AI Infra 硬件体系与编程模型:15. CUDA编程基础:混合精度计算
CUDA混合精度计算完全指南:从基础原理到工程实现
在CUDA性能优化的进阶路径上,混合精度计算是一道必须跨过的门槛。从AI大模型训练到高性能科学计算,混合精度已经成为工业界的标准配置——它能在几乎不损失最终精度的前提下,将矩阵运算性能提升数倍,同时显存占用减半。
很多开发者对混合精度的理解停留在"把float换成half"的表层,却忽略了背后的硬件机制、数值稳定性和工程化落地的细节。本文将从浮点格式的底层原理讲起,串联Tensor Core硬件机制、WMMA编程接口和数值稳定性避坑指南,带你系统掌握CUDA混合精度的完整知识体系。
一、为什么需要混合精度计算?
在很长一段时间里,FP32(单精度浮点数)是CUDA程序的默认选择。但随着计算规模的爆炸式增长,FP32逐渐成为了瓶颈:
- 算力瓶颈:通用CUDA Core的FP32算力增长缓慢,远跟不上模型和数据规模的扩张
- 显存瓶颈:大模型、大矩阵动辄几十GB的参数,FP32存储会迅速占满显存
- 带宽瓶颈:数据量越大,全局内存传输的开销越高,访存瓶颈越突出
混合精度计算正是为了解决这些矛盾而生的。
1.1 混合精度的核心思想
混合精度的核心逻辑可以用一句话概括:非关键路径用低精度换性能,关键路径用高精度保精度。
典型的混合精度计算范式:
- 输入矩阵、权重等数据用低精度(FP16/BF16)存储和运算
- 矩阵乘的中间累加过程用高精度(FP32)保存,避免误差累积
- 最终结果根据需求转回低精度存储或保留高精度
这种模式的合理性在于:绝大多数数值场景对输入的微小误差不敏感,但累加过程的误差会被放大。用低精度做乘法、高精度做累加,既拿到了低精度的性能收益,又保住了最终结果的精度。
1.2 混合精度的三重收益
以A100 GPU为例,我们可以直观看到精度降低带来的全方位提升:
| 维度 | FP32 | FP16/BF16 | 提升倍数 |
|---|---|---|---|
| Tensor Core峰值算力 | 19.5 TFLOPS | 312 TFLOPS | 16倍 |
| 显存占用 | 4字节/元素 | 2字节/元素 | 显存减半 |
| 内存带宽效率 | 基准 | 2倍 | 传输耗时减半 |
这还只是理论峰值,在实际业务中,显存和带宽的缓解往往能带来更显著的端到端收益——很多场景下瓶颈根本不是算力,而是装不下数据、传不动数据。
二、主流浮点精度格式详解
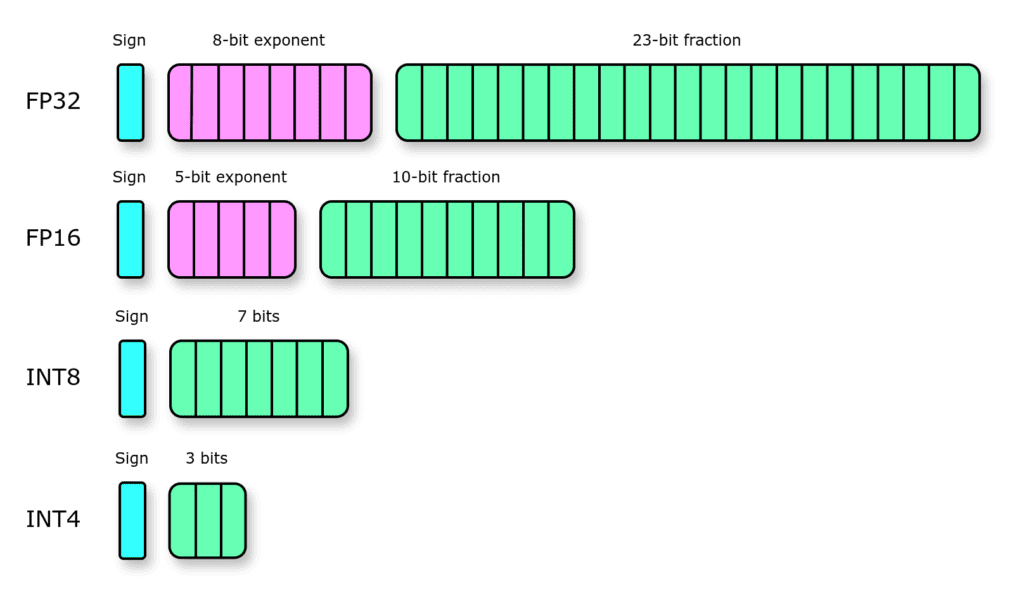
要搞懂混合精度,首先要搞懂不同浮点格式的底层差异。浮点数由符号位、指数位、尾数位三部分组成:
- 指数位决定动态范围(能表示的最大/最小数)
- 尾数位决定精度(数值的细腻程度)
- 符号位表示正负,占1位
2.1 四种核心浮点格式对比
这是CUDA开发中最常用的四种浮点格式,也是Tensor Core支持的主流格式: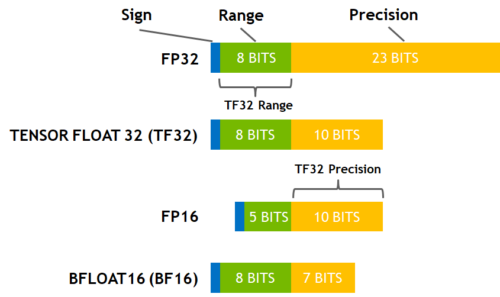
| 格式 | 总位数 | 符号位 | 指数位 | 尾数位 | 动态范围 | 相对精度 | 支持架构 | 核心定位 |
|---|---|---|---|---|---|---|---|---|
| FP32(单精度) | 32 | 1 | 8 | 23 | ~10^±38 | ~1e-7 | 全架构 | 通用计算基准精度 |
| TF32(张量浮点) | 19(逻辑) | 1 | 8 | 10 | ~10^±38 | ~1e-3 | Ampere(sm_80)+ | FP32透明加速 |
| FP16(半精度) | 16 | 1 | 5 | 10 | ~10^±8 | ~1e-3 | Volta(sm_70)+ | 推理/训练高性能格式 |
| BF16(脑浮点) | 16 | 1 | 8 | 7 | ~10^±38 | ~1e-2 | Ampere(sm_80)+ | 训练首选稳定格式 |
2.2 各格式的特点与适用场景
1. FP32:通用基准
FP32是最经典的单精度格式,精度高、动态范围足,是所有GPU的标配。但它的算力最低、显存占用最大,通常只用于累加器和对精度要求极高的计算步骤。
2. FP16:性能先锋
FP16只有16位,显存和带宽收益拉满,Tensor Core算力是FP32的16倍。但它的硬伤是动态范围太小:最小正数只有约6.1e-5,很容易出现数值下溢(梯度变成0),在深度学习训练中需要配合损失缩放使用。
适用场景:推理部署、对数值稳定性要求不高的科学计算。
3. BF16:稳定之选
BF16同样是16位,但它把指数位拉到了和FP32一样的8位,牺牲了部分尾数精度换来了和FP32完全一致的动态范围。这意味着它几乎不会出现下溢/上溢问题,训练时不需要损失缩放,稳定性大幅提升。
适用场景:深度学习训练、对稳定性要求高的通用矩阵运算,是当前AI训练的主流格式。
4. TF32:黑科技透明加速
TF32是Ampere架构的"隐形福利":它本质上是Tensor Core内部的一种计算格式,对外完全透明。输入是标准的FP32数据,Tensor Core自动将尾数截断到10位进行计算,累加仍然用FP32。
它的优势在于:不需要改代码,只需要开启一个开关,就能让FP32的矩阵乘获得8倍左右的算力提升,精度损失微乎其微,绝大多数场景下完全感知不到。
2.3 补充:低精度整数格式
除了浮点格式,Tensor Core还支持INT8、INT4等整数精度,算力更高、显存更小,但精度损失也更大。它们主要用于推理部署场景,通过量化技术将浮点模型转为整数模型,进一步提升推理性能。本文重点讲解浮点混合精度,暂不展开整数量化。
三、混合精度的硬件基石:Tensor Core
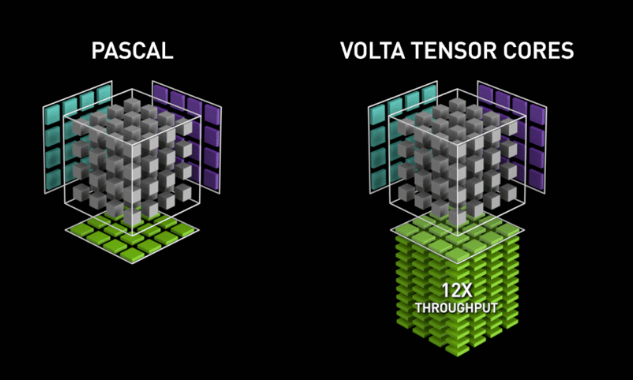
混合精度能带来数量级的性能提升,核心不是"把float换成half",而是调用了专门的Tensor Core硬件。如果只是用普通CUDA Core做FP16运算,性能提升非常有限。
3.1 Tensor Core是什么?
Tensor Core是NVIDIA从Volta架构(V100)开始引入的专用硬件单元,专门针对矩阵乘累加(MMA, Matrix Multiply-Accumulate)运算做了硬件级优化。它执行的是一个固定的融合运算:
D=A×B+C D = A \times B + C D=A×B+C
这个运算把乘法和加法融合成了一步硬件操作,没有中间结果的读写开销,再加上专门的电路设计,单单元吞吐量比通用CUDA Core高一个数量级。
打个比方:CUDA Core是通用螺丝刀,什么螺丝都能拧但效率一般;Tensor Core是专用电动扳手,只能拧特定规格的螺丝,但速度快几十倍。
3.2 WMMA执行模型
Tensor Core不是给单个线程用的,它采用Warp级协作的执行模型,称为WMMA(Warp Matrix Multiply Accumulate),是 CUDA 9.0+ 引入的一套 API 和数据类型,专门用于在 NVIDIA GPU 的 Tensor Core 上高效执行小矩阵的乘加运算(D = A * B + C)。
- 一个warp的32个线程共同协作,完成一个固定尺寸小矩阵块的乘累加
- 每个线程持有矩阵块的一部分元素,存储在自己的寄存器中
- 一次WMMA调用,整个warp协同完成一次矩阵块运算
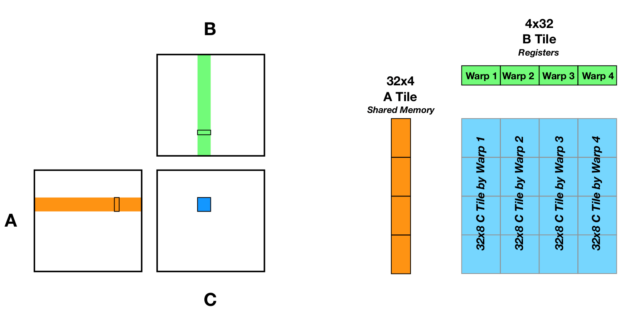
最基础的WMMA块尺寸是 16×16×16(M×N×K):
- A矩阵:16行 × 16列
- B矩阵:16行 × 16列
- C/D矩阵:16行 × 16列
- 一次运算完成 16×16×16 = 4096 次乘加操作(8192次浮点运算)
不同架构支持更多块尺寸(如32×8×16、8×32×16),但16×16×16是兼容性最好的基础尺寸。
3.3 各代架构的精度支持
| 架构 | 计算能力 | 支持的Tensor Core精度 |
|---|---|---|
| Volta | sm_70 | FP16 |
| Turing | sm_75 | FP16、INT8/INT4 |
| Ampere | sm_80/sm_86 | FP16、BF16、TF32、INT8 |
| Hopper | sm_90 | FP16、BF16、TF32、FP8、INT8 |
| Blackwell | sm_100 | FP16、BF16、TF32、FP8、INT4 |
简单来说:越新的架构,支持的精度格式越多,Tensor Core算力越强。
四、CUDA中实现混合精度的三种方式
在实际开发中,我们有三种层级的方式来实现混合精度,对应不同的开发效率和灵活度。
4.1 开箱即用:调用高性能库
这是绝大多数场景的首选方案。NVIDIA官方的cuBLAS、cuDNN、TensorRT等库已经深度优化了Tensor Core混合精度,只需要改几个参数就能用上,不需要自己写核函数。
以cuBLAS的矩阵乘法为例,只需要把数据类型改成FP16,就能自动调用Tensor Core:
#include <cublas_v2.h>
cublasHandle_t handle;
cublasCreate(&handle);
// 启用Tensor Core加速
cublasSetMathMode(handle, CUBLAS_TENSOR_OP_MATH);
// FP16矩阵乘:C = alpha * A * B + beta * C
half alpha = 1.0f;
half beta = 0.0f;
// 注意:cuBLAS默认是列主序,参数顺序和行主序有区别
cublasHgemm(handle,
CUBLAS_OP_N, CUBLAS_OP_N, // B和A的转置标志
N, M, K, // 列数、行数、内维度
&alpha,
d_B, N, // B矩阵和leading dimension
d_A, K, // A矩阵和leading dimension
&beta,
d_C, N); // C矩阵和leading dimension
适用场景:标准的矩阵运算、深度学习推理/训练,开发效率最高,性能也最优。
4.2 手动调用:WMMA API
如果需要实现自定义的矩阵运算逻辑,不能直接用库,就可以用CUDA提供的WMMA API,在核函数中直接调用Tensor Core。
核心概念:Fragment(片段)
WMMA的核心数据结构是fragment,可以理解为"矩阵片段"。它是存储在寄存器中的小矩阵块,由整个warp的线程共同持有,单个线程只持有其中一部分元素。
fragment有三种类型:
matrix_a:左乘矩阵A的片段matrix_b:右乘矩阵B的片段accumulator:累加矩阵C/D的片段
四大核心函数
WMMA API只有四个核心函数,所有函数都必须由整个warp同步调用,参数保持一致:
load_matrix_sync:从内存加载矩阵块到fragmentmma_sync:执行矩阵乘累加,调用Tensor Corestore_matrix_sync:将fragment结果写回内存fill_fragment:用常量填充fragment
完整代码示例:WMMA基础矩阵乘
#include <iostream>
#include <cuda_runtime.h>
#include <mma.h>
#define CHECK_CUDA_ERROR(err) \
if (err != cudaSuccess) { \
std::cerr << "CUDA Error: " << cudaGetErrorString(err) \
<< " at line " << __LINE__ << std::endl; \
exit(1); \
}
using namespace nvcuda::wmma;
// 简化示例:每个warp计算一个16x16的C矩阵块
// A: MxK 行主序 FP16, B: KxN 列主序 FP16, C: MxN 行主序 FP32
__global__ void wmmaBasicKernel(const half* __restrict__ A,
const half* __restrict__ B,
float* __restrict__ C,
int M, int N, int K)
{
// 当前warp负责的C矩阵块坐标
int warpRow = blockIdx.y;
int warpCol = blockIdx.x;
// 初始化累加器为0
fragment<accumulator, 16, 16, 16, float> acc;
fill_fragment(acc, 0.0f);
// 遍历K维度,逐块累加
for (int k = 0; k < K; k += 16) {
// 加载A和B的片段
fragment<matrix_a, 16, 16, 16, half, row_major> a_frag;
fragment<matrix_b, 16, 16, 16, half, col_major> b_frag;
load_matrix_sync(a_frag, A + warpRow * 16 * K + k, K);
load_matrix_sync(b_frag, B + k * N + warpCol * 16, N);
// 执行Tensor Core乘累加
mma_sync(acc, a_frag, b_frag, acc);
}
// 将结果写回全局内存
store_matrix_sync(C + warpRow * 16 * N + warpCol * 16, acc, N, row_major);
}
注意:这只是最基础的WMMA用法,实际高性能实现还需要结合共享内存分块、消除Bank冲突等优化,和普通矩阵乘法的优化思路一致。
适用场景:自定义矩阵运算、算子开发、需要特殊逻辑的矩阵融合运算。
4.3 透明加速:TF32自动升级
如果你不想改代码、不想动精度,只想让现有的FP32矩阵乘跑得更快,TF32是最佳选择。
开启TF32有两种方式:
- 编译时开启:添加编译选项
-arch=sm_80 -ftz=true,配合cuBLAS的Tensor Op模式 - 运行时开启:设置环境变量
NVIDIA_TF32_OVERRIDE=1
开启后,所有FP32的cuBLAS矩阵乘、cuDNN卷积都会自动用TF32精度在Tensor Core上运行,累加仍然是FP32,绝大多数场景下精度完全可接受,性能提升非常明显。
适用场景:已有FP32代码的快速加速、对精度要求不苛刻的科学计算。
五、数值稳定性与避坑指南
混合精度不是"换个类型就完事了",数值稳定性是最容易踩坑的地方。
5.1 最常见的问题:下溢与上溢
FP16的动态范围只有~10^±8,在深度学习训练和很多迭代算法中,梯度、残差等数值很容易变得非常小(小于6e-5),导致数值下溢(变成0);也可能出现数值过大,导致上溢(变成无穷大)。
最典型的场景就是深度学习反向传播:梯度值往往非常小,直接用FP16存储会大量变成0,导致模型不收敛。
5.2 解决方案1:损失缩放(Loss Scaling)
这是FP16训练的标准解决方案,核心思路很简单:
- 前向传播计算损失后,将损失乘以一个较大的缩放因子(比如1024)
- 反向传播时,梯度也会跟着放大,不会下溢
- 更新权重之前,再把梯度除以缩放因子,还原真实值
- 动态调整缩放因子,避免上溢
现在的深度学习框架(PyTorch、TensorFlow)都内置了自动混合精度(AMP),会自动处理损失缩放,不需要手动实现。
5.3 解决方案2:直接用BF16
如果你的GPU支持BF16(Ampere及以上),最省心的方案就是直接用BF16替代FP16。BF16的动态范围和FP32完全一致,几乎不会出现下溢/上溢,不需要损失缩放,训练稳定性和FP32差不多,性能和FP16相当。
这也是为什么现在大模型训练普遍首选BF16的原因——稳定、省心、性能够。
5.4 其他避坑要点
- 累加器一定要用高精度:绝对不要用FP16做累加,误差会快速累积到不可接受的程度
- 关键计算保留FP32:比如归一化、指数、对数等对精度敏感的运算,转回FP32再做
- 做好精度验证:切换混合精度后,一定要和FP32基准结果做对比,确认误差在可接受范围内
- 不要盲目追求更低精度:FP8虽然算力更高,但精度损失更大,只适合推理等对精度容忍度高的场景
六、最佳实践总结
6.1 精度选型建议
| 场景 | 推荐精度 | 理由 |
|---|---|---|
| 深度学习训练 | BF16(优先)/ FP16+损失缩放 | 平衡性能与稳定性 |
| 深度学习推理 | FP16 / INT8 / FP8 | 极致性能,精度损失可接受 |
| 通用科学计算 | TF32(优先)/ FP32 | 透明加速,几乎无精度损失 |
| 自定义算子开发 | FP16输入 + FP32累加 | 标准混合精度范式 |
6.2 性能优化要点
- 优先用官方库:cuBLAS的Tensor Core实现比绝大多数手写的WMMA性能好很多
- 数据布局要匹配硬件:注意行主序/列主序,避免额外的转置开销
- 结合共享内存分块:和普通矩阵乘一样,WMMA也需要分块+共享内存来减少全局内存访问
- 保证对齐:矩阵的起始地址和leading dimension最好按128字节对齐,提升访存效率
6.3 正确性验证流程
- 先跑通FP32版本,作为基准
- 切换混合精度,对比最终结果的误差
- 误差过大时,排查是否有累加精度不够、敏感运算用了低精度等问题
- 用不同规模的输入反复验证,避免极端数值下出现异常
七、总结
混合精度计算不是简单的"降精度",而是一套完整的技术体系——它以Tensor Core硬件为核心,通过"低精度运算+高精度累加"的范式,在精度和性能之间找到了极佳的平衡点。
本文我们从底层浮点格式讲起,梳理了Tensor Core的硬件原理、三种混合精度实现方式,以及数值稳定性的避坑指南。对于绝大多数开发者来说,优先用好官方库的混合精度支持是性价比最高的选择;如果需要自定义算子,再深入WMMA编程。
在后续的文章中,我们会继续深入,讲解如何结合共享内存写出高性能的WMMA矩阵乘,以及FP8等更前沿的混合精度技术。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 0
0 0
0- 0



 已为社区贡献20条内容
已为社区贡献20条内容

所有评论(0)