RAG技术怎么让AI笔记工具读懂你的知识库?
我一直在找一种能把零散信息变成体系的方法。收藏夹几百个视频,播客几十期,真正回头看的不到十分之一。
后来接触到RAG(检索增强生成)这个技术思路,才搞明白为什么有些AI笔记工具用起来特别懂你,有些就只会泛泛总结。
RAG到底在解决什么问题
大模型有个老毛病,你问它一个跟自己领域相关的问题,它经常编造答案。原因是模型的知识是训练时固化进去的,跟你的实际业务场景之间有条鸿沟。
RAG的做法是,先把你的内容(视频笔记、播客文字稿、文档)拆成小块存进向量数据库。
当你提问时,系统先从你的知识库里检索出最相关的内容片段,再把这些片段连同你的问题一起喂给大模型。模型拿到的是你自己的真实素材,输出自然就靠谱了。
简单说,RAG = 检索 + 增强 + 生成。
检索找到相关内容,增强把内容注入上下文,生成产出精准回答。
向量检索:让机器理解「意思相近」
传统搜索靠关键词匹配,你搜「会议纪要」,它只能找到包含这几个字的内容。但你真正想找的可能是「上周三讨论的那个方案」。
向量检索把每段文字编码成高维向量(embedding),语义相近的内容在向量空间里距离也近。
这样哪怕表述完全不同,只要意思相关就能被检索到。比如你搜「如何提高团队效率」,它能找到你之前记录的「敏捷开发实践」和「每日站会机制」。
这一步的关键在于分块策略。一篇长笔记怎么切,切多大,块与块之间要不要保留重叠区域,都直接影响检索质量。切太碎会丢失上下文,切太大会混入无关信息。
在笔记工具里的实际应用
当你把一批视频笔记导入知识库后,RAG的工作流程大概是这样:
首先,系统对每篇笔记做分块和向量化处理,建立索引。
然后你问「我之前看的那个关于大模型微调的视频讲了什么」,系统会从所有笔记中检索出最相关的几个片段。
最后把这些片段作为上下文交给大模型,模型基于你的实际内容生成回答。
整个过程用户是无感的,你只觉得「这工具怎么什么都知道」。
多模态内容的特殊挑战
音视频笔记和纯文本不太一样。
一个B站技术视频可能包含讲解者的口述、PPT上的图表、代码演示画面。纯靠语音转文字出来的内容,结构化程度往往不够。
现在一些工具的做法是,把语音转录和视频画面分析分开处理。比如Ai好记在转录时会自动截取视频中的PPT画面,把图文信息整合到同一篇笔记里。这样RAG系统拿到的输入更丰富,检索和生成的质量也会更好。
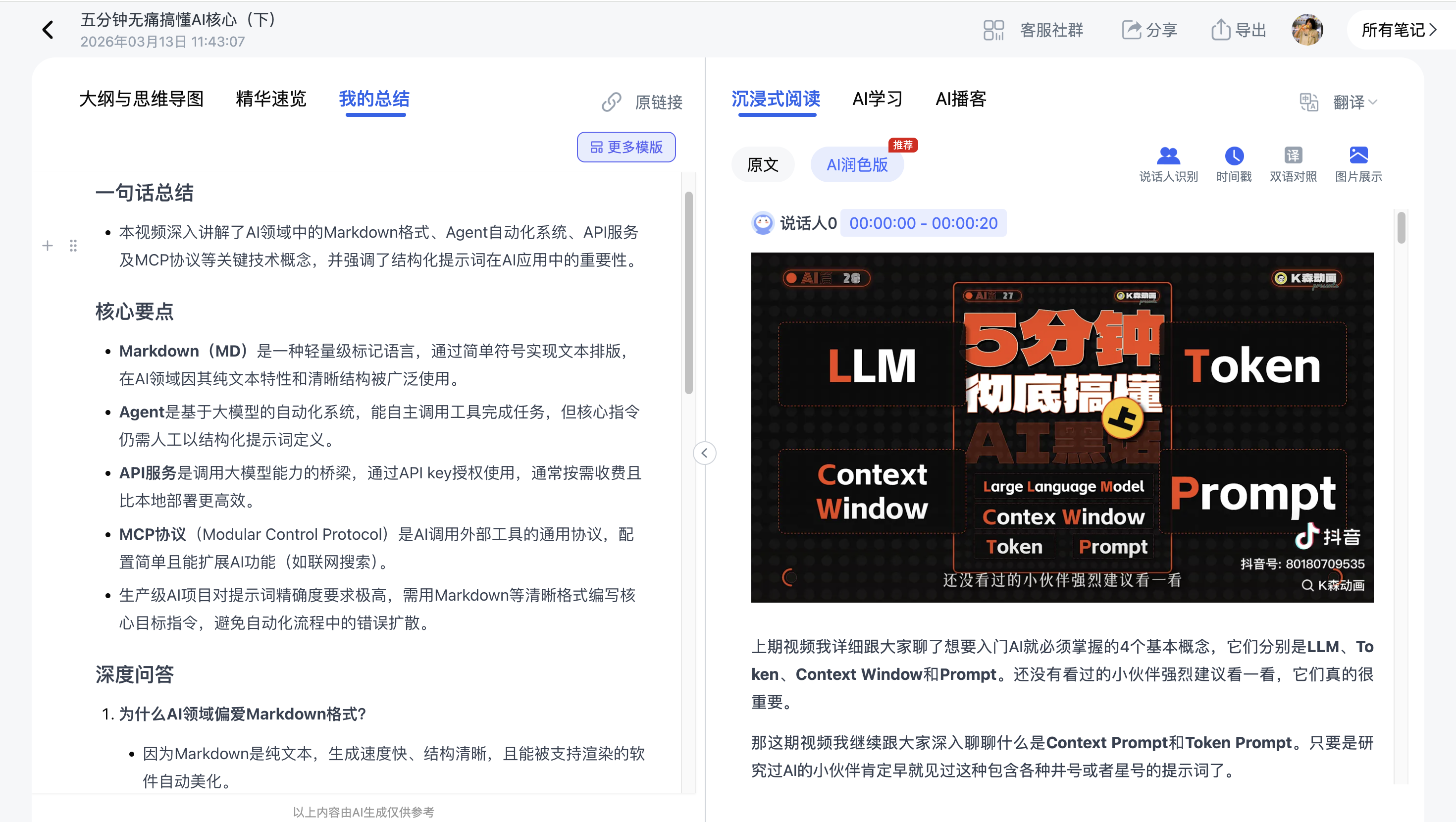
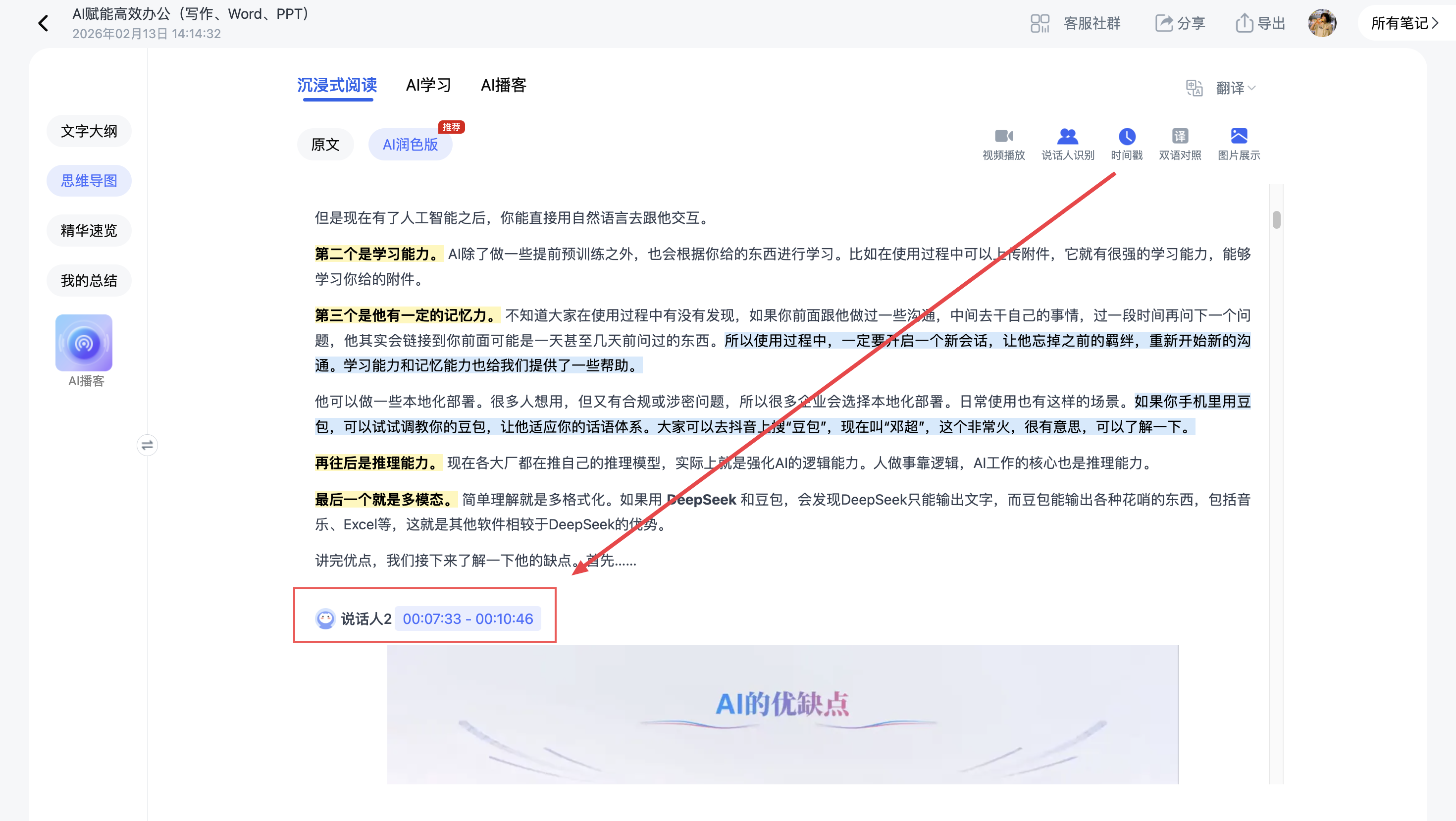
另外,视频笔记天然带有时间戳信息。RAG系统如果能利用这个特征,在检索时就能告诉你「这个问题的答案在视频的第23分钟」,用户体验会好很多。
RAG不是万能的
坦率地讲,RAG也有明显局限。检索质量高度依赖分块策略和embedding模型的选择,选不好就会出现「明明库里有相关内容,但就是检索不到」的情况。
还有就是知识库的维护成本。你积累了上千条笔记后,内容之间难免有冲突或过时信息。RAG系统本身不做内容质量判断,过时的笔记照样会被检索出来。
另外,上下文窗口是有限的。检索出来的相关片段太多时,要取舍哪些放进去,哪些丢掉,这个排序策略也很关键。
跟传统知识管理工具的区别
Obsidian、Notion这类工具的核心逻辑是手动建立链接和目录结构。你得自己想清楚笔记之间的关系,手动打标签、建索引。
RAG驱动的知识管理是反过来的,你只管往库里扔内容,检索和关联由系统自动完成。
对于像我这种懒人来说,后者明显更省心。当然如果你享受手动整理的过程,那传统方式也有它的价值,两者并不矛盾。
说到底,RAG在笔记工具中的作用就是帮你把「收藏了但没看」变成「随时能调用」。技术本身不复杂,关键是工程落地的细节。谁能把分块、检索、生成这一套链路打磨得好,谁的产品用起来就更顺手。
FAQ
Q:RAG和普通搜索有什么区别?
A:普通搜索基于关键词匹配,RAG基于语义理解。搜「怎么开会更高效」,普通搜索找包含这几个字的内容,RAG能找到语义相关的「敏捷开发实践」。
Q:知识库内容太多会不会变慢?
A:会有影响。向量数据库的检索速度跟数据量有关,但一般万级以下的笔记量不会有明显延迟。更大规模需要做索引优化。
Q:AI笔记工具的RAG和企业级RAG有什么不同?
A:个人笔记场景数据量小、查询频率低,对基础设施要求不高。企业级RAG需要处理权限控制、多租户、高并发等更复杂的问题。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 1
1 0
0- 0



 已为社区贡献27条内容
已为社区贡献27条内容

所有评论(0)