一个 Token 的完整旅程:从输入到输出,揭秘大模型内部工作流程
一个 Token 的完整旅程:从输入到输出,揭秘大模型内部工作流程 🚀
导读:你是否好奇,当你在聊天框输入一句话时,大模型内部发生了什么?本文将带你追踪一个 token 从进入模型到生成回复的完整旅程,揭开 LLM 的神秘面纱!

🗺️ 前言:为什么要理解 Token 的旅程?
在之前的三篇文章中,我们深入拆解了 Transformer 的各个组件(Attention、FFN、Embedding 等)。但单独看每个部分就像只看汽车的零件——你知道发动机怎么工作,却不知道整辆车如何行驶。
真正的 LLM 是一条精密的流水线:文字进去,概率出来,一步步生成流畅的回复。
今天,我们将以第一视角追踪一个 token 的完整旅程,看看它从输入到输出都经历了什么!这将帮助你:
- 🎯 建立全局认知:理解各组件如何协同工作
- 🔧 定位优化点:知道性能瓶颈在哪里
- 💡 启发创新思路:在合适的环节尝试改进
准备好了吗?让我们开始这场奇妙的旅程!✨
📥 第一站:输入层 - 文字的"数字化" transformation
1.1 Tokenizer:把文字切成模型能理解的碎片
当你输入 “我想吃苹果” 时,模型并不能直接理解这些汉字。首先需要经过 Tokenizer(分词器) 把文本切成一个个 token(词元)。
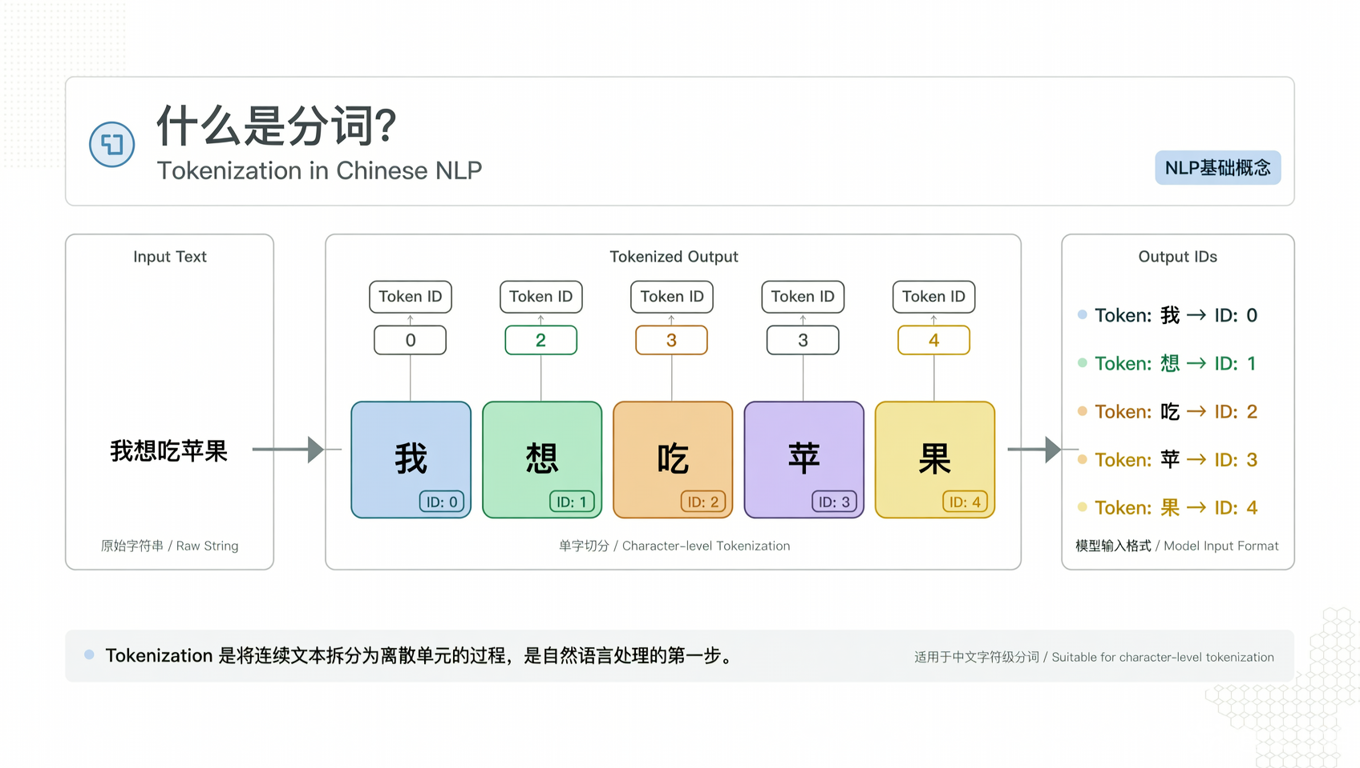
原始输入: "我想吃苹果"
↓ Tokenizer
Token序列: ["我", "想", "吃", "苹果"]
Token ID: [1024, 2048, 3072, 5432]
三种 Tokenization 策略对比
| 策略 | 示例 | 优点 | 缺点 |
|---|---|---|---|
| 字符级 | “我”|“想”|“吃”|“苹”|“果” | 词汇表小 | 序列长,效率低 |
| 词语级 | “我”|“想”|“吃”|“苹果” | 语义清晰 | 未登录词问题 |
| 子词级 (BPE/WordPiece) | “我”|“想”|“吃”|“苹果” | 平衡灵活 | 实现复杂 |
现代大模型的选择:绝大多数采用 子词级别 的 Tokenization(如 BPE、Unigram LM),在词汇量(通常 30K-100K)和表达能力之间取得平衡。
💡 小知识:GPT-4 的词表大小约 100K,LLaMA 约 32K。中文 token 通常比英文更"贵",因为一个汉字的信息密度更高。
1.2 Embedding:查表获得语义向量
每个 token ID 会通过 Embedding 层 查找对应的向量表示:
# 伪代码示例:Embedding 过程
vocab_size = 32000 # 词表大小
embedding_dim = 4096 # 向量维度(LLaMA-2-7B)
# 1. 查找 token 对应的 ID
token_id = vocab["苹果"] # 例如: 5432
# 2. 从 embedding 矩阵中查表
embedding_matrix = nn.Embedding(vocab_size, embedding_dim)
token_embedding = embedding_matrix[token_id] # 得到 4096 维向量
这个 4096 维的向量 包含了 “苹果” 这个词的语义信息:
- 它是一种水果 🍎
- 也可以是科技公司 📱
- 上下文会决定具体含义
Embedding 的本质
可以把 Embedding 看作一个巨大的查找表:
Token ID → [0.12, -0.45, 0.78, ..., 0.33] (4096 维)
训练过程中,这个表会不断更新,让语义相近的词向量距离更近(比如 “苹果” 和 “梨” 的向量会很相似)。
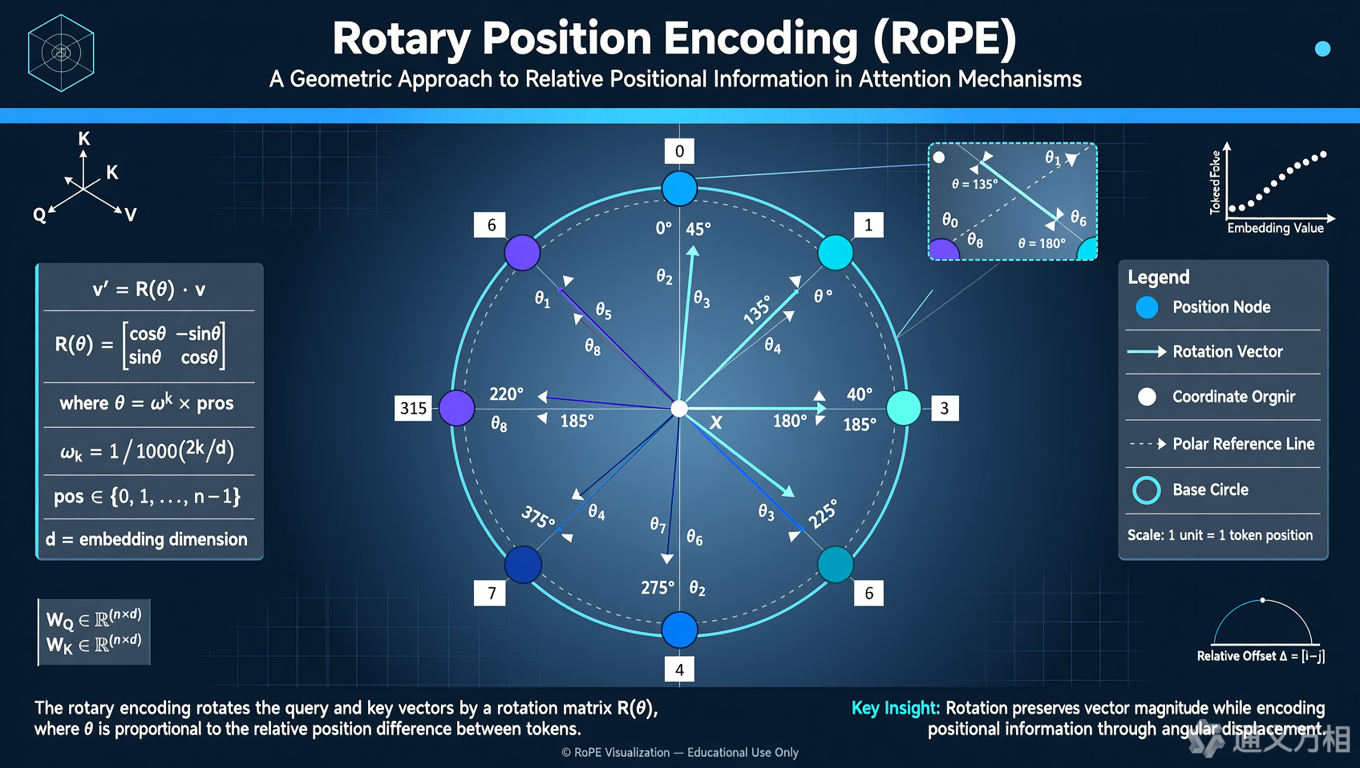
1.3 RoPE 位置编码:告诉模型"顺序很重要"
Transformer 有个致命缺陷:它本身不知道 token 的顺序!
"我想吃苹果" 和 "苹果吃我想"
对纯 Attention 来说是一样的 ❌
所以需要加入 位置编码(Position Encoding):
# 最终输入向量 = Token Embedding + 位置编码
final_input = token_embedding + position_encoding(position=3)
为什么选择 RoPE?
现代大模型(LLaMA、PaLM 等)普遍使用 RoPE(Rotary Position Embedding,旋转位置编码),原因是:
| 特性 | 传统位置编码 | RoPE |
|---|---|---|
| 相对位置感知 | ❌ 弱 | ✅ 强 |
| 外推能力 | ❌ 差 | ✅ 好 |
| 计算复杂度 | O(n) | O(n) |
RoPE 的核心思想:通过旋转矩阵给不同位置的 token 注入角度信息,让模型能更好地捕捉相对位置关系。
✅ 到这一步,模型拿到的是同时包含 “什么意思” 和 “在什么位置” 的输入向量,可以进入核心加工厂了!
🔄 第二站:Transformer Block - 核心加工厂
接下来,向量会进入堆叠的 Transformer Block(可能有 32 层、64 层甚至更多)。每个 Block 主要做三件事:
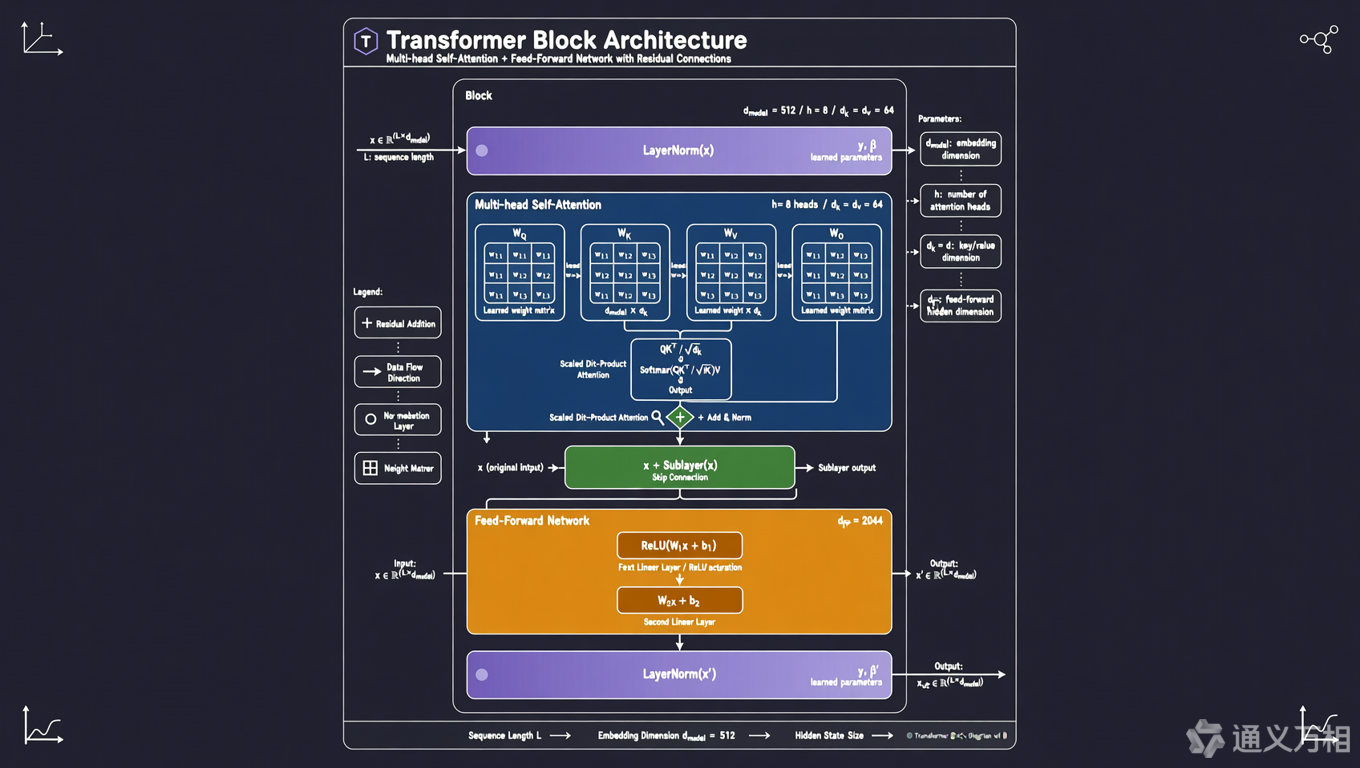
2.1 Attention:Token 之间互相"交流信息"
Self-Attention(自注意力机制) 让每个 token 都能看到其他 token,建立上下文联系:
输入: "我想吃苹果"
Attention 过程:
"我" ←→ "想" (代词找动词)
"想" ←→ "吃" (助动词找主要动词)
"吃" ←→ "苹果" (动词找宾语)
Attention 的三大职责
- 从别人那里拿信息:每个 token 收集其他 token 的相关信息
- 建立依赖关系:识别语法结构(主谓宾、定状补)
- 带上下文回家:融合全局信息形成新的表示
关键技术优化
在实际工程中,Attention 有多个重要优化:
| 技术 | 作用 | 效果 |
|---|---|---|
| KV Cache | 缓存历史计算的 K 和 V | 推理速度提升 2-3 倍 |
| FlashAttention | 优化内存访问模式 | 显存减少 20%,速度提升 3 倍 |
| Multi-Head | 多头并行关注不同方面 | 表达能力大幅提升 |
| Grouped Query | 分组共享 Key/Value | 平衡性能和效果 |
🔍 深入理解:Attention 的输出仍然是 4096 维向量,但现在每个向量都融合了整个句子的上下文信息。
2.2 FFN(前馈网络):对每个 Token 单独"深加工"
Attention 之后,每个 token 会经过 Feed-Forward Network(前馈神经网络):
# 简化的 FFN 结构(LLaMA 使用 SwiGLU)
def forward(x):
# 第一步:升维(4096 → 11008)
x = Linear1(x)
# 第二步:非线性激活(SwiGLU)
x = swiglu_activation(x)
# 第三步:降维(11008 → 4096)
x = Linear2(x)
return x
FFN 的核心职责
- 信息再加工:把 Attention 收集的混合信息进行深度处理
- 非线性变换:引入复杂的函数映射能力
- 知识存储:模型大部分参数其实在这里! 💪
⚠️ 惊人事实:在 LLaMA-2-7B 中,FFN 占据了约 67% 的参数(约 47 亿参数),而 Attention 只占约 25%。
前沿优化:MoE(Mixture of Experts)
传统 FFN 每次推理都要激活所有参数,而 MoE 采用稀疏激活:
传统 FFN:所有样本都用同一组参数
MoE FFN:不同样本路由到不同的"专家"网络
优势:
- 参数量可以扩大 10 倍(如 Mixtral 8x7B)
- 推理成本只增加 2-3 倍
- 效果显著提升
2.3 残差连接 + LayerNorm:让深层网络能"跑稳"
# Pre-Norm 架构(现代模型主流)
output = attention_input + Attention(LayerNorm(attention_input))
output = ffn_input + FFN(LayerNorm(ffn_input))
这两个组件至关重要:
| 组件 | 作用 | 不用的后果 |
|---|---|---|
| 残差连接 | 让信息跨层传递,防止梯度消失 | 超过 10 层就训练不动 |
| LayerNorm | 稳定每层的输入分布 | 训练震荡,难以收敛 |
⚠️ 没有这两样,几十层甚至上百层的网络,梯度早崩了!这是 Transformer 能堆这么深的关键秘诀。
2.4 层层递进:从字面到任务的抽象升级
Transformer Block 会堆叠很多次,不同层学习不同抽象级别的信息:
第 1-8 层(低层):学字面信息
├─ 词性标注(名词、动词...)
├─ 局部语法(短语结构)
└─ 基础语义(词义消歧)
第 9-24 层(中层):学句法结构
├─ 从句关系
├─ 指代消解("他"指的是谁)
└─ 逻辑关系(因果、转折)
第 25-32 层(高层):学任务目标
├─ 整体语义理解
├─ 意图识别
└─ 任务特定特征(翻译、问答等)
🎯 类比理解:就像阅读理解,先看字词(低层),再看句子结构(中层),最后理解主旨(高层)。
📤 第三站:输出层 - 隐藏状态变概率
3.1 Final Hidden State → Logits
经过所有 Transformer Block 后,最后一个 token 的 final hidden state 会被送到输出层:
# 假设最后一个 token 的隐藏状态
last_hidden_state = [0.23, -0.56, 0.89, ..., 0.12] # 4096 维
# 通过线性层映射到词表大小
vocab_size = 32000
logits = Linear(last_hidden_state) # 输出 32000 维向量
这 32000 维的 logits 对应词表中每个词的"得分"。
3.2 Softmax:变成概率分布
import torch
probabilities = torch.softmax(logits, dim=-1)
假设词表里只有几个词,预测 “我想吃___” 后面可能得到:
概率分布:
- "苹果":8%
- "饭":15%
- "面":5%
- "火锅":25%
- "烧烤":12%
- "..." :35%(其他所有词)
📊 可视化想象:就像一个有 32000 个格子的长条,每个格子代表一个词,高度代表被选中的概率。
3.3 解码策略:决定选哪个词
有了概率分布,还需要解码策略来选择下一个 token。不同的策略会产生不同的效果:
| 策略 | 原理 | 适用场景 | 示例 |
|---|---|---|---|
| Greedy | 永远选概率最大的 | 确定性任务(翻译) | “火锅”(25%) |
| Top-k | 从前 k 个中随机采样 | 需要多样性 | 从 top 50 中选 |
| Top-p | 累积概率达 p 的集合中采样 | 对话生成 | p=0.9 动态调整 |
| Temperature | 调节概率分布的平滑度 | 控制创造性 | T=0.7 平衡 |
Temperature 的神奇效果
# Temperature 如何改变概率分布
def apply_temperature(logits, temperature):
scaled_logits = logits / temperature
return softmax(scaled_logits)
- T → 0:趋近 Greedy,输出确定但可能单调
- T = 1:原始概率分布
- T → ∞:趋近均匀分布,完全随机
🎲 实际应用:ChatGPT 默认 T≈0.7,代码生成 T≈0.2,创意写作 T≈1.0。
3.4 Autoregressive:一个字一个字"滚"出来
选完 token 后,把它加回上下文,继续预测下一个:
第 1 步: 输入 "我想吃"
→ 预测 → 选中 "火锅" (25%)
第 2 步: 输入 "我想吃火锅"
→ 预测 → 选中 "," (40%)
第 3 步: 输入 "你想吃火锅,"
→ 预测 → 选中 "你" (18%)
第 4 步: 输入 "你想吃火锅,你"
→ 预测 → 选中 "要" (35%)
... 循环直到遇到结束符 </s>
🎬 聊天回复就是这样一个字一个字"滚"出来的! 这就是为什么长回复需要更多时间。
🔧 工程视角:知道模块职责,才知道优化哪里
理解完整流程后,我们可以针对性地优化各个模块:
性能优化地图
| 模块 | 瓶颈 | 优化方向 | 典型技术 | 加速效果 |
|---|---|---|---|---|
| Attention | 计算复杂度 O(n²) | KV Cache、FlashAttention | PagedAttention、Ring Attention | 2-5 倍 |
| FFN | 参数量大 | MoE、量化 | Mixtral、AWQ、GPTQ | 2-10 倍 |
| Embedding | 词表查找 | 共享嵌入、量化 | - | 1.2 倍 |
| 解码 | 串行生成 | 并行解码、推测采样 | Speculative Decoding | 2-3 倍 |
| 内存 | KV Cache 占用 | 分页管理、压缩 | vLLM、PagedAttention | 显存减半 |
实际案例分析:vLLM 的优化策略
vLLM 是目前最快的推理引擎之一,它的核心优化:
- PagedAttention:像操作系统管理内存一样管理 KV Cache
- Continuous Batching:动态批处理不同长度的请求
- Kernel 融合:减少 GPU kernel 启动开销
效果:相比 HuggingFace Transformers,吞吐量提升 24 倍!🚀
🎯 总结:建立一张工程地图
通过追踪一个 token 的完整旅程,我们建立了这样的认知地图:
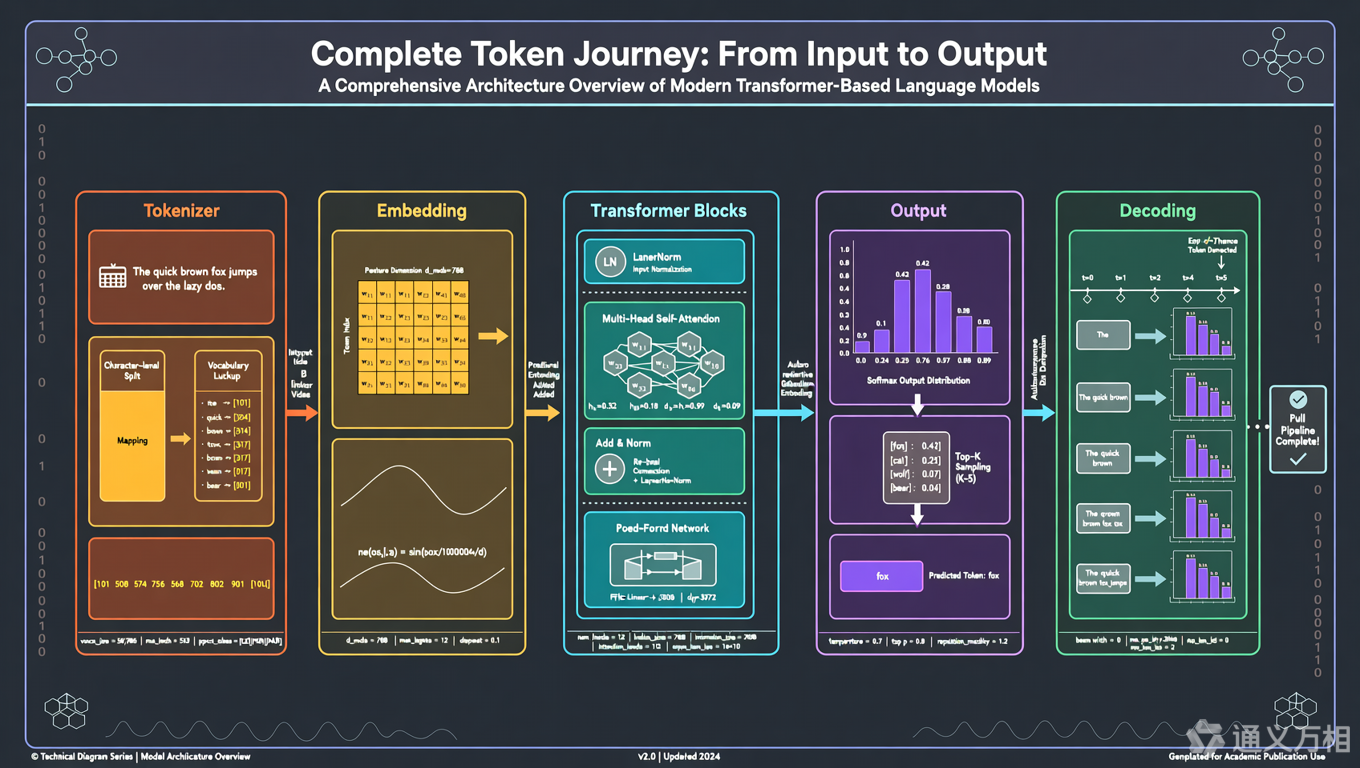
📝 输入文本
↓
🔪 Tokenizer 切分(BPE/WordPiece)
↓
📊 Embedding + RoPE 位置编码
↓
🔄 [Transformer Block × N 层]
├─ 🔍 Attention(交互信息,建立上下文)
├─ ⚙️ FFN(深度加工,存储知识)
└─ 🔗 残差 + LayerNorm(稳定训练)
↓
📤 输出层线性映射(4096 → 32000)
↓
📈 Softmax 转概率分布
↓
🎲 解码策略选择(Greedy/Top-p/Temperature)
↓
✅ 下一个 Token
↓
🔄 (循环直到生成结束符)
理解全貌的四大价值
- 📍 定位问题:知道每个环节的职责,bug 出现时能快速定位
- 🚀 性能优化:找到瓶颈所在(通常是 Attention 或 FFN)
- 🔬 创新改进:在合适的地方尝试新方法(如在 FFN 用 MoE)
- 💰 成本控制:理解为什么某些操作"贵"(如长上下文的 KV Cache)
💡 延伸阅读与实战建议
深入学习的经典论文
- Attention 机制:《Attention Is All You Need》(2017) - Transformer 开山之作
- RoPE 位置编码:《RoFormer: Enhanced Transformer with Rotary Position Embedding》
- FlashAttention:《FlashAttention: Fast and Memory-Efficient Exact Attention》
- MoE 架构:《Switch Transformers: Scaling to Trillion Parameter Models》
- 推理优化:《vLLM: Easy, Fast, and Cheap LLM Serving with PagedAttention》
动手实践建议
初级:可视化理解
# 使用 transformers 库查看中间层输出
from transformers import AutoModel, AutoTokenizer
model = AutoModel.from_pretrained("bert-base-chinese")
tokenizer = AutoTokenizer.from_pretrained("bert-base-chinese")
inputs = tokenizer("我想吃苹果", return_tensors="pt")
outputs = model(**inputs, output_hidden_states=True)
# 查看每一层的隐藏状态
for i, hidden_state in enumerate(outputs.hidden_states):
print(f"Layer {i}: shape={hidden_state.shape}")
中级:性能分析
# 使用 pytorch profiler 分析瓶颈
import torch.profiler
with torch.profiler.profile(
activities=[torch.profiler.ProfilerActivity.CUDA],
record_shapes=True
) as prof:
model.generate(inputs)
print(prof.key_averages().table(sort_by="cuda_time_total"))
高级:自定义优化
- 实现简单的 KV Cache
- 尝试不同的解码策略
- 实验量化(INT8/INT4)效果
🏷️ 标签
#LLM #Transformer #DecoderOnly #Attention #FFN #AI原理 #大模型 #技术科普 #推理优化 #干货 #NLP #深度学习
📢 互动话题
💬 你在实践中遇到过哪些推理性能瓶颈?
💬 你对哪个环节的优化最感兴趣?
欢迎在评论区留言讨论!如果觉得这篇文章对你有帮助,请点赞 👍、收藏 ⭐、转发分享~ 😊
下一篇预告:我们将深入探讨 KV Cache 的实现细节和优化技巧,敬请期待!
作者简介:专注于大模型底层原理与工程优化,致力于让 AI 技术更易懂、更易用。
版权声明:本文为原创内容,转载请注明出处。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 11
11 0
0- 0



 已为社区贡献19条内容
已为社区贡献19条内容

所有评论(0)