Brew 技术解析:AI 驱动的电子邮件自动化引擎架构与原理
摘要
Brew 是一款面向电子邮件营销与自动化流程生成的 AI 原生平台,核心能力是通过自然语言输入自动生成符合品牌调性的邮件内容、设计模板、目标受众规则与自动化流程逻辑,同时具备跨 AI 智能体兼容、无厂商锁定的灵活部署能力与全链路渲染一致性保障机制。本文从技术架构、核心模块实现、AI 生成引擎原理、跨智能体兼容机制、数据流转与存储、邮件渲染适配、扩展性设计、安全机制及性能优化九大维度,深度剖析 Brew 的底层技术实现,结合代码示例与架构图解拆解其核心技术逻辑,为开发者理解同类 AI 营销工具的技术范式提供参考。
一、引言
电子邮件营销作为数字营销领域 ROI 最高的渠道之一,长期面临内容创作效率低、设计适配复杂、自动化流程配置门槛高、多平台迁移成本大等痛点。传统电子邮件服务提供商(ESP)仅提供邮件发送与基础模板功能,文案撰写、视觉设计、受众筛选、流程逻辑编排等核心环节仍需人工完成,单条营销活动落地耗时可达数小时,且难以保障多邮箱客户端的渲染一致性与品牌调性统一。
Brew 以 “AI 全链路生成 + 无锁定灵活部署” 为核心设计理念,重构电子邮件营销的技术实现路径。用户仅需通过日常英语描述营销活动或自动化流程需求,平台即可在数秒内完成文案生成、视觉设计、受众分层、流程逻辑编排全链路工作,同时兼容 OpenClaw、Viktor、Claude、Lovable 等主流 AI 智能体,支持直接发送或导出至现有 ESP,从技术层面解决传统工具的效率瓶颈与生态壁垒。
本文聚焦 Brew 技术内核,从架构设计到模块实现、从算法原理到工程落地,全面拆解其技术体系,不涉及营销功能介绍,仅从技术视角解析其核心能力的实现逻辑,为技术从业者提供 AI 驱动的营销自动化平台技术参考。
二、Brew 整体技术架构
Brew 采用前端轻量化交互 + 后端微服务集群 + AI 引擎中台 + 数据存储分层 + 第三方服务适配层的分布式架构,遵循高可用、高扩展性、低耦合设计原则,整体架构可分为 5 大核心层级,各层级通过标准化 API 通信,确保模块解耦与独立迭代。
2.1 技术栈选型
Brew 技术栈兼顾性能、开发效率与生态兼容性,核心技术选型如下:
- 前端层:Next.js 15 + React 19(服务端渲染 SSR 保障首屏加载速度)、Tailwind CSS 4(样式原子化设计)、Zustand(轻量级状态管理)、Dexie(IndexedDB 本地缓存)、Framer Motion(交互动效);
- 后端层:Node.js + Express(API 服务)、Go(高并发核心服务)、Python(AI 算法服务)、gRPC(微服务间高效通信);
- AI 引擎层:大语言模型(LLM)、扩散模型(图像生成)、NLP 语义解析模型、品牌风格识别模型;
- 数据存储层:PostgreSQL(结构化数据,用户信息、模板元数据)、MongoDB(非结构化数据,邮件内容、设计资源)、Redis(缓存,会话信息、热点数据)、对象存储(AWS S3 / 阿里云 OSS,图片、附件等静态资源);
- 适配层:RESTful API、Webhook、SMTP/ESMTP、第三方 ESP 接口(SendGrid、Mailchimp 等)、AI 智能体通信协议(OpenClaw、Claude 专用协议)。
2.2 五层架构设计
2.2.1 前端交互层
前端交互层是用户与平台的唯一交互入口,负责自然语言输入接收、生成结果预览、模板编辑、流程可视化配置、数据展示等功能,核心设计目标是轻量化、低门槛、响应式适配。
核心模块包括:
- 自然语言输入模块:支持纯文本输入、品牌信息关联、参考素材上传(图片、Figma 链接)、历史指令复用;
- 实时预览模块:基于 React Email 实现,支持多邮箱客户端(Gmail、Outlook、QQ 邮箱等)实时渲染预览,同步展示桌面端 / 移动端适配效果;
- 可视化编辑器:低代码拖拽式界面,支持对 AI 生成的文案、设计、流程逻辑进行二次编辑,无需代码基础;
- 数据看板模块:展示邮件发送状态、打开率、点击率、自动化流程转化率等数据,基于 ECharts 实现可视化图表。
前端通过 RESTful API 与后端服务通信,采用 SSR 提升首屏加载速度,IndexedDB 缓存用户常用模板与品牌配置,减少重复请求,提升交互流畅度。
2.2.2 API 网关层
API 网关层是整个系统的流量入口,承担请求路由、身份认证、权限控制、限流熔断、日志监控、跨域处理等核心功能,基于 Kong 实现,保障系统安全性与稳定性。
核心功能:
- 请求路由:根据请求路径与方法,将前端请求转发至对应的后端微服务(内容生成服务、设计服务、自动化服务、用户服务等);
- 身份认证:基于 JWT 实现用户登录态校验,API 接口访问权限控制,防止非法请求;
- 限流熔断:针对 AI 生成服务等高耗时接口,设置请求限流规则,避免突发流量压垮服务;基于 Hystrix 实现熔断机制,下游服务故障时快速降级,保障核心功能可用;
- 日志监控:统一收集全链路请求日志、错误日志,对接 Prometheus + Grafana 实现实时监控,异常告警;
- 跨域处理:配置 CORS 规则,支持前端跨域请求,适配多端访问场景。
2.2.3 后端微服务层
后端微服务层是系统的核心业务处理层,采用领域驱动设计(DDD) 拆分微服务,每个服务聚焦单一业务领域,独立部署、迭代,通过 gRPC 实现服务间高效通信,核心微服务包括:
- 用户服务(User Service):负责用户注册、登录、信息管理、品牌配置存储、权限管理等,关联 PostgreSQL 存储用户结构化数据;
- AI 内容生成服务(Content Generation Service):核心服务之一,接收自然语言指令,调用 AI 引擎生成邮件文案、主题行、受众规则、流程逻辑,基于 Python 实现;
- AI 设计生成服务(Design Generation Service):核心服务之一,根据品牌风格、文案内容生成适配多客户端的邮件视觉模板,包括布局、配色、字体、图片排版,基于 Python + 扩散模型实现;
- 自动化流程服务(Automation Service):解析生成的流程逻辑,构建自动化工作流,处理触发条件、定时规则、分支逻辑、异常处理,基于 Go 实现高并发流程调度;
- 邮件发送服务(Email Delivery Service):负责邮件模板渲染、SMTP 协议对接、第三方 ESP 接口适配、发送状态追踪、退信处理,保障邮件送达率;
- 数据统计服务(Analytics Service):收集邮件发送数据、用户行为数据(打开、点击、转化)、自动化流程执行数据,进行数据清洗、聚合、分析,支撑前端数据看板;
- 第三方适配服务(Integration Service):对接外部 AI 智能体、ESP、CRM 系统,实现数据互通、功能联动,保障无厂商锁定特性。
2.2.4 AI 引擎中台层
AI 引擎中台层是 Brew 核心能力的底层支撑,整合大语言模型、图像生成模型、NLP 语义解析模型、品牌风格识别模型、渲染适配模型,提供统一的 AI 能力调用接口,屏蔽底层模型差异,支撑上层内容生成、设计生成、流程逻辑解析等核心功能。
核心子模块:
- NLP 语义解析模块:负责自然语言指令的语义理解、意图识别、实体提取(活动类型、受众、流程步骤、品牌信息)、指令优化,将非结构化自然语言转化为结构化参数,输入至下游生成模型;
- LLM 内容生成模块:基于自研或第三方大语言模型(如 GPT-4、Claude 3),接收结构化参数,生成符合品牌调性、营销场景的邮件文案、主题行、受众筛选规则、自动化流程逻辑描述;
- 扩散模型设计生成模块:基于 Stable Diffusion 优化,结合品牌风格库(配色、字体、Logo、视觉元素),生成适配多邮箱客户端的邮件布局、视觉模板、配图,保障设计一致性;
- 品牌风格识别模块:通过用户上传品牌官网、Logo、参考设计,提取品牌核心视觉特征(主色、辅助色、字体、设计元素)、文案风格(正式、活泼、简洁),构建专属品牌风格模型,确保生成内容符合品牌调性;
- 渲染适配模块:基于邮件渲染规则库,对生成的 HTML 模板进行兼容性处理,适配不同邮箱客户端的渲染差异(如 CSS 支持度、标签兼容性),确保邮件在所有收件箱完美渲染。
2.2.5 数据存储层
数据存储层采用分层存储策略,根据数据类型、访问频率、存储成本选择适配的存储方案,保障数据安全、高效读写,核心存储组件包括:
- PostgreSQL:存储结构化数据,如用户信息、品牌配置、模板元数据、自动化流程配置、权限信息,支持事务处理与复杂查询;
- MongoDB:存储非结构化数据,如邮件文案内容、HTML 模板、设计资源元数据、用户行为日志,灵活适配数据结构变化;
- Redis:缓存热点数据,如用户会话信息、常用模板缓存、AI 生成结果缓存、限流计数器,降低数据库访问压力,提升接口响应速度;
- 对象存储(S3/OSS):存储静态资源,如邮件配图、Logo、附件、模板文件,支持高并发访问与大规模存储;
- 时序数据库(InfluxDB):存储时序数据,如邮件发送状态、打开 / 点击时间戳、自动化流程执行时间线,支撑数据统计与分析。
2.3 核心数据流转流程
Brew 核心数据流转遵循 “自然语言输入→语义解析→AI 生成→结果编辑→流程调度→邮件发送→数据统计” 的闭环流程,具体步骤如下:
- 用户通过前端输入自然语言指令(如 “生成一个 3 步的新用户欢迎邮件流程,第一步介绍产品功能,第二步发送快速入门指南,第三步引导预约演示”),并关联品牌信息;
- 前端将指令与品牌配置发送至 API 网关,网关转发至 AI 内容生成服务;
- AI 内容生成服务调用 NLP 语义解析模块,解析指令意图、提取关键实体,生成结构化参数;
- 结构化参数输入 LLM 内容生成模块,生成邮件文案、主题行、受众规则、自动化流程逻辑;
- 文案内容与品牌风格参数发送至 AI 设计生成服务,生成适配的视觉模板;
- 自动化流程服务解析流程逻辑,构建工作流,设置触发条件、定时规则、分支节点;
- 前端返回生成结果(文案、设计、流程),用户可进行二次编辑;
- 用户确认后,自动化流程服务调度流程执行,邮件发送服务渲染模板并发送(或导出至第三方 ESP);
- 数据统计服务收集发送数据与用户行为数据,进行分析并展示至前端看板。
三、核心模块技术实现
3.1 自然语言语义解析模块
语义解析模块是 Brew 实现 “日常英语转营销内容” 的关键,核心目标是将非结构化自然语言指令转化为结构化、可被 AI 生成模型识别的参数,解决自然语言歧义性、模糊性问题。
3.1.1 技术选型
采用BERT 预训练模型 + 微调分类器 + 实体识别模型的组合方案,结合规则引擎优化,兼顾解析准确率与响应速度:
- 预训练模型:基于 BERT-base 微调,适配营销领域语料,提升意图识别与语义理解准确率;
- 意图识别:多分类任务,识别用户指令核心意图(邮件生成、自动化流程生成、模板修改、品牌更新等);
- 实体识别:采用 BiLSTM-CRF 模型,提取指令中的关键实体(活动类型、受众人群、流程步骤、邮件数量、品牌名称、时间节点等);
- 规则引擎:基于正则表达式与营销领域规则库,补充处理高频模糊指令,提升解析稳定性。
3.1.2 核心解析流程
- 指令预处理:对用户输入的自然语言指令进行清洗,去除冗余字符、修正语法错误、统一格式(如大小写、标点);
- 意图识别:将预处理后的文本输入微调后的 BERT 模型,输出意图分类结果(如 “自动化流程生成”),置信度低于阈值时触发人工确认;
- 实体提取:通过 BiLSTM-CRF 模型提取关键实体,输出实体 - 值映射关系,示例如下:
{
"intent": "automation_flow_generation",
"entities": {
"flow_steps": 3,
"audience": "new_saas_trial_users",
"email_purpose": ["introduce_product", "quick_start_guide", "demo_booking"],
"brand_id": "brand_123"
}
}
- 参数结构化:将意图与实体信息转化为标准化结构化参数,补充默认值(如邮件风格、发送频率),生成可直接输入 LLM 的请求参数;
- 指令优化:对模糊指令进行自动补全(如用户仅输入 “生成欢迎邮件”,自动补充默认参数:1 步流程、新用户受众、简洁风格),提升生成结果贴合度。
3.1.3 代码示例(语义解析核心逻辑)
# 语义解析模块核心代码(Python)
import torch
from transformers import BertTokenizer, BertForSequenceClassification
from bilstm_crf import BiLSTM_CRF
import re
# 加载预训练模型与分词器
tokenizer = BertTokenizer.from_pretrained("bert-base-marketing-finetuned")
intent_model = BertForSequenceClassification.from_pretrained("bert-base-marketing-finetuned")
entity_model = BiLSTM_CRF.load_model("bilstm_crf_entity_model.pth")
# 意图映射表
intent_map = {
0: "email_generation",
1: "automation_flow_generation",
2: "template_edit",
3: "brand_update"
}
# 实体提取正则规则(补充模型)
entity_rules = {
"flow_steps": r"(\d+)步",
"audience": r"新用户|老用户|试用用户|付费用户",
"email_purpose": r"介绍产品|快速入门|预约演示|促活|回访"
}
def preprocess_text(text):
"""文本预处理"""
text = re.sub(r"\s+", " ", text.strip()) # 去除冗余空格
text = re.sub(r"[^\w\s,。、;:?!]", "", text) # 去除特殊字符
return text
def intent_recognition(text):
"""意图识别"""
inputs = tokenizer(text, return_tensors="pt", truncation=True, padding=True)
with torch.no_grad():
outputs = intent_model(**inputs)
pred_intent = torch.argmax(outputs.logits).item()
return intent_map[pred_intent], torch.softmax(outputs.logits, dim=1)[0][pred_intent].item()
def entity_extraction(text):
"""实体提取(模型+规则)"""
entities = {}
# 模型提取
model_entities = entity_model.predict(text)
entities.update(model_entities)
# 规则补充
for key, pattern in entity_rules.items():
match = re.search(pattern, text)
if match:
entities[key] = match.group(1) if key == "flow_steps" else match.group()
return entities
def semantic_parse(text, brand_id=None):
"""语义解析主函数"""
# 预处理
clean_text = preprocess_text(text)
# 意图识别
intent, confidence = intent_recognition(clean_text)
# 实体提取
entities = entity_extraction(clean_text)
# 补充品牌ID
if brand_id:
entities["brand_id"] = brand_id
# 结构化参数
params = {
"intent": intent,
"confidence": confidence,
"entities": entities
}
return params
# 测试示例
if __name__ == "__main__":
user_input = "生成一个3步的新试用用户欢迎邮件流程,第一步介绍产品,第二步快速入门,第三步预约演示"
parse_params = semantic_parse(user_input, brand_id="brand_123")
print("结构化解析参数:", parse_params)
3.2 AI 内容生成模块
AI 内容生成模块基于大语言模型,接收语义解析后的结构化参数,生成邮件文案、主题行、受众筛选规则、自动化流程逻辑,核心解决内容生成效率与品牌调性一致性问题。
3.2.1 技术选型
采用自研 Prompt 工程 + 第三方 LLM API 调用 + 品牌风格适配层的方案,兼顾生成质量、响应速度与成本:
- LLM 选型:支持 GPT-4、Claude 3、文心一言等主流大语言模型,通过统一适配层屏蔽模型差异,可根据成本与性能需求切换;
- Prompt 工程:设计营销领域专属 Prompt 模板,包含角色定义、品牌风格约束、内容要求、格式规范、示例参考,确保生成内容符合营销场景与品牌调性;
- 品牌风格适配层:将品牌风格模型输出的风格参数(文案语气、用词偏好、禁忌词汇)注入 Prompt,实现个性化内容生成;
- 生成策略:采用批量生成 + 质量过滤 + 人工微调策略,单次生成多版本内容,通过规则过滤低质量结果,提升最终输出质量。
3.2.2 Prompt 模板设计
Prompt 模板是内容生成质量的核心,需精准约束生成内容的风格、结构、长度、格式,示例如下:
【角色】:你是资深电子邮件营销专家,擅长撰写符合品牌调性、高转化率的营销邮件文案
【品牌风格】:{{brand_tone}}(如:专业简洁、活泼亲和、高端正式)
【品牌信息】:{{brand_info}}(品牌名称、核心业务、目标用户)
【生成要求】:
1. 基于以下参数生成营销邮件内容:
- 受众:{{audience}}
- 邮件数量:{{email_count}}
- 每封邮件目的:{{email_purposes}}
- 语气:{{tone}}
- 长度:每封邮件正文200-300字
2. 输出内容包含:每封邮件的主题行、正文、CTA按钮文案
3. 严格符合品牌风格,无语法错误,文案简洁有吸引力
4. 输出格式:JSON格式,键为email_1、email_2...,值包含subject、content、cta
【示例参考】:
{
"email_1": {
"subject": "欢迎加入XX,开启高效办公之旅",
"content": "亲爱的用户,感谢你选择XX...",
"cta": "立即体验"
}
}
【参数】:
{{structured_params}}
3.2.3 核心生成流程
- 参数注入:将语义解析后的结构化参数、品牌风格参数注入 Prompt 模板,生成完整 Prompt;
- LLM 调用:通过 API 调用大语言模型,传入 Prompt,请求生成内容;
- 结果解析:解析 LLM 输出的 JSON 格式内容,校验格式合法性、内容完整性;
- 质量过滤:基于规则库过滤低质量内容(如字数不符、风格偏差、存在敏感词);
- 多版本生成:若过滤后无合格结果,自动调整 Prompt 重新生成,最多重试 3 次;
- 结果返回:返回合格的内容结果至后端服务,供前端预览。
3.2.4 代码示例(内容生成核心逻辑)
# AI内容生成模块核心代码(Python)
import openai
import json
from brand_style_model import get_brand_style
# 配置OpenAI API
openai.api_key = "your-api-key"
# Prompt模板
PROMPT_TEMPLATE = """
【角色】:你是资深电子邮件营销专家,擅长撰写符合品牌调性、高转化率的营销邮件文案
【品牌风格】:{brand_tone}
【品牌信息】:{brand_info}
【生成要求】:
1. 基于以下参数生成营销邮件内容:
- 受众:{audience}
- 邮件数量:{email_count}
- 每封邮件目的:{email_purposes}
- 语气:{tone}
- 长度:每封邮件正文200-300字
2. 输出内容包含:每封邮件的主题行、正文、CTA按钮文案
3. 严格符合品牌风格,无语法错误,文案简洁有吸引力
4. 输出格式:JSON格式,键为email_1、email_2...,值包含subject、content、cta
【参数】:
{structured_params}
"""
def generate_email_content(parse_params, brand_id):
"""生成邮件内容主函数"""
# 获取品牌风格信息
brand_style = get_brand_style(brand_id)
brand_tone = brand_style["tone"]
brand_info = brand_style["info"]
# 提取结构化参数
entities = parse_params["entities"]
structured_params = json.dumps(entities, ensure_ascii=False, indent=2)
# 构建Prompt
prompt = PROMPT_TEMPLATE.format(
brand_tone=brand_tone,
brand_info=brand_info,
audience=entities["audience"],
email_count=entities["flow_steps"],
email_purposes=entities["email_purpose"],
tone=brand_tone,
structured_params=structured_params
)
# 调用LLM生成内容
try:
response = openai.ChatCompletion.create(
model="gpt-4",
messages=[{"role": "user", "content": prompt}],
temperature=0.7, # 控制生成随机性,0.7兼顾创意与稳定性
max_tokens=2000
)
# 解析生成结果
content = response.choices[0].message.content
email_content = json.loads(content)
# 质量过滤(简单示例)
for email in email_content.values():
if len(email["content"]) < 150 or len(email["content"]) > 350:
raise ValueError("邮件正文字数不符合要求")
return email_content
except Exception as e:
print(f"内容生成失败:{e}")
return None
# 测试示例
if __name__ == "__main__":
parse_params = {
"intent": "automation_flow_generation",
"confidence": 0.95,
"entities": {
"flow_steps": 3,
"audience": "新试用用户",
"email_purpose": ["介绍产品", "快速入门", "预约演示"],
"brand_id": "brand_123"
}
}
content = generate_email_content(parse_params, "brand_123")
print("生成的邮件内容:", json.dumps(content, ensure_ascii=False, indent=2))
3.3 AI 设计生成模块
AI 设计生成模块基于扩散模型,结合品牌风格库,生成适配多邮箱客户端的邮件视觉模板,核心解决邮件设计效率低、多客户端渲染不一致的问题。
3.3.1 技术选型
采用Stable Diffusion 优化模型 + 品牌风格嵌入 + 邮件渲染约束层的方案,兼顾设计质量、适配性与生成速度:
- 基础模型:基于 Stable Diffusion XL 微调,适配邮件设计场景,优化布局、配色、排版生成能力;
- 品牌风格嵌入:将品牌视觉特征(主色、辅助色、字体、Logo、设计元素)转化为模型可识别的嵌入向量,注入生成过程,确保设计一致性;
- 邮件渲染约束层:基于邮件渲染规则库,对生成的设计模板进行HTML 兼容性处理、CSS 内联化、响应式适配,解决不同邮箱客户端的渲染差异;
- 生成加速:采用模型蒸馏、TensorRT 加速,降低生成耗时,单模板生成时间控制在 10 秒内。
3.3.2 品牌风格提取与嵌入
品牌风格提取是设计生成的关键,流程如下:
- 品牌素材输入:用户上传品牌官网 URL、Logo、参考设计图片;
- 视觉特征提取:通过计算机视觉模型(如 ResNet)提取素材的主色、辅助色、字体特征、设计元素(几何图形、线条风格);
- 风格向量生成:将视觉特征转化为固定维度的嵌入向量(如 512 维),存储至品牌风格库;
- 风格注入生成:设计生成时,将风格向量注入扩散模型的生成过程,引导模型生成符合品牌视觉风格的模板。
3.3.3 邮件渲染适配处理
不同邮箱客户端(Gmail、Outlook、QQ 邮箱、163 邮箱)对 HTML/CSS 的支持度差异较大,是邮件设计的核心痛点。Brew 通过渲染约束层实现全客户端兼容,核心处理逻辑:
- CSS 内联化:将所有 CSS 样式转为内联样式(style 属性),避免外部样式表被邮箱客户端屏蔽;
- 标签兼容性过滤:仅保留所有客户端支持的 HTML 标签(如 div、table、tr、td、p、a),移除不兼容标签(如 flex、grid 相关标签);
- 响应式适配:基于媒体查询(@media)实现移动端适配,自动调整布局、字体大小、图片尺寸;
- 图片优化:自动压缩图片大小,生成适配不同分辨率的图片,避免图片加载缓慢或显示异常;
- 渲染测试:生成模板后,自动调用多客户端渲染测试接口,检测渲染异常并自动修复。
3.3.4 核心生成流程
- 参数接收:接收内容生成模块输出的文案内容、品牌风格向量、邮件数量参数;
- 设计 Prompt 构建:结合文案长度、邮件目的、品牌风格,构建设计专属 Prompt(如 “生成专业简洁风格的产品介绍邮件模板,主色 #2563EB,布局简洁,包含 Logo、标题、正文区、CTA 按钮,适配桌面端与移动端”);
- 扩散模型生成:将设计 Prompt 与品牌风格向量输入微调后的 Stable Diffusion 模型,生成邮件设计初稿(HTML 模板 + 配图);
- 渲染适配处理:通过渲染约束层对初稿进行 CSS 内联化、标签过滤、响应式适配、图片优化;
- 渲染测试与修复:自动测试多客户端渲染效果,修复异常问题(如布局错乱、样式丢失);
- 结果输出:输出最终适配的 HTML 模板、配图资源,返回至后端服务。
3.4 自动化流程服务
自动化流程服务负责解析 AI 生成的流程逻辑,构建、调度、执行自动化工作流,核心解决多步骤营销流程配置复杂、调度效率低的问题。
3.4.1 技术选型
采用Go 语言 + 工作流引擎 + 状态机 + 定时调度器的方案,保障高并发、高可用、低延迟:
- 开发语言:Go,天生支持高并发、轻量级协程,适合流程调度场景;
- 工作流引擎:自研轻量级工作流引擎,支持触发节点、邮件节点、定时节点、分支节点、条件判断节点、结束节点;
- 状态机:基于状态机管理流程执行状态(待触发、执行中、已完成、异常),保障流程执行稳定性;
- 定时调度器:基于 Cron 表达式实现定时触发,支持分钟级、小时级、日级、周级定时规则;
- 消息队列:基于 Redis 消息队列实现流程节点解耦,异步处理耗时节点(如邮件发送),提升流程吞吐量。
3.4.2 流程逻辑解析与建模
AI 生成的流程逻辑为自然语言描述,自动化流程服务需将其转化为可执行的工作流模型,核心步骤:
- 流程逻辑接收:接收内容生成模块输出的自动化流程逻辑描述(如 “新用户注册后立即发送欢迎邮件,24 小时后发送快速入门邮件,用户未点击则 3 天后发送促活邮件”);
- 逻辑语义解析:基于 NLP 模型解析流程逻辑,提取触发条件、节点顺序、定时规则、分支条件、异常处理;
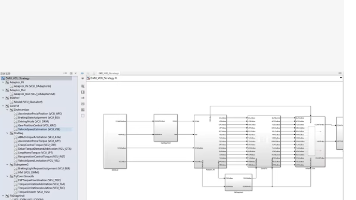
- 工作流建模:将解析后的逻辑转化为标准化工作流模型(JSON 格式),示例如下:
{
"flow_id": "flow_456",
"flow_name": "新用户欢迎流程",
"trigger": {
"type": "event",
"event_name": "user_register",
"audience": "new_users"
},
"nodes": [
{
"node_id": "node_1",
"type": "email",
"email_id": "email_1",
"delay": 0,
"next_node": "node_2"
},
{
"node_id": "node_2",
"type": "delay",
"duration": "24h",
"next_node": "node_3"
},
{
"node_id": "node_3",
"type": "email",
"email_id": "email_2",
"next_node": "node_4"
},
{
"node_id": "node_4",
"type": "condition",
"condition": "email_2_click == false",
"true_node": "node_5",
"false_node": "node_end"
},
{
"node_id": "node_5",
"type": "delay",
"duration": "3d",
"next_node": "node_6"
},
{
"node_id": "node_6",
"type": "email",
"email_id": "email_3",
"next_node": "node_end"
},
{
"node_id": "node_end",
"type": "end"
}
],
"status": "active",
"create_time": "2026-05-27T12:00:00Z"
}
- 模型校验:校验工作流模型合法性(节点 ID 唯一、无循环引用、条件逻辑合法),校验失败则返回错误提示;
- 模型存储:将校验通过的工作流模型存储至 MongoDB,关联用户 ID 与品牌 ID。
3.4.3 流程调度与执行
流程调度与执行是自动化流程服务的核心,核心逻辑:
- 触发监听:监听触发事件(如用户注册、订单支付、定时任务),事件触发后创建流程实例;
- 实例初始化:初始化流程实例状态为 “执行中”,记录实例 ID、流程 ID、用户 ID、触发时间;
- 节点调度:基于工作流模型,按节点顺序依次调度执行,当前节点执行完成后触发下一个节点;
- 异步处理:邮件发送等耗时节点通过 Redis 消息队列异步处理,避免阻塞主流程;
- 状态更新:实时更新流程实例与节点状态,执行成功则标记为 “已完成”,失败则标记为 “异常” 并触发重试;
- 异常重试:节点执行失败时,基于重试规则(最多 3 次、指数退避)自动重试,重试失败则记录异常并告警;
- 流程结束:所有节点执行完成后,标记流程实例为 “已完成”,释放资源。
3.4.4 代码示例(流程调度核心逻辑)
// 自动化流程调度核心代码(Go)
package main
import (
"context"
"encoding/json"
"fmt"
"time"
"github.com/go-redis/redis/v8"
)
// 工作流模型结构体
type Workflow struct {
FlowID string `json:"flow_id"`
Trigger TriggerNode `json:"trigger"`
Nodes []WorkflowNode `json:"nodes"`
Status string `json:"status"`
}
// 流程节点结构体
type WorkflowNode struct {
NodeID string `json:"node_id"`
Type string `json:"type"`
EmailID string `json:"email_id,omitempty"`
Delay string `json:"delay,omitempty"`
Duration string `json:"duration,omitempty"`
Condition string `json:"condition,omitempty"`
NextNode string `json:"next_node,omitempty"`
TrueNode string `json:"true_node,omitempty"`
FalseNode string `json:"false_node,omitempty"`
}
// 流程实例结构体
type FlowInstance struct {
InstanceID string `json:"instance_id"`
FlowID string `json:"flow_id"`
UserID string `json:"user_id"`
Status string `json:"status"`
CreateTime string `json:"create_time"`
}
var redisClient *redis.Client
var ctx = context.Background()
// 初始化Redis
func initRedis() {
redisClient = redis.NewClient(&redis.Options{
Addr: "localhost:6379",
})
}
// 加载工作流模型
func loadWorkflow(flowID string) (*Workflow, error) {
// 从MongoDB加载工作流模型(示例简化)
workflowJSON, err := redisClient.Get(ctx, fmt.Sprintf("workflow:%s", flowID)).Result()
if err != nil {
return nil, err
}
var workflow Workflow
err = json.Unmarshal([]byte(workflowJSON), &workflow)
if err != nil {
return nil, err
}
return &workflow, nil
}
// 调度执行流程
func executeWorkflow(instance *FlowInstance, workflow *Workflow) error {
instance.Status = "running"
// 遍历节点执行
currentNodeID := workflow.Nodes[0].NodeID
for {
// 查找当前节点
var currentNode *WorkflowNode
for _, node := range workflow.Nodes {
if node.NodeID == currentNodeID {
currentNode = &node
break
}
}
if currentNode == nil {
return fmt.Errorf("节点%s不存在", currentNodeID)
}
// 执行节点
err := executeNode(instance, currentNode)
if err != nil {
return fmt.Errorf("节点%s执行失败:%v", currentNodeID, err)
}
// 判断下一个节点
if currentNode.Type == "end" {
instance.Status = "completed"
break
}
currentNodeID = currentNode.NextNode
}
return nil
}
// 执行单个节点
func executeNode(instance *FlowInstance, node *WorkflowNode) error {
switch node.Type {
case "email":
// 异步发送邮件(推送至Redis消息队列)
emailTask := map[string]string{
"instance_id": instance.InstanceID,
"email_id": node.EmailID,
"user_id": instance.UserID,
}
taskJSON, _ := json.Marshal(emailTask)
return redisClient.LPush(ctx, "email:send:queue", taskJSON).Err()
case "delay":
// 延迟执行
duration, err := time.ParseDuration(node.Duration)
if err != nil {
return err
}
time.Sleep(duration)
return nil
case "condition":
// 条件判断(示例简化,实际需查询用户行为数据)
// 此处模拟条件判断结果
click := true
if click {
node.NextNode = node.TrueNode
} else {
node.NextNode = node.FalseNode
}
return nil
case "end":
return nil
default:
return fmt.Errorf("未知节点类型:%s", node.Type)
}
}
func main() {
initRedis()
// 模拟触发流程
instance := &FlowInstance{
InstanceID: "instance_789",
FlowID: "flow_456",
UserID: "user_123",
Status: "pending",
CreateTime: time.Now().Format(time.RFC3339),
}
workflow, err := loadWorkflow(instance.FlowID)
if err != nil {
fmt.Printf("加载工作流失败:%v\n", err)
return
}
err = executeWorkflow(instance, workflow)
if err != nil {
fmt.Printf("执行流程失败:%v\n", err)
return
}
fmt.Printf("流程执行完成:%+v\n", instance)
}
四、跨 AI 智能体兼容机制
Brew 核心特性之一是兼容任意 AI 智能体,支持将平台文档 / 指令粘贴至 OpenClaw、Viktor、Claude、Lovable 等第三方 AI 智能体使用,核心通过标准化指令格式、统一数据接口、协议适配层实现,无厂商锁定。
4.1 兼容设计核心目标
- 指令通用化:Brew 生成的营销指令、流程逻辑、品牌配置可直接被第三方 AI 智能体识别、解析、执行,无需二次修改;
- 数据互通化:第三方 AI 智能体生成的内容、设计、流程可无缝导入 Brew,复用平台的发送、渲染、统计能力;
- 协议标准化:屏蔽不同 AI 智能体的通信协议差异,实现一次接入、多智能体兼容;
- 无锁定特性:用户可自由切换 AI 智能体,无需迁移数据、重新配置品牌,降低迁移成本。
4.2 标准化指令格式
Brew 定义通用营销指令格式(Common Marketing Instruction Format,CMIF),作为与第三方 AI 智能体的交互标准,格式基于 JSON 设计,包含指令类型、品牌信息、内容参数、设计参数、流程参数、格式要求六大核心字段,示例如下:
{
"instruction_type": "marketing_campaign_generation",
"brand_info": {
"brand_id": "brand_123",
"brand_name": "XX科技",
"brand_tone": "专业简洁",
"brand_color": "#2563EB",
"brand_font": "微软雅黑"
},
"content_params": {
"campaign_purpose": "新用户获客",
"audience": "25-35岁职场人士",
"email_count": 3,
"email_tone": "亲和",
"content_length": "200-300字"
},
"design_params": {
"layout_style": "简洁现代",
"include_logo": true,
"include_cta": true,
"responsive": true
},
"flow_params": {
"trigger_condition": "user_register",
"delay_rules": ["0h", "24h", "72h"],
"branch_conditions": ["click == false"]
},
"format_requirements": {
"output_format": "json",
"include_subject": true,
"include_cta": true
}
}
该格式具备无歧义、易解析、可扩展特性,第三方 AI 智能体只需适配该格式,即可直接处理 Brew 生成的指令,输出符合要求的内容、设计、流程。
4.3 协议适配层实现
不同 AI 智能体(OpenClaw、Viktor、Claude、Lovable)采用不同的通信协议、数据格式、接口规范,Brew 通过协议适配层屏蔽差异,实现统一接入。
4.3.1 适配层核心能力
- 协议转换:将 Brew 内部统一的 RESTful 协议转换为第三方 AI 智能体的专用协议(如 Claude 的 Anthropic API 协议、OpenClaw 的自定义 RPC 协议);
- 数据格式转换:将 CMIF 格式数据转换为第三方智能体要求的格式(如 JSON、XML、Protobuf);
- 接口适配:适配第三方智能体的接口路径、请求方法、参数名称、认证方式(API Key、OAuth2);
- 响应归一化:将第三方智能体的响应结果统一转换为 Brew 内部格式,供上层服务使用。
4.3.2 适配流程示例(以 Claude 为例)
- 指令导出:Brew 用户生成营销指令后,导出 CMIF 格式指令;
- 格式转换:协议适配层将 CMIF 格式转换为 Claude 要求的 Prompt 格式;
- 协议封装:适配层添加 Claude API Key、请求头、接口路径,封装为标准 Anthropic API 请求;
- 请求发送:适配层通过 HTTP 发送请求至 Claude API;
- 响应解析:接收 Claude 响应结果,解析生成的内容、设计、流程;
- 格式归一化:将响应结果转换为 Brew 内部格式,支持导入 Brew 平台编辑、发送。
4.4 无厂商锁定技术保障
无厂商锁定(No lock-in)是 Brew 的核心设计理念,除跨 AI 智能体兼容外,还通过数据导出标准化、ESP 接口通用化、品牌配置可迁移三大技术手段实现:
- 数据导出标准化:所有用户数据(品牌配置、模板、流程、发送记录、统计数据)支持导出为CSV、JSON、XML通用格式,可直接导入其他平台;
- ESP 接口通用化:邮件发送服务适配SMTP/ESMTP 标准协议与主流 ESP(SendGrid、Mailchimp、阿里云邮件推送)的开放 API,用户可自由选择发送渠道;
- 品牌配置可迁移:品牌风格模型、视觉配置、文案风格配置支持导出为独立配置文件,迁移至其他 AI 工具时可直接复用,无需重新配置。
五、邮件渲染适配技术
邮件渲染适配是保障邮件在所有收件箱完美渲染的核心能力,Brew 基于渲染规则库、自动化适配引擎、多客户端测试构建全链路渲染适配体系,解决不同邮箱客户端的渲染差异问题。
5.1 邮箱客户端渲染差异痛点
主流邮箱客户端对 HTML/CSS 的支持度差异显著,核心差异如下:
- CSS 支持:Gmail 仅支持内联 CSS,不支持外部样式表、CSS 选择器;Outlook 不支持 flex、grid 布局,对圆角、阴影样式支持有限;
- HTML 标签:部分客户端不支持 div、span 标签的复杂嵌套,仅兼容 table、tr、td 等表格标签;
- 图片显示:部分客户端默认屏蔽外部图片,需添加 alt 文本;
- 响应式适配:移动端适配规则在不同客户端解析不一致,易出现布局错乱。
5.2 渲染规则库构建
Brew 基于主流邮箱客户端(Gmail、Outlook、QQ 邮箱、163 邮箱、网易邮箱) 的渲染特性,构建邮件渲染规则库,包含CSS 规则、HTML 标签规则、布局规则、图片规则、响应式规则五大类,规则库持续迭代更新,适配客户端版本更新带来的渲染变化。
核心规则示例:
- CSS 规则:所有样式必须内联,禁止使用 class、id 选择器;仅支持 color、font-size、padding、margin、background-color 等基础样式;
- HTML 标签规则:布局优先使用 table、tr、td 标签,替代 div 布局;禁止使用 iframe、video、audio 标签;
- 布局规则:邮件宽度固定为 600px(桌面端适配),移动端通过媒体查询自动调整为 100%;
- 图片规则:图片格式优先使用 JPG、PNG,大小控制在 500KB 以内;必须添加 alt 文本;
- 响应式规则:通过 @media (max-width: 600px) 媒体查询,调整移动端字体大小、图片尺寸、布局间距。
5.3 自动化适配引擎
自动化适配引擎是渲染适配的核心,基于渲染规则库,对 AI 生成的 HTML 模板进行全自动化适配处理,无需人工干预,核心处理流程:
- 模板解析:解析 AI 生成的 HTML 模板,构建 DOM 树;
- CSS 内联化:将所有外部 CSS、内部 CSS 转换为内联 style 属性,移除 class、id 选择器;
- 标签转换:将 div、span 等标签转换为 table、tr、td 标签,重构布局结构;
- 样式过滤:过滤不兼容的 CSS 样式(如 flex、grid、border-radius、box-shadow),替换为兼容样式;
- 响应式适配:添加移动端媒体查询,调整布局、字体、图片尺寸;
- 图片优化:压缩图片大小,生成适配分辨率,添加 alt 文本;
- 代码压缩:移除冗余代码、注释,压缩 HTML 体积,提升加载速度。
5.4 多客户端渲染测试
适配处理完成后,自动化测试模块调用多客户端渲染测试接口,对模板进行全客户端渲染测试,核心流程:
- 测试请求:将适配后的 HTML 模板发送至渲染测试接口,请求在主流客户端中渲染;
- 结果采集:采集各客户端的渲染截图、DOM 结构、样式信息;
- 异常检测:对比标准渲染模板,检测布局错乱、样式丢失、图片显示异常等问题;
- 自动修复:针对检测到的异常,自动调整模板代码,重新适配;
- 测试报告:生成渲染测试报告,展示各客户端渲染结果、异常问题、修复状态。
六、数据安全与权限控制
Brew 处理用户核心数据(品牌信息、邮件内容、用户受众数据、自动化流程配置),数据安全与权限控制是核心设计要求,采用数据加密、访问控制、脱敏处理、审计日志、合规适配五大技术手段,保障数据安全。
6.1 数据加密
采用传输加密 + 存储加密双重加密机制:
- 传输加密:所有 API 通信采用 HTTPS 协议,基于 TLS 1.3 加密,防止数据传输过程中被窃取、篡改;
- 存储加密:
- 结构化数据(用户信息、品牌配置):PostgreSQL 透明加密,敏感字段(API Key、密钥)采用 AES-256 加密存储;
- 非结构化数据(邮件内容、模板):MongoDB 字段级加密,静态资源(图片、附件)对象存储服务端加密;
- 缓存数据(会话信息、热点数据):Redis 内存加密,防止缓存数据泄露。
6.2 访问控制
基于RBAC(基于角色的访问控制) 模型,实现精细化权限管理:
- 角色定义:预设超级管理员、团队管理员、普通用户、只读用户等角色;
- 权限分配:不同角色分配不同权限(品牌管理、内容生成、模板编辑、流程配置、邮件发送、数据查看、导出);
- 接口权限:API 接口绑定权限,用户请求时校验权限,无权限则拒绝访问;
- 数据隔离:不同用户、不同团队的数据物理隔离,禁止跨团队数据访问;
- IP 限制:支持绑定访问 IP,仅允许指定 IP 访问平台,防止非法访问。
6.3 数据脱敏
针对敏感数据(用户手机号、邮箱、地址、支付信息),采用数据脱敏处理:
- 展示脱敏:前端展示时,敏感数据部分隐藏(如手机号 138**1234、邮箱 a*@xxx.com);
- 导出脱敏:用户导出数据时,敏感数据自动脱敏,仅保留非敏感字段;
- AI 生成脱敏:AI 生成内容时,自动过滤敏感数据,避免敏感信息泄露。
6.4 审计日志
全链路操作日志记录,实现操作可追溯、异常可审计:
- 日志内容:记录用户 ID、操作时间、操作 IP、操作类型(登录、生成内容、编辑模板、发送邮件、导出数据)、操作详情、操作结果;
- 日志存储:日志存储至时序数据库,保留 180 天,支持日志查询、导出;
- 异常告警:检测到异常操作(如批量导出数据、删除大量模板、异地登录),实时触发告警,通知管理员。
6.5 合规适配
适配全球数据安全法规,保障合规运营:
- GDPR 适配:支持用户数据删除、导出、修改,用户同意管理;
- CCPA 适配:支持用户隐私数据查询、删除,禁止数据售卖;
- 国内法规适配:符合《网络安全法》《个人信息保护法》,用户信息收集需获得用户同意,数据存储在国内服务器。
七、性能优化策略
Brew 核心场景为 AI 生成(高耗时)、邮件发送(高并发)、数据统计(大数据量),性能优化直接影响用户体验,核心优化策略包括AI 生成优化、接口响应优化、数据库优化、缓存优化、并发处理优化。
7.1 AI 生成性能优化
AI 生成是最耗时环节(单内容生成 5-10 秒),优化目标为降低生成耗时、提升生成吞吐量:
- 模型优化:采用模型蒸馏、量化压缩,减小模型体积,提升推理速度;
- 批量生成:合并用户生成请求,批量调用 LLM,减少 API 调用次数,提升吞吐量;
- 缓存复用:缓存高频生成结果(如常用模板、标准文案),相同请求直接返回缓存结果,无需重新生成;
- 异步生成:AI 生成请求异步处理,前端返回生成任务 ID,用户可继续操作,生成完成后通知用户;
- 多模型负载均衡:接入多个 LLM 服务商,基于负载情况动态分配请求,避免单一服务商限流。
7.2 接口响应优化
优化目标为降低接口响应时间、提升接口并发能力:
- API 网关优化:Kong 网关开启压缩、连接复用,减少请求延迟;
- 接口精简:精简接口返回字段,仅返回必要数据,减少数据传输量;
- GraphQL 替代:复杂查询接口采用 GraphQL,支持按需获取数据,避免过度请求;
- 边缘计算:静态资源、高频接口部署至 CDN 边缘节点,缩短访问距离,提升响应速度。
7.3 数据库优化
优化目标为提升数据库读写性能、降低查询延迟:
- 索引优化:核心查询字段(用户 ID、品牌 ID、流程 ID)建立索引,避免全表扫描;
- 分库分表:大数据量表(发送记录、行为日志)按时间、用户 ID 分库分表,提升查询效率;
- 读写分离:主库负责写操作,从库负责读操作,分担主库压力;
- 查询优化:优化 SQL 语句,避免复杂关联查询、嵌套查询,减少数据库负载。
7.4 缓存优化
充分利用 Redis 缓存,降低数据库访问压力:
- 热点数据缓存:缓存用户会话、品牌配置、常用模板、生成结果,缓存过期时间 1-24 小时;
- 接口结果缓存:缓存高频查询接口结果(数据看板、模板列表),减少重复查询;
- 分布式缓存:Redis 集群部署,支持缓存数据高可用、水平扩展;
- 缓存穿透 / 击穿 / 雪崩防护:采用布隆过滤器、互斥锁、过期时间随机化,避免缓存异常。
7.5 并发处理优化
针对邮件发送、流程调度等高并发场景,优化并发处理能力:
- 协程并发:Go 语言服务采用轻量级协程,单进程支持上万并发,资源占用低;
- 消息队列解耦:邮件发送、数据统计等耗时操作通过 Redis 消息队列异步处理,提升系统吞吐量;
- 连接池优化:数据库、Redis、第三方 API 连接池优化,合理设置连接数,避免连接耗尽;
- 限流熔断:高并发接口设置限流规则,下游服务故障时熔断降级,保障系统稳定性。
八、总结与展望
8.1 技术总结
Brew 作为 AI 驱动的电子邮件自动化引擎,核心技术体系围绕自然语言处理、大语言模型、扩散模型、分布式架构、自动化流程调度、跨平台兼容、渲染适配、数据安全八大核心能力构建,通过模块化、分层化、标准化设计,解决传统电子邮件营销工具的效率低、适配差、锁定强、安全弱等痛点。
从技术架构看,Brew 采用前端轻量化交互、API 网关统一流量、后端微服务解耦、AI 引擎中台支撑、数据分层存储的分布式架构,兼顾高可用、高扩展性、低耦合;从核心模块看,语义解析模块实现自然语言到结构化参数的转化,AI 生成模块实现文案与设计的自动化创作,自动化流程服务实现多步骤营销流程的调度执行,跨智能体兼容机制实现无锁定生态适配,渲染适配技术保障全客户端渲染一致性;从非功能特性看,通过数据加密、权限控制、审计日志保障数据安全,通过多维度性能优化保障系统高并发、低延迟。
8.2 技术展望
随着 AI 技术、云计算、大数据的持续发展,Brew 技术体系将向智能化、轻量化、生态化、实时化方向演进:
- 智能化升级:引入多模态大模型,支持图片、语音、视频等多模态输入生成;强化学习优化生成策略,自动学习用户偏好,提升生成内容精准度;
- 轻量化部署:推出私有化部署版本,支持企业本地部署,满足数据本地化需求;优化模型体积,支持边缘设备部署;
- 生态化扩展:拓展兼容更多 AI 智能体、ESP、CRM、营销工具,构建开放的营销自动化生态;开放 API 接口,支持开发者二次开发、定制化功能;
- 实时化交互:优化 AI 生成速度,实现秒级生成;支持实时对话式编辑,用户可通过自然语言实时调整生成内容、设计、流程;
- 数据驱动优化:基于用户行为数据、邮件效果数据,构建智能推荐模型,自动推荐最优文案、设计、发送时间、受众人群,提升营销转化效果。
互动环节
以上就是关于 Brew 电子邮件自动化引擎的全维度技术解析,从架构设计到模块实现、从算法原理到工程落地,全面拆解了其核心技术逻辑。
如果觉得这篇技术干货对你有帮助,欢迎点赞、收藏、加关注,后续会持续分享更多 AI 营销工具、自动化平台的深度技术解析,带你从底层原理看懂前沿工具!
你还希望了解 Brew 哪些技术细节?或者对 AI 驱动的营销自动化平台有什么技术疑问?欢迎在评论区留言交流!

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 10
10 0
0- 0



 已为社区贡献96条内容
已为社区贡献96条内容

所有评论(0)