RAG 本地知识库问答实战:LangChain 接入文档检索,用 cpolar 远程演示带引用答案
RAG 本地知识库问答实战:LangChain 接入文档检索,用 cpolar 远程演示带引用答案

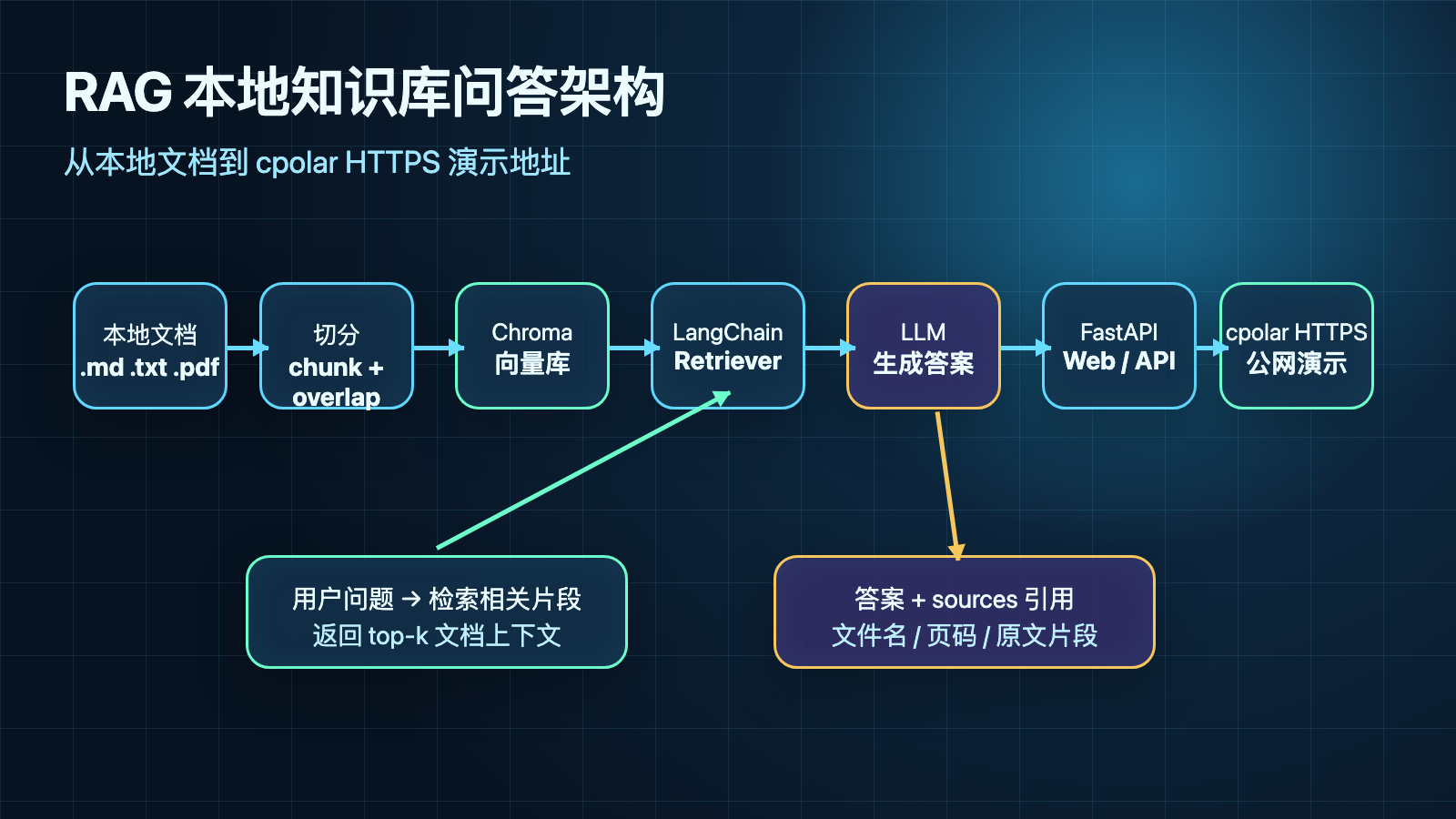
本地知识库问答最容易卡在两个地方:一是模型答得像“凭感觉总结”,看不到依据;二是服务只能在 localhost 打开,想让同事或手机试一下,还要截图、录屏来回解释。
这篇文章不讲模型部署入门,也不讲 AI 助手权限安全边界。我们只做一件可落地的事:把一批本地文档切分、向量化,做成一个带引用来源的 RAG 问答服务,然后用 cpolar 暴露一个临时演示地址,让异地同事直接打开页面测试。
本文主线如下:
- 准备本地文档
- 文档切分
- 向量化并写入 Chroma
- 启动本地 FastAPI 问答页面和 API
- 验证答案引用依据
- 用 cpolar 分享
7860端口的演示地址
安全边界先说清楚:本文只暴露演示问答服务,不暴露向量库管理端,不提供上传、删除、重建索引等无鉴权写接口。演示结束后关闭 cpolar 隧道。
一、最终效果
完成后,本机启动一个服务:
- Web 页面:
http://127.0.0.1:7860 - API 接口:
POST http://127.0.0.1:7860/ask - 公网演示:通过
cpolar http 7860生成临时访问地址
页面输入问题后,返回内容包含两部分:
answer:模型基于检索片段生成的回答sources:回答引用的文档名、页码或段落位置、原文片段
二、环境准备
本文用 Python + LangChain + Chroma + Ollama 跑通最小可用版本。Ollama 只作为本地模型服务使用,重点不在模型安装,而在 RAG 检索、引用和演示分享。
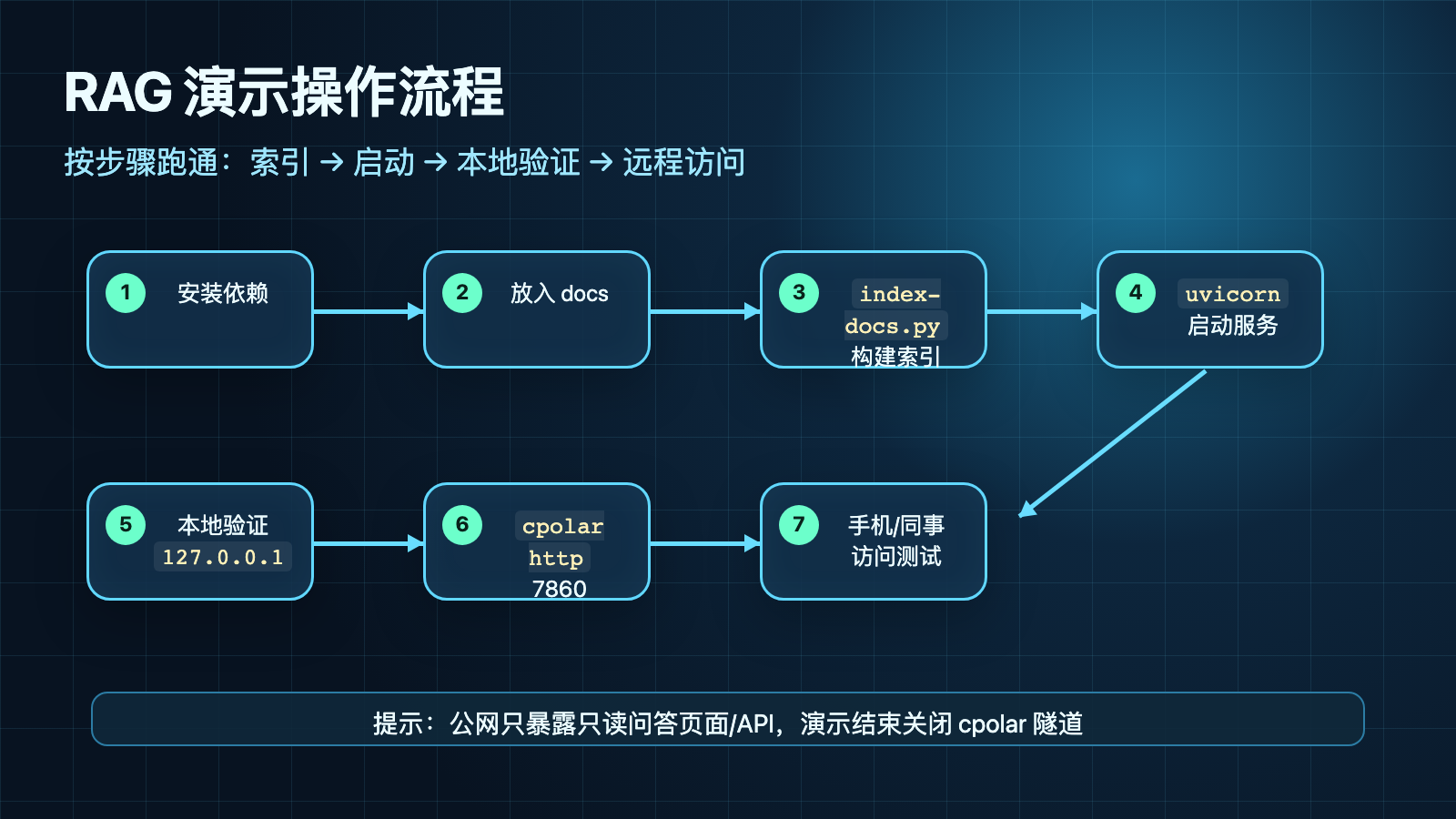
1. 创建项目目录
mkdir rag-local-demo
cd rag-local-demo
mkdir docs storage
2. 创建虚拟环境
macOS / Linux:
python3 -m venv .venv
source .venv/bin/activate
python -m pip install --upgrade pip
Windows PowerShell:
python -m venv .venv
.\.venv\Scripts\Activate.ps1
python -m pip install --upgrade pip
3. 安装依赖
pip install fastapi uvicorn chromadb pypdf langchain langchain-community langchain-chroma langchain-ollama python-dotenv
4. 准备本地模型
本文示例使用 Ollama 的本地对话模型和向量模型:
ollama pull qwen2.5:7b
ollama pull nomic-embed-text
确认 Ollama 服务可用:
ollama list
能看到 qwen2.5:7b 和 nomic-embed-text,就可以进入 RAG 部分。
三、准备文档
把要问答的资料放进 docs/ 目录。为了方便验证,先放一个 Markdown 示例。创建 docs/company_faq.md,内容如下:
# 内部知识库示例
## 报销规则
差旅报销需要在返程后 7 个自然日内提交。发票抬头必须与公司主体一致。单笔超过 500 元的交通费用需要附行程单。
## 远程演示规则
内部演示服务只能暴露只读页面或只读 API。禁止将管理后台、数据库控制台、向量库写入接口直接暴露到公网。
## 客户交付材料
客户交付前需要完成自测记录、版本号确认和回滚方案确认。交付文档必须包含部署步骤、验证步骤和联系人。
也可以把 PDF 放进 docs/,后面的脚本会读取 .md、.txt 和 .pdf。
四、写入配置文件
创建 .env:
cat > .env <<'EOF'
OLLAMA_BASE_URL=http://127.0.0.1:11434
CHAT_MODEL=qwen2.5:7b
EMBED_MODEL=nomic-embed-text
CHROMA_DIR=storage/chroma
DEMO_TOKEN=change-this-demo-token
EOF
DEMO_TOKEN 用于保护演示接口。公开演示时,把这个 token 单独发给测试同事,不要写在页面标题、截图或文章评论区里。
五、构建向量索引
创建 index_docs.py:
from pathlib import Path
from pypdf import PdfReader
from dotenv import load_dotenv
import os
from langchain_core.documents import Document
from langchain_text_splitters import RecursiveCharacterTextSplitter
from langchain_chroma import Chroma
from langchain_ollama import OllamaEmbeddings
load_dotenv()
DOCS_DIR = Path("docs")
CHROMA_DIR = os.getenv("CHROMA_DIR", "storage/chroma")
EMBED_MODEL = os.getenv("EMBED_MODEL", "nomic-embed-text")
OLLAMA_BASE_URL = os.getenv("OLLAMA_BASE_URL", "http://127.0.0.1:11434")
def load_documents() -> list[Document]:
documents: list[Document] = []
for path in sorted(DOCS_DIR.glob("**/*")):
if path.is_dir():
continue
suffix = path.suffix.lower()
if suffix in {".md", ".txt"}:
text = path.read_text(encoding="utf-8")
documents.append(Document(page_content=text, metadata={"source": str(path), "page": 1}))
elif suffix == ".pdf":
reader = PdfReader(str(path))
for page_no, page in enumerate(reader.pages, start=1):
text = page.extract_text() or ""
if text.strip():
documents.append(Document(page_content=text, metadata={"source": str(path), "page": page_no}))
return documents
def main() -> None:
raw_docs = load_documents()
if not raw_docs:
raise SystemExit("docs/ 目录没有可索引的 .md、.txt 或 .pdf 文件")
splitter = RecursiveCharacterTextSplitter(chunk_size=600, chunk_overlap=120)
chunks = splitter.split_documents(raw_docs)
embeddings = OllamaEmbeddings(model=EMBED_MODEL, base_url=OLLAMA_BASE_URL)
Chroma.from_documents(
documents=chunks,
embedding=embeddings,
persist_directory=CHROMA_DIR,
collection_name="local_docs",
)
print(f"indexed raw_docs={len(raw_docs)} chunks={len(chunks)} dir={CHROMA_DIR}")
if __name__ == "__main__":
main()
执行索引:
python index_docs.py
看到类似输出即完成:
indexed raw_docs=1 chunks=3 dir=storage/chroma
这一步完成后,storage/chroma 里已经有本地向量库数据。
六、启动带引用的问答服务
创建 app.py:
import os
from typing import Any
from dotenv import load_dotenv
from fastapi import FastAPI, Header, HTTPException
from fastapi.responses import HTMLResponse
from pydantic import BaseModel
from langchain_chroma import Chroma
from langchain_ollama import OllamaEmbeddings, ChatOllama
from langchain_core.prompts import ChatPromptTemplate
load_dotenv()
OLLAMA_BASE_URL = os.getenv("OLLAMA_BASE_URL", "http://127.0.0.1:11434")
CHAT_MODEL = os.getenv("CHAT_MODEL", "qwen2.5:7b")
EMBED_MODEL = os.getenv("EMBED_MODEL", "nomic-embed-text")
CHROMA_DIR = os.getenv("CHROMA_DIR", "storage/chroma")
DEMO_TOKEN = os.getenv("DEMO_TOKEN", "change-this-demo-token")
app = FastAPI(title="Local RAG Demo")
embeddings = OllamaEmbeddings(model=EMBED_MODEL, base_url=OLLAMA_BASE_URL)
vectorstore = Chroma(
collection_name="local_docs",
embedding_function=embeddings,
persist_directory=CHROMA_DIR,
)
retriever = vectorstore.as_retriever(search_kwargs={"k": 4})
llm = ChatOllama(model=CHAT_MODEL, base_url=OLLAMA_BASE_URL, temperature=0)
prompt = ChatPromptTemplate.from_messages([
("system", "你是一个本地知识库问答助手。只根据给定资料回答;资料不足时直接说资料中没有找到。回答后列出引用依据。"),
("human", "问题:{question}\n\n资料:\n{context}")
])
class AskRequest(BaseModel):
question: str
def check_token(x_demo_token: str | None) -> None:
if x_demo_token != DEMO_TOKEN:
raise HTTPException(status_code=401, detail="invalid demo token")
def format_docs(docs: list[Any]) -> str:
parts = []
for i, doc in enumerate(docs, start=1):
source = doc.metadata.get("source", "unknown")
page = doc.metadata.get("page", "-")
parts.append(f"[{i}] source={source} page={page}\n{doc.page_content}")
return "\n\n".join(parts)
@app.get("/", response_class=HTMLResponse)
def home() -> str:
return """
<!doctype html><html><head><meta charset="utf-8"><title>Local RAG Demo</title></head>
<body style="max-width:880px;margin:40px auto;font-family:Arial, sans-serif;line-height:1.6">
<h2>Local RAG Demo</h2>
<p>输入 Demo Token 和问题,服务会返回答案与引用片段。</p>
<input id="token" placeholder="Demo Token" style="width:100%;padding:8px"><br><br>
<textarea id="q" rows="4" style="width:100%;padding:8px" placeholder="例如:远程演示服务能暴露哪些接口?"></textarea><br><br>
<button onclick="ask()">提问</button>
<pre id="out" style="white-space:pre-wrap;background:#f6f8fa;padding:16px"></pre>
<script>
async function ask(){
const res = await fetch('/ask', {
method:'POST', headers:{'Content-Type':'application/json','X-Demo-Token':document.getElementById('token').value},
body:JSON.stringify({question:document.getElementById('q').value})
});
document.getElementById('out').textContent = JSON.stringify(await res.json(), null, 2);
}
</script></body></html>
"""
@app.post("/ask")
def ask(req: AskRequest, x_demo_token: str | None = Header(default=None)) -> dict[str, Any]:
check_token(x_demo_token)
docs = retriever.invoke(req.question)
context = format_docs(docs)
answer = llm.invoke(prompt.format_messages(question=req.question, context=context)).content
sources = [
{
"source": doc.metadata.get("source", "unknown"),
"page": doc.metadata.get("page", "-"),
"snippet": doc.page_content[:220],
}
for doc in docs
]
return {"answer": answer, "sources": sources}
启动服务:
uvicorn app:app --host 127.0.0.1 --port 7860
这里故意绑定 127.0.0.1,表示服务只监听本机。后面需要远程演示时,再用 cpolar 暴露这个端口。
七、本地验证引用依据
打开浏览器访问:
http://127.0.0.1:7860
输入 .env 里的 DEMO_TOKEN,再输入问题:
远程演示服务能暴露哪些接口?
如果用 API 测试,可以执行:
curl -s http://127.0.0.1:7860/ask \
-H 'Content-Type: application/json' \
-H 'X-Demo-Token: change-this-demo-token' \
-d '{"question":"远程演示服务能暴露哪些接口?"}'
返回结果会包含 sources,其中能看到来自 docs/company_faq.md 的片段,例如:
{
"answer": "内部演示服务只能暴露只读页面或只读 API,不能暴露管理后台、数据库控制台或向量库写入接口。引用依据:[1]。",
"sources": [
{
"source": "docs/company_faq.md",
"page": 1,
"snippet": "内部演示服务只能暴露只读页面或只读 API。禁止将管理后台、数据库控制台、向量库写入接口直接暴露到公网。"
}
]
}
验证 RAG 是否真的生效,看三点就够:
sources里有文档来源,不是只有一段自然语言回答。- 回答内容能对应到
snippet,不是脱离资料自由发挥。 - 问一个资料里没有的问题,服务会回答“资料中没有找到”,而不是编一个结论。
例如继续问:
公司食堂几点开门?
示例文档里没有食堂信息,合格回答应明确说明资料中没有找到。
八、用 cpolar 分享远程演示地址
本地验证通过后,再开一个终端执行:
cpolar http 7860
命令启动后,终端会显示公网访问地址。把 https://... 这一条发给同事,对方就能访问本机的 RAG 演示页面。
如果你的 cpolar 客户端已经以后台服务方式运行,也可以打开本地 Web UI 查看在线隧道:
http://127.0.0.1:9200
这一步的定位很简单:RAG 服务仍然跑在本机 127.0.0.1:7860,cpolar 只负责把这个演示端口临时映射到公网。手机、异地同事、客户预览环境都可以用这个地址快速验证交互效果。
演示时建议只发送三样内容:
- cpolar 生成的 HTTPS 地址
- Demo Token
- 测试问题示例
不要发送服务器目录、向量库路径、后台管理地址和无关端口。
九、演示服务的安全收口
RAG 演示常见风险不是“别人能不能打开页面”,而是“打开之后能不能做不该做的事”。本文的示例按只读演示设计:
/ask需要X-Demo-Token- Web 页面只调用
/ask - 没有提供上传文档接口
- 没有提供重建索引接口
- 没有暴露 Chroma 管理端
- uvicorn 绑定
127.0.0.1,远程访问只经过指定的 cpolar 隧道
演示结束后,按 Ctrl + C 关闭 cpolar http 7860,公网地址随即失效。免费随机地址会变化,适合临时演示;需要固定地址时,再按团队要求配置固定域名或固定隧道。
如果要给更多人测试,建议增加两层控制:
- 把
DEMO_TOKEN改成更长的随机字符串。 - 在应用层记录提问日志,但不要记录用户输入的隐私信息和密钥。
可以用下面命令生成随机 token:
python - <<'PY'
import secrets
print(secrets.token_urlsafe(32))
PY
替换 .env 后重启服务即可。
十、常见问题排查
1. python index_docs.py 报 Ollama 连接失败
先确认 Ollama 服务在本机运行:
ollama list
如果命令无法返回模型列表,先启动 Ollama,再重新执行索引脚本。
2. 页面能打开,但回答很慢
本地模型推理速度取决于机器配置和模型大小。先保持 k=4、chunk_size=600,不要一次检索太多片段。需要更快响应时,换更小的对话模型,或把演示问题控制在知识库范围内。
3. 返回没有引用
检查三个位置:
ls docs
ls storage/chroma
python index_docs.py
确保 docs/ 里有文档,并且重新执行过索引。新增文档后必须重新运行 python index_docs.py。
4. cpolar 地址打开后提示 401
这是正常的鉴权结果。页面里需要填写 .env 中的 DEMO_TOKEN,API 调用需要带 X-Demo-Token 请求头。
5. cpolar 地址能打开页面,但提问失败
先在本机测试接口:
curl -s http://127.0.0.1:7860/ask \
-H 'Content-Type: application/json' \
-H 'X-Demo-Token: change-this-demo-token' \
-d '{"question":"报销规则是什么?"}'
本机接口正常,再检查 cpolar 终端里的公网地址是否复制完整,以及浏览器页面里 token 是否填写正确。
十一、扩展方向
这个最小版本已经具备 RAG 演示所需的核心能力:本地资料、向量检索、带来源回答、Web/API 访问和公网临时分享。后续可以按需求扩展:
- 把 Markdown、PDF 之外的 Word、HTML 接入解析流程
- 给每个团队或项目建立独立 collection
- 把引用片段做成可点击的文档定位
- 增加只读审计日志,方便复盘哪些问题没有命中资料
- 在正式环境前接入统一登录,而不是只用 demo token
不要一开始就把系统做成“大而全知识库平台”。先用这套流程把一个小目录跑通,确认回答质量、引用依据和远程演示链路都成立,再决定是否接入更多文档类型和权限体系。
总结
这篇文章完成了一条完整的本地 RAG 问答链路:
本地文档 -> 文档切分 -> Ollama Embedding -> Chroma 向量库 -> LangChain 检索 -> 本地模型生成 -> FastAPI Web/API -> cpolar 临时演示地址
关键点不在于堆模型参数,而在于让答案有依据、让别人能快速测试、让演示边界可控。只要坚持“只暴露演示服务,不暴露管理端和写接口”,本地知识库问答就可以既方便展示,也保留必要的安全边界。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 6
6 0
0- 0



 已为社区贡献8条内容
已为社区贡献8条内容

所有评论(0)