面向驾驭工程的 MCP-Agent 研发运维闭环自动化模型研究
摘要
随着大模型与智能体技术进入软件工程场景,传统 DevOps 流程中工具割裂、人工操作冗余、故障响应滞后、自动化过程不可审计等问题进一步凸显。驾驭工程(Harness Engineering)强调通过工程化约束、工具封装、流程调度与反馈回路,使智能体在可控边界内执行复杂任务。基于这一思想,本文提出一种面向研发运维一体化场景的 MCP-Agent 闭环自动化模型。
该模型以 Model Context Protocol(MCP)为异构工具和平台的能力接入协议,以智能 Agent 为调度与决策中枢,以 Skill 工作流为任务编排载体,打通需求接入、代码提交、工程构建、配置变更、生产发布、日志感知、异常研判、修复迭代与复盘归档等环节。模型进一步引入可观测记录层,通过 Markdown 人工复盘文档与 JSON 结构化数据双轨存储,实现智能体操作过程的可追溯、可审计与可数据化复用。
研究表明,该模型能够为 AI 原生 DevOps 提供一种可组合、可扩展、可治理的工程化实现路径,有助于降低重复性人工操作、提升故障响应效率,并为智能体在研发运维场景中的安全落地提供参考。
关键词
驾驭工程;MCP;智能 Agent;DevOps;AIOps;闭环自动化;可观测性
一、引言
软件系统的业务复杂度、架构复杂度与交付频率持续提升,研发团队不仅需要完成代码开发,还需要参与构建、部署、配置管理、运行监控、故障定位和版本修复等全生命周期工作。传统研发运维体系中,GitLab/GitHub、Jenkins、Nacos、Kubernetes、日志监控平台、发布平台、需求管理系统等工具通常以相对独立的方式存在,数据与操作链路难以自然贯通。
在人工主导的流程下,研发和运维人员需要在多个系统之间反复切换,完成提交、构建、配置、发布、回滚、排障等操作。这类操作重复性强、上下文分散、错误成本高。一旦线上服务发生异常,团队往往需要人工收集日志、判断影响范围、定位根因、修复代码并重新发布,导致故障恢复时间和迭代反馈周期难以进一步压缩。
与此同时,智能 Agent 具备任务拆解、工具调用、上下文理解和多步骤执行能力,为软件工程自动化带来了新的可能。但如果缺乏明确的工具边界、权限约束、过程记录和人工治理机制,Agent 的自动化能力也可能放大误操作、误发布和不可追溯风险。因此,智能体并不能简单替代传统 DevOps 流程,而需要被置于一套可控、可观测、可审计的工程化体系之中。
驾驭工程的核心思想正是“人类掌舵,智能体执行”:人类定义目标、规则、权限与验收标准,智能体在工程化边界内完成任务执行、状态反馈与持续优化。本文围绕这一思想,研究 MCP 与智能 Agent 协同的研发运维闭环自动化模型,回答以下三个问题:
- 如何将异构研发运维工具封装为可被 Agent 标准调用的能力集合?
- 如何让 Agent 按照可治理的流程完成研发、发布、运维与修复任务?
- 如何记录、审计和复用 Agent 的自动化操作过程,降低黑盒执行风险?
本文主要贡献如下:
- 提出 MCP-Agent 四层闭环架构,将能力封装、智能调度、可观测记录和业务执行纳入统一模型。
- 设计覆盖需求迭代与故障修复两类场景的自动化运行机制,形成“输入-执行-反馈-修复-复盘”的闭环。
- 引入 Markdown 与 JSON 双轨归档机制,为智能体操作审计、复盘分析和流程优化提供数据基础。
二、相关技术与研究基础
2.1 驾驭工程
驾驭工程不是单纯提升大模型能力,而是通过外部工程体系约束智能体行为。其重点包括目标拆解、工具接入、流程编排、权限控制、结果验证、异常回退和持续反馈。与传统提示工程相比,驾驭工程更关注智能体运行环境的可靠性;与普通自动化脚本相比,它更强调智能分析、动态决策和跨系统协同。
在研发运维场景中,驾驭工程可以被理解为一种面向 AI Agent 的 DevOps 治理框架。人类负责制定规则、审批关键操作和评估结果,Agent 负责调用工具、执行流程和生成复盘数据。二者的关系不是替代关系,而是“控制权在人,执行权受限委托给智能体”的协作关系。
2.2 MCP 协议
MCP(Model Context Protocol)是一种面向 AI 应用与外部系统交互的开放协议。官方架构中,MCP 采用 Host、Client、Server 的分层模式:Host 是承载 AI 能力的应用,Client 负责与特定 Server 建立会话,Server 则向 Client 暴露工具、资源、提示等能力。MCP 底层消息遵循 JSON-RPC 2.0,并通过生命周期管理、能力协商、通知机制和传输层机制支持多种交互场景。
对于研发运维系统而言,MCP 的价值不在于替代 Jenkins、Kubernetes 或日志平台,而在于为这些系统提供统一的能力描述和调用边界。例如,代码仓库可以暴露分支查询、提交记录、合并请求等工具;构建平台可以暴露构建触发、构建状态查询和产物获取能力;日志系统可以暴露异常检索、日志聚合和告警订阅能力。Agent 通过统一协议发现和调用这些能力,从而减少异构系统接入成本。
2.3 智能 Agent 与 Skill 编排
智能 Agent 是闭环模型的调度与决策主体,负责理解任务目标、选择工具、组织执行步骤、处理异常并输出结果。单个 MCP 工具通常只解决局部问题,无法自然形成完整业务流程,因此需要通过 Skill 对多个工具调用进行组合。Skill 可以被视为可复用的任务模板,描述某类业务目标下的触发条件、执行步骤、输入输出、失败处理和人工审批点。
在本文模型中,Agent 不直接“自由操作”所有系统,而是在能力清单、权限策略和流程模板共同约束下执行任务。这种方式既保留了 Agent 的智能调度能力,也避免了无边界自动化带来的风险。
2.4 DevOps 与 AIOps 指标
DevOps 强调持续集成、持续交付、快速反馈与稳定运行。DORA 研究长期使用部署频率、变更前置时间、失败部署恢复时间、变更失败率等指标评价软件交付能力,并在 2024 年后进一步引入部署返工率,以刻画发布后非计划修复带来的额外成本。AIOps 则进一步利用智能分析方法处理日志、指标、事件和告警数据,辅助异常检测、根因分析和自动修复。
本文提出的 MCP-Agent 模型可以被看作 AI 原生 DevOps 的一种实现方式:通过 MCP 接入工具,通过 Agent 编排流程,通过可观测记录沉淀数据,通过反馈机制驱动持续优化。
三、MCP-Agent 闭环自动化模型
3.1 总体架构
模型由能力封装层、智能调度层、可观测记录层和业务执行层组成,如图 1 所示。
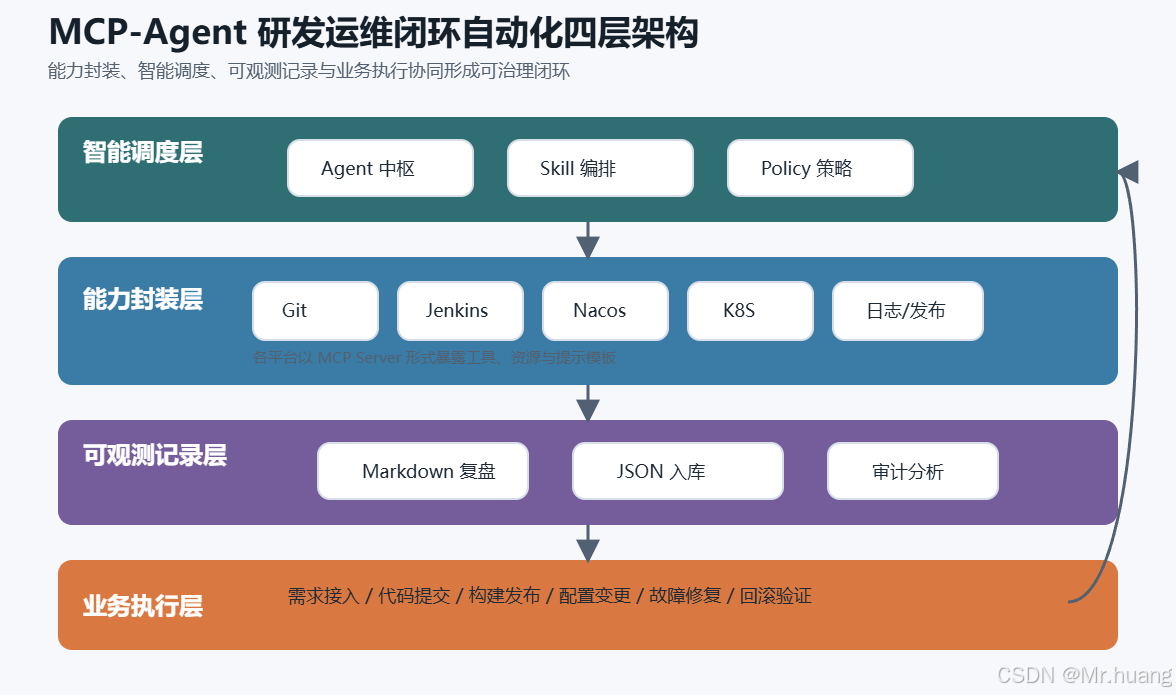
能力封装层面向各类研发运维基础设施,负责将代码仓库、构建平台、配置中心、容器集群、中间件、日志系统、发布平台、需求管理系统和远程服务器等能力封装为 MCP Server。每个 Server 聚焦明确职责,并通过工具、资源或提示模板向上层暴露能力。
智能调度层以 Agent 为核心,负责能力发现、任务拆解、流程编排、工具调用、状态判断和异常处理。该层不直接绕过流程访问生产系统,而是根据 Skill 模板、权限策略和人工审批规则组织自动化任务。
可观测记录层负责记录 Agent 的执行上下文,包括任务目标、触发来源、调用工具、输入参数、执行结果、异常信息、审批记录、回滚操作和最终产物。该层既生成便于人工阅读的 Markdown 复盘文档,也生成便于系统分析的 JSON 结构化数据。
业务执行层是模型落地的操作对象,包含代码提交、工程构建、配置更新、容器运维、灰度发布、健康检查、日志分析、故障修复和需求迭代等实际业务动作。
3.2 核心组件职责
| 组件 | 核心职责 | 输入 | 输出 |
|---|---|---|---|
| MCP Server | 封装工具和平台能力 | 平台 API、脚本、资源数据 | 工具、资源、提示模板 |
| Agent | 任务理解、流程调度、异常判断 | 用户目标、告警事件、需求单 | 调用计划、执行结果、修复建议 |
| Skill | 固化可复用工作流 | 触发条件、参数、策略 | 标准化执行链路 |
| Policy | 权限、审批和安全约束 | 用户角色、环境级别、风险等级 | 允许、拒绝、需审批 |
| Recorder | 操作记录与复盘归档 | 执行上下文、调用结果 | Markdown 报告、JSON 数据 |
3.3 运行流程
模型运行流程如图 2 所示。流程从需求输入、代码变更或线上异常开始,由 Agent 判断任务类型并选择对应 Skill。随后,Agent 按照流程模板调用 MCP 能力完成开发、构建、配置、发布和验证操作。若执行失败,系统进入异常处理分支;若执行成功,则进入复盘归档和指标更新环节。
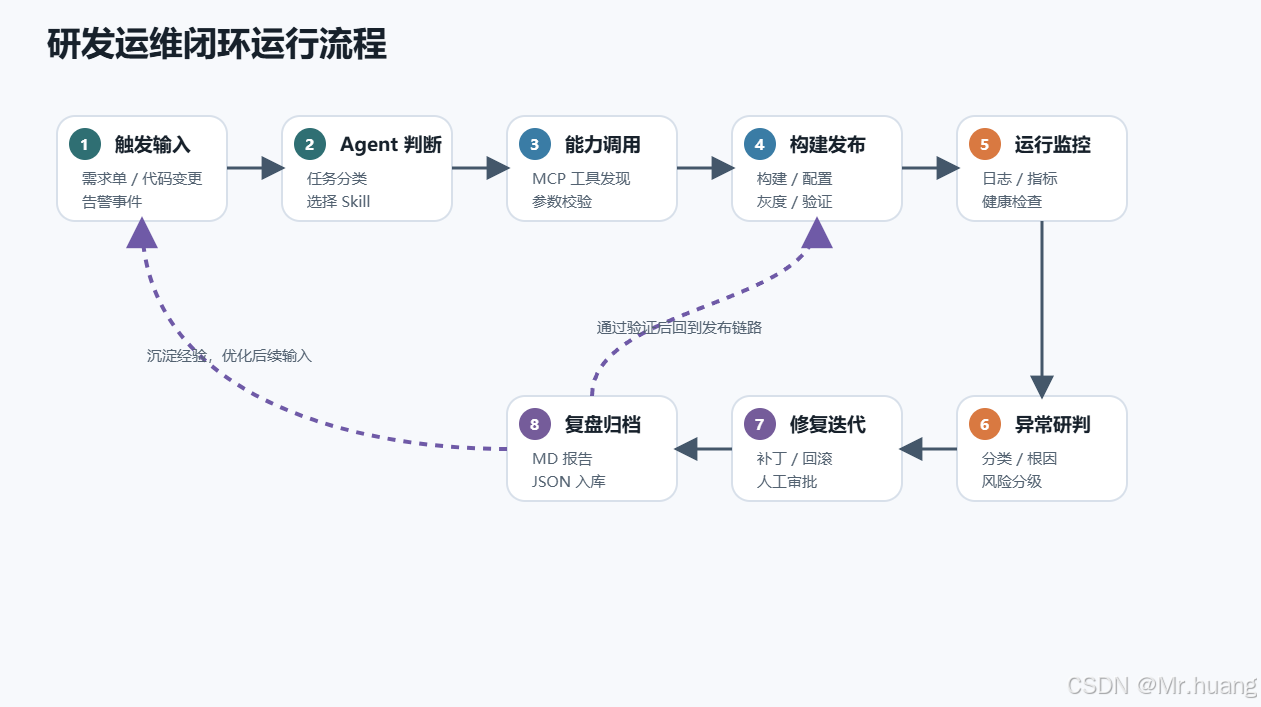
该流程具有两个闭环:
- 需求闭环:需求进入系统后,Agent 辅助拆解任务、生成开发计划、触发构建发布,并在上线后记录交付结果。
- 故障闭环:线上异常触发后,Agent 聚合日志和指标,判断异常类型,辅助定位根因,并驱动修复、验证和复盘。
四、关键机制设计
4.1 MCP 能力注册与发现机制
每个 MCP Server 应提供明确的能力元数据,包括工具名称、工具描述、输入 Schema、输出格式、权限等级、环境范围和副作用说明。Agent 在执行任务前先完成能力发现与能力匹配,避免直接依赖硬编码脚本。
以构建平台为例,可暴露如下能力:
| 能力名称 | 功能说明 | 风险等级 |
|---|---|---|
list_pipelines |
查询项目流水线 | 低 |
trigger_build |
触发指定分支构建 | 中 |
get_build_status |
查询构建状态 | 低 |
download_artifact |
获取构建产物 | 中 |
rollback_release |
回滚指定版本 | 高 |
这种能力分级有助于 Agent 在执行时自动识别风险,并触发相应的审批、限流或二次确认。
4.2 Skill 工作流编排机制
Skill 用于将多个 MCP 能力组织为稳定流程。一个“生产发布 Skill”可以包含代码状态检查、构建触发、单元测试、镜像打包、配置同步、灰度发布、健康检查和复盘归档等步骤。每个步骤都应声明前置条件、成功标准、失败处理和回滚策略。
与传统脚本相比,Skill 的优势在于可以被 Agent 动态调用和组合。例如,当需求变更涉及配置项时,Agent 可在标准发布流程中插入配置校验步骤;当健康检查失败时,Agent 可暂停后续发布并触发回滚 Skill。
4.3 异常分类与修复机制
线上异常可初步划分为三类:
- 临时性异常:如瞬时网络抖动、短暂连接超时,可记录并观察。
- 业务状态异常:如订单状态不一致、消息堆积、定时任务失败,需要调用业务恢复能力。
- 代码逻辑缺陷:如空指针、边界条件错误、兼容性问题,需要进入修复迭代流程。
Agent 的判断不应只依赖单条日志,而应综合日志、指标、链路追踪、近期发布记录、配置变更和历史故障库。对于高风险修复,Agent 只生成定位建议、补丁草案或回滚方案,由人工审批后再执行。
4.4 可观测记录与复盘机制
可观测记录层采用“Markdown + JSON”双轨输出,如图 3 所示。
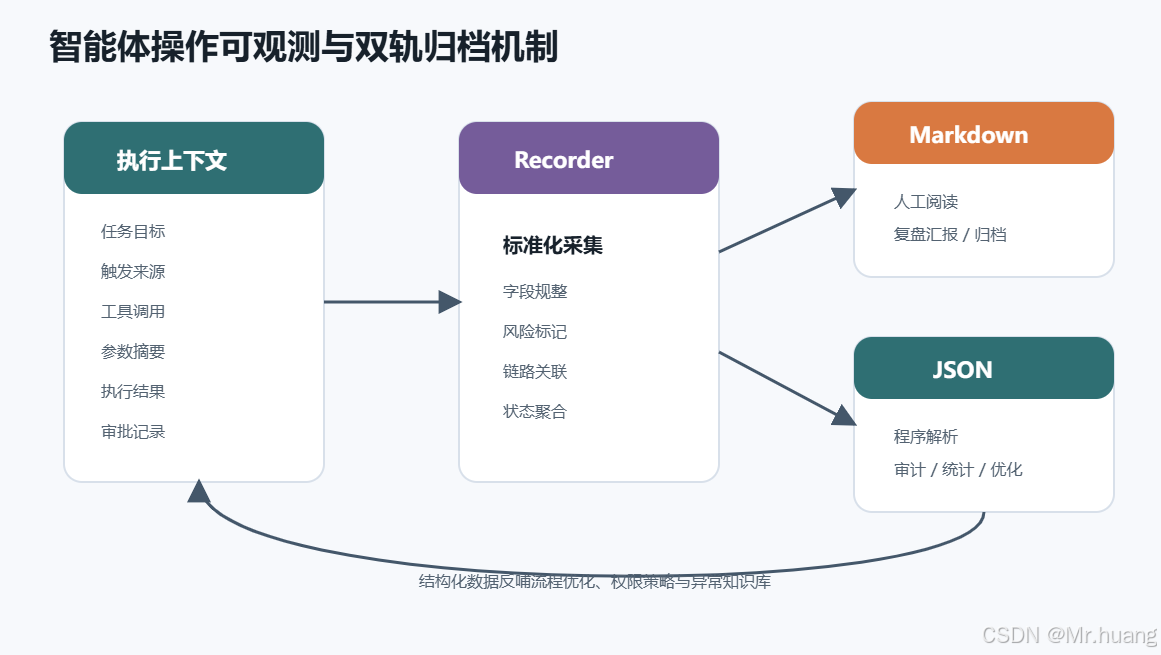
Markdown 报告服务于人工复盘,建议包含任务背景、执行链路、关键决策、异常处理、最终结果、遗留问题和改进建议。JSON 数据服务于系统分析,建议包含任务 ID、触发来源、调用工具、输入参数摘要、执行耗时、状态码、审批节点、风险等级和产物链接等字段。
示例结构如下:
{
"task_id": "deploy-20260601-001",
"trigger": "zentao_requirement",
"risk_level": "medium",
"workflow": "release_skill",
"steps": [
{
"name": "trigger_build",
"tool": "jenkins.trigger_build",
"status": "success",
"duration_ms": 183000
}
],
"approval": {
"required": true,
"approver": "release_manager",
"result": "approved"
},
"final_status": "success"
}
4.5 权限控制与安全边界
为了避免 Agent 自动化能力失控,模型应设置以下边界:
- 生产环境高风险操作必须经过人工审批,如生产发布、数据修复、回滚、扩缩容和权限变更。
- MCP Server 只暴露完成任务所需的最小能力,避免授予全量系统权限。
- Agent 只能访问当前任务必要上下文,不能默认读取所有历史会话、代码仓库或敏感配置。
- 所有副作用操作必须记录输入、输出、执行人、审批人和回滚路径。
- 对连续失败、异常高频调用和越权尝试设置熔断机制。
五、案例验证设计
为验证模型可行性,可选取一个典型后台服务作为试点对象,设置传统 DevOps 流程与 MCP-Agent 流程两组对照。
5.1 试点场景
试点系统包含代码仓库、Jenkins 流水线、Nacos 配置中心、Kubernetes 集群、日志平台和禅道需求管理系统。系统选择两个场景进行验证:
- 需求迭代场景:从禅道需求单进入,到代码修改、构建、配置、灰度发布和复盘归档。
- 故障修复场景:从线上 Error 日志触发,到异常分类、根因定位、修复建议、重新发布和结果验证。
5.2 评价指标
| 指标 | 含义 | 评价目标 |
|---|---|---|
| 人工操作次数 | 完成一次迭代所需人工切换和命令次数 | 越少越好 |
| 变更前置时间 | 从需求确认到可发布产物形成的时间 | 越短越好 |
| 构建发布耗时 | 从提交到上线完成的时间 | 越短越好 |
| 故障发现时间 | 异常发生到被系统识别的时间 | 越短越好 |
| 故障恢复时间 | 异常确认到服务恢复的时间 | 越短越好 |
| 变更失败率 | 发布后引发回滚或故障的比例 | 越低越好 |
| 部署返工率 | 发布后因缺陷产生非计划修复的比例 | 越低越好 |
| 复盘完整度 | 是否记录关键步骤、参数、结果和审批信息 | 越完整越好 |
5.3 预期效果
在不牺牲审批和安全边界的前提下,MCP-Agent 流程预期能够减少重复性人工操作,提升构建、发布、日志检索和复盘归档的自动化程度。对于高风险动作,模型并不追求完全无人化,而是通过人机协同降低操作负担,并保留关键控制权。
六、模型优势与适用边界
6.1 模型优势
第一,模型通过 MCP 将异构系统能力统一暴露,降低工具接入和流程编排成本。第二,Agent 与 Skill 的结合使复杂研发运维任务具备可组合性和可复用性。第三,可观测记录层为智能体操作提供审计证据,缓解自动化过程不可见的问题。第四,模型同时覆盖需求迭代和故障修复,能够支撑从业务输入到生产反馈的持续闭环。
6.2 适用边界
该模型适用于工具链相对完整、流程标准化程度较高、具备基础自动化能力的研发团队。对于流程高度依赖人工经验、系统接口缺失、权限体系混乱或生产环境缺乏回滚机制的团队,应先完成基础治理,再逐步引入 Agent 自动化。
6.3 风险与治理
模型落地过程中需要关注以下风险:
- 误判风险:Agent 对异常类型或根因的判断可能不准确,需要引入人工审批和多源证据校验。
- 权限风险:MCP Server 暴露能力过宽可能造成越权操作,需要按最小权限原则设计。
- 发布风险:自动发布可能放大错误变更影响,需要灰度、回滚和熔断机制。
- 数据风险:日志、配置和代码中可能包含敏感信息,需要脱敏、审计和访问控制。
- 依赖风险:当 MCP Server、网络或外部平台不可用时,系统应具备降级与人工接管方案。
七、结论与展望
本文面向 AI 原生研发运维场景,提出一种基于 MCP 与智能 Agent 的闭环自动化模型。该模型以 MCP 解决异构工具能力接入问题,以 Agent 解决跨系统任务调度问题,以 Skill 解决流程复用问题,以可观测记录层解决智能体操作的透明化和审计问题。整体上,该模型为驾驭工程在 DevOps 场景中的落地提供了一种可实施的架构参考。
未来研究可从三个方向继续深化:一是完善 Agent 的异常诊断与根因分析能力,引入更多日志、指标、链路追踪和发布变更数据;二是扩展 MCP 能力库,覆盖代码评审、性能测试、安全扫描、容量预测和容灾演练等场景;三是建立更细粒度的智能体治理体系,包括风险分级、审批策略、行为审计、红线检测和持续评估机制。
参考资料
[1] Model Context Protocol. Architecture overview. https://modelcontextprotocol.io/docs/learn/architecture
[2] Model Context Protocol Specification. Architecture, Version 2025-06-18. https://modelcontextprotocol.io/specification/2025-06-18/architecture
[3] Model Context Protocol Specification. Base Protocol Overview, Version 2025-11-25. https://modelcontextprotocol.io/specification/2025-11-25/basic
[4] DORA. A history of DORA’s software delivery metrics. https://dora.dev/insights/dora-metrics-history/
[5] NIST. Artificial Intelligence Risk Management Framework (AI RMF 1.0). https://www.nist.gov/publications/artificial-intelligence-risk-management-framework-ai-rmf-10
注:本文为研究性技术方案,案例验证部分可根据真实项目数据进一步补充实验结果。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 2
2 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)