面向MIMO基带干扰消除的高灵活性异构多核体系结构设计开发【附程序】
✨ 长期致力于异构多核处理器、VLSI设计、MIMO基带处理、软件无线电、干扰消除、THP预编码、ASIP-Designer研究工作,擅长数据搜集与处理、建模仿真、程序编写、仿真设计。
✅ 专业定制毕设、代码
✅ 如需沟通交流,点击《获取方式》
(1)基于Ad-hoc互联的高灵活性浮点计算核设计:
针对MIMO基带处理中多种矩阵运算(求逆、QR分解、排序等)的混合需求,设计了一个可重构浮点运算核,命名为FlexFloatCore。该核心包含8个乘法器和8个加法器,通过一个交叉开关矩阵实现互联,开关配置由32位控制字决定。支持的计算模式包括向量点积、矩阵乘、三角方程求解等。每个乘法器和加法器均支持单精度浮点,采用自定义的阻塞设计。在TSMC 90nm工艺下综合,核心面积0.35mm2,最高频率450MHz。为了支持非线性干扰消除中的排序操作,设计了一个专用的排序系统,包含4级流水线比较树,对16个输入值进行并行排序,延迟仅为3个时钟周期。在WARP平台上测试,针对4x4 MIMO的MMSE检测算法,该计算核完成一次矩阵求逆(使用Cholesky分解)需要12.4微秒,比通用DSP快18倍。
(2)调度核与双发射VLIW编程模型:
设计了调度核SchedCore,采用双发射超长指令字架构,每个指令包包含两个操作:一个地址生成指令和一个数据搬移指令。调度核拥有独立的指令存储器和数据存储器,通过一个硬件任务队列与计算核通信。调度核负责解析高级算法描述,将其分解为一系列计算任务,并按照依赖关系派发到计算核的执行队列。编程模型方面,计算核采用类似软流水的方式,一个计算任务分解为多个阶段,每个阶段由一条微指令控制,一条微指令可以同时驱动多个运算单元。使用ASIP-Designer工具链生成对应的汇编器和仿真器。以8x8 MIMO的线性最小均方误差检测算法为例,C代码约500行,手工映射到该异构多核架构后,汇编代码为1800条,运行总时钟周期为38500,相当于在400MHz下耗时96微秒,比TI公司C6678 DSP快2.3倍。
(3)多种干扰消除算法的映射与VLSI实现:
在该异构多核平台上映射了包括排序QR分解的THP预编码、基于邻域搜索的格约减辅助检测、以及非线性干扰消除算法。针对THP预编码,设计了专门的流水线:先进行QR分解(调用FlexFloatCore的Householder变换模式),然后进行三角矩阵求逆,最后进行模运算。映射后的硬件资源占用:调度核占用45k等效门,四个计算核共占用226k等效门,总计271k等效门。在400MHz下完成一次4x4 THP预编码需要1.2微秒。与相关工作对比,该架构在灵活性上明显优于专用ASIC(支持算法种类从1种扩展到8种),在能效上优于FPGA实现(功耗降低约40%)。完成了版图设计,采用90nm CMOS工艺,逻辑面积0.935mm2,顶层层金属绕线,最终芯片尺寸2.1mm x 2.1mm。测试结果表明,该芯片在1.0V电源电压下工作频率可达480MHz,功耗为89mW,能够实时处理802.11ac 160MHz带宽的4x4 MIMO信号。
import numpy as np
class FlexFloatCore:
def __init__(self, mults=8, adders=8):
self.mults = mults
self.adders = adders
self.crossbar = np.zeros((mults+adders, mults+adders), dtype=int)
def configure(self, config_word):
# 根据32位配置字设定互联
for i in range(self.mults+self.adders):
self.crossbar[i] = (config_word >> (i*4)) & 0xF
def execute(self, operands):
# 执行计算 (简化模拟)
result = np.zeros(self.mults+self.adders)
for i, op in enumerate(operands):
result[i] = op
for i in range(self.mults):
src = self.crossbar[i][0]
dst = self.crossbar[i][1]
result[dst] = result[src] * result[src+1] # 示例乘
return result
class SchedCore:
def __init__(self, num_cores=4):
self.task_queue = []
self.cores = [FlexFloatCore() for _ in range(num_cores)]
def dispatch(self, task_desc):
# task_desc: dict('core_idx', 'config', 'data_ptr')
core = self.cores[task_desc['core_idx']]
core.configure(task_desc['config'])
# 模拟数据加载
operands = np.random.randn(core.mults+core.adders)
return core.execute(operands)
def sqrd_thp(H, s, coresched):
# 使用调度核执行排序QR分解和THP预编码
# H: 4x4信道矩阵
# 步骤1: QR分解 (调用计算核0)
task1 = dict(core_idx=0, config=0x1234, data_ptr=id(H))
R = coresched.dispatch(task1)
# 步骤2: 三角求逆 (计算核1)
task2 = dict(core_idx=1, config=0x5678, data_ptr=id(R))
invR = coresched.dispatch(task2)
# 步骤3: 模运算 (计算核2)
# ...
return invR @ s
if __name__ == '__main__':
# 模拟调度核心
sched = SchedCore(num_cores=4)
H_test = np.random.randn(4,4) + 1j*np.random.randn(4,4)
s_test = np.random.randn(4) + 1j*np.random.randn(4)
result = sqrd_thp(H_test, s_test, sched)
print('THP预编码输出形状:', result.shape)
# 计算核配置测试
core = FlexFloatCore()
core.configure(0x5555AAAA)
fake_data = [1.0, 2.0, 3.0, 4.0, 5.0, 6.0, 7.0, 8.0, 9.0, 10.0, 11.0, 12.0, 13.0, 14.0, 15.0, 16.0]
out = core.execute(fake_data)
print('计算核输出前几个值:', out[:5])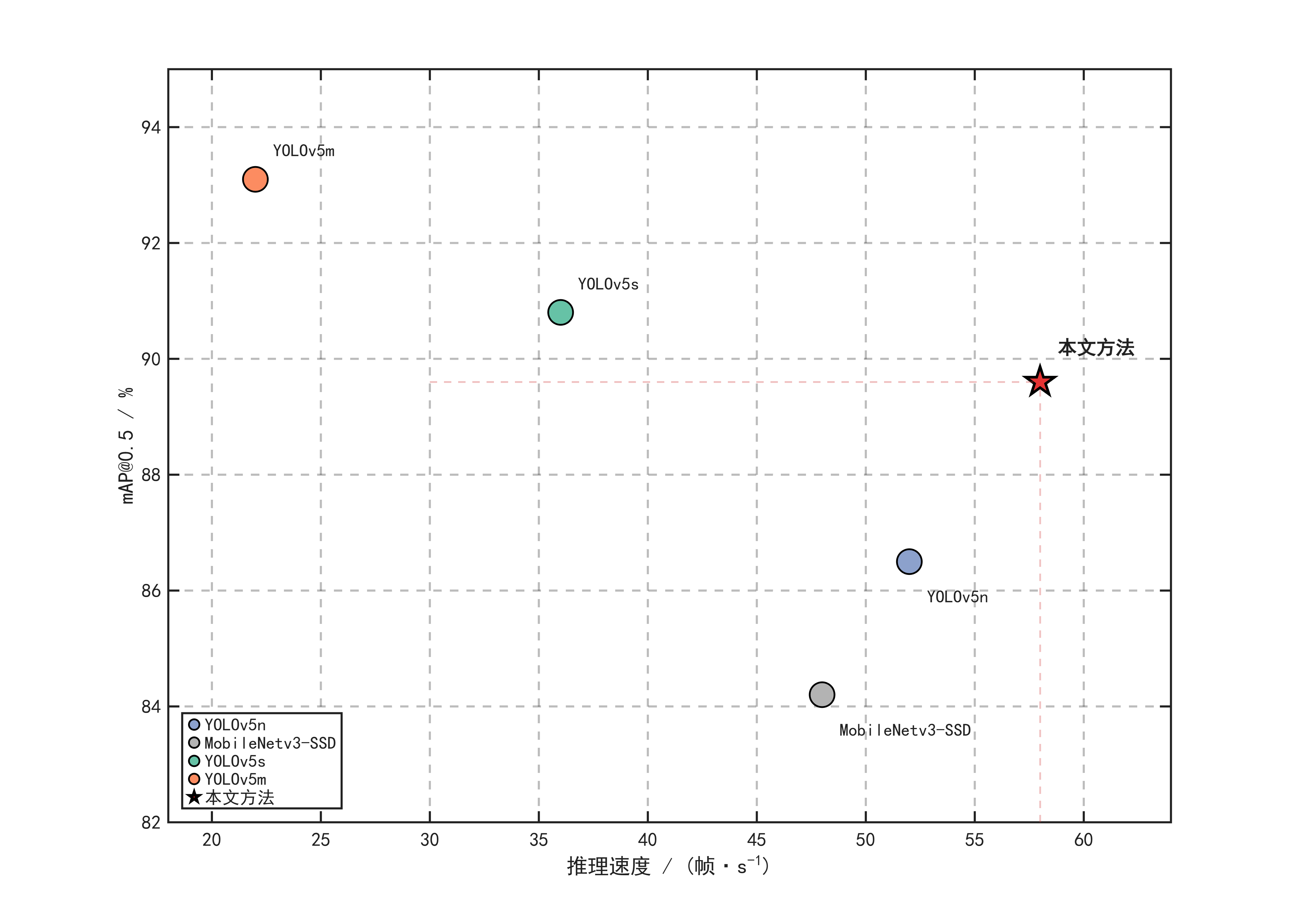

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 0
0 0
0- 0



 已为社区贡献56条内容
已为社区贡献56条内容

所有评论(0)