大模型应用开发必读:OpenAI 接口格式全方位详解与生产最佳实践
OpenAI 接口格式详解
本文面向开发者,系统梳理 OpenAI 及 OpenAI-Compatible API 的常见接口格式:认证、模型列表、Chat Completions、Responses、Embeddings、工具调用、流式输出、错误处理与最佳实践。
1. 什么是 OpenAI 接口格式
OpenAI 接口格式通常指以 OpenAI REST API 为参考的一套请求与响应约定。很多大模型服务商会提供 OpenAI-Compatible API,即尽量复用 OpenAI 的路径、请求字段和响应结构,方便开发者低成本迁移。
典型特征包括:
-
使用 HTTP REST 接口。
-
使用 JSON 作为主要请求与响应格式。
-
使用
Authorization: Bearer API_KEY进行鉴权。 -
以
model字段指定模型。 -
Chat 类任务使用
messages数组表达上下文。 -
支持非流式和流式输出。
-
支持工具调用、结构化输出、Embedding 等能力。
2. 基础请求规范
2.1 Base URL
官方 OpenAI API 常见基础地址:
https://api.openai.com/v1
OpenAI-Compatible 服务一般会提供自己的 Base URL,例如:
https://api.example.com/v1
调用时通常只需要替换 Base URL 和 API Key,业务代码可以尽量复用。
2.2 请求头
Authorization: Bearer YOUR_API_KEY
Content-Type: application/json
常见请求头说明:
| Header | 是否必需 | 说明 |
|---|---|---|
Authorization |
是 | Bearer Token 鉴权 |
Content-Type |
是 | 通常为 application/json |
Accept |
否 | 可指定期望返回类型 |
OpenAI-Organization |
否 | 官方 OpenAI 组织 ID,部分场景使用 |
Idempotency-Key |
否 | 幂等键,适合需要避免重复提交的场景 |
不要把 API Key 写进前端代码、Git 仓库、日志或报错信息中。生产环境应通过服务端代理、环境变量或密钥管理服务读取。
3. 常见接口总览
| 接口 | 路径 | 主要用途 |
|---|---|---|
| 模型列表 | GET /v1/models |
查询可用模型 |
| Chat Completions | POST /v1/chat/completions |
多轮对话、文本生成、工具调用 |
| Responses | POST /v1/responses |
新一代统一生成接口,支持文本、图像、工具等多模态输入输出 |
| Embeddings | POST /v1/embeddings |
文本向量化,用于检索、聚类、相似度计算 |
| Images | POST /v1/images/generations |
图像生成,具体字段因模型而异 |
| Audio | POST /v1/audio/transcriptions |
语音转文本 |
| Files | POST /v1/files |
上传文件,用于微调、批处理、助手等场景 |
| Batch | POST /v1/batches |
批量异步任务 |
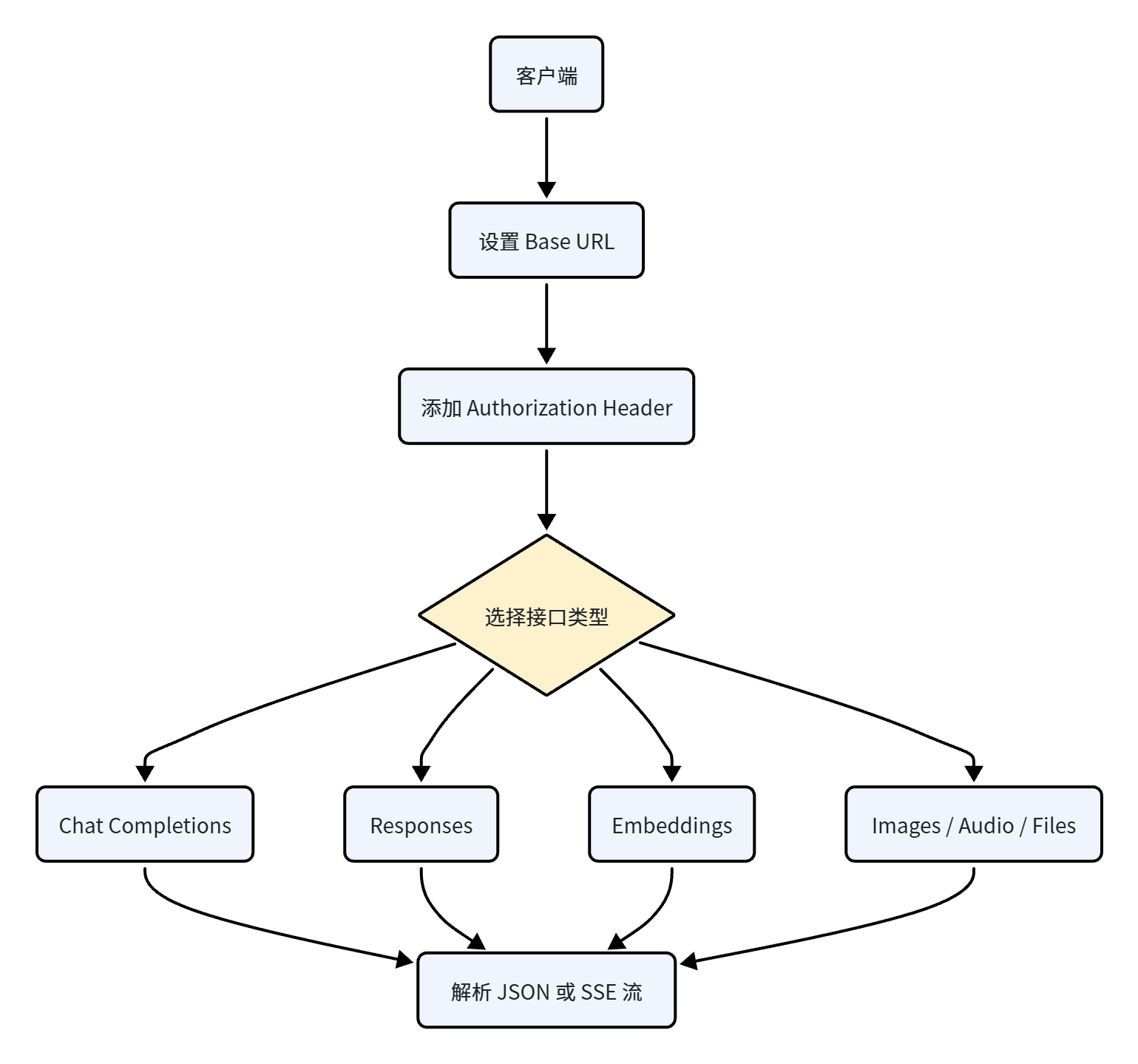
4. 模型列表接口:GET /v1/models
4.1 请求示例
curl https://api.openai.com/v1/models \
-H "Authorization: Bearer $OPENAI_API_KEY"
4.2 响应示例
{
"object": "list",
"data": [
{
"id": "gpt-4.1",
"object": "model",
"created": 1715367049,
"owned_by": "openai"
}
]
}
4.3 字段说明
| 字段 | 类型 | 说明 |
|---|---|---|
object |
string | 通常为 list |
data |
array | 模型对象列表 |
data[].id |
string | 模型 ID,调用其他接口时填入 model |
data[].owned_by |
string | 模型归属方 |
5. Chat Completions 接口
Chat Completions 是目前 OpenAI-Compatible 生态中最常见的接口格式,适合聊天、问答、摘要、分类、代码生成、Agent 工具调用等场景。
5.1 请求路径
POST /v1/chat/completions
5.2 最小请求示例
{
"model": "gpt-4.1-mini",
"messages": [
{
"role": "user",
"content": "用一句话解释什么是向量数据库"
}
]
}
5.3 cURL 示例
curl https://api.openai.com/v1/chat/completions \
-H "Authorization: Bearer $OPENAI_API_KEY" \
-H "Content-Type: application/json" \
-d '{
"model": "gpt-4.1-mini",
"messages": [
{"role": "user", "content": "写一个 Python 快速排序"}
]
}'
5.4 messages 格式
messages 是 Chat Completions 的核心字段,用于表达上下文。
| role | 用途 | 示例 |
|---|---|---|
system |
设定模型行为、身份、约束 | “你是严谨的技术文档助手” |
user |
用户输入 | “帮我解释这个接口” |
assistant |
模型历史回复 | “好的,下面是解释……” |
tool |
工具调用结果 | 查询数据库后的返回内容 |
示例:
{
"model": "gpt-4.1-mini",
"messages": [
{
"role": "system",
"content": "你是一个资深后端工程师,回答要准确、简洁。"
},
{
"role": "user",
"content": "解释 HTTP 429 的含义。"
}
]
}
5.5 content 的几种形态
纯文本 content
{
"role": "user",
"content": "总结下面这段文章"
}
多模态 content
部分模型支持数组形式的 content,用于同时传入文本和图片。
{
"role": "user",
"content": [
{
"type": "text",
"text": "请描述这张图片"
},
{
"type": "image_url",
"image_url": {
"url": "https://example.com/image.png"
}
}
]
}
OpenAI-Compatible 服务对多模态字段的支持差异较大。接入第三方服务时,应优先查看该服务的模型能力说明。
6. Chat Completions 常用参数
| 参数 | 类型 | 默认值 | 说明 |
|---|---|---|---|
model |
string | 无 | 模型 ID,必填 |
messages |
array | 无 | 对话上下文,必填 |
temperature |
number | 通常 1 | 控制随机性,越高越发散 |
top_p |
number | 通常 1 | nucleus sampling,通常不和 temperature 同时大幅调整 |
max_tokens |
integer | 模型默认 | 限制输出 token 数,部分新接口使用 max\_output\_tokens |
stream |
boolean | false | 是否使用流式输出 |
stop |
string/array | null | 遇到指定文本停止输出 |
presence_penalty |
number | 0 | 鼓励引入新主题 |
frequency_penalty |
number | 0 | 减少重复表达 |
tools |
array | null | 可调用工具定义 |
tool_choice |
string/object | auto | 控制是否调用工具 |
response_format |
object | null | 控制结构化输出格式 |
seed |
integer | null | 尝试获得更稳定的采样结果,非绝对确定 |
参数选择建议
稳定、可控任务
-
分类
-
信息抽取
-
JSON 生成
-
代码转换
建议:
{
"temperature": 0,
"top_p": 1
}
创意、发散任务
-
文案创作
-
头脑风暴
-
故事生成
-
命名方案
建议:
{
"temperature": 0.7,
"top_p": 0.9
}
7. Chat Completions 响应格式
7.1 非流式响应示例
{
"id": "chatcmpl-abc123",
"object": "chat.completion",
"created": 1710000000,
"model": "gpt-4.1-mini",
"choices": [
{
"index": 0,
"message": {
"role": "assistant",
"content": "向量数据库是一种专门存储和检索向量表示的数据系统,常用于语义搜索和推荐。"
},
"finish_reason": "stop"
}
],
"usage": {
"prompt_tokens": 20,
"completion_tokens": 28,
"total_tokens": 48
}
}
7.2 核心响应字段
| 字段 | 类型 | 说明 |
|---|---|---|
id |
string | 本次请求的唯一 ID |
object |
string | 对象类型,如 chat\.completion |
created |
integer | Unix 时间戳 |
model |
string | 实际使用的模型 |
choices |
array | 候选输出列表 |
choices[].message |
object | 模型回复消息 |
choices[].finish_reason |
string | 结束原因 |
usage |
object | token 用量统计 |
7.3 finish_reason 常见值
| 值 | 含义 | 处理建议 |
|---|---|---|
stop |
正常停止 | 可直接使用结果 |
length |
达到 token 限制 | 增大 token 限制或继续请求 |
tool_calls |
模型请求调用工具 | 执行工具后把结果放回 messages |
content_filter |
内容被安全策略拦截 | 调整输入或提示用户 |
null |
流式输出未结束 | 继续读取流 |
8. 流式输出格式
流式输出适合聊天界面、长文本生成、实时交互等场景。请求时设置:
{
"model": "gpt-4.1-mini",
"messages": [
{"role": "user", "content": "写一段 200 字的产品介绍"}
],
"stream": true
}
8.1 SSE 返回格式
OpenAI 流式响应通常使用 Server-Sent Events,每个片段形如:
data: {"id":"chatcmpl-abc","object":"chat.completion.chunk","choices":[{"delta":{"content":"你好"},"index":0,"finish_reason":null}]}
data: {"id":"chatcmpl-abc","object":"chat.completion.chunk","choices":[{"delta":{"content":",世界"},"index":0,"finish_reason":null}]}
data: [DONE]
8.2 流式解析要点
-
按行读取,以
data:开头的行为有效数据。 -
遇到
data: [DONE]表示结束。 -
每个 chunk 中的增量内容通常位于
choices[0].delta.content。 -
工具调用流式返回时,函数名和参数可能分片到达,需要拼接。
9. 工具调用 Tool Calling
工具调用允许模型在需要时输出结构化的函数调用请求,由业务系统执行真实工具,再把工具结果返回给模型。
9.1 定义工具
{
"model": "gpt-4.1-mini",
"messages": [
{
"role": "user",
"content": "北京今天适合跑步吗?"
}
],
"tools": [
{
"type": "function",
"function": {
"name": "get_weather",
"description": "查询指定城市的天气",
"parameters": {
"type": "object",
"properties": {
"city": {
"type": "string",
"description": "城市名称"
}
},
"required": ["city"]
}
}
}
],
"tool_choice": "auto"
}
9.2 模型返回工具调用
{
"role": "assistant",
"content": null,
"tool_calls": [
{
"id": "call_123",
"type": "function",
"function": {
"name": "get_weather",
"arguments": "{\"city\":\"北京\"}"
}
}
]
}
9.3 回传工具结果
执行工具后,将结果以 tool 消息追加进 messages:
{
"role": "tool",
"tool_call_id": "call_123",
"content": "{\"city\":\"北京\",\"temperature\":28,\"air_quality\":\"良\",\"suggestion\":\"适合傍晚慢跑\"}"
}
然后再次请求模型,让模型基于工具结果生成自然语言回答。
模型只负责“提出调用请求”,不能直接访问真实系统。是否执行工具、如何鉴权、如何校验参数,必须由业务服务端控制。
10. 结构化输出 JSON
很多业务希望模型稳定返回 JSON。常见做法是使用 response_format。
10.1 JSON Object 模式
{
"model": "gpt-4.1-mini",
"messages": [
{
"role": "user",
"content": "从句子中抽取姓名和城市:张三住在杭州。"
}
],
"response_format": {
"type": "json_object"
}
}
返回内容可能是:
{
"name": "张三",
"city": "杭州"
}
10.2 JSON Schema 模式
部分模型支持更严格的 JSON Schema:
{
"response_format": {
"type": "json_schema",
"json_schema": {
"name": "person_info",
"schema": {
"type": "object",
"properties": {
"name": {"type": "string"},
"city": {"type": "string"}
},
"required": ["name", "city"],
"additionalProperties": false
}
}
}
}
10.3 实践建议
-
对强结构化任务,设置
temperature: 0。 -
在 prompt 中明确“只输出 JSON,不要解释”。
-
服务端仍需做 JSON parse 和 Schema 校验。
-
不要假设模型永远返回合法 JSON,异常分支必须处理。
11. Responses 接口简介
Responses 是 OpenAI 新一代统一生成接口,目标是把文本生成、多模态输入、工具调用等能力统一到一个更灵活的格式中。
11.1 请求路径
POST /v1/responses
11.2 简单请求示例
{
"model": "gpt-4.1-mini",
"input": "用三点解释什么是 RAG。"
}
11.3 多模态输入示例
{
"model": "gpt-4.1-mini",
"input": [
{
"role": "user",
"content": [
{
"type": "input_text",
"text": "请分析这张图中的主要信息"
},
{
"type": "input_image",
"image_url": "https://example.com/chart.png"
}
]
}
]
}
11.4 Responses 与 Chat Completions 对比
| 对比项 | Chat Completions | Responses |
|---|---|---|
| 成熟度 | 生态最广,兼容服务多 | 新一代接口,能力更统一 |
| 输入字段 | messages |
input |
| 输出结构 | choices[].message.content |
通常从 output 或便捷字段提取 |
| 多模态 | 支持但格式较分散 | 设计上更统一 |
| 工具调用 | tools / tool_calls |
工具能力更统一 |
| 兼容性 | 第三方最常支持 | 第三方支持不一定完整 |
如果你要兼容更多第三方模型服务,优先使用 Chat Completions;如果主要使用 OpenAI 官方新模型和复杂多模态能力,可以评估 Responses。
12. Embeddings 接口
Embedding 用于把文本转换为向量,常用于:
-
语义搜索
-
RAG 检索增强生成
-
文本聚类
-
推荐系统
-
相似度计算
12.1 请求路径
POST /v1/embeddings
12.2 请求示例
{
"model": "text-embedding-3-small",
"input": [
"OpenAI 接口格式详解",
"如何调用 Chat Completions API"
]
}
12.3 响应示例
{
"object": "list",
"data": [
{
"object": "embedding",
"index": 0,
"embedding": [0.0123, -0.0456, 0.0789]
}
],
"model": "text-embedding-3-small",
"usage": {
"prompt_tokens": 12,
"total_tokens": 12
}
}
12.4 字段说明
| 字段 | 说明 |
|---|---|
input |
待向量化文本,支持字符串或字符串数组 |
data[].embedding |
向量数组 |
data[].index |
对应输入数组下标 |
usage |
token 用量 |
13. 错误响应格式
13.1 常见错误响应
{
"error": {
"message": "Incorrect API key provided",
"type": "invalid_request_error",
"param": null,
"code": "invalid_api_key"
}
}
13.2 常见 HTTP 状态码
| 状态码 | 含义 | 常见原因 | 处理建议 |
|---|---|---|---|
| 400 | Bad Request | 参数错误、JSON 格式错误 | 校验请求体 |
| 401 | Unauthorized | API Key 错误或缺失 | 检查密钥和 Header |
| 403 | Forbidden | 没有权限访问模型或资源 | 检查权限、账户状态 |
| 404 | Not Found | 路径或模型不存在 | 检查 Base URL、模型 ID |
| 409 | Conflict | 资源状态冲突 | 稍后重试或检查任务状态 |
| 422 | Unprocessable Entity | 字段语义不合法 | 检查参数类型和范围 |
| 429 | Too Many Requests | 频率或额度限制 | 指数退避重试、限流 |
| 500 | Internal Server Error | 服务端异常 | 重试并记录 request id |
| 503 | Service Unavailable | 服务暂不可用 | 稍后重试、切换模型 |
13.3 重试策略
建议只对以下情况自动重试:
-
429:限流
-
500/502/503/504:服务端或网关异常
-
网络超时、连接中断
不建议对以下情况盲目重试:
-
400:请求参数错误
-
401:鉴权失败
-
403:权限不足
-
404:资源不存在
14. Token 与上下文窗口
14.1 Token 是什么
Token 是模型处理文本的基本单位,可以近似理解为“词片段”。中文、英文、标点、空格都会被切分为 token。
14.2 usage 字段
{
"usage": {
"prompt_tokens": 1200,
"completion_tokens": 300,
"total_tokens": 1500
}
}
| 字段 | 说明 |
|---|---|
prompt_tokens |
输入消耗 token |
completion_tokens |
输出消耗 token |
total_tokens |
总 token |
14.3 上下文窗口
每个模型都有上下文窗口限制。请求中的历史 messages、系统提示词、工具定义、图片描述和预期输出都会占用上下文。
优化建议:
-
长对话定期摘要历史。
-
RAG 只放入最相关片段,不要整篇塞入。
-
工具定义保持简洁。
-
明确最大输出长度。
-
对日志、网页、代码等长文本先做切分和筛选。
15. SDK 调用示例
15.1 Python 示例
from openai import OpenAI
client = OpenAI(api_key="YOUR_API_KEY")
resp = client.chat.completions.create(
model="gpt-4.1-mini",
messages=[
{"role": "system", "content": "你是一个严谨的技术助手。"},
{"role": "user", "content": "解释 OpenAI Chat Completions 的 messages 字段。"},
],
temperature=0.2,
)
print(resp.choices[0].message.content)
15.2 Node.js 示例
import OpenAI from "openai";
const client = new OpenAI({
apiKey: process.env.OPENAI_API_KEY,
});
const resp = await client.chat.completions.create({
model: "gpt-4.1-mini",
messages: [
{ role: "system", content: "你是一个严谨的技术助手。" },
{ role: "user", content: "给我一个 OpenAI API 请求示例。" },
],
temperature: 0.2,
});
console.log(resp.choices[0].message.content);
15.3 OpenAI-Compatible Base URL
很多第三方服务可以通过 SDK 的 baseURL 参数接入:
import OpenAI from "openai";
const client = new OpenAI({
apiKey: process.env.PROVIDER_API_KEY,
baseURL: "https://api.example.com/v1",
});
const resp = await client.chat.completions.create({
model: "provider-model-name",
messages: [
{ role: "user", content: "你好" },
],
});
16. 兼容不同服务商时的注意事项
虽然很多服务号称 OpenAI-Compatible,但兼容程度并不完全一致。
| 差异点 | 可能表现 | 处理建议 |
|---|---|---|
| 模型名 | 不支持 OpenAI 官方模型名 | 通过 /models 或服务商文档获取 |
| 参数支持 | 不支持 seed、response_format、tools 等 |
做能力探测和降级 |
| 流式格式 | SSE 字段略有差异 | 封装统一解析层 |
| 错误码 | HTTP 状态码或 error 字段不一致 | 做兼容映射 |
| 多模态 | 图片字段格式不同 | 按服务商文档适配 |
| Token 统计 | usage 字段缺失或延迟返回 | 不强依赖实时 usage |
| 工具调用 | tool_calls 格式不完全一致 | 参数校验、容错解析 |
建议在业务代码里抽象一层 LLM Provider Adapter,把模型名映射、参数裁剪、错误处理、流式解析统一封装,避免业务层到处写兼容逻辑。
17. 生产环境最佳实践
17.1 安全
-
API Key 只保存在服务端。
-
使用环境变量或密钥管理服务。
-
不把完整请求和响应直接打进日志,尤其是用户隐私和密钥。
-
对用户输入做内容隔离,避免把外部文本当成系统指令。
-
工具调用必须有白名单、参数校验和权限控制。
17.2 稳定性
-
设置请求超时。
-
对 429 和 5xx 做指数退避重试。
-
对长任务使用流式输出或异步任务。
-
提供备用模型或备用服务商。
-
记录 request id、模型名、耗时、token 用量。
17.3 成本控制
-
限制最大输出 token。
-
对长上下文做摘要和裁剪。
-
缓存稳定问题的结果。
-
Embedding 批量处理,避免逐条请求。
-
为不同任务选择合适尺寸的模型,不要所有任务都用最大模型。
17.4 输出质量
-
system prompt 写清角色、目标、边界。
-
对结构化任务使用 JSON Schema。
-
对复杂任务拆步骤,必要时工具化。
-
对关键业务输出做人审或规则校验。
-
保存失败样本,用于持续优化 prompt 和参数。
18. 一份标准请求模板
下面是一份比较通用的 Chat Completions 请求模板:
{
"model": "gpt-4.1-mini",
"messages": [
{
"role": "system",
"content": "你是一个严谨、简洁、可靠的技术助手。回答必须基于用户提供的信息,不确定时说明不确定。"
},
{
"role": "user",
"content": "请总结下面的接口文档,并列出调用注意事项:..."
}
],
"temperature": 0.2,
"top_p": 1,
"max_tokens": 1200,
"stream": false
}
如果需要 JSON 输出:
{
"model": "gpt-4.1-mini",
"messages": [
{
"role": "system",
"content": "你只输出合法 JSON,不要输出 Markdown。"
},
{
"role": "user",
"content": "从文本中抽取字段:姓名、公司、职位。文本:李雷在星辰科技担任产品经理。"
}
],
"temperature": 0,
"response_format": {
"type": "json_object"
}
}
19. 快速排查清单
-
Base URL 是否正确,是否包含
/v1。 -
API Key 是否有效,Header 是否是
Authorization: Bearer xxx。 -
model是否是当前服务商支持的模型名。 -
请求体是否是合法 JSON。
-
messages中 role 是否正确。 -
多模态字段是否被当前模型支持。
-
是否超过上下文窗口或输出 token 限制。
-
429 是否需要限流和退避。
-
流式输出是否正确处理
\[DONE\]。 -
工具调用参数是否经过服务端校验。
20. 总结
OpenAI 接口格式的核心是:
-
统一鉴权:
Authorization: Bearer API_KEY。 -
统一模型选择:通过
model指定能力。 -
统一上下文表达:Chat 使用
messages,Responses 使用input。 -
统一输出解析:非流式解析 JSON,流式解析 SSE chunk。
-
统一工程治理:错误重试、限流、日志、成本、安全都需要在服务端做好。
如果只是做通用文本生成和兼容多家模型服务,优先掌握 Chat Completions;如果要使用 OpenAI 新一代多模态与复杂工具能力,再进一步评估 Responses 接口。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 129
129 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)