又快又准!FasterViT玩转图像与视频分类(附完整源码)
引言
在计算机视觉领域,想要同时兼顾模型的推理速度和分类精度,一直是开发者的核心诉求。而FasterViT的出现,完美解决了这一痛点——它融合了卷积神经网络(CNN)的局部特征提取优势,以及视觉Transformer的全局注意力机制,既能保证高精度,又能实现超快推理。

今天这篇教程,我们将手把手带你从环境搭建到代码实战,完整掌握FasterViT在图像分类和视频分类中的应用,所有代码均可直接复用,新手也能轻松上手!
一、FasterViT:兼顾速度与精度的混合视觉模型
1.1 什么是FasterViT?
FasterViT是一款混合架构的视觉模型,核心思路是“先卷积,后注意力”:先用CNN提取图像的局部特征(比如边缘、纹理、形状),再通过Transformer风格的注意力模块捕捉图像的长距离依赖关系(即图像不同区域的关联)。这种设计让它既具备CNN的高效性,又拥有Transformer的全局理解能力,是兼顾速度与精度的最优解之一。
1.2 FasterViT的核心优势:精度与吞吐量双优
在这里插入图片描述
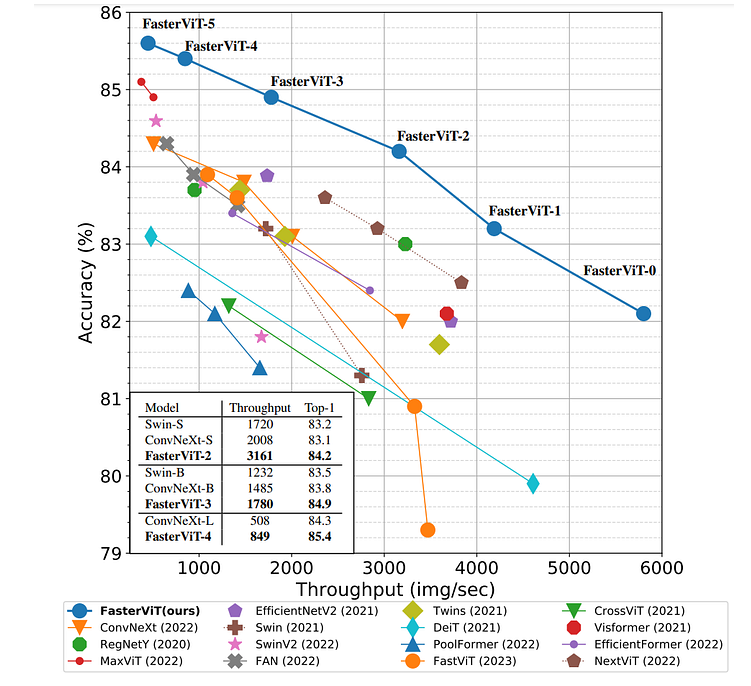
吞吐量(每秒可处理的图像数量)是衡量模型推理速度的核心指标,而Top-1 ImageNet准确率则是分类精度的关键参考。
从实测数据来看,FasterViT系列(从FasterViT-0到FasterViT-5)在精度逐步提升的同时,吞吐量远优于Swin、ConvNeXt、EfficientNetV2等主流模型。比如FasterViT-2能以3161张/秒的吞吐量实现84.2%的Top-1准确率,FasterViT-3则以1780张/秒的吞吐量达到84.9%的准确率——同等精度下,速度优势十分显著。这也让FasterViT特别适合边缘设备、实时视频分析、大规模推理等对效率要求高的场景。
二、FasterViT的工作原理
在这里插入图片描述
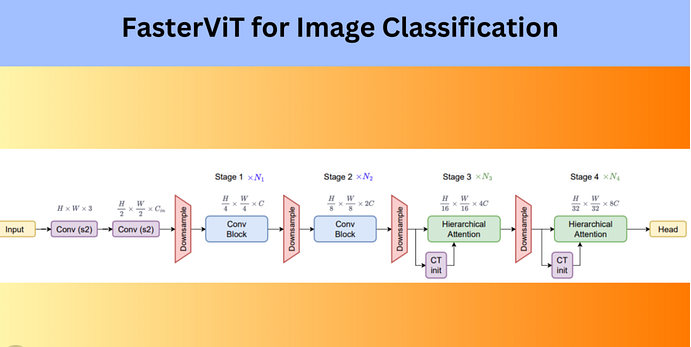
FasterViT的推理流程可拆解为以下步骤:
-
初始卷积下采样:通过两层步长为2的卷积层对图像下采样,提取边缘、纹理等基础局部特征,同时降低空间分辨率、提升通道维度(特征维度)。
-
卷积特征提取阶段:前两个阶段使用标准卷积块重复提取特征,逐步检测更复杂的图像模式,阶段间的下采样模块进一步压缩空间尺寸、增强特征表达能力。
-
分层注意力模块阶段:第三、四阶段替换为分层注意力模块,引入Transformer的注意力机制,捕捉图像长距离依赖关系(比如“车轮”和“车身”的关联),这也是FasterViT混合架构的核心亮点。
-
分类头输出:最后通过池化层和分类层,将学习到的特征转换为各类别的概率,完成分类任务。
简单来说,FasterViT的设计思路是“先做局部特征压缩,再做全局关系建模”,既保证效率,又不丢精度。
为方便大家学习 这里给大家整理了一份学习资料包 需要的同学 根据下图自取即可

三、实战准备:环境搭建
在开始代码实战前,我们需要先搭建适配的Python环境,重点是安装带CUDA支持的PyTorch(支持GPU加速)和FasterViT相关依赖。
步骤1:创建并激活conda环境
# 创建名为fasterVit的conda环境,指定Python 3.11
conda create -n fasterVit python=3.11
# 激活环境
conda activate fasterVit
# 查看系统CUDA版本(确保后续PyTorch版本匹配)
nvcc --version
步骤2:安装核心依赖
# 安装PyTorch 2.5.0(适配CUDA 12.4)
conda install pytorch==2.5.0 torchvision==0.20.0 torchaudio==2.5.0 pytorch-cuda=12.4 -c pytorch -c nvidia
# 安装FasterViT及配套库
pip install fastervit==0.9.8
pip install timm==0.9.12
pip install matplotlib
pip install opencv-python==4.10.0.84
四、手把手实战:FasterViT图像分类
环境搭建完成后,我们从单张图像分类开始,完整走一遍“加载模型→预处理图像→推理→解析结果”的流程。
4.1 模型加载与图像预处理

在这里插入图片描述
首先加载预训练的FasterViT模型,并定义图像预处理流程(保证输入格式符合模型要求):
import torch
from torchvision import transforms
from PIL import Image
from fastervit import create_model
# 加载预训练的FasterViT-0模型(输入尺寸224x224,适配ImageNet 1000类)
model = create_model(
"faster_vit_0_224",
pretrained=True,
model_path="d:/temp/models/faster_vit_0.pth.tar" # 模型权重路径可自行调整
)
# 设为评估模式(关闭训练相关的层,如Dropout)
model.eval()
# 定义图像预处理流程(与模型训练时的预处理保持一致)
preprocess = transforms.Compose([
transforms.Resize(256), # 缩放图像短边至256
transforms.CenterCrop(224), # 中心裁剪至224x224
transforms.ToTensor(), # 转换为张量
transforms.Normalize( # 标准化(匹配ImageNet训练数据分布)
mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225]
),
])
# 加载并预处理单张图像
image_path = "Basketball.jpg" # 替换为你的图像路径
img = Image.open(image_path)
input_tensor = preprocess(img)
input_batch = input_tensor.unsqueeze(0) # 添加批次维度(模型要求批量输入)
4.2 推理执行与结果解析
将模型和输入数据移至GPU/CPU,执行推理并将原始输出转换为可读的类别概率:
# 选择计算设备(GPU优先)
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model.to(device)
input_batch = input_batch.to(device)
# 执行推理(关闭梯度追踪,节省内存、提升速度)
with torch.no_grad():
output = model(input_batch)
# 将原始输出转换为类别概率(softmax)
prob = torch.nn.functional.softmax(output[0], dim=0)
# 获取概率最高的前5个类别
top5_prob, top5_catid = torch.topk(prob, 5)
for i in range(top5_prob.size(0)):
print(f"类别ID:{top5_catid[i]}, 概率:{top5_prob[i].item():.4f}")
# 下载ImageNet类别名称并映射(可选,将ID转为可读名称)
import json
import requests
# 加载ImageNet类别映射
url = "https://raw.githubusercontent.com/anishathalye/imagenet-simple-labels/master/imagenet-simple-labels.json"
response = requests.get(url)
class_names = json.loads(response.text)
# 映射类别ID到名称
class_idx = {i: class_names[i] for i in range(len(class_names))}
# 保存映射文件(方便后续复用)
with open("imagenet_class_index.json", "w") as f:
json.dump(class_idx, f)
4.3 结果可视化
将预测结果直接标注在图像上,直观验证分类效果:
import matplotlib.pyplot as plt
# 显示图像(隐藏坐标轴)
plt.imshow(img)
plt.axis('off')
# 获取概率最高的类别
top_prob, top_catid = torch.topk(prob, 1)
predicted_class_id = top_catid[0].item()
predicted_class_name = class_idx[predicted_class_id]
probability = top_prob[0].item()
# 在图像上标注预测结果
plt.text(
20, 20,
f"预测类别:{predicted_class_name}(概率:{probability:.4f})",
color='white',
backgroundcolor='black',
fontsize=12,
bbox=dict(facecolor='black', alpha=0.5)
)
# 显示标注后的图像
plt.show()
五、进阶应用:FasterViT视频分类
视频分类的核心思路是“逐帧处理”——将视频的每一帧当作单张图像分类,再实时标注结果。以下是完整代码:
import cv2
# 加载视频文件(替换为你的视频路径)
video_path = "Airplane.mp4"
cap = cv2.VideoCapture(video_path)
# 检查视频是否成功打开
if not cap.isOpened():
print("错误:无法打开视频文件!")
exit()
# 设置视频输出尺寸
output_width = 640
output_height = 480
# 逐帧处理视频
while cap.isOpened():
ret, frame = cap.read()
if not ret: # 无帧可读时退出循环
break
# 调整帧尺寸
frame = cv2.resize(frame, (output_width, output_height))
# 将OpenCV的BGR格式转为RGB(匹配PIL格式)
img = Image.fromarray(cv2.cvtColor(frame, cv2.COLOR_BGR2RGB))
# 预处理帧(与图像分类一致)
input_tensor = preprocess(img)
input_batch = input_tensor.unsqueeze(0).to(device)
# 推理
with torch.no_grad():
output = model(input_batch)
probs = torch.nn.functional.softmax(output[0], dim=0)
# 获取预测结果
top_prob, top_catid = torch.topk(probs, 1)
predicted_class_id = top_catid[0].item()
predicted_class_name = class_idx[predicted_class_id]
probability = top_prob[0].item()
# 在帧上标注结果
cv2.putText(
frame,
f'类别:{predicted_class_name}',
(10, 30),
cv2.FONT_HERSHEY_SIMPLEX,
1, (0, 255, 0), 2
)
cv2.putText(
frame,
f'概率:{probability:.4f}',
(10, 70),
cv2.FONT_HERSHEY_SIMPLEX,
1, (0, 255, 0), 2
)
# 显示标注后的帧
cv2.imshow("FasterViT视频分类", frame)
# 按Q键退出
if cv2.waitKey(1) & 0xFF == ord('q'):
break
# 释放资源
cap.release()
cv2.destroyAllWindows()
六、高频问题解答
-
Q:为什么要对图像做Resize和CenterCrop?A:保证所有输入图像的尺寸与模型训练时一致(224x224),避免尺寸不匹配导致推理错误,同时让输入数据标准化,提升模型稳定性。
-
Q:归一化(Normalize)的作用是什么?A:让图像像素值匹配模型训练时的数据分布,能显著提升分类精度和模型收敛性。
-
Q:with torch.no_grad()有什么用?A:关闭梯度追踪,减少内存占用,同时提升推理速度(推理阶段无需计算梯度)。
-
Q:FasterViT可以微调吗?A:可以!本文聚焦于预训练模型的推理,若需适配自定义数据集,可基于现有模型做微调训练。
-
Q:GPU加速的优势是什么?A:相比CPU,GPU能将推理速度提升数倍甚至数十倍,尤其适合视频实时分类等对速度要求高的场景。
七、总结
本文从理论到实战,完整讲解了FasterViT的核心原理和落地步骤:从环境搭建到单张图像分类,再到视频实时分类,整套流程兼顾了易用性和实用性。
FasterViT的混合架构让它在“速度-精度”权衡中脱颖而出,无论是静态图像分析还是动态视频处理,都能满足工业级应用的需求。希望这篇教程能帮你快速上手FasterViT,把它应用到实际的计算机视觉项目中!
为方便大家学习 这里给大家整理了一份学习资料包 需要的同学 根据下图自取即可


AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 9
9 0
0- 0



 已为社区贡献24条内容
已为社区贡献24条内容

所有评论(0)