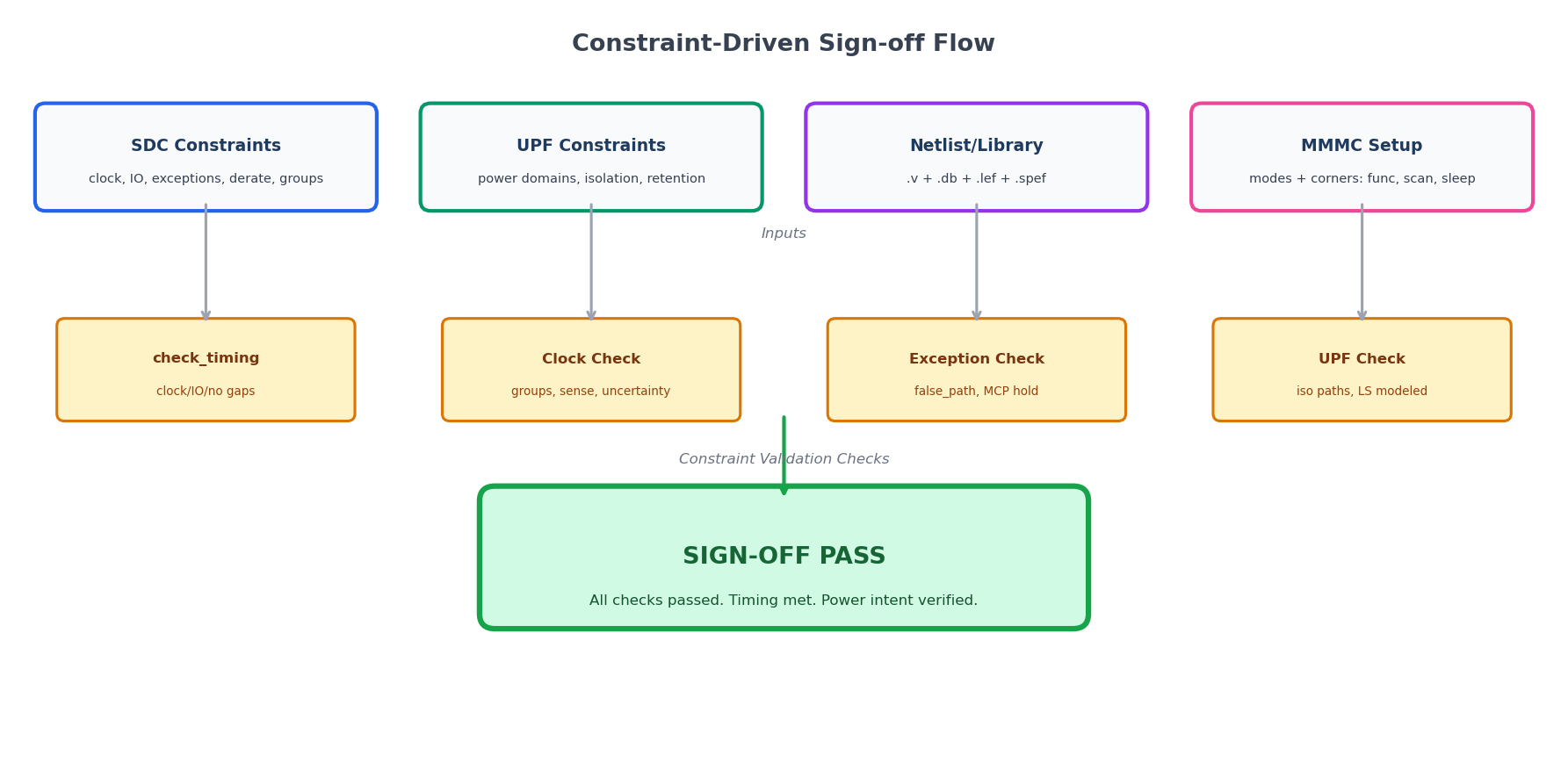
一、什么是约束驱动的 Sign-off
传统 sign-off 流程的致命问题是:约束问题留到最后才发现。你布完线跑 STA,发现 slack 差 200ps。改什么?改约束还是改 floorplan?不知道,因为你从来没验证过约束本身。
约束驱动的 Sign-off 把约束验证提前到第一步:
约束写完后 → 约束完整性检查(check_timing + 人工判读)→ 综合 → CTS → SPEF → STA → 约束回归 → sign-off
↑ 本篇重点
二、report_clock:时钟报告怎么看
2.1 正常输出长什么样
pt_shell> report_clock
Clock Period Waveform Sources
──────────────────────────────────────────────────────────
clk_2M5 400.0 {0 200} clk_in
spi_clk 1000.0 {0 500} spi_sclk
clk_1M25 800.0 {0 400} clk_divider/Q
scan_clk 100.0 {0 50} test_clk
逐行判读:
-
clk_2M5period=400ns ← 2.5MHz ✅ -
spi_clkperiod=1000ns ← 1MHz ✅ -
clk_1M25period=800ns ← 2.5MHz÷2=1.25MHz ✅ -
scan_clkperiod=100ns ← 10MHz ✅
错误信号(一眼能看出问题):
# ❌ 错误示例
Clock Period Waveform Sources
──────────────────────────────────────────────────────────
clk_2M5 400.0 {0 200} clk_in
clk_1M25 400.0 {0 200} clk_divider/Q ← period=400 和 master 一样,没分频!
clk_1M25 的 period 应该是 800(÷2),但它显示 400 和 master 一样。原因可能是 -divide_by 2 漏写了,或者 -master_clock 指向了错误的 source。
你的项目的正确值怎么来?
| 时钟 | 频率 | 来源 | 如何确定 |
|---|---|---|---|
| clk_2M5 | 2.5MHz | 外部 pin clk_in | 芯片 spec:系统时钟 2.5MHz |
| spi_clk | 1MHz | 外部 pin spi_sclk | SPI 从模式,外部 master 决定,设 1MHz 为最差情形 |
| clk_1M25 | 1.25MHz | clk_divider/Q(÷2) | 数字逻辑内部生成,从 rtl 看分频比 |
| scan_clk | 10MHz | 外部 test_clk | DFT spec:scan 频率 10MHz |
关键: 这些数字不是你拍脑袋定的。它们来自项目 spec(system clock)、接口协议(SPI 速率)、RTL 代码(分频比)、DFT plan(scan 频率)。
2.2 常见异常及根因
| report_clock 输出 | 问题 | 根因 |
|---|---|---|
| period=0 | clock 未正确传播 | -period 没写或 syntax error |
| 某时钟没出现 | clock 定义无效 | create_clock 的 port/pin 名字写错 |
| gen_clk 和 master 的 period 一样 | 分频没生效 | -divide_by 漏了或 -master_clock 指向错误 |
| 多出意料之外的 clock | clock 被意外 propagated | 没设 set_clock_sense -stop_propagation |
三、check_timing:约束完整性报告解读
3.1 正常输出
pt_shell> check_timing
Information: (PT-001) The following design/analysis information:
No constraining statements exist for the following:
(none) ← 没有未约束内容
No timing generator statements exist for the following:
(none) ← 所有 clock 都定义了
Warning: : some pins have no clock. (PT-016) ← 这个警告要仔细看
那个 PT-016 是什么?
pt_shell> report_clock -pins
Pin Clock
──────────────────────────────
clk_in clk_2M5
clk_divider/Q clk_1M25
scan_mux/Z (no clock) ← 这里有 clock 没传播到
判读: scan_mux/Z 没有 clock。在功能模式下,scan_mux/Z 应该是 clk_2M5 的一个分支。如果这里没 clock,所有经过 scan_mux 的路径都不会被分析。但你的设计中 scan_mux 在功能模式下应当传播 clk_2M5。
修复:
# 让工具知道 clock 可以通过 scan_mux
set_clock_sense -stop_propagation [get_pins scan_mux/SEL] # 只切断 SEL pin 的传播
# 这样 clock 仍然可以从 A/B 输入传送到 Z 输出
3.2 错误输出的判读
# ❌ 错误示例
No constraining statements exist for the following:
Ports: int_out ← IO 约束漏了
Pins: u_charge_ctrl/pwm_out_reg/D ← 这个 FF 没被任何 clock 覆盖
Warning: (PT-016) Some pins have no clock.
255 pins have no clock. ← 255 个 pin 没时钟,问题严重
分析:
| 报告项 | 可能原因 | 影响 | 修复 |
|---|---|---|---|
Ports: int_out |
忘写 set_output_delay |
该端口相关路径不分析 | 补上 output_delay |
Pins: u_charge_ctrl/pwm_out_reg/D |
该 FF 所在时钟域没定义时钟 | 该路径不分析 | 检查 pwm 模块的时钟定义 |
255 pins have no clock |
set_clock_sense 设错或 gen_clk 没定义 |
大量路径遗漏,sign-off 无效 | 查 report_clock -pins 找出哪些 pin 没时钟 |
3.3 coverage 报告怎么看
pt_shell> report_analysis_coverage
Type of Check Total Met Violated Untested Coverage%
──────────────────────────────────────────────────────────────
setup 3353 3353 0 0 100.0
hold 3353 3353 0 0 100.0
recovery 100 100 0 0 100.0
removal 100 100 0 0 100.0
──────────────────────────────────────────────────────────────
Overall 6906 6906 0 0 100.0
逐行判读:
-
setup 3353= 3353 条 setup path ✅ -
setup Coverage 100%= 所有寄存器都被覆盖 ✅ -
Untested 0= 没有未测试路径 ✅
❌ 错误示例:
Type of Check Total Met Violated Untested Coverage%
──────────────────────────────────────────────────────────────
setup 2900 2890 10 0 99.7
hold 2800 2800 0 553 83.5 ← 553 条 hold path 没测!
hold Untested=553 意味着: 553 条路径没有做 hold check。通常是因为 clock 关系没定义好——工具不知道这些路径的 launch 和 capture 是什么关系。
检查方法:
# 找出哪些路径是 untested
report_timing -untested -max_paths 10
# 输出示例:
Path 1: launch clock = clk_2M5, capture clock = <none>
→ 这个 FF 的 capture clock 没定义
四、report_timing:路径延迟报告深度解析
4.1 正常输出逐段判读
pt_shell> report_timing -from [get_ports spi_mosi] -to [get_pins spi_reg/D]
Startpoint: spi_mosi (input port)
Endpoint: spi_reg/D (rising edge triggered flip-flop)
Path Group: SPI_input
Path Type: max (setup)
Point Incr Path
────────────────────────────────────────────────────────────────────────────
input external delay 0.300 0.300 r
spi_mosi (in) 0.100 0.400 r
U1/BUF (BUF_X2) 0.080 0.480 r
U2/NAND (NAND_X1) 0.120 0.600 f
U3/INV (INV_X1) 0.050 0.650 r
spi_reg/D (DFF_X1) 0.000 0.650 r
────────
Library setup time -0.050
Data required time (clock edge + uncertainty) 0.800
────────────────────────────────────────────────────────────────────────────
Slack (MET) 0.150
每列含义:
-
Point— 路径经过的 cell/net + pin 名 ← 每个 cell 的延迟都列在这里 -
Incr— 本段增加的延迟 ← 找瓶颈看这里 -
Path— 累计延迟 ← 看总延迟看最后一行的 Path -
r/f— rise/fall transition
判读步骤:
① 总 path delay = 0.650ns
② data required time = 0.800ns(一个 clock period 400ns - uncertainty 0.5ns + clock path delay...
等等,400ns 是因为 `set_clock_uncertainty -setup 0.5` 把 capture edge 从 400ns 提前到了 399.5ns?
不是,这是 IO 路径,用的是 spi_clk period 1000ns)
实际上这里:
clock period = 1000ns (spi_clk)
uncertainty = 1.5ns (set_clock_uncertainty -setup 1.5 [get_clocks spi_clk])
clock path delay ≈ 0.3ns
所以 data required time ≠ 1000-1.5+0.3 ≈ 998.8...
但在 report 中 data required time = 0.800 是相对于 data arrival time 的...
实际上 report_timing 中的 Time 值是经过简化的。你需要理解原理而不是死记数字。
setup 公式(简化):
slack = T_capture + T_capture_clock_delay - T_launch - T_launch_clock_delay - T_data - T_setup - uncertainty
重点看 Incr 列:
-
如果某个 cell 的 Incr 突然变大(比如从 0.05 跳到 0.30)→ 瓶颈在这里
-
如果是 IO 路径:0.3 的 input_delay 占了路径的一半 → 可以考虑收紧 input_delay
4.2 ❌ slack 失败时的分析
Slack (VIOLATED) -0.250
分析步骤:
1. 看哪个 cell 的 Incr 最大 → 瓶颈 cell
2. 看这个 cell 的 input_slew 和 output_load 是不是合理
3. 如果 input_slew 过大 → 前面的 cell 驱动不够,换大 cell
4. 如果 output_load 过大 → 扇出太多或走线太长,插入 buffer
5. 如果 cell 本身 delay 大 → 换 LVT(但你的库没有 LVT)或优化 floorplan
4.3 parameter 从哪来
| 参数 | 来源 | 例子 |
|---|---|---|
| clock period | 项目 spec / 协议 | SPI=1MHz → period=1000ns |
| input_delay | 上游芯片 datasheet | SPI master 输出 delay max=200ns |
| output_delay | 下游芯片 datasheet | ADC 采样 setup time=300ns |
| wire_load | foundry 的 WLM 表 | smic018_wl10 |
| operating_conditions | foundry 的 .lib | wc_0_18v_125c |
实操方法:
用 SPI 接口举例:
上游芯片 datasheet 说:
t_CO_clk (clock to data out) = 150ns max
t_hold_data = 50ns
t_setup_data = 80ns
你的 input_delay = t_CO_clk = 150ns max
t_CO_clk = 50ns min
五、check_power_domain:UPF 约束报告解读
5.1 正常输出
pt_shell> check_power_domain
Information: Checked 2 power domains
PD_TOP — always-on domain. 125 cells.
PD_SW — switchable domain. 250 cells.
Information: Isolation strategy: clamp output low (ISO_CLAMP_LOW)
Information: Level shifters found: 5 (3 from PD_TOP→PD_SW, 2 from PD_SW→PD_TOP)
Information: Retention registers: 50 (in PD_SW domain)
Information: (no errors)
5.2 ❌ 错误示例
Error: PD_SW has 25 cells without retention behavior.
Warning: No isolation cell found on signal adc_data[7:0] crossing from PD_SW to PD_TOP.
Error: Level shifter required but not found on path from PD_TOP (1.8V) to PD_SW (1.8V).
判读:
-
25 cells without retention→ 这些寄存器在 PD_SW 关断时会丢数据 → 要么加 retention,要么改 UPF 定义 -
No isolation cell→ 该信号跨域时没 clamp → PD_SW 关断时 PD_TOP 会收到不定态 -
Level shifter required but same voltage→ 两侧都是 1.8V,不需要 LS。可能是 UPF 设错了 supply net
六、跨工艺节点的典型参数对比:180nm / 130nm / 12nm
同一个约束参数,在不同工艺节点下有完全不同的量级和分配逻辑。以下以你的虚拟项目为基础,给出三个节点的典型值。
6.1 工艺节点 × 频率组合
| 标准 | 中端 | 高端 | |
|---|---|---|---|
| 工艺 | Smic 180nm | Smic 130nm | 先进 12nm |
| 典型时钟 | 1MHz | 2MHz | 400MHz |
| 周期 | 1000ns | 500ns | 2.5ns |
| 应用 | PMIC、充电管理 | MCU、BLE | 应用处理器、AI |
6.2 set_clock_uncertainty 的分配对比
# ===== 180nm @ 1MHz (周期 1000ns) =====
# 0.5ns 的 uncertainty 对 1000ns 周期影响 = 0.05%
# → 几乎无影响
set_clock_uncertainty -setup 0.5 [get_clocks clk_1M]
set_clock_uncertainty -hold 0.2 [get_clocks clk_1M]
# 分配:
# Clock tree skew 0.30ns ← CTS 后 real skew ≈ 0.25~0.35ns
# PLL jitter 0.10ns ← 180nm PLL period jitter ≈ 100~200ps
# Margin 0.10ns
# ===== 130nm @ 2MHz (周期 500ns) =====
# 0.8ns 的 uncertainty 对 500ns 周期影响 = 0.16%
# → 影响仍然很小
set_clock_uncertainty -setup 0.8 [get_clocks clk_2M]
set_clock_uncertainty -hold 0.3 [get_clocks clk_2M]
# 分配:
# Clock tree skew 0.50ns ← 130nm 工艺波动更大,skew 更大
# PLL jitter 0.15ns
# Margin 0.15ns
# ===== 12nm @ 400MHz (周期 2.5ns) =====
# 0.15ns 的 uncertainty 对 2.5ns 周期影响 = 6%
# → uncertainty 占据了周期间的显著比例,必须精确控制
set_clock_uncertainty -setup 0.15 [get_clocks clk_400M]
set_clock_uncertainty -hold 0.05 [get_clocks clk_400M]
# 分配:
# Clock tree skew 0.08ns ← 先进的 CTS 算法 + H-tree,skew 控制好
# PLL jitter 0.03ns ← 先进 PLL jitter 更小
# Margin 0.04ns ← 余量很紧
#
# 注意:12nm 下 uncertainty 占总周期的 6%
# 如果设成 0.3ns(像 180nm 那种比例),你的 setup 不可能过
| 参数 | 180nm @ 1MHz | 130nm @ 2MHz | 12nm @ 400MHz |
|---|---|---|---|
| setup_uncertainty | 0.5ns | 0.8ns | 0.15ns |
| 占周期比例 | 0.05% | 0.16% | 6% |
| skew 主导因素 | 线长差异 | 线长+工艺波动 | OCV + 局部工艺波动 |
| margin 宽松度 | 余量宽裕 | 适中 | 必须精确控制 |
6.3 IO delay 的对比
# ===== 180nm @ 1MHz SPI =====
# 上游 SPI master datasheet: t_co = 5~200ns
# 200ns 对 1000ns 周期 = 20%
set_input_delay -clock spi_clk -max 200 [get_ports {spi_mosi}]
set_input_delay -clock spi_clk -min 5 [get_ports {spi_mosi}]
# ===== 130nm @ 2MHz SPI =====
# 上游 SPI master: t_co = 3~100ns
# 100ns 对 500ns 周期 = 20%
set_input_delay -clock spi_clk -max 100 [get_ports {spi_mosi}]
set_input_delay -clock spi_clk -min 3 [get_ports {spi_mosi}]
# ===== 12nm @ 400MHz DDR =====
# DDR PHY: t_co = 0.1~0.5ns
# 0.5ns 对 2.5ns 周期 = 20%
# 比例和 180nm 一样——IO delay 通常占周期的 15~25%
set_input_delay -clock ddr_clk -max 0.5 [get_ports {dq[*]}]
set_input_delay -clock ddr_clk -min 0.1 [get_ports {dq[*]}]
| 参数 | 180nm SPI | 130nm SPI | 12nm DDR |
|---|---|---|---|
| input_delay max | 200ns | 100ns | 0.5ns |
| 占周期比例 | 20% | 20% | 20% |
| 上游器件 | 通用 SPI master | 通用 SPI master | DDR PHY |
| 是否瓶颈 | ❌ 不是(周期大) | ❌ 不是 | ⚠️ 可能是 |
6.4 set_load 的对比
# 180nm: PCB 走线 + 下游芯片输入 = 3pF + 2pF = 5pF
set_load 5.0 [get_ports spi_miso]
# 130nm: PCB 走线 + 下游芯片输入 = 2pF + 1.5pF = 3.5pF
set_load 3.5 [get_ports spi_miso]
# 12nm: 片上负载为主,片外走线极短 = 0.1pF + 0.05pF = 0.15pF
set_load 0.15 [get_ports dq_io]
6.5 timing derate 的对比
# ===== 180nm @ 1MHz =====
# OCV 影响小,全局 derate 足够
set_timing_derate -early 0.95
set_timing_derate -late 1.10
# ===== 130nm @ 2MHz =====
# 工艺波动更大,derate 范围略宽
set_timing_derate -early 0.93
set_timing_derate -late 1.12
# ===== 12nm @ 400MHz =====
# OCV 严重,必须用 AOCV table 而非全局 derate
# 假设 AOCV table 中 5 级 cell: early=0.90, late=1.15
# 假设 AOCV table 中 20 级 cell: early=0.95, late=1.08
# → 直接用 report_timing_derate 验证当前路径的 derate 值
6.6 WLPM 精度的对比
| 工艺 | pre→post slack 差异 | 原因 |
|---|---|---|
| 180nm | 10~20% | 线延迟占比较小,WLPM 误差影响不大 |
| 130nm | 20~30% | 线延迟占比增大,WLPM 误差放大 |
| 12nm | 30~60% | 线延迟占 path delay 的 50%+,耦合效应显著 |
12nm 为什么差异大:
180nm: cell_delay : wire_delay ≈ 80% : 20%
WLPM 误差 40% → 整体误差 = 20% × 40% = 8%
12nm: cell_delay : wire_delay ≈ 40% : 60%
WLPM 误差 40% → 整体误差 = 60% × 40% = 24%
再加上耦合电容占 wire_cap 的 50%+
综合时不知道耦合 → wire_delay 低估更多
6.7 一句话总结
| 工艺 | 约束设计的核心理念 |
|---|---|
| 180nm @ MHz | 周期大,约束宽松——uncertainty 0.5ns 不影响 setup。重点在 IO 时序和 reset |
| 130nm @ MHz | 周期适中,约束要开始关注——skew 和 derate 开始占周期比例 |
| 12nm @ GHz | 周期极小,每个 ps 都要精打细算——必须用 AOCV,必须用 CCS,必须精确提取 |
七、参数值从哪来:完整溯源(工艺无关部分)
7.1 uncertainty 的分配公式
# 你一直写的:
set_clock_uncertainty -setup 0.5 [get_clocks clk_2M5]
# 但 0.5 怎么来的?
# uncertainty = clock_skew + PLL_jitter + margin
# clock_skew: post-CTS report 显示 max skew = 0.28ns
# PLL_jitter: datasheet 说 period jitter = 150ps pk-pk
# margin: 安全余量 = 0.07ns
# 所以:0.28 + 0.15 + 0.07 = 0.50ns
7.2 input_delay 的来源(以 SPI 为例)
上游芯片(SPI master)datasheet:
CPOL=0, CPHA=0 模式
t_clk = 1000ns (1MHz)
t_co (clock to data out) = 5ns ~ 200ns
t_hold (data hold after clock) = 10ns
所以你的 input_delay:
max = t_co_max = 200ns ← 数据在 clock edge 后最晚 200ns 到达
min = t_co_min = 5ns ← 数据最早在 clock edge 后 5ns 到达
= set_input_delay -clock spi_clk -max 200 [get_ports {spi_mosi spi_csn}]
set_input_delay -clock spi_clk -min 5 [get_ports {spi_mosi spi_csn}]
7.3 set_load 的来源
SPI 输出 pin 接到 PCB 走线 + 下游芯片输入 pin
负载 = PCB 走线电容 + 下游芯片输入电容
≈ 3pF + 2pF = 5pF
= set_load 5.0 [get_ports spi_miso]
7.4 derating 的来源
foundry 的 AOCV table 文件示例(smic018_aocv.tbl):
Depth Early Late
1 0.85 1.20
2 0.88 1.17
5 0.92 1.12
10 0.94 1.08
20 0.96 1.05
你设的:
set_timing_derate -early 0.95
set_timing_derate -late 1.10
这是"全局 derating",对所有路径统一应用。
AOCV table 是根据路径深度查表,更精确。
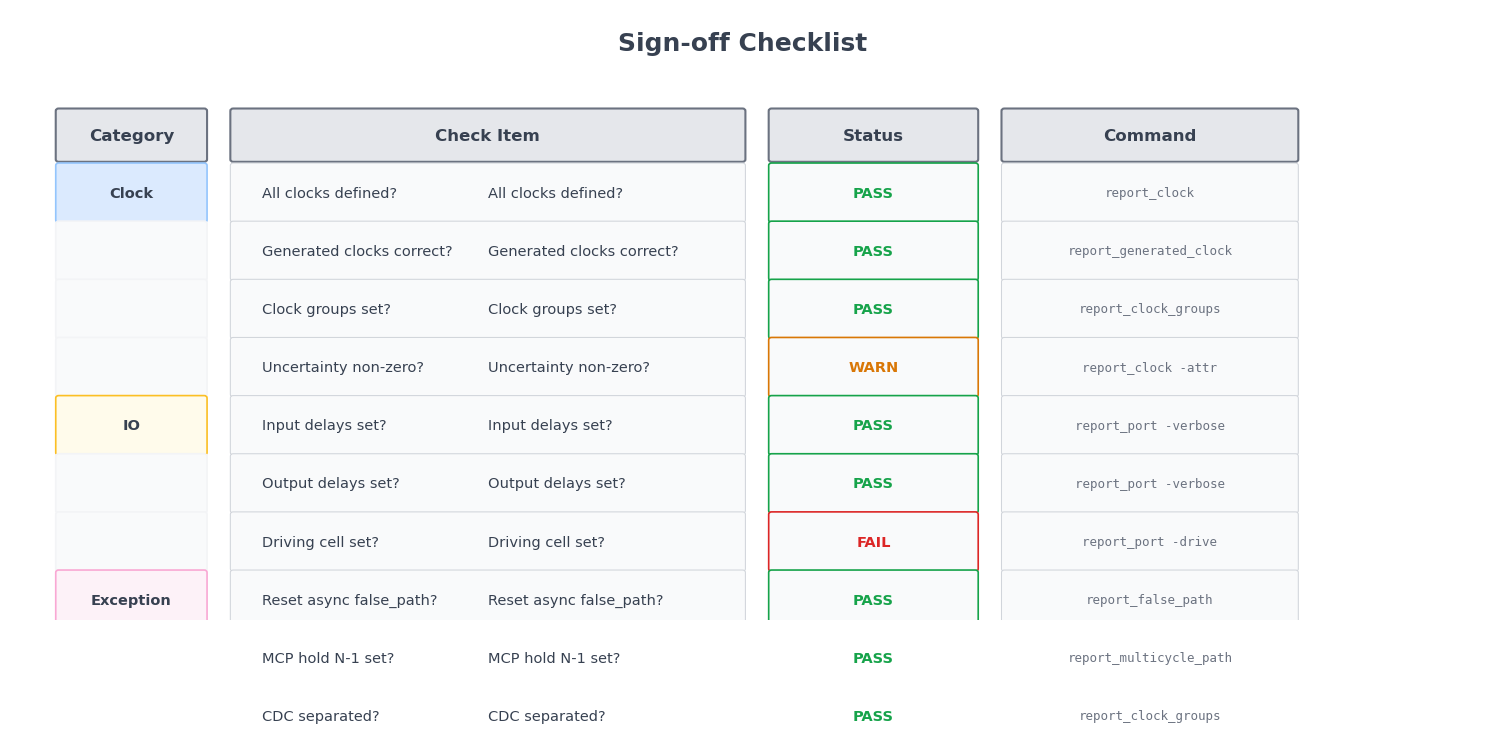
八、完整的 Sign-off 检查清单
九、总结
三个核心原则:
-
不要只看命令有没有跑过,要看输出——
report_clock的 period 对不对、check_timing有没有列 port、coverage是不是 100% -
参数值不是拍脑袋的——uncertainty 来自 CTS skew + PLL jitter,IO delay 来自上下游 datasheet,derating 来自 foundry 的 AOCV table
-
错误输出一眼能看出来——period=0、coverage<95%、untested>0、slack VIOLATED

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 9
9 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)