一文让你搞懂EtherCAT 与 IgH 主站工程实战
发布这篇文档的目的,不会只让大家停留在“协议定义是什么”,而是按一线实战第一视角的方式讲:为什么这样配、哪里容易错、出了问题先看什么、哪些东西上线前必须留证据,去杂留真,只给大家讲精髓,希望大家以后某一天,碰到问题回来看本文时,会发出“原来如此~”的感叹。
切记,大家读的时候可以把它当成一份现场经验整理,而不是单纯的概念笔记!
目录
- 文档定位
- EtherCAT 协议基础
- 从站控制器 ESC、AL 状态与核心寄存器
- FMMU、SyncManager、PDO 与 Mailbox
- CoE、EoE、FoE 与 SII
- Distributed Clocks 分布式时钟
- IgH EtherCAT Master 总体架构
- IgH 核心对象:Master、Slave、Domain、Datagram
- IgH 状态机与启动流程
- 拓扑扫描、热插拔与冗余
- IgH 应用开发流程与 API 使用模型
- ENI/ESI XML 配置文件
- 编译安装、平台移植与实时系统选型
- 实时网卡驱动与性能调优
- EoE 桥接与 FoE 固件升级实操
- 调试、运维与故障排查清单
- 工程交付清单与上线验收
1. 文档定位
EtherCAT 是面向工业自动化的实时以太网技术。它常用于伺服驱动、远程 IO、运动控制、机器人、数控系统和高同步采集场景。工程上真正难的不是“发出一帧 EtherCAT 报文”,而是把协议、从站配置、实时内核、网卡驱动、周期任务、状态监控和故障恢复连成一个稳定系统。
本文按照“协议原理 -> IgH 主站内部机制 -> 应用开发 -> 部署调优 -> 现场排查”的顺序组织,目标读者是需要在 Linux 或实时 Linux 上使用 IgH EtherCAT Master 的工程人员。
本文强调可落地的工程路径:先建立稳定通信,再建立可诊断、可恢复、可交付的系统边界。阅读时不需要先掌握全部源码细节,但需要理解每个配置动作对从站状态、过程映像和实时周期的影响。
我们建议第一次做主站工程的同学,不要一上来就追求“把所有轴都跑起来”。更稳的路线是先让一台从站稳定进入 OP,再把 PDO 表、WKC、AL 状态和日志链路打通。只要这条最小链路是可靠的,后面扩展到多轴、多 IO、多 domain,基本就是工程量问题;如果最小链路都没有搞清楚,后面出问题会非常难查。
实际建议大家把 EtherCAT 当成一个完整系统来看,而不是只当成通信库。它前面连着网卡、内核和实时调度,后面连着伺服、IO、安全回路和工艺动作。现场很多问题不是协议本身难,而是这些边界没有定义清楚。
2. EtherCAT 协议基础
2.1 EtherCAT 的基本通信模型
普通工业以太网协议往往把每个设备看成独立通信节点,主站分别与多个从站交换数据。EtherCAT 的核心思路不同:主站发送一帧或少量帧,帧在从站链路中依次经过每个设备,从站控制器在帧经过本设备时即时读取或写入属于自己的数据区,最后帧回到主站。
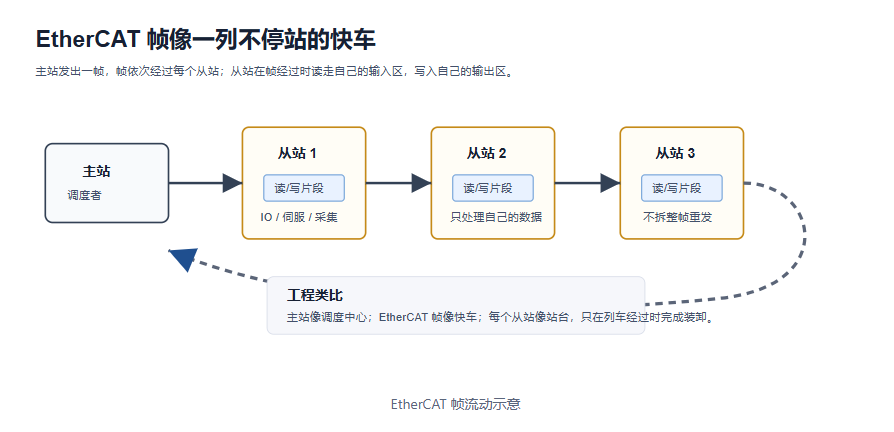
可以把 EtherCAT 总线想成一列不停站的快车。主站是调度中心,EtherCAT 帧是列车,从站是沿途站台。列车经过每个站台时,站台只装卸属于自己的货物,不会把整列车拆开重组。正因为“边经过边处理”,EtherCAT 才能把多个设备的数据交换压缩到很短的周期里。
这个模型带来几个直接结果:
- 主站通常只有一个主动调度者,网络行为容易预测。
- 从站在“帧经过时”处理数据,减少逐站请求响应带来的延迟叠加。
- 过程数据可以映射为连续逻辑地址空间,应用层读写的是过程映像,而不是逐个设备发消息。
- 网络诊断依赖工作计数 WKC、AL 状态、错误计数器、端口状态和拓扑扫描结果。
2.2 帧、Datagram 与工作计数
EtherCAT 帧中可以包含一个或多个 Datagram。Datagram 是协议栈处理的基本操作单元,它描述一次逻辑读写、物理读写、广播读写或组合读写。每个 Datagram 有命令类型、地址、长度、数据区和工作计数。
WKC 是现场排查中最常用的指标之一。它表示预期参与该 Datagram 操作的从站是否完成了对应处理。WKC 偏小通常意味着以下问题之一:
- 拓扑中某个从站未响应或链路中断。
- PDO/FMMU/SyncManager 映射不匹配。
- 从站尚未进入期望 AL 状态。
- 主站应用配置与实际从站型号、位置、别名或 Vendor/Product 信息不一致。
- 周期线程或网卡收发路径发生异常,导致帧丢失或超时。
工程建议:上线调试时不要只看应用层变量是否变化,应同时记录主站状态、domain 状态、从站状态、WKC、link state 和 AL 错误码。
我的建议是,WKC 一定要从项目第一天就开始看,不要等设备不动了才想起来。WKC 就像物流回执,回执数量不对,说明数据这趟车没有完整跑完。只看应用变量,很容易把通信问题误判成算法问题。
2.3 EtherCAT 地址模型
EtherCAT 常见地址方式包括自动递增地址、配置地址和逻辑地址。
自动递增地址适合扫描阶段。主站通过链路顺序发现从站数量和端口关系,不要求预先知道每个从站配置地址。
配置地址由主站分配或根据固定站地址/别名使用,适合对单个从站执行寄存器、EEPROM、邮箱等访问。
逻辑地址用于过程数据通信。主站把所有从站的 PDO 映射到一个连续过程映像中,通过 FMMU 把逻辑地址映射到每个从站本地物理地址。
从应用开发者视角看,逻辑地址像一条统一编号的货架。业务代码只关心“第几个格子放什么变量”,至于这个变量最终落在哪个从站、哪个 SyncManager、哪个 PDO entry,由主站配置好的映射关系完成。这个抽象很方便,但也意味着 offset 一旦错位,应用可能仍然能跑,却会读错或写错对象。
2.4 工程建模建议
做 EtherCAT 工程时,不建议一开始就从代码变量出发,而应先把网络建模成三张表:
| 表 | 内容 | 作用 |
|---|---|---|
| 拓扑表 | 从站顺序、别名、端口连接、安装位置 | 解决“我正在控制哪台设备”的问题 |
| 过程数据表 | 每个 PDO entry 的 Index/SubIndex、位宽、方向、单位、offset | 解决“每个字节代表什么”的问题 |
| 状态表 | 主站、domain、从站、业务对象的状态和错误码 | 解决“异常时如何定位”的问题 |
这三张表应当由同一套配置生成或校验,避免代码、图纸、现场接线和调试记录各自维护。工程规模较小时可以手工维护 Markdown 或表格;从站数量、轴数或 IO 点数增加后,应考虑生成式配置,把 ESI/ENI、PDO 注册表和诊断页面放到同一条数据链路里。
过程数据设计要遵循几个原则:
- 控制闭环需要的量放入 PDO,不要依赖周期内 SDO。
- 诊断量如果变化慢,可以放在监控线程中通过 SDO 读取。
- 多字节变量必须统一字节序访问方式,应用代码不要手写裸指针强转。
- 位变量要明确 bit position,不要把一个状态字在多个模块里重复解析。
- 输出数据写入前要有默认安全值,通信异常时能回到可解释状态。
3. 从站控制器 ESC、AL 状态与核心寄存器
3.1 ESC 的角色
ESC 是 EtherCAT Slave Controller,即从站控制器。它可以是专用芯片、FPGA IP、SoC 内置模块,也可以是某些从站方案中的硬件控制单元。ESC 负责处理 EtherCAT 帧、端口转发、FMMU、SyncManager、分布式时钟、邮箱缓存、事件中断和 EEPROM/SII 访问。
对主站应用开发者来说,不一定每天直接读写 ESC 寄存器,但理解 ESC 对排查问题非常重要。典型寄存器区域包括:
| 区域 | 作用 | 现场用途 |
|---|---|---|
| 类型与版本 | 标识 ESC 类型、版本和能力 | 判断从站能力和兼容性 |
| 站地址与别名 | 保存配置地址和别名地址 | 固定拓扑、替换从站、按别名匹配 |
| DL 控制/状态 | 数据链路层端口、转发和链路状态 | 判断线缆、端口、拓扑方向 |
| 事件与中断 | 表示邮箱、同步、错误等事件 | 诊断丢包、中断和状态变化 |
| 错误计数器 | 记录链路和帧错误 | 定位线缆、干扰、端口质量问题 |
| 看门狗 | 监控过程数据更新时间 | 判断主站周期是否中断 |
| EEPROM/SII | 保存从站描述信息 | 识别从站、读取 PDO/SM/FMMU 默认信息 |
| FMMU | 逻辑地址映射单元 | 过程映像映射问题排查 |
| SyncManager | 数据通道缓冲管理 | Mailbox、PDO 通道配置 |
| DC | 分布式时钟 | 同步误差、参考时钟和偏移排查 |
| AL 控制/状态 | 应用层状态机 | INIT/PREOP/SAFEOP/OP 切换诊断 |
3.2 AL 状态机
EtherCAT 从站应用层状态通常包括 INIT、PREOP、SAFEOP 和 OP。
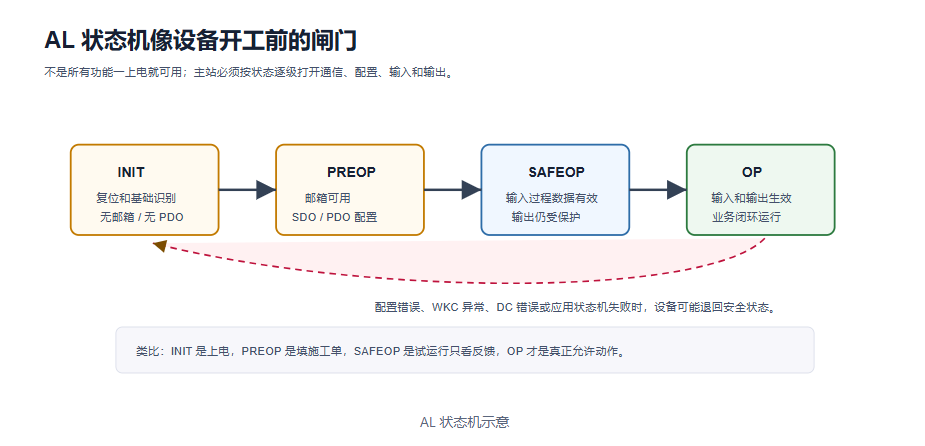
INIT 是初始化阶段。从站完成基本复位,尚未开放邮箱通信或过程数据。
PREOP 允许邮箱通信。主站通常在此阶段读取对象字典、写 SDO、下载 PDO 映射、配置 SyncManager 和 DC 参数。
SAFEOP 允许输入过程数据有效,输出过程数据仍处于安全状态。这个阶段适合验证输入、检查 WKC 和同步配置。
OP 是正常运行状态。输入和输出过程数据都生效,控制闭环开始进入正常工作。
AL 状态机可以理解成设备开工前的一道道闸门:INIT 只是上电和识别;PREOP 允许填配置单;SAFEOP 像试运行,只允许看输入反馈;OP 才是真正允许输出动作。很多现场问题的根源就是把“通信已经连上”和“设备已经允许动作”混为一谈。
这里我建议大家养成一个习惯:每次从站进不了 OP,先读 AL 状态码,再去改代码。AL 状态码是从站明确告诉你的拒绝原因,比应用层一句“启动失败”有价值得多。不要靠猜,也不要靠反复重启碰运气。
从站无法进入 OP 时,排查顺序建议如下:
- 先读取 AL 状态和 AL 状态码,不要只看应用报错。
- 检查 ESI/ENI 与实际从站固件版本是否匹配。
- 检查 PDO 映射是否与从站对象字典一致。
- 检查 SyncManager 方向、长度和类型。
- 检查初始化 SDO 是否在正确状态下写入。
- 若使用 DC,确认 reference clock、cycle time、shift time 和同步模式。
- 若是伺服驱动,再检查 CiA402 控制字状态机是否已经走到可使能状态。
4. FMMU、SyncManager、PDO 与 Mailbox
4.1 FMMU
FMMU 负责把主站看到的逻辑地址空间映射到从站内部的物理地址空间。主站应用通常不直接操作 FMMU,但它是 PDO 过程映像成立的基础。
可以把 FMMU 理解成“过程数据地址翻译器”:应用读写 domain process data 中某个 offset,IgH 通过配置好的 FMMU 让这段数据落到对应从站、对应 SyncManager、对应 PDO entry。
FMMU 错误常表现为:
- 某个 PDO 变量一直为 0 或不更新。
- WKC 与预期不一致。
- 从站能到 SAFEOP 但无法到 OP。
- 输出数据写入后设备无响应,或反馈字段错位。
4.2 SyncManager
SyncManager 是 ESC 内部的数据缓冲通道。常见用途包括:
- SM0:Mailbox 输出,主站到从站。
- SM1:Mailbox 输入,从站到主站。
- SM2:RxPDO,主站到从站的周期输出。
- SM3:TxPDO,从站到主站的周期输入。
实际编号和用途要以 ESI/ENI 和设备手册为准。许多工程问题本质上是 SyncManager 长度、方向、启用状态和 PDO 映射不一致。
4.3 PDO 与过程映像
PDO 是周期过程数据。运动控制场景中常见 PDO entry 包括控制字、状态字、模式、目标位置、目标速度、目标转矩、实际位置、实际速度、实际转矩、错误码和探针状态。
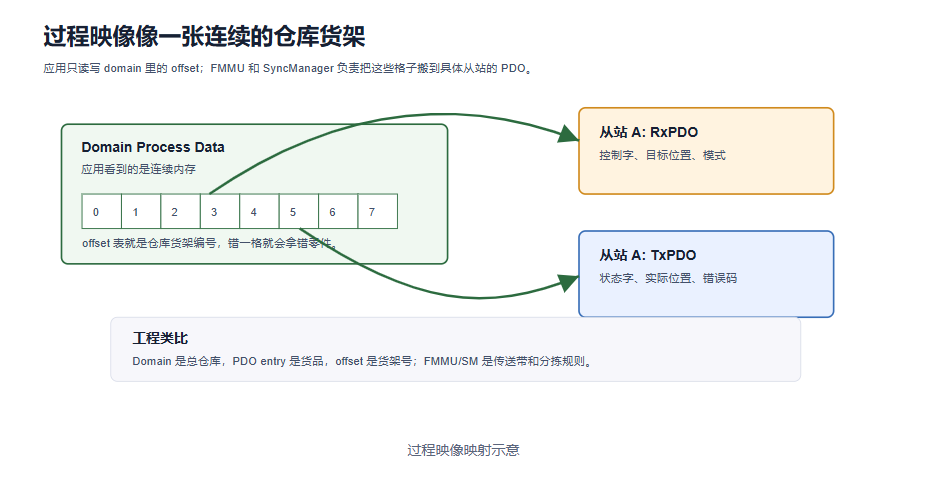
过程映像可以类比成一张连续的仓库货架。PDO entry 是货架上的货品,offset 是货架编号,FMMU 和 SyncManager 是传送带和分拣规则。应用每个周期都从固定格子拿货、放货;如果货架编号记录错了,拿到的可能仍然是“一个值”,但已经不是你以为的那个变量。
实际工程里,我建议大家把 PDO 表当成核心资产来维护。它不是附属文档,而是应用代码、电气图纸和现场调试之间的共同语言。只要 PDO 表清楚,很多看似复杂的问题都会变得可定位;PDO 表混乱,系统再小也会越调越乱。
建议把 PDO 映射管理成明确的结构表:
| 信息 | 说明 |
|---|---|
| 从站位置或别名 | 防止拓扑变化时绑定错误设备 |
| Vendor ID/Product Code | 防止替换为不兼容型号 |
| Index/SubIndex | 对象字典入口 |
| Bit length | 用于计算 offset 和 bit position |
| Direction | RxPDO 或 TxPDO |
| 应用变量名 | 与业务代码绑定 |
| 单位和缩放 | 避免脉冲、编码器值、工程单位混用 |
4.4 Mailbox
Mailbox 是非周期通信通道。它不适合高频闭环,但非常适合配置、诊断和文件传输。典型上层协议包括 CoE、EoE、FoE 和 SoE 等。
Mailbox 可以理解成设备的“办事窗口”。办事窗口可以查资料、改参数、传文件,但不适合每毫秒去排队办理一次闭环控制。闭环变量应该走 PDO,配置和维护动作才走 Mailbox。
工程上要区分周期数据和非周期数据:闭环控制变量放 PDO;初始化参数、对象字典访问和诊断放 SDO;网络透传放 EoE;固件文件传输放 FoE。
4.5 PDO offset 管理
IgH 应用最终读写的是 domain process data。offset 管理如果不清晰,问题会非常隐蔽:代码能运行,WKC 也可能正常,但变量含义已经错位。
一个实用经验是:offset 表要像电气图纸一样被维护,而不是像临时代码常量一样散落在工程里。电气图纸接错线会烧设备,PDO offset 写错也可能让控制字写到目标速度上,后果同样严重。
推荐把 PDO entry 注册和业务变量绑定拆成两层:
- 底层只保存
offset和bit_position,不写业务逻辑。 - 中间层提供读写函数,例如
read_status_word(axis)、write_target_position(axis, value)。 - 业务层只使用中间层接口,不直接访问
pd + offset。
典型注册表可以整理成如下形式:
| 字段 | 示例 | 说明 |
|---|---|---|
| slave_pos | 0:3 | 站点位置或别名 |
| index/subindex | 0x6040:00 | 对象字典入口 |
| bit_len | 16 | 位宽 |
| dir | RxPDO | 主站到从站 |
| offset | 自动填充 | 激活后由 IgH 写入 |
| bit_position | 自动填充 | 非字节对齐变量使用 |
| name | control_word | 应用变量名 |
多轴系统建议给每个轴建立独立结构体,里面只保存该轴相关 offset。这样替换轴、增减 IO 或调整 PDO 时,影响范围更容易控制。
4.6 SDO 初始化策略
SDO 初始化不要散落在业务代码里。建议把初始化命令按阶段管理:
| 阶段 | 典型内容 | 失败处理 |
|---|---|---|
| PREOP 前后 | 对象字典读取、厂商参数检查 | 失败则阻止进入运行 |
| PDO 配置阶段 | 清空映射、写入 PDO entry、恢复映射数量 | 失败则回滚或停止启动 |
| 同步配置阶段 | 操作模式、插补周期、同步模式 | 失败则禁止使能 |
| 业务参数阶段 | 限幅、比例系数、回零参数 | 失败则降级或进入维护模式 |
初始化写入完成后,应对关键对象执行回读校验。只看 SDO 写入函数返回成功不够,因为部分设备会接受写入但在状态切换时拒绝配置,或者因固件差异把参数修正为别的值。
我实际更推荐“写入 + 回读 + 记录”的方式管理关键 SDO。尤其是 PDO 映射、同步模式、插补周期、限幅参数和驱动工作模式,不要只写不查。现场最怕的是参数表面写成功,运行时才发现设备并没有按你以为的方式工作。
5. CoE、EoE、FoE 与 SII
5.1 CoE 与 SDO
CoE 是 CANopen over EtherCAT。它把 CANopen 对象字典模型用于 EtherCAT 从站。SDO 用来读取或写入对象字典项,常用于初始化参数、模式配置、PDO 映射和诊断。
SDO 使用建议:
- 初始化阶段集中完成 SDO 写入,避免在实时周期中频繁 SDO 访问。
- 对关键 SDO 写入记录返回码和中止码,便于现场定位。
- 区分 complete access 和 segmented access,不同从站支持能力不同。
- 对伺服驱动,确认厂商对象字典与 CiA402 标准对象的差异。
- 重要参数写入后,应读取回验证,尤其是 PDO 映射和同步模式。
5.2 EoE
EoE 是 Ethernet over EtherCAT。它允许在 EtherCAT Mailbox 上承载以太网帧,通常通过主站侧虚拟网卡和 Linux bridge 接入 IP 网络。
EoE 的典型用途:
- 给带 IP 服务的从站提供配置、诊断或 Web 管理通道。
- 通过 EtherCAT 网络转发少量管理流量。
- 在不增加额外网线的情况下访问从站网络功能。
EoE 不应被当成实时过程数据通道。它走邮箱、涉及分片重组和 Linux 网络栈,实时性和确定性远低于 PDO。
5.3 FoE
FoE 是 File Access over EtherCAT,常用于从站固件升级。FoE 的工程风险高于普通参数配置,因为升级失败可能导致从站无法启动或需要离线恢复。
FoE 升级建议流程:
- 确认设备支持 FoE,并确认固件文件适配型号、硬件版本和当前固件版本。
- 记录升级前从站信息、对象字典关键参数、拓扑位置和当前 AL 状态。
- 在非生产运行状态下执行升级,关闭会干扰升级的周期控制或业务流程。
- 设置合理超时,记录每个块传输状态和错误码。
- 升级后重新扫描从站,确认 Vendor/Product/Revision、对象字典和 PDO 映射仍然符合预期。
- 对批量升级,应先做单台验证,再做小批量灰度,最后进入量产流程。
5.4 SII 与 EEPROM
SII 是 Slave Information Interface,通常保存在从站 EEPROM 中。它包含从站类别、厂商信息、邮箱能力、SyncManager、PDO 和其他设备描述信息。主站扫描从站时会读取 SII,用于识别设备能力和默认配置。
现场替换从站时,如果硬件型号相同但 EEPROM 内容、Revision 或固件版本不同,主站仍可能出现配置差异。因此替换件管理要同时记录硬件型号、固件版本、ESI 文件版本和 Revision。
6. Distributed Clocks 分布式时钟
6.1 为什么需要 DC
多轴运动控制、高速采集和同步输出场景需要多个从站在同一时间基准下工作。如果每个从站只按本地晶振运行,长时间会产生漂移;如果只依赖主站周期到达时间,又会把主站调度抖动传递给从站。
DC 的作用是让 EtherCAT 网络中具备 DC 能力的从站维持统一时间基准,并通过同步信号让设备在确定时刻采样或输出。
可以把 DC 想成整条产线共用的一面高精度时钟。没有 DC 时,每台设备都拿自己的手表干活,短时间看不出问题,时间一长动作就会错开;有 DC 后,大家按同一个钟点采样和输出,主站周期的小抖动也不容易直接变成从站动作误差。
6.2 DC 的关键概念
| 概念 | 说明 |
|---|---|
| Reference Clock | 参考时钟,通常选择第一个具备 DC 能力的从站 |
| System Time | 从站内部 64 位时间 |
| Propagation Delay | 帧在链路和从站之间传播的延迟 |
| Offset | 从站时钟相对参考时钟的偏移 |
| Sync0/Sync1 | 从站周期同步输出信号 |
| Cycle Time | 同步周期,通常与主站控制周期一致或成整数倍 |
| Shift Time | 同步信号相对周期起点的偏移 |
6.3 IgH 中的 DC 使用模型
应用层通常需要完成以下步骤:
- 在从站配置阶段调用 DC 配置接口,设置 sync0/sync1 周期和偏移。
- 在周期任务中向主站提交应用时间。
- 周期性同步 reference clock。
- 周期性同步 slave clocks。
- 监控从站时钟偏差和同步状态。
DC 调试时要注意:主站周期稳定不等于 DC 稳定,DC 稳定也不代表业务控制变量正确。需要同时观测周期线程抖动、WKC、AL 状态、时钟偏差和设备业务反馈。
6.4 DC 参数落地方法
DC 参数通常要和应用控制周期一起设计。以 1 ms 控制周期为例,常见做法是让 Sync0 周期等于 1 ms,Shift Time 留出主站收发、从站处理和应用计算的时间窗口。实际取值不能只看公式,还要结合设备手册、驱动模式和现场 jitter 结果。
建议按以下步骤落地:
- 确定应用周期,例如 250 us、500 us、1 ms 或 2 ms。
- 确认所有需要同步的从站都支持 DC,并记录不支持 DC 的设备位置。
- 选择参考时钟,一般选择链路靠前、稳定在线、具备 DC 能力的从站。
- 设置 Sync0/Sync1 周期和偏移,并记录配置版本。
- 在周期线程中固定调用 application time、reference clock 同步和 slave clock 同步。
- 连续运行压力测试,记录最大偏差、周期抖动和 WKC 异常次数。
若 DC 偏差偶发尖峰,应优先排查主站线程调度、网卡路径和链路错误计数;若偏差持续漂移,应排查参考时钟选择、同步调用频率和从站固件配置。
我的建议是,DC 不要一开始就追求很漂亮的数字。先确认基础通信稳定、WKC 稳定、周期线程没有明显长尾,再看 DC 偏差。否则你看到的同步问题,可能只是调度抖动或链路质量问题的外在表现。
7. IgH EtherCAT Master 总体架构
IgH EtherCAT Master 是 Linux 上常用的开源 EtherCAT 主站实现。它由内核模块、用户态库、命令行工具和可选网卡驱动适配组成。
可以把 IgH 分成五层:
| 层级 | 作用 |
|---|---|
| 应用层 | 调用 ecrt API,创建主站、domain、从站配置和周期任务 |
| 用户态库 | 封装 ioctl,与内核主站模块交互 |
| 主站核心 | 管理 Master、Slave、Domain、Datagram 和状态机 |
| 设备抽象层 | 处理网卡绑定、帧发送、帧接收和链路状态 |
| 实时平台 | PREEMPT-RT、Xenomai、RTAI 或普通 Linux 决定实时能力上限 |
7.1 应用层和内核层的边界
应用层负责业务逻辑和周期调度,内核主站负责协议状态机、帧收发、从站配置和过程数据交换。应用层不应该绕开主站直接操作底层网卡,也不应该在周期线程中做大量非周期配置。
7.2 普通网卡驱动与适配驱动
IgH 可以通过通用网卡接口工作,也可以使用适配过的实时网卡驱动。通用接口部署简单,适合调试和一般实时要求;适配驱动减少 Linux 网络栈干扰,更适合严格周期和低抖动场景。
7.3 进程、内核模块与设备节点
典型部署中,IgH 主站由内核模块、用户态库、命令行工具和配置文件共同组成。应用程序通过用户态库调用 ecrt API,用户态库再通过设备节点与内核主站交互。内核主站负责真正的 EtherCAT 状态机、帧收发和从站配置推进。
工程部署时要明确以下边界:
- 应用进程退出不等于内核模块卸载。
- 主站被一个进程占用后,其他应用不能随意再次请求同一个 master。
- 命令行工具用于诊断时可能与运行应用共享状态,但不能替代应用自身的状态监控。
- 网卡一旦交给 EtherCAT 主站使用,就不应再被普通 IP 网络、NetworkManager 或其他服务管理。
- systemd 启停顺序要保证网卡绑定、模块加载、权限设置和应用启动有明确先后关系。
7.4 多 Master 与多 Domain
多 Master 适合物理上独立的 EtherCAT 网络,例如一条总线控制运动轴,另一条总线采集高速 IO。多 Domain 适合在同一个 Master 内拆分不同过程数据区域,例如高频闭环数据和低频诊断数据。
设计多 Domain 时要注意:
- 同一从站的 PDO 映射不要被多个模块重复解释。
- 高频 domain 尽量只放闭环必要数据。
- 低频 domain 可以放温度、诊断、扩展状态等慢变量。
- 每个 domain 都要独立监控 WKC 和 wc_state。
- 日志中要能区分 master 编号、domain 编号和从站位置。
8. IgH 核心对象:Master、Slave、Domain、Datagram
8.1 Master
Master 是主站实例,负责全局状态、线程、设备、从站列表、datagram 队列、domain 列表、状态机和统计信息。应用通过 request master 获取实例,通过 release master 释放实例。
Master 可以类比成工厂总调度室:它知道有哪些设备、线路是否通、每一趟数据列车发到哪里、回来以后是否完成了任务。
Master 生命周期可以概括为:
- 模块加载和实例创建。
- 网卡绑定和链路准备。
- 空闲线程扫描总线。
- 应用创建配置并激活主站。
- 进入 operation 阶段,周期任务驱动帧收发。
- 应用退出或异常时释放资源。
8.2 Slave
Slave 表示主站识别到的从站设备。它包含位置、别名、厂商/产品信息、端口状态、SII、邮箱能力、PDO 信息、AL 状态和 DC 信息。
应用开发时,必须明确“按位置匹配”和“按别名匹配”的差异。按位置简单,但拓扑变化时风险高;按别名更适合可维护系统,但需要现场维护别名地址。
8.3 Domain
Domain 是过程数据域。一个应用可以创建一个或多个 domain。单域模式简单,适合中小型系统;多域模式可以把不同周期、不同优先级或不同业务模块的过程数据分离。
Domain 的关键是 process data 指针和 PDO entry offset。应用应把 offset 封装到结构体或映射表中,避免在业务代码中散落魔法数字。
Domain 更像一块共享工作台。实时线程每个周期都在这块工作台上取输入、放输出;从站并不会直接出现在业务代码里,而是通过这块工作台间接交互。
8.4 Datagram
Datagram 是主站内部组织帧操作的基础对象。应用层通常不直接操作 datagram,但理解其生命周期有助于理解主站如何把配置、扫描、SDO、PDO 和状态查询排队发送。
Datagram 常见状态包括未发送、已排队、已发送、已接收、超时和错误。周期抖动、丢帧或 WKC 异常,最终都能在 datagram 层看到痕迹。
Datagram 可以理解成列车上的一张运单:写明这次要访问哪段地址、搬多少数据、期望多少从站确认。WKC 就是运单回执,回执数量不对,说明路上至少有一个环节没有按预期完成。
9. IgH 状态机与启动流程
9.1 启动总流程
IgH 主站从启动到运行一般经历以下阶段:
- 加载内核模块,创建 master 实例。
- 根据配置绑定网卡设备。
- 空闲线程发起总线扫描。
- 读取从站 SII、识别拓扑和能力。
- 应用调用 ecrt API 创建 domain 和从站配置。
- 下载初始化 SDO、配置 PDO、SyncManager、FMMU 和 DC。
- 主站激活,映射 process data。
- 从站从 INIT/PREOP/SAFEOP 切换到 OP。
- 周期线程稳定执行 receive/process/application/queue/send。
9.2 Master FSM
Master FSM 负责主站级状态推进。它在空闲和运行阶段处理扫描、状态读取、从站配置触发、DC 偏移计算、链路状态监控和异常恢复。
工程上不一定需要修改 Master FSM,但需要理解:应用层看到的“扫描中”“配置中”“从站状态变化”背后,是主站状态机分步完成的。不要期望模块加载后总线立即可用,应等待扫描和配置完成。
9.3 Slave Scan FSM
Slave Scan FSM 负责读取单个从站的身份、端口、SII、邮箱能力、PDO 信息和 DC 信息。拓扑复杂或从站响应慢时,扫描过程可能需要更长时间。
如果扫描结果与实际设备不符,应检查:线缆顺序、端口连接、从站电源、ESC 错误计数器、别名地址、SII 内容和网卡收发状态。
9.4 Slave Config FSM
Slave Config FSM 负责把从站配置到目标状态。它会执行邮箱初始化、SDO 下载、PDO 映射、SyncManager/FMMU 配置、DC 配置和 AL 状态切换。
从站卡在 SAFEOP 或 PREOP 时,重点看配置阶段日志和 AL 状态码。很多问题不是通信断了,而是从站拒绝某个配置项。
9.5 CoE/EoE/FoE/SII FSM
IgH 把邮箱协议和 SII 访问也组织成状态机。这样可以在异步收发和超时条件下逐步推进协议。理解这一点有助于避免在应用层写“同步阻塞式”的错误假设。
10. 拓扑扫描、热插拔与冗余
10.1 拓扑扫描
EtherCAT 拓扑扫描需要识别每个从站、每个端口的连接状态和上下游关系。线型拓扑最简单,分支和多端口从站会让拓扑树更复杂。
现场建议:
- 先用简单线型拓扑验证主站和从站。
- 再引入分支、冗余或复杂拓扑。
- 保存每次发布时的拓扑快照,便于现场对比。
- 对关键设备使用别名地址或明确位置约束。
10.2 热插拔
热插拔意味着主站能够检测从站消失、重新出现并尝试恢复配置。热插拔对系统设计提出额外要求:业务层必须知道某个从站当前是否可信,不能在设备离线时继续使用旧过程数据。
热插拔恢复一般包括:
- 通过 WKC、link state 或拓扑扫描发现异常。
- 标记受影响从站和 domain 状态。
- 重新扫描并匹配从站配置。
- 重新执行必要的 SDO/PDO/DC 配置。
- 进入 SAFEOP/OP 后通知业务层恢复。
10.3 线缆冗余
EtherCAT 支持通过双网卡和环形链路做线缆冗余。冗余的目标是在单点线缆断开时仍能从另一方向访问从站。
冗余不是万能容错。它不能解决从站断电、从站硬件损坏、错误配置或主站实时线程失效。使用冗余时,应把链路切换事件记录到日志,并在 HMI 或上位系统中暴露状态。
11. IgH 应用开发流程与 API 使用模型
11.1 最小应用流程
一个典型 IgH 应用可以按以下流程组织:
- 请求 master。
- 创建 domain。
- 获取 slave_config。
- 配置 PDO 和 SDO 初始化项。
- 可选:配置 DC。
- 激活 master。
- 获取 domain process data 指针。
- 启动实时周期线程。
- 周期内接收帧、处理 domain、读输入、写输出、排队 domain、发送帧。
- 退出时停止周期线程并释放 master。
伪代码如下:
master = ecrt_request_master(0);
domain = ecrt_master_create_domain(master);
sc = ecrt_master_slave_config(master, alias, position, vendor_id, product_code);
configure_pdos(sc);
configure_sdos(sc);
configure_dc_if_needed(sc);
ecrt_master_activate(master);
pd = ecrt_domain_data(domain);
while (running) {
wait_next_period();
ecrt_master_application_time(master, now_ns);
ecrt_master_sync_reference_clock(master);
ecrt_master_sync_slave_clocks(master);
ecrt_master_receive(master);
ecrt_domain_process(domain);
read_inputs(pd);
run_control_algorithm();
write_outputs(pd);
ecrt_domain_queue(domain);
ecrt_master_send(master);
}
ecrt_release_master(master);
实际工程中还要补充三类错误处理:
request_master、create_domain、slave_config、PDO 注册和activate每一步都要检查返回值。- 周期线程启动前要准备默认输出,避免刚进入 OP 时输出区仍是未初始化数据。
- 退出流程要先让业务设备进入安全状态,再停止周期线程,最后释放 master。
11.2 API 调用顺序细化
建议把应用启动分成五个阶段,每个阶段只做一类事情:
| 阶段 | 主要动作 | 输出结果 |
|---|---|---|
| 资源申请 | 请求 master、创建 domain、定位从站 | 获得主站和配置句柄 |
| 配置构建 | 注册 PDO、写入 SDO 初始化项、配置 DC | 得到完整从站配置 |
| 激活 | 激活 master、获取 process data 指针 | 过程映像可访问 |
| 运行 | 周期收发、状态监控、业务控制 | 进入稳定 OP 运行 |
| 停机 | 输出安全值、停止线程、释放资源 | 设备和主站有序退出 |
不要在激活后继续修改 PDO 映射。需要变更映射时,应停止应用、重新构建配置并重新激活。对伺服驱动一类设备,还应在应用层把“通信 OP”和“设备可使能”区分开,不能因为 EtherCAT 到 OP 就立即下发运动目标。
我建议大家在应用里明确区分三件事:EtherCAT 已经 OP、驱动已经可使能、业务允许运动。这三个条件不能混成一个布尔值。通信正常不代表机械安全,驱动可使能也不代表工艺允许运动。这个边界越早设计清楚,后期越少返工。
11.3 周期线程设计
周期线程必须只做确定性工作。建议把系统拆成三类线程:

| 线程 | 职责 | 实时要求 |
|---|---|---|
| EtherCAT 周期线程 | 收发过程数据、执行控制闭环 | 最高 |
| 监控线程 | 状态查询、报警、统计、慢速 SDO | 中等 |
| 管理线程 | UI、日志、配置文件、网络服务 | 低 |
周期线程中应避免:printf、文件写入、动态内存分配、DNS、阻塞 socket、复杂锁、长时间 SDO、数据库操作和不可控系统调用。
可以把周期线程理解成生产线鼓点。鼓点每 1 ms 敲一次,所有动作都要跟着这个节拍走。打印日志、查文件、访问数据库、等待网络回复,都是“临时插活”,一旦插进鼓点里,就会破坏整条产线节奏。
周期线程推荐固定顺序:
- 等待下一个绝对时间点,而不是简单 sleep 相对时间。
- 更新时间戳并执行 DC 同步相关调用。
- 接收帧并处理 domain。
- 读取输入,更新状态机和安全条件。
- 计算控制输出。
- 写入输出。
- queue domain 并发送帧。
- 记录轻量统计,不在实时线程中做重日志。
如果周期超时,应明确处理策略。轻微偶发超时可以记录并继续;连续超时应触发降级,例如停止使能、保持安全输出、通知上位系统并要求人工确认。
实际建议大家不要把周期线程写成“永远相信下一拍会正常”的形式。实时系统也会遇到异常,关键是异常发生时输出是否可控、日志是否够用、恢复是否有条件。一个成熟的 EtherCAT 应用,不是从不报错,而是报错时知道该停哪里、保留什么信息、怎么恢复。
11.4 状态监控
主站应用至少要周期性监控以下状态:
- Master state:从站数量、AL states、link up。
- Domain state:working counter、wc_state。
- Slave config state:online、operational、AL state。
- Link state:网卡链路是否正常。
- 业务状态:伺服状态字、错误码、限位、急停和使能状态。
没有状态监控的 EtherCAT 应用很难现场维护,因为它只能表现为“设备不动”或“应用报错”,无法定位到链路、协议、配置还是业务逻辑。
11.5 CiA402 伺服控制落地
伺服驱动常用 CiA402 状态机。应用层要把状态字解析、控制字下发、故障复位、模式设置和目标值写入拆开管理,不要把一串控制字硬编码在业务循环里。
典型使能顺序如下:
| 目标状态 | 控制动作 | 检查点 |
|---|---|---|
| Switch On Disabled | 故障复位或等待驱动准备 | 状态字无 fault |
| Ready to Switch On | 下发 shutdown 控制字 | 电源和安全输入正常 |
| Switched On | 下发 switch on 控制字 | 驱动已上电但未使能 |
| Operation Enabled | 下发 enable operation 控制字 | 可接受目标值 |
进入 Operation Enabled 之前,应先设置工作模式,例如 CSP、CSV 或 CST,并确认模式显示对象反馈一致。运动控制应用还要处理限位、急停、跟随误差、驱动报警和回零状态;这些属于业务安全条件,不应只依赖 EtherCAT 通信状态。
我的建议是,伺服使能流程一定要写成状态机,不要写成几行连续控制字。现场调试时你会遇到故障复位、急停解除、限位触发、模式切换失败、驱动报警未清除等各种分支,状态机能把这些分支表达清楚,也方便日志记录。
12. ENI/ESI XML 配置文件
12.1 ESI 与 ENI 的区别
ESI 是 EtherCAT Slave Information,描述单个从站设备能力,由设备厂商提供。
ENI 是 EtherCAT Network Information,描述一个具体网络配置,通常由配置工具根据 ESI、实际拓扑和用户配置生成。
可以这样理解:ESI 是设备说明书,ENI 是现场网络施工图。
再换一个比喻:ESI 像某个零件的产品手册,说明它有多少接口、支持哪些参数;ENI 像整台设备的装配图,说明这些零件在现场怎么摆、怎么连、哪些信号接到哪里。只拿 ESI 不能直接代表现场网络,只有 ENI 或等价的工程配置才能描述“这条总线真正长什么样”。
12.2 ENI 的核心内容
ENI 通常包含:
- 主站配置。
- 从站列表、位置、别名、Vendor ID、Product Code、Revision。
- SyncManager 配置。
- PDO 映射和 process image。
- 初始化命令,例如 SDO 写入。
- DC 和同步模式。
- 周期、任务和过程数据区域。
12.3 ENI 在工程中的价值
手写 IgH 配置适合学习和小系统;大型系统更适合从 ENI 自动生成或加载配置。原因是:
- PDO 数量多时手写 offset 容易出错。
- 厂商对象字典和 Revision 变化需要跟踪。
- 多轴系统需要统一管理 DC 和 CiA402 参数。
- 可视化配置工具更容易给现场工程师使用。
12.4 配置变更管理
ENI/ESI 不是一次性文件,而是工程配置的一部分。每次变更都应能回答三个问题:改了什么、为什么改、影响哪些从站和变量。
建议建立配置变更记录:
| 项目 | 说明 |
|---|---|
| 配置版本 | 与软件版本或设备包版本关联 |
| 拓扑摘要 | 从站数量、顺序、别名和关键型号 |
| PDO 变更 | 新增、删除、位宽变化、方向变化 |
| SDO 变更 | 初始化参数变化和默认值 |
| DC 变更 | 周期、偏移、参考时钟变化 |
| 验证结果 | 是否通过空载、带载和异常恢复测试 |
上线前应把当前配置导出并归档。现场替换设备后,应先核对 Vendor ID、Product Code、Revision 和固件版本,再允许进入 OP。对于“型号相同但 Revision 不同”的设备,应按新设备处理,不能直接假定 PDO 和对象字典完全兼容。
我建议大家不要轻视 Revision 和固件版本。很多设备外壳型号一样,PDO 默认映射、对象字典细节或者同步行为却已经变了。现场替换件如果不做版本校验,短期可能能跑,长期就是隐患。
13. 编译安装、平台移植与实时系统选型
13.1 编译安装关注点
IgH 编译安装通常涉及:
- 内核 headers 或内核源码路径。
- 是否启用用户态库。
- 是否启用命令行工具。
- 是否启用特定网卡驱动。
- 是否支持 Xenomai、RTAI 或 RTDM。
- 安装路径、模块加载、udev、systemd 和配置文件。
上线环境中,建议把以下信息写入版本记录:
| 项目 | 示例 |
|---|---|
| Linux 内核版本 | 5.x/6.x + 是否 RT 补丁 |
| IgH 版本 | 1.5.x/1.6.x 或具体 Git commit |
| 实时平台 | 普通 Linux、PREEMPT-RT、Xenomai、RTAI |
| 网卡型号和驱动 | Intel/Realtek/其他,generic 或适配驱动 |
| 从站清单 | Vendor/Product/Revision/Firmware |
| ESI/ENI 版本 | 文件名、生成工具、生成日期 |
13.2 平台选型
| 平台 | 优点 | 代价 | 适合场景 |
|---|---|---|---|
| 普通 Linux | 部署简单,生态完整 | 抖动不可控 | 学习、调试、低实时要求 |
| PREEMPT-RT | 接近主线生态,维护成本较低 | 极端最坏延迟仍受驱动和内核路径影响 | 中等实时要求、工业 PC |
| Xenomai | 硬实时能力强,实时域明确 | 内核补丁和驱动维护复杂 | 严格周期控制、运动控制 |
| RTAI | 历史方案成熟 | 生态和维护压力较大 | 旧系统维护 |
| RTOS/裸机主站 | 可控性高 | 协议栈和生态成本高 | 产品化嵌入式主站 |
13.3 移植到其他 OS 的思路
把 IgH 移植到 Linux 之外的平台,本质上是替换它依赖的操作系统服务:
- 内存分配与锁。
- 线程、定时器和等待队列。
- 网卡收发接口。
- 时间源和高精度定时。
- 文件、设备节点和配置接口。
- 用户态 API 或应用集成方式。
移植难点不只是编译通过,而是保持周期收发、超时、状态机推进和错误恢复的确定性。
13.4 服务化部署建议
现场应用通常不应依赖人工命令启动。建议用服务化方式管理 IgH 模块、网卡绑定和业务应用。
部署顺序建议如下:
- 系统启动后固定 CPU 频率、实时策略和内核参数。
- 确认 EtherCAT 网卡未被普通网络服务占用。
- 加载 IgH 相关内核模块。
- 绑定主站网卡并创建设备节点权限。
- 启动业务应用。
- 应用完成自检后进入待使能状态。
- 上位系统或人工确认后进入运行。
服务停止顺序应反过来:先让设备输出安全值和停止运动,再停止业务应用,最后释放主站或卸载模块。不能直接杀掉实时进程来代替停机流程。
实际建议大家把启动和停机都当成正式功能开发,而不是脚本凑合一下。启动流程决定系统能否稳定上线,停机流程决定异常时设备能否安全退场。越是运动控制和产线设备,越不能把“kill 进程”当成停机方案。
13.5 版本记录模板
每台设备建议保留一份运行环境记录:
| 类别 | 记录内容 |
|---|---|
| 操作系统 | 发行版、内核版本、实时补丁、启动参数 |
| 主站 | IgH 版本、编译选项、安装路径、模块列表 |
| 硬件 | CPU、主板、网卡型号、BIOS 关键设置 |
| 总线 | 从站清单、拓扑顺序、线缆长度、冗余方式 |
| 配置 | ESI/ENI、PDO 表、SDO 初始化表、DC 参数 |
| 应用 | 软件版本、控制周期、线程优先级、CPU 绑定 |
| 验证 | 性能测试结果、异常恢复测试、验收日期 |
14. 实时网卡驱动与性能调优
14.1 为什么网卡路径重要
EtherCAT 主站周期通常依赖稳定的收发时序。普通 Linux 网络栈包含中断、NAPI、软中断、协议栈、队列和调度路径,这些机制服务于通用网络吞吐,不一定适合硬实时周期。
IgH 适配网卡驱动的目标是让主站更直接地控制帧收发,减少不必要的网络栈路径和调度干扰。
14.2 调优维度
| 维度 | 操作 |
|---|---|
| BIOS/固件 | 关闭深度 C-state、动态省电、不可控睿频;固定性能模式 |
| 内核参数 | CPU isolation、IRQ affinity、nohz/rcu 参数按实时平台选择 |
| 线程调度 | 实时线程固定 CPU,设置优先级,避免迁移 |
| 内存 | mlockall,预分配,避免周期中缺页和 malloc |
| 网卡 | 独占 EtherCAT 网卡,关闭无关 offload,检查驱动路径 |
| 日志 | 周期线程不直接打印,使用环形缓冲转发 |
| 测试 | 空载、CPU 压力、内存压力、IO 压力和网络压力分别测试 |
14.3 性能指标
建议至少记录:
- 周期时间 min/avg/max。
- 最大 jitter。
- 超时次数。
- WKC 异常次数。
- AL 状态变化次数。
- 网卡收发错误计数。
- DC 偏差。
- CPU 占用和实时线程调度延迟。
14.4 性能测试方法
性能测试要覆盖空载、正常负载和压力负载。只在空载情况下运行几分钟不能证明系统可上线。
建议测试矩阵:
| 测试项 | 方法 | 观察指标 |
|---|---|---|
| 空载稳定性 | 业务算法最小化,保持 EtherCAT 周期运行 | 周期抖动、WKC、DC 偏差 |
| CPU 压力 | 非实时核运行计算压力 | 实时线程是否被影响 |
| 内存压力 | 触发内存访问和页缓存压力 | 是否出现缺页或长尾延迟 |
| IO 压力 | 磁盘日志、数据记录或文件复制 | 周期最大延迟 |
| 网络压力 | 非 EtherCAT 网卡产生普通网络流量 | IRQ 和 CPU 亲和性是否合理 |
| 业务压力 | 多轴同时运动或 IO 快速变化 | 控制稳定性和报警 |
测试结果不要只记录平均值。工程上更关心最坏值、连续异常次数和异常恢复行为。对于 1 ms 周期系统,若偶发最大延迟已经接近周期本身,即使平均值很好,也应继续排查。
我建议性能报告里一定要写最大值和连续异常次数。平均值好看没有太大意义,真正决定现场风险的是最坏情况。实时系统看的是底线,不是平均表现。
14.5 常见调优误区
- 只提高线程优先级,不处理 IRQ 亲和性和 CPU 隔离。
- 周期线程里打印大量日志,导致偶发长延迟。
- 把控制网卡和普通网络混用。
- 只测主站周期,不看从站 DC 偏差和设备反馈。
- 使用虚拟机做严格实时控制。
- 在周期内执行 SDO、文件操作或阻塞锁。
- 用平均延迟替代最坏延迟评估。
15. EoE 桥接与 FoE 固件升级实操
15.1 EoE 桥接模型
主站侧通常会出现一个 EoE 虚拟网络设备。通过 Linux bridge 可以把它与物理网卡、tap 或其他网络接口连接。实际配置要根据 IgH 版本和系统网络管理方式确定。
建议配置原则:
- EoE 用于管理,不用于控制闭环。
- 给 EoE 单独规划 IP 网段,避免和控制网络混淆。
- 限制广播和大流量,防止邮箱通道挤占控制资源。
- 把 EoE 连通性纳入系统诊断,但不要把它作为从站在线的唯一依据。
15.2 FoE 升级流程
FoE 升级可以整理成六步:
- 升级前检查:型号、固件、供电、链路、状态、版本备份。
- 准备固件:校验文件、版本兼容性、厂商说明和回滚方案。
- 进入升级状态:停止会干扰升级的业务控制。
- 执行传输:记录每个传输块、超时和错误码。
- 重启和重新扫描:确认从站重新上线。
- 升级后验证:AL 状态、对象字典、PDO、DC、业务功能。
FoE 升级一定要有失败恢复方案。对现场设备,升级失败的影响往往高于普通通信故障。
15.3 EoE 与控制周期的隔离
EoE 使用 Mailbox 通道,和 PDO 实时过程数据不是同一类负载。若 EoE 流量过大,可能导致邮箱拥塞、诊断响应变慢,甚至影响从站内部应用处理。
建议隔离方式:
- 给 EoE 单独规划管理网段,不承载生产控制数据。
- 限制从站 Web 页面、文件传输和扫描工具的使用时段。
- 在运行状态下禁用不必要的大流量诊断。
- 对 EoE 连通性做健康检查,但不要用 ping 结果判断 EtherCAT 实时通信是否健康。
- 发生 WKC 或 DC 异常时,先暂停 EoE 管理流量再复测。
15.4 FoE 升级风险控制
FoE 升级应作为维护流程,而不是普通运行功能。批量升级尤其要控制节奏。
推荐风险控制点:
| 控制点 | 要求 |
|---|---|
| 固件来源 | 文件名、版本、适配型号和校验值明确 |
| 供电 | 升级期间电源稳定,不允许中途断电 |
| 状态 | 设备处于维护状态,运动和输出已停止 |
| 备份 | 升级前记录参数、版本、拓扑和关键对象 |
| 回滚 | 明确失败后的恢复手段和责任人 |
| 验证 | 升级后重新执行通信、配置和业务测试 |
16. 调试、运维与故障排查清单
故障排查要像剥洋葱,一层一层来。最外层先看物理链路和从站数量;第二层看 AL 状态和配置;第三层看 WKC、DC 和实时周期;最里面才是业务状态机、伺服使能和工艺逻辑。跳过分层直接改业务代码,往往会把链路问题、配置问题和控制问题混在一起。
我的现场建议是:先证明“不是线的问题”,再证明“不是配置的问题”,最后再看“是不是业务逻辑的问题”。很多人一看到设备不动就改程序,结果线缆松、从站没进 OP、PDO offset 错这些基础问题反而被拖到最后才发现。
16.1 主站无法发现从站
排查顺序:
- 网卡是否被 IgH 绑定,MAC 是否配置正确。
- 模块是否加载,master 是否创建成功。
- 线缆、端口、电源和从站 RUN/ERR 指示灯。
- 是否误接交换机或普通以太网网络。
- 网卡驱动是否支持当前工作方式。
- 是否需要关闭 NetworkManager 对该网卡的管理。
可采集的信息:
| 信息 | 目的 |
|---|---|
| 网卡 MAC 和链路状态 | 确认主站绑定对象正确 |
| 内核模块加载状态 | 确认主站核心已运行 |
| 从站电源和指示灯 | 排除物理层故障 |
| 线缆连接顺序 | 排除拓扑接错 |
| 系统日志 | 查找驱动、权限和模块错误 |
16.2 从站无法进入 OP
排查顺序:
- 读取 AL 状态和错误码。
- 检查 Vendor ID、Product Code、Revision。
- 检查 ESI/ENI 与固件版本。
- 检查 SDO 初始化返回值。
- 检查 PDO 映射、SyncManager、FMMU。
- 检查 DC 配置和周期参数。
- 检查 CiA402 或厂商应用状态机。
处理原则:
- 先看 AL 错误码,再看业务日志。
- 先验证单个从站,再恢复整条总线。
- 先使用厂商默认 PDO 或最小 PDO,再逐步增加自定义映射。
- 先关闭 DC 验证基础通信,再打开 DC 验证同步。
- 对伺服设备先进入 OP,再单独处理使能和运动状态机。
16.3 WKC 不稳定
常见原因:
- 线缆质量或电磁干扰。
- 从站掉电、重启或端口错误。
- 周期线程被抢占或延迟过大。
- 网卡驱动收发路径不稳定。
- 热插拔或拓扑变化。
- Domain 映射与实际过程数据不一致。
16.4 DC 同步异常
排查顺序:
- 确认从站支持 DC。
- 确认 reference clock 选择合理。
- 检查 sync0/sync1 周期和偏移。
- 检查应用是否持续提交 application time。
- 检查同步调用顺序和周期。
- 对比主站周期 jitter 与从站时钟偏差。
16.5 伺服不使能
排查顺序:
- EtherCAT 层是否 OP。
- PDO 控制字和状态字 offset 是否正确。
- CiA402 状态机是否按顺序切换。
- 模式是否正确,例如 CSP、CSV、CST、PP、PV。
- 目标值单位和缩放是否正确。
- 使能前是否存在故障、限位、急停或安全输入。
16.6 命令行排查思路
命令行工具适合快速确认主站和从站状态。常见排查顺序是:
- 查看 master 是否存在、网卡是否绑定、链路是否 up。
- 查看从站列表,确认数量、顺序、Vendor/Product/Revision。
- 查看每个从站 AL 状态和错误码。
- 查看 PDO、SDO、SII 和对象字典信息。
- 对比应用中的配置表和实际扫描结果。
命令行排查要避免两类误判:一是应用未运行时看到的状态不能代表运行状态;二是临时手工写入 SDO 可能掩盖应用初始化流程的问题。现场排查时,应记录命令、时间、从站位置和输出摘要,便于复盘。
16.7 日志与报警设计
建议把 EtherCAT 报警分成四级:
| 等级 | 示例 | 处理 |
|---|---|---|
| 信息 | 从站数量正常、进入 OP、配置版本 | 记录 |
| 警告 | 单次 WKC 异常、轻微周期超时 | 记录并统计 |
| 错误 | 连续 WKC 异常、从站掉线、AL 错误 | 停止相关业务 |
| 致命 | 主站失效、伺服故障无法复位、急停 | 停机并要求人工处理 |
日志字段至少包括时间戳、master 编号、domain 编号、从站位置、AL 状态、WKC、错误码和业务状态。不要只记录一句“EtherCAT error”,这种日志无法支持现场定位。
16.8 异常恢复策略
异常恢复要分层处理:
- 链路短暂抖动:保持安全输出,等待连续正常周期后恢复。
- 单个非关键从站掉线:隔离相关功能,主流程降级运行。
- 关键从站掉线:停止运动或关闭输出,等待人工确认。
- 从站 AL 错误:读取错误码,必要时回到 INIT/PREOP 后重新配置。
- 伺服 fault:先停目标值,再执行故障复位,最后重新走 CiA402 使能流程。
- 主站异常:停止应用,释放 master,重新初始化整条总线。
自动恢复不能无限重试。连续失败应升级为人工处理,并保留现场状态,避免反复复位导致机械或工艺风险。
17. 工程交付清单与上线验收
EtherCAT 系统上线前,应把“能跑”升级为“可交付”。可交付意味着现场人员知道当前配置是什么、异常时看哪里、故障后如何恢复、替换设备后如何验证。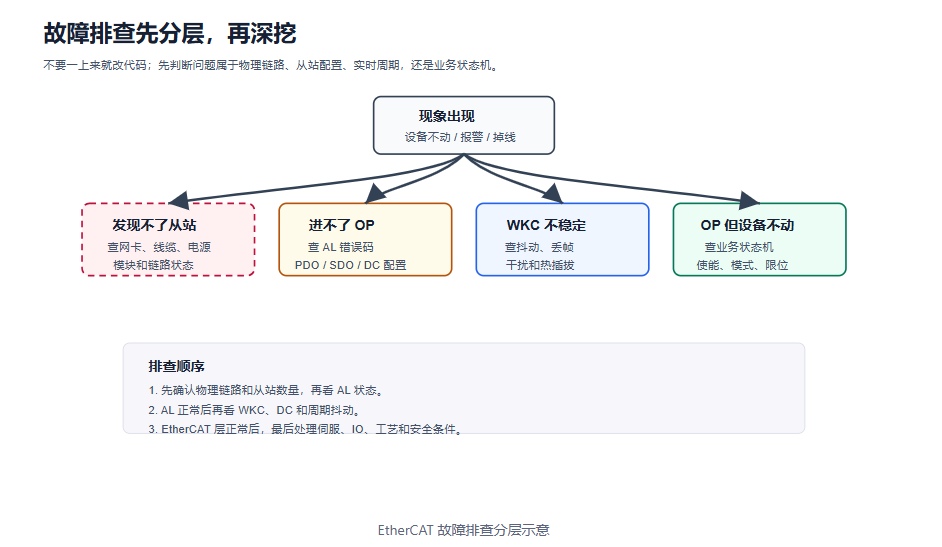
故障排查要像剥洋葱,一层一层来。最外层先看物理链路和从站数量;第二层看 AL 状态和配置;第三层看 WKC、DC 和实时周期;最里面才是业务状态机、伺服使能和工艺逻辑。跳过分层直接改业务代码,往往会把链路问题、配置问题和控制问题混在一起。
我们的现场建议是:先证明“不是线的问题”,再证明“不是配置的问题”,最后再看“是不是业务逻辑的问题”。很多人一看到设备不动就改程序,结果线缆松、从站没进 OP、PDO offset 错这些基础问题反而被拖到最后才发现。
17.1 交付资料清单
| 资料 | 内容 |
|---|---|
| 拓扑图 | 从站顺序、端口连接、安装位置、别名 |
| 从站清单 | Vendor ID、Product Code、Revision、固件版本 |
| PDO 表 | Index/SubIndex、方向、位宽、offset、单位 |
| SDO 初始化表 | 参数、写入值、写入阶段、回读要求 |
| DC 配置表 | 参考时钟、周期、Sync0/Sync1、shift time |
| 软件版本表 | 应用版本、IgH 版本、内核版本、驱动版本 |
| 性能报告 | 周期 jitter、WKC、DC 偏差、压力测试结果 |
| 故障处理表 | 常见报警、定位步骤、恢复动作 |
17.2 上线前检查
上线前至少完成以下检查:
- 所有从站能稳定扫描,数量和顺序符合拓扑图。
- 所有从站能进入 OP,AL 状态和错误码正常。
- Domain WKC 在空载和带载下稳定。
- DC 偏差满足控制要求。
- 周期线程在压力测试下没有不可接受的长尾延迟。
- 伺服轴完成上电、使能、运动、停止、故障复位和急停测试。
- IO 点完成输入变化、输出动作和断线诊断测试。
- EoE/FoE 等维护功能不会影响控制周期。
- 应用退出、重启、断电恢复和从站重启流程可控。
- 日志和报警能定位到 master、domain、从站和业务对象。
17.3 现场验收测试
验收测试应覆盖正常流程和异常流程。
| 类别 | 测试内容 | 通过标准 |
|---|---|---|
| 通信 | 启动、扫描、进入 OP、周期收发 | 无异常 WKC 和 AL 错误 |
| 实时 | 连续运行和压力运行 | 最大延迟在允许范围内 |
| 同步 | DC 偏差和同步输出 | 满足工艺或控制指标 |
| 运动 | 使能、点动、轨迹、停止 | 状态机正确,运动平稳 |
| 安全 | 急停、限位、驱动 fault | 输出进入安全状态 |
| 恢复 | 断线、从站重启、应用重启 | 按策略恢复或报警停机 |
| 维护 | 参数读取、固件升级演练 | 流程可控,有记录 |
17.4 量产与维护建议
量产系统要避免每台机器靠人工调试。建议把配置校验、从站识别、PDO 表校验和版本记录做成启动自检。自检失败时,应用应给出明确原因,例如“第 3 站 Revision 不匹配”或“Domain 0 WKC 低于预期”,而不是只提示启动失败。
我的建议是,能自动检查的东西尽量不要留给人工记忆。人工适合判断复杂现场情况,不适合每天重复核对几十个版本号和 offset。把这些检查做进启动流程,项目维护成本会明显下降。
维护阶段重点关注:
- 更换从站后的版本一致性。
- 线缆和接地导致的偶发 WKC 异常。
- 长时间运行后的温度、负载和延迟变化。
- 软件升级是否改变 PDO、SDO 或 DC 行为。
- 现场人员是否能按日志定位故障。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 2
2 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)