第1课:LangSmith整体认知【是什么、能做什么、LLMOps核心价值与应用场景】

文章目录
一、开篇导读
欢迎来到《LangSmith从入门到精通》专栏的第1节课。作为整个专栏的开篇之作,本节课将为你构建对LangSmith的完整认知框架。
在开始之前,请你思考一个问题:当你开发一个基于大语言模型(LLM)的应用时,是否遇到过以下困扰——模型输出的结果时好时坏,完全不知道原因是什么?链路调用复杂到难以调试,出了问题不知道从哪排查?想优化Prompt却只能凭感觉盲目尝试?多个版本的提示词和模型参数无法有效管理和对比?如果这些问题你至少遇到过1-2个,那么LangSmith正是你需要的工具。
本节课将从零开始,用最通俗的语言为你讲解LangSmith是什么、它能解决什么问题、它的底层工作原理是什么,以及它在LLMOps体系中的核心价值。我们会通过一个完整的入门案例,让你亲身体验LangSmith带来的链路追踪能力。
本节课你将收获:
- 理解LLMOps的核心概念及其与大模型应用的关系
- 掌握LangSmith的定位、核心功能和技术架构
- 理解Trace、Run、Project等核心概念的本质
- 完成LangSmith账号注册和环境配置
- 运行第一个带LangSmith追踪的完整项目
- 学会在LangSmith面板查看和分析链路数据
- 了解LangSmith在企业级场景下的最佳实践
二、知识前置铺垫
在正式接触LangSmith之前,我们需要先理解几个前置概念。这些概念是理解LangSmith价值的基础。
2.1 什么是大模型应用开发中的“可观测性”
可观测性(Observability) 这个词原本来自云计算和分布式系统领域。简单来说,就是一个系统的内部状态能够通过外部输出被准确推断的程度。
举个生活化的例子:你开车时,仪表盘上的速度表、油量表、发动机故障灯就是汽车的可观测性体现。如果没有这些仪表,你只能凭感觉猜测车况,那就处于“不可观测”的状态。
在大模型应用开发中,可观测性意味着:
- 你能看到每一次模型调用传入的Prompt是什么
- 你能知道模型返回的具体内容是什么
- 你能追踪整个调用链路(从用户输入到最终输出经过了哪些环节)
- 你能量化每次调用的耗时、Token消耗、成本等指标
- 你能对比不同版本Prompt的效果差异
没有可观测性,大模型应用就像一个黑盒,你往里扔问题,它往外吐答案,中间发生了什么完全未知。这在开发阶段或许还能忍受,但一旦进入生产环境,面对成百上千的用户请求,没有可观测性将导致你无法定位问题、无法优化性能、无法控制成本。
2.2 LLMOps的提出背景
LLMOps(Large Language Model Operations) 是近年来随着大模型爆发而兴起的一个新领域。它借鉴了传统机器学习中的MLOps理念,但针对大语言模型的特性做了专门调整。
传统的MLOps专注于管理机器学习模型的训练、部署、监控全生命周期。但大模型应用有完全不同的特点:
特点一:Prompt即代码
在传统机器学习中,模型训练完成后参数就固定了。但在大模型应用中,你不需要训练模型(除非做微调),你写的是Prompt。Prompt的质量直接决定应用效果,而Prompt的编写和优化过程充满不确定性。
特点二:输出非确定性
传统程序,输入1+1,输出永远是2。但大模型每次调用结果都可能不同(即使temperature=0也不能保证100%确定)。这意味着你的测试用例今天通过明天可能就不通过。
特点三:链路复杂性
一个真实的大模型应用通常包含多个组件:
- 用户输入预处理
- Prompt模板渲染
- 大模型调用
- 输出后处理
- 外部工具调用(如搜索引擎、数据库、API)
- RAG检索增强
- Agent的思考循环
这些组件串联起来形成复杂链路,任何一个环节出问题都会影响最终输出。
特点四:评估困难
传统程序判断输出是否正确很简单(断言是否相等)。但大模型的输出是自然语言,“正确答案”可以有无数种表达方式。如何自动化评估模型输出质量是个巨大挑战。
LLMOps正是为了解决这些问题而诞生的。它提供了一整套方法论和工具链,帮助开发者构建可靠、可观测、可优化的大模型应用。
2.3 LangChain生态中的定位
LangChain 是目前最流行的LLM应用开发框架。它提供了标准化的组件抽象(如ChatModel、PromptTemplate、OutputParser等)和丰富的内置工具(如文档加载器、向量数据库集成、Agent框架等)。
但LangChain本身只解决了“如何构建”的问题,没有解决“如何调试、如何评估、如何监控”的问题。这就好比给你一套乐高积木,你可以搭出各种造型,但你不知道哪块积木松了、哪个接口接触不良。
LangSmith 正是LangChain官方推出的配套可观测性平台。它的定位是:
- 为LangChain应用提供开箱即用的链路追踪能力
- 提供可视化的调试和分析界面
- 内置数据集管理和模型评估功能
- 支持生产环境监控和告警
简单来说,LangChain负责“造车”,LangSmith负责给车上装仪表盘、行车记录仪和诊断系统。
三、核心概念精讲
现在进入正题,我们逐层拆解LangSmith的核心概念。
3.1 LangSmith是什么
官方定义:LangSmith是一个用于构建、调试、评估和监控基于LLM的应用程序的平台。
我的理解:LangSmith就是大模型应用的“鹰眼系统”——它能让你看清应用内部发生的每一件事,记录下每一次调用的完整上下文,并提供工具帮你分析和优化应用表现。
LangSmith不是本地工具,而是一个SaaS云服务平台。你只需要在代码中集成LangSmith的SDK,所有追踪数据就会被自动上传到LangSmith云端,然后你通过Web界面查看和分析。
核心能力矩阵:
| 能力维度 | 具体功能 | 解决什么问题 |
|---|---|---|
| 链路追踪 | 自动记录每次调用的输入、输出、耗时、Token消耗 | 不知道链路中发生了什么 |
| 调试分析 | 可视化展示调用树,支持筛选、搜索、对比 | 难以定位问题根源 |
| 数据集管理 | 创建测试集,导入导出数据,版本管理 | 没有标准化的测试用例 |
| 模型评估 | 运行评估任务,对比不同版本效果 | 无法量化模型表现 |
| 生产监控 | 实时监控线上请求,设置告警规则 | 生产环境出问题无法感知 |
3.2 Trace(追踪)与Run(运行)
这两个概念是LangSmith最核心的抽象,必须彻底理解。
Trace(追踪) 代表一次完整的应用调用。从用户发起请求到系统返回响应的全过程,被记录为一个Trace。一个Trace可以包含多个嵌套的子步骤。
举例:用户问“今天的天气怎么样”,你的应用可能经历了:
- 查询天气API(1次调用)
- 将天气数据填入Prompt模板
- 调用大模型生成回答(1次LLM调用)
整个这个流程就是一个Trace。
Run(运行) 代表Trace中的一个步骤单元。上面的例子包含3个Run:
- Run1: 查询天气API
- Run2: Prompt模板渲染
- Run3: LLM调用
Run之间可以形成父子关系(Run3是Run2的子Run,Run2是Run1的子Run),从而构建出完整的调用树。
Trace与Run的关系:
- 一个Trace包含至少1个Run
- Run是Trace的组成单元
- Trace通过唯一的trace_id标识
- 每个Run有独立的run_id和父子关系
为什么需要区分这两个概念?
因为在实际调试中,你既需要从宏观上看到一次请求的整体表现(耗时、成功/失败),也需要深入到微观细节(某个环节的输入输出是什么)。Trace提供宏观视角,Run提供微观视角。
3.3 Project(项目)
Project 是LangSmith中组织资源的基本单位。你可以理解为“文件夹”或“工作空间”。
每个Project包含:
- 该Project下的所有Runs(追踪记录)
- 该Project下的所有Datasets(数据集)
- 该Project的配置信息(如默认设置)
最佳实践:
- 按应用划分:一个应用对应一个Project
- 按环境划分:dev、staging、production分别建Project
- 按版本划分:v1.0、v2.0分别建Project
为什么不把所有Run都放在一个Project里?
因为Project提供了隔离性。如果所有开发、测试、生产的Run混在一起,你会面临:
- 筛选困难:无法快速找到特定环境的Run
- 评估混乱:评估任务会混合不同环境的数据
- 权限管理复杂:无法针对不同团队设置不同权限
3.4 Session(会话)
Session 用于将多个相关的Trace组织在一起。最常见的场景是对话会话。
在一个多轮对话中,用户的每次提问都会产生一个独立的Trace(因为每次都是独立的请求-响应)。但这些Trace属于同一个对话上下文。通过给这些Trace打上相同的session_id,你就能在LangSmith中一键查看整个对话的完整历史。
Session的应用场景:
- 多轮对话的上下文追踪
- 用户行为分析(一个用户的多次访问)
- A/B测试的流量分组
3.5 Tag(标签)
Tag 是键值对形式的元数据标记。你可以在创建Run时附加任意自定义标签。
典型用法:
# 伪代码示例,具体语法后面会讲
with trace("处理用户请求", tags={"env": "production", "user_id": "12345", "version": "v2.0"}):
# 你的业务逻辑
Tag的价值:
- 筛选过滤:在LangSmith面板中按标签筛选Run
- 成本分析:按用户、按版本统计Token消耗
- 质量分析:对比不同版本的错误率、响应时间
四、原理底层剖析
了解了基本概念后,我们需要深入理解LangSmith的底层工作原理。这能帮助你更好地使用它,并在遇到问题时快速定位原因。
4.1 数据采集原理
LangSmith的数据采集基于装饰器模式和上下文管理器。当你在代码中使用LangSmith SDK时,它会在不侵入业务逻辑的前提下,自动拦截和记录关键信息。
核心机制:
1. 自动注入回调处理器
LangChain的所有核心组件(如ChatModel、LLMChain、Retriever等)都支持通过回调系统扩展行为。LangSmith SDK会在初始化时注册一个特殊的回调处理器——RunCollector。
这个处理器会监听所有组件的:
on_llm_start:LLM即将调用前触发on_llm_end:LLM调用完成后触发on_chain_start:Chain开始执行前触发on_chain_end:Chain执行完成后触发on_tool_start/on_tool_end:工具调用的前后钩子
2. 运行时数据捕获
当你的代码执行时,回调处理器会自动记录:
- 当前Run的输入参数(如Prompt的变量值)
- 当前Run的输出结果
- 执行耗时(自动计算start和end的时间差)
- 错误堆栈(如果发生异常)
- Token使用量(如果组件提供该信息)
- 模型参数(temperature、max_tokens等)
3. 异步上报
为了不影响业务代码的性能,LangSmith SDK采用异步队列上报数据:
- 每个Run的数据先存入本地内存队列
- 后台线程定期从队列取出数据
- 通过HTTP POST请求批量发送到LangSmith API
- 发送失败时自动重试(带指数退避策略)
这种设计的好处:
- 业务代码无感知,不需要手动埋点
- 即使LangSmith服务短暂不可用,数据也不会丢失(会暂时缓存在内存中)
- 对业务性能影响极小(异步非阻塞)
4.2 数据模型设计
LangSmith的数据模型围绕前面讲的Trace和Run展开,但内部实现更精细。
Run对象的内部结构(简化版):
{
"id": "run_abc123",
"trace_id": "trace_xyz789",
"parent_run_id": null,
"name": "ChatOpenAI",
"run_type": "llm",
"inputs": {
"messages": [{"role": "user", "content": "你好"}]
},
"outputs": {
"generations": [[{"text": "你好!有什么可以帮助你的吗?"}]]
},
"start_time": "2024-01-15T10:30:00Z",
"end_time": "2024-01-15T10:30:02Z",
"latency": 2.0,
"total_tokens": 50,
"prompt_tokens": 20,
"completion_tokens": 30,
"error": null,
"tags": ["env:dev"],
"metadata": {"model": "gpt-3.5-turbo"}
}
关键字段解读:
-
run_type:枚举值,包括
llm(大模型调用)、chain(链路)、tool(工具调用)、retriever(检索器)、parser(解析器)等。LangSmith会根据类型在前端展示不同的UI组件。 -
parent_run_id:实现嵌套追踪的关键。如果为null,表示这是根Run(即Trace的入口)。如果不为null,则指向父Run的ID,形成树形结构。
-
latency:端到端耗时,单位秒。自动计算end_time - start_time。
-
total_tokens/prompt_tokens/completion_tokens:仅对run_type="llm"有意义。LangSmith会自动解析LLM提供商的响应,提取Token使用量。
-
error:如果Run执行过程中发生异常,这里会记录错误类型、错误消息和堆栈跟踪。
4.3 数据流与存储
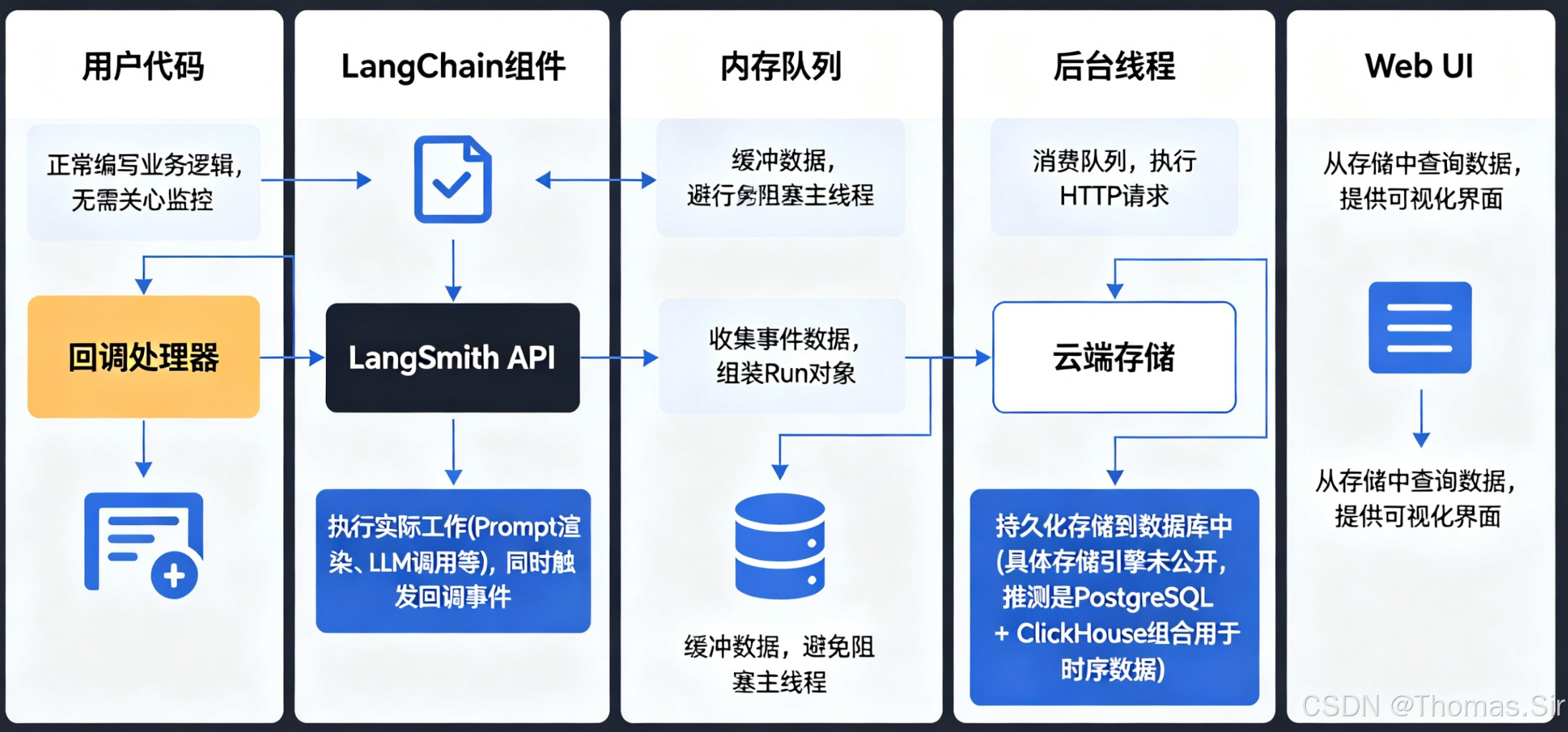
各环节的职责:
- 用户代码:正常编写业务逻辑,无需关心监控
- LangChain组件:执行实际工作(Prompt渲染、LLM调用等),同时触发回调事件
- 回调处理器:收集事件数据,组装Run对象
- 内存队列:缓冲数据,避免阻塞主线程
- 后台线程:消费队列,执行HTTP请求
- LangSmith API:接收数据,进行身份验证和数据校验
- 云端存储:持久化存储到数据库中(具体存储引擎未公开,推测是PostgreSQL + ClickHouse组合用于时序数据)
- Web UI:从存储中查询数据,提供可视化界面
数据保留策略:
- 免费版:7天数据保留期
- 专业版:30天或更长
- 企业版:可定制保留期
4.4 与LangChain的集成深度
LangSmith是LangChain官方产品,因此集成深度远超任何第三方监控方案。
深层次集成体现在:
1. 自动识别组件类型
LangChain的每个组件都有明确的类型标识。LangSmith的SDK能自动识别你调用的是ChatModel还是LLMChain,从而在前端展示不同的详细信息面板。
2. 序列化支持
LangChain的组件支持序列化和反序列化。LangSmith可以直接存储和还原整个Chain的结构,方便你在UI中查看链路配置。
3. 评估框架集成
LangSmith内置的评估器可以与LangChain的输出解析器无缝配合,自动提取结构化数据进行评估。
4. 调试工具链
LangSmith提供了专门的调试模式,可以暂停执行、单步调试、断点分析,这些功能深度依赖于LangChain的回调系统。
这种深度集成意味着:如果你使用LangChain构建应用,启用LangSmith监控几乎是零成本的——你只需要设置环境变量,不需要改任何代码。
五、环境配置手把手实战
理论讲完了,现在进入实战环节。我们将从零开始完成LangSmith的环境配置。
5.1 注册LangSmith账号
步骤1:访问官网
打开浏览器,访问 https://smith.langchain.com
步骤2:选择注册方式
- 使用Google账号登录(推荐,最快捷)
- 使用GitHub账号登录
- 使用邮箱注册
我推荐使用Google或GitHub账号,可以少记一个密码。
步骤3:完成初始设置
首次登录后,系统会引导你:
- 阅读并同意服务条款
- 选择使用目的(个人学习/团队协作/企业应用) —— 这一步不影响功能,随便选
- 选择默认组织(个人账号会自动创建一个以你用户名命名的组织)
步骤4:进入控制台
完成引导后,你会进入LangSmith的主控制台。此时界面还是空的,因为我们还没有创建任何Project和Run。
5.2 获取API密钥
LangSmith使用API Key进行身份认证。你需要生成一个API Key用于代码中配置。
步骤1:找到API Key管理页面
在控制台左侧菜单栏,点击设置图标(齿轮状),进入Settings页面,然后选择"API Keys"选项卡。
步骤2:生成新Key
点击"Create API Key"按钮:
- 输入Key的名称(建议:dev-key-2024、prod-key等,便于区分)
- 选择权限级别(一般选择"All"即可)
- 点击确认
步骤3:保存Key
系统会生成一个形如 lsv2_pt_xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx 的字符串。请立即复制并保存到安全的地方。LangSmith不会再次显示完整的Key,如果你忘记了,只能删除重建。
安全提醒:
- 不要把API Key提交到Git仓库
- 不要在代码中硬编码API Key
- 建议使用环境变量或.env文件管理
5.3 理解免费版限制
在开始使用前,你需要了解免费版的限制,避免超出配额。
免费版提供的资源:
- 每月1000次Trace(追踪记录)
- 每月1000次评估任务执行
- 7天数据保留期
- 最多5个团队成员(仅限查看,不能协作编辑)
- 基础筛选和搜索功能
超过配额后:
- 超出1000次Trace后,新Trace会被拒绝上报(不会扣费,只是无法记录)
- 超出7天的数据自动删除,无法恢复
- 升级到专业版(Pro)可解除限制
对于个人学习和开发测试,免费版完全够用。但如果你是做生产环境监控(每天成千上万次请求),就需要升级到付费版本。
5.4 本地环境配置
现在配置本地开发环境。
创建项目目录:
mkdir langsmith-tutorial
cd langsmith-tutorial
创建虚拟环境(推荐):
# Windows
python -m venv venv
venv\Scripts\activate
# macOS/Linux
python3 -m venv venv
source venv/bin/activate
安装依赖包:
pip install langchain langchain-openai langsmith
这里解释一下三个包的作用:
langchain:核心框架langchain-openai:OpenAI集成(用于调用GPT模型)langsmith:LangSmith Python SDK
配置环境变量:
创建.env文件(注意文件开头的点):
# .env 文件内容
LANGCHAIN_TRACING_V2=true
LANGCHAIN_ENDPOINT="https://api.smith.langchain.com"
LANGCHAIN_API_KEY="你的API Key" # 替换成刚才复制的Key
LANGCHAIN_PROJECT="quickstart"
OPENAI_API_KEY="你的OpenAI API Key"
环境变量说明:
LANGCHAIN_TRACING_V2=true:启用v2版本的追踪功能(推荐使用v2)LANGCHAIN_ENDPOINT:LangSmith服务端点,SaaS版固定为这个地址LANGCHAIN_API_KEY:你的身份凭证LANGCHAIN_PROJECT:指定数据发送到哪个Project(不存在会自动创建)OPENAI_API_KEY:调用OpenAI服务需要的Key
加载环境变量:
在你的Python代码开头加载.env文件:
from dotenv import load_dotenv
load_dotenv() # 在import其他库之前调用
或者你也可以在运行Python脚本前手动export环境变量。
六、完整可运行代码案例
现在让我们编写第一个完整的LangSmith追踪项目。
6.1 最简单的追踪示例
这个例子展示了最基础的追踪能力——从字符串模板到LLM调用的完整链路。
# 文件名: basic_tracing.py
# 说明: 第一个LangSmith追踪示例
import os
from dotenv import load_dotenv
from langchain_openai import ChatOpenAI
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.output_parsers import StrOutputParser
# 加载环境变量(必须在其他导入之前)
load_dotenv()
# 验证环境变量是否配置正确
required_vars = ["LANGCHAIN_API_KEY", "OPENAI_API_KEY"]
for var in required_vars:
if not os.getenv(var):
raise ValueError(f"环境变量 {var} 未设置,请检查.env文件")
print("✅ 环境变量加载成功")
print(f"📁 LangSmith项目: {os.getenv('LANGCHAIN_PROJECT', 'default')}")
# 创建ChatOpenAI实例
# model: 使用的模型名称
# temperature: 控制随机性(0-1),0表示最确定
llm = ChatOpenAI(
model="gpt-3.5-turbo",
temperature=0.7
)
# 创建Prompt模板
# {topic} 是一个占位符,运行时会被替换
prompt = ChatPromptTemplate.from_messages([
("system", "你是一个乐于助人的AI助手,请用{language}回答问题。"),
("human", "{input}")
])
# 创建输出解析器,将模型输出转换为纯字符串
output_parser = StrOutputParser()
# 使用LCEL语法构建Chain
# | 符号表示数据流从左到右传递
chain = prompt | llm | output_parser
# 执行Chain
print("\n🤖 开始调用...")
result = chain.invoke({
"language": "中文",
"input": "请介绍一下LangSmith是什么"
})
print(f"\n📝 最终回答:\n{result}")
print("\n✨ 调用完成!请登录LangSmith控制台查看追踪数据。")
6.2 复杂链路示例(含嵌套追踪)
这个例子展示了一个更真实的场景:生成一个笑话 -> 评估笑话质量 -> 如果质量不好就重新生成。
# 文件名: complex_chain.py
# 说明: 展示嵌套追踪和条件逻辑
import os
import random
from dotenv import load_dotenv
from langchain_openai import ChatOpenAI
from langchain_core.prompts import PromptTemplate
from langchain_core.output_parsers import StrOutputParser
from langchain_core.runnables import RunnableLambda, RunnableBranch
load_dotenv()
# 初始化模型
llm = ChatOpenAI(model="gpt-3.5-turbo", temperature=0.8)
# 定义各个子链
# 1. 生成笑话的链
joke_prompt = PromptTemplate.from_template(
"请生成一个关于{topic}的短笑话。要求: 有趣、积极向上,不超过50字。"
)
joke_chain = joke_prompt | llm | StrOutputParser()
# 2. 评估笑话质量的链
eval_prompt = PromptTemplate.from_template(
"""请评估以下笑话的质量,只输出一个数字(1-5分),5分表示最好。
笑话内容: {joke}
质量分数(仅输出数字):"""
)
eval_chain = eval_prompt | llm | StrOutputParser()
# 3. 改进笑话的链(如果质量不够好)
improve_prompt = PromptTemplate.from_template(
"""请改进以下笑话,让它变得更有趣、更精炼。
原始笑话: {joke}
改进后的笑话:"""
)
improve_chain = improve_prompt | llm | StrOutputParser()
# 定义评分解析函数(将模型输出转换为整数)
def parse_score(score_text: str) -> int:
"""从LLM输出中提取分数"""
# 简单实现: 提取第一个数字字符
import re
match = re.search(r'\d+', score_text)
if match:
score = int(match.group())
return min(max(score, 1), 5) # 限制在1-5范围内
return 3 # 默认3分
# 定义质量检查逻辑
def check_quality(inputs: dict) -> str:
"""根据评分决定分支: good(>=4分) 或 bad(<4分)"""
score = inputs["score"]
if score >= 4:
return "good"
else:
return "bad"
# 构建条件分支
# 如果笑话质量好,直接返回;否则进行改进
branch = RunnableBranch(
(lambda x: check_quality(x) == "good", lambda x: x["original_joke"]),
(lambda x: check_quality(x) == "bad", lambda x: improve_chain.invoke({"joke": x["original_joke"]})),
)
# 完整的主流程
def generate_quality_joke(topic: str) -> str:
"""
生成高质量笑话的主函数
"""
print(f"\n🎯 开始为话题 '{topic}' 生成笑话...")
# Step 1: 生成初始笑话
print("📝 Step 1: 生成初始笑话...")
initial_joke = joke_chain.invoke({"topic": topic})
print(f" 初始笑话: {initial_joke}")
# Step 2: 评估质量
print("⚖️ Step 2: 评估质量...")
score_text = eval_chain.invoke({"joke": initial_joke})
score = parse_score(score_text)
print(f" 质量评分: {score}/5")
# Step 3: 根据质量决定是否改进
print("🔄 Step 3: 质量检查与改进...")
result = branch.invoke({
"original_joke": initial_joke,
"score": score
})
if result == initial_joke:
print(f" ✅ 质量合格,直接采用")
else:
print(f" 🔧 质量不足,已改进: {result}")
return result
# 执行主流程
if __name__ == "__main__":
# 测试几个不同的话题
topics = ["程序员", "人工智能", "火锅"]
for topic in topics:
print("\n" + "="*60)
final_joke = generate_quality_joke(topic)
print(f"\n🎉 最终笑话:\n{final_joke}")
print("="*60)
print("\n✨ 所有任务完成!请登录LangSmith查看完整的嵌套追踪链路。")
print(" 提示: 在Trace详情页可以看到3个步骤的完整调用树。")
6.3 错误追踪示例
这个例子展示LangSmith如何自动捕获和记录异常。
# 文件名: error_tracing.py
# 说明: 展示错误情况下的追踪
import os
from dotenv import load_dotenv
from langchain_openai import ChatOpenAI
from langchain_core.prompts import PromptTemplate
load_dotenv()
def run_with_potential_error(enable_error: bool):
"""
运行可能出错的链
"""
llm = ChatOpenAI(model="gpt-3.5-turbo")
# 故意使用一个不存在的变量(如果enable_error为True)
if enable_error:
prompt = PromptTemplate.from_template("你好,{name}! 今天的{undefined_variable}很好。")
else:
prompt = PromptTemplate.from_template("你好,{name}!")
chain = prompt | llm
try:
result = chain.invoke({"name": "张三"})
print(f"✅ 成功: {result}")
except Exception as e:
print(f"❌ 失败: {type(e).__name__}: {e}")
# 异常会被LangSmith自动捕获并记录到Trace中
raise # 重新抛出,让调用者看到错误
if __name__ == "__main__":
print("第一个调用(正常):")
run_with_potential_error(enable_error=False)
print("\n第二个调用(故意制造错误):")
try:
run_with_potential_error(enable_error=True)
except:
pass # 错误已经被记录,这里静默处理避免中断
print("\n📊 请在LangSmith控制台查看两个Trace的对比:")
print(" - 第一个Trace: 状态为success")
print(" - 第二个Trace: 状态为error,包含错误详情")
七、代码逐行详解
我们来深入分析第一个示例basic_tracing.py,理解每一行代码的作用。
7.1 导入和初始化部分
import os
from dotenv import load_dotenv
os模块用于读取环境变量load_dotenv函数从.env文件加载环境变量到os.environ
from langchain_openai import ChatOpenAI
ChatOpenAI是LangChain提供的OpenAI聊天模型适配器- 它封装了OpenAI API的调用细节,提供了统一的接口
from langchain_core.prompts import ChatPromptTemplate
ChatPromptTemplate用于构建聊天格式的Prompt- 支持system、human、ai等角色消息
from langchain_core.output_parsers import StrOutputParser
StrOutputParser将LLM的输出(通常是AIMessage对象)转换为纯字符串- 简化了后续处理
load_dotenv()
- 读取当前目录下的
.env文件 - 将文件中的键值对设置到环境变量中
- 必须在其他导入之前调用,因为LangSmith的初始化会读取环境变量
7.2 配置验证部分
required_vars = ["LANGCHAIN_API_KEY", "OPENAI_API_KEY"]
for var in required_vars:
if not os.getenv(var):
raise ValueError(f"环境变量 {var} 未设置,请检查.env文件")
- 主动检查必需的配置是否存在
- 避免运行时才发现配置缺失,浪费时间排查
print(f"📁 LangSmith项目: {os.getenv('LANGCHAIN_PROJECT', 'default')}")
- 打印当前使用的Project名称
os.getenv的第二个参数是默认值(如果不设置环境变量)
7.3 组件构建部分
llm = ChatOpenAI(
model="gpt-3.5-turbo",
temperature=0.7
)
model参数指定使用的模型,gpt-3.5-turbo是目前性价比最高的选择temperature控制输出的随机性:0表示最确定,1表示最随机。0.7是较好的平衡点
prompt = ChatPromptTemplate.from_messages([
("system", "你是一个乐于助人的AI助手,请用{language}回答问题。"),
("human", "{input}")
])
from_messages方法从消息列表构建模板- 每条消息是
(role, content)元组 {language}和{input}是占位符,运行时会被替换
output_parser = StrOutputParser()
- 创建输出解析器实例,不做任何复杂处理,只做类型转换
7.4 LCEL链路组合
chain = prompt | llm | output_parser
|操作符是LCEL(LangChain Expression Language)的核心语法- 表示数据从左到右依次经过每个组件
prompt接收输入字典 → 生成消息列表 →llm调用模型 → 返回AIMessage →output_parser转换为字符串
7.5 执行调用
result = chain.invoke({
"language": "中文",
"input": "请介绍一下LangSmith是什么"
})
invoke是LangChain的统一调用接口- 传入一个字典,key对应Prompt模板中的占位符
- LangSmith会自动监控这次调用的整个过程
7.6 LangSmith的自动追踪如何工作
当你运行这段代码时,幕后发生的事情:
-
导入时的初始化:
- 当
from langchain_openai import ChatOpenAI执行时,LangSmith的回调系统被激活 - 检查环境变量
LANGCHAIN_TRACING_V2,如果为true则启用追踪
- 当
-
组件创建时:
- 每个LangChain组件在创建时都会被分配一个ID
- 但此时还没有实际追踪,因为还没有调用
-
调用
chain.invoke时:- 触发
on_chain_start回调,创建根Run - 执行
prompt渲染,触发on_chain_end(对于PromptTemplate) - 调用
llm,触发on_llm_start→ 发送HTTP请求到OpenAI → 收到响应 → 触发on_llm_end - 执行
output_parser,触发相应回调 - 最后触发
on_chain_end,完成根Run
- 触发
-
数据上报:
- 所有Run数据被放入队列
- 后台线程异步发送到LangSmith API
八、常见坑点与避坑指南
基于大量实战经验,总结以下常见问题和解决方案。
8.1 环境变量未生效
症状:
- 代码运行正常,但LangSmith控制台看不到任何数据
- 或者看到错误日志:
LangSmith API key is not set
原因:
.env文件位置不对(不在当前工作目录)load_dotenv()调用位置太晚(在某些库初始化之后)- 环境变量名拼写错误(如
LANGCHAIN_API_KEY写成LANGCHAIN-API-KEY)
解决方案:
# 正确的做法
from dotenv import load_dotenv
load_dotenv() # 在所有其他导入之前
# 验证配置
import os
print(os.getenv("LANGCHAIN_API_KEY")) # 应该输出你的Key
print(os.getenv("LANGCHAIN_TRACING_V2")) # 应该输出'true'
8.2 免费版配额超限
症状:
- 代码运行成功,但LangSmith中没有新数据
- 或者收到错误响应:
Quota exceeded
原因:
- 当月Trace次数已超过1000次(免费版限制)
- 可能是在循环或批处理中大量调用,无意中消耗了配额
解决方案:
- 在开发和测试阶段,使用采样策略:只记录部分请求
- 或者升级到付费版本
- 或者在代码中判断环境,只在必要的时候启用追踪:
import os
if os.getenv("ENVIRONMENT") == "production":
os.environ["LANGCHAIN_TRACING_V2"] = "true"
else:
os.environ["LANGCHAIN_TRACING_V2"] = "false"
8.3 网络连接问题
症状:
- 代码执行缓慢,有多次重试日志
- 部分Trace丢失
原因:
- 公司网络限制,无法访问
api.smith.langchain.com - 需要配置HTTP代理
解决方案:
# 配置代理(如果公司网络需要)
os.environ["HTTP_PROXY"] = "http://proxy.example.com:8080"
os.environ["HTTPS_PROXY"] = "http://proxy.example.com:8080"
或者使用离线模式(数据只保存在本地,不同步到云端):
os.environ["LANGCHAIN_TRACING_OFFLINE"] = "true"
8.4 敏感数据泄露
症状:
- 不小心把用户隐私数据(如手机号、身份证)记录到了LangSmith
- 无法删除(免费版不支持数据删除)
原因:
- LangSmith默认会记录所有输入输出,包括敏感信息
解决方案:
- 使用
@traceable装饰器的参数控制哪些数据被记录:
from langsmith import traceable
@traceable(
capture_input=False, # 不记录输入
capture_output=False # 不记录输出
)
def process_user_data(user_info):
# 处理敏感数据
pass
- 或者在环境变量中全局禁用数据捕获:
LANGCHAIN_HIDE_INPUTS=true
LANGCHAIN_HIDE_OUTPUTS=true
8.5 异步代码追踪失效
症状:
- 在async函数中调用LLM,LangSmith没有记录
原因:
- LangSmith的回调系统对异步上下文有特殊要求
解决方案:
使用ainvoke而不是invoke:
# 错误的做法
async def my_func():
result = chain.invoke(...) # 同步调用,但在异步函数中
# 正确的做法
async def my_func():
result = await chain.ainvoke(...) # 异步调用
8.6 大量小Trace影响性能
症状:
- 代码运行明显变慢
- CPU占用率升高
原因:
- 每个小的组件调用都创建Run,产生大量网络请求开销
解决方案:
- 使用
with tracing上下文管理器合并多个操作为一个Trace:
from langsmith import trace_context
with trace_context("batch_processing"):
for item in items:
process_item(item) # 这些调用都会被放在同一个Trace下
- 或者提高采样率,只记录一部分请求:
import random
if random.random() < 0.1: # 10%采样
os.environ["LANGCHAIN_TRACING_V2"] = "true"
九、企业级落地最佳实践
基于多个生产环境的实践经验,总结以下最佳实践。
9.1 项目组织策略
多Project并行管理:
- project: myapp-dev (开发环境)
- project: myapp-staging (预发布环境)
- project: myapp-production (生产环境)
- project: myapp-experiment (A/B测试)
命名规范:
格式: {团队}_{应用}_{环境}_{用途}
示例:
- ai_chatbot_prod_main
- ai_chatbot_staging_test
- search_engine_dev_embeddings
为什么要这样组织:
- 环境隔离:开发和生产的Trace混在一起,会导致监控数据污染
- 权限分离:生产环境应该只有运维人员可访问
- 成本控制:对开发环境可以降低采样率,节省配额
9.2 标签规范化
定义标准标签集:
# 统一的标签字典
STANDARD_TAGS = {
"version": "v2.1.0", # 应用版本
"user_group": "premium", # 用户分组
"region": "us-east", # 地理区域
"model": "gpt-4", # 使用的模型
"agent_type": "rag_agent", # Agent类型
"session_id": "sess_12345", # 会话ID
"ab_test": "variant_b" # A/B测试组
}
# 使用时合并
chain.invoke(input, config={"tags": list(STANDARD_TAGS.items())})
标签使用原则:
- 基数(cardinality)低的属性适合做标签(如
version、env) - 基数高的属性(如
user_id)容易导致筛选面板卡顿,建议用metadata - 标签数量控制在10个以内,过多会影响性能
9.3 生产环境采样策略
生产环境不可能追踪每一个请求(即使是付费版本,也会受限于API速率)。采用智能采样策略。
方案一:按用户分层采样
def should_trace(user_id: str) -> bool:
"""决定是否追踪该请求"""
# 白名单用户:100%追踪
if user_id in PREMIUM_USERS:
return True
# 普通用户:5%随机采样
import hashlib
hash_val = int(hashlib.md5(user_id.encode()).hexdigest(), 16)
return (hash_val % 100) < 5
# 使用
if should_trace(current_user_id):
os.environ["LANGCHAIN_TRACING_V2"] = "true"
else:
os.environ["LANGCHAIN_TRACING_V2"] = "false"
方案二:按业务价值采样
# 只追踪高价值请求
def should_trace_by_intent(user_query: str) -> bool:
# 包含特定关键词的请求才追踪
high_value_keywords = ["支付", "退款", "订阅", "企业版"]
return any(kw in user_query for kw in high_value_keywords)
方案三:自适应采样
# 动态调整采样率,错误越多的时段采样率越高
error_rate = get_recent_error_rate(minutes=5)
if error_rate > 0.1: # 错误率超过10%
sample_rate = 0.5 # 提高采样率到50%
else:
sample_rate = 0.05 # 正常5%采样
should_trace = random.random() < sample_rate
9.4 成本控制
LangSmith本身免费版有配额,付费版按量计费。控制成本的策略:
1. 精简Run数据
# 配置不记录大字段
import langsmith
langsmith.config.hide_inputs = True # 不记录Prompt(可能很长)
langsmith.config.hide_outputs = True # 不记录输出(但这样就失去了意义)
2. 合并细粒度Run
# 不好的写法:每个操作都有独立Run
chain = step1 | step2 | step3 | step4 # 4个Run
# 好的写法:合并为一个大Run
@traceable(name="combined_chain")
def combined_process(input_data):
intermediate1 = step1(input_data)
intermediate2 = step2(intermediate1)
return step3(intermediate2)
3. 定期清理旧数据
虽然免费版自动清理7天前数据,但付费版需要手动清理:
from langsmith import Client
client = Client()
# 删除30天前的Runs
client.delete_runs(older_than_days=30)
9.5 团队协作规范
Code Review检查点:
- 是否配置了正确的
LANGCHAIN_PROJECT(不要在PR中硬编码个人测试项目) - 是否添加了有意义的
tags和metadata - 是否处理了敏感数据(不应该记录密码、Token等)
开发流程集成:
# 在本地开发时自动使用个人Project
if os.getenv("CI") != "true": # 不是CI环境
os.environ["LANGCHAIN_PROJECT"] = f"{os.getenv('USER')}-dev"
共享链接规范:
LangSmith支持生成分享链接。在提交Issue或PR时,附上相关Trace的分享链接:
# 获取当前Trace的分享链接
from langsmith import get_current_run_tree
run_tree = get_current_run_tree()
share_url = run_tree.get_url()
print(f"📎 调试链接: {share_url}")
十、本节知识点总结
本节课我们系统学习了以下内容:
理论层面:
- LLMOps核心概念:理解了大模型应用为什么需要可观测性,LLMOps与传统MLOps的区别
- LangSmith定位:LangSmith是LangChain官方的可观测性平台,负责调试、评估、监控
- 核心概念:
- Trace:一次完整请求的全流程记录
- Run:Trace中的单个步骤
- Project:资源隔离单元
- Session:多轮对话的组织方式
- Tag:自定义标记,用于筛选分析
- 工作原理:
- 基于回调系统自动捕获数据
- 异步队列上报,不影响业务性能
- 深度集成LangChain组件
实操层面:
- 环境配置:
- 注册LangSmith账号并获取API Key
- 配置环境变量(LANGCHAIN_TRACING_V2、API_KEY、PROJECT)
- 安装必要的Python包
- 代码实战:
- 第一个链式调用示例(basic_tracing.py)
- 复杂链路示例(嵌套调用、条件分支)
- 错误追踪示例
- 调试分析:
- 学会在LangSmith面板查看Trace详情
- 理解每个Run的输入输出和耗时
避坑指南:
- 环境变量必须在导入前加载
- 免费版每月1000次Trace限额
- 注意敏感数据的泄露风险
- 异步代码需要使用
ainvoke
企业实践:
- 多Project组织策略(按环境、按团队)
- 标签规范化(统一命名、控制基数)
- 生产环境采样策略(按用户、按业务价值)
- 成本控制方法(精简数据、定期清理)
- 团队协作规范(Code Review、共享链接)
十一、课后思考练习题
为了巩固本节课的内容,请完成以下练习。
练习题1:理论理解(简答题)
1.1 请用自己的话解释Trace和Run的区别,并举例说明。(提示:类比浏览器开发者工具中的网络请求和子请求)
1.2 为什么大模型应用比传统应用更需要可观测性?列出至少3个原因。
1.3 如果公司只有3个人使用LangSmith(你、同事A、同事B),你们分别负责开发、测试、运维,应该如何规划Project?请说明理由。
练习题2:动手实践
2.1 改造basic_tracing.py,添加以下功能:
- 增加一个
temperature参数,让用户可以在调用时指定(而不是硬编码) - 使用
with trace_context()将整个处理过程包装在一个自定义Trace下 - 添加3个自定义标签:
env="test"、user_type="beginner"、model="gpt3.5"
2.2 编写一个函数,接收一个用户问题列表questions = ["什么是LangSmith?", "如何安装LangSmith?", "LangSmith收费吗?"],循环处理每个问题。要求:
- 每个问题单独一个Trace
- 所有问题共享同一个Session ID
- 在LangSmith面板中,能够一键筛选出这个Session的所有对话
提示:使用config={"callbacks": [SessionCallback(session_id="...")]}或查阅文档了解如何设置Session。
练习题3:场景设计
3.1 你正在开发一个客服机器人,面临以下问题:
- 用户投诉回答质量不好,但原因不明
- 每次修改Prompt后,不确定效果是否提升
- 有些用户问相同的问题,机器人却给出不同的答案
请设计一个基于LangSmith的解决方案,回答:
- 你会如何配置Project和标签?
- 如何使用LangSmith定位“回答质量不好”的问题?
- 如果要对新Prompt进行A/B测试,LangSmith能提供什么帮助?
3.2 生产环境流量较大(每天约10万次请求),免费版的1000次/月显然不够。请设计一个成本可控的监控方案:
- 采样率如何设置?
- 哪些请求必须100%监控?
- 如何平衡成本和可观测性?
练习题4:源码分析(选做)
阅读LangSmith Python SDK的部分源码(https://github.com/langchain-ai/langsmith-sdk),回答:
traceable装饰器的实现原理是什么?- 在什么情况下会触发
on_chain_start回调? - 异步队列的默认最大容量是多少?
提交方式:
- 将代码和答案整理成文档
- 在LangSmith社区分享你的学习心得
- 参考答案将在下节课公布
下节课预告:
第2课我们将深入学习LangSmith的账号体系、权限模型和计费规则。届时会详细讲解:
- 不同付费版本的差异对比
- 团队成员的邀请和权限管理
- 如何估算你的使用量并选择合适的套餐
- 企业版的自托管方案
请确保完成本节课的环境配置和基础代码调试,下节课我们将在同样的环境基础上继续深入。
学习建议:
- 本节课的所有代码示例建议你亲自运行一遍,不要只看不练
- 运行代码后,务必登录LangSmith控制台查看Trace详情,直观感受数据呈现
- 尝试故意制造一些错误(如删掉API Key、使用错误的Project名),观察LangSmith的行为
- 对照课后练习,检验自己的掌握程度
如果有任何疑问,欢迎在专栏评论区留言,我会定期回复。下一节课见!
🔗《20节课 LangSmith 从入门到精通》系列课程导航
🌟 感谢您耐心阅读到这里!
💡 如果本文对您有所启发欢迎:
👍 点赞📌 收藏 📤 分享给更多需要的伙伴。
🗣️ 期待在评论区看到您的想法, 共同进步。
🔔 关注我,持续获取更多干货内容~
🤗 我们下篇文章见~

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 12
12 0
0- 0



 已为社区贡献223条内容
已为社区贡献223条内容

所有评论(0)