NLP —— Transformer底层代码剖析(通用部分)
目录
Transformer —— 通用部分(代码)
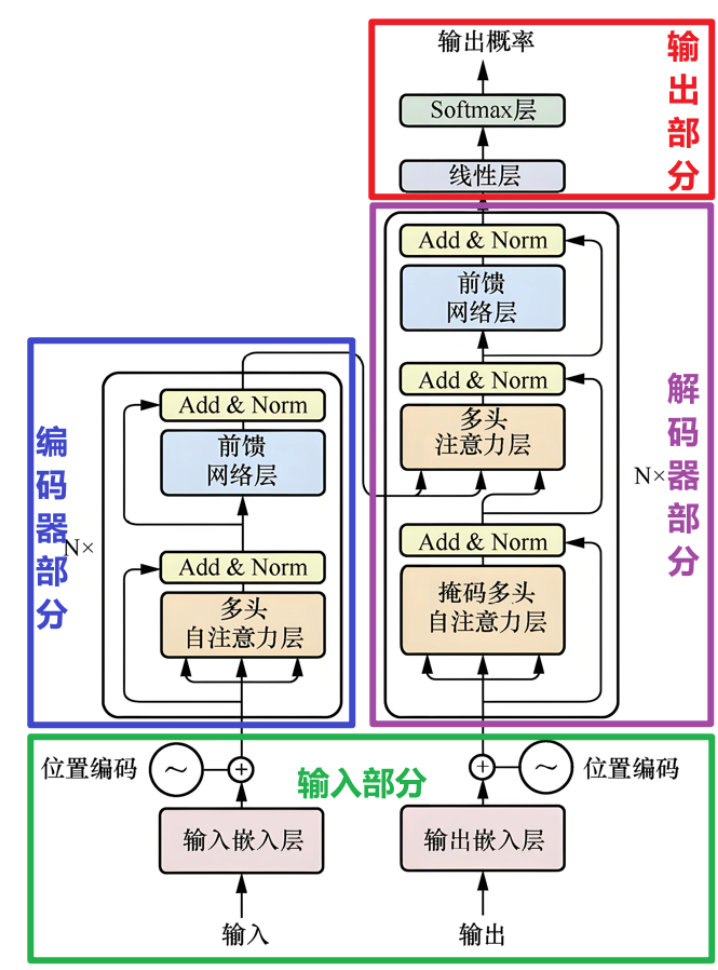
如下图所示:
编码器 / 解码器 有许多通用模块
本篇围绕通用模块做代码实例
① Norm 层归一化
② 构建子层连接处理:
(前馈网络 、多头注意力层<也称为交叉注意力层>、多头自注意力层、掩码多头自注意力层)
这四个层都会与 残差连接和层归一化结合,所以封装一个子层连接处理函数调提供调用。
③ 前馈网络
④ 注意力计算
注意力机制下的 专属信息包C 和 权重 的计算。
⑤ 多头注意力机制
一个通用的多头注意力机制的通用函数,提供给(多头注意力层<也称为交叉注意力层>、多头自注意力层、掩码多头自注意力层)调用。
一、Norm 层归一化
通过标准化处理数据,正态分布。提出极值导致的梯度消失和爆炸,让数据更正常。
通过 y = kx + b 实现计算均值mean 和 标准差 std
import torch
import torch.nn as nn
"""
层归一化:
随着网络模型训练,数据可能出现极值,导致梯度消失或爆炸,为了让模型训练更稳定,通过标准化处理,正态分布,让数据变的正常
也就是要实现 y = kx + b ,其中x要经过标准化处理 (要计算数据的均值mean和标准差std)
"""
class LayerNorm(nn.Module):
def __init__(self, d_model, eps=1e-6):
super().__init__()
"""
为什么k和b 要通过nn.Parameter进行定义
因为nn.Parameter会自动将k和b注册到神经网络模型中,作为可训练的参数
通过反向传播得到k和b
如果不写nn.Parameter,那么k和b的值永远固定,不会改变
对应前面神经网络代码如
optimizer = optim.Adam(model.parameters())
optimizer.step()
eps 定义小常数:防止分母为0
"""
self.k = nn.Parameter(torch.ones(d_model))
self.b = nn.Parameter(torch.zeros(d_model))
self.eps = eps
def forward(self, data):
"""
前向传播 实现【标准化处理】
:param data: 前面子层处理后的数据。形状【batch_size,seq_len,d_model】
:return:
"""
# 1.计算均值
# 最后一个维度计算均值,张量形状保留
mean = data.mean(dim=-1,keepdim=True)
# 2. 标准差
std = data.std(dim=-1,keepdim=True)
# 3. 实现y=kx+b
return self.k * (data - mean) / (std + self.eps) + self.b二、构建子层连接处理
输入 => 层数据 data + 数据维度 d_model + 随机失活概率值dropout_p
经过 Norm 实例对象 和 随机失活函数 处理后的数据 + 原始数据(Add) => 输出
对图的代码实现:
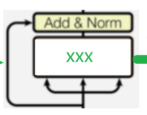
xxx 为
前馈网络实例对象 || 多头自注意力机制实例对象 || 掩码多头自注意力实例对象 || 交叉自注意力实例对象
实例流程:
方式1: 论文中实现的 数据 -> 数据处理实例对象 -> 随机失活 -> 残差连接 -> 层归一化
方式2: 目前主流实现 数据 -> 层归一化 -> 数据处理实例对象 -> 随机失活 -> 残差连接
(让数据更稳定的带入模型)
代码实现:
"""
子层连接
"""
class SubLayerConnection(nn.Module):
def __init__(self, d_model, dropout=0.2):
super().__init__()
self.d_model = d_model
self.dropout = nn.Dropout(p=dropout)
self.layer_norm = LayerNorm(d_model)
def forward(self, data, data_handle_obj):
"""
:param data: 子层需要处理的数据
:param data_handle_obj: (前馈网络 || 多头自注意力机制实例对象 || 掩码多头自注意力实例对象 || 交叉自注意力实例对象 )
方式1: 论文中实现的 数据 -> 数据处理实例对象 -> 随机失活 -> 残差连接 -> 层归一化
方式2: 目前主流 数据 -> 层归一化 -> 数据处理实例对象 -> 随机失活 -> 残差连接 (让数据更稳定的带入模型)
"""
# 方式1
# result = self.layer_norm( self.dropout(data_handle_obj(data)) + data )
# 方式2
result = self.dropout(data_handle_obj(self.layer_norm(data))) + data
return result三、前馈网络层(FFN)
作用:通过调整张量大小的调整,实现强化信息的过程
① 线性层 1 d_model -> output_dim
② relu处理下数据 引入非线性因素
注意力机制本质是线性计算,如果没有非线性因素,那么整个网络模型比较简单,只能处理线性问题(也就是回归),引入relu激活也就是引入了非线性因素;Transformer论文中用的就是relu
③ 随机失活层 避免失活
④ 线性层 2,把张量大小调回来 output_dim -> d_model
代码实现:
"""
前馈网络
1.线性层 1 d_model -> output_dim
2.relu处理下数据 引入非线性因素
注意力机制本质是线性计算,如果没有非线性因素,那么整个网络模型比较简单,只能处理线性问题(也就是回归)
引入relu激活也就是引入了非线性因素;Transformer论文中用的就是relu
3.随机失活层 避免失活
4.线性层 2,把张量大小调回来 output_dim -> d_model
实现强化信息的过程
"""
class FeedForward(nn.Module):
def __init__(self, d_model, output_dim, dropout=0.2):
super().__init__()
self.linear_1 = nn.Linear(in_features=d_model, out_features=output_dim)
self.dropout = nn.Dropout(p=dropout)
self.linear_2 = nn.Linear(in_features=output_dim, out_features=d_model)
def forward(self, data):
data = self.linear_1(data)
data = torch.relu(data)
data = self.dropout(data)
data = self.linear_2(data)
return data四、注意力计算
整个transformer中有用到三种注意力机制
① 编码器端,多头自注意力机制 K=Q=V Mask=None
② 解码器端,掩码多头自注意力机制,K=Q=V Mask不能为空
③ 解码器端,交叉注意力机制,K=V来至编码器,Q来至解码器(上一个时间步隐藏状态),Mask=None
公式:
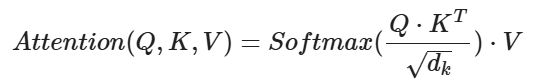
代码实现
"""
注意力计算
有三种注意力机制要实现:
1.编码器端,多头自注意力机制 K=Q=V Mask=None
2.解码器端,掩码多头自注意力机制,K=Q=V Mask不能为空
3.解码器端,交叉注意力机制,K=V来至编码器,Q来至解码器(上一个时间步隐藏状态),Mask=None
自注意力机制原理:K=Q=V 【batch_size, seq_len, d_model】
公式:
Attention(Q,K,V)= (Softmax((Q @ K转置)/ sqrt(d_model)))* V
mask 形状【batch_size, seq_len, seq_len】
"""
def attention(query, key, value, mask=None, dropout=None):
# 1.获取d_model
d_model = query.shape[-1]
# 2.Q 矩阵乘 K转置 除以 根号d_model -> 相似对得分
scores = torch.matmul(query, key.transpose(-2,-1)) / math.sqrt(d_model)
# 3.对 相似度得分 进行掩码处理
if mask is not None:
# 对需要进行掩码的地方,将值替换成 -1e9,
# 注意:不要直接设置为0。需要和softmax结合理解。e的 - 1e9的结果趋近于0,表示权重趋近于0
scores = scores.masked_fill(mask==0, -1e9)
# 4.将相似度转为权重矩阵
weight = torch.softmax(scores, dim=-1)
# 5.随机失活,缓解过拟合
if dropout is not None:
weight = dropout(weight)
# 6.计算专属信息包C
C = torch.matmul(weight, value)
return C, weight五、多头注意力机制
作用:
① 能够让模型进行并行计算,提高运行效率
② 多个头来同时处理数据,那么模型对数据的理解、学习会更好,模型整体效果会更好。
注意点:
对Q、K、V的线性、升维处理
【batch_size, seq_len, d_model】 => [batch_size, num_heads, seq_len, head_him]
位置交换
计算后拼接
位置交换
还原 降维处理
[batch_size, num_heads, seq_len, head_him] => [batch_size, seq_len, num_heads, head_him] => [batch_size, seq_len, num_heads*head_him]
线性后再输出
mask 也要升维度 【batch_size, seq_len, seq_len】=> 【1,batch_size, seq_len, seq_len】
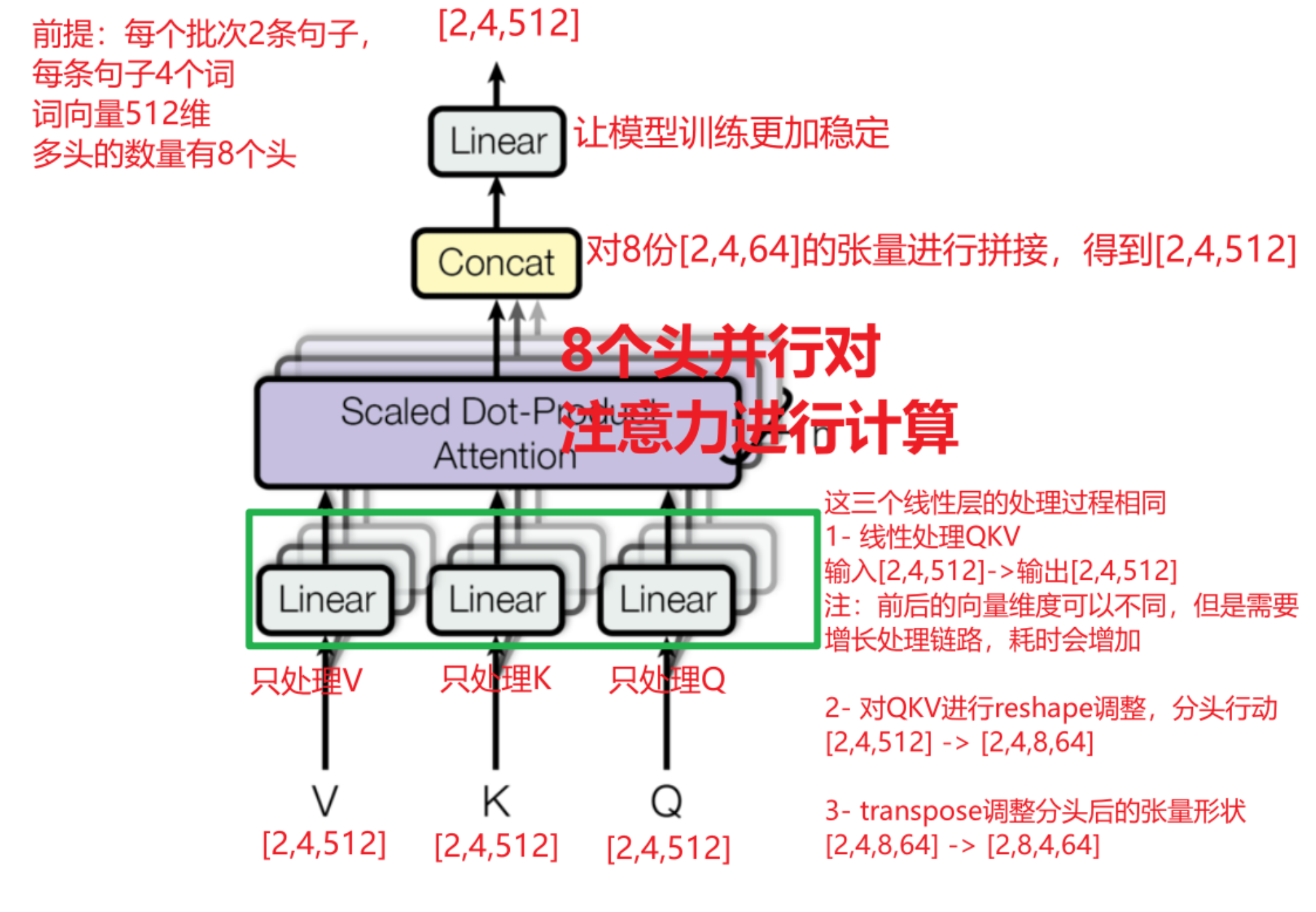
代码实现:
clone 函数
def clone(module_obj, cnt):
"""
module_obj:需要深拷贝的对象
cnt:需要深拷贝多少份
"""
return nn.ModuleList([copy.deepcopy(module_obj) for i in range(cnt)])class MultiHeadAttention(nn.Module):
def __init__(self, d_model, num_heads, dropout_p=0.2):
# 验证头数是否 能被整除
assert d_model%num_heads==0
super().__init__()
self.d_model = d_model
self.num_heads = num_heads
self.head_him = d_model//num_heads
self.dropout = nn.Dropout(p=dropout_p)
self.weight = None #权重矩阵
"""
4个线性层 分别对
Q、K、V、output 进行线性处理
"""
self.linear_list = clone(nn.Linear(in_features=self.d_model, out_features=self.d_model),4)
def forward(self, query, key, value, mask=None):
# 1. 掩码升维
if mask is not None:
"""
多头 4维,mask 需要升维
【batch_size, seq_len, seq_len】 -> 【1, batch_size, seq_len, seq_len】
"""
mask = mask.unsqueeze(0)
# 2. 获取batch_size
batch_size = query.shape[0]
"""
相当于
linear_1 处理 Q
linear_2 处理 K
linear_3 处理 V
"""
# 3. 处理Q、K、V,
# 分别线性处理
# 多头分配 升维处理
# 位置交互
# 生成新的Q,K,V
model_and_data_pair = list(zip(self.linear_list, (query, key, value)))
handle_result_list = []
for linear, data in model_and_data_pair:
linear_output:Tensor = linear(data)
"""
【batch_size, seq_len, d_model】 => [batch_size, num_heads, seq_len, head.him]
比如. [2, 4, 512] => [2, 8, 4, 64]
"""
tmp_data = linear_output.reshape(batch_size, -1, self.num_heads, self.head_him).transpose(dim0=1,dim1=2)
handle_result_list.append(tmp_data)
new_q, new_k, new_v = handle_result_list
# 4. 多头计算注意力,得到专属信息包C
# C是 四维度
C, weighted = attention(new_q, new_k, new_v, mask=mask, dropout=self.dropout)
# 5. 多头计算后 还原 以前的维度,降维
"""
[batch_size, num_heads, seq_len, head.him] => 【batch_size, seq_len, d_model】
比如. [2, 8, 4, 64] => [2, 4, 8, 64] => [2, 4, 512]
"""
result = C.transpose(1, 2).reshape(batch_size, -1, self.num_heads*self.head_him)
# 6. 最后线性处理输出
return self.linear_list[-1](result)
AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 13
13 0
0- 0



 已为社区贡献11条内容
已为社区贡献11条内容

所有评论(0)