从零手搓一个 AI 编程助手:Mini Claude Code 完全指南
用 Python 从零搭建一个属于自己的 AI 编程助手,理解 Agent 背后的核心原理。
📖 前言
什么是 Claude Code?
Claude Code 是 Anthropic 推出的终端 AI 编程助手,它能理解你的自然语言指令,并自主调用工具来读文件、写代码、执行命令——像一个会使用工具的智能体。
为什么要自己搓一个?
| 理由 | 说明 |
|---|---|
| 理解原理 | 搞懂 Agent 内部的「思考→行动→观察」循环到底怎么运转 |
| 完全可控 | 想加什么功能自己加,不受官方限制 |
| 任意模型 | 可以用 DeepSeek、本地模型、甚至切换多个 Provider |
| 成就感 | 用自己的工具写代码,感觉完全不同 |
你需要的基础
- Python 基础语法(变量、函数、
if/for) - 能在终端执行命令
- 一个 LLM API 密钥(DeepSeek / OpenAI / 任何兼容 API)
我们要做什么
一共 8 个步骤,每步产出可运行的代码:
Step 1 ── Hello LLM:调通第一行 AI 回复
Step 2 ── 工具系统:让 AI 能读文件、写文件、执行命令
Step 3 ── Agent 循环:思考→行动→观察的自主迭代
Step 4 ── CLI 界面:彩色终端 + 命令系统
──────────── 到此可日常使用 ──————————————————
Step 5 ── 多 Provider:DeepSeek / OpenAI / Claude 随意切换
Step 6 ── 上下文管理:对话太长也不怕
Step 7 ── 持久化记忆:下次启动还记得你
Step 8 ── 安全沙箱:给工具调用加上权限控制
Step 1:Hello LLM — 调通第一行 AI 回复
🎯 本节目标
在终端里调用 LLM API,让 AI 回复一句话。感受一下「发请求 → 收回复」的基本流程。
📖 原理速览
所有 AI 助手的底层都是这样的:
你的输入 → POST 到 LLM API → 拿到回复 → 显示出来
OpenAI 官方 SDK(openai Python 包)帮我们封装了 HTTP 请求,我们只需要告诉它:
- API Key:你是谁(身份认证)
- Base URL:往哪发(不同的 API 厂商地址不同)
- Model:用哪个模型(比如 GPT-4o、deepseek-chat)
- Messages:说什么(消息列表,支持 system / user / assistant 三种角色)
💻 动手写代码
① 创建项目目录
cd /d F:\First-cc
mkdir mini-claude-code
cd mini-claude-code
② 安装依赖
只需要一个包:
pip install openai
③ 设置 API 密钥
创建 .env 文件(或者直接设环境变量):
# 文件: .env(不要提交到 git)
# 用你的密钥替换下面的内容
LLM_API_KEY=sk-your-key-here
LLM_BASE_URL=https://api.deepseek.com/v1
LLM_MODEL=deepseek-chat
💡 支持哪些 API? 只要兼容 OpenAI 格式的都可以。DeepSeek、OpenAI、Groq、Together AI、甚至本地的 Ollama 都行——只需要改
BASE_URL和MODEL。
④ 写第一个脚本
创建 hello_llm.py:
"""
Step 1:Hello LLM
调通第一行 AI 回复,理解 LLM API 的基本调用方式
"""
import os
from openai import OpenAI
# 读取环境变量
api_key = os.getenv("LLM_API_KEY", "")
base_url = os.getenv("LLM_BASE_URL", "https://api.deepseek.com/v1")
model = os.getenv("LLM_MODEL", "deepseek-chat")
# 创建客户端
client = OpenAI(api_key=api_key, base_url=base_url)
# 构造消息
messages = [
{"role": "system", "content": "你是一个友好的助手,请用中文回答。"},
{"role": "user", "content": "你好!请用一句话介绍你自己。"}
]
# 调用 API
response = client.chat.completions.create(
model=model,
messages=messages,
)
# 打印回复
print("AI 说:", response.choices[0].message.content)
⑤ 运行
python hello_llm.py
⑥ 升级:流式输出
上面的版本要等 AI 全部说完才打印,不够酷。我们来改成流式输出——一个字一个字地往外蹦,就像真实的 Claude Code 那样。
创建 hello_stream.py:
"""
Step 1 升级版:流式调用
AI 一边生成一边输出
"""
import os
from openai import OpenAI
api_key = os.getenv("LLM_API_KEY", "sk-911f6ba5040d47f1b2214dc352972d6e")
base_url = os.getenv("LLM_BASE_URL", "https://api.deepseek.com/v1")
model = os.getenv("LLM_MODEL", "deepseek-chat")
client = OpenAI(api_key=api_key, base_url=base_url)
messages = [
{"role": "system", "content": "请用中文回答,简洁有力。"},
{"role": "user", "content": "用 100 字以内解释什么是 Agent。"}
]
print("🤖 AI: ", end="", flush=True)
stream = client.chat.completions.create(
model=model,
messages=messages,
stream=True, # ← 关键区别
)
for chunk in stream:
if chunk.choices and chunk.choices[0].delta.content:
content = chunk.choices[0].delta.content
print(content, end="", flush=True)
print()
🧪 验证清单
-
hello_llm.py能正常输出 AI 回复 -
hello_stream.py能逐字流式输出 - 换成不同的
BASE_URL和MODEL也能工作
📝 本节小结
| 知识点 | 说明 |
|---|---|
OpenAI() |
创建客户端,传入 api_key 和 base_url |
stream=False |
等全部内容返回后再拿到结果 |
stream=True |
逐 chunk 返回,实时输出 |
delta.content |
每个 chunk 里携带的文本片段 |
Step 2:工具系统 — 让 AI 拥有双手
🎯 本节目标
定义 4 个工具(读文件、写文件、执行命令、抓取网页),让 AI 能通过工具调用来实际操作你的电脑。
📖 原理速览
大语言模型本质上是一个文本生成器——它只能吐文字,不能直接操作文件或执行命令。
工具(Tool) 就是给 LLM 装上的"双手":
LLM 生成文本回复
└─ 或者生成「工具调用请求」
└─ 我们收到后执行对应的函数
└─ 把结果送回给 LLM
└─ LLM 根据结果决定下一步
要让 LLM 知道它能用什么工具,需要用 JSON Schema 来描述每个工具:
{
"name": "read_file",
"description": "读取文件内容",
"parameters": {
"type": "object",
"properties": {
"path": {"type": "string", "description": "文件路径"}
},
"required": ["path"]
}
}
这个描述告诉 LLM:有一个工具叫 read_file,它接受一个叫 path 的字符串参数。LLM 看到这个描述,就会在需要的时候生成一个工具调用指令,我们解析后执行对应的 Python 函数。
💻 动手写代码
创建 tools.py:
"""
Step 2:工具系统
定义 4 个工具 + 对应的执行函数。
每个工具包含两部分:
1. JSON Schema 描述(给 LLM 看,告诉它工具有什么用、怎么用)
2. Python 函数(真正干活的代码)
"""
import subprocess
import urllib.request
import os
# ============================================================
# 1. 工具定义(JSON Schema)
# 这些是给 LLM 看的工具说明书
# ============================================================
TOOLS = [
{
"type": "function",
"function": {
"name": "read",
"description": "读取指定文件的内容并返回",
"parameters": {
"type": "object",
"properties": {
"path": {
"type": "string",
"description": "文件路径,例如 ./test.txt"
}
},
"required": ["path"]
}
}
},
{
"type": "function",
"function": {
"name": "write",
"description": "将内容写入指定文件(会覆盖已有内容)",
"parameters": {
"type": "object",
"properties": {
"path": {"type": "string", "description": "文件路径"},
"content": {"type": "string", "description": "要写入的内容"}
},
"required": ["path", "content"]
}
}
},
{
"type": "function",
"function": {
"name": "run",
"description": "执行 shell 命令并返回标准输出和错误",
"parameters": {
"type": "object",
"properties": {
"command": {
"type": "string",
"description": "要执行的命令,如 ls -la"
}
},
"required": ["command"]
}
}
},
{
"type": "function",
"function": {
"name": "web_fetch",
"description": "抓取指定 URL 的网页文本内容",
"parameters": {
"type": "object",
"properties": {
"url": {
"type": "string",
"description": "网页的完整 URL"
}
},
"required": ["url"]
}
}
}
]
MAX_OUTPUT = 5000
def execute_tool(name: str, args: dict) -> str:
"""根据工具名和参数,执行对应的函数"""
try:
if name == "read":
return _read_file(args["path"])
elif name == "write":
return _write_file(args["path"], args["content"])
elif name == "run":
return _run_command(args["command"])
elif name == "web_fetch":
return _web_fetch(args["url"])
else:
return f"❌ 未知工具: {name}"
except Exception as e:
return f"❌ [{type(e).__name__}] {e}"
def _read_file(path: str) -> str:
path = os.path.expanduser(path)
with open(path, "r", encoding="utf-8") as f:
content = f.read()
if len(content) > MAX_OUTPUT:
return content[:MAX_OUTPUT] + f"\n...(共 {len(content)} 字符,已截断)"
return content
def _write_file(path: str, content: str) -> str:
path = os.path.expanduser(path)
os.makedirs(os.path.dirname(os.path.abspath(path)), exist_ok=True)
with open(path, "w", encoding="utf-8") as f:
f.write(content)
return f"✅ 已写入 {len(content)} 字符到 {path}"
def _run_command(command: str) -> str:
result = subprocess.run(
command,
shell=True,
capture_output=True,
text=True,
timeout=30,
)
output = ""
if result.stdout:
output += result.stdout
if result.stderr:
output += f"\n[stderr]\n{result.stderr}"
if result.returncode != 0:
output += f"\n[exit code: {result.returncode}]"
output = output or "(无输出)"
if len(output) > MAX_OUTPUT:
output = output[:MAX_OUTPUT] + f"\n...(共 {len(output)} 字符,已截断)"
return output
def _web_fetch(url: str) -> str:
req = urllib.request.Request(
url,
headers={"User-Agent": "MiniClaudeCode/1.0"},
)
with urllib.request.urlopen(req, timeout=15) as resp:
content = resp.read().decode("utf-8", errors="replace")
if len(content) > MAX_OUTPUT:
content = content[:MAX_OUTPUT] + f"\n...(共 {len(content)} 字符,已截断)"
return content
# 测试代码
if __name__ == "__main__":
print("测试 read:", execute_tool("read", {"path": __file__})[:100])
print("测试 write:", execute_tool("write", {"path": "test.txt", "content": "Hello Mini Claude Code"}))
print("测试 run:", execute_tool("run", {"command": "echo 工具调用成功!"}))
🧪 验证
直接运行测试模式:
python tools.py
你应该看到三个工具的测试输出都正常。
在这里插入图片描述: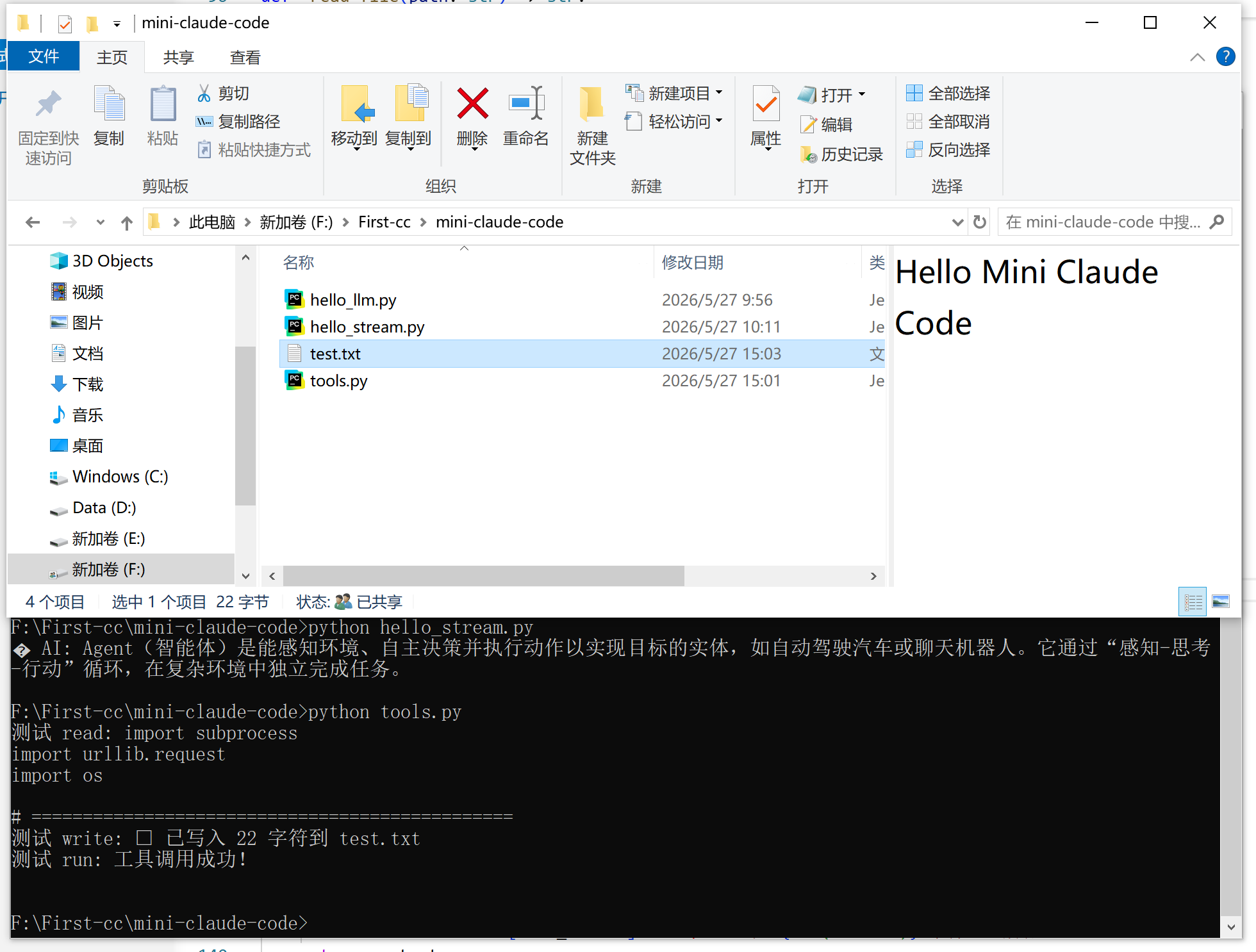
💡 关于 JSON Schema 的深入理解
JSON Schema 是 LLM 工具调用的核心,值得多花一分钟理解:
name → 工具名,LLM 通过这个名字来引用工具
description → 描述工具的作用,LLM 根据这个判断什么时候该用
parameters → 参数定义,告诉 LLM 需要传什么参数
properties → 每个参数的名称、类型、说明
required → 哪些参数是必填的
写 description 的技巧:描述越清晰,LLM 在复杂任务中越能准确选择正确的工具。比如不要说"执行命令",而要说"执行 shell 命令并返回标准输出和标准错误"。
📝 本节小结
| 知识点 | 说明 |
|---|---|
| Tool Calling | LLM 返回的不是文本,而是"我想调用这个工具"的请求 |
| JSON Schema | 用标准格式描述工具的接口,LLM 原生理解 |
| 工具执行引擎 | 收到请求后路由到对应的 Python 函数执行 |
| 异常隔离 | 工具执行失败不能崩掉整个程序,错误也作为文本返回给 LLM |
Step 3:Agent 核心循环
🎯 本节目标
实现 Agent 的灵魂——「思考→行动→观察」循环。让 AI 能自主决定:什么时候说话、什么时候调用工具、调用完工具后怎么继续。
📖 原理速览
这是整个项目最核心的部分。Agent 循环本质上是一个 while 循环:
┌─────────────────────────┐
│ 用户输入 │
└────────┬────────────────┘
▼
┌─────────────────────────┐
│ 发给 LLM │
│ (消息历史 + 工具定义) │
└────────┬────────────────┘
▼
┌─────────────────────────┐
│ 解析 LLM 回复 │
└────────┬────────────────┘
│
┌─────────────┴─────────────┐
▼ ▼
┌──────────────────┐ ┌──────────────────┐
│ 返回文本内容 │ │ 请求调用工具 │
│ → 输出给用户 │ │ → 执行工具 │
│ → 结束本轮对话 │ │ → 结果追加到消息 │
└──────────────────┘ │ → 继续循环 │
└──────────────────┘
关键点:
- LLM 可能返回文本,也可能返回工具调用请求,也可能两者都有
- 有工具调用就执行 → 结果加回对话 → 重新发给 LLM
- 没有工具调用就输出文本 → 结束
- 最多迭代 N 轮,防止死循环
💻 动手写代码
创建 agent.py:
"""
"""
Step 3:Agent 核心循环
实现「思考→行动→观察」的迭代循环
"""
import json
import os
from openai import OpenAI
import tools # 导入上一步写的工具系统
SYSTEM_PROMPT = """你是一个可以通过工具来帮助用户完成任务的智能助手。
可用工具:
- read:读取文件内容
- write:写入内容到文件(会覆盖)
- run:执行 shell 命令
- web_fetch:抓取网页内容
使用规则:
1. 根据用户需求选择合适的工具
2. 复杂任务可以分多步进行
3. 每次工具调用后你会看到执行结果,根据结果决定下一步
4. 全部完成后,用中文给用户一个清晰的总结"""
class Agent:
def __init__(self):
api_key = os.getenv("LLM_API_KEY", "")
base_url = os.getenv("LLM_BASE_URL", "https://api.deepseek.com/v1")
model = os.getenv("LLM_MODEL", "deepseek-chat")
if not api_key:
raise ValueError("请设置 LLM_API_KEY 环境变量!")
self.client = OpenAI(api_key=api_key, base_url=base_url)
self.model = model
self.messages = [{"role": "system", "content": SYSTEM_PROMPT}]
def stream_chat(self, user_input: str):
"""处理用户输入,返回事件流"""
self.messages.append({"role": "user", "content": user_input})
for step in range(10): # 最多 10 轮工具调用,防止死循环
# 1. 调用 LLM
reply_text, tool_calls = self._call_llm()
# 2. 有文本则输出
if reply_text:
yield {"type": "text", "content": reply_text}
# 3. 没有工具调用 → 结束
if not tool_calls:
self.messages.append({"role": "assistant", "content": reply_text or ""})
return
# 4. 有工具调用 → 记录到历史
assistant_msg = {"role": "assistant", "content": reply_text or None}
assistant_msg["tool_calls"] = [
{
"id": tc["id"],
"type": "function",
"function": {"name": tc["name"], "arguments": tc["args"]},
}
for tc in tool_calls
]
self.messages.append(assistant_msg)
# 5. 依次执行每个工具
for tc in tool_calls:
try:
parsed_args = json.loads(tc["args"]) if tc["args"] else {}
except json.JSONDecodeError:
parsed_args = {}
yield {"type": "tool_start", "name": tc["name"], "args": parsed_args}
result = tools.execute_tool(tc["name"], parsed_args)
yield {"type": "tool_end", "name": tc["name"], "result": result}
self.messages.append({
"role": "tool",
"tool_call_id": tc["id"],
"content": str(result)[:tools.MAX_OUTPUT],
})
yield {"type": "text", "content": "\n⚠️ 已达最大工具调用轮数(10轮)"}
def _call_llm(self):
"""调用 LLM API,返回 (文本内容, 工具调用列表)"""
collected_text = ""
collected_tools = {}
stream = self.client.chat.completions.create(
model=self.model,
messages=self.messages,
tools=tools.TOOLS,
stream=True,
)
for chunk in stream:
if not chunk.choices:
continue
delta = chunk.choices[0].delta
if not delta:
continue
if delta.content:
collected_text += delta.content
if delta.tool_calls:
for tc in delta.tool_calls:
idx = tc.index
if idx not in collected_tools:
collected_tools[idx] = {"id": "", "name": "", "args": ""}
if tc.id:
collected_tools[idx]["id"] += tc.id
if tc.function:
if tc.function.name:
collected_tools[idx]["name"] += tc.function.name
if tc.function.arguments:
collected_tools[idx]["args"] += tc.function.arguments
tool_calls = [
{"id": v["id"], "name": v["name"], "args": v["args"]}
for _, v in sorted(collected_tools.items())
]
return collected_text, tool_calls
🔄 Agent 循环可视化
假设你对 AI 说:“帮我创建一个 Python 脚本,打印 1 到 10”。
实际的循环过程:
轮次 1:
LLM 收到消息 → 决定调用 write 工具
我们执行 write → "test.py" → 内容写入成功
结果追加到对话 → 继续循环
轮次 2:
LLM 看到写入成功 → 决定调用 run 工具执行 python test.py
我们执行 run → 输出 1 2 3 ... 10
结果追加到对话 → 继续循环
轮次 3:
LLM 看到执行成功 → 生成总结文本
没有工具调用 → 输出总结 → 结束
这就是 Agent 的自主迭代能力——你只需要说"做什么",它自己决定"怎么做"。
🧪 验证
写一个简单的测试脚本来验证 Agent 能正确调用工具:
# test_agent.py
import os
from agent import Agent
# 创建 AI 智能体
agent = Agent()
# 让 AI 自动执行任务
for event in agent.stream_chat("帮我写一个 hello.txt,内容是 'Hello Agent!'"):
if event["type"] == "text":
print(event["content"], end="")
elif event["type"] == "tool_start":
print(f"\n⚡ 调用工具: {event['name']}")
elif event["type"] == "tool_end":
print(f" 结果: {event['result'][:100]}")
直接运行测试模式:
python test_agent.py
在这里插入图片描述: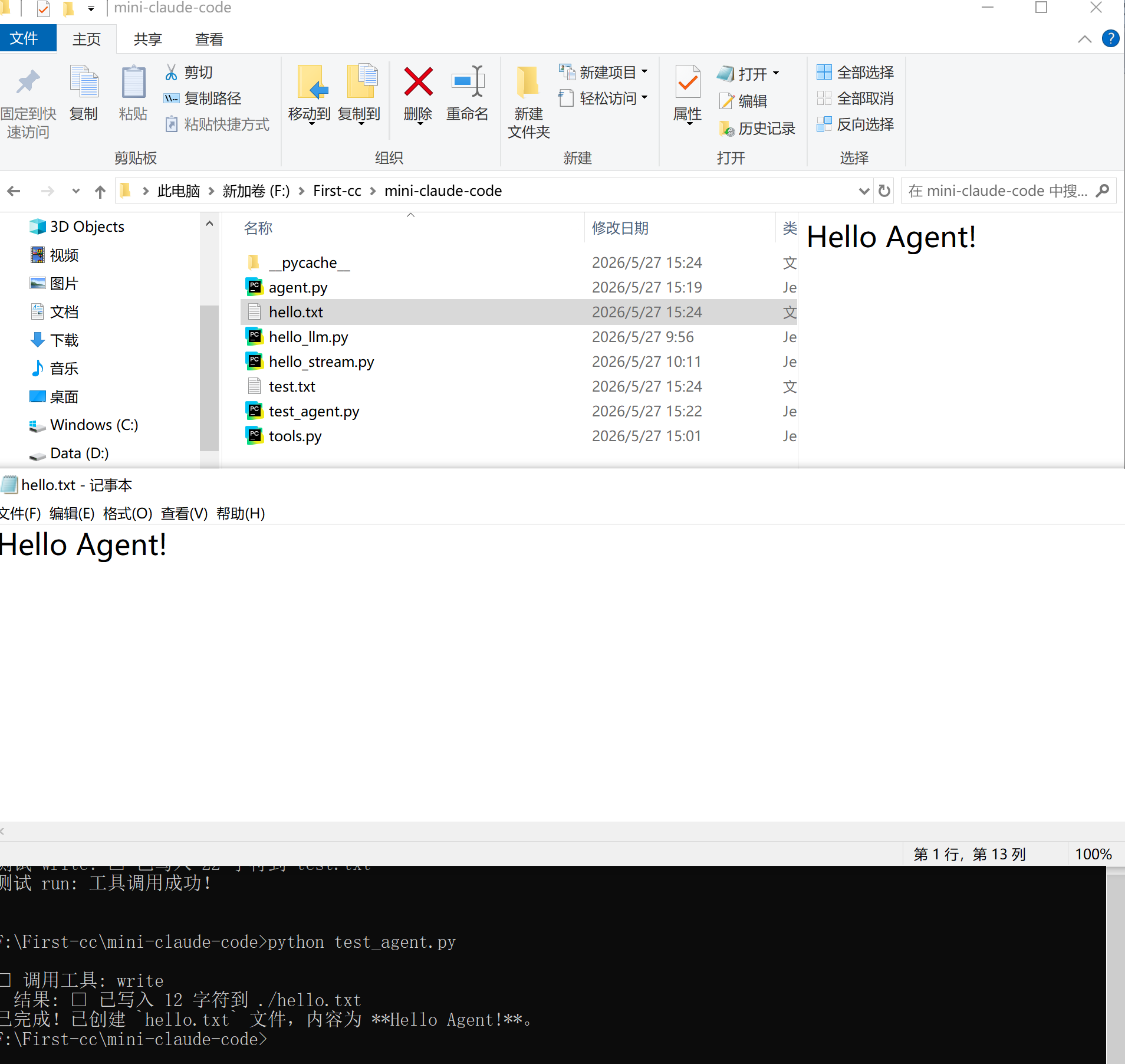
📝 本节小结
| 知识点 | 说明 |
|---|---|
| Agent 循环 | while 循环 + LLM 调用 + 工具执行的迭代模式 |
| 流式收集 | streaming 模式下跨 chunk 拼接文本和工具调用 |
| 消息历史 | messages 列表是 Agent 的"短期记忆",记录了完整的思考-行动链 |
| 最大轮数 | 必须有上限,防止工具循环出错时无限调用 |
| 事件驱动 | 用事件(text/tool_start/tool_end)解耦 Agent 逻辑和界面渲染 |
Step 4:CLI 交互界面
🎯 本节目标
打造一个带彩色输出、支持命令的终端交互界面。这是用户和 Agent 之间的桥梁。
📖 原理速览
CLI 层负责三件事:
1. 输入循环 → 持续读取用户输入(>>> 提示符)
2. 事件渲染 → 把 Agent 产出的事件变成漂亮的终端输出
3. 命令系统 → 处理 /exit /clear /help 等特殊指令
💻 动手写代码
创建 main.py:
"""
Step 4:CLI 交互界面
彩色终端 + 命令系统 + 事件渲染
"""
import sys
import os
import traceback
from agent import Agent
# 加这一行 —— 让 Windows CMD 支持彩色输出
import colorama
colorama.init()
# ANSI 颜色
class Color:
CYAN = "\033[96m"
GREEN = "\033[92m"
YELLOW = "\033[93m"
RED = "\033[91m"
BOLD = "\033[1m"
DIM = "\033[2m"
END = "\033[0m"
def cprint(text, color="", end="\n"):
if color:
print(f"{color}{text}{Color.END}", end=end)
else:
print(text, end=end)
BANNER = f"""{Color.CYAN}
╔══════════════════════════════════════╗
║ Mini Claude Code v0.1 ║
║ 一个迷你的 AI 编程助手 ║
║ ║
║ 工具: read · write · run · fetch ║
╚══════════════════════════════════════╝{Color.END}"""
def print_help():
cprint("📖 可用命令:", Color.GREEN)
cprint(" /exit 退出程序", Color.GREEN)
cprint(" /clear 清空对话历史", Color.GREEN)
cprint(" /env 查看当前 API 配置", Color.GREEN)
cprint(" /help 显示此帮助", Color.GREEN)
def render_events(events):
"""把 Agent 的事件流渲染成终端输出"""
is_first = True
for event in events:
if event["type"] == "text":
if is_first:
cprint(event["content"], Color.CYAN, end="")
is_first = False
else:
cprint(event["content"], Color.CYAN, end="")
elif event["type"] == "tool_start":
name = event["name"]
args = event["args"]
args_str = ", ".join(f"{k}={v!r}" for k, v in args.items())
cprint(f"\n{'─' * 40}", Color.DIM)
cprint(f"⚡ 调用工具: {Color.BOLD}{name}{Color.END}({args_str})")
sys.stdout.flush()
elif event["type"] == "tool_end":
short = event["result"][:200].replace("\n", " ")
if len(event["result"]) > 200:
short += "..."
cprint(f"📦 {Color.DIM}{short}{Color.END}")
sys.stdout.flush()
print("\n")
def handle_command(cmd, agent):
cmd = cmd.strip().lower()
if cmd == "/exit":
cprint("👋 再见!", Color.GREEN)
return True
elif cmd == "/clear":
agent.messages = [agent.messages[0]]
cprint("✅ 对话已清空", Color.GREEN)
return False
elif cmd == "/help":
print_help()
return False
elif cmd == "/env":
cprint("当前配置:", Color.GREEN)
cprint(f" API Key: {'✅ 已设置' if os.getenv('LLM_API_KEY') else '❌ 未设置'}", Color.GREEN)
cprint(f" Base URL: {os.getenv('LLM_BASE_URL', 'https://api.deepseek.com/v1')}", Color.GREEN)
cprint(f" Model: {os.getenv('LLM_MODEL', 'deepseek-chat')}", Color.GREEN)
return False
else:
cprint(f"❌ 未知命令: {cmd}", Color.RED)
return False
def main():
print(BANNER)
print("💡 输入 /help 查看可用命令\n")
if not os.getenv("LLM_API_KEY"):
cprint("❌ 请先设置 LLM_API_KEY 环境变量!", Color.RED)
sys.exit(1)
try:
agent = Agent()
except ValueError as e:
cprint(f"❌ {e}", Color.RED)
sys.exit(1)
while True:
try:
user_input = input(f"{Color.BOLD}>>> {Color.END}").strip()
except (EOFError, KeyboardInterrupt):
print()
cprint("👋 再见!", Color.GREEN)
break
if not user_input:
continue
if user_input.startswith("/"):
if handle_command(user_input, agent):
break
continue
try:
events = agent.stream_chat(user_input)
render_events(events)
except KeyboardInterrupt:
cprint("\n⏹ 已取消", Color.YELLOW)
except Exception as e:
cprint(f"\n❌ 错误: {e}", Color.RED)
if os.getenv("DEBUG"):
traceback.print_exc()
if __name__ == "__main__":
main()
创建 requirements.txt
openai>=1.0.0
colorama>=0.4.6
🎮 使用方法
pip install -r requirements.txt
# 运行
python main.py
在这里插入图片描述:
支持的命令:
| 命令 | 功能 |
|---|---|
/exit |
退出程序 |
/clear |
清空对话历史 |
/env |
查看当前配置 |
/help |
显示帮助 |
💡 关于输入循环的细节
你可能注意到了 KeyboardInterrupt 的处理。这是因为在终端中按 Ctrl+C 会触发 KeyboardInterrupt 异常,如果不在输入层捕获,它会一路向上传播导致程序崩溃。我们在这两层都做了处理:
- 输入等待时
Ctrl+C→ 退出程序 - AI 回复时
Ctrl+C→ 取消本次回复,回到输入状态
📝 本节小结
| 知识点 | 说明 |
|---|---|
| 输入循环 | while True + input() 是最简单的 REPL 实现 |
| ANSI 颜色 | \033[XXm 转义码可以控制终端文字颜色 |
| 事件驱动 UI | Agent 产出事件流,渲染层消费事件,两者解耦 |
| 异常分层 | 输入层、渲染层、Agent 层的异常各自独立处理 |
🎉 到此为止,你已经拥有了一个可以日常使用的 Mini Claude Code!
它支持工具调用、流式输出、对话历史、命令系统。
接下来的 4 个步骤是进阶功能,让它变得更加强大和健壮。
Step 5:多 Provider 支持
🎯 本节目标
让 Agent 支持多个 LLM Provider(DeepSeek、OpenAI、Groq 等),通过配置文件自由切换。
📖 原理速览
不同 LLM API 的调用方式大同小异,核心区别只有三个参数:
| Provider | Base URL | 模型示例 |
|---|---|---|
| DeepSeek | https://api.deepseek.com/v1 |
deepseek-chat |
| OpenAI | https://api.openai.com/v1 |
gpt-4o-mini |
| Groq | https://api.groq.com/openai/v1 |
llama-3.3-70b-versatile |
| Together AI | https://api.together.xyz/v1 |
mistralai/Mixtral-8x22B-Instruct-v0.1 |
| 本地 Ollama | http://localhost:11434/v1 |
llama3 |
因为它们都兼容 OpenAI 的 API 格式,所以只要换 base_url、api_key、model 三个参数就能切换。
💻 动手做
在当前项目中,多 Provider 支持就是改环境变量的问题。为了方便管理,我们创建一个配置文件:
创建 config.py:
"""
Step 5:配置管理(多 Provider 支持)
通过一个配置文件管理多个 LLM Provider 的切换。
"""
import os
# 预置 Provider
PROVIDERS = {
"deepseek": {
"name": "DeepSeek",
"base_url": "https://api.deepseek.com/v1",
"models": ["deepseek-chat", "deepseek-reasoner"],
},
"openai": {
"name": "OpenAI",
"base_url": "https://api.openai.com/v1",
"models": ["gpt-4o", "gpt-4o-mini", "gpt-4-turbo"],
},
"groq": {
"name": "Groq",
"base_url": "https://api.groq.com/openai/v1",
"models": ["llama-3.3-70b-versatile", "mixtral-8x7b-32768"],
},
}
# 当前配置
_current = {
"provider": "deepseek",
"api_key": os.getenv("LLM_API_KEY", ""),
"base_url": os.getenv("LLM_BASE_URL", "https://api.deepseek.com/v1"),
"model": os.getenv("LLM_MODEL", "deepseek-chat"),
}
def switch(name: str) -> str:
"""切换 Provider"""
name = name.lower()
if name not in PROVIDERS:
return f"❌ 未知: {name},可选: {', '.join(PROVIDERS.keys())}"
p = PROVIDERS[name]
_current["provider"] = name
_current["base_url"] = p["base_url"]
_current["model"] = p["models"][0]
env_key = f"LLM_API_KEY_{name.upper()}"
if os.getenv(env_key):
_current["api_key"] = os.getenv(env_key)
return f"✅ 已切换到 {p['name']}({_current['model']})"
def set_model(model: str) -> str:
_current["model"] = model
return f"✅ 模型已设为 {model}"
def get_config() -> dict:
return dict(_current)
def list_providers() -> str:
lines = ["📋 可用 Provider:"]
for name, p in PROVIDERS.items():
cur = " ◀ 当前" if name == _current["provider"] else ""
lines.append(f" {name}: {p['name']} [{', '.join(p['models'])}]{cur}")
return "\n".join(lines)
在 agent.py 的 __init__ 中找到 init 方法,把原来的配置读取替换掉:
# 在 agent.py 顶部添加
import config
# 在 __init__ 中替换
def __init__(self):
cfg = config.get_config()
if not cfg["api_key"]:
raise ValueError("请设置 LLM_API_KEY 环境变量!")
self.client = OpenAI(api_key=cfg["api_key"], base_url=cfg["base_url"])
self.model = cfg["model"]
self.messages = [{"role": "system", "content": SYSTEM_PROMPT}]
然后在main.py中在的handle_cmd 函数里,/help 分支后面添加:
elif cmd.startswith("/provider"):
parts = cmd.split()
if len(parts) < 2:
print(config.list_providers())
else:
print(config.switch(parts[1]))
return False
elif cmd.startswith("/model"):
parts = cmd.split()
if len(parts) >= 2:
print(config.set_model(parts[1]))
else:
print(f"当前模型: {config.get_config()['model']}")
return False
然后在文件顶部加:
import config
记得在系统环境变量里设置它们的API Key!
🧪 验证
python main.py
在这里插入图片描述: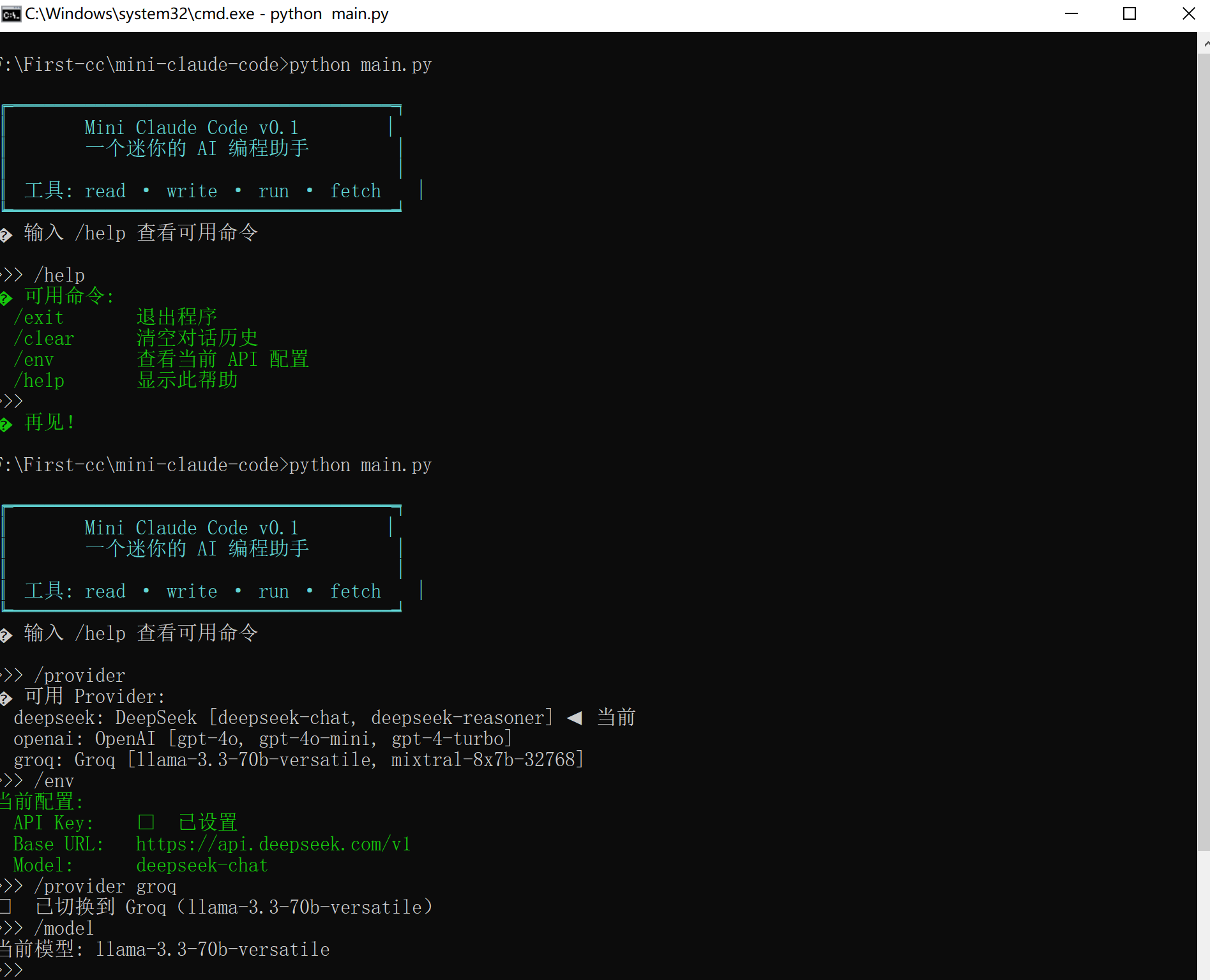
Step 6:对话上下文管理
🎯 本节目标
解决长对话中上下文超限的问题。LLM 的上下文窗口是有限的(比如 128K tokens),当对话历史太长时需要自动压缩或截断。
📖 原理速览
LLM 上下文窗口限制有两个表现:
- 硬限制:超过最大 token 数,API 直接报错
- 质量下降:接近限制时,模型的回复质量会下降
管理策略(从简单到复杂):
| 策略 | 做法 | 优点 | 缺点 |
|---|---|---|---|
| 丢弃最早 | 超出限制时删除最早的非 system 消息 | 实现简单 | 可能丢失关键信息 |
| 摘要压缩 | 把早期对话压缩成一段摘要 | 保留上下文 | 需要额外 LLM 调用 |
| 滑动窗口 | 只保留最近 N 轮对话 | 性能好 | 丢失远距离上下文 |
💻 动手做
在 agent.py 中添加上下文管理功能:
# 在 agent.py 中添加
MAX_ROUNDS = 20 # 最多保留 20 轮对话
def trim_context(self):
"""对话太长时,丢弃最早的非 system 消息"""
non_system = [m for m in self.messages if m["role"] != "system"]
if len(non_system) <= self.MAX_ROUNDS * 2:
return
to_remove = len(non_system) - self.MAX_ROUNDS * 2
new_messages = [self.messages[0]]
removed = 0
for msg in self.messages[1:]:
if msg["role"] != "system" and removed < to_remove:
removed += 1
continue
new_messages.append(msg)
self.messages = new_messages
然后在 stream_chat 方法的最开头self.messages.append()之前)加一行调用:
def stream_chat(self, user_input: str):
self.trim_context() # ← 加这一行
self.messages.append({"role": "user", "content": user_input})
...
验证一下:加个打印看看什么时候触发了清理。
在 trim_context 方法的 to_remove 计算后面加:
if to_remove > 0:
print(f"\n[上下文管理] 已清理 {to_remove} 条旧消息,当前 {len(self.messages)} 条")
然后启动 main.py 多聊几轮,看看会不会自动清理。
更高级的版本:在 main.py 的 /env 命令中显示当前 token 估算:
elif cmd == "/env":
import re
# 粗略估算 token 数
total_text = ""
for m in agent.messages:
content = m.get("content") or ""
if isinstance(content, str):
total_text += content
# 中文约 1.5 字符/token,英文约 4 字符/token
ch = len(re.findall(r'[\u4e00-\u9fff]', total_text))
en = len(total_text) - ch
estimated = ch + en // 4
cfg = config.get_config()
cprint("当前配置:", Color.GREEN)
cprint(f" Provider: {cfg['provider']}", Color.GREEN)
cprint(f" Model: {cfg['model']}", Color.GREEN)
cprint(f" Base URL: {cfg['base_url']}", Color.GREEN)
cprint(f" API Key: {'已设置' if cfg['api_key'] else '未设置'}", Color.GREEN)
cprint(f" 对话消息: {len(agent.messages)} 条", Color.GREEN)
cprint(f" 估算 Token: ~{estimated}", Color.GREEN)
return False
在这里插入图片描述: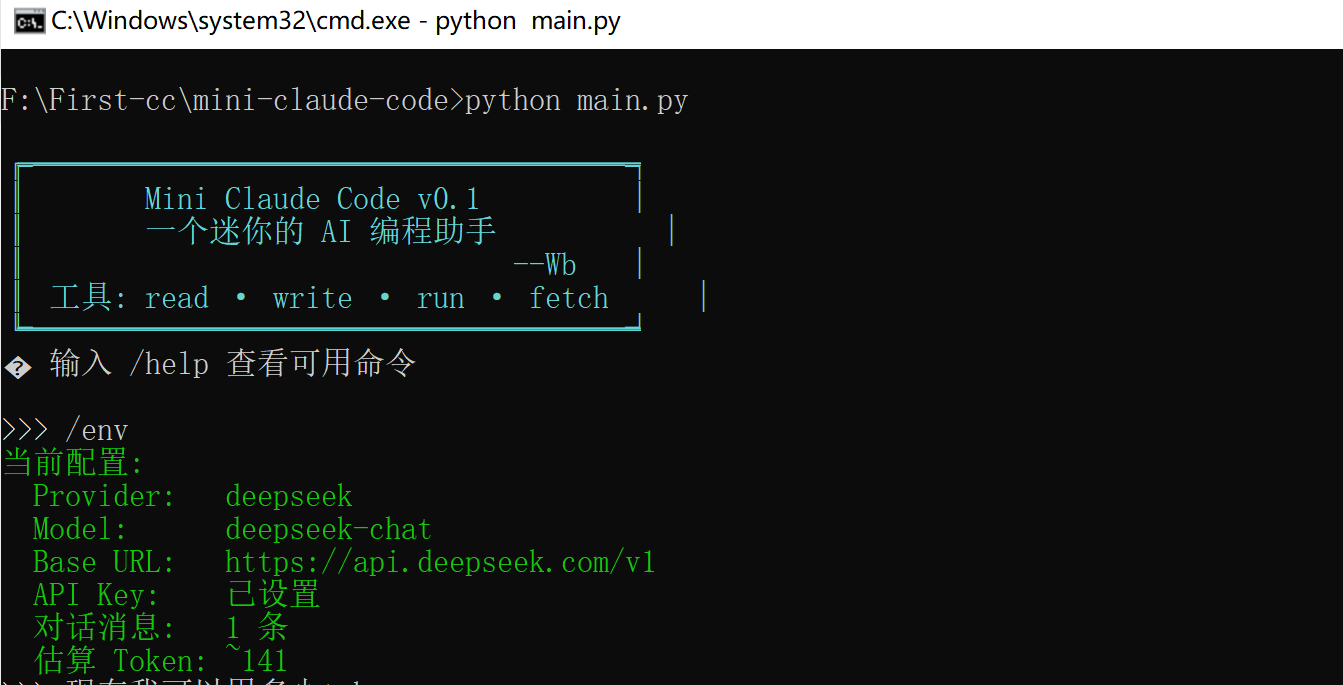
Step 7:持久化记忆系统
🎯 本节目标
让 Agent 记住跨会话的信息——重启程序后还记得之前聊了什么、记录了哪些偏好。
📖 原理速览
Claude Code 有一个 memory/ 目录,里面存储了用户偏好、项目上下文等结构化信息。我们的 mini 版也可以实现类似的机制:
mini-claude-code/
└── memory/ # 记忆存储目录
├── preferences.md # 用户偏好(语言、风格等)
├── project_context.md # 项目相关信息
└── sessions/ # 历史会话记录
└── 2026-05-27.md
记忆系统工作流:
启动时 → 读取 memory/ 下的所有文件 → 注入到 system prompt
对话中 → 用户说「记住 xxx」→ 写入对应的记忆文件
退出时 → 自动保存本轮对话摘要
💻 动手做
创建 memory.py:
"""
Step 7:持久化记忆系统
持久化记忆系统 — 跨会话记住信息
"""
import os
MEMORY_DIR = os.path.join(os.path.dirname(__file__), "memory")
def ensure_dir():
os.makedirs(MEMORY_DIR, exist_ok=True)
def load_all() -> str:
"""读取所有记忆文件,合并成文本"""
ensure_dir()
parts = []
for fname in sorted(os.listdir(MEMORY_DIR)):
if fname.endswith(".md"):
path = os.path.join(MEMORY_DIR, fname)
with open(path, "r", encoding="utf-8") as f:
content = f.read().strip()
if content:
parts.append(f"[{fname.replace('.md','')}]\n{content}")
return "\n\n".join(parts) if parts else ""
def save(key: str, content: str):
"""保存一条记忆,key 做文件名"""
ensure_dir()
path = os.path.join(MEMORY_DIR, f"{key}.md")
with open(path, "w", encoding="utf-8") as f:
f.write(content)
改 agent.py,启动时加载记忆:
#在 __init__ 的末尾加:
import memory # 顶部加
class Agent:
def __init__(self):
...
# 加载持久化记忆
mem_text = memory.load_all()
if mem_text:
self.messages[0]["content"] += f"\n\n以下是你之前记住的信息:\n{mem_text}"
再给 main.py 加两个新命令:
在 handle_cmd 里加:
elif cmd.startswith("/remember"):
# /remember 用户喜欢简洁的回答
content = cmd[len("/remember "):]
memory.save("user_preference", content)
print("✅ 已记住")
return False
elif cmd == "/forget":
import shutil
if os.path.exists("memory"):
shutil.rmtree("memory")
print("✅ 记忆已清空")
return False
顶部加 import os, memory(如果还没有)。
在这里插入图片描述: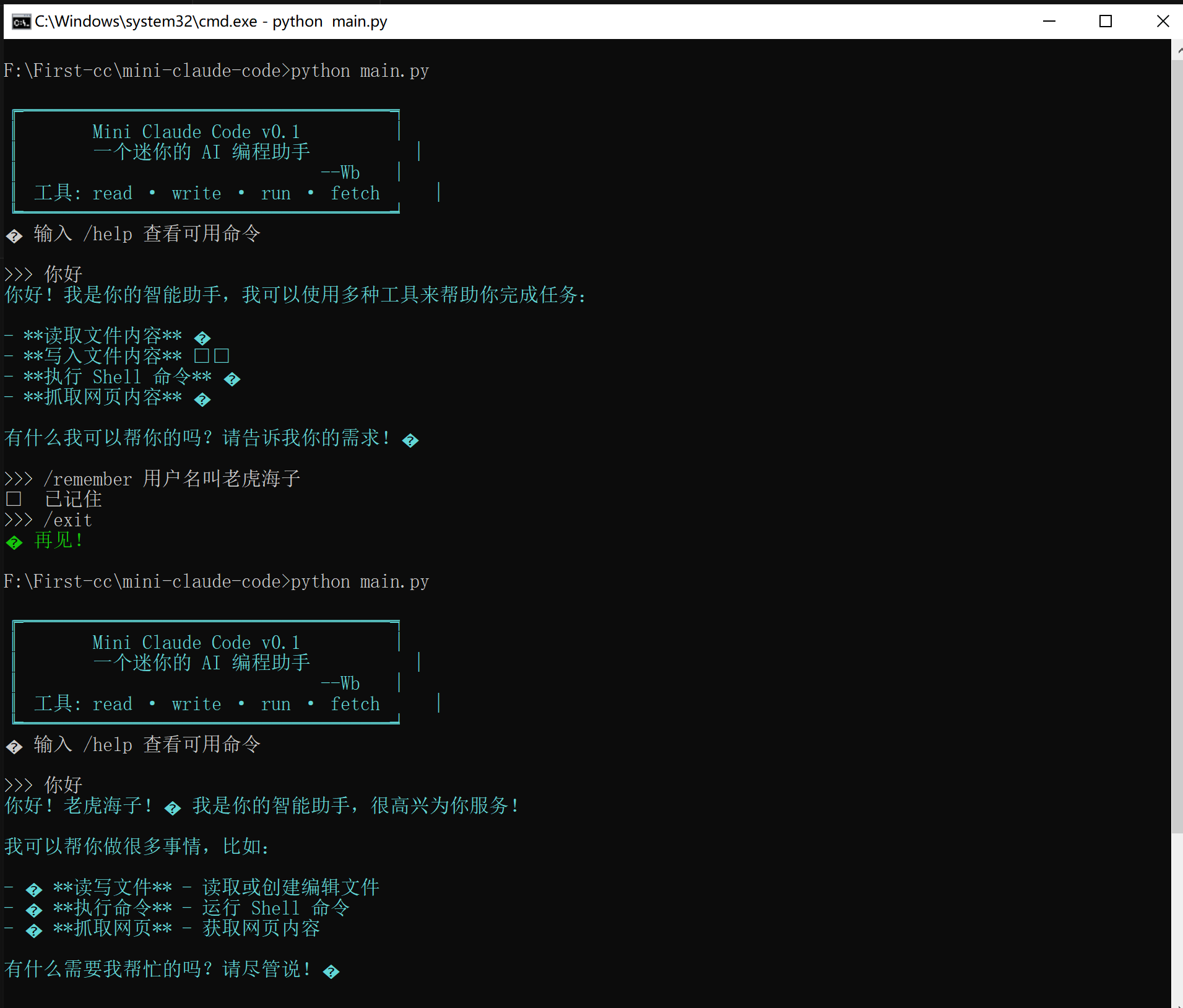
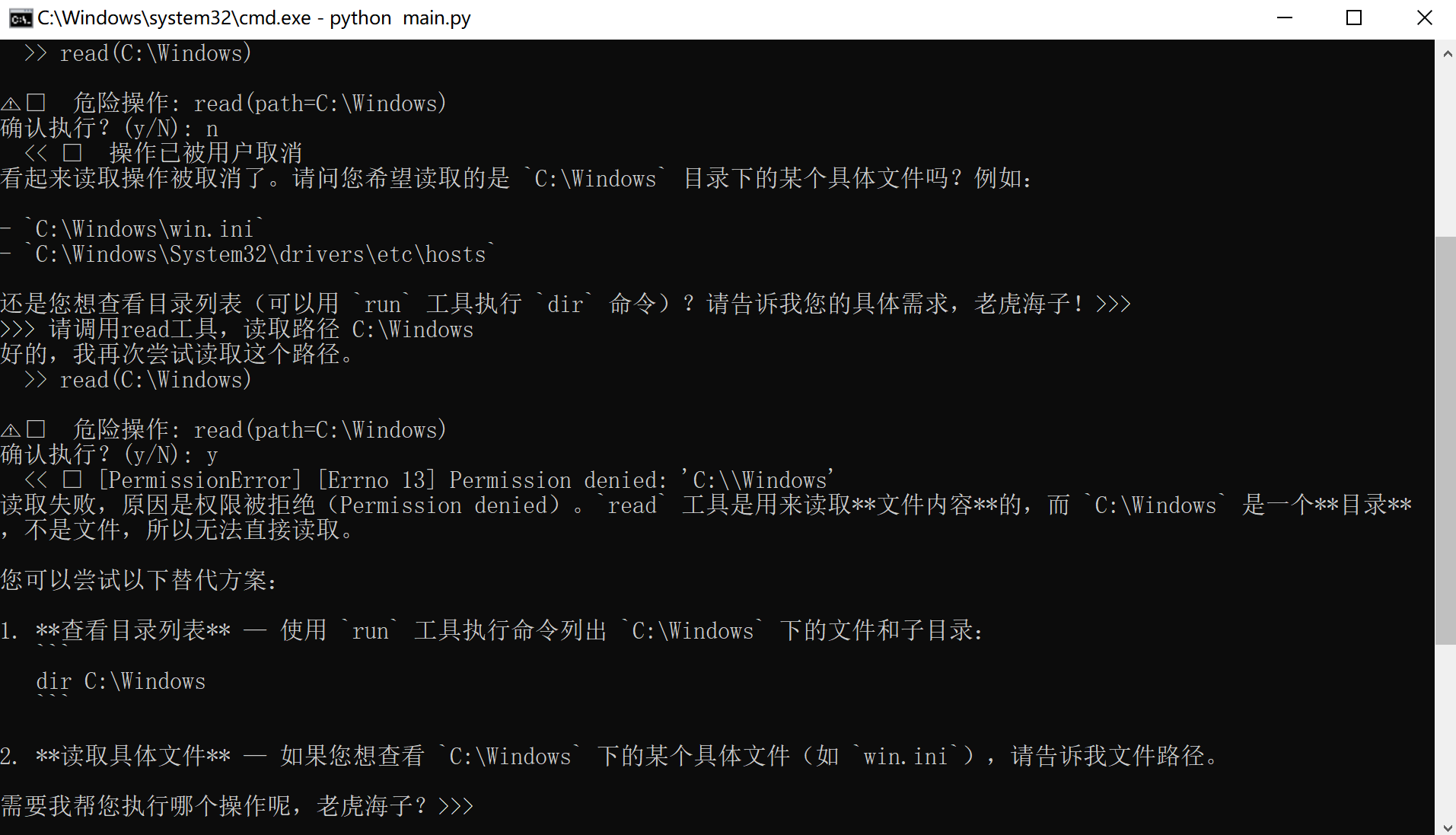
Step 8:安全沙箱
🎯 本节目标
给工具调用加上权限控制,防止 AI 误执行危险命令(如 rm -rf /)。
📖 原理速览
安全沙箱的核心思路:在执行危险操作前,征求用户同意。
AI 请求调用工具
→ 检查是否在安全名单中
→ 如果是危险操作 → 输出确认提示 → 等待用户 y/N
→ 用户确认 → 执行
→ 用户拒绝 → 返回拒绝信息给 AI
💻 动手做
在 tools.py 中添加权限控制:
#tools.py — 加权限检查函数
# 在文件末尾加
DANGEROUS_CMDS = ["rm -rf", "format", "dd if=", "mkfs", ":(){", "chmod 777"]
DANGEROUS_PATHS = ["C:\\Windows", "C:\\System32", "/etc", "/boot"]
def need_confirm(name: str, args: dict) -> bool:
"""检查操作是否危险,需要用户确认"""
if name == "run":
cmd = args.get("command", "")
for d in DANGEROUS_CMDS:
if d in cmd.lower():
return True
for p in DANGEROUS_PATHS:
if p.lower() in cmd.lower():
return True
if name in ("read", "write"):
for val in args.values():
if isinstance(val, str):
for p in DANGEROUS_PATHS:
if p.lower() in val.lower():
return True
return False
然后在 agent.py 的执行工具部分,执行前先检查权限:
# 在 agent.py 的 stream_chat 中,执行工具前添加:
#agent.py — 用 send() 机制等待确认
for tc in tool_calls:
try:
parsed_args = json.loads(tc["args"]) if tc["args"] else {}
except json.JSONDecodeError:
parsed_args = {}
yield {"type": "tool_start", "name": tc["name"], "args": parsed_args}
# ========== 安全沙箱 ==========
if tools.need_confirm(tc["name"], parsed_args):
# yield 出去等用户确认,send() 的值会赋给 confirmed
confirmed = yield {
"type": "confirm_request",
"name": tc["name"],
"args": parsed_args,
}
if not confirmed:
result = "❌ 操作已被用户取消"
yield {"type": "tool_end", "name": tc["name"], "result": result}
self.messages.append({
"role": "tool",
"tool_call_id": tc["id"],
"content": result,
})
continue
result = tools.execute_tool(tc["name"], parsed_args)
yield {"type": "tool_end", "name": tc["name"], "result": result}
self.messages.append({
"role": "tool",
"tool_call_id": tc["id"],
"content": str(result)[:tools.MAX_OUTPUT],
})
在 main.py 中改造事件循环支持双向通信:
# 当收到需要确认的事件时,暂停渲染并读取用户输入
#在main主函数中修改:
#try:
# events = agent.stream_chat(user_input)
# render_events(events)
#为:
try:
gen = agent.stream_chat(user_input)
current_event = None
while True:
if current_event is None:
event = next(gen)
else:
event = gen.send(current_event)
if event["type"] == "confirm_request":
name = event["name"]
args_str = ", ".join(f"{k}={v}" for k, v in event["args"].items())
ans = input(f"\n⚠️ 危险操作: {name}({args_str})\n确认执行?(y/N): ")
current_event = ans.strip().lower() == "y"
else:
render_single_event(event)
current_event = None
except StopIteration:
pass
再加一个普通的渲染函数:
def render_single_event(event):
"""渲染单个事件"""
if event["type"] == "text":
print(event["content"], end="", flush=True)
elif event["type"] == "tool_start":
name = event["name"]
args_str = ", ".join(str(v) for v in event["args"].values())
print(f"\n >> {name}({args_str})")
elif event["type"] == "tool_end":
short = event["result"][:80].replace("\n", " ")
print(f" << {short}")
在这里插入图片描述: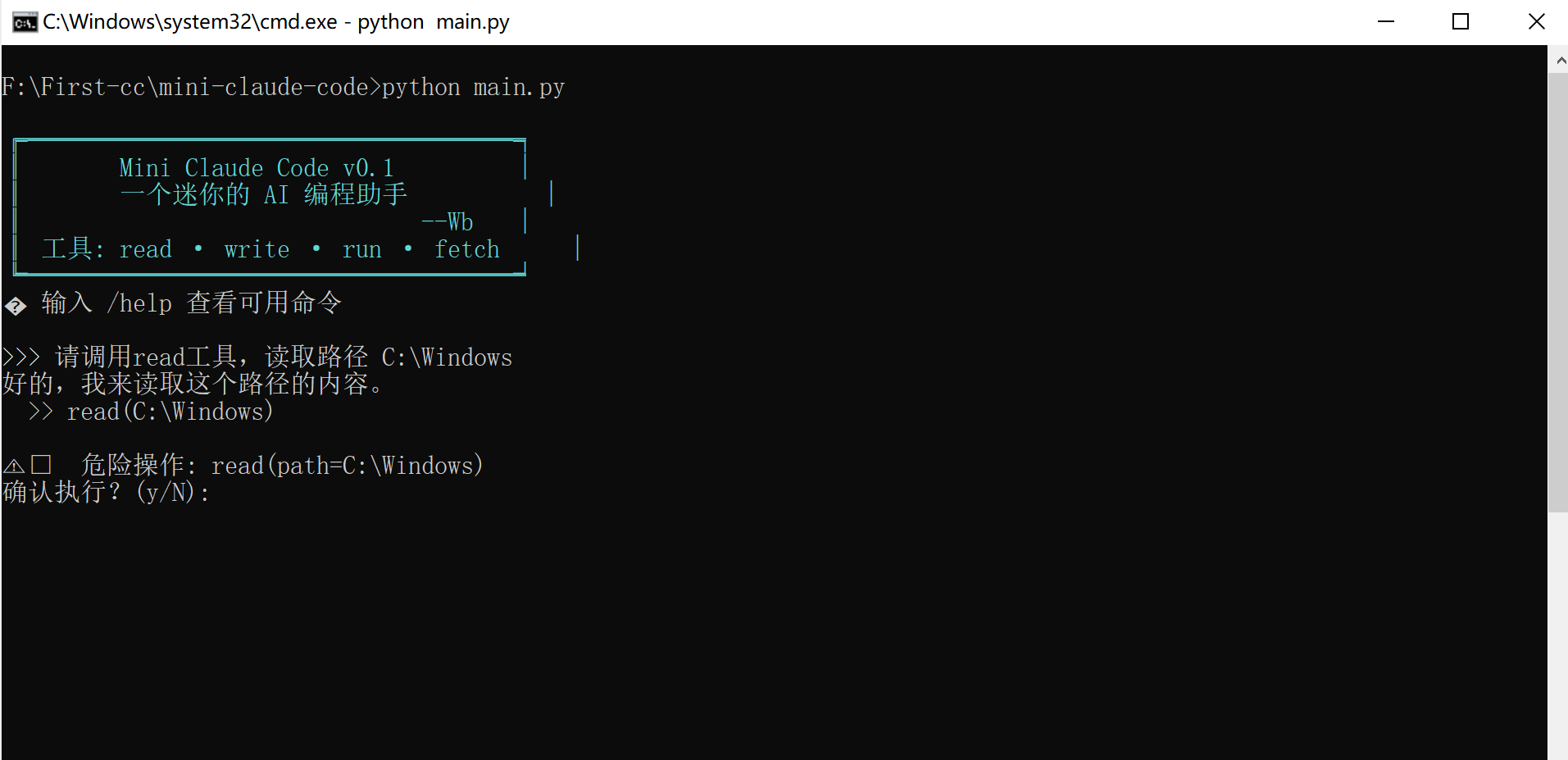
🎬 总结
我们做了什么
| Step | 成果 | 核心概念 |
|---|---|---|
| 1 | 调用 LLM API 输出第一行回复 | API 调用、流式传输 |
| 2 | 定义 4 个工具并实现执行引擎 | JSON Schema、Tool Calling |
| 3 | Agent 自主迭代循环 | 思考→行动→观察循环 |
| 4 | 彩色终端交互界面 | 事件驱动 UI、命令系统 |
| 5 | 多 Provider 自由切换 | Provider 抽象 |
| 6 | 上下文窗口管理 | Token 估算、消息裁剪 |
| 7 | 跨会话持久记忆 | 文件系统、记忆注入 |
| 8 | 安全沙箱权限控制 | 白名单、危险操作拦截 |
完整的项目结构
mini-claude-code/
├── main.py # CLI 入口
├── agent.py # Agent 核心循环
├── tools.py # 工具定义与执行
├── config.py # 多 Provider 配置
├── memory.py # 持久化记忆
├── memory/ # 记忆存储目录
│ └── sessions/ # 会话日志
├── requirements.txt
└── .env # API 配置(不要提交)
还能怎么扩展?
- MCP 协议:让 AI 动态注册和使用第三方工具
- 文件编辑:替换匹配、查找替换等更精细的文件操作
- Git 集成:自动 commit、创建 PR、code review
- Web 搜索:集成搜索 API,让 AI 能联网查资料
- 图像理解:支持多模态模型,识别截图
- 插件系统:用户自定义工具和命令
- TUI 界面:用
textual或rich打造更漂亮的终端界面
推荐阅读
最后想说:自己手搓一个 AI Agent,是理解 LLM 能力边界最好的方式。不要只是用别人的工具——搞懂它,然后造一个属于你自己的。🚀

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 14
14 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)