YOLOv8改进 - 注意力机制 | LS-YOLO MSFE:新颖的多尺度特征提取模块 | 小目标/遥感
前言
本文介绍了用于滑坡检测的 LS-YOLO 模型及其核心多尺度特征提取模块(MSFE)。该模块融合了高效通道注意力(ECA)、平均池化及空间可分离卷积,通过多分支并行结构充分提取滑坡的多尺度特征信息。我们将 MSFE 模块成功集成进 YOLOv8,增强了模型对复杂背景下滑坡特征的捕捉能力。
文章目录: YOLOv8改进大全:卷积层、轻量化、注意力机制、损失函数、Backbone、SPPF、Neck、检测头全方位优化汇总
专栏链接: YOLOv8改进专栏
介绍
摘要
摘要——滑坡是一种广泛且具有毁灭性的自然灾害,对人类生命、安全和自然资产构成严重威胁。研究利用遥感影像进行滑坡精准检测的高效方法具有重要的学术和实际意义。本文提出了一种新颖且有效的滑坡检测模型LS-YOLO,利用遥感影像进行滑坡检测。我们首先构建了一个多尺度滑坡数据集(MSLD),并在数据增强中引入随机种子以增加数据的鲁棒性。考虑到遥感影像中滑坡的多尺度特性,设计了基于高效通道注意力、平均池化和空间可分离卷积的多尺度特征提取模块。为了增加模型的感受野,在解耦头中采用了膨胀卷积。具体而言,将由膨胀卷积组成的上下文增强模块添加到解耦头回归任务分支中,然后用改进的解耦头替换YOLOv5s中的耦合头。大量实验表明,我们提出的模型在多尺度滑坡检测方面具有高性能,优于其他目标检测模型(faster RCNN、SSD、EfficientDet-D0、YOLOv5s、YOLOv7和YOLOX)。与基准模型YOLOv5s相比,LS-YOLO在滑坡检测中的AP提升了2.18%,达到了97.06%。
文章链接
论文地址: 论文地址
代码地址: 代码地址
基本原理
LS-YOLO
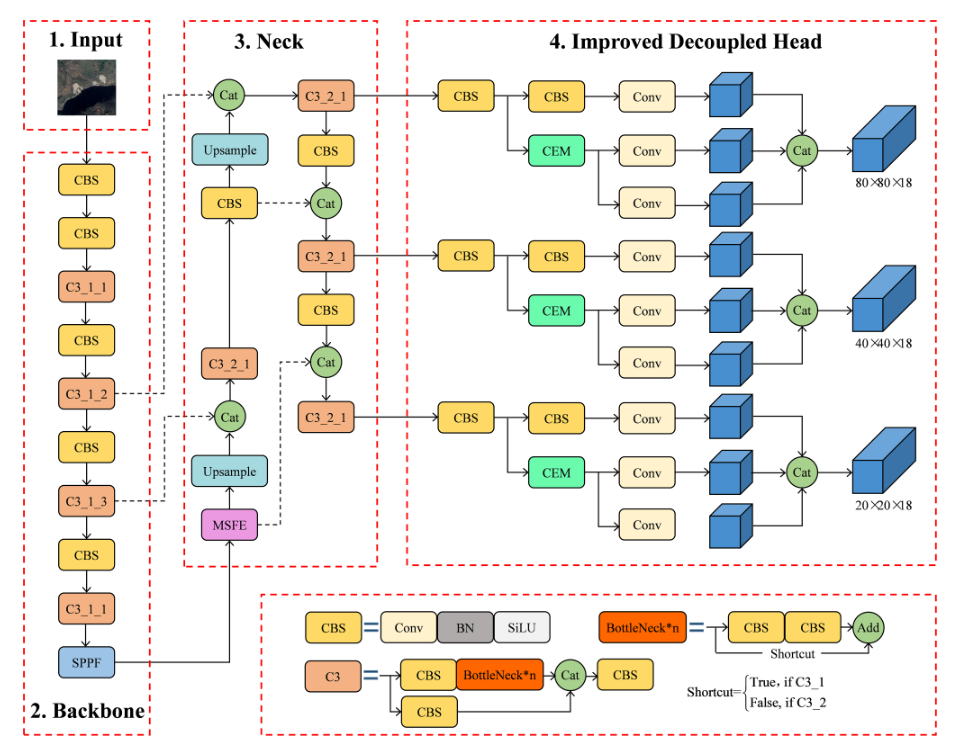
-
多尺度滑坡数据集(MSLD) :
- 构建了一个包含大量滑坡样本的MSLD,具有高度的类内变化、广泛的滑坡尺寸范围和复杂的背景,为模型训练提供了丰富的数据资源。
-
多尺度特征提取(MSFE)模块 :
-
MSFE模块包括Efficient Channel Attention(ECA)、平均池化和空间可分离卷积,用于充分提取滑坡特征信息。
-
ECA部分引入了注意力机制,通过全局平均池化聚合特征并自适应地确定核大小,以增强模型对重要特征的关注。
-
-
改进的解耦头 :
-
LS-YOLO通过引入扩张卷积来改进解耦头,增加模型的感受野,提高滑坡定位的准确性。
-
扩张卷积有助于捕获多尺度上下文信息,提升模型在滑坡位置定位方面的精度。
-
-
整体框架 :
-
LS-YOLO的整体框架结合了YOLOv5s的通用目标检测能力,并针对滑坡检测任务进行了优化和改进。
-
模型在滑坡检测中利用MSFE模块提取多尺度特征,同时通过改进的解耦头提高了滑坡位置的准确性。
-
MSFE
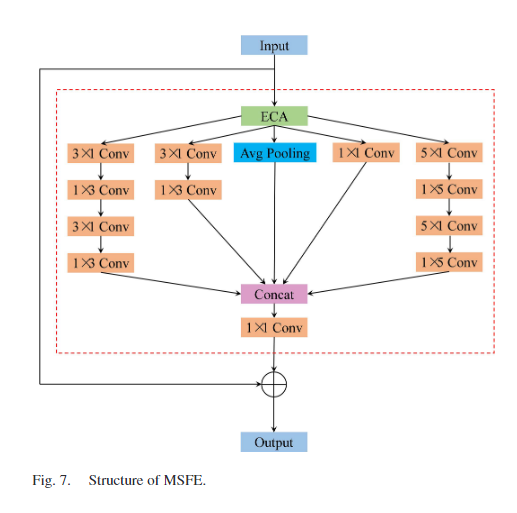
MSFE(Multiscale Feature Extraction)模块是论文中提出的一个关键技术,通过五个并行分支从多个感受野充分提取滑坡特征。
-
模块结构 :
-
MSFE模块包含两个分支:
-
第一个分支是残差连接,有助于减轻梯度消失并加快模型训练速度。
-
第二个分支包括Efficient Channel Attention(ECA)、平均池化和空间可分离卷积,用于充分提取滑坡特征信息。
-
-
-
Efficient Channel Attention(ECA) :
-
ECA是一种通用的插入式块,用于增强CNN的性能。
-
ECA包含一个挤压模块,用于压缩全局空间信息,以及一个激励模块,用于实现通道间的交互。
-
ECA通过全局平均池化聚合特征,自适应确定核大小k。
-
核心代码
import torch
import torch.nn as nn
# MSFE模块定义
class MSFE(nn.Module):
def __init__(self, c_in, c_out):
super(MSFE, self).__init__()
c_ = int(c_in // 4) # 计算每个分支的输出通道数
self.ECA = ECA(c_in, k_size=5) # ECA模块
self.branch1 = Conv(c_in, c_, 1, 1) # 分支1,1x1卷积
# 分支2,3x3平均池化
self.branch2 = nn.AvgPool2d(kernel_size=3, stride=1, padding=1)
# 分支3,串联两个卷积层
self.branch3 = nn.Sequential(
Conv(c_in, c_, (3, 1), s=1, p=(1, 0)), # 3x1卷积
Conv(c_, c_, (1, 3), s=1, p=(0, 1)) # 1x3卷积
)
# 分支4,串联四个卷积层
self.branch4 = nn.Sequential(
Conv(c_in, c_, (3, 1), s=1, p=(1, 0)), # 3x1卷积
Conv(c_, c_, (1, 3), s=1, p=(0, 1)), # 1x3卷积
Conv(c_, c_, (3, 1), s=1, p=(1, 0)), # 3x1卷积
Conv(c_, c_, (1, 3), s=1, p=(0, 1)) # 1x3卷积
)
# 分支5,串联四个卷积层
self.branch5 = nn.Sequential(
Conv(c_in, c_, (5, 1), s=1, p=(2, 0)), # 5x1卷积
Conv(c_, c_, (1, 5), s=1, p=(0, 2)), # 1x5卷积
Conv(c_, c_, (5, 1), s=1, p=(2, 0)), # 5x1卷积
Conv(c_, c_, (1, 5), s=1, p=(0, 2)) # 1x5卷积
)
self.conv = Conv(c_in * 2, c_out, k=1) # 1x1卷积,用于整合所有分支的输出
def forward(self, x):
x1 = self.ECA(x) # 通过ECA模块
y1 = self.branch1(x1) # 分支1的输出
y2 = self.branch2(x1) # 分支2的输出
y3 = self.branch3(x1) # 分支3的输出
y4 = self.branch4(x1) # 分支4的输出
y5 = self.branch5(x1) # 分支5的输出
# 将所有分支的输出在通道维度上拼接,并通过1x1卷积层,然后与输入x相加
out = x + self.conv(torch.cat([y1, y2, y3, y4, y5], 1))
return out
引入代码
在根目录下的 ultralytics/nn/ 目录,新建一个 attention 目录,然后新建一个以 MSFE 为文件名的py文件, 把代码拷贝进去。
import torch
import torch.nn as nn
def autopad(k, p=None, d=1): # kernel, padding, dilation
# Pad to 'same' shape outputs
if d > 1:
k = d * (k - 1) + 1 if isinstance(k, int) else [d * (x - 1) + 1 for x in k] # actual kernel-size
if p is None:
p = k // 2 if isinstance(k, int) else [x // 2 for x in k] # auto-pad
return p
class Conv(nn.Module):
# Standard convolution with args(ch_in, ch_out, kernel, stride, padding, groups, dilation, activation)
default_act = nn.SiLU() # default activation
def __init__(self, c1, c2, k=1, s=1, p=None, g=1, d=1, act=True):
super().__init__()
self.conv = nn.Conv2d(c1, c2, k, s, autopad(k, p, d), groups=g, dilation=d, bias=False)
self.bn = nn.BatchNorm2d(c2)
self.act = self.default_act if act is True else act if isinstance(act, nn.Module) else nn.Identity()
def forward(self, x):
return self.act(self.bn(self.conv(x)))
def forward_fuse(self, x):
return self.act(self.conv(x))
class ECA(nn.Module):
def __init__(self, channel, k_size=5):
super(ECA, self).__init__()
self.avg_pool = nn.AdaptiveAvgPool2d(1)
self.conv = nn.Conv1d(1, 1, kernel_size=k_size, padding=(k_size - 1) // 2, bias=False)
self.sigmoid = nn.Sigmoid()
def forward(self, x):
# x: input features with shape [b, c, h, w]
b, c, h, w = x.size()
# feature descriptor on the global spatial information
y = self.avg_pool(x)
# Two different branches of ECA module
y = self.conv(y.squeeze(-1).transpose(-1, -2)).transpose(-1, -2).unsqueeze(-1)
# Multi-scale information fusion
y = self.sigmoid(y)
return x * y.expand_as(x)
class MSFE(nn.Module):
def __init__(self, c_in, c_out):
super(MSFE, self).__init__()
c_ = int(c_in//4)
self.ECA = ECA(c_in, k_size=5)
self.branch1 = Conv(c_in, c_, 1, 1)
self.branch2 = nn.AvgPool2d(kernel_size=3, stride=1, padding=1)
self.branch3 = nn.Sequential(
Conv(c_in, c_, (3, 1), s=1, p=(1, 0)),
Conv(c_, c_, (1, 3), s=1, p=(0, 1))
)
self.branch4 = nn.Sequential(
Conv(c_in, c_, (3, 1), s=1, p=(1, 0)),
Conv(c_, c_, (1, 3), s=1, p=(0, 1)),
Conv(c_, c_, (3, 1), s=1, p=(1, 0)),
Conv(c_, c_, (1, 3), s=1, p=(0, 1))
)
self.branch5 = nn.Sequential(
Conv(c_in, c_, (5, 1), s=1, p=(2, 0)),
Conv(c_, c_, (1, 5), s=1, p=(0, 2)),
Conv(c_, c_, (5, 1), s=1, p=(2, 0)),
Conv(c_, c_, (1, 5), s=1, p=(0, 2))
)
self.conv = Conv(c_in*2, c_out, k=1)
def forward(self, x):
x1 = self.ECA(x)
y1 = self.branch1(x1)
y2 = self.branch2(x1)
y3 = self.branch3(x1)
y4 = self.branch4(x1)
y5 = self.branch5(x1)
out = x + self.conv(torch.cat([y1, y2, y3, y4, y5], 1))
return out
注册卷积
在 ultralytics/nn/tasks.py 中进行如下操作:
步骤1:
from ultralytics.nn.attention.MSFE import MSFE
步骤2
修改 def parse_model(d, ch, verbose=True) :
MSFE
配置yolov8_MSFE.yaml
ultralytics/cfg/models/v8/yolov8_MSFE.yaml
# Ultralytics YOLO 🚀, GPL-3.0 license
# YOLOv8 object detection model with P3-P5 outputs. For Usage examples see https://docs.ultralytics.com/tasks/detect
# Parameters
nc: 1 # number of classes
scales: # model compound scaling constants, i.e. 'model=yolov8n.yaml' will call yolov8.yaml with scale 'n'
# [depth, width, max_channels]
n: [0.33, 0.25, 1024] # YOLOv8n summary: 225 layers, 3157200 parameters, 3157184 gradients, 8.9 GFLOPs
s: [0.33, 0.50, 1024] # YOLOv8s summary: 225 layers, 11166560 parameters, 11166544 gradients, 28.8 GFLOPs
m: [0.67, 0.75, 768] # YOLOv8m summary: 295 layers, 25902640 parameters, 25902624 gradients, 79.3 GFLOPs
l: [1.00, 1.00, 512] # YOLOv8l summary: 365 layers, 43691520 parameters, 43691504 gradients, 165.7 GFLOPs
x: [1.00, 1.25, 512] # YOLOv8x summary: 365 layers, 68229648 parameters, 68229632 gradients, 258.5 GFLOPs
# YOLOv8.0n backbone
backbone:
# [from, repeats, module, args]
- [-1, 1, Conv, [64, 3, 2]] # 0-P1/2
- [-1, 1, Conv, [128, 3, 2]] # 1-P2/4
- [-1, 3, C2f, [128, True]]
- [-1, 1, Conv, [256, 3, 2]] # 3-P3/8
- [-1, 6, C2f, [256, True]]
- [-1, 1, Conv, [512, 3, 2]] # 5-P4/16
- [-1, 6, C2f, [512, True]]
- [-1, 1, Conv, [1024, 3, 2]] # 7-P5/32
- [-1, 3, C2f, [1024, True]]
- [-1, 1, SPPF, [1024, 5]] # 9
- [-1, 1, MSFE, [1024]]
# YOLOv8.0n head
head:
- [-1, 1, nn.Upsample, [None, 2, 'nearest']]
- [[-1, 6], 1, Concat, [1]] # cat backbone P4
- [-1, 3, C2f, [512]] # 13
- [-1, 1, nn.Upsample, [None, 2, 'nearest']]
- [[-1, 4], 1, Concat, [1]] # cat backbone P3
- [-1, 3, C2f, [256]] # 16 (P3/8-small)
- [-1, 1, Conv, [256, 3, 2]]
- [[-1, 13], 1, Concat, [1]] # cat head P4
- [-1, 3, C2f, [512]] # 19 (P4/16-medium)
- [-1, 1, Conv, [512, 3, 2]]
- [[-1, 10], 1, Concat, [1]] # cat head P5
- [-1, 3, C2f, [1024]] # 22 (P5/32-large)
- [[16, 19, 22], 1, Detect, [nc]] # Detect(P3, P4, P5)
实验
脚本
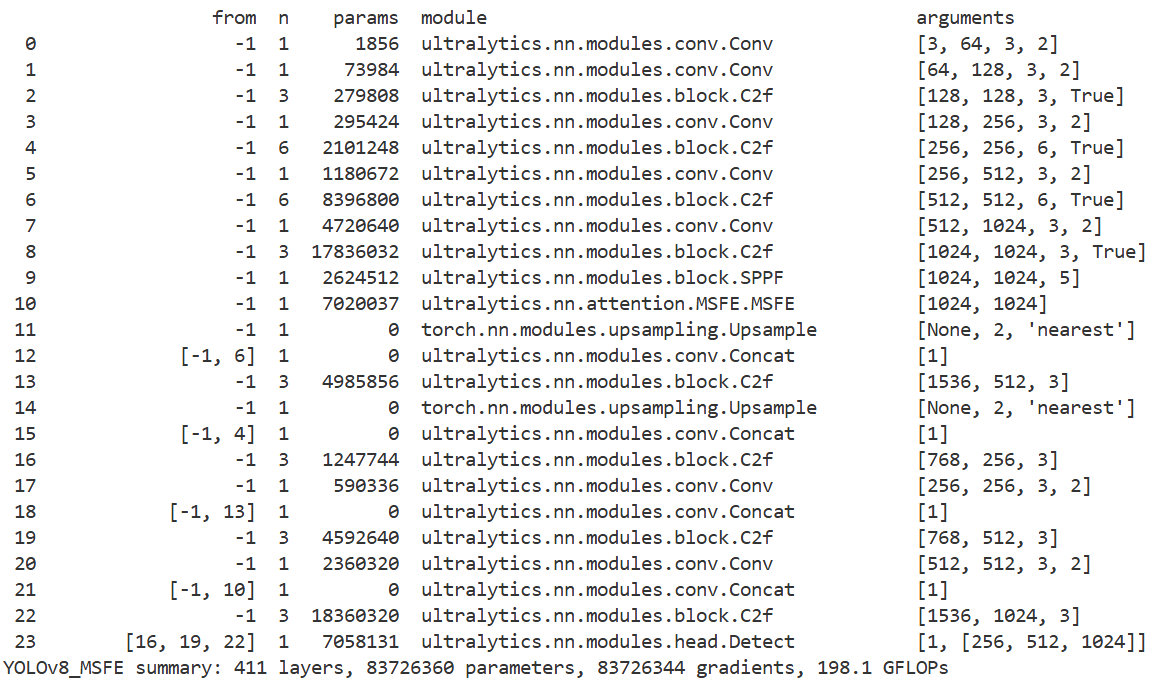
import os
from ultralytics import YOLO
yaml = 'ultralytics/cfg/models/v8/yolov8_MSFE.yaml'
model = YOLO(yaml)
model.info()
if __name__ == "__main__":
results = model.train(data='coco128.yaml',
name='yolov8',
epochs=10,
amp=False,
workers=8,
batch=1)
结果

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 0
0 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)