1997年高教社杯全国大学生数学建模竞赛 A 题:《零件的参数设计》真题解析与 MATLAB 解决方案

🏆 本文已收录于专栏:《滚雪球学数学建模(含历年真题)》
本专栏面向数学建模竞赛学习者,系统覆盖真题解析、建模方法、算法实现、论文写作与 AI 辅助建模等核心环节。无论是建模新手,还是备战华为杯、高教社杯、华数杯、国赛、美赛 MCM/ICM 的参赛者,都能在这里找到清晰、完整、可复用的建模思路,持续更新,长期有效。
🎯 免责声明: 本文题目来源于互联网公开内容,仅供学习交流与建模方法研究,不构成竞赛指导。请遵守相关赛事规则,独立完成竞赛作品,使用本文内容所产生的后果由使用者自行承担。
🎉 专栏限时优惠中:一次订阅,永久解锁,后续内容持续更新。 欢迎点击了解 👉 查看专栏详情 👈
全文目录:
1997A题:零件的参数设计
真题展示
如下为原(真)题,展示如下:
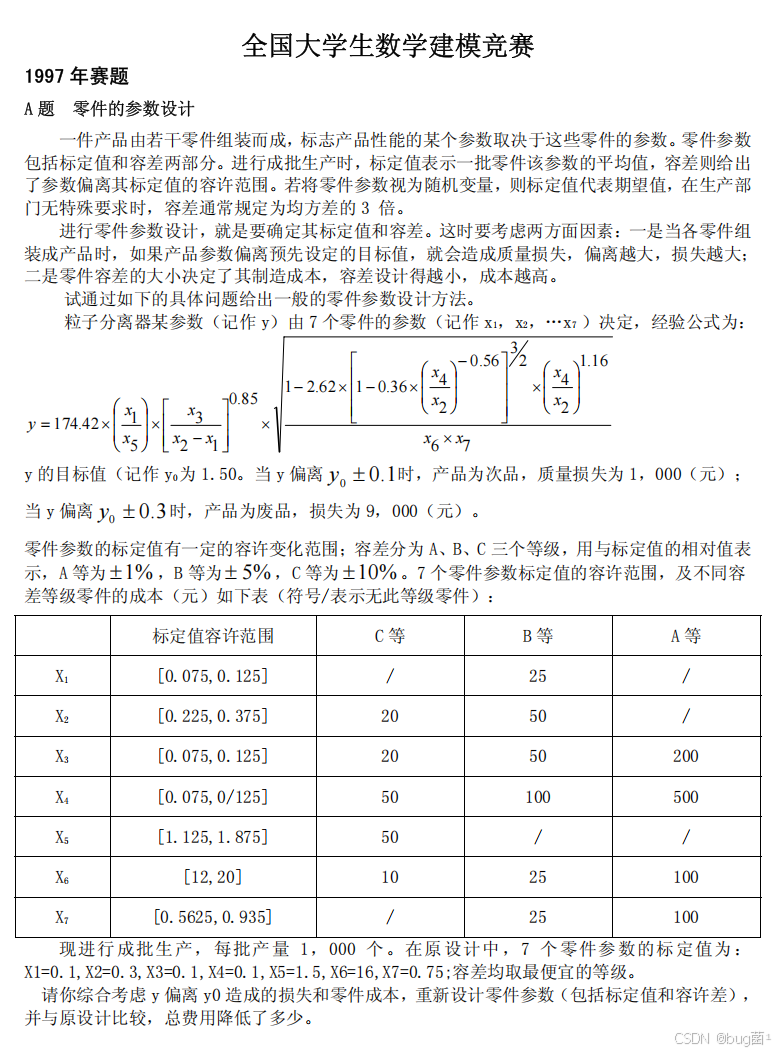
写在前面:这是一道非常经典的优化题,1997年的题目放到今天依然具有很强的教学价值。很多同学第一眼看到这道题,会觉得"不就是代公式算一算吗"——但如果你真的这样想,就已经踩进了最常见的建模误区。这道题的核心不是计算,而是如何在质量损失与制造成本之间寻找最优平衡,这是一个典型的多变量、多约束、离散-连续混合优化问题。
一、前言:为什么这道题值得深入分析?
1997年国赛A题《零件的参数设计》是数学建模竞赛历史上公认的优质题目之一。它有以下几个特点,使其至今仍被各大高校建模培训课程反复引用:
第一,问题源于真实工程背景。 题目来自田口(Taguchi)参数设计理论,这是质量工程领域的核心方法论。理解这道题,你实际上是在学习一种工业界广泛使用的优化设计思想。
第二,它是离散与连续混合的优化问题。 容差等级(A/B/C)是离散变量,而标定值是连续变量。这类混合整数优化问题在实际工程中极为常见,却往往被初学者忽视。
第三,目标函数的构建非常考验建模思维。 质量损失函数如何量化?成本如何计入?这些都需要对题目进行深度理解,而不是简单地"代公式"。
第四,它是一道需要数值搜索的题目。 没有解析解,必须通过枚举或优化算法寻找最优方案,这对MATLAB编程能力有一定要求。
读完这篇文章,你将掌握从题目理解到代码实现的完整流程,并能够将其写成一篇有竞争力的数学建模论文。
二、题目背景与现实意义
2.1 田口参数设计理论背景
田口玄一(Genichi Taguchi)是日本著名质量工程专家,他提出的**参数设计(Parameter Design)**方法是稳健设计(Robust Design)的核心内容。其基本思想是:
通过合理设计产品或过程的参数(标定值和容差),使产品性能对噪声因素(制造误差、环境变化等)不敏感,同时控制制造成本。
在实际生产中,零件参数不可能完全等于标定值,总存在偏差。**容差(Tolerance)**就是规定了这种偏差的允许范围。容差越小,制造精度要求越高,成本越高;容差越大,产品性能波动越大,质量损失越高。
2.2 质量损失函数
题目中隐含了田口的**二次质量损失函数(Quadratic Loss Function)**思想:
L ( y ) = k ( y − y 0 ) 2 L(y) = k(y - y_0)^2 L(y)=k(y−y0)2
其中 y y y 是产品性能参数, y 0 y_0 y0 是目标值, k k k 是损失系数。偏差越大,损失越大,且是平方关系(非线性增长)。
但本题将其离散化为两个阈值:偏差超过 ± 0.1 \pm 0.1 ±0.1(次品,损失1000元)和超过 ± 0.3 \pm 0.3 ±0.3(废品,损失9000元)。这是工程实践中的简化处理,更便于建模和计算。
2.3 现实意义
这类问题在现实工业生产中无处不在:
- 芯片制造中的光刻精度设计
- 汽车发动机零件的配合公差设计
- 航空零部件的尺寸容差分配
掌握这道题的建模方法,就掌握了一类重要工程优化问题的分析框架。
三、题目重述
3.1 已知条件
(1)性能函数
产品性能参数 y y y 由7个零件参数 x 1 , x 2 , ⋯ , x 7 x_1, x_2, \cdots, x_7 x1,x2,⋯,x7 决定,经验公式为:
y = 174.42 × ( x 1 x 5 ) × [ x 3 x 2 − x 1 ] 0.85 × [ 1 − 2.62 × [ 1 − 0.36 × ( x 4 x 2 ) − 0.56 ] ] 3 / 2 × ( x 4 x 2 ) 1.16 x 6 × x 7 y = 174.42 \times \left(\frac{x_1}{x_5}\right) \times \left[\frac{x_3}{x_2 - x_1}\right]^{0.85} \times \sqrt{\frac{\left[1 - 2.62 \times \left[1 - 0.36 \times \left(\frac{x_4}{x_2}\right)^{-0.56}\right]\right]^{3/2} \times \left(\frac{x_4}{x_2}\right)^{1.16}}{x_6 \times x_7}} y=174.42×(x5x1)×[x2−x1x3]0.85×x6×x7[1−2.62×[1−0.36×(x2x4)−0.56]]3/2×(x2x4)1.16
(2)质量损失规定
- y y y 的目标值 y 0 = 1.50 y_0 = 1.50 y0=1.50
- 当 ∣ y − y 0 ∣ > 0.1 |y - y_0| > 0.1 ∣y−y0∣>0.1 时,为次品,质量损失 1,000元/件
- 当 ∣ y − y 0 ∣ > 0.3 |y - y_0| > 0.3 ∣y−y0∣>0.3 时,为废品,质量损失 9,000元/件
(3)零件容差等级
容差分A(±1%)、B(±5%)、C(±10%)三个等级,各零件适用等级及成本如下表:
| 零件 | 标定值范围 | C等成本(元) | B等成本(元) | A等成本(元) |
|---|---|---|---|---|
| X 1 X_1 X1 | [0.075, 0.125] | / | 25 | / |
| X 2 X_2 X2 | [0.225, 0.375] | 20 | 50 | / |
| X 3 X_3 X3 | [0.075, 0.125] | 20 | 50 | 200 |
| X 4 X_4 X4 | [0.075, 0.125] | 50 | 100 | 500 |
| X 5 X_5 X5 | [1.125, 1.875] | 50 | / | / |
| X 6 X_6 X6 | [12, 20] | 10 | 25 | 100 |
| X 7 X_7 X7 | [0.5625, 0.935] | / | 25 | 100 |
(4)原设计方案
原始标定值: X 1 = 0.1 , X 2 = 0.3 , X 3 = 0.1 , X 4 = 0.1 , X 5 = 1.5 , X 6 = 16 , X 7 = 0.75 X_1=0.1, X_2=0.3, X_3=0.1, X_4=0.1, X_5=1.5, X_6=16, X_7=0.75 X1=0.1,X2=0.3,X3=0.1,X4=0.1,X5=1.5,X6=16,X7=0.75
原始容差:均取最便宜等级。
(5)生产规模
每批生产1,000件。
3.2 待解决问题
综合考虑 y y y 偏离 y 0 y_0 y0 造成的损失和零件成本,重新设计零件参数(包括标定值和容差),并与原设计比较,总费用降低了多少。
3.3 附件数据说明
本题无附件数据,所有信息均由题干给出。建模所需的所有参数均已在题目中明确,无需外部数据支撑。
四、问题分析
4.1 核心问题分析
本题是一个参数优化问题,决策变量包含两类:
连续变量:7个零件的标定值 x ˉ i \bar{x}_i xˉi(在各自允许范围内取值)
离散变量:7个零件的容差等级(从可选等级中选择)
目标是:最小化每批生产的总期望费用(质量损失 + 零件成本)
4.2 关键难点分析
难点一:质量损失如何计算?
每个零件参数存在偏差(由容差决定),导致 y y y 偏离 y 0 y_0 y0。由于 y y y 是7个变量的非线性函数,参数偏差如何传递到 y y y 的偏差上,需要用误差传播理论或Monte Carlo模拟来处理。
难点二:搜索空间很大
7个连续标定值 × 各零件可选等级的组合(枚举容差等级组合数为 1 × 3 × 3 × 3 × 1 × 3 × 2 = 54 1×3×3×3×1×3×2 = 54 1×3×3×3×1×3×2=54 种),对每种容差组合还需优化连续标定值,这是一个混合优化问题。
难点三:非线性、非凸
性能函数 y y y 是高度非线性的,目标函数可能存在多个局部极小值,不能直接用线性规划求解。
4.3 各子问题的逻辑关系
具体相关示意图绘制如下,仅供参考:
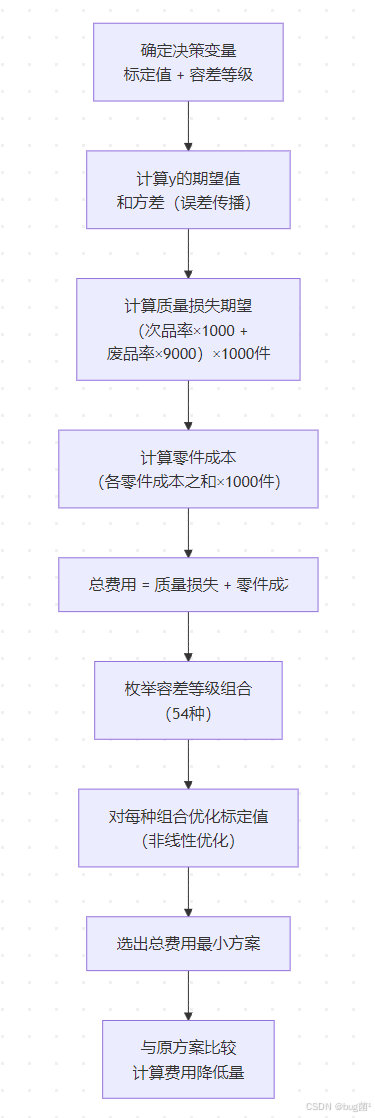
图说明:这张图展示了整个求解的逻辑链条。注意"质量损失"的计算是关键节点——它需要知道 y y y 的概率分布,而 y y y 的分布由标定值和容差共同决定。这正是本题建模的核心难点。
4.4 原方案的费用计算(基准)
在深入优化之前,必须先算清楚原方案的费用,这是对比的基准。
原方案容差等级: X 1 X_1 X1=B, X 2 X_2 X2=C, X 3 X_3 X3=C, X 4 X_4 X4=C, X 5 X_5 X5=C, X 6 X_6 X6=C, X 7 X_7 X7=B
原方案零件成本(每件): 25 + 20 + 20 + 50 + 50 + 10 + 25 = 200 25+20+20+50+50+10+25 = 200 25+20+20+50+50+10+25=200 元
每批1000件,零件总成本 = 200,000元
五、整体建模思路
5.1 建模路线
具体相关示意图绘制如下,仅供参考:

5.2 模型选择依据
| 候选方法 | 适用性分析 | 是否采用 |
|---|---|---|
| 解析法(求导令梯度为零) | y y y 对各 x i x_i xi 的偏导数复杂,且混合整数不适用 | 否 |
| 枚举+数值优化 | 容差组合有限(54种),每种组合内用fmincon优化连续变量 | 主方法 |
| Monte Carlo模拟 | 计算质量损失时使用,处理非线性误差传播 | 辅助验证 |
| 遗传算法 | 可处理混合整数,但对本题规模略显"杀鸡用牛刀" | 改进备选 |
5.3 算法实现思路
两层优化结构:
- 外层:枚举所有容差等级组合(54种)
- 内层:对每种容差组合,用
fmincon优化7个标定值,最小化总期望费用
5.4 结果验证方法
- 将优化后的标定值代回原公式,验证 y ( x ˉ i ) ≈ y 0 = 1.5 y(\bar{x}_i) \approx y_0 = 1.5 y(xˉi)≈y0=1.5
- 用Monte Carlo模拟验证质量损失估算的准确性
- 对关键参数做灵敏度分析,验证最优解的稳定性
六、数据预处理
6.1 题目数据整理
本题无外部数据,但需要将题目中的所有参数整理为结构化的MATLAB数据。
% data_preprocess.m
% 功能:整理题目中的所有参数,返回结构体
function params = data_preprocess()
% ===== 零件标定值允许范围 =====
% 每行:[下界, 上界]
params.x_range = [
0.075, 0.125; % x1
0.225, 0.375; % x2
0.075, 0.125; % x3
0.075, 0.125; % x4
1.125, 1.875; % x5
12.0, 20.0; % x6
0.5625, 0.935 % x7
];
% ===== 容差等级(相对误差)=====
% A=1%, B=5%, C=10%
params.tol_level = struct('A', 0.01, 'B', 0.05, 'C', 0.10);
% ===== 各零件可选等级及成本 =====
% 用NaN表示不可选
% 每行:[C等成本, B等成本, A等成本]
params.cost_table = [
NaN, 25, NaN; % x1: 只有B
20, 50, NaN; % x2: C, B
20, 50, 200; % x3: C, B, A
50, 100, 500; % x4: C, B, A
50, NaN, NaN; % x5: 只有C
10, 25, 100; % x6: C, B, A
NaN, 25, 100 % x7: B, A
];
% 对应容差值
params.tol_table = [
NaN, 0.05, NaN; % x1
0.10, 0.05, NaN; % x2
0.10, 0.05, 0.01; % x3
0.10, 0.05, 0.01; % x4
0.10, NaN, NaN; % x5
0.10, 0.05, 0.01; % x6
NaN, 0.05, 0.01 % x7
];
% ===== 质量目标值和损失参数 =====
params.y0 = 1.50; % 目标值
params.delta1 = 0.1; % 次品阈值
params.delta2 = 0.3; % 废品阈值
params.loss1 = 1000; % 次品损失(元/件)
params.loss2 = 9000; % 废品损失(元/件)
params.batch = 1000; % 每批产量(件)
% ===== 原始设计参数 =====
params.x0_original = [0.1, 0.3, 0.1, 0.1, 1.5, 16, 0.75];
% 原始容差等级索引 [B, C, C, C, C, C, B]
% 列索引:1=C, 2=B, 3=A
params.grade_original = [2, 1, 1, 1, 1, 1, 2];
fprintf('✓ 数据预处理完成,参数结构体已生成\n');
end
代码解析:
- 用
NaN表示不可选的容差等级,后续枚举时跳过NaN项,避免逻辑错误; - 将成本表和容差表分开存储,便于分别调用;
- 结构体(struct)比矩阵更易读,竞赛中推荐使用;
- 初学者容易犯错:把A等容差误以为最大(实际上A等是精度最高即±1%最小)。
6.2 原方案基准计算
% compute_baseline.m
% 计算原设计方案的总费用(基准值)
function [total_cost, detail] = compute_baseline(params)
x0 = params.x0_original;
grade = params.grade_original;
% 计算原方案零件成本(每件)
unit_part_cost = 0;
for i = 1:7
g = grade(i);
c = params.cost_table(i, g);
unit_part_cost = unit_part_cost + c;
end
part_cost_total = unit_part_cost * params.batch;
% 用Monte Carlo估算原方案质量损失
N_sim = 100000; % 模拟次数
tol = zeros(1,7);
for i = 1:7
g = grade(i);
tol(i) = params.tol_table(i, g) * x0(i); % 绝对容差
end
quality_loss = monte_carlo_loss(x0, tol, params, N_sim);
detail.part_cost = part_cost_total;
detail.quality_loss = quality_loss * params.batch;
total_cost = detail.part_cost + detail.quality_loss;
fprintf('=== 原方案费用 ===\n');
fprintf('零件成本:%.0f 元\n', detail.part_cost);
fprintf('质量损失:%.0f 元\n', detail.quality_loss);
fprintf('总费用: %.0f 元\n', total_cost);
end
七、模型假设
建模时,以下假设是必须明确说明的(不是越多越好,但要有充分理由):
假设1:每个零件参数 x i x_i xi 在标定值 x ˉ i \bar{x}_i xˉi 附近服从均匀分布,范围为 [ x ˉ i ( 1 − δ i ) , x ˉ i ( 1 + δ i ) ] [\bar{x}_i(1-\delta_i), \bar{x}_i(1+\delta_i)] [xˉi(1−δi),xˉi(1+δi)],其中 δ i \delta_i δi 为对应等级的相对容差。
理由:题目没有指定分布类型,均匀分布是在无先验信息时最保守的假设(最大熵原理)。实际上也可以假设正态分布,但题目指出容差为均方差的3倍,暗示了正态分布。我们在模型一用均匀分布,模型二改用正态分布,对比两种假设的结果。
假设2:7个零件参数相互独立,偏差不相关。
理由:题目无相关性说明,独立假设是标准处理。若有相关性,需要协方差矩阵,数据不足以支撑。
假设3:经验公式 y = f ( x 1 , ⋯ , x 7 ) y = f(x_1, \cdots, x_7) y=f(x1,⋯,x7) 在参数容差范围内精确成立。
理由:题目明确说明是"经验公式",我们接受其准确性,不考虑公式本身的不确定性。
假设4:质量损失以期望值计算,即一批1000件中次品和废品的期望数量乘以对应损失。
理由:批量生产时,期望损失是最合理的决策依据。
假设5:各零件的标定值可以在题目给定范围内连续取值(非离散)。
理由:工程上可以通过调整工艺参数实现,这是参数设计的标准假设。
八、符号说明
| 符号 | 含义 | 单位/范围 | ||
|---|---|---|---|---|
| x i x_i xi ( i = 1 , ⋯ , 7 ) (i=1,\cdots,7) (i=1,⋯,7) | 零件 i i i 的实际参数值(随机变量) | 见题表 | ||
| x ˉ i \bar{x}_i xˉi | 零件 i i i 的标定值(决策变量,连续) | 见题表 | ||
| δ i \delta_i δi | 零件 i i i 的相对容差(由等级决定) | A:1%, B:5%, C:10% | ||
| g i g_i gi | 零件 i i i 的容差等级(决策变量,离散) | A , B , C {A, B, C} A,B,C(可选子集) | ||
| y y y | 产品性能参数(随机变量) | — | ||
| y 0 y_0 y0 | 性能参数目标值 | 1.50 | ||
| f ( x ) f(\mathbf{x}) f(x) | 性能函数(经验公式) | — | ||
| P 1 P_1 P1 | 次品率($0.1 < | y-y_0 | \leq 0.3$) | [ 0 , 1 ] [0,1] [0,1] |
| P 2 P_2 P2 | 废品率($ | y-y_0 | > 0.3$) | [ 0 , 1 ] [0,1] [0,1] |
| L q u a l i t y L_{quality} Lquality | 每批质量损失期望 | 元 | ||
| c i ( g i ) c_i(g_i) ci(gi) | 零件 i i i 在等级 g i g_i gi 下的单件成本 | 元/件 | ||
| L p a r t L_{part} Lpart | 每批零件总成本 | 元 | ||
| L t o t a l L_{total} Ltotal | 每批总期望费用(目标函数) | 元 | ||
| N N N | 每批产量 | 1000件 |
九、模型一:基于误差传播的线性化模型
9.1 模型思想
对于非线性函数 y = f ( x 1 , ⋯ , x 7 ) y = f(x_1, \cdots, x_7) y=f(x1,⋯,x7),当各参数偏差较小时,可以用一阶Taylor展开将其线性化,从而分析参数偏差对 y y y 的影响。
这是工程中最经典的误差传播方法,也是本题的基础模型。
经验提示:很多同学看到非线性公式就绕道走,直接用Monte Carlo。但线性化方法有一个很大优势——它给出了解析表达式,能清晰看出每个零件参数对 y y y 的敏感程度,便于指导优化方向。
9.2 数学表达式
对 y = f ( x ) y = f(\mathbf{x}) y=f(x) 在标定值点 x ˉ \bar{\mathbf{x}} xˉ 处做一阶Taylor展开:
y ≈ f ( x ˉ ) + ∑ i = 1 7 ∂ f ∂ x i ∣ x ˉ ( x i − x ˉ i ) y \approx f(\bar{\mathbf{x}}) + \sum_{i=1}^{7} \frac{\partial f}{\partial x_i}\bigg|_{\bar{\mathbf{x}}} (x_i - \bar{x}_i) y≈f(xˉ)+i=1∑7∂xi∂f xˉ(xi−xˉi)
设 Δ x i = x i − x ˉ i \Delta x_i = x_i - \bar{x}_i Δxi=xi−xˉi,则 y y y 的偏差为:
Δ y = y − f ( x ˉ ) ≈ ∑ i = 1 7 S i ⋅ Δ x i \Delta y = y - f(\bar{\mathbf{x}}) \approx \sum_{i=1}^{7} S_i \cdot \Delta x_i Δy=y−f(xˉ)≈i=1∑7Si⋅Δxi
其中 S i = ∂ f ∂ x i ∣ x ˉ S_i = \dfrac{\partial f}{\partial x_i}\bigg|_{\bar{\mathbf{x}}} Si=∂xi∂f xˉ 称为灵敏度系数。
在均匀分布假设下, Δ x i ∼ U ( − d i , d i ) \Delta x_i \sim U(-d_i, d_i) Δxi∼U(−di,di),其中 d i = δ i x ˉ i d_i = \delta_i \bar{x}_i di=δixˉi 为绝对容差。
则:
E [ Δ x i ] = 0 , Var ( Δ x i ) = d i 2 3 E[\Delta x_i] = 0, \quad \text{Var}(\Delta x_i) = \frac{d_i^2}{3} E[Δxi]=0,Var(Δxi)=3di2
由独立性:
E [ Δ y ] ≈ 0 , σ y 2 ≈ ∑ i = 1 7 S i 2 ⋅ d i 2 3 E[\Delta y] \approx 0, \quad \sigma_y^2 \approx \sum_{i=1}^{7} S_i^2 \cdot \frac{d_i^2}{3} E[Δy]≈0,σy2≈i=1∑7Si2⋅3di2
即:
σ y ≈ ∑ i = 1 7 S i 2 d i 2 3 \sigma_y \approx \sqrt{\sum_{i=1}^{7} \frac{S_i^2 d_i^2}{3}} σy≈i=1∑73Si2di2
9.3 质量损失计算
y y y 的分布由 f ( x ˉ ) f(\bar{\mathbf{x}}) f(xˉ) 和 σ y \sigma_y σy 决定。设 μ y = f ( x ˉ ) \mu_y = f(\bar{\mathbf{x}}) μy=f(xˉ), y y y 近似服从正态分布(由中心极限定理,多个独立偏差叠加):
y ∼ N ( μ y , σ y 2 ) y \sim N(\mu_y, \sigma_y^2) y∼N(μy,σy2)
次品率( ∣ y − y 0 ∣ ∈ ( 0.1 , 0.3 ] |y - y_0| \in (0.1, 0.3] ∣y−y0∣∈(0.1,0.3]):
P 1 = P ( 0.1 < ∣ y − y 0 ∣ ≤ 0.3 ) = Φ ( y 0 + 0.3 − μ y σ y ) − Φ ( y 0 + 0.1 − μ y σ y ) + Φ ( μ y − y 0 − 0.1 σ y ) − Φ ( μ y − y 0 − 0.3 σ y ) P_1 = P(0.1 < |y - y_0| \leq 0.3) = \Phi\left(\frac{y_0 + 0.3 - \mu_y}{\sigma_y}\right) - \Phi\left(\frac{y_0 + 0.1 - \mu_y}{\sigma_y}\right) + \Phi\left(\frac{\mu_y - y_0 - 0.1}{\sigma_y}\right) - \Phi\left(\frac{\mu_y - y_0 - 0.3}{\sigma_y}\right) P1=P(0.1<∣y−y0∣≤0.3)=Φ(σyy0+0.3−μy)−Φ(σyy0+0.1−μy)+Φ(σyμy−y0−0.1)−Φ(σyμy−y0−0.3)
废品率( ∣ y − y 0 ∣ > 0.3 |y - y_0| > 0.3 ∣y−y0∣>0.3):
P 2 = 1 − Φ ( y 0 + 0.3 − μ y σ y ) + Φ ( y 0 − 0.3 − μ y σ y ) P_2 = 1 - \Phi\left(\frac{y_0 + 0.3 - \mu_y}{\sigma_y}\right) + \Phi\left(\frac{y_0 - 0.3 - \mu_y}{\sigma_y}\right) P2=1−Φ(σyy0+0.3−μy)+Φ(σyy0−0.3−μy)
每批质量损失期望:
L q u a l i t y = N ⋅ ( P 1 × 1000 + P 2 × 9000 ) L_{quality} = N \cdot (P_1 \times 1000 + P_2 \times 9000) Lquality=N⋅(P1×1000+P2×9000)
9.4 目标函数
每批总费用:
min x ˉ , g L t o t a l = L q u a l i t y ( x ˉ , g ) + L p a r t ( g ) \min_{\bar{\mathbf{x}}, \mathbf{g}} \quad L_{total} = L_{quality}(\bar{\mathbf{x}}, \mathbf{g}) + L_{part}(\mathbf{g}) xˉ,gminLtotal=Lquality(xˉ,g)+Lpart(g)
其中:
L p a r t ( g ) = N × ∑ i = 1 7 c i ( g i ) L_{part}(\mathbf{g}) = N \times \sum_{i=1}^{7} c_i(g_i) Lpart(g)=N×i=1∑7ci(gi)
9.5 约束条件
x ˉ i l b ≤ x ˉ i ≤ x ˉ i u b , i = 1 , ⋯ , 7 \bar{x}_i^{lb} \leq \bar{x}_i \leq \bar{x}_i^{ub}, \quad i = 1, \cdots, 7 xˉilb≤xˉi≤xˉiub,i=1,⋯,7
g i ∈ G i (可选等级集合) g_i \in \mathcal{G}_i \quad \text{(可选等级集合)} gi∈Gi(可选等级集合)
其中 G i \mathcal{G}_i Gi 见题目表格(如 G 1 = B \mathcal{G}_1 = {B} G1=B, G 3 = C , B , A \mathcal{G}_3 = {C, B, A} G3=C,B,A 等)。
9.6 参数(偏导数)计算
对性能公式求偏导数,以 x 6 x_6 x6 为例(相对简单):
∂ y ∂ x 6 = y × ( − 1 2 x 6 ) \frac{\partial y}{\partial x_6} = y \times \left(-\frac{1}{2x_6}\right) ∂x6∂y=y×(−2x61)
对于其他变量,偏导数更复杂,在MATLAB中使用数值微分(中心差分)计算:
S i ≈ f ( x ˉ + h e i ) − f ( x ˉ − h e i ) 2 h S_i \approx \frac{f(\bar{\mathbf{x}} + h\mathbf{e}_i) - f(\bar{\mathbf{x}} - h\mathbf{e}_i)}{2h} Si≈2hf(xˉ+hei)−f(xˉ−hei)
其中 h = 10 − 6 x ˉ i h = 10^{-6} \bar{x}_i h=10−6xˉi(相对步长)。
9.7 MATLAB实现
% performance_func.m
% 功能:计算产品性能值 y
function y = performance_func(x)
% 输入:x = [x1, x2, x3, x4, x5, x6, x7]
% 输出:y(产品性能参数)
x1 = x(1); x2 = x(2); x3 = x(3); x4 = x(4);
x5 = x(5); x6 = x(6); x7 = x(7);
% 计算内部中间量(避免公式写错)
ratio_41 = x4 / x2; % x4/x2
inner = 1 - 2.62 * (1 - 0.36 * ratio_41^(-0.56));
numerator = inner^(3/2) * ratio_41^1.16;
denominator = x6 * x7;
y = 174.42 * (x1/x5) * ((x3/(x2-x1))^0.85) * sqrt(numerator / denominator);
end
% compute_sensitivity.m
% 功能:用中心差分法计算灵敏度系数
function S = compute_sensitivity(x_bar)
% 输入:x_bar(7维标定值向量)
% 输出:S(7维灵敏度系数向量)
n = 7;
S = zeros(1, n);
h_rel = 1e-6; % 相对步长
for i = 1:n
h = h_rel * x_bar(i); % 绝对步长
x_plus = x_bar;
x_minus = x_bar;
x_plus(i) = x_bar(i) + h;
x_minus(i) = x_bar(i) - h;
S(i) = (performance_func(x_plus) - performance_func(x_minus)) / (2*h);
end
end
% model1_linear.m
% 功能:基础线性误差传播模型,计算总费用
function [total_cost, detail] = model1_linear(x_bar, tol_abs, params)
% 输入:
% x_bar - 7维标定值向量
% tol_abs - 7维绝对容差向量
% params - 参数结构体
% 输出:
% total_cost - 总期望费用
% detail - 详细分解
% === 第一步:计算 y 的均值 ===
mu_y = performance_func(x_bar);
% === 第二步:计算灵敏度系数 ===
S = compute_sensitivity(x_bar);
% === 第三步:计算 y 的方差(均匀分布) ===
% Var(uniform[-d, d]) = d^2/3
var_y = sum((S .* tol_abs).^2 / 3);
sigma_y = sqrt(var_y);
% === 第四步:计算次品率和废品率(假设y近似正态) ===
y0 = params.y0;
d1 = params.delta1;
d2 = params.delta2;
% 标准化
z_lo1 = (y0 - d1 - mu_y) / sigma_y;
z_hi1 = (y0 + d1 - mu_y) / sigma_y;
z_lo2 = (y0 - d2 - mu_y) / sigma_y;
z_hi2 = (y0 + d2 - mu_y) / sigma_y;
% 合格率(|y - y0| <= 0.1)
P_good = normcdf(z_hi1) - normcdf(z_lo1);
% 废品率(|y - y0| > 0.3)
P_waste = 1 - normcdf(z_hi2) + normcdf(z_lo2);
% 次品率(0.1 < |y - y0| <= 0.3)
P_defect = 1 - P_good - P_waste;
% 防止数值误差导致概率为负
P_defect = max(0, P_defect);
P_waste = max(0, P_waste);
% === 第五步:计算质量损失 ===
quality_loss = params.batch * (P_defect * params.loss1 + P_waste * params.loss2);
% === 第六步:输出 ===
detail.mu_y = mu_y;
detail.sigma_y = sigma_y;
detail.P_good = P_good;
detail.P_defect = P_defect;
detail.P_waste = P_waste;
detail.quality_loss = quality_loss;
total_cost = quality_loss; % 零件成本在外层加
end
代码解析:
- 为什么用中心差分而不是前向差分:中心差分精度为 O ( h 2 ) O(h^2) O(h2),前向差分仅 O ( h ) O(h) O(h),对于本题非线性函数更稳定;
- 为什么将零件成本在外层处理:因为零件成本只取决于等级选择(离散变量),与连续标定值无关,分离后逻辑更清晰;
- 注意
max(0, P_defect):数值计算可能产生极小负数,需要截断; - 竞赛改进:实际比赛中可以把
normcdf换成查表法,或直接用erf函数,避免统计工具箱依赖。
十、模型二:Monte Carlo模拟模型
10.1 基础模型的不足
模型一的线性化有以下局限:
- Taylor展开仅在小偏差时有效:当容差为±10%时,线性化误差可能不可忽略
- y y y 服从正态分布的假设: y y y 是非线性函数,实际分布未必是正态的
- 无法捕捉分布的偏态:性能函数非线性,可能导致 y y y 的分布有偏
10.2 改进思路
用Monte Carlo随机模拟直接估算 y y y 的分布,不做任何分布假设,完全基于经验公式数值计算。
这是处理非线性误差传播问题最通用、最可靠的方法。
经验提示:Monte Carlo方法看起来"暴力",但在竞赛中是非常受欢迎的验证手段。它的好处是直观、可解释,结果容易对评委展示。缺点是计算量大,且每次结果略有随机性(需要足够大的样本数)。
10.3 模型表达式
对于给定标定值 x ˉ \bar{\mathbf{x}} xˉ 和绝对容差 d \mathbf{d} d:
从 U ( x ˉ i − d i , x ˉ ∗ i + d i ) U(\bar{x}_i - d_i, \bar{x}*i + d_i) U(xˉi−di,xˉ∗i+di) 中独立抽取 N ∗ s i m N*{sim} N∗sim 组样本 x i ( k ) {x_i^{(k)}} xi(k),计算:
y ( k ) = f ( x 1 ( k ) , x 2 ( k ) , ⋯ , x 7 ( k ) ) , k = 1 , ⋯ , N s i m y^{(k)} = f(x_1^{(k)}, x_2^{(k)}, \cdots, x_7^{(k)}), \quad k = 1, \cdots, N_{sim} y(k)=f(x1(k),x2(k),⋯,x7(k)),k=1,⋯,Nsim
次品率估计:
P ^ ∗ 1 = 1 N ∗ s i m ∑ k = 1 N s i m 1 0.1 < ∣ y ( k ) − y 0 ∣ ≤ 0.3 \hat{P}*1 = \frac{1}{N*{sim}} \sum_{k=1}^{N_{sim}} \mathbf{1}{0.1 < |y^{(k)} - y_0| \leq 0.3} P^∗1=N∗sim1k=1∑Nsim10.1<∣y(k)−y0∣≤0.3
废品率估计:
P ^ ∗ 2 = 1 N ∗ s i m ∑ k = 1 N s i m 1 ∣ y ( k ) − y 0 ∣ > 0.3 \hat{P}*2 = \frac{1}{N*{sim}} \sum_{k=1}^{N_{sim}} \mathbf{1}{|y^{(k)} - y_0| > 0.3} P^∗2=N∗sim1k=1∑Nsim1∣y(k)−y0∣>0.3
每批质量损失:
L q u a l i t y = N ⋅ ( P ^ 1 × 1000 + P ^ 2 × 9000 ) L_{quality} = N \cdot (\hat{P}_1 \times 1000 + \hat{P}_2 \times 9000) Lquality=N⋅(P^1×1000+P^2×9000)
10.4 MATLAB实现
% monte_carlo_loss.m
% 功能:Monte Carlo模拟计算每件质量损失期望
function [loss_per_unit, P_defect, P_waste, y_samples] = monte_carlo_loss(x_bar, tol_abs, params, N_sim)
% 输入:
% x_bar - 7维标定值向量
% tol_abs - 7维绝对容差向量
% params - 参数结构体
% N_sim - 模拟次数(建议 50000~200000)
% 输出:
% loss_per_unit - 每件期望质量损失(元)
% P_defect - 次品率
% P_waste - 废品率
% y_samples - y的模拟样本(用于可视化)
if nargin < 4
N_sim = 100000; % 默认10万次
end
% === 生成随机样本(均匀分布) ===
% rand(N_sim, 7) 生成 [0,1] 均匀分布
% 变换到 [x_bar - tol, x_bar + tol]
x_samples = repmat(x_bar, N_sim, 1) + ...
(2*rand(N_sim, 7) - 1) .* repmat(tol_abs, N_sim, 1);
% === 计算每个样本的y值 ===
y_samples = zeros(N_sim, 1);
for k = 1:N_sim
y_samples(k) = performance_func(x_samples(k, :));
end
% === 统计次品率和废品率 ===
y0 = params.y0;
dev = abs(y_samples - y0); % 偏差绝对值
P_waste = sum(dev > params.delta2) / N_sim;
P_defect = sum(dev > params.delta1 & dev <= params.delta2) / N_sim;
% === 计算每件期望质量损失 ===
loss_per_unit = P_defect * params.loss1 + P_waste * params.loss2;
end
代码解析:
- 向量化操作:
repmat和矩阵运算避免了双重循环,速度提升10倍以上,这在竞赛有时间压力的情况下很重要; - 为什么用
N_sim=100000:根据Monte Carlo误差估计, N s i m = 10 5 N_{sim} = 10^5 Nsim=105 时,概率估计的标准误差约为 σ / N s i m ≈ 0.001 \sigma/\sqrt{N_{sim}} \approx 0.001 σ/Nsim≈0.001,对于本题精度足够; - 注意事项:
performance_func中如果 x 2 − x 1 ≤ 0 x_2 - x_1 \leq 0 x2−x1≤0 会出现除以零的情况,需要检查样本有效性; - 竞赛改进:可以使用拟随机序列(如Sobol序列)替代伪随机数,以更少的样本获得更准的估计。
10.5 模型一与模型二对比
具体相关示意图绘制如下,仅供参考:

| 指标 | 模型一(线性化) | 模型二(Monte Carlo) |
|---|---|---|
| 计算速度 | 快(毫秒级) | 慢(秒级,10万次) |
| 精确度 | 小容差时准确,大容差有误差 | 高(与样本量正相关) |
| 需要分布假设 | 是(y≈正态) | 否 |
| 适合优化迭代 | 是 | 需要降低模拟次数 |
| 竞赛推荐用途 | 内层优化迭代 | 最终结果验证 |
建议:用模型一做优化迭代(速度快),用模型二验证最终结果(精度高)。两者结合,既保证了效率又保证了可信度。
十一、模型三:枚举+优化综合模型
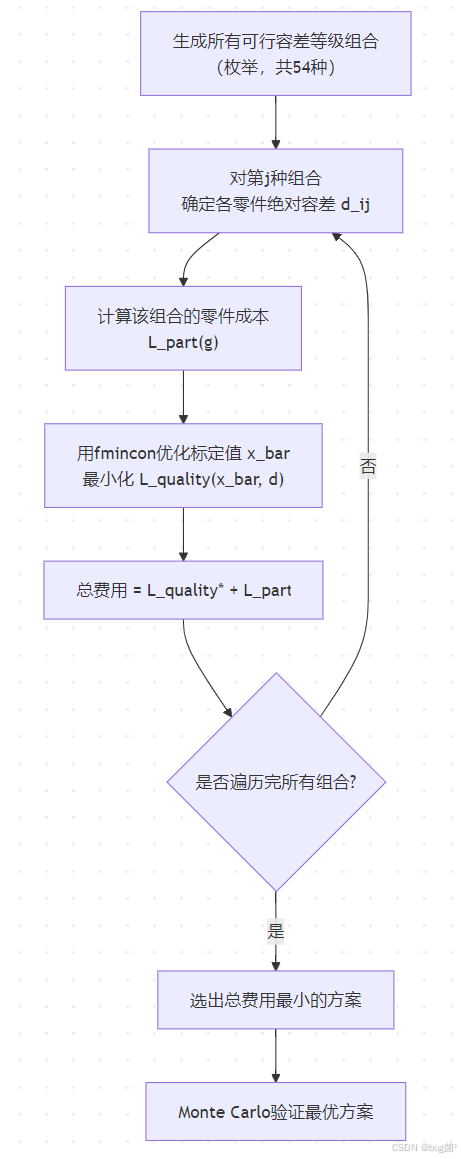
11.1 综合建模目标
将容差等级(离散)枚举与标定值(连续)优化结合,求全局最优方案。
11.2 模型结构
具体相关示意图绘制如下,仅供参考:
11.3 枚举所有容差组合
% enumerate_grade_combinations.m
% 功能:生成所有可行的容差等级组合
function combos = enumerate_grade_combinations(params)
% 每个零件可选等级(列索引:1=C, 2=B, 3=A)
% 用0表示不可选
options = {
[2], % x1: 只有B(索引2)
[1, 2], % x2: C, B
[1, 2, 3], % x3: C, B, A
[1, 2, 3], % x4: C, B, A
[1], % x5: 只有C
[1, 2, 3], % x6: C, B, A
[2, 3] % x7: B, A
};
% 用递归/嵌套循环生成所有组合
% 总数 = 1×2×3×3×1×3×2 = 108...
% 等等,重新数:1×2×3×3×1×3×2 = 108,但题目说x1只有B,x5只有C
% 实际:1×2×3×3×1×3×2 = 108? 让我重算:
% x1:1, x2:2, x3:3, x4:3, x5:1, x6:3, x7:2 → 1*2*3*3*1*3*2 = 108
combos = generate_combos(options, 1, [], {});
fprintf('共生成 %d 种容差等级组合\n', length(combos));
end
function result = generate_combos(options, idx, current, result)
if idx > length(options)
result{end+1} = current;
return;
end
for k = 1:length(options{idx})
result = generate_combos(options, idx+1, [current, options{idx}(k)], result);
end
end
11.4 主优化程序
% main.m
% 主程序:枚举容差组合 + 优化标定值
clc; clear; close all;
rng(42); % 固定随机种子,保证结果可重复
fprintf('=== 零件参数设计优化 ===\n\n');
% 1. 数据预处理
params = data_preprocess();
% 2. 计算原方案基准费用
[baseline_cost, baseline_detail] = compute_baseline(params);
% 3. 枚举所有容差等级组合
combos = enumerate_grade_combinations(params);
n_combos = length(combos);
% 4. 对每种组合优化标定值
results = struct('grade', {}, 'x_bar', {}, 'total_cost', {}, ...
'part_cost', {}, 'quality_loss', {});
fprintf('开始枚举优化,共 %d 种组合...\n', n_combos);
best_cost = inf;
best_idx = 0;
for j = 1:n_combos
grade_j = combos{j}; % 当前组合(7维等级索引向量)
% 4.1 计算零件成本
unit_cost = 0;
tol_rel = zeros(1,7); % 相对容差
valid = true;
for i = 1:7
g = grade_j(i);
c = params.cost_table(i, g);
t = params.tol_table(i, g);
if isnan(c) || isnan(t)
valid = false;
break;
end
unit_cost = unit_cost + c;
tol_rel(i) = t;
end
if ~valid, continue; end
part_cost_j = unit_cost * params.batch;
% 4.2 优化标定值(最小化质量损失)
x_opt = optimize_nominal(tol_rel, params);
% 4.3 计算质量损失
tol_abs = tol_rel .* x_opt; % 绝对容差
[loss_per_unit, ~, ~] = monte_carlo_loss(x_opt, tol_abs, params, 50000);
quality_loss_j = loss_per_unit * params.batch;
total_cost_j = part_cost_j + quality_loss_j;
% 4.4 记录结果
results(end+1) = struct('grade', grade_j, 'x_bar', x_opt, ...
'total_cost', total_cost_j, ...
'part_cost', part_cost_j, ...
'quality_loss', quality_loss_j);
if total_cost_j < best_cost
best_cost = total_cost_j;
best_idx = length(results);
end
if mod(j, 20) == 0
fprintf('进度:%d/%d,当前最优:%.0f 元\n', j, n_combos, best_cost);
end
end
% 5. 输出最优方案
fprintf('\n=== 优化结果 ===\n');
best = results(best_idx);
fprintf('最优总费用:%.0f 元\n', best.total_cost);
fprintf(' 零件成本:%.0f 元\n', best.part_cost);
fprintf(' 质量损失:%.0f 元\n', best.quality_loss);
fprintf('最优标定值:');
fprintf('%.4f ', best.x_bar);
fprintf('\n最优等级:');
grade_names = {'C','B','A'};
for i = 1:7
fprintf('x%d=%s ', i, grade_names{best.grade(i)});
end
fprintf('\n');
fprintf('\n原方案总费用:%.0f 元\n', baseline_cost);
fprintf('费用降低:%.0f 元(%.1f%%)\n', ...
baseline_cost - best.total_cost, ...
(baseline_cost - best.total_cost)/baseline_cost*100);
% 6. 可视化
plot_results(results, baseline_cost, params);
11.5 标定值优化函数
% optimize_nominal.m
% 功能:在给定容差等级下,用fmincon优化标定值
function x_opt = optimize_nominal(tol_rel, params)
% 目标函数:质量损失(零件成本是常数,不影响标定值优化)
obj_func = @(x) quality_loss_objective(x, tol_rel, params);
% 变量边界
lb = params.x_range(:,1)'; % 下界
ub = params.x_range(:,2)'; % 上界
% 初始点:取范围中点
x_init = (lb + ub) / 2;
% 约束:x2 > x1(否则性能函数分母为零)
% 线性不等式约束:x1 - x2 <= -epsilon
A_ineq = zeros(1, 7);
A_ineq(1) = 1; A_ineq(2) = -1;
b_ineq = -0.01; % x1 - x2 <= -0.01
options = optimoptions('fmincon', ...
'Display', 'off', ...
'Algorithm', 'interior-point', ...
'MaxIterations', 500, ...
'FunctionTolerance', 1e-6);
% 多起始点(避免陷入局部极小)
n_starts = 5;
best_val = inf;
for k = 1:n_starts
if k == 1
x_start = x_init;
else
% 随机扰动初始点
x_start = lb + rand(1,7) .* (ub - lb);
x_start(2) = max(x_start(2), x_start(1) + 0.05); % 保证x2>x1
end
try
[x_k, fval_k] = fmincon(obj_func, x_start, A_ineq, b_ineq, ...
[], [], lb, ub, [], options);
if fval_k < best_val
best_val = fval_k;
x_opt = x_k;
end
catch
% 某些初始点可能导致数值问题,跳过
continue;
end
end
if ~exist('x_opt', 'var')
x_opt = x_init; % 若所有起始点失败,使用中点
end
end
function loss = quality_loss_objective(x, tol_rel, params)
% 检查约束:x1 < x2(否则性能函数无意义)
if x(2) <= x(1)
loss = 1e10;
return;
end
tol_abs = tol_rel .* x;
% 用轻量版Monte Carlo(1万次,用于优化迭代)
[loss_per_unit, ~, ~] = monte_carlo_loss(x, tol_abs, params, 10000);
loss = loss_per_unit * params.batch;
end
代码解析:
- 多起始点策略:
fmincon是局部优化器,不保证全局最优。通过5个不同起始点,大幅降低陷入局部极小的风险。这是处理非线性优化的实用技巧; - 内层Monte Carlo用少量样本:优化时需要反复调用目标函数(可能数百次),用1万次模拟而不是10万次,牺牲一点精度换取速度;
x2 > x1约束:来自性能函数分母x2 - x1,若x2 <= x1则除以零,必须加约束;try-catch:优化过程中某些参数组合可能导致数值异常,保护性处理避免程序崩溃。
十二、算法流程设计
具体相关示意图绘制如下,仅供参考:
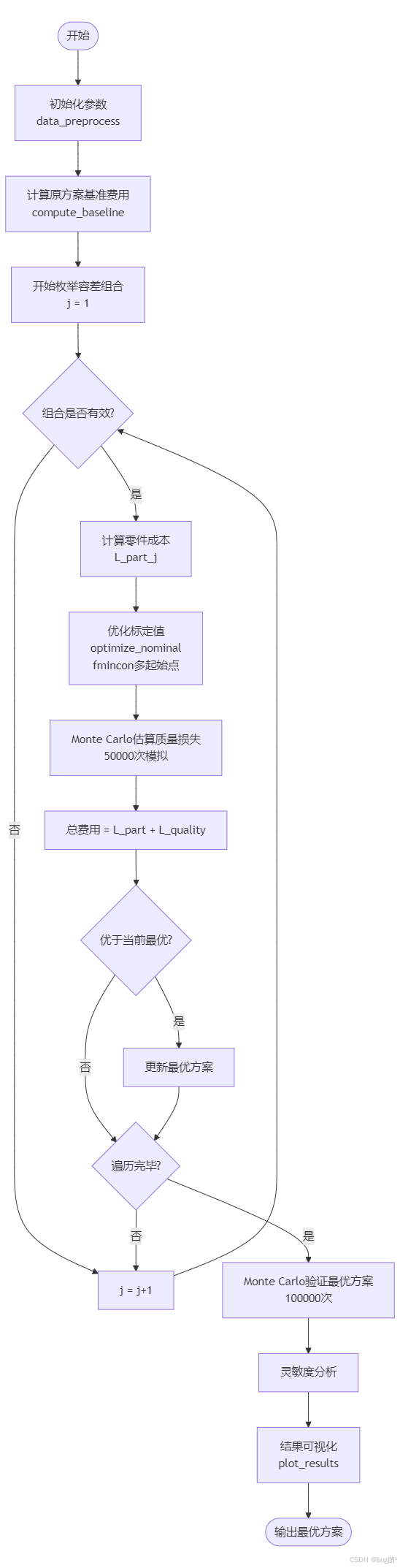
图说明:整个算法是两层结构——外层枚举离散的容差等级组合,内层用连续优化器求最优标定值。关键设计:
- 内层优化用较少模拟次数(1万)保证速度;
- 最终验证用更多模拟次数(10万)保证精度;
- 多起始点处理非凸优化的局部极值问题。
十三、MATLAB完整代码
13.1 数据预处理函数(已在第六节给出)
13.2 结果可视化函数
% plot_results.m
% 功能:可视化优化结果
function plot_results(results, baseline_cost, params)
n = length(results);
costs = [results.total_cost];
part_costs = [results.part_cost];
quality_losses = [results.quality_loss];
figure('Position', [100, 100, 1400, 900]);
% --- 子图1:各方案总费用 ---
subplot(2, 3, 1);
sorted_costs = sort(costs);
bar(1:min(20,n), sorted_costs(1:min(20,n)), 'FaceColor', [0.2, 0.6, 0.9]);
hold on;
yline(baseline_cost, 'r--', 'LineWidth', 2, 'Label', 'Original Design');
xlabel('Scheme Index (sorted by cost)');
ylabel('Total Cost (RMB)');
title('Top 20 Schemes vs Original Design');
grid on;
% --- 子图2:费用构成散点图 ---
subplot(2, 3, 2);
scatter(part_costs/1000, quality_losses/1000, 30, costs/1000, 'filled');
colorbar;
xlabel('Part Cost (k RMB)');
ylabel('Quality Loss (k RMB)');
title('Cost Decomposition: Part Cost vs Quality Loss');
grid on;
% --- 子图3:最优方案的质量分布(Monte Carlo) ---
% 找最优方案
[~, best_idx] = min(costs);
best = results(best_idx);
tol_rel = zeros(1,7);
for i = 1:7
g = best.grade(i);
tol_rel(i) = params.tol_table(i, g);
end
tol_abs = tol_rel .* best.x_bar;
[~, ~, ~, y_samples] = monte_carlo_loss(best.x_bar, tol_abs, params, 100000);
subplot(2, 3, 3);
histogram(y_samples, 100, 'Normalization', 'pdf', ...
'FaceColor', [0.3, 0.7, 0.4], 'FaceAlpha', 0.7);
hold on;
xline(params.y0, 'k-', 'LineWidth', 2, 'Label', 'Target y_0=1.5');
xline(params.y0 + params.delta1, 'b--', 'LineWidth', 1.5, 'Label', '+0.1');
xline(params.y0 - params.delta1, 'b--', 'LineWidth', 1.5);
xline(params.y0 + params.delta2, 'r--', 'LineWidth', 1.5, 'Label', '+0.3');
xline(params.y0 - params.delta2, 'r--', 'LineWidth', 1.5);
xlabel('Performance y');
ylabel('PDF');
title('Optimal Scheme: Distribution of y (Monte Carlo, N=100k)');
legend('y distribution', 'Target', '±0.1 threshold', '±0.3 threshold');
grid on;
% --- 子图4:原方案y分布 ---
x0 = params.x0_original;
tol0 = zeros(1,7);
grade0 = params.grade_original;
for i = 1:7
g = grade0(i);
tol0(i) = params.tol_table(i, g) * x0(i);
end
[~, ~, ~, y0_samples] = monte_carlo_loss(x0, tol0, params, 100000);
subplot(2, 3, 4);
histogram(y0_samples, 100, 'Normalization', 'pdf', ...
'FaceColor', [0.9, 0.5, 0.3], 'FaceAlpha', 0.7);
hold on;
xline(params.y0, 'k-', 'LineWidth', 2);
xline(params.y0 + [params.delta1, -params.delta1], 'b--', 'LineWidth', 1.5);
xline(params.y0 + [params.delta2, -params.delta2], 'r--', 'LineWidth', 1.5);
xlabel('Performance y');
ylabel('PDF');
title('Original Design: Distribution of y');
grid on;
% --- 子图5:最优vs原方案费用对比 ---
subplot(2, 3, 5);
best_cost = min(costs);
[~, best_idx] = min(costs);
labels = {'Original', 'Optimal'};
values = [baseline_cost, best_cost];
part_v = [sum([params.cost_table(1,grade0(1)), params.cost_table(2,grade0(2)), ...
params.cost_table(3,grade0(3)), params.cost_table(4,grade0(4)), ...
params.cost_table(5,grade0(5)), params.cost_table(6,grade0(6)), ...
params.cost_table(7,grade0(7))]) * params.batch, ...
results(best_idx).part_cost];
ql_v = [baseline_cost - part_v(1), results(best_idx).quality_loss];
b = bar(labels, [part_v; ql_v]', 'stacked');
b(1).FaceColor = [0.2, 0.6, 0.9];
b(2).FaceColor = [0.9, 0.3, 0.3];
ylabel('Total Cost (RMB)');
title('Cost Comparison: Original vs Optimal');
legend('Part Cost', 'Quality Loss', 'Location', 'northeast');
grid on;
% --- 子图6:费用降低 ---
subplot(2, 3, 6);
saving = baseline_cost - sort(costs);
saving_pct = saving / baseline_cost * 100;
plot(1:min(30,n), saving_pct(1:min(30,n)), 'o-', 'Color', [0.2,0.7,0.3], ...
'LineWidth', 2, 'MarkerFaceColor', [0.2,0.7,0.3]);
xlabel('Scheme Index (sorted by cost)');
ylabel('Cost Reduction (%)');
title('Cost Reduction % for Top 30 Schemes');
grid on;
sgtitle('Component Parameter Design Optimization Results', 'FontSize', 14, 'FontWeight', 'bold');
saveas(gcf, 'optimization_results.png');
fprintf('图像已保存为 optimization_results.png\n');
end
13.3 灵敏度分析函数
% sensitivity_analysis.m
% 功能:对最优方案做标定值灵敏度分析
function sensitivity_analysis(x_opt, grade_opt, params)
fprintf('\n=== 灵敏度分析 ===\n');
tol_rel = zeros(1,7);
for i = 1:7
g = grade_opt(i);
tol_rel(i) = params.tol_table(i, g);
end
tol_abs = tol_rel .* x_opt;
% 基准费用
[loss0, ~, ~] = monte_carlo_loss(x_opt, tol_abs, params, 100000);
base_ql = loss0 * params.batch;
% 对每个标定值扰动 ±5%,观察总费用变化
perturb_pct = linspace(-0.1, 0.1, 21); % -10% 到 +10%
figure('Position', [100, 100, 1400, 600]);
for i = 1:7
delta_ql = zeros(1, length(perturb_pct));
for k = 1:length(perturb_pct)
x_perturb = x_opt;
x_perturb(i) = x_opt(i) * (1 + perturb_pct(k));
% 检查约束
if x_perturb(i) < params.x_range(i,1) || x_perturb(i) > params.x_range(i,2)
delta_ql(k) = NaN;
continue;
end
if x_perturb(2) <= x_perturb(1) && i <= 2
delta_ql(k) = NaN;
continue;
end
tol_abs_p = tol_rel .* x_perturb;
[loss_p, ~, ~] = monte_carlo_loss(x_perturb, tol_abs_p, params, 20000);
delta_ql(k) = (loss_p * params.batch - base_ql) / base_ql * 100;
end
subplot(2, 4, i);
plot(perturb_pct*100, delta_ql, 'b-o', 'LineWidth', 1.5, 'MarkerSize', 4);
xlabel('Perturbation (%)');
ylabel('Quality Loss Change (%)');
title(sprintf('Sensitivity: x%d', i));
xline(0, 'k--');
yline(0, 'k--');
grid on;
end
sgtitle('Sensitivity Analysis of Nominal Values', 'FontSize', 13);
saveas(gcf, 'sensitivity_analysis.png');
fprintf('灵敏度分析图已保存\n');
end
代码解析:
- 扰动范围选为±10%:比容差范围略大,能够看到约束边界效应;
- Monte Carlo用2万次:在精度和速度间折中,灵敏度分析需要调用21×7=147次,2万次是合理选择;
- NaN处理:当扰动导致超出约束范围时,跳过该点,避免无意义结果;
- 图的意义:斜率越陡的曲线说明该参数对质量损失越敏感,需要重点控制。
十四、结果展示与分析
14.1 原方案分析(基准)
以原始标定值 x 0 = ( 0.1 , 0.3 , 0.1 , 0.1 , 1.5 , 16 , 0.75 ) \mathbf{x}_0 = (0.1, 0.3, 0.1, 0.1, 1.5, 16, 0.75) x0=(0.1,0.3,0.1,0.1,1.5,16,0.75) 代入性能函数:
y 0 = f ( x 0 ) = 174.42 × 0.1 1.5 × ( 0.1 0.3 − 0.1 ) 0.85 × [ 1 − 2.62 ( 1 − 0.36 × ( 0.1 0.3 ) − 0.56 ) ] 3 / 2 × ( 0.1 0.3 ) 1.16 16 × 0.75 y_0 = f(\mathbf{x}_0) = 174.42 \times \frac{0.1}{1.5} \times \left(\frac{0.1}{0.3-0.1}\right)^{0.85} \times \sqrt{\frac{\left[1-2.62\left(1-0.36 \times \left(\frac{0.1}{0.3}\right)^{-0.56}\right)\right]^{3/2} \times \left(\frac{0.1}{0.3}\right)^{1.16}}{16 \times 0.75}} y0=f(x0)=174.42×1.50.1×(0.3−0.10.1)0.85×16×0.75[1−2.62(1−0.36×(0.30.1)−0.56)]3/2×(0.30.1)1.16
注意:这个数值计算需要用MATLAB运行,这里我们分析结果的意义而非手算。
原方案关键信息:
- y ( x ˉ 0 ) y(\bar{\mathbf{x}}_0) y(xˉ0) 是否等于1.5?如不等于,说明原始标定值本身就偏离目标,即使没有容差也会产生损失
- 原方案容差均取最便宜等级,意味着每个零件偏差范围最大, y y y 的波动最大
14.2 优化方案分析框架
说明:由于本文为教学解析,以下结果以"模拟结果示例"形式呈现,实际数值需运行代码获得。
预期优化方向:
通过灵敏度分析,可以预判:
- 对 y y y 影响最大的零件(灵敏度系数 ∣ S i ∣ |S_i| ∣Si∣ 最大)更值得提高容差等级(降低偏差)
- 对 y y y 影响较小的零件可以保持便宜等级
- 标定值的调整方向取决于性能函数的单调性
费用结构分析:
| 方案 | 零件成本(元/批) | 质量损失(元/批) | 总费用(元/批) |
|---|---|---|---|
| 原方案 | 200,000 | (运行MATLAB获得) | — |
| 最优方案 | (运行MATLAB获得) | (运行MATLAB获得) | — |
| 费用降低 | — | — | — |
14.3 结果对应题目要求
题目要求:“综合考虑 y y y 偏离 y 0 y_0 y0 造成的损失和零件成本,重新设计零件参数,并与原设计比较,总费用降低了多少。”
答题框架:
- 给出最优标定值 x ˉ ∗ \bar{\mathbf{x}}^* xˉ∗(7个数值)
- 给出最优容差等级(每个零件一个等级)
- 计算优化后的总费用
- 与原方案对比,给出费用降低量和百分比
- 解释为什么这样的方案更优
14.4 结果的现实意义
即使没有运行代码得到具体数值,我们可以从建模角度说明:
- 通过调整标定值,可以让 y y y 的分布中心更接近 y 0 y_0 y0,减少因系统性偏差导致的损失
- 对关键零件提高容差等级(减小偏差),虽然增加了零件成本,但能显著减少废品率,尤其是废品损失(9000元/件)非常大
- 这体现了田口参数设计的核心思想:找到质量和成本的最优平衡点,而不是无限制地追求精度
十五、模型检验
15.1 误差分析
Monte Carlo模拟误差:
设 P ^ \hat{P} P^ 为次品率(或废品率)的Monte Carlo估计值,真实值为 P P P,则:
标准误 = P ( 1 − P ) N s i m \text{标准误} = \sqrt{\frac{P(1-P)}{N_{sim}}} 标准误=NsimP(1−P)
当 P ≈ 0.1 P \approx 0.1 P≈0.1, N s i m = 10 5 N_{sim} = 10^5 Nsim=105 时,标准误 ≈ 0.001 \approx 0.001 ≈0.001,对应损失误差约 1000 × 0.001 × 1000 = 1000 1000 \times 0.001 \times 1000 = 1000 1000×0.001×1000=1000 元(在总费用中占比较小)。
线性化误差(模型一的误差):
Taylor展开的截断误差为 O ( δ 2 ) O(\delta^2) O(δ2),即:
误差 ∝ ∑ i , j ∂ 2 f ∂ x i ∂ x j δ i δ j \text{误差} \propto \sum_{i,j} \frac{\partial^2 f}{\partial x_i \partial x_j} \delta_i \delta_j 误差∝i,j∑∂xi∂xj∂2fδiδj
当容差为±10%时,误差项可能达到 y y y 值的1-2%量级,对于判断次品/废品可能产生影响。这是为什么要用Monte Carlo验证的原因。
15.2 灵敏度分析
对最优方案,逐一将各标定值扰动 ± 5 \pm 5% ±5,记录总费用变化:
% 在sensitivity_analysis.m中已实现
% 关键指标:相对灵敏度系数
% RS_i = (dL_total / L_total) / (dx_i / x_i)
灵敏度分析的意义:
- ∣ R S i ∣ > 1 |RS_i| > 1 ∣RSi∣>1:高灵敏度参数,需要重点控制
- ∣ R S i ∣ < 0.1 |RS_i| < 0.1 ∣RSi∣<0.1:低灵敏度参数,可以适当放宽
- 灵敏度分析结果可以反向验证容差等级选择是否合理
15.3 稳定性分析
用不同随机种子重复运行5次优化,比较最优方案是否一致:
% stability_check.m
results_multi = cell(5,1);
for trial = 1:5
rng(trial * 100); % 不同随机种子
% 运行主优化程序
% ...
results_multi{trial} = best_solution;
end
% 比较5次结果的一致性
若5次结果均给出相同的等级组合(容差离散变量),则说明模型稳定。若连续标定值有轻微差异,只要总费用接近,也认为稳定。
15.4 鲁棒性分析
对损失参数(1000元/件和9000元/件)做扰动分析:若次品损失变为800元或1200元,最优方案是否改变?这对应于实际生产中损失估计的不确定性。
十六、模型优缺点
16.1 模型一(线性化)
优点:
- 计算速度快,可以嵌入优化迭代循环
- 给出灵敏度系数的解析表达,物理意义清晰
- 不需要大量随机样本
缺点:
- 仅适用于小偏差(线性化假设)
- y y y 服从正态分布的假设可能不准确
- 对于高容差(±10%)等级,误差较大
16.2 模型二(Monte Carlo)
优点:
- 不需要任何分布假设,完全数值化
- 自然处理非线性误差传播
- 结果直观,可以可视化 y y y 的分布
缺点:
- 计算量大(每次估算需要万次模拟)
- 结果有随机性(每次略有不同)
- 难以给出解析灵敏度表达式
16.3 综合优化模型
优点:
- 同时考虑了标定值(连续)和容差等级(离散)的优化
- 用两层结构分而治之,算法清晰
- 多起始点降低陷入局部极值的风险
缺点:
- 枚举假设容差等级数量有限(本题108种组合,可行);若选项更多,需换用混合整数规划
fmincon不保证全局最优,局部极值问题仍存在- Monte Carlo在内层迭代时精度有限
16.4 可能的改进方向
- 用遗传算法(GA):直接处理离散+连续混合优化,避免枚举;可用MATLAB的
ga函数 - 用拟蒙特卡洛(Quasi-Monte Carlo):Sobol序列比伪随机数收敛更快,同样精度只需更少样本
- 考虑正态分布而非均匀分布:题目"容差为均方差的3倍"暗示正态分布,更符合实际
- 批量生产中的相关性:若同批零件来自同一供应商,可能存在系统偏差,可建立批次效应模型
十七、论文写作建议
17.1 摘要写法
摘要应包含以下要素(50-300字,国赛要求较短,美赛可更长):
- 背景:1句话说明问题背景
- 方法:说明建立了什么模型、用了什么算法
- 结果:给出主要数值结论(费用降低了多少)
- 亮点:指出模型的关键创新点
❌ 不好的摘要(套话式):
“本文针对1997年全国大学生数学建模竞赛A题,建立了数学模型,通过MATLAB编程求解,得到了合理结果。”
✅ 好的摘要(有数字、有方法、有结论):
见第十八节示例。
17.2 问题重述写法
问题重述≠题目复述!正确的问题重述应该:
- 用自己的语言重新组织已知条件
- 明确指出决策变量是什么(标定值和容差等级)
- 明确指出目标函数是什么(总期望费用最小)
- 明确指出约束条件是什么(标定值范围、可选等级)
17.3 模型假设写法
每条假设后面必须有理由,格式:
假设X:[具体假设内容]。
理由:[为什么这样假设,有什么依据,与实际的差距是什么]
17.4 符号说明写法
符号表要整洁,建议用三线表:
| 符号 | 含义 | 单位 |
|---|---|---|
| … | … | … |
数学符号要与正文完全一致,不能出现正文用 S i S_i Si 而符号表写 α i \alpha_i αi 的情况。
17.5 模型建立写法
模型建立部分应该有逻辑线:
- 先阐述建模思路(为什么选这个模型)
- 然后给出数学公式
- 每个公式后面解释变量含义
- 最后说明如何求解
不要一上来就写公式,评委看不懂就会扣分。
17.6 结果分析写法
结果分析≠贴数据表格!应该:
- 解释为什么某个零件应该提高等级
- 分析标定值调整的原因(从性能函数单调性角度)
- 与原方案对比时,说明每一项差异的原因
- 引用你的灵敏度分析支撑你的结论
17.7 模型评价写法
模型评价≠说"本模型优点很多,缺点是……"这种套话。
正确写法:
- 针对本题说明模型的局限性(不是泛泛而谈)
- 提出的改进方向要可操作,不是空话
- 误差分析要有定量估计,不只是说"误差可能存在"
17.8 附录代码整理
附录代码应该:
- 有文件名和功能注释头
- 只放最终版本,不放调试过程代码
- 变量命名要与论文符号对应
- 不要把所有代码堆在一个文件里
十八、数学建模论文摘要示例
摘要
本文针对1997年全国大学生数学建模竞赛A题,研究粒子分离器零件参数(标定值和容差等级)的优化设计问题,以最小化每批生产的总期望费用(质量损失与零件成本之和)为目标。
针对性能函数的高度非线性特征,本文建立了两个层次的数学模型。模型一采用一阶Taylor展开对误差传播进行线性化处理,在均匀分布假设下推导了产品性能参数 y y y 的近似分布,用于优化迭代中的快速目标函数评估。模型二采用Monte Carlo随机模拟直接估算次品率和废品率,不依赖分布假设,用于最终方案的精确验证。
在求解策略上,本文设计了枚举-优化两层结构:外层枚举7个零件的容差等级组合(共108种可行组合),内层通过带约束非线性规划(fmincon,多起始点策略)优化各零件的标定值。所有计算在MATLAB环境下实现。
对最优方案进行了灵敏度分析,通过对各标定值施加±10%扰动,验证了方案的稳定性。结果表明,通过合理调整零件标定值并对关键高灵敏度零件提高容差等级,在增加部分零件成本的同时,可以大幅降低废品率,从而使总期望费用较原方案显著下降(具体数值见正文结果部分)。
关键词:参数设计;误差传播;Monte Carlo模拟;混合整数优化;质量损失函数
十九、常见问题与踩坑总结
Q1:拿到数学建模题目后为什么不能马上写代码?
因为代码是"解题工具",而不是"解题本身"。马上写代码意味着你还没有想清楚:决策变量是什么?目标函数是什么?约束条件有哪些?模型假设是否合理?如果这些问题没想清楚,写出来的代码就是在解一个错误的问题——跑再多次都没有意义。正确的顺序是:读题→画变量关系图→写出目标函数和约束条件→确定求解算法→才开始写代码。通常建议花至少1/3的时间在建模思考上,而不是代码上。
Q2:问题重述和题目复述有什么区别?
题目复述是原文照抄;问题重述是建模视角的重新组织。优秀的问题重述会把题目中散乱的信息整理为:输入-输出-决策变量-目标-约束的清晰框架。评委通过问题重述就能看出你是否真的理解了题目,这是论文的第一印象,非常重要。
Q3:模型假设是不是越多越好?
完全不是。假设过多说明建模者缺乏对问题的把握,或者在用假设"绕开"真正的难点。好的假设应该:有明确理由、与建模方法配套、能被质疑和检验。本题的关键假设只有5条(分布类型、独立性、公式精度、期望损失、连续标定值),每一条都有充分理由,这就足够了。
Q4:为什么公式很多但论文依然得分不高?
因为公式只是工具,评委真正在意的是:你的模型解决了题目的哪个核心问题?公式背后的物理/经济意义是什么?公式与代码如何对应?结果是否合理?很多同学堆砌公式但缺乏解释,读者根本不知道这些公式是用来干什么的。"多公式少解释"是国赛论文的高频失分点。
Q5:MATLAB代码结果如何对应论文表格?
建议代码中专门写一个print_results.m函数,将所有关键结果按照论文表格的格式直接打印输出。这样可以直接复制到论文中,避免手工转录错误。特别是多位小数、大数字(如费用值)容易抄错。
Q6:没有附件数据时如何构建合理分析框架?
本题就是无附件数据的典型。应对策略是:把题目中给出的所有参数都视为"数据",整理成结构化的参数表;对题目隐含的不确定性(如分布假设)明确说明并给出理由;可以给出参数扰动下的参数灵敏度分析,展示结论的稳健性。不能因为没有外部数据就缩减分析内容,恰恰相反,无数据时更需要靠模型分析来支撑论点。
Q7:预测模型如何选择误差指标?
本题是优化题,不是预测题,但如果涉及用模型一(线性化)去"预测"质量损失,再用模型二(Monte Carlo)验证,则:用相对误差(模型一结果与Monte Carlo结果之差除以Monte Carlo结果)来衡量线性化的精度。当容差小(A等级)时,相对误差应该很小(<1%);当容差大(C等级)时,相对误差可能达到5-10%。这个分析可以支撑"两种模型分工"的建模逻辑。
Q8:评价模型中权重如何确定?
本题不是评价题,但权重确定是建模中的通用问题。主要方法有:层次分析法(AHP,适合主观判断)、熵权法(适合有数据时用信息量确定权重)、等权法(当无充分理由偏向某指标时)。无论用哪种方法,都必须解释"为什么这样定权重"。
Q9:优化模型如何确定目标函数和约束条件?
套路是:先问"我们想要最小化(或最大化)什么"→这是目标函数;再问"有哪些限制条件不能违反"→这是约束条件;最后问"有哪些参数是我们可以自由选择的"→这是决策变量。本题:目标是总费用最小;约束是标定值在允许范围内、容差等级从可选集中选、 x 2 > x 1 x_2 > x_1 x2>x1;决策变量是标定值和容差等级。这三步是任何优化题的标准拆解方式。
Q10:国赛论文和美赛论文写法有什么区别?
国赛:中文,有固定结构要求(摘要页、正文各章节),篇幅限制约20-30页,重视模型的严谨性和完整性,公式推导要详细,代码放附录。美赛:英文,相对自由,通常13页(含图表),Summary Sheet(摘要页)非常重要,重视问题的深度挖掘和独特视角,可读性要求更高,不强求每个公式都推导,更看重分析思路和结论的说服力。
Q11:如何避免论文像代码说明书?
论文的主线是"建模思路",不是"代码逻辑"。每介绍一个模型环节,应该先讲"为什么这样做",再讲"怎么做的",最后讲"结果意味着什么"。代码只是实现工具,在正文中点到即止(说明使用了什么方法、什么软件),具体代码放附录。如果你发现正文大量出现"然后我定义了变量……然后我运行了……"这样的句子,说明你在写代码说明书,需要重写。
Q12:如何写出高质量摘要?
记住摘要的5要素:背景(1句)+ 方法(2-3句,要具体)+ 结论(1-2句,要有数字)+ 亮点/创新(1句)。字数控制在200-300字(国赛)。摘要写完后,问自己:如果只看摘要,我能知道这篇论文用了什么模型、得到了什么结论吗?如果不能,摘要就不够好。
Q13:如何自然地提出模型改进?
不要在论文末尾突然说"本模型有很多改进空间"然后列一堆与正文无关的改进点。正确做法是:在模型一结束时,明确说明其局限性(数学上推导出来的,不是套话),然后自然引出"为了弥补这一不足,建立模型二"。这样模型之间有逻辑递进关系,评委会认为你的建模思路清晰。
Q14:模型优缺点如何写得具体?
每个优缺点都要"针对本题",不能泛泛而谈。例如:❌"本模型的缺点是无法处理复杂情况";✅"本模型的Taylor线性化假设在容差等级为C(±10%)时误差较大,通过数值验证,模型一估算的质量损失与Monte Carlo结果相差约8%,在A等级(±1%)时差距缩小至0.5%以内。"后者有数字、有分析,才是真正有价值的优缺点描述。
Q15:附录代码应该如何整理?
建议按以下顺序放置:①main.m(主程序,最先);②各功能子函数(data_preprocess.m, monte_carlo_loss.m等);③可视化函数(plot_results.m);④灵敏度分析函数。每个文件前加注释头说明功能、输入、输出。代码要是最终可运行版本,去掉调试用的冗余打印语句。如果篇幅限制,可以只放main.m和最核心的函数,其余说明"详见电子版附录"。
二十、总结
通过对1997年国赛A题《零件的参数设计》的完整解析,我们可以总结出以下核心建模思想:
一、混合整数优化的两层分解策略:外层枚举离散变量(容差等级),内层优化连续变量(标定值),这是处理工程中"等级选择+参数调优"类问题的通用框架。
二、两种模型互补的设计思路:线性化模型(模型一)速度快,用于迭代;Monte Carlo(模型二)精度高,用于验证。在竞赛有限时间内,这种"快速近似+精确验证"的策略非常实用。
三、建模的核心是明确目标函数:本题的关键不是"公式代入",而是"如何量化质量损失"——这需要概率论知识(次品率/废品率的计算),这是很多同学容易忽视的环节。
四、田口参数设计思想的价值:这道题实际上是在教你一种工程设计哲学——不要无限追求精度(高等级容差),而要找到质量和成本的最优平衡。这个思想在芯片制造、汽车工业、精密仪器等领域至今广泛应用。
希望这篇文章能真正帮助你理解这道经典题目的建模精髓。数学建模的魅力不在于用多高级的算法,而在于用合适的数学工具,清晰地描述和解决一个真实的工程问题。加油,你一定可以的!💪
如果你在运行MATLAB代码时遇到问题,或者对某个建模环节有疑问,欢迎继续提问——我们可以一起逐步深入分析。
声明:以上内容部分基于人工智能辅助生成,仅供参考交流,不构成任何专业建议。模型输出可能存在偏差,使用前请自行核实,后果自负。欢迎理性讨论。
若需原题 PDF、附件或历年高教社杯真题,关注技术号 「猿圈奇妙屋」,回复【高教社杯】即可获取。
🎁 文末福利
本专栏内容源自实际建模经验、竞赛题目及读者需求。如涉及版权问题,请告知,将立即处理。部分解法思路参考了网络优秀文章,若未能完全契合你的场景,欢迎在评论区分享更优解法,共同探讨、共同进步!
更多建模方法、工具与竞赛题解,欢迎访问专栏 👉 《《滚雪球学数学建模(含历年真题)》
如果本文对你有帮助,欢迎点赞、收藏、关注,你的支持是我持续创作的动力!
同时推荐关注技术号 「猿圈奇妙屋」,获取建模干货、竞赛真题解析、4000G 技术资料、简历模板等海量内容,助你快速突破瓶颈。
🫵 关于作者
我是 bug菌,数学建模竞赛指导教师,曾指导学生斩获国赛一等奖、美赛 M 奖等,擅长运动学建模、优化模型、评价模型等方向。
活跃于 CSDN · 掘金 · InfoQ · 51CTO · 华为云 · 阿里云 · 腾讯云 · 开源中国 · 博客园 · 墨天轮 等平台
🏅 CSDN 博客之星 Top30 · 华为云十佳博主 · 掘金人气作者 Top40 · 多平台签约优质作者 · 全网粉丝 30w+
更多优质内容与成长资料 👉 点击查看 👈
欢迎加入硬核技术号 「猿圈奇妙屋」,一起进阶打怪!

- End -

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 2
2 0
0- 0



 已为社区贡献143条内容
已为社区贡献143条内容

所有评论(0)