如何在CV中使用transformer
VIT
首先看一下谷歌的开篇论文AN IMAGE IS WORTH 16X16 WORDS: TRANSFORMERS FOR IMAGE RECOGNITION AT SCALE这篇论文是计算机视觉领域具有里程碑意义的开山之作,由谷歌研究团队(Google Research, Brain Team)在2020年提出,并在2021年的 ICLR 会议上发表。它首次成功地将自然语言处理(NLP)领域大火的 Transformer架构,直接应用到了图像识别任务中,打破了卷积神经网络(CNN)在视觉领域的长期统治地位。
CNN和注意力在归纳偏置(Inductive Bias)上的区别。
- CNN 的做法:它的局部性(Locality,认为相邻像素关系更紧密)、二维邻域结构(2D neighborhood,图像是平面的),以及平移等变性(Translation equivariance,物体在图里换个位置依然是同一个物体)这些规则,是“硬编码(baked into)”在每一层里的。也就是说,CNN 天生就懂这些图像的基本规律。
- ViT 的做法:在 ViT 里,只有最后的前馈网络(MLP层)还保留了一点点局部和平移的特性,而最核心的自注意力层(Self-attention layers)是全局的,它一视同仁地看待所有图像块之间的关系,并没有“相邻就更相关”的固有概念。
- ViT 只在两个地方用到了图像的二维结构:
- 模型最开始,把图片切成一个个小块(Patches)的时候。
- 在微调(Fine-tuning)阶段,为了适应不同分辨率的图片,去调整位置编码(Position Embeddings)的时候。
- 从零学习(Learned from scratch):除了上面这两点,ViT 在初始化时,位置编码里其实不包含任何关于图像块二维位置的信息。也就是说,图片里哪个块在左上角、哪个在右下角,它们之间的空间关系,ViT 必须在训练过程中完全从零开始学习。这也正是为什么 ViT 必须在超大规模数据集上预训练,才能发挥出超越 CNN 威力的根本原因。
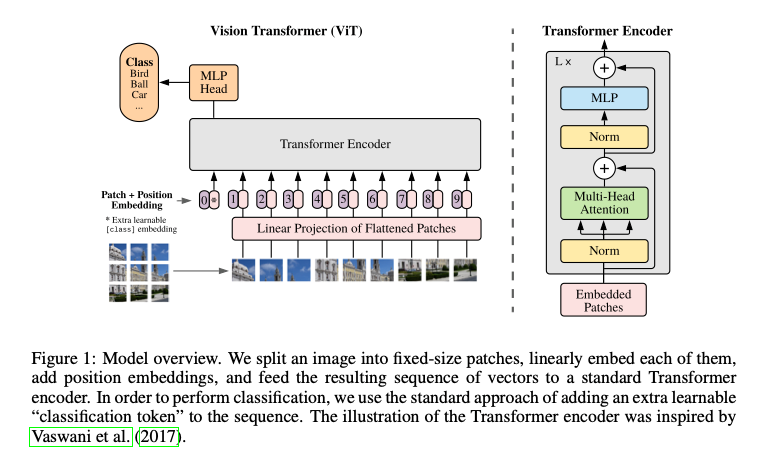
ViT 的处理流程非常直观,主要分为以下几个步骤:
- 切图成块 (Patching):
就像论文标题所说“An Image is Worth 16x16 Words”,它会将一张完整的图片(比如 224x224 像素)切割成一个个固定大小的小方块(比如 16x16 像素)。 - 展平与嵌入 (Linear Projection):
将这些小方块拉直(展平),然后通过一个线性映射,把它们转换成一个个向量(也就是 NLP 中的 Token/词向量)。 - 加入位置信息 (Position Embedding):
因为 Transformer 本身不知道这些方块的先后顺序,所以必须给每个方块加上一个“位置编码”,让模型知道每个方块在原图中的具体位置。 - 输入 Transformer 编码器:
把这一串带着位置信息的方块向量,直接输入到标准的 Transformer 编码器(Encoder)中。模型会通过“自注意力机制(Self-Attention)”来学习这些图像块之间的全局关系,最终输出分类结果。
CoAtNet
CoAtNet: Marrying Convolution and Attention for All Data Sizes
同样来自google。CoAtNet 在 ViT 之后提出的,它的出现正是为了解决 ViT 的一些短板,并证明了“CNN + Transformer 结合”往往能产生“1+1>2”的效果。CoAtNet 的设计哲学非常直观,它采用了一种“先卷积,后注意力”的串行金字塔结构:
- 前期(底层)使用 CNN(MBConv模块):
在网络的浅层,图像分辨率还很高,包含大量边缘、纹理等细节信息。CoAtNet 利用 CNN 强大的局部特征提取能力和泛化能力,快速压缩图像尺寸并提取扎实的局部特征,同时避免了过拟合。 - 后期(高层)使用 Transformer(相对注意力模块):
当特征图经过 CNN 下采样变小后,CoAtNet 切换到 Transformer。此时模型不再局限于局部,而是利用 Transformer 强大的全局建模能力,去理解整张图的宏观语义和物体间的关系,从而极大地提升了模型的精度上限。 - MBConv(Mobile Inverted Bottleneck Convolution,移动倒置瓶颈卷积)模块最早是在 MobileNetV2 中被正式提出的,后来在 EfficientNet 系列模型中得到了进一步的发扬光大和极致优化。MBConv 的设计哲学就是“扬长避短”——利用倒残差结构在高维空间保护信息不丢失,利用深度可分离卷积把高维空间的计算成本压到最低,最后利用SE注意力机制,SE 模块通过全局平均池化和全连接层,自动学习出每个通道的重要性权重,让提取出的特征更加精准。
CNN+Transfomer
Low-level 视觉领域(如图像去噪、超分辨率、低光增强、去模糊等),CNN + Transformer 的混合架构是非常主流且效果极佳的选择。
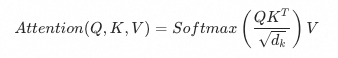
1. 三个不同的角色:Q 代表“我想找什么”,K 代表“我有什么特征”,V 代表“我实际的内容是什么”。
2. 用 Query ( Q ) 去和 Key ( K ) 做匹配,计算它们之间的相关性分数。最常用的方法是点积(Dot-Product)。点积需要对K做转置才能实现,结果矩阵里的每一个元素,正好代表了“第 i 个 Query 和 第 j 个 Key 的相似度(点积)”。
3. 缩放(Scale):将上一步得到的分数除以 dk ( dk 是 Key 向量的维度)。
- 为什么要除以根号 dk? 因为当维度很大时,点积的结果数值会变得非常大,导致后续的 Softmax 函数进入“饱和区”(梯度趋近于0),模型就学不动了。除以根号 dk 可以把数值拉回到一个合理的范围,保证训练稳定。
- 现在更常用的做法是先把q和k在最后一个维度L2归一化,这样之后再做内积就转化为了余弦相似度,避免某个向量的模长特别大,它的点积分数就会虚高,可能会干扰 Softmax 的分配,导致训练不稳定。内积之后乘scale,把scale参数作为一个可学习的参数
4. 归一化(Softmax):对缩放后的分数应用 Softmax 函数。它会把所有的分数转换成 0 到 1 之间的概率值,并且所有分数的总和为 1。
5.用算出来的注意力权重,去对 Value ( V ) 进行加权求和。
| 算法 | 关键代码 |
|
SwinIR 传统的 Transformer 计算全局注意力太慢,SwinIR 把图片切成一个个小窗口,只在窗口内算注意力,再通过移位窗口让信息跨窗口交流。 |
|
|
Resrormer 注意力计算从“空间维度”搬到了“通道维度”。计算复杂度是线性的,处理高分辨率图像非常快。 |
1x1通道变3倍,chunk得到qkv,rearrange分离出head,合并hw,b (head c) h w -> b head c (h w),计算得到的attn是[b, head, c, c],表明了通道之间的注意力,得到attn后softmax,再和v做内积,最终得到的 out 形状为: |
|
XRestormer 通道注意力 + 空间注意力 (缝合版) |
qkv的得到和Resrormer是相同的 都是划分块,q和kv有区别。q不重叠,可以使用rearrange,kv使用unfold。内积之前没有归一化,只使用scale参数,,计算得到的attn是[b, head, n, n], |
|
RetiNexFormer 用一个光照引导的 Transformer(IGT),利用光照信息去指导图像的增强和去噪。 |
x先合并hw qkv通过全连接得到,每个的通道数都是dim_head * heads,之后再rearrange,分离最后一个通道,得到b h n d,qkv全部交换最后两个通道,得到b h d n,之后就是归一化,softmax,内积。内积时对v按照光照图进行加权。最终的结果和位置编码相加,因为这里的位置编码是由分组卷积得到的。 没有分块,得到的attn是 |

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 0
0 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)