LlamaFactory v0.9.5 发布:Qwen3.5/Qwen3.6/Gemma4 全面支持,Transformers v5 兼容性正式到位

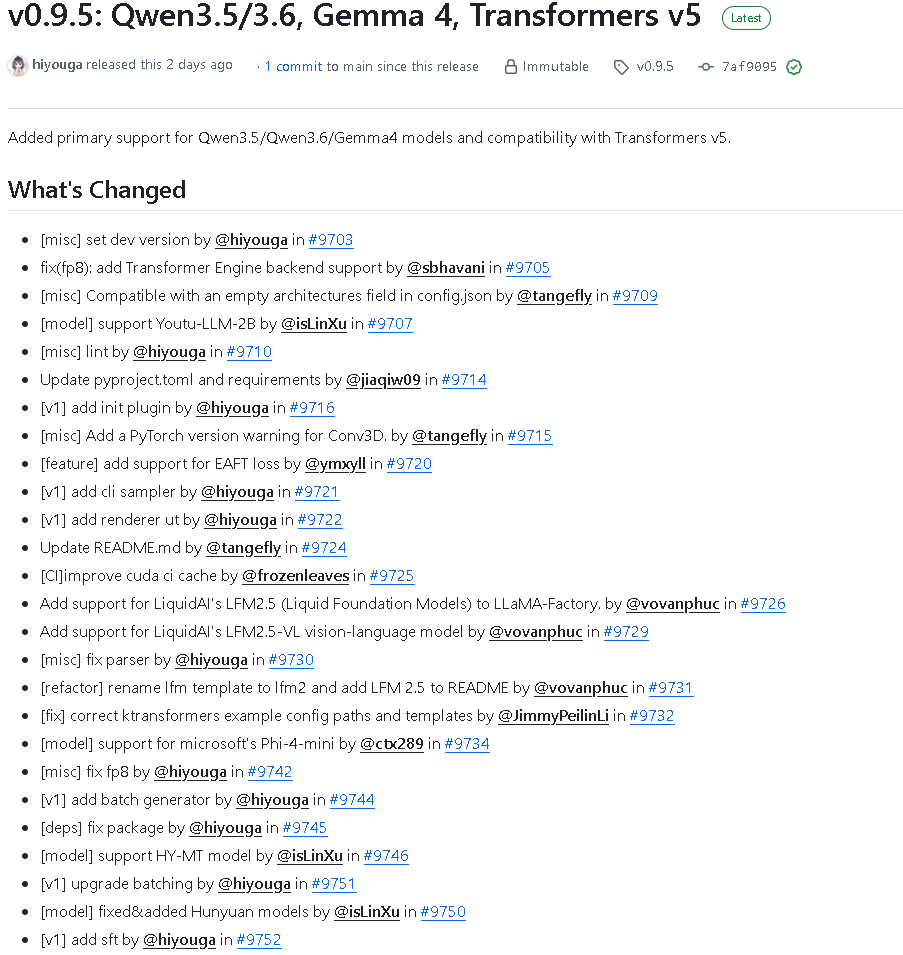

2026 年 5 月 30 日,LlamaFactory 正式发布 v0.9.5。这是一个 Immutable release,意味着该版本发布后,只有 release title 和 notes 可以被修改。从这次更新说明来看,v0.9.5 的核心方向非常明确:新增对 Qwen3.5、Qwen3.6、Gemma4 的主力支持,并完成对 Transformers v5 的兼容适配。
如果用一句话概括这个版本,那就是:模型支持继续快速扩容,v1 训练栈持续补强,分布式与多后端训练能力进一步完善,同时大量修复围绕 Qwen3.5、Gemma4、多模态、Transformers v5 的兼容问题。
下面就按照功能模块,对 LlamaFactory v0.9.5 的更新内容进行完整梳理。
1、版本核心亮点:Qwen3.5 / Qwen3.6 / Gemma4 + Transformers v5
v0.9.5 最醒目的升级,就是在版本标题中直接点明了两件事:
- Added primary support for Qwen3.5 / Qwen3.6 / Gemma4 models
- Added compatibility with Transformers v5
这意味着,这一版已经把新一代主流模型和新版 Transformers 生态的适配,推到了核心支持层面。围绕这个目标,后续整个更新列表里也能看到大量与这些模型和框架相关的补丁、功能接入与兼容性修复。
尤其是 Qwen3.5 和 Qwen3.6,这次不仅是“支持”,而是围绕模板、视觉模块、projector 路径、packing、FlashAttention、NPU、Liger Kernel、文档等多个层面进行了完善,说明其在实际训练与使用链路中的适配已经非常深入。
2、模型支持大扩容:新增与完善的模型一览
在模型支持方面,LlamaFactory v0.9.5 延续了高频扩展节奏,新增和完善的模型覆盖语言模型、多模态模型、视觉语言模型以及多种训练场景。
本次新增或增强支持的模型包括:
- Youtu-LLM-2B
- LiquidAI 的 LFM2.5
- LiquidAI 的 LFM2.5-VL 视觉语言模型
- microsoft 的 Phi-4-mini
- HY-MT
- Hunyuan 系列模型修复与补充
- youtu-vl
- MiniCPM-o-4.5
- GLM-4.7-Flash SFT
- GLM-OCR SFT
- Qwen3-Next 的 liger kernel 支持
- Aeva
- Qwen3.5 全系列模型
- Qwen3.6 模型
- Hy3-Preview
- Gemma4
- MiniCPM-V-4.6
除了模型本体的支持外,还有多项与模型生态配套的更新:
- 将 lfm template 重命名为 lfm2,并在 README 中加入 LFM 2.5
- 更新 mca supported models
- mca support qwen3.5
- mca workflow compatible with qwen-vl series
- update mcore related docker and mca supported models
这意味着 v0.9.5 不只是简单“识别模型”,而是把模型模板、示例、工作流、容器环境、生态文档和自动化流程一并跟上了。
3、围绕 Qwen3.5 / Qwen3.6 的重点适配非常密集
如果把本次更新按模型聚焦来看,Qwen3.5 无疑是最重要的适配对象之一。相关更新非常多,覆盖了从模型注册到模板、从视觉模块到训练性能、从多后端到文档修复的完整链路。
与 Qwen3.5 / Qwen3.6 直接相关的更新包括:
- Adapt Qwen3.5
- register visual part for Qwen3.5
- support Qwen3.5 all series models
- qwen3.5 projector path 修复
- support qwen3.6 models
- add qwen3 templates and fix rendering plugin
- support qwen3.5 in mca
- support Qwen3.5 with Partial RoPE and Hybrid Attention on NPU
- liger_kernel support Qwen3.5
- fix qwen3vl timestamp
- add visual.pos_embed to Qwen3-VL visual model keys
- qwen3_5 patch for neat_packing
- fix IMA when train qwen3_5 in fa2
- fix non-packing batch (bsz>1) for Qwen3.5 with flash attention
- fix qwen3_6 template doc
另外还包括与 Qwen3-Next 相关的专项增强:
- add liger kernel support for Qwen3-Next
- Add DeepSpeed Z3 leaf module for Qwen3-Next
这组更新非常能说明问题:LlamaFactory v0.9.5 对 Qwen3.5/3.6 的支持已经不只是“能跑”,而是开始进入模板、视觉、多模态、打包、训练后端、NPU、Kernel 优化、FlashAttention、文档一致性的全面成熟阶段。
4、Gemma4 支持落地,并补齐多模态细节
除了 Qwen3.5/3.6,Gemma4 也是本版本标题级重点。对应更新包括:
- gemma4
- fix gemma4 mm_token_type_ids padding
- fix projector lookup for gemma4 modules
这说明 Gemma4 的支持并不仅是模型入口层面的接入,还包括多模态 token 类型、padding 细节以及 projector 模块检索修复。对于实际训练和多模态适配来说,这些通常都属于非常关键的落地问题。
5、v1 训练栈继续进化:从插件、SFT 到量化、FSDP2、DeepSpeed、动态批处理
v0.9.5 的另一条主线,是 v1 训练体系 的持续建设。更新说明中有大量以 v1 标注的改动,表明该体系正在快速完善。
这部分新增能力包括:
- add init plugin
- add cli sampler
- add renderer ut
- add batch generator
- upgrade batching
- add sft
- init commit for v1 docs
- Add v1 LoRA / Freeze support and merge workflow
- support deepspeed
- support quantization
- add seed for training and fix gradient checkpointing
- Support meta loading for full and free
- add callbacks
- add init on rank0 for fsdp2
- support ulysses cp for fsdp2
- support resume training from checkpoint
- fix device mesh and clip_grad_norm for ulysses cp
- add deepspeed zero3 trigger for low memory usage weight loading
- fix init on meta in transformers v5
- support reward training stage
- add cuda fused moe kernel, implementing with triton
- support liger_kernel
- Add FlashAttention selection and implement normal / padding-free / dynamic batching
- Implement dynamic padding-free strategy for batching
- fix padding free with sp
- fix epoch and steps
- fix device_mesh and sp for fsdp2
从这些内容可以看出,v1 在本版本已经覆盖了训练初始化、采样、渲染测试、批处理生成、SFT、LoRA/Freeze、量化、DeepSpeed、FSDP2、恢复训练、MoE Kernel、FlashAttention、动态 batching 等多个关键模块,已经形成比较完整的训练能力拼图。
特别值得关注的是三块能力:
第一,FSDP2 支持持续加深
相关更新包括:
- support training with fsdp2
- add dpo / kto fsdp fsdp2 support
- add init on rank0 for fsdp2
- support ulysses cp for fsdp2
- support LlamaFactory SFT training by HyperParallel FSDP2 backend
- fix device mesh and clip_grad_norm for ulysses cp
- fix device_mesh and sp for fsdp2
这说明 FSDP2 已经不只是初步接入,而是扩展到了 SFT、DPO/KTO、并行策略、初始化流程和设备网格修复层面。
第二,DeepSpeed 能力继续增强
相关更新包括:
- support deepspeed
- add deepspeed zero3 trigger for low memory usage weight loading
- Add DeepSpeed Z3 leaf module for Qwen3-Next
第三,批处理和注意力优化继续深入
相关更新包括:
- upgrade batching
- Add FlashAttention selection
- implement normal / padding-free / dynamic batching
- Implement dynamic padding-free strategy for batching
- fix padding free with sp
这部分更新非常契合大模型训练对吞吐、显存和并行效率的需求。
6、Transformers v5 兼容进入实战阶段
v0.9.5 的另一个核心主题,是适配 Transformers v5。从更新清单看,这并不是一句口号,而是经过了大量分散修复之后形成的整体兼容。
与 Transformers v5 直接相关的更新包括:
- update peft, deepspeed, adapt transformers v5
- fix ut huggingface hub 429 error when transformers>=5.0.0
- remove safe_serialization arg for transformers v5 compatibility
- fix init on meta in transformers v5
- handle NotImplementedError in export_model for transformers>=5.0
- bump transformers version upperbound
此外,还有一些兼容性相关更新也属于适配过程中的关键组成部分:
- Compatible with an empty architectures field in config.json
- fix parser
- fix package
- fix fp8
- fix constants
- update constants
- docs: fix Python version requirement from 3.10 to >=3.11.0
可以说,LlamaFactory v0.9.5 在新版本 Transformers 生态下已经完成了模型加载、序列化、导出、测试、依赖边界、文档要求等多个层面的适配。
7、训练后端、分布式与加速能力继续增强
在训练基础设施方面,这一版继续加强多种后端与分布式场景的可用性。
相关更新包括:
- fix(fp8): add Transformer Engine backend support
- support using ray.remote to start distributed training
- Fix race condition in LoggerHandler during multi-GPU training
- using mp to run kernel test
- fix get ray head ip
- fix unused keys in ray example
- support all_exhausted_without_replacement in datasets.interleave_datasets
- Add ASFT
- add torch profiler callback
- use getattr for profiler attrs to support MCA TrainingArguments
- Add KTransformers AMX MoE SFT support via Accelerate
- fix moe
- Fix NPU FusedMoE and RMSNorm
- support reward model training safetensors saving
- support reward training stage
这些更新覆盖了分布式启动、日志并发安全、数据集采样策略、性能剖析、MoE、奖励模型训练、NPU 后端等多个方向,说明 v0.9.5 对复杂训练任务的支持在进一步增强。
8、多模态与插件链路修复非常密集
这一版还有一个很明显的特点,就是多模态细节修复数量很多。这说明项目正在处理越来越多真实训练和推理链路中的边缘情况。
相关更新包括:
- add visual.pos_embed to Qwen3-VL visual model keys
- fix(vllm): support mixed multimodal payloads
- support youtu-vl model
- support MiniCPM-o-4.5
- support GLM-OCR SFT
- fallback to audio_processor when feature_extractor is missing
- handle empty content list in system message
- fix IndexError in MiniCPMVPlugin process_messages when training with video
- support MiniCPM-V-4.6
- Fix MiniCPM-V-4.6 image preprocessing behavior
- set mm_projectors for omni models
- Optimize Qwen video token metadata preprocessing
- fix gdn crash when meeting dummy image
- add missing return statement in MiniCPMVPlugin.get_mm_inputs
- fix mixed multimodal payloads
- fix qwen3vl timestamp
再加上前面提到的 Gemma4、Qwen3.5 的视觉部分修复,可以看出多模态已经是这一版本非常重要的适配方向之一。
9、数据处理、工具调用与对话格式兼容进一步完善
数据链路方面,v0.9.5 也有不少很实用的修复和增强:
- support EAFT loss
- support discard history cot for multiturn
- add SGSC zero-hallucination B2B dataset (NOO-Protocol)
- SeedToolUtils.tool_extractor returns content when no tool calls found
- handle None tool_calls in OpenAI-style messages
- correct gpt_oss format_assistant
- fix mimo-v2 tool call
- Fix compatibility issue with HuggingFace Dataset Column when saving
- convert filter() to list in read_cloud_json to fix broken empty-check
这些更新说明,LlamaFactory v0.9.5 不仅在模型和训练层升级,也在面向真实数据集、OpenAI-style message 格式、tool_calls、对话式训练样本处理等方面做了较多兼容工作。
10、Packing、模板、配置与示例全面补强
围绕训练配置、模板与样例使用,本次也有不少补丁:
- rename lfm template to lfm2 and add LFM 2.5 to README
- correct ktransformers example config paths and templates
- add qwen3 templates and fix rendering plugin
- fit neat_packing & mrope model packing
- add qwen35 patch for neat_packing
- fix non-packing batch (bsz>1) for Qwen3.5 with flash attention
- fix qwen3_6 template doc
- fix constants
- update constants
- Compatible with an empty architectures field in config.json
这些改动对于实际落地非常重要。很多时候版本升级并不卡在大功能,而是卡在模板路径、打包策略、配置字段、示例不一致这些细节上。v0.9.5 在这些方面补得很细。
11、文档、README、依赖与 CI 环境同步更新
除了功能本身,这一版也同步进行了不少文档、依赖和 CI 基础设施更新。
相关内容包括:
- set dev version
- lint
- code lint
- Update pyproject.toml and requirements
- Update README.md
- assets update readme
- init commit for v1 docs
- fix typo in examples/README_zh.md
- fix Python version requirement from 3.10 to >=3.11.0
- improve cuda ci cache
- Update outdated GitHub Actions versions
- add nginx cache config for Ascend NPU CI environment
- upgrade to ROCm 7.2 base image, drop PyTorch reinstall
- update npu docker
- update npu docker
- update mcore related docker and mca supported models
- mca workflow compatible with qwen-vl series
可以看出,这一版不仅在功能层推进,还在构建、测试、CI 缓存、容器镜像和文档说明上同步完善,让整个版本更适合持续维护和部署。
12、其他重要修复汇总
还有一些虽然不属于某一个大类,但同样值得记录的重要修复与增强:
- Add a PyTorch version warning for Conv3D
- fix kernel moe patch
- fix reward model training safetensors saving
- support all_exhausted_without_replacement in datasets.interleave_datasets
- fix parser
- fix package
- fix fp8
- fix constants
- fix moe
- release v0.9.5
这些补丁共同构成了版本稳定性的底层支撑。
13、LlamaFactory v0.9.5 这次到底更新了什么?
如果把这次版本压缩成几条主线,可以归纳为以下几点:
1)主力模型支持继续向前推进
Qwen3.5、Qwen3.6、Gemma4 是这次的核心主角,同时新增和补齐了大量模型支持,包括 Youtu-LLM-2B、LFM2.5、LFM2.5-VL、Phi-4-mini、HY-MT、Hunyuan、youtu-vl、MiniCPM-o-4.5、GLM-4.7-Flash、GLM-OCR、Aeva、Hy3-Preview、MiniCPM-V-4.6 等。
2)Transformers v5 适配正式进入可用阶段
从依赖、导出、序列化、测试、meta 初始化,到 safe_serialization 参数、429 错误处理、版本边界控制,v0.9.5 围绕 Transformers v5 做了大量实战补丁。
3)v1 训练栈快速补强
插件、CLI sampler、渲染测试、batch generator、SFT、LoRA/Freeze、量化、DeepSpeed、FSDP2、恢复训练、FlashAttention、动态 padding-free batching、fused moe kernel 等能力都在继续补齐。
4)多模态和 Qwen 生态适配非常深入
视觉模块、projector、timestamp、audio_processor fallback、视频训练、dummy image、mixed multimodal payloads 等问题都得到了修复。
5)训练基础设施继续完善
包括 Ray 分布式启动、LoggerHandler 竞态修复、Profiler、KTransformers、NPU、ROCm、CI 缓存、GitHub Actions、Docker 等。
14、结语
代码地址:github.com/hiyouga/LlamaFactory
总体来看,LlamaFactory v0.9.5 是一个覆盖面极广、工程含量很高的版本。它的重点并不只是“新增几个模型”,而是围绕 Qwen3.5/Qwen3.6/Gemma4 + Transformers v5 这个核心目标,把模型支持、训练框架、分布式能力、多模态处理、模板配置、CI 环境、文档说明一起往前推进了一大步。
对于关注 LlamaFactory 的开发者来说,这个版本最值得注意的几个关键词就是:
- Qwen3.5
- Qwen3.6
- Gemma4
- Transformers v5
- FSDP2
- DeepSpeed
- FlashAttention
- 量化
- 多模态
- v1 训练栈

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 0
0 0
0- 0



 已为社区贡献49条内容
已为社区贡献49条内容

所有评论(0)