【Embodiment Gap in Robot Learning: A Comprehensive Survey】
Embodiment Gap in Robot Learning: A Comprehensive Survey
摘要 (Abstract)
随着大语言模型(LLMs)与多模态视觉-语言模型(VLMs)在数字世界的认知能力趋于成熟,人工智能的触角正不可阻挡地向物理世界延伸。近年来,具身智能基础模型(Embodied Foundation Models)在复杂语义理解、常识推理与通用任务规划方面取得了突破性进展。然而,当试图将基于单一或局部本体数据训练的控制策略,零样本(Zero-shot)或少样本(Few-shot)迁移到具备不同硬件拓扑结构的全新机器人系统时,模型往往遭遇严重的性能衰退甚至执行失效。这种因跨硬件形态(Cross-embodiment)的物理特性与拓扑结构差异导致的动作技能迁移壁垒,被称为具身鸿沟(Embodiment Gap)。
这一鸿沟不仅极大限制了具身模型的形态泛化能力,更在各类异构硬件本体之间形成了难以互通的“数据孤岛)”,导致具身领域无法像纯粹的自然语言处理(NLP)领域那样享受数据规模倍增的缩放红利(Scaling Laws)。具身鸿沟的本质是异构硬件在物理拓扑、输入感知与底层控制信号上的严重差异。为了系统性地应对这一挑战,本文首次提出了跨本体泛化的演进层级,将具身鸿沟的跨越由浅入深划分为 L0 至 L5 六个递进层次。
在此理论框架下,本文全面梳理了当前主流的跨越鸿沟技术范式:包括统一表征学习、动作-观测空间对齐、本体外观视觉解耦、多本体架构设计、以及“感知-控制”解耦的中间态视觉感知引导。针对最极端的形态迁移,本文深入探讨了从人类第一视角视频到机器人的极致重定向技术。最后,本文从梯度冲突的数学视角剖析了在打破数据孤岛进行数据混合(Data Mixing)时爆发的负迁移(Negative Transfer)现象,并对未来构建真正硬件无关(Hardware-Agnostic)的通用具身基座模型指明了研究方向。
1. 引言 (Introduction)
1.1 具身智能与莫拉维克悖论的演进
在人工智能的发展历程中,“莫拉维克悖论(Moravec’s paradox,“在人工智能领域,困难的问题极其简单,而简单的问题却极其困难。”)”始终是一个挥之不去的幽灵。过去的十年被自然语言处理和计算机视觉领域的纯数字模型所主导,但真正的通用人工智能(AGI)必须具备与开放、非结构化物理世界闭环交互的能力。近年来,随着 RT-X, Octo, OpenVLA, PI等具身大模型的提出,具身智能(Embodied AI)正经历着从“特定任务小模型”向“通用具身基础模型”的范式转变。然而,认知能力的飞跃并未完全转化为物理执行能力的同等提升。
1.2 数据孤岛与通用机器人的瓶颈
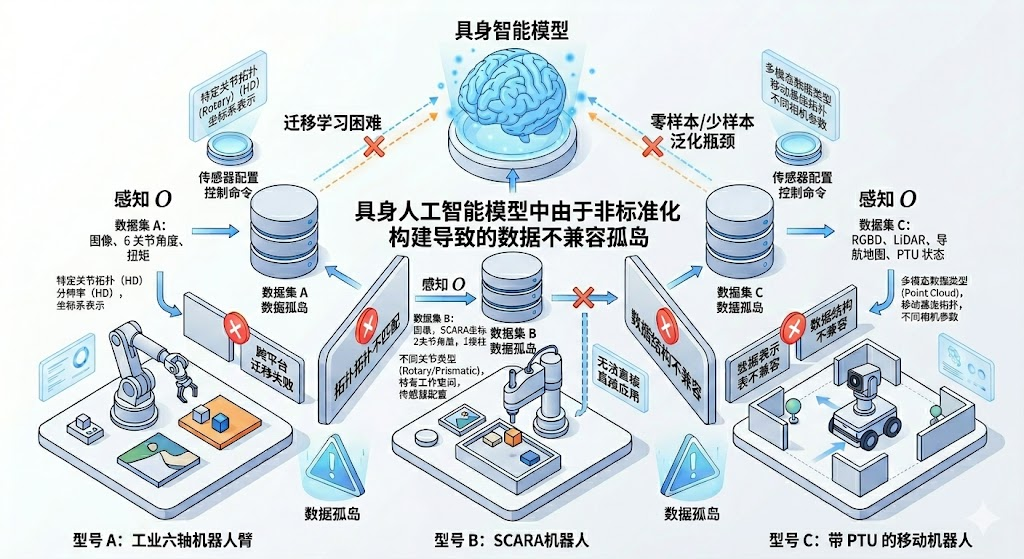
因机器人硬件本体的差异造成了数据孤岛
学术界与工业界正共同描绘构建通用机器人(Generalist Robots)的宏伟愿景。然而,由于底层控制指令(如电机力矩、关节角度)、传感器等与特定的机器人形态强绑定,某一型号机器人(如 Franka Panda)收集的海量优质数据,完全无法被另一型号(如 UR5)直接复用。这导致具身智能领域充斥着高度碎片化、互不相通的“数据孤岛”,迟滞了通用具身智能的发展。
1.3 具身鸿沟的数学本质
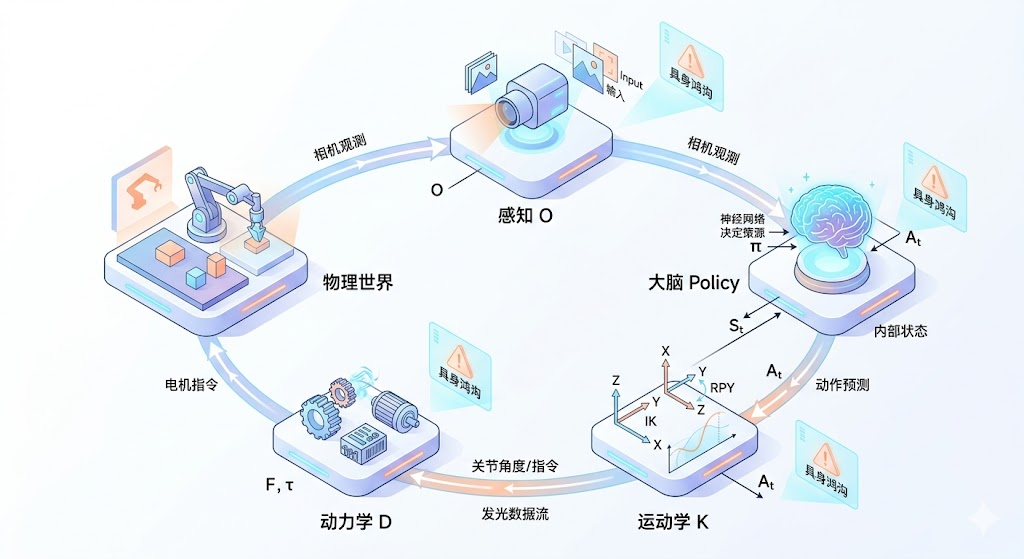 从感知到推理再到动作执行全流程
从感知到推理再到动作执行全流程
假设物理世界在t时刻的真实状态为 S t S_t St,机器人在执行完一个决策周期后,物理世界状态发生演进,即 Δ S = S t + 1 − S t ΔS=S_{t+1} −S_t ΔS=St+1−St。对于一个特定的机器人本体 E E E,其硬件属性可以由三个正交的参数集定义: E = [ ξ s e n , ξ k i n , ξ d y n ] E=[ξ_{sen}, ξ_{kin} ,ξ_{dyn}] E=[ξsen,ξkin,ξdyn],分别对应传感器配置、运动学拓扑和动力学参数。那么,以深度学习策略网络 π θ π_θ πθ为核心的端到端具身控制链路,可以由以下统一映射方程串接表达:
s t + 1 = P e n v ( s t , D d y n ( K k i n ( π θ ( O s e n ( s t ) ) ) ) ) s_{t+1} = \mathcal{P}_{env} \Big( s_t, \mathcal{D}_{dyn} \big( \mathcal{K}_{kin} ( \pi_\theta ( \mathcal{O}_{sen}(s_t) ) ) \big) \Big) st+1=Penv(st,Ddyn(Kkin(πθ(Osen(st)))))
具身智能主要观测传感器是相机,上面的公式可以进一步详细展开为:
s t + 1 = P e n v ( s t , D d y n ( K k i n ( ( T w o r l d b a s e ) − 1 ⋅ T w o r l d c a m ⏟ 相对外参变换 T c a m b a s e ⋅ π θ ( Π p r o j ( s t ; K i n t , T w o r l d c a m ) ⏟ 视觉成像观测 O c a m ) ) ) ) s_{t+1} = \mathcal{P}_{env} \Bigg( s_t, \mathcal{D}_{dyn} \bigg( \mathcal{K}_{kin} \Big( \underbrace{(T_{world}^{base})^{-1} \cdot T_{world}^{cam}}_{\text{相对外参变换 } T_{cam}^{base}} \cdot \pi_\theta \big( \underbrace{\Pi_{proj}(s_t; K_{int}, T_{world}^{cam})}_{\text{视觉成像观测 } O_{cam}} \big) \Big) \bigg) \Bigg) st+1=Penv(st,Ddyn(Kkin(相对外参变换 Tcambase
(Tworldbase)−1⋅Tworldcam⋅πθ(视觉成像观测 Ocam
Πproj(st;Kint,Tworldcam)))))
上式中可提取具身智能数据里的标签,即动作 a t = ( T w o r l d b a s e ) − 1 ⋅ T w o r l d c a m ⏟ 相对外参变换 T c a m b a s e ⋅ π θ ( o t ) ∈ A a_t = \underbrace{(T_{world}^{base})^{-1} \cdot T_{world}^{cam}}_{\text{相对外参变换 } T_{cam}^{base}} \cdot \pi_\theta(o_t) \in \mathcal{A} at=相对外参变换 Tcambase (Tworldbase)−1⋅Tworldcam⋅πθ(ot)∈A
为了将我们在前文解构的多维物理鸿沟(感知、运动学、动力学)映射到这个方程中,我们将该复合函数进一步显式展开:
s t + 1 t g t = P e n v ( s t , ( D d y n s r c + Δ D g a p ) ⏟ 动力学鸿沟 ( ( K k i n s r c + Δ K g a p ) ⏟ 运动学鸿沟 ( ( ( T c a m b a s e ) s r c + Δ T c a m b a s e ) ⏟ 执行外参鸿沟 ⋅ π θ s r c ( Π p r o j ( s t ; ( K i n t ) s r c + Δ K i n t , ( T w o r l d c a m ) s r c + Δ T w o r l d c a m ) ⏟ 视觉感知鸿沟 ) ) ) ) s_{t+1}^{tgt} = \mathcal{P}_{env} \Bigg( s_t, \underbrace{\Big(\mathcal{D}_{dyn}^{src} + \Delta \mathcal{D}_{gap}\Big)}_{\text{动力学鸿沟}} \Bigg( \underbrace{\Big(\mathcal{K}_{kin}^{src} + \Delta \mathcal{K}_{gap}\Big)}_{\text{运动学鸿沟}} \bigg( \underbrace{\Big( (T_{cam}^{base})_{src} + \Delta T_{cam}^{base} \Big)}_{\text{执行外参鸿沟}} \cdot \pi_\theta^{src} \Big( \underbrace{\Pi_{proj}\big(s_t; (K_{int})_{src} + \Delta K_{int}, (T_{world}^{cam})_{src} + \Delta T_{world}^{cam}\big)}_{\text{视觉感知鸿沟}} \Big) \bigg) \Bigg) \Bigg) st+1tgt=Penv(st,动力学鸿沟 (Ddynsrc+ΔDgap)(运动学鸿沟 (Kkinsrc+ΔKgap)(执行外参鸿沟 ((Tcambase)src+ΔTcambase)⋅πθsrc(视觉感知鸿沟 Πproj(st;(Kint)src+ΔKint,(Tworldcam)src+ΔTworldcam)))))
将鸿沟用代数误差式展开如下:
s t + 1 t g t = P e n v ( s t , ( D d y n s r c + Δ D g a p ) ( ( K k i n s r c + Δ K g a p ) ( ( ( T c a m b a s e ) s r c + Δ T c a m b a s e ) ⋅ π θ s r c ( Π p r o j ( s t ; ( K i n t ) s r c + Δ K i n t , ( T w o r l d c a m ) s r c + Δ T w o r l d c a m ) ) ) ) ) s_{t+1}^{tgt} = \mathcal{P}_{env} \Bigg( s_t, \Big(\mathcal{D}_{dyn}^{src} + \Delta \mathcal{D}_{gap}\Big) \bigg( \Big(\mathcal{K}_{kin}^{src} + \Delta \mathcal{K}_{gap}\Big) \Big( \big((T_{cam}^{base})_{src} + \Delta T_{cam}^{base}\big) \cdot \pi_\theta^{src} \big( \Pi_{proj}(s_t; (K_{int})_{src} + \Delta K_{int}, (T_{world}^{cam})_{src} + \Delta T_{world}^{cam}) \big) \Big) \bigg) \Bigg) st+1tgt=Penv(st,(Ddynsrc+ΔDgap)((Kkinsrc+ΔKgap)(((Tcambase)src+ΔTcambase)⋅πθsrc(Πproj(st;(Kint)src+ΔKint,(Tworldcam)src+ΔTworldcam)))))
其中:
- S \mathcal{S} S:物理环境的状态空间 (State Space)。
- s t , s t + 1 s_t, s_{t+1} st,st+1:当前时刻 t t t 与下一时刻 t + 1 t+1 t+1 的真实物理状态。
- O \mathcal{O} O:观测空间 (Observation Space),也是传感器对物理世界的物理观测模型。
- A \mathcal{A} A:动作空间 (Action Space)。
- a t a_t at:网络在 t t t 时刻输出的动作指令。
- π θ \pi_\theta πθ:以 θ \theta θ 为参数的策略网络(即 具身智能大模型),接收观测,输出动作。
- P e n v \mathcal{P}_{env} Penv:物理世界客观存在的状态转移函数/转移概率 (Transition Dynamics)。
- O s e n \mathcal{O}_{sen} Osen:传感器观测映射函数(将物理状态转化为图像或本体感受)。
- K k i n \mathcal{K}_{kin} Kkin:底层运动学解算器映射(将末端位姿解算为关节空间指令)。
- D d y n \mathcal{D}_{dyn} Ddyn:底层动力学映射(将关节指令转化为实际电机力矩)。
- K i n t K_{int} Kint:相机内参矩阵 (Camera Intrinsics Matrix),包含焦距、主点坐标等,决定了 3D 空间到 2D 像素的投影畸变。
- T w o r l d c a m T_{world}^{cam} Tworldcam:世界坐标系到相机坐标系的外参矩阵 (World-to-Camera Extrinsics),决定了相机在物理空间中的绝对安装位姿。
- T w o r l d b a s e T_{world}^{base} Tworldbase:世界坐标系到机械臂基座的外参矩阵 (World-to-Base Extrinsics),决定了机器人在物理空间中的绝对锚定点。
- Π p r o j \Pi_{proj} Πproj:相机光学投影映射函数 (Optical Projection Mapping),将高维物理状态 s t s_t st 结合内外参压缩为二维像素观测矩阵。
- ( T w o r l d b a s e ) − 1 ⋅ T w o r l d c a m (T_{world}^{base})^{-1} \cdot T_{world}^{cam} (Tworldbase)−1⋅Tworldcam:即 T c a m b a s e T_{cam}^{base} Tcambase,由于控制指令必须在基座坐标系下执行,而 视觉特征提取自相机视角,该乘积项在数学上构成了连接“网络输出”与“底层运动学”的必经刚体变换桥梁。
鸿沟的数学本质:累积误差与分布散度 ,基于上述统一映射方程,我们可以给出具身鸿沟的严格数学定义:当一个在源本体 E s r c E_{src} Esrc上训练收敛的策略 π θ s r c π_{θsrc} πθsrc ,直接零样本(Zero-shot)部署到目标异构本体 E t g t E_{tgt} Etgt上时,物理世界实际产生的状态转移,与预期状态转移之间的差异:
E s t − P = ∥ s t + 1 t g t − s t + 1 e x p e c t e d ∥ 2 {E}_{s_t-\mathcal{P}} = \left\| s_{t+1}^{tgt} - s_{t+1}^{expected} \right\|_2 Est−P=
st+1tgt−st+1expected
2
由于上述映射是高度非线性的复合函数,任何一层算子(如 K K K 矩阵的微小偏移)的微小扰动,都会经过后序的神经网络 π θ π_θ πθ和控制执行等产生指数级的级联误差放大。
1.4 概念界定:严辨 Embodiment Gap 与 Sim-to-Real Gap
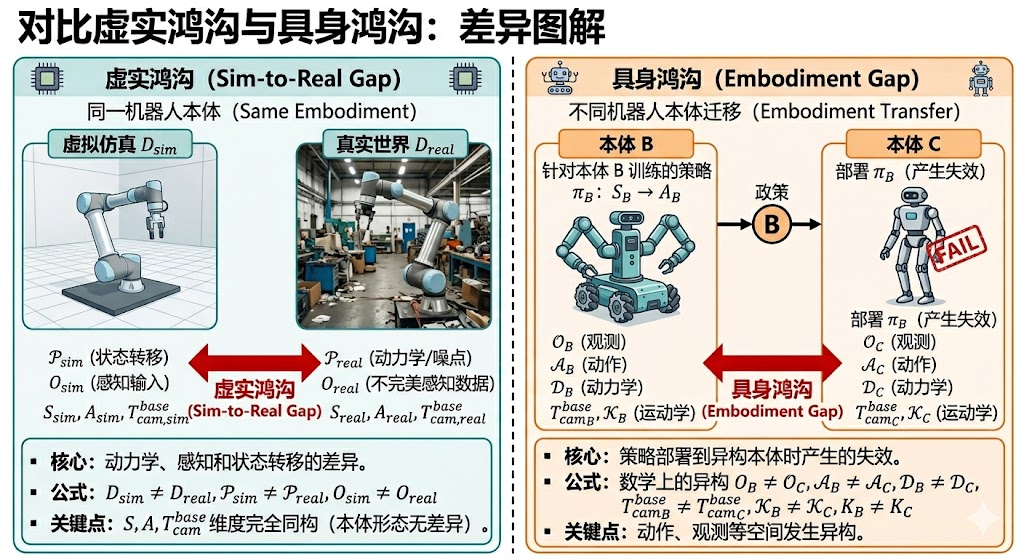
具身鸿沟与虚实鸿沟的差异
虚实鸿沟 (Sim-to-Real Gap): 在同一种机器人本体(同一 URDF)前提下,虚拟仿真与真实世界的动力学差异、状态转移和感知输入的信息差异( D s i m ≠ D r e a l D_{sim}≠D_{real} Dsim=Dreal, ( P s i m ≠ P r e a l \mathcal{P}_{sim}≠\mathcal{P}_{real} Psim=Preal, O s i m ≠ O r e a l O_{sim}≠O_{real} Osim=Oreal),其状态空间 S S S 、动作空间 A A A和相机外参 T c a m b a s e T_{cam}^{base} Tcambase等的维度完全同构(本体形态拓扑上无差异)。
具身鸿沟 (Embodiment Gap): 基于本体 B训练的策略 π B : S B → A B π_B :S_B →A_B πB:SB→AB部署到本体C时产生的失效。数学上意味着动作、观测等都有可能发生了异构( O B ≠ O C , A B ≠ A C , D B ≠ D C , T c a m B b a s e ≠ T c a m C b a s e , K B ≠ K C , K B ≠ K C \mathcal{O}_B≠\mathcal{O}_C,\mathcal{A}_B≠\mathcal{A}_C,\mathcal{D}_{B}≠\mathcal{D}_{C}, T_{cam_B}^{base}≠T_{cam_C}^{base},\mathcal{K}_B≠\mathcal{K}_C,{K}_B≠{K}_C OB=OC,AB=AC,DB=DC,TcamBbase=TcamCbase,KB=KC,KB=KC)
2. 跨本体数据集的发展与孤岛现状 (Evolution of Cross-Embodiment Datasets)
数据集本身自带的形态差异决定了模型必须跨越的鸿沟层级:
| 数据集名称 | 数据规模 | 包含的本体数量 | 数据模态 | 包含的具身鸿沟类型 |
|---|---|---|---|---|
| RT-1 | ~130k | 1 | 图像,+7-DoF动作 | 无 (单一本体) |
| Open X-Embodiment | ~2M | 22+ | 多机位图像+动作 | 异构动作 (涵盖动力学、外观与形态拓扑差异) |
| UMI | 数千小时 | 无本体 | 视频+夹爪动作+手部轨迹 | 无底层运动学约束的拓扑断层 |
| Ego4D | >3000 小时 | 纯人类骨骼与肌肉 | 人类第一视角视频 | 极致形态鸿沟,无动作标签 |
3. 跨本体鸿沟的多维物理解构
3.1 形态学与运动学鸿沟
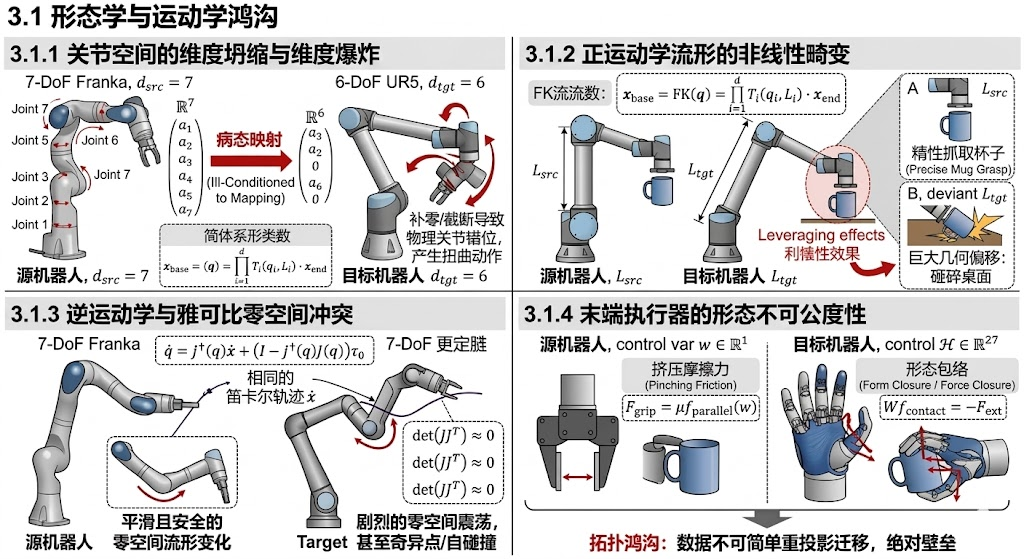
四大形态学与运动学鸿沟示意图
形态学与运动学鸿沟是跨本体迁移中最直观、但在几何层面上也最难逾越的硬性物理屏障。它源于不同机器人在连杆长度、关节类型(旋转关节或平移关节)、自由度(DoF)以及末端执行器拓扑结构上的根本性差异。这种差异导致了在源本体上学到的动作专家,在目标本体的参数空间中变得完全“不可公度”。
我们可以从以下四个维度对其数学本质进行深度解构:
3.1.1 关节空间的维度坍缩与维度爆炸
在端到端控制的最朴素形式中,策略网络直接输出机器人的关节角度(或角速度)。设源机器人与目标机器人的关节空间分别为 Q s r c \mathcal{Q}_{src} Qsrc 和 Q t g t \mathcal{Q}_{tgt} Qtgt,其对应的自由度分别为 d s r c d_{src} dsrc 和 d t g t d_{tgt} dtgt。
源机器人的动作输出为:
q s r c = [ q 1 , q 2 , … , q d s r c ] T ∈ R d s r c q_{src} = [q_1, q_2, \dots, q_{d_{src}}]^T \in \mathbb{R}^{d_{src}} qsrc=[q1,q2,…,qdsrc]T∈Rdsrc
当 d s r c ≠ d t g t d_{src} \neq d_{tgt} dsrc=dtgt 时(例如从 7-DoF 的 Franka 机械臂迁移到 6-DoF 的 UR5,或从双臂系统迁移到单臂系统),这构成了数学上的病态映射。即使强行通过补零或截断的方法对齐维度,由于两个空间的基向量所代表的物理关节(如肩部偏航角 vs. 肘部俯仰角)完全错位,这种粗暴的映射也会导致目标机器人产生毫无物理意义的扭曲动作。
3.1.2 正运动学流形的非线性畸变
即使两个机器人的自由度完全相同( d s r c = d t g t d_{src} = d_{tgt} dsrc=dtgt,且关节拓扑一致),由于连杆长度(Link Lengths)或 Denavit-Hartenberg (D-H) 参数的差异,同样的关节角度指令也会在三维任务空间(Cartesian Space, S E ( 3 ) SE(3) SE(3))中映射到完全不同的末端位姿。
正运动学(Forward Kinematics, FK)是一个高度非线性的连乘矩阵变换:
x b a s e = FK ( q ) = ∏ i = 1 d T i ( q i , L i ) ⋅ x e n d x_{base} = \text{FK}(q) = \prod_{i=1}^{d} T_i(q_i, L_i) \cdot x_{end} xbase=FK(q)=i=1∏dTi(qi,Li)⋅xend
其中 T i T_i Ti 是依赖于关节角 q i q_i qi 和连杆长度 L i L_i Li 的齐次变换矩阵。
当源本体的连杆参数 L s r c L_{src} Lsrc 与目标本体 L t g t L_{tgt} Ltgt 存在微小偏差时,由于矩阵连乘的杠杆放大效应,会在末端执行器 x b a s e ∈ S E ( 3 ) x_{base} \in SE(3) xbase∈SE(3) 处产生巨大的几何偏移:
∥ FK t g t ( q ; L t g t ) − FK s r c ( q ; L s r c ) ∥ S E ( 3 ) > ϵ f a t a l \left\| \text{FK}_{tgt}(q; L_{tgt}) - \text{FK}_{src}(q; L_{src}) \right\|_{SE(3)} > \epsilon_{fatal} ∥FKtgt(q;Ltgt)−FKsrc(q;Lsrc)∥SE(3)>ϵfatal
这意味着,一个在源机器人上刚好能捏住杯子的关节指令 q q q,在目标机器人上可能直接砸碎桌面。
3.1.3 逆运动学与雅可比零空间冲突
为了规避上述的关节空间错位,当前 VLA 模型普遍选择在统一的笛卡尔任务空间 S E ( 3 ) SE(3) SE(3) 中输出末端位姿指令 x b a s e x_{base} xbase。然而,这只是将鸿沟转嫁给了下层的逆运动学(Inverse Kinematics, IK)求解器。
对于冗余机械臂(自由度 d > 6 d > 6 d>6),从 6D 任务空间到高维关节空间的映射存在无穷多组解。其关节速度 q ˙ \dot{q} q˙ 与末端速度 x ˙ \dot{x} x˙ 的关系由雅可比矩阵 J ( q ) J(q) J(q) 及其伪逆 J † ( q ) J^\dagger(q) J†(q) 决定:
q ˙ = J † ( q ) x ˙ + ( I − J † ( q ) J ( q ) ) τ 0 \dot{q} = J^\dagger(q) \dot{x} + \big( I - J^\dagger(q)J(q) \big) \tau_0 q˙=J†(q)x˙+(I−J†(q)J(q))τ0
公式右侧的第二项 ( I − J † ( q ) J ( q ) ) τ 0 \big( I - J^\dagger(q)J(q) \big) \tau_0 (I−J†(q)J(q))τ0 被称为雅可比零空间投影(Null-Space Projection)。它决定了机器人的“姿态(Posture)”——例如在保持末端位置不动的情况下,机械臂的肘部是向上抬起还是向下低垂。
不同形态的机器人,其零空间流形截然不同。源本体在追踪一段轨迹时,其零空间变化可能是平滑且安全的;但同样的笛卡尔轨迹 x ˙ \dot{x} x˙ 强加给目标本体的雅可比矩阵 J t g t J_{tgt} Jtgt 时,可能会触发目标本体极其剧烈的零空间震荡,甚至使其陷入**运动学奇异点(Kinematic Singularities, 即 det ( J J T ) = 0 \det(J J^T) = 0 det(JJT)=0)**或发生严重的自碰撞(Self-collision)。
3.1.4 末端执行器的形态不可公度性
这种情况的形态学鸿沟发生在末端执行器(夹爪/灵巧手)层面。
假设源本体使用的是二指平行夹爪(控制变量为一个标量开度 w ∈ R 1 w \in \mathbb{R}^1 w∈R1),而目标本体使用的是拥有 27 个自由度的仿生软体灵巧手 H ∈ R 27 \mathcal{H} \in \mathbb{R}^{27} H∈R27。这两者不仅维度不同,其底层的**交互物理机制(Physics of Interaction)**也发生了根本改变。
平行夹爪依靠的是单一维度的“挤压摩擦力(Pinching Friction)”:
F g r i p = μ ⋅ f p a r a l l e l ( w ) F_{grip} = \mu \cdot f_{parallel}(w) Fgrip=μ⋅fparallel(w)
而灵巧手依靠的是复杂的多指“形态包络(Form Closure / Force Closure)”:
W ⋅ f c o n t a c t = − F e x t W \cdot f_{contact} = -F_{ext} W⋅fcontact=−Fext
(其中 W W W 为抓取矩阵, f c o n t a c t f_{contact} fcontact 为各接触点的接触力向量)。
这种从“简单捏取”到“高维包络”的拓扑鸿沟,使得在平行夹爪上收集的海量数据集,完全无法通过简单的数学重投影迁移到灵巧手上,构成了从 L 3 L_3 L3 到 L 4 L_4 L4 级别迁移的绝对壁垒。
3.2 动力学与执行器鸿沟
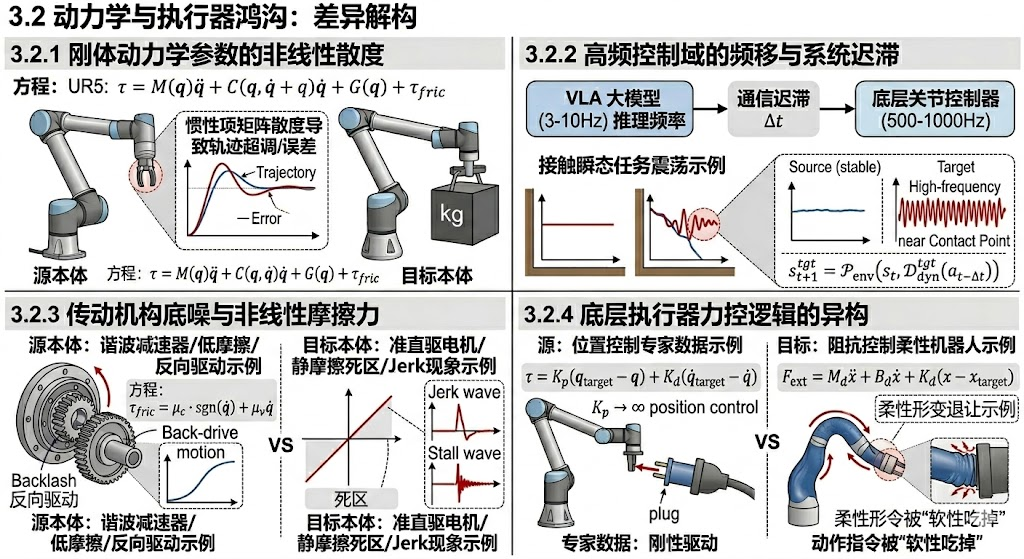
如果说运动学鸿沟是由于“躯干形态不同”导致的几何空间错位,那么动力学与执行器鸿沟则是由于“肌肉力量与神经反射速度不同”引发的物理底层崩塌。即使源本体与目标本体在几何尺寸和自由度上完全一致(例如两台同型号的 UR5 机械臂),只要它们的负载质量不同、电机磨损程度不同,或者底层的伺服控制逻辑不同,大模型输出的同一组动作指令也会在物理世界中产生截然不同的动态响应。
我们可以从以下四个维度对动力学鸿沟的数学本质进行深度解构:
3.2.1 刚体动力学参数的非线性散度
机器人的底层物理运动严格遵循牛顿-欧拉刚体动力学方程(Rigid Body Dynamics Equation)。无论上层大模型输出的是位置还是速度指令,最终都必须由底层的电机转化为力矩(Torque)来实现。标准的动力学方程如下:
τ = M ( q ) q ¨ + C ( q , q ˙ ) q ˙ + G ( q ) + τ f r i c \tau = M(q)\ddot{q} + C(q, \dot{q})\dot{q} + G(q) + \tau_{fric} τ=M(q)q¨+C(q,q˙)q˙+G(q)+τfric
其中, M ( q ) M(q) M(q) 为惯性张量矩阵, C ( q , q ˙ ) C(q, \dot{q}) C(q,q˙) 为科里奥利力与离心力项, G ( q ) G(q) G(q) 为重力补偿项, τ \tau τ 为所需的电机力矩。
当策略网络从无负载的源本体迁移到携带重物或自身材质更重的目标本体时,其惯性矩阵 M t g t ( q ) M_{tgt}(q) Mtgt(q) 和重力项 G t g t ( q ) G_{tgt}(q) Gtgt(q) 会发生剧变。如果网络在训练时隐式过拟合了源本体的动力学特征(即假设了一个固定的 M s r c M_{src} Msrc),那么在目标本体上执行相同的加速度 q ¨ \ddot{q} q¨ 时,由于力矩输出不足或过剩,系统会产生严重的轨迹超调(Overshoot)或稳态误差。
3.2.2 高频控制域的频移与系统迟滞
当前视觉-语言-动作大模型(VLA)受限于庞大的参数量,其推理频率通常极低(如 3Hz 到 10Hz),而机器人的底层关节控制器(如 PID)则运行在极高的频率(500Hz 到 1000Hz)。这种跨频域控制极其依赖于系统的通信迟滞(Communication Latency, Δ t \Delta t Δt)。
假设在理想情况下,策略网络根据观测状态 s t s_t st 下发动作 a t a_t at;但在异构硬件上,由于总线协议或电机响应时间的差异,实际执行的动作存在相位延迟:
s t + 1 t g t = P e n v ( s t , D d y n t g t ( a t − Δ t ) ) s_{t+1}^{tgt} = \mathcal{P}_{env} \Big( s_t, \mathcal{D}_{dyn}^{tgt}(a_{t-\Delta t}) \Big) st+1tgt=Penv(st,Ddyntgt(at−Δt))
在抓取或插入等接触丰富的瞬态任务(Transient Tasks)中,哪怕是几十毫秒的 Δ t \Delta t Δt 偏差,都会导致反馈回路中的误差被离散时间积分以指数级放大,引发系统在接触点附近产生灾难性的高频震荡(High-frequency Oscillation)。
**3.2.3 传动机构底噪与非线性摩擦力 **
由于造价和工艺的不同,不同机器人的关节传动机构(如谐波减速器 Harmonic Drives vs. 准直驱电机 Quasi-Direct Drives)具有完全不同的物理“底噪”。方程中的摩擦力项 τ f r i c \tau_{fric} τfric 是一个高度非线性的分段函数,通常包含库仑摩擦(静摩擦)与粘滞摩擦:
τ f r i c = μ c ⋅ sgn ( q ˙ ) + μ v q ˙ \tau_{fric} = \mu_c \cdot \text{sgn}(\dot{q}) + \mu_v \dot{q} τfric=μc⋅sgn(q˙)+μvq˙
源本体(例如昂贵的 Franka)可能具有极低的静摩擦系数 μ c \mu_c μc 和反向驱动力;而目标本体(例如低成本的步进电机机械臂)可能存在巨大的静摩擦死区和齿轮背隙(Backlash)。当 VLA 模型输出微小的微调位姿增量 Δ T \Delta T ΔT 时,目标本体的电机力矩可能根本无法克服静摩擦死区(死机现象),或者在突破静摩擦的瞬间突然急加速(Jerk 现象),导致精细操作任务直接宣告失败。
3.2.4 底层执行器力控逻辑的异构
除了硬件本身的物理属性,控制器固件(Firmware)中写死的底层力控逻辑差异,是跨本体迁移的另一个隐形杀手。
专家数据往往来源于具备极高刚度(High Stiffness)的位置控制(Position Control)机器人,其底层是一个强硬的 PD 控制器:
τ = K p ( q t a r g e t − q ) + K d ( q ˙ t a r g e t − q ˙ ) \tau = K_p(q_{target} - q) + K_d(\dot{q}_{target} - \dot{q}) τ=Kp(qtarget−q)+Kd(q˙target−q˙)
而目标本体可能是一台设计用于人机协作的柔性机器人,其底层采用的是阻抗控制(Impedance Control),表现为一个弹簧-质量-阻尼系统:
F e x t = M d x ¨ + B d x ˙ + K d ( x − x t a r g e t ) F_{ext} = M_d \ddot{x} + B_d \dot{x} + K_d (x - x_{target}) Fext=Mdx¨+Bdx˙+Kd(x−xtarget)
如果大模型在训练时习惯了“不管遇到什么阻力,都强行驱动到目标点( K p → ∞ K_p \to \infty Kp→∞)”的数据流形,当它指挥一台低刚度(小 K d K_d Kd 值)的目标机器人去用力插入插头时,目标机器人的柔顺控制逻辑会主动发生形变以卸载反作用力,导致动作指令在物理执行层被“软性吃掉(Softly Absorbed)”,彻底打破了“所见即所动”的马尔可夫决策闭环。
3.3 感知与本体感受鸿沟
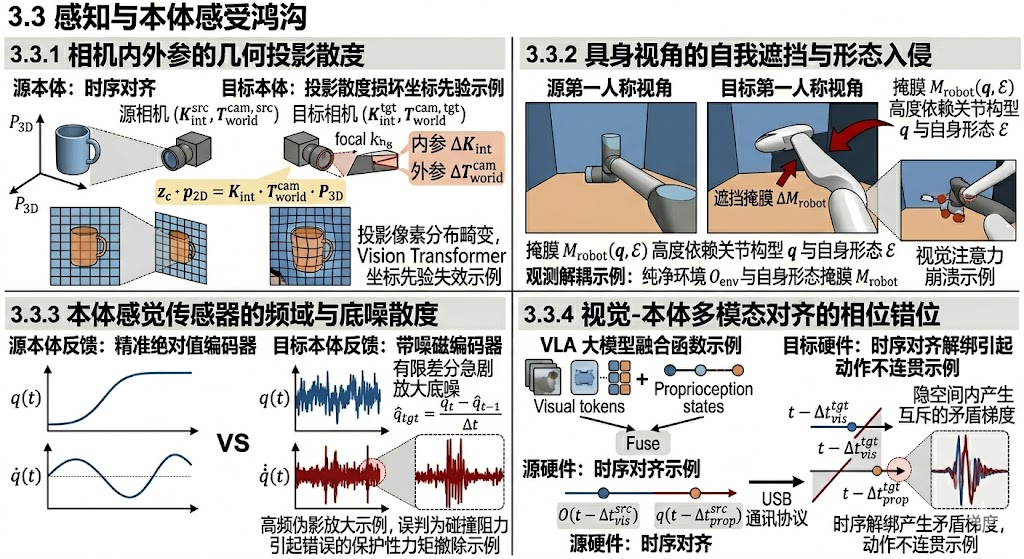
如果在运动学与动力学中,我们讨论的是机器人如何“输出”动作,那么感知与本体感受鸿沟探讨的则是机器人如何“输入”世界状态。当视觉-语言-动作大模型(VLA)从一台机器人迁移到另一台机器人时,它的“眼睛(相机)”和“神经末梢(关节编码器)”都发生了根本性的替换。这种传感界面的非连续性,会在多模态特征融合阶段引发致命的幻觉与状态估计偏离。
我们可以从以下四个维度对感知鸿沟的数学本质进行深度解构:
3.3.1 相机内外参的几何投影畸变
视觉感知大模型的底层依赖于二维像素空间到三维物理空间的映射。在真实物理世界中,空间中的三维点 P 3 D = [ X , Y , Z , 1 ] T P_{3D} = [X, Y, Z, 1]^T P3D=[X,Y,Z,1]T 投影到相机像素坐标系 p 2 D = [ u , v , 1 ] T p_{2D} = [u, v, 1]^T p2D=[u,v,1]T 的过程,由相机内参矩阵 K i n t K_{int} Kint 与外参矩阵 T w o r l d c a m T_{world}^{cam} Tworldcam 严格定义:
z c ⋅ p 2 D = K i n t ⋅ T w o r l d c a m ⋅ P 3 D z_c \cdot p_{2D} = K_{int} \cdot T_{world}^{cam} \cdot P_{3D} zc⋅p2D=Kint⋅Tworldcam⋅P3D
当跨本体迁移时,目标机器人的相机镜头畸变参数、焦距或视场角(FOV)发生了变化(即 Δ K i n t \Delta K_{int} ΔKint),或者相机的安装倾角和高度发生了哪怕几厘米的偏移(即 Δ T w o r l d c a m \Delta T_{world}^{cam} ΔTworldcam),同一个物理目标在图像上的像素分布 p 2 D p_{2D} p2D 就会发生非线性平移和拉伸。对于高度依赖空间位置编码(Positional Encoding)的 Vision Transformer 而言,这种底层的几何投影散度会直接摧毁预训练阶段建立的“像素-物理坐标”对应先验。
3.3.2 具身视角的自我遮挡与形态入侵
具身智能区别于传统计算机视觉的一个核心特征是第一人称视角(Egocentric Vision)。在操作过程中,相机的视野中必然会包含机器人自身的机械臂。
我们将观测图像解耦为纯净环境 O e n v O_{env} Oenv 与自身形态掩膜 M r o b o t ( q , E ) M_{robot}(q, \mathcal{E}) Mrobot(q,E) 的结合:
O c a m = O e n v ⊙ ( 1 − M r o b o t ( q , E ) ) + O r o b o t _ t e x t u r e O_{cam} = O_{env} \odot \big(1 - M_{robot}(q, \mathcal{E})\big) + O_{robot\_texture} Ocam=Oenv⊙(1−Mrobot(q,E))+Orobot_texture
其中,掩膜 M r o b o t M_{robot} Mrobot 高度依赖于当前机器人的关节构型 q q q 以及自身的拓扑形态 E \mathcal{E} E。
当策略模型 π θ \pi_\theta πθ 在源本体上训练时,它不仅学会了抓取物体,还隐式地学会了将源本体的机械臂外观(如 UR5 的银灰色圆柱体)作为“末端执行器位置”的视觉锚点。当迁移到目标本体(如 Franka 的白色流线型外壳)时,形态入侵使得 O r o b o t _ t e x t u r e O_{robot\_texture} Orobot_texture 完全改变。更严重的是,更粗壮的目标机械臂会产生更大的遮挡掩膜 Δ M r o b o t \Delta M_{robot} ΔMrobot,导致关键的物理交互点(Contact Points)在视觉流形上表现为不可观测状态(Partially Observable),引发视觉注意力的彻底崩溃。
3.3.3 本体感觉传感器的频域与底噪散度
除了视觉,具身大脑还严重依赖本体感觉(Proprioception)——如关节编码器反馈的位置 q q q 和速度 q ˙ \dot{q} q˙,作为闭环控制的状态输入。
不同的硬件具有不同精度的传感器。假设源机器人的编码器是极其精准的绝对值编码器,而目标机器人使用的是带有高斯观测底噪 N ( 0 , Σ t g t ) \mathcal{N}(0, \Sigma_{tgt}) N(0,Σtgt) 的廉价磁编码器:
q ^ t g t = q t r u e + N ( 0 , Σ t g t ) \hat{q}_{tgt} = q_{true} + \mathcal{N}(0, \Sigma_{tgt}) q^tgt=qtrue+N(0,Σtgt)
更致命的是,速度 q ˙ ^ \hat{\dot{q}} q˙^ 通常是由离散的位置信号通过有限差分(Finite Difference)估算得出的:
q ˙ ^ t g t = q ^ t − q ^ t − 1 Δ t \hat{\dot{q}}_{tgt} = \frac{\hat{q}_t - \hat{q}_{t-1}}{\Delta t} q˙^tgt=Δtq^t−q^t−1
目标硬件上微小的位置高频底噪,在经过有限差分的求导操作后,会被急剧放大。如果 VLA 模型的特征提取层没有针对这种目标本体特有的频率分布进行自适应低通滤波(Low-pass Filtering),这些高频伪影(Artifacts)将被网络误判为外部碰撞或阻力,从而触发错误的保护性力矩撤除。
3.3.4 视觉-本体多模态对齐的相位错位 (Phase Misalignment in Multimodal Fusion)
在 VLA 大模型的输入端,视觉令牌(Visual Tokens)与本体感受状态(Proprioceptive State)必须在时间轴上实现严格的对齐。
在源硬件架构上,由于总线带宽和摄像头采样率的匹配,视觉延迟 Δ t v i s \Delta t_{vis} Δtvis 与本体延迟 Δ t p r o p \Delta t_{prop} Δtprop 是相对固定的。模型隐式地拟合了这种时间差,其融合函数可以表示为:
F e a t u r e f u s e d = f f u s i o n ( O ( t − Δ t v i s s r c ) , q ( t − Δ t p r o p s r c ) ) Feature_{fused} = f_{fusion} \big( O(t - \Delta t_{vis}^{src}), \; q(t - \Delta t_{prop}^{src}) \big) Featurefused=ffusion(O(t−Δtvissrc),q(t−Δtpropsrc))
然而,目标机器人的通讯架构可能完全不同(例如从 EtherCAT 工业总线切换为 USB 串口通讯),导致两类传感器的相对时间戳发生相位漂移(Phase Drift)。当视觉画面显示“已经接触到物体”时,本体感受器却汇报“手爪还在一秒前的位置”。这种系统级的多模态时序解绑,会在隐空间内产生完全互斥的矛盾梯度,使得端到端网络无法输出任何连贯的动作流。
4. 跨本体泛化的层级(抛砖引玉)
| 层级 | 异构点 | 详细描述 |
|---|---|---|
| L5 | 完全异构跨本体 | 机器人及其携带的传感器参数存在明显差异,模型内部物理表征彻底与硬件解耦。输入新本体参数,或经数分钟无监督“随机微动”标定,即刻实现 Zero-shot 控制,如实现极致的 Human-to-Robot 数据复用 |
| L4 | 跨拓扑结构 | 传感器(主要是视觉)的参数和安装位置差异明显,导致其观测视角和动作空间都不一致。通过观测-动作空间的对齐已经得到缓解 |
| L3 | 跨机械臂构型 | 拓扑结构一致,但机械臂构型不一样(6-DoF 迁移至 7-DoF)。必须在统一笛卡尔空间或隐空间中构建动作表征,而不能直接在关节空间进行 |
| L2 | 跨末端执行器 | 拓扑结构一致,但末端机构突变(夹爪到吸盘/灵巧手)。需将执行器的动作进行解耦转译 |
| L1 | 跨细微参数/同构泛化 | 拓扑结构一致,但外观、摩擦力、负载会存在偏差。这个目前通过机械臂位置控制和外观增强已得到较好的解决。 |
| L0 | 无跨本体能力 | 与单一硬件强绑定,充满硬编码 |
5. 跨越本体鸿沟的主流技术范式
要实现多源异构数据的正迁移,首要任务是在算法底层建立一个与具体机器人形态无关的同构动作-观测流形。
5.1 统一表征学习与动作-观测空间解耦
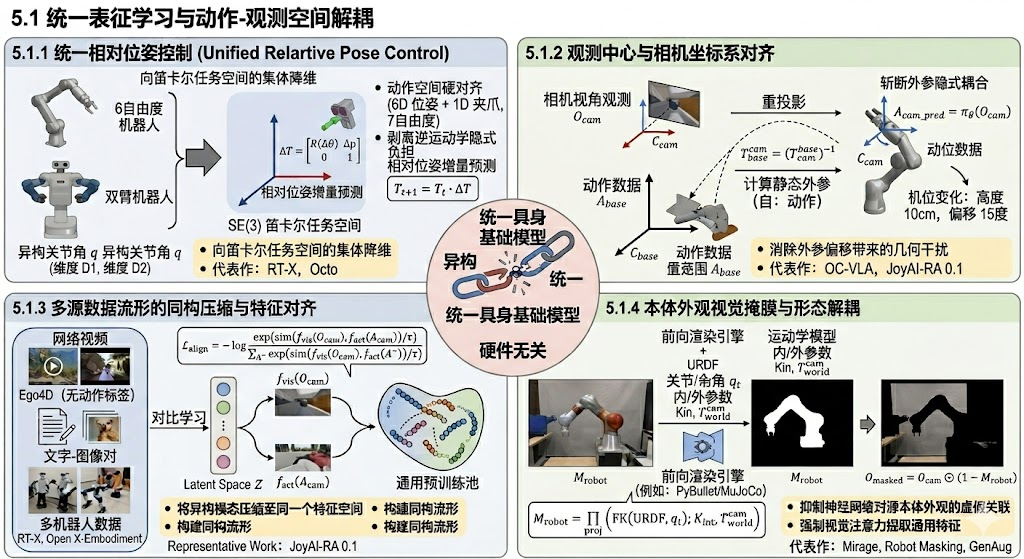
要打破异构硬件之间的数据孤岛,首要任务是在算法层面找到一种“硬件无关(Hardware-Agnostic)”的通用数学表达。本节探讨的四大核心范式,沿着从“统一动作维度”、“统一坐标系空间”、“跨模态数据强同构”到“视觉特征解耦”的脉络,彻底重构了具身控制的基础输入输出链路。
5.1.1 统一相对位姿控制:向笛卡尔任务空间的集体降维 (Unified Relative Pose Control in Task Space)
为了规避 3.1 节中提到的“关节空间维度坍缩”与“正运动学非线性畸变”,当前主流 VLA 模型(如 RT-X, Octo)彻底抛弃了预测高维异构关节角 q q q 的端到端范式。取而代之的是,所有异构动作被强行投影到统一的三维笛卡尔任务空间,预测末端执行器在特殊欧几里得群 S E ( 3 ) SE(3) SE(3) 中的6D 连续相对位姿增量 Δ T \Delta T ΔT:
T t + 1 = T t ⋅ Δ T T_{t+1} = T_t \cdot \Delta T Tt+1=Tt⋅ΔT
其中 Δ T = [ R ( Δ θ ) Δ p 0 1 ] \Delta T = \begin{bmatrix} R(\Delta \theta) & \Delta p \\ 0 & 1 \end{bmatrix} ΔT=[R(Δθ)0Δp1] 包含了微小的相对旋转矩阵和平移向量。
这种“相对增量预测”不仅实现了动作空间的硬对齐,还有效缓解了 3.2 节中动力学惯量差异带来的长程累积误差,将极其复杂的逆运动学(IK)非线性求解负担,交还给了目标机器人底层的传统优化求解器 f s o l v e r f_{solver} fsolver。
核心收益:实现动作空间的“硬”对齐:通过统一为 6 维的空间增量外加 1 维的夹爪开合状态(共 7-DoF),所有异构数据终于能通过同一个全连接层输出,打破了数据混合的最基本物理壁垒。
剥离逆运动学的隐式负担:大模型只需专注学习高层语义与空间直觉,将繁琐的非线性逆运动学映射交还给下游传统的 IK 求解器,极大释放了网络参数容量。
代表性工作:RT-X (CoRL 2023) 首次在涵盖 22 种异构本体的 Open X-Embodiment 数据集中,证明了将动作归一化到增量空间后进行混合训练的巨大正向收益;Octo (RSS 2024) 则利用 Diffusion 扩散模型的去噪机制,在这一统一空间中展现出极强的轨迹平滑度。
5.1.2 观测中心与相机坐标系对齐:斩断外参隐式耦合
为了解决 3.4 节中指出的“观测-执行空间异构”这一绝对死穴,OC-VLA(Observation-Centric VLA)等前沿架构提出了一种极其优雅的几何预处理手段:动作视点重投影。
在数据输入模型之前,利用已知的静态相机外参矩阵 T w o r l d c a m T_{world}^{cam} Tworldcam 与基座外参 T w o r l d b a s e T_{world}^{base} Tworldbase,求得基座到相机的逆向变换 T b a s e c a m = ( T c a m b a s e ) − 1 T_{base}^{cam} = (T_{cam}^{base})^{-1} Tbasecam=(Tcambase)−1。随后,将原本定义在基座坐标系下的真实动作标签 A b a s e A_{base} Abase,强制重投影至相机坐标系下:
A c a m = T b a s e c a m ⋅ A b a s e A_{cam} = T_{base}^{cam} \cdot A_{base} Acam=Tbasecam⋅Abase
此时,大模型的学习目标从 π θ ( O c a m ) → A b a s e \pi_\theta(O_{cam}) \to A_{base} πθ(Ocam)→Abase 转变为了:
A c a m _ p r e d = π θ ( O c a m ) A_{cam\_pred} = \pi_\theta(O_{cam}) Acam_pred=πθ(Ocam)
通过这一纯数学的刚体变换,网络输出的动作指令 A c a m _ p r e d A_{cam\_pred} Acam_pred 永远与视觉观测 O c a m O_{cam} Ocam 处于同一个局部坐标系中。这从根本上斩断了网络对基座外参的隐式过拟合,使得机位视角的轻微扰动 Δ T c a m b a s e \Delta T_{cam}^{base} ΔTcambase 不再引发灾难性的物理散度。
核心收益:从算法底层强行消除了外参偏移带来的几何干扰。即使目标机器人的相机支架比源机器人高出 10 厘米、偏移 15 度,只要网络在相机坐标系内预测出了正确的抓取轨迹,通过目标机自身的 T cambase逆向推算回基座即可。这赋予了模型极强的跨机位、跨形态视觉几何鲁棒性。
代表性工作:OC-VLA (AAAI 2025)和JoyAI-RA 0.1 (arXiv 2026)都提出通过相机-机械臂外参矩阵将末端动作转换到相机坐标系,大幅加速了多实验室数据混合训练的收敛速度。
**5.1.3 多源数据流形的同构压缩与特征对齐 **
在对齐了基础物理空间后,模型需要吸收极其庞杂的互联网图文、无动作标签视频(如 Ego4D)与多机真机数据。
为了将这些异构模态压缩至同一个特征空间,模型通常会引入跨模态对比学习(Contrastive Learning)。通过最小化视觉表征 f v i s ( O c a m ) f_{vis}(O_{cam}) fvis(Ocam) 与本体动作表征 f a c t ( A c a m ) f_{act}(A_{cam}) fact(Acam) 在隐空间 Z \mathcal{Z} Z 中的距离,强制构建同构流形:
L a l i g n = − log exp ( sim ( f v i s ( O c a m ) , f a c t ( A c a m ) ) / τ ) ∑ A − exp ( sim ( f v i s ( O c a m ) , f a c t ( A − ) ) / τ ) \mathcal{L}_{align} = -\log \frac{\exp\big(\text{sim}(f_{vis}(O_{cam}), f_{act}(A_{cam})) / \tau\big)}{\sum_{A^-} \exp\big(\text{sim}(f_{vis}(O_{cam}), f_{act}(A^-)) / \tau\big)} Lalign=−log∑A−exp(sim(fvis(Ocam),fact(A−))/τ)exp(sim(fvis(Ocam),fact(Acam))/τ)
这使得即使在缺乏本体传感器的互联网视频数据中,模型也能凭借 f v i s f_{vis} fvis 在隐空间中“幻觉”出合理的动作意图特征。
核心收益:将原本严重碎片化、低质孤立的局部数据,汇聚成了如同自然语言语料库般庞大的通用预训练池。这种数据规模的量级跨越,使得网络突破了容量瓶颈,在面对 L4 级别的极端异构跨越时展现出强悍的泛化涌现。
代表性工作:JoyAI-RA 0.1 (arXiv 2026) 是这一方向的集大成者,其核心引擎正是基于这种多源空间强同构的物理隔离机制,成功实现了互联网先验知识向实体底层的无损注入。
5.1.4 本体外观视觉掩膜与形态解耦
为了抵御 3.3.2 节中提到的“具身视角自我遮挡与形态入侵”,最暴力的有效手段是在视觉流形上实施“物理隐身术”。
利用目标机器人的 URDF 运动学模型、当前时刻的关节角 q t q_t qt,以及相机的内外参( K i n t K_{int} Kint, T w o r l d c a m T_{world}^{cam} Tworldcam),可以通过前向渲染引擎(如 PyBullet 或 MuJoCo)实时计算出机器人在二维像素平面上的二值化投影掩膜 M r o b o t ( u , v ) ∈ { 0 , 1 } M_{robot}(u, v) \in \{0, 1\} Mrobot(u,v)∈{0,1}:
M r o b o t = Π p r o j ( FK ( U R D F , q t ) ; K i n t , T w o r l d c a m ) M_{robot} = \Pi_{proj} \Big( \text{FK}\big(URDF, q_t\big); K_{int}, T_{world}^{cam} \Big) Mrobot=Πproj(FK(URDF,qt);Kint,Tworldcam)
随后,利用该掩膜将图像中的自身本体像素动态涂黑,得到形态解耦的观测图像:
O m a s k e d = O c a m ⊙ ( 1 − M r o b o t ) O_{masked} = O_{cam} \odot (1 - M_{robot}) Omasked=Ocam⊙(1−Mrobot)
通过向网络喂入 O m a s k e d O_{masked} Omasked,强行剥夺了 VLM 对源硬件表皮纹理和材质颜色的依赖,迫使网络的视觉注意力机制(Self-Attention)从“记忆机械臂形状”转移到“理解物体与空间几何交互关系”的通用特征上。
核心收益:极大地抑制了神经网络对“源本体外观”的虚假关联(Spurious Correlation)。迫使模型在“看不见自己手”或“忽略自己长相”的状态下,不再利用夹爪的颜色或品牌 Logo 作为捷径,而是专注于提取目标物体与环境交互的纯粹物理规律。
代表性工作:Mirage (ICRA 2024) 利用重绘技术实现了纯视觉层面的零样本迁移;而在最新的 VLA 数据流水线中,基于分割大模型的动态本体遮罩(Robot Masking)与 GenAug (RSS 2023) 纹理增强,已经成为消除视觉鸿沟的标配工程范式。
5.2 多本体协同架构与条件注入
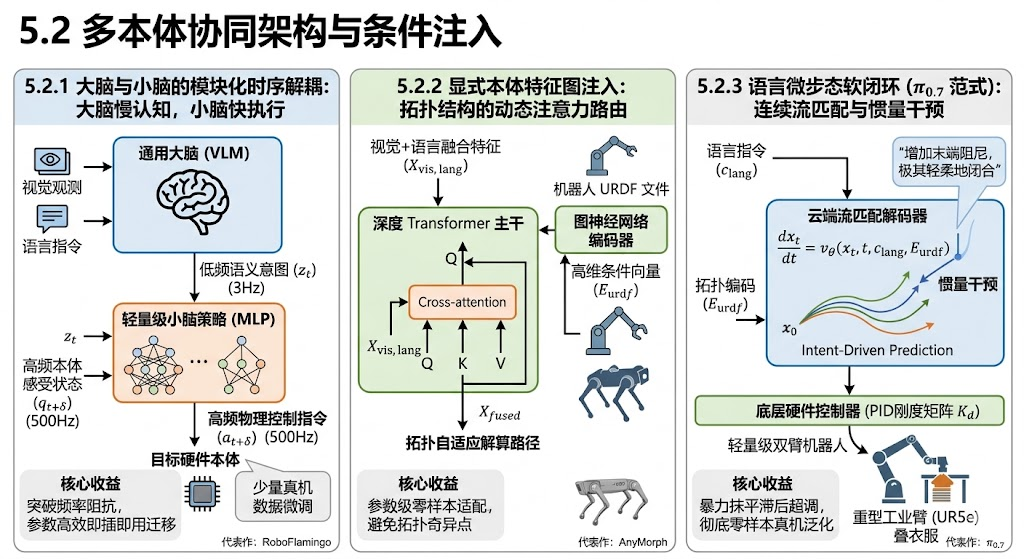
本节将深入“网络内部”,探讨如何通过架构解耦与特征注入,让同一个视觉-语言大模型(VLM)的大脑能够自适应地驱动拥有不同“肌肉与骨骼”的物理本体。
为了彻底解决 3.2 节提到的“频域迟滞”与 3.1 节的“拓扑错位”,当前前沿 VLA 架构正从朴素的端到端(End-to-End)向**具身条件化生成(Embodiment-Conditioned Generation)**演进。
我们可以从以下三个核心技术流派对其数学本质进行解构:
5.2.1 大脑与小脑的模块化时序解耦:低频语义与高频控制的异构闭环 **
为了逾越 3.2.2 节中指出的高频控制域频移问题,现代 VLA 架构(如 RoboFlamingo 与 ALOHA 衍生框架)放弃了由庞大 Transformer 直接输出底层力矩或高频动作的幻想,转而采用“慢认知(大脑) + 快执行(小脑)”的异步双层马尔可夫链。
庞大的多模态主干网络 π v l m \pi_{vlm} πvlm 运行在极低的频率(如 3Hz),仅负责从高维视觉与语言流形中提取抽象的“宏观语义意图(Semantic Intent)” z t z_t zt:
z t = π v l m ( O c a m , Instruction ) z_t = \pi_{vlm}(O_{cam}, \text{Instruction}) zt=πvlm(Ocam,Instruction)
而在极高的执行频率(如 500Hz)下,针对特定异构硬件部署一个极轻量级的 MLP 小脑策略 π m l p \pi_{mlp} πmlp。该小脑接收宏观意图 z t z_t zt,并结合实时的、以高频刷新的本体感受状态 q t + δ q_{t+\delta} qt+δ(如关节角、速度),输出高频物理控制指令 a t + δ a_{t+\delta} at+δ:
a t + δ = π m l p ( z t , q t + δ ) a_{t+\delta} = \pi_{mlp}(z_t, q_{t+\delta}) at+δ=πmlp(zt,qt+δ)
这种时序与架构的双重解耦,不仅将 VLM 从严苛的实时性计算灾难中解放出来,更使得在跨硬件迁移时,我们只需冻结通用大脑 π v l m \pi_{vlm} πvlm,仅用少量真机数据微调特定的小脑 π m l p \pi_{mlp} πmlp**,从而实现了硬件的即插即用(Plug-and-Play)。
核心收益:
突破频率阻抗与算力瓶颈:完美解决了认知网络的高延迟与底层硬件对高频反馈的刚性需求之间的矛盾。
极低成本的即插即用(Plug-and-Play):当需要适配一台全新品牌的异构机械臂时,研究人员无需重新微调整个百亿参数的基座模型,只需收集少量该硬件的数据,在冻结“大脑”特征的条件下,花几分钟训练一个全新的“小脑”解码头(Head)即可,实现了极致的参数效率(Parameter Efficiency)。
代表性工作:RoboFlamingo (CoRL 2023) 完美贯彻了这一理念,通过极低的算力成本,实现了一个统一的视觉理解大脑同时驱动多类不同自由度与控制频率的末端硬件。
5.2.2 显式本体特征图注入:拓扑结构的动态注意力路由
不同机器人的关节空间不可公度(见 3.1.1 节),如果强制网络输出相同的特征图,必然引发模式坍塌。因此,模型必须在推理时“意识到”自己当前被部署在什么躯壳上。
这一过程通过显式的本体特征图条件注入(Condition Injection)来实现。首先,利用图神经网络(GNN)或运动学树编码器,将目标机器人的 URDF 文件(包含自由度、连杆长度、关节类型)嵌入为一个高维条件向量 E u r d f E_{urdf} Eurdf:
E u r d f = f k i n e m a t i c s _ e n c o d e r ( URDF t g t ) E_{urdf} = f_{kinematics\_encoder}(\text{URDF}_{tgt}) Eurdf=fkinematics_encoder(URDFtgt)
在 Transformer 主干网络的深层,抛弃传统的自注意力,转而采用以 E u r d f E_{urdf} Eurdf 为键(Key)和值(Value)的交叉注意力机制(Cross-Attention)。让融合了视觉与语言的特征 X v i s , l a n g X_{vis, lang} Xvis,lang 作为查询(Query),根据当前控制的躯干拓扑,动态自适应解算最优的特征路由路径:
X f u s e d = Softmax ( Q ( X v i s , l a n g ) ⋅ K ( E u r d f ) T d k ) ⋅ V ( E u r d f ) X_{fused} = \text{Softmax}\left(\frac{Q(X_{vis, lang}) \cdot K(E_{urdf})^T}{\sqrt{d_k}}\right) \cdot V(E_{urdf}) Xfused=Softmax(dkQ(Xvis,lang)⋅K(Eurdf)T)⋅V(Eurdf)
通过这种结构,同一个权重矩阵 θ \theta θ 在接收到四足狗的 E u r d f E_{urdf} Eurdf 时,会激活控制腿部步态的子神经元;而在接收到机械臂的 E u r d f E_{urdf} Eurdf 时,则会自动屏蔽步态特征,聚焦于末端灵巧手的空间流形。
核心收益:实现了真正的参数级零样本适配(Zero-shot Parameter Adaptability)。网络不再隐式地死记硬背特定硬件的动作映射,而是学会了“依据输入的躯干拓扑,动态计算对应的运动学解”。在推理阶段,即使输入一台未曾见过的全新机械臂的 URDF 描述,模型也能依据图结构自适应地调整输出维度与关节规划,避开目标硬件独有的奇异点。
代表性工作:URDF-Driven Universal Control (ICLR 2024) 与 AnyMorph,初步验证了基于解析拓扑文件实现通用物理控制的可行性,是迈向 L4 级别泛化的坚实一步。
5.2.3 语言微步态软闭环 ( π 0.7 \pi_{0.7} π0.7 范式):连续流匹配与惯量干预
这是 2026 年跨越动力学鸿沟(见 3.2 节)的重大理论突破。为了干预不同硬件惯量、质量带来的超调或阻尼迟滞,研究者将自然语言指令(NLP)直接引入底层高频阻抗逻辑中。
该范式抛弃了离散的动作分类,转而引入连续流匹配(Continuous Flow Matching)或条件扩散模型(Conditioned Diffusion)。模型不再输出单一动作点,而是学习一个描述整个目标动作轨迹的连续常微分方程(ODE)向量场 v θ v_\theta vθ:
d x t d t = v θ ( x t , t , c l a n g , E u r d f ) \frac{d x_t}{d t} = v_\theta\big(x_t, t, c_{lang}, E_{urdf}\big) dtdxt=vθ(xt,t,clang,Eurdf)
其中,初始噪声 x 0 ∼ N ( 0 , I ) x_0 \sim \mathcal{N}(0, I) x0∼N(0,I)。
更核心的是,该架构支持极高分辨率的语言极端信息掩码与干预。例如,当目标机械臂由于传动背隙(Backlash)在接近杯子时发生震荡,人类操作员可以通过输入极为具象的自然语言指令 c l a n g = “增加末端阻尼,极其轻柔地闭合” c_{lang} = \text{“增加末端阻尼,极其轻柔地闭合”} clang=“增加末端阻尼,极其轻柔地闭合”,直接在向量场 v θ v_\theta vθ 中重塑采样轨迹的曲率,实现语言控制指令与硬件底层控制器刚度矩阵 K d K_d Kd 的“软闭环(Soft Closed-Loop)”。这种方法史无前例地允许大模型通过语义级指令,跨越不同重量级硬件底层 PID 参数的鸿沟,实现真正的零样本动态微调。
核心收益:利用云端超大流匹配解码器与语言交互构成“软闭环”,暴力抹平了底层的动力学滞后与惯量超调。这种极致的可引导性(Steerability),彻底终结了跨本体迁移必须依赖目标硬件收集真机数据进行二次微调(Fine-tuning)的历史。
代表性工作:π 0 .7 (Physical Intelligence, 2026) 是该范式的里程碑。它首次实现了仅基于轻量级双臂机器人的操作数据,零样本直接驱动拥有巨大惯量与截然不同拓扑结构的重型工业机械臂(UR5e)完成复杂的叠衣服任务。标志着条件注入技术正式从“静态标识符”走向了“动态多模态对话”的新纪元。
5.3 硬件本体无关的中间态表征与视觉引导
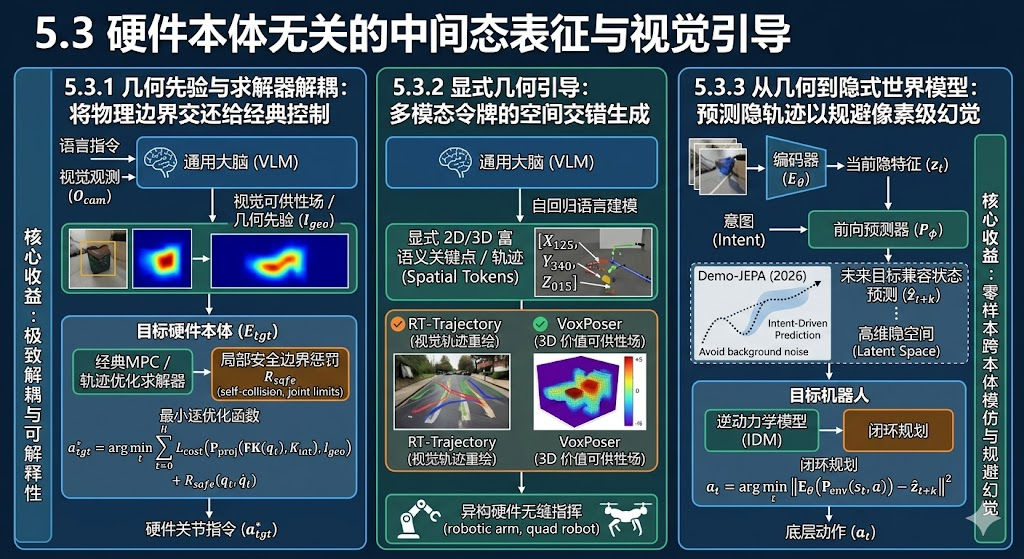
如果在 5.1 节和 5.2 节中,我们试图让网络直接输出或拟合底层的物理动作;那么在 5.3 节的流派中,研究者们选择了完全相反的哲学:“重感知,轻控制(Heavy Perception, Light Control)”。
该范式认为,与其让通用大脑(VLM)去痛苦地学习不同硬件极其碎片化的逆运动学和动力学映射,不如彻底放弃对底层控制信号(如关节角、力矩或 S E ( 3 ) SE(3) SE(3) 增量)的端到端预测。取而代之的是,大模型只需输出一种**“与具体物理躯壳完全无关的、纯粹描述物理世界状态变化的中间态表征”**。
我们可以从以下三个层级对其数学本质进行解构:
5.3.1 几何先验与求解器解耦:将物理边界交还给经典控制
通用大脑 π v l m \pi_{vlm} πvlm 仅利用其强大的常识与视觉特征提取能力,根据语言指令在观测图像上预测出任务的关键交互点或三维可供性热力图 I g e o \mathcal{I}_{geo} Igeo:
I g e o = π v l m ( O c a m , Instruction ) \mathcal{I}_{geo} = \pi_{vlm}(O_{cam}, \text{Instruction}) Igeo=πvlm(Ocam,Instruction)
对于目标本体 E t g t \mathcal{E}_{tgt} Etgt 而言,它并不需要接收任何关节指令,而是将 I g e o \mathcal{I}_{geo} Igeo 作为目标代价(Target Cost),输入到其自带的经典模型预测控制器(MPC)或基于轨迹优化的求解器中。
目标硬件上的局部优化问题可以形式化为在未来地平线 H H H 内最小化跟踪误差:
a t g t ∗ = arg min a 0 : H ∑ t = 0 H L c o s t ( Π p r o j ( FK ( q t ) , K i n t ) , I g e o ) + R s a f e ( q t , q ˙ t ) a_{tgt}^* = \arg\min_{a_{0:H}} \sum_{t=0}^H \mathcal{L}_{cost} \Big( \Pi_{proj}\big(\text{FK}(q_t), K_{int}\big), \; \mathcal{I}_{geo} \Big) + \mathcal{R}_{safe}(q_t, \dot{q}_t) atgt∗=arga0:Hmint=0∑HLcost(Πproj(FK(qt),Kint),Igeo)+Rsafe(qt,q˙t)
其中, R s a f e \mathcal{R}_{safe} Rsafe 是目标硬件的物理安全边界惩罚项(如自碰撞规避、关节限位)。这种解耦范式完美隔离了跨硬件的动力学鸿沟,并赋予了具身大模型极强的可解释性与绝对的物理安全底线。
典型工作:
VoxPoser (CoRL 2023):利用大语言模型(LLM)编写代码,直接在 3D 体素空间中生成场景的“可供性热力图(Affordance Value Maps)”。例如让“杯柄”区域呈现高价值(吸引),让“桌面障碍物”呈现负价值(排斥),下游求解器只需寻找局部梯度最优路径即可完成跨本体控制。
Grasp-Anything (ICCV 2023):利用大语言模型(LLM)进行场景与任务描述生成,并协同文本到图像扩散模型(Diffusion)与视觉分割大模型(SAM),零成本“凭空”创造出包含百万级图像与自然语言指令对应的 6-DoF 抓取边界框数据集,打通了“开放词汇描述”到“多物体抓取点”的语义映射大门。
5.3.2 显式几何引导:多模态令牌的空间交错生成
这是以 Google DeepMind (如 Gemini Robotics, RT-Trajectory) 为代表的前沿路线。大模型不再输出可能存在数值不稳定性的连续 S E ( 3 ) SE(3) SE(3) 浮点向量,而是直接利用原生的自回归语言建模能力,在视觉观测上标定 2D/3D 富语义坐标框或关键点,然后作为条件注入到下游的动作生成模型。
通过引入特殊的空间位置令牌(Spatial Tokens),网络将图像的像素空间离散化。给出一个抓取指令,模型直接生成空间令牌序列:
P k e y p o i n t s = Decoder a u t o r e g r e s s i v e ( Encode ( O c a m ) , Encode ( Instruction ) ) = [ ⟨ X 125 ⟩ , ⟨ Y 340 ⟩ , ⟨ Z 015 ⟩ , … ] P_{keypoints} = \text{Decoder}_{autoregressive}\Big( \text{Encode}(O_{cam}), \text{Encode}(\text{Instruction}) \Big) = [\langle X_{125} \rangle, \langle Y_{340} \rangle, \langle Z_{015} \rangle, \dots] Pkeypoints=Decoderautoregressive(Encode(Ocam),Encode(Instruction))=[⟨X125⟩,⟨Y340⟩,⟨Z015⟩,…]
由于这些关键点直接锚定在视觉观测的三维环境中,它们独立于任何具体的机器人基座坐标系。无论是单臂机械臂、双臂协作机器人还是四足机器狗,只要其机载小脑能够解析这些空间坐标 P k e y p o i n t s P_{keypoints} Pkeypoints,同一个 VLM 大脑就能无缝指挥这些跨物种的硬件完成任务。
核心收益 (Key Benefits)
极致的硬件解耦与即插即用 (Absolute Hardware Decoupling):由于 I g e o \mathcal{I}_{geo} Igeo是纯粹的客观物理几何表达(如“目标在这个三维坐标”或“手柄应该沿这条红色像素线移动”),它完美绕过了 L1 到 L3 的所有运动学与动力学鸿沟。只要目标硬件具备基础的寻路与闭环追踪能力,就能直接复用大模型的认知能力。
极强的可解释性与安全边界 (Interpretability and Safety):端到端模型输出的 6-DoF 增量往往如同黑盒,一旦出错难以溯源。而中间态视觉引导将大模型的意图以可视化的形式直接渲染在画面上。工程师可以直观地验证大模型的空间理解是否正确,甚至在求解器层面加入硬性的刚体碰撞检测,极大提升了工业级应用的安全下限。
充分压榨纯视觉数据的扩展红利 (Exploiting Visual Scaling Laws):大模型不需要大量昂贵的“带有精确力矩标签的真机数据”也能变强。通过学习海量的互联网人类教学视频,模型即可学会跨维复用的交互轨迹。
经典与前沿代表作:
RT-Trajectory(CoRL 2023):Google 团队的开创性工作。它将机器人的动作转化为在 2D 图像平面上“画出”任务执行的 2D 像素线(Ink-washed Trajectories)。模型只需预测这些直观的 2D 像素路径,大幅降低了跨硬件预测高维 3D 位姿的难度。
Gemini Robotics (Google DeepMind, 2024-2026):这是将“具身无关中间态”推向极致的前沿标杆。依托于 Gemini 原生的多模态交错生成能力和空间理解先验,Gemini 展现出了极强的零样本空间坐标定位能力(Spatial VLM)。Gemini 模型不再被强迫输出 SE(3) 坐标矩阵,而是直接在输入的图像观测上输出带有空间语义的 [x, y] 坐标框,标定出抓取点与需要建立的禁行区(Keep-out Zone)。这种富语义几何约束(Rich-semantic Geometric Constraints)使得同一套云端大脑,可以毫无阻碍地同时指挥单臂机器人清理桌面,或是指挥一台四足机器狗绕开该区域。
5.3.3 从几何到隐式世界模型:预测隐轨迹以规避像素级幻觉
上述两步仍然依赖于显式的像素级或几何级预测。然而,真实物理世界的遮挡与形变极其复杂,直接预测未来帧的像素极易产生致命的“视觉幻觉(Visual Hallucination)”。
2026 年的最新突破(如基于联合嵌入预测架构 Demo-JEPA 的衍生工作)提出,最高级的中间态表征不应该在像素空间,而应该在**高维隐空间(Latent Space)**中。
编码器 E θ E_\theta Eθ 将当前观测 O t O_t Ot 映射为隐特征 z t z_t zt,一个具有物理常识的前向预测器(Predictor) P ϕ P_\phi Pϕ 在隐空间中预测未来时刻的目标兼容状态 z ^ t + k \hat{z}_{t+k} z^t+k:
z ^ t + k = P ϕ ( z t , Intent ) \hat{z}_{t+k} = P_\phi(z_t, \text{Intent}) z^t+k=Pϕ(zt,Intent)
由于这是一种联合嵌入(Joint-Embedding),预测器过滤掉了环境背景中无关的高频底噪(如光照变化、机械臂外观),仅保留了与任务核心物理状态(如“杯子被倒出水”)相关的低维流形。
随后,目标机器人利用在自身无动作数据上无监督预训练的极轻量级逆动力学模型(Inverse Dynamics Model, IDM),在隐空间内闭环规划底层动作:
a t = arg min a ∥ E θ ( P e n v ( s t , a ) ) − z ^ t + k ∥ Z 2 a_t = \arg\min_a \left\| E_\theta \big( \mathcal{P}_{env}(s_t, a) \big) - \hat{z}_{t+k} \right\|_{\mathcal{Z}}^2 at=argamin
Eθ(Penv(st,a))−z^t+k
Z2
这种基于隐空间世界模拟器的范式,彻底摆脱了显式三维几何重建的计算瓶颈,并利用纯视觉的未来轨迹演示,实现了最高难度级别的跨拓扑形态 One-shot 模仿学习。
核心收益:
极简的零样本跨本体模仿 (Zero-shot Imitation):目标本体只需要“看”一眼源本体的视觉演示,并结合自身的物理互动经验(Interaction Experience),即可完成原本需要极其复杂的运动学重定向(Retargeting)才能完成的异构模仿任务。
规避像素级生成的幻觉与算力深渊:相比于利用视频扩散模型在像素级一帧帧生成未来画面,JEPA 在高维抽象的隐空间中进行预测,不仅滤除了背景光影等与任务无关的冗余信息,大幅降低了算力开销,更有效避免了生成模型中常见的违反物理规律的“像素幻觉(Pixel Hallucinations)”。
代表性工作:Demo-JEPA (2026) 通过这种解耦意图(Intent)与执行(Execution)的优雅架构,在跨越巨大形态偏移(Distribution Shift)的操作任务中,实现了超越传统同构规划器的零样本泛化。这一工作证明了基于隐空间世界模型的表示学习,能够成为连接视觉先验与机器人异构动力学最坚固的桥梁。
5.4 从人类第一视角视频到机器人的极致迁移
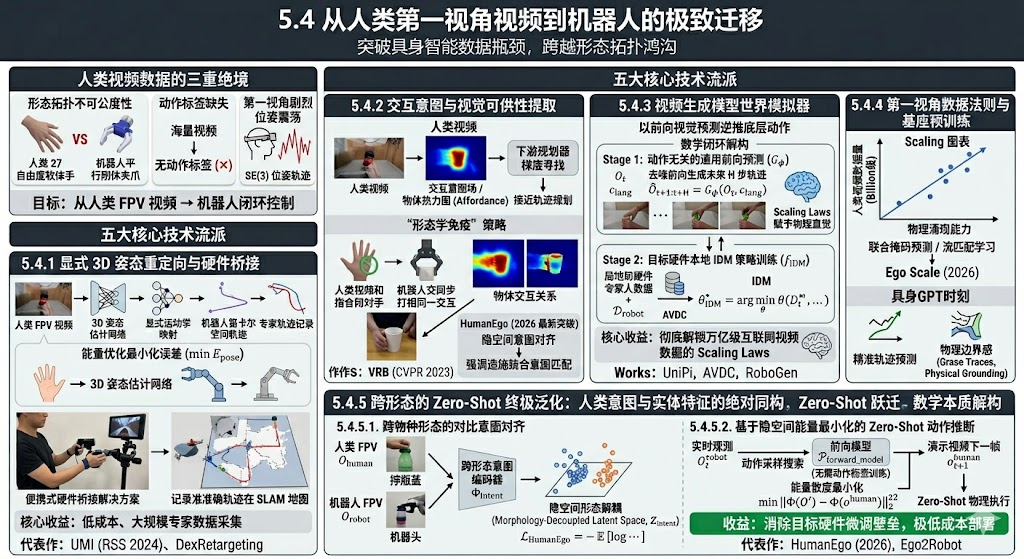
突破通用机器人数据瓶颈的最终答案,潜藏在海量的人类互联网视频(特别是第一视角视频 Egocentric Videos)中。然而,直接利用人类数据面临着三重绝境:形态拓扑的不可公度性(Incommensurability)(人类 27 自由度软体手 vs 机器人平行刚体夹爪)、动作标签的完全缺失(Action-Free)、以及第一视角相机的剧烈位姿震荡。当前学术界正通过以下四大核心技术流派,强行跨越这一最宽阔的具身鸿沟。
5.4.1 显式 3D 姿态重定向与硬件桥接
底层机制:该范式试图在三维空间中建立人手与机械手的显式运动学映射。首先利用已有的3D 姿态估计网络,从 2D 视频中恢复人类手部的 3D 关键点序列。随后,构建一个复杂的能量优化函数,最小化人类指尖姿态与机器人末端相应节点的笛卡尔空间误差。为了弥补纯算法重定向的误差,最新研究引入了“便携式硬件桥接”方案:操作员手持与真实机器人末端相同构造的夹爪执行任务,同时利用便携式相机结合 SLAM 记录精确的 SE(3) 轨迹。
核心收益:将无法直接使用的纯人类动作,高保真地“翻译”为带有物理约束的连续机器人专家轨迹,无需动用昂贵的真机遥操设备即可实现低成本、大规模的数据采集。
代表性工作:UMI (RSS 2024) 通过便携式夹爪装备,展示了将无底座约束的人类动作高精度注入真机闭环;DexRetargeting 则提供了从人手向多指灵巧手进行运动学拓扑重映射的开源通用框架。
5.4.2 交互意图与视觉可供性提取
底层机制:既然人类的手与夹爪在形态上不可公度,该范式主张“放弃映射手,转而映射手与物体的交互关系(Hand-Object Interaction, HOI)”。网络不再学习“手是怎么弯曲的”,而是从人类视频中学习“在执行任务时应在哪个像素点接触物体(Affordance)”以及“物体受力后的运动轨迹”。
核心收益:实现了策略的“形态学免疫(Morphology Immunity)”。因为无论操作者是人类还是机械臂,物理任务的核心要求是不变的。提取出的以物体为中心(Object-centric)的热力图,能直接作为下游规划器的几何约束。
代表性工作与前沿突破:除了早期的 VRB (CVPR 2023) 之外,近期备受瞩目的 HumanEgo (2026) 进一步将这一思想推向极致。HumanEgo 摒弃了脆弱的显式接触点估计,转而构建了一个跨物种的“第一视角隐式特征空间”。它通过自监督对比学习,强制让“人类在第一视角下抓取杯子”的视觉表征与“机器人在第一视角下抓取杯子”的视觉表征在隐空间中高度对齐。这种基于人类视角的强对齐,使得机器人能够直接“看懂”人类教程视频背后的深层意图,并在自身硬件限位内自主规划出最优的接近轨迹(Approach Trajectory)。
5.4.3 视频生成模型世界模拟器:以前向视觉预测逆推底层动作
这是最具 AGI 雏形的方向。它利用生成式人工智能(GenAI)强大的“脑补”能力,在隐空间中构建了一个无需显示物理建模的世界模拟器。该流派的创新在于:利用视频扩散模型(Video Diffusion Models)充当世界模拟器,随后通过逆动力学网络(IDM)强行提取底层动作。
我们可以将这一范式的数学闭环解构为两个解耦的阶段:
第一阶段:动作无关的通用前向预测 (Action-free Universal Forward Prediction)
利用在亿万级互联网视频上预训练的超大规模视频扩散模型 G ϕ G_\phi Gϕ。给定当前相机的物理观测图像 O t O_t Ot 与描述任务意图的自然语言指令 c l a n g c_{lang} clang,模型通过去噪过程,以前向自回归或并行生成的方式,预测出未来 H H H 步的物理交互画面(轨迹) O ^ t + 1 : t + H \hat{O}_{t+1:t+H} O^t+1:t+H:
O ^ t + 1 : t + H = G ϕ ( O t , c l a n g ) \hat{O}_{t+1:t+H} = G_\phi(O_t, c_{lang}) O^t+1:t+H=Gϕ(Ot,clang)
这一步赋予了系统极其强大的“视觉直觉物理学(Intuitive Physics)”常识。模型能够在像素层面预演出“手靠近杯子 -> 抓住杯柄 -> 提起水杯”的完整时空流形演变。
第二阶段:目标硬件的极轻量级逆动力学推断 (Lightweight Inverse Dynamics Inference for Target Hardware)
由于生成的未来画面 O ^ t + 1 \hat{O}_{t+1} O^t+1 仅仅是像素,无法直接驱动电机。目标硬件 E t g t \mathcal{E}_{tgt} Etgt 必须在本地利用自己独有的、极少量的带有动作标签的真机数据 D r o b o t = { ( o i , a i , o i + 1 ) } \mathcal{D}_{robot} = \{(o_i, a_i, o_{i+1})\} Drobot={(oi,ai,oi+1)},训练一个极轻量的逆动力学模型 (Inverse Dynamics Model, IDM) f I D M f_{IDM} fIDM。
IDM 的优化目标是,仅仅根据相邻两帧的视觉变化,逆推出导致该物理变化的底层动作 a t a_t at:
θ I D M ∗ = arg min θ E ( o t , a t , o t + 1 ) ∼ D r o b o t ∥ f I D M ( o t , o t + 1 ; θ ) − a t ∥ 2 2 \theta_{IDM}^* = \arg\min_{\theta} \mathbb{E}_{(o_t, a_t, o_{t+1}) \sim \mathcal{D}_{robot}} \left\| f_{IDM}(o_t, o_{t+1}; \theta) - a_t \right\|_2^2 θIDM∗=argθminE(ot,at,ot+1)∼Drobot∥fIDM(ot,ot+1;θ)−at∥22
在实际的跨本体闭环控制中,系统将视频世界模型 G ϕ G_\phi Gϕ 生成的“完美未来帧 O ^ t + 1 \hat{O}_{t+1} O^t+1”喂入目标硬件的 IDM 中,逆向解算出当前应该执行的指令 a t a_t at:
a t = f I D M ( O t , O ^ t + 1 ) a_t = f_{IDM}(O_t, \hat{O}_{t+1}) at=fIDM(Ot,O^t+1)
- 💡 核心收益 (Core Benefits):彻底解锁万亿级互联网视频数据的 Scaling Laws。 这一架构巧妙地将最难训练、最需要数据规模的“物理常识与高级规划能力(Brain)”剥离给了无需动作标签的视频生成模型;而将“如何控制具体肌肉(Cerebellum)”的低级任务,下放给了仅需几千条数据就能收敛的极轻量级 IDM。它彻底打破了机器人具身数据的天花板,使得机器人可以像人类在 YouTube 上看视频学做菜一样,实现高级语义动作的跨物种泛化。
- 🏆 代表性工作 (Representative Works): * UniPi (Universal Policies via Internet Data, MIT & Google): 最早且最具代表性的工作之一。它证明了利用文本条件视频扩散模型生成的高保真未来帧,可以作为极强的通用中间态计划(Universal Intermediate Plans),随后用一个微小的 IDM 即可让不同的机械臂完成极其复杂的未见任务。
- AVDC (Action-free Video Diffusion Controllers): 进一步将视频扩散去噪过程与控制回路结合,证明了在无需任何真机动作标签的情况下,纯粹的视频预测流形本身就包含了最优的控制梯度。
- RoboGen (CMU): 利用大规模生成式 AI(不仅是视频,还包含 3D 资产生成)为机器人自动构建仿真环境与交互轨迹,通过“生成式模拟(Generative Simulation)”倒逼实体策略收敛。
5.4.4 第一视角数据法则与基座预训练
要让上述所有算法(无论是意图提取还是视频生成)爆发出涌现能力,底层的基石是对人类第一视角数据的暴力扩展(Scaling)。
底层机制与突破:过去,第一视角数据集(如 Ego4D 或 Epic-Kitchens)虽然庞大,但主要用于行为识别(Action Recognition),缺乏控制所需的高密度空间几何监督。最新范式主张构建十亿级别的参数化模型,在海量无标注的人类第一视角视频上进行联合掩码预测(Masked Prediction)或流匹配学习,探寻视觉运动学(Visuo-motor)特有的 Scaling Laws。
- 💡核心收益与代表作: 最新提出的 Ego Scale (2026) 标志着具身领域真正意义上迎来了属于自己的“GPT 时刻”。Ego Scale 证明了,当人类第一视角视频数据的投喂量突破某个临界阈值后,模型不仅能极其精准地预测人类手部的三维时空轨迹,还会自发涌现出极强的“物理边界感(Physical Grounding)”——例如知道水杯不能穿透桌面。Ego Scale 将极其庞大杂乱的第一视角野外视频(In-the-wild Videos)提纯为了高纯度的时空物理先验(Spatio-temporal Physical Priors),下游任何异构机器人只需极少量的微调(甚至零样本),即可继承这种对三维世界深度的操作直觉,彻底打破了机器人真机数据量不足的终极诅咒。
5.4.5 跨越形态的 Zero-Shot 终极泛化:人类意图与实体特征的绝对同构
尽管前文提到的 5.4.1 至 5.4.4 节极大地释放了人类第一视角数据(Egocentric Data)的潜力,但它们本质上仍停留在**“大规模预训练 (Pre-training)”**范式。无论是视频生成还是特征表示,目标硬件在部署前依然需要依赖少量带有真实动作标签的真机数据,去微调一个逆动力学模型(IDM)或动作适配头。
然而,2026 年以 HumanEgo 为代表的最新工作,彻底颠覆了这一管线。它证明了:通过在隐空间中建立人类手部与异构机械手之间的绝对意图同构(Absolute Intent Isomorphism),具身智能可以完全不依赖任何目标机器人的真机动作标签,直接实现从人类视频到实体机器人的 Zero-Shot(零样本) 动作映射。
我们可以将这一 Zero-Shot 跃迁的数学本质解构为以下两个核心机制:
跨物种形态的对比意图对齐 (Cross-Species Contrastive Intent Alignment)
HumanEgo 的核心哲学是:无论是人手还是三指机械手,当它们执行“拧开瓶盖”这一任务时,其在物理空间中引发的**环境流形变化(Environmental Manifold Change)**是完全一致的。
模型摒弃了对动作向量 a a a 的直接回归,转而训练一个跨形态的意图编码器 Φ i n t e n t \Phi_{intent} Φintent。利用无监督的对比学习(如基于时间对比或空间对比的 InfoNCE 损失),系统强行拉近“人类手部执行任务的视频帧 O h u m a n O_{human} Ohuman”与“机械手执行相同任务的视频帧 O r o b o t O_{robot} Orobot”在隐空间中的距离:
L H u m a n E g o = − E [ log exp ( ⟨ Φ i n t e n t ( O h u m a n ) , Φ i n t e n t ( O r o b o t ) ⟩ / τ ) ∑ O − exp ( ⟨ Φ i n t e n t ( O h u m a n ) , Φ i n t e n t ( O − ) ⟩ / τ ) ] \mathcal{L}_{HumanEgo} = - \mathbb{E} \left[ \log \frac{\exp\big(\langle \Phi_{intent}(O_{human}), \Phi_{intent}(O_{robot}) \rangle / \tau \big)}{\sum_{O^-} \exp\big(\langle \Phi_{intent}(O_{human}), \Phi_{intent}(O^-) \rangle / \tau \big)} \right] LHumanEgo=−E[log∑O−exp(⟨Φintent(Ohuman),Φintent(O−)⟩/τ)exp(⟨Φintent(Ohuman),Φintent(Orobot)⟩/τ)]
当该损失函数收敛时,隐空间 Z i n t e n t \mathcal{Z}_{intent} Zintent 被彻底“形态解耦(Morphology-Decoupled)”。在这个空间里,网络“看不见”是人手还是机械手,只“看得见”物体被操作的语义意图。
基于隐空间能量最小化的 Zero-Shot 动作推断 (Zero-Shot Action Inference via Energy Minimization)
在没有任何目标硬件动作标签的情况下,如何控制机器人?HumanEgo 将控制问题转化为了一阶马尔可夫链上的能量函数优化问题(Energy-based Optimization)。
给定一段人类第一视角的操作演示视频 V d e m o = { o 1 h u m a n , o 2 h u m a n , … , o T h u m a n } V_{demo} = \{o_1^{human}, o_2^{human}, \dots, o_T^{human}\} Vdemo={o1human,o2human,…,oThuman},目标机器人通过实时采样自身的视觉观测 O t r o b o t O_t^{robot} Otrobot,并在其自带的有效动作空间 A t g t \mathcal{A}_{tgt} Atgt 中进行随机采样或基于梯度的动作搜索。
控制器的目标是找到一个当前的最优动作 a t ∗ a_t^* at∗,使得机器人执行该动作后的预测意图特征,与人类演示的下一帧意图特征之间的“能量散度(Energy Divergence)”最小:
a t ∗ = arg min a ∈ A t g t ∥ Φ i n t e n t ( P f o r w a r d _ m o d e l ( O t r o b o t , a ) ) − Φ i n t e n t ( o t + 1 h u m a n ) ∥ Z 2 a_t^* = \arg\min_{a \in \mathcal{A}_{tgt}} \left\| \Phi_{intent} \Big( \mathcal{P}_{forward\_model}(O_t^{robot}, a) \Big) - \Phi_{intent}\big(o_{t+1}^{human}\big) \right\|_{\mathcal{Z}}^2 at∗=arga∈Atgtmin
Φintent(Pforward_model(Otrobot,a))−Φintent(ot+1human)
Z2
由于前向预测模型 P f o r w a r d _ m o d e l \mathcal{P}_{forward\_model} Pforward_model 可以在无动作的纯视频上进行自监督训练,整个推理链路完全不需要目标硬件的真实动作标签 ( o t , a t ) (o_t, a_t) (ot,at),从而实现了真正的 Zero-Shot 物理执行。
- 💡 核心收益 (Core Benefits):彻底消除Human2Robot 的微调壁垒。 传统的预训练微调(Pretrain-Finetune)范式每适配一种新硬件,都需要人类工程师手动采集至少数百条真机数据。HumanEgo 的 Zero-Shot 范式打破了这一物理枷锁,只要机械臂的底层运动学求解器(IK)正常工作,模型仅凭“看一眼”人类专家的操作视频,就能直接在物理世界中复刻该动作流形,极大地加速了具身大模型在海量长尾异构硬件上的低成本部署。
- 🏆 代表性工作 (Representative Works):
- HumanEgo (2026 最新突破): 首次在极其复杂的跨形态任务(如人类肉手示范,多指灵巧手直接执行)中验证了无标签 Zero-Shot 迁移的可行性。它通过时空对比学习构建了极其鲁棒的意图表征,将人类视频直接转化为机器人的实时控制梯度。
- Ego2Robot / Any-Morphology Control: 衍生系列工作。它们进一步将隐式意图与显式的 3D 拓扑重定向(3D Topology Retargeting)结合,利用隐空间距离作为奖励函数(Reward Function),结合在线强化学习(Online RL)实现零样本下复杂接触任务的自适应微调。
6. 开放挑战:多本体数据的负迁移与流形重塑
在大语言模型(LLM)的语境中,“数据越多,模型越强”是广受认可的 Scaling Laws 铁律。然而,在具身智能领域,当试图打破数据孤岛,将数十种异构机器人(如 Open X-Embodiment 数据集中的 22 种机器人、500 多种技能)的海量数据倒入同一个 具身智能模型网络进行联合预训练时,往往不会出现预期的能力涌现,反而会爆发灾难性的负迁移(Negative Transfer)——模型在源任务和目标任务上的成功率双双暴跌。
负迁移的本质是:引入异构数据非但没有提升通用泛化能力,反而污染了网络已有的特征,导致模型在所有源任务和目标任务上的性能下降。
学术界与工业界正从算法与数据双重维度进行深度的理论干预。我们可以将其数学本质与解决方案解构为以下四个前沿方向:
6.1 梯度冲突下的灾难性均值与路由干预
问题本质:
负迁移的本质是“多对一”感知映射与“一对多”动作分布在多层感知机中发生的严重冲突。当针对同一视觉指令(例如“抓取苹果”),不同硬件由于末端执行器不同(如吸盘与二指夹爪),采取了物理背离的动作方式(比如二指夹爪会倾向从侧面抓取,而吸盘会从上方吸取,二者的轨迹数据明显差异)。在反向传播时,这两个批次的数据产生的偏导数向量(梯度, g g r i p p e r \mathbf{g}_{gripper} ggripper和 g s u c t i o n \mathbf{g}_{suction} gsuction)会发生方向上的冲突。
假设对于完全相同的视觉观测 O O O 和语义指令 c c c(例如“抓起苹果”),共享参数为 θ \theta θ 的端到端策略网络输出预测动作 a ^ = π θ ( O , c ) \hat{a} = \pi_\theta(O, c) a^=πθ(O,c)。
平行夹爪(Gripper)和吸盘(Suction)在同一个任务上的真实动作标签(Ground Truth)分别为 a g r i p p e r a_{gripper} agripper 和 a s u c t i o n a_{suction} asuction。在均方误差(MSE)损失函数下,它们各自的损失函数为:
L g r i p p e r = 1 2 ∥ π θ ( O , c ) − a g r i p p e r ∥ 2 2 \mathcal{L}_{gripper} = \frac{1}{2} \left\| \pi_\theta(O, c) - a_{gripper} \right\|_2^2 Lgripper=21∥πθ(O,c)−agripper∥22
L s u c t i o n = 1 2 ∥ π θ ( O , c ) − a s u c t i o n ∥ 2 2 \mathcal{L}_{suction} = \frac{1}{2} \left\| \pi_\theta(O, c) - a_{suction} \right\|_2^2 Lsuction=21∥πθ(O,c)−asuction∥22
根据链式法则,这两批异构数据在进行反向传播时,对网络参数 θ \theta θ 产生的偏导数(梯度向量)分别为:
g g r i p p e r = ∇ θ L g r i p p e r = ( π θ ( O , c ) − a g r i p p e r ) T ⋅ ∇ θ π θ ( O , c ) \mathbf{g}_{gripper} = \nabla_\theta \mathcal{L}_{gripper} = \Big( \pi_\theta(O, c) - a_{gripper} \Big)^T \cdot \nabla_\theta \pi_\theta(O, c) ggripper=∇θLgripper=(πθ(O,c)−agripper)T⋅∇θπθ(O,c)
g s u c t i o n = ∇ θ L s u c t i o n = ( π θ ( O , c ) − a s u c t i o n ) T ⋅ ∇ θ π θ ( O , c ) \mathbf{g}_{suction} = \nabla_\theta \mathcal{L}_{suction} = \Big( \pi_\theta(O, c) - a_{suction} \Big)^T \cdot \nabla_\theta \pi_\theta(O, c) gsuction=∇θLsuction=(πθ(O,c)−asuction)T⋅∇θπθ(O,c)
在参数空间中,如果两个梯度向量 g g r i p p e r \mathbf{g}_{gripper} ggripper 和 g s u c t i o n \mathbf{g}_{suction} gsuction 的夹角为钝角,即内积小于零:
⟨ g g r i p p e r , g s u c t i o n ⟩ < 0 \langle \mathbf{g}_{gripper}, \mathbf{g}_{suction} \rangle < 0 ⟨ggripper,gsuction⟩<0
在均方误差(MSE Loss)的优化目标下,网络试图同时满足这两个矛盾的物理指令,最终会收敛到两个动作流形的几何中点:
a p r e d = arg min a ( ∥ a − a g r i p p e r ∥ 2 + ∥ a − a s u c t i o n ∥ 2 ) ≈ a g r i p p e r + a s u c t i o n 2 a_{pred} = \arg\min_a \big( \| a - a_{gripper} \|^2 + \| a - a_{suction} \|^2 \big) \approx \frac{a_{gripper} + a_{suction}}{2} apred=argamin(∥a−agripper∥2+∥a−asuction∥2)≈2agripper+asuction
这种“均值动作”在物理世界中既无法闭合夹爪,也无法产生吸力,导致了灾难性的模式坍塌。
6.2 动作分块与两阶段解耦学习
问题本质:时序马尔可夫噪声与频域混叠
在真实物理世界中采集的遥操作(Teleoperation)数据,其底层动作存在极强的高频震荡。人类专家的微小手颤、传感器的底噪、以及通信总线的抖动,都会叠加在真实的动作意图上。
设理想的低频语义动作流形为 a s e m a n t i c ( t ) a_{semantic}(t) asemantic(t),采集到的真实动作记录为 a r e c o r d ( t ) a_{record}(t) arecord(t),高频物理底噪为 ξ n o i s e ( t ) ∼ N ( 0 , σ 2 ) \xi_{noise}(t) \sim \mathcal{N}(0, \sigma^2) ξnoise(t)∼N(0,σ2),则:
a r e c o r d ( t ) = a s e m a n t i c ( t ) + ξ n o i s e ( t ) a_{record}(t) = a_{semantic}(t) + \xi_{noise}(t) arecord(t)=asemantic(t)+ξnoise(t)
如果直接使用均方误差让具身智能大模型去拟合单步动作:
L = E t [ ∥ π θ ( O t ) − a r e c o r d ( t ) ∥ 2 2 ] \mathcal{L} = \mathbb{E}_{t} \left[ \left\| \pi_\theta(O_t) - a_{record}(t) \right\|_2^2 \right] L=Et[∥πθ(Ot)−arecord(t)∥22]
由于具身智能模型本质上擅长处理低频且平滑的宏观语义(如“拿起杯子”),这种单步拟合会迫使庞大的 Transformer 注意力矩阵去强行拟合高频物理底噪。
从频域(Fourier Domain)来看,这导致策略网络的 Lipschitz 常数激增:
∥ ∇ O π θ ( O ) ∥ → ∞ \left\| \nabla_{O} \pi_\theta(O) \right\| \to \infty ∥∇Oπθ(O)∥→∞
其物理后果是极其灾难性的:即使视觉观测 O O O 发生人眼无法察觉的单像素微小扰动,网络也会输出剧烈跳变的动作指令,导致机械臂在半空中疯狂抽搐,彻底破坏了执行的平滑性与安全性。
6.3 动态均衡与高分辨率动作语义重塑
问题本质:长尾梯度湮灭与多模态分布坍塌
跨本体数据集在“数据量”与“语义颗粒度”上存在双重病态分布。
1. 梯度的长尾湮灭:
假设数据集中包含主流机器人(如 Google RT-1,占比 90%)和小众机器人(如某实验室的自制机械臂,占比 10%)。网络的全局期望梯度由数据的边缘概率分布 P ( D ) P(\mathcal{D}) P(D) 支配:
∇ θ L g l o b a l = E ( O , a ) ∼ P ( D ) [ ∇ θ L ( O , a ) ] ≈ 0.9 ⋅ ∇ L m a i n + 0.1 ⋅ ∇ L n i c h e \nabla_\theta \mathcal{L}_{global} = \mathbb{E}_{(O, a) \sim P(\mathcal{D})} [\nabla_\theta \mathcal{L}(O, a)] \approx 0.9 \cdot \nabla \mathcal{L}_{main} + 0.1 \cdot \nabla \mathcal{L}_{niche} ∇θLglobal=E(O,a)∼P(D)[∇θL(O,a)]≈0.9⋅∇Lmain+0.1⋅∇Lniche
由于主流数据的梯度占据了绝对的主导地位,小众机器人的动作流形( ∇ L n i c h e \nabla \mathcal{L}_{niche} ∇Lniche)会在多层感知机(MLP)的权重更新中被直接“湮灭”,导致模型在小众机器人上表现为彻底的“灾难性遗忘”。
2. 一对多映射引发的模式坍塌:
自然语言的描述通常是粗粒度的模糊指令 c f u z z y = “抓住水杯” c_{fuzzy} = \text{“抓住水杯”} cfuzzy=“抓住水杯”。但在物理空间中,“从上方抓”、“从侧面抓”、“用左手抓”都是合理的。这使得条件动作分布不再是单峰的,而是一个包含 K K K 个峰值的高斯混合模型:
P ( a ∣ O , c f u z z y ) = ∑ k = 1 K w k N ( a ; μ k , Σ k ) P(a \mid O, c_{fuzzy}) = \sum_{k=1}^K w_k \mathcal{N}(a; \mu_k, \Sigma_k) P(a∣O,cfuzzy)=k=1∑KwkN(a;μk,Σk)
面对这种多峰分布,朴素的 MSE 损失函数在数学上会收敛到该分布的期望均值:
a p r e d ∗ = arg min a E a ∼ P ∥ a − a g t ∥ 2 = ∑ k = 1 K w k μ k a_{pred}^* = \arg\min_a \mathbb{E}_{a \sim P} \|a - a_{gt}\|^2 = \sum_{k=1}^K w_k \mu_k apred∗=argaminEa∼P∥a−agt∥2=k=1∑Kwkμk
致命的问题在于:多个合理动作(峰值 μ k \mu_k μk)的线性加权均值,往往落在极低概率的物理盲区。例如,“向左走( μ 1 \mu_1 μ1)”和“向右走( μ 2 \mu_2 μ2)”的平均值是“撞上前面的墙( a p r e d ∗ a_{pred}^* apred∗)”。这种语义模糊直接导致了模型输出非物理的无效动作。
6.4 预处理坐标同构投影:消除几何散度的终极防线
问题本质:机器人本体绝对坐标系下的非本质方差膨胀
前文提到,同一个物理轨迹在不同机位下会变成随机张量。我们可以用严谨的李群几何变换来揭示这种散度。
设在三维物理世界中,末端执行器执行了一个微小的位姿增量 Δ X t a r g e t ∈ S E ( 3 ) \Delta X_{target} \in SE(3) ΔXtarget∈SE(3)(例如“向前平移 1 厘米”)。
有两个形态相同的机器人 A 和 B,它们的相机均注视着该物体,但相机的安装位置(外参)存在微小差异,即世界-基座的外参分别为 T A b a s e T_{A}^{base} TAbase 和 T B b a s e T_{B}^{base} TBbase。
当这个纯粹的物理位移被记录到各自的基座坐标系下时,其动作标签 a A a_A aA 和 a B a_B aB 为:
a A = ( T A b a s e ) − 1 ⋅ Δ X t a r g e t ⋅ T A b a s e a_A = (T_{A}^{base})^{-1} \cdot \Delta X_{target} \cdot T_{A}^{base} aA=(TAbase)−1⋅ΔXtarget⋅TAbase
a B = ( T B b a s e ) − 1 ⋅ Δ X t a r g e t ⋅ T B b a s e a_B = (T_{B}^{base})^{-1} \cdot \Delta X_{target} \cdot T_{B}^{base} aB=(TBbase)−1⋅ΔXtarget⋅TBbase
尽管两者执行的是完全相同的物理交互流形,但由于伴随矩阵(Adjoint Matrix)变换 Ad T − 1 ( Δ X ) \text{Ad}_{T^{-1}}(\Delta X) AdT−1(ΔX) 的存在, a A a_A aA 与 a B a_B aB 在欧氏空间中的数值将天差地别( a A ≠ a B a_A \neq a_B aA=aB)。
如果在训练时直接将这些基于各自基座坐标系的 a g t a^{gt} agt 喂给网络,整个数据集的动作方差 Var ( D ) \text{Var}(\mathcal{D}) Var(D) 会被严重污染:
Var ( D ) = Var ( Δ X t a r g e t ) ⏟ 真实任务方差 + Var ( T b a s e ) ⏟ 外参引入的几何噪声方差 \text{Var}(\mathcal{D}) = \underbrace{\text{Var}(\Delta X_{target})}_{\text{真实任务方差}} + \underbrace{\text{Var}(T^{base})}_{\text{外参引入的几何噪声方差}} Var(D)=真实任务方差
Var(ΔXtarget)+外参引入的几何噪声方差
Var(Tbase)
网络的大量参数(容量)将被迫用来隐式地去拟合这个毫无意义的“相机安装位置方差( Var ( T b a s e ) \text{Var}(T^{base}) Var(Tbase))”。一旦外参发生变化,网络对特征空间的推断能力就会瞬间跌出泛化边界(Out-of-Distribution, OOD),导致负迁移的发生。
7 破除负迁移的前沿算法与工程策略
为了在物理级消除这种梯度干涉与分布污染,学术界与工业界正在广泛部署以下几类前沿策略:
7.1 梯度投影与冲突手术
- 梯度手术: 既然梯度冲突是负迁移的根源,算法层可以直接干预反向传播过程。借鉴多任务学习(Multi-Task Learning)中的 PCGrad (Projecting Conflicting Gradients) 思想,当检测到来自不同本体批次数据的梯度发生冲突时,强制将其中一个梯度投影到另一个梯度的法平面上:
g i ∗ = g i − ⟨ g i , g j ⟩ ∥ g j ∥ 2 g j \mathbf{g}_i^* = \mathbf{g}_i - \frac{\langle \mathbf{g}_i, \mathbf{g}_j \rangle}{\|\mathbf{g}_j\|^2} \mathbf{g}_j gi∗=gi−∥gj∥2⟨gi,gj⟩gj
这种“梯度手术”在保留了各自硬件特征的同时,去除了相互抵消的分量,强制网络在参数更新时寻找帕累托最优(Pareto Optimal)方向。 在反向传播的底层截断负分量。 - 具身混合专家系统: 摒弃共享所有权重的单体网络,引入专家路由网络 G ( S t , E u r d f ) G(S_t, E_{urdf}) G(St,Eurdf)。利用机器人本体的拓扑条件 E u r d f E_{urdf} Eurdf,将物理冲突的数据“硬隔离”到独立的子网络(Expert)通道中处理:
a p r e d = ∑ i = 1 N G ( S t , E u r d f ) i ⋅ Expert i ( S t ) a_{pred} = \sum_{i=1}^N G(S_t, E_{urdf})_i \cdot \text{Expert}_i(S_t) apred=i=1∑NG(St,Eurdf)i⋅Experti(St)
利用显式的本体拓扑特征 $ E_{urdf}$ 引导门控权重 G G G。让特定形态(如双臂协同、吸盘抓取)的轨迹数据仅被路由至专属的子网络更新权重,实现物理层面的梯度硬隔离,而在前方的 Transformer 层共享高维视觉注意力权重。
7.2 时序动作分块
放弃单步动作预测,转而在时间轴上预测未来 k k k 步的动作块(Chunk)。通过在重叠的时间窗口上对预测轨迹进行指数加权移动平均(EMA)或时序集成:
a t ∗ = ∑ k = 0 K w k ⋅ a t ( t − k ) a_t^* = \sum_{k=0}^{K} w_k \cdot a_t^{(t-k)} at∗=k=0∑Kwk⋅at(t−k)
这在数学上等效于一个天然的低通滤波器(Low-pass Filter),极大平滑了异构数据的时序噪声,规避了异构硬件在单步响应上的剧烈差异。
7.3 通用感知与本体控制的解耦两阶段学习
底层机制:传统的端到端(End-to-End)多本体联合训练存在一个致命隐患:迫使前段共享的视觉编码器(Visual Backbone)同时去迎合多种异构硬件的底层物理约束。这会导致视觉特征层在反向传播时被截然不同的动作梯度剧烈拉扯,甚至引发“表征坍塌(Representation Collapse)”。该范式主张放弃“一步到位”的联合优化,将模型生命周期严格切割为两个异步阶段:
阶段一:通用物理认知预训练: 完全剥离具体的机器人动作标签。利用海量互联网图文、人类视频以及多本体观测画面,通过掩码自编码器(MAE)、对比学习(Contrastive Learning)或视频下一帧预测(Next-frame Prediction),训练一个极其强大的视觉-语言基座模型 θ v l m \theta_{vlm} θvlm。此时,模型只负责回答“物体在哪、空间几何关系如何、世界如何运转”。
阶段二:特定本体控制的轻量级微调: 将第一阶段炼成的巨大感知大脑完全冻结(Frozen)。随后,针对每一种目标硬件,利用其专有的高质量专家数据,仅训练轻量级的参数高效微调模块(如 LoRA 适配器)或独立的动作解码头(Action Heads)。
a t g t = f ( ϕ h e a d ∣ Frozen ( θ v l m , O c a m ) ) a_{tgt} = f(\phi_{head} \mid \text{Frozen}(\theta_{vlm}, O_{cam})) atgt=f(ϕhead∣Frozen(θvlm,Ocam))
核心收益(切断向上的梯度污染): 这种架构和训练策略上的双重解耦,从根本上阻断了底层执行器的异构性向高层认知表征的“反向传播污染(Backpropagation Pollution)”。感知主干网络免受了运动学特征冲突的破坏,得以保留由亿级数据带来的强大泛化能力;而独立的动作适配器只需专注于处理极其纯粹的低维运动学映射。这不仅完美化解了参数容量的挤兑危机,更使得向全新本体迁移的边际训练成本(Marginal Training Cost)呈指数级下降。
7.4 数据层面的破局策略:流形重塑与分布均衡
这一节是通过采用各种数据处理的工程和算法等方法来缓和跨本体负迁移问题。
7.4.1 基于大模型的自动化数据清洗
负迁移往往是由低质量、标注错误的次优轨迹引发的。当前最先进的数据生产流水线,利用强大的云端 VLM 作为“裁判模型(Reward/Scoring Model)”。在数据入库前,VLM 会自动审视海量多本体轨迹,清洗掉那些包含冗余停顿、奇异点锁死、或由于人类操作失误导致的高方差数据。确保投入到 预训练池中的,全是纯度极高的高维专家直觉,从源头上遏制了动作分布的污染。
7.4.2 极度致密的语言重新对齐
底层机制: 这是化解 6.1 节中“动作分布污染”最绝妙的数据策略。为什么“吸盘”和“夹爪”抓同一个杯子会导致梯度冲突?因为它们的数据标签都极其粗糙地写着:“拿起杯子”,文本条件完全一样,动作分布却截然相反,网络必然发生灾难性均值坍塌。
该范式主张利用强大的云端 VLM(如Gemini 1.5 Pro)作为“标注员”,对所有历史历史轨迹进行高分辨率的语义重写。将标签细化为极其致密的物理描述:“使用两指平行夹爪,以 45 度俯角,捏住杯壁边缘并以 0.2m/s 的速度垂直抬升”。
核心收益: 通过在语言条件(Language Condition)中注入极其丰富的姿态、速度与形态学先验,原本模糊的“一对多(One-to-Many)”映射被强行解耦为了完美的“一对一(Injective)”映射。网络不再感到困惑,而是学会了“依据极其具体的文本定语,路由到特定的动作子空间”,从源头瓦解了梯度冲突。
7.4.3 跨域生成式数据合成与流形填补
底层机制: 异构数据混合时,常常存在“特征空洞”。比如,数据集中有大量的“人类叠衣服”和“机械臂抓杯子”,但模型从未见过“机械臂衣服”。这种联合分布 P(Embodiment,Task) 上的大面积缺失会导致流形断裂。
研究人员利用视频扩散模型在数据层面进行“移花接木”。例如,将人类叠衣服的视频,通过图像修复(Inpainting)和 ControlNet,强行将人类的手臂替换/渲染为目标机械臂的纹理与关节,“凭空”获得大量之前没有采集过的数据。
核心收益: 在不增加任何物理采集成本的前提下,人为填补了跨本体、跨任务组合的空白矩阵。这种数据级别的数据增强(Data Augmentation)使得高维特征空间变得极度连续和平滑,极大地缓解了模型在面对罕见状态组合时的“出域(Out-of-Distribution, OOD)”崩溃。
7.4.5 预处理阶段的动作-观测同构重投影
底层机制: 正如第 6.4节所述,动作输出空间的空间非对称性是导致跨本体失效的根源。在多源数据混合训练中,这种非对称性直接演变为了最致命的梯度干涉。如果不同数据集在基座坐标系下的动作标签本身就存在物理冲突,那么网络优化就注定是一个无解的零和博弈。该范式主张在数据进入神经网络进行反向传播之前,利用各数据源采集时的静态或动态相机外参 T b a s e c a m T_{base}^{cam} Tbasecam ,将异构数据集中所有宏观的绝对动作指令,统一重投影为相机坐标系下的相对视觉光流增量或相机系三维轨迹 A c a m A_{cam} Acam 。
核心收益(消解梯度拉扯): 从几何拓扑的根源上减缓了梯度干涉。通过将控制指令锚定在统一的视觉观测坐标系中,使得原本在物理世界中轨迹背离的“异构动作”,在算法的损失流形(Loss Manifold)中被强行旋转并聚类到了相同的优化方向上。真值标签(Ground Truth)的空间一致性,使得不同本体批次数据在反向传播时产生的偏导数向量夹角由钝角转为锐角( ⟨ g 1 , g 2 ⟩ > 0 \langle \mathbf{g}_{1}, \mathbf{g}_{2} \rangle > 0 ⟨g1,g2⟩>0)。这不仅彻底消除了动作模式坍塌,更使得 具身智能模型在混合训练时能够产生互相促进的协同增强效应,是实现真正 Data Scaling Laws 的关键预处理前置条件。
8. 跨本体迁移评估指标
8.1 Zero-shot/Few-shot 成功率衰减率
不看绝对成功率,而是看能力折损。公式可以表示为: 1 − ( S R T a r g e t / S R S o u r c e ) 1−(SR_{Target} /SR_{Source} ) 1−(SRTarget/SRSource)。衰减率越接近 0,说明跨本体性能越好。
8.2 微调样本效率
在目标本体上达到 Baseline 成功率所需的训练轨迹数量(Trajectories)。优秀的跨本体模型只需极少量的目标本体数据(Few Shot)甚至无需目标本体数据(Zero-Shot)即可完成微调,达到需要的成功率(99%+)。
9. 结论与未来展望 (Conclusion and Future Directions)
打破因硬件异构引发的严重数据孤岛,是具身智能通往真正“通用大模型”的必由之路。本文系统性地揭示了具身鸿沟在运动学多解性、非线性动力学以及相机感知等维度的误差级联机制,提出了 L0-L5 泛化演进层级,并全面梳理了前沿破局范式。
为了构建真正的 L5 级即插即用物理基座模型,以下三大方向亟待突破:
- 从表征对齐走向统一物理法则:模型需具备强大的物理归纳偏置。在海量参数隐空间中隐式学习重力、惯性与动量守恒,唯有理解“世界如何运转”,才能面对未知异构硬件给出合理物理推断;
- 进军高维灵巧操作深水区:打破 6-DoF 夹爪的舒适区。将知识平滑重定向至具备 20 多个主动关节、高度依赖多点摩擦规划的仿生多指灵巧手上;
- 云端预训练与端侧快速系统辨识闭环:由于物理世界的非结构化特性,具身鸿沟永远无法在云端彻底归零。端侧机器人必须具备类似动物学步的自感知机制,通过数分钟的试探闭环快速微调残存的动力学误差;
- 系统性高效数据处理管道:可以综合使用自动化精细语言标注、视频编辑、动作-观测空间对齐、通用感知标注等方法将数据处理成异构本体易于使用的高质量训练数据集,从数据源头减缓该问题。
解决具身鸿沟,不仅是算法工程师在控制与视觉交叉领域的胜利,更是将通用人工智能(AGI)稳固扎根于复杂物理世界的重要里程碑。当工业机械臂、四足巡检狗与仿生双足机器人都能即插即用地共用唯一的“云端通用大脑”时,机器人技术才算真正迎来了它的“iPhone 时刻”。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 2
2 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)