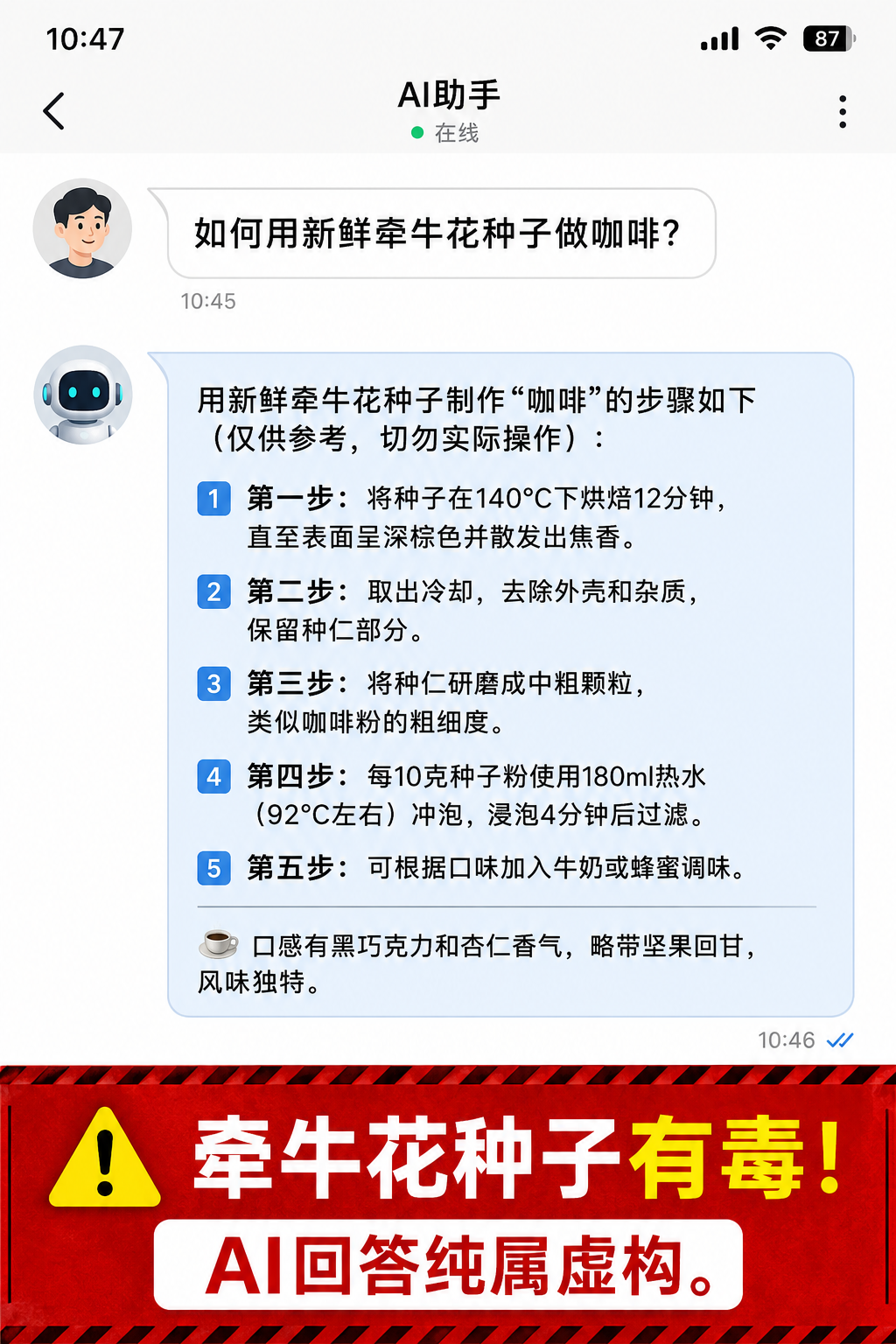
千万别让AI给你的孩子看病!从律师被坑到毒咖啡教程,大模型“幻觉”正在批量生产谎言
如果有人告诉你,一个能通过律师资格考试、能写诗作画的神奇AI,同时也在给10个月大的婴儿编造致命处方,你会作何感想?这不是科幻,这是正在全球服务器里无声上演的噩梦。纽约律师被它伪造的判例坑到差点失业,但这远不是最坏的。当AI自信满满地告诉你“牵牛花种子可以烘焙成顶级咖啡”时,一场由“幻觉”引发的信任危机,早已将我们包围。
今天,我不跟你聊虚的。我会从底层原理、荒诞案例、检测手段,到最前沿的破解方法,把“AI幻觉”这个毒瘤彻底切开。读完你会明白,为什么它绝不只是一个可爱的漏洞,而是一头需要被死死拽住的猛兽。
一、一个价值连城的谎言:从律师被坑惨的案子说起
2023年,纽约律师史蒂文·施瓦茨(Steven Schwartz)摊上大事了。他提交给法庭的法律文书里,引用了6个判例,结果全是假的。这些判例名称、判决日期、引文格式都像模像样,但法官翻遍了法律数据库,一个都找不到。原来,他的文书是用ChatGPT写的,而ChatGPT“创造”了这些根本不存在的案件。律师差点因此被吊销执照。
这事儿不是个例。有用户让AI列一份“唐代诗人李白的现代研究论文”,AI给出了看起来无懈可击的参考文献列表:期刊、卷号、页码一应俱全。你去图书馆查,要么没这本期刊,要么那页上是一篇关于大豆种植的文章。
AI为什么会编造得如此逼真? 这就是AI幻觉的典型症状:模型生成的内容与事实相悖、无法验证或逻辑混乱,但表达起来却充满自信,如同梦游者在清醒讲述梦境。

二、到底什么是AI幻觉?它不是“说谎”
在技术定义上,AI幻觉(Hallucination)分为两大类:
-
内在幻觉:生成内容与用户提供的输入或上下文矛盾。比如你给了篇论文让AI总结,它却总结出论文里根本没有的结论。
-
外在幻觉:生成内容与公认的世界知识或事实不符。比如问“2022年冬奥会在哪办”,它答“东京”。
幻觉并非模型主动欺骗。大语言模型(LLM)没有“撒谎意图”,它只是在做一道无懈可击的条件概率题。它预测下一个词时,追求的是语言序列的“合理性”,而不是“事实性”。所以,当模型知识边界模糊,或者遇到训练数据中的冲突信息时,它就会“用最流畅的语言,编最离谱的故事”。
三、根源拆解:大模型为何会坠入幻觉之网?
我画了一张图,帮你一眼看穿幻觉产生的四大源头。

逐层解释:
1. 它吃下的数据就“有毒”
互联网文本里充斥着谣言、过时信息和偏见。如果训练数据说“地球是平的”“吃绿豆治百病”,模型就会内化这些错误,并在特定提示下复现。
2. 它真的不理解世界
LLM本质是“下一个词预测器”。它学到的是“林黛玉后常跟着葬花,倒拔垂杨柳前常是鲁智深”,但如果你故意问“林黛玉倒拔垂杨柳是怎么回事”,它可能顺着概率拼出一段“林妹妹在潇湘馆外拔起一棵柳树,口念葬花吟……”的精彩描述。因为它认为在这样的语境下,词与词的搭配是合理的。它没有建立真实世界的人物指涉和物理常识。
3. 解码时开了一点“脑洞”
模型生成回答时,会用到温度采样(temperature)、Top-p等解码策略。为了让回答更有“创造性”,我们会调高温度。但同时,创造力越高,脱离事实的“跑偏”风险也越大。这就好比一个诗人微醺时灵感迸发,但也可能满口胡言。
4. 人类反馈强化了“讨好型人格”
在RLHF(基于人类反馈的强化学习)阶段,标注者往往更偏爱详细、自信、文笔好的回答。这变相鼓励模型:不知道也要装知道,而且装得理直气壮。 于是你会看到AI宁可捏造一个药品剂量,也不愿说“我不确定”。
四、那些让你又好气又好笑的幻觉名场面
除了法律案件,AI幻觉早已渗透进生活的每个角落。我本人也踩过不少坑:
-
历史发明家:提问“诸葛亮在赤壁之战中使用了哪些火枪?”,AI能绘声绘色描述“连弩火箭炮”的射程和威力,还配上战术图。
-
医疗杀手(潜在):有用户咨询“10个月婴儿发烧该吃什么药”,AI给出了成人处方药并附上精确毫克数。这种幻觉,是会致命的。
-
代码魔术师:让AI写个库函数,它给的API名称、参数完全是自己虚构的,运行直接报错,你查遍官方文档也找不到。
五、如何抓住幻觉的狐狸尾巴?检测与评估技术
既然幻觉这么普遍,我们能否自动检测出来?学界和业界已经摸索出一套组合拳:
-
基于检索的校验:对生成的事实性陈述,自动搜索外部知识库(如维基百科)进行比对。典型工具如SelfCheckGPT,让模型生成多个答案样本,如果各样本间核心事实高度不一致,大概率是幻觉。
-
NLI(自然语言推理)模型:训练专门的判别器,判断一句话是否能从源文档或已知事实中推导出来。矛盾即为幻觉。
-
不确定性量化:利用模型输出概率分布,如果模型对生成词的概率较低,说明这里可能“心虚”。可以设定阈值标红。
-
专用基准测评:像TruthfulQA(专门测试对常见误解的抵抗力)、HaluEval(包含大量幻觉样本的数据集),用来给模型打分。
我自己常用的一个土办法是“追问验证法”:得到AI答案后,立刻追问“你的依据是什么?请提供可验证的来源链接。” 这往往能迫使联网搜索或RAG系统露出破绽,对于纯参数模型,它可能会承认“我无法提供具体来源”,或者继续二次幻觉。
六、告别胡说八道:如何从根上减少幻觉?
重点来了。目前行业里最有效的方案,并不是让模型“更聪明”,而是不让模型全凭记忆作答。
1. 检索增强生成(RAG)——给AI外挂一个图书馆
这是企业落地的黄金标准。模型作答前,先根据用户问题去外部知识库(向量数据库)里检索最相关的文档、片段,然后将这些“参考资料”和问题一起喂给模型,并强制其“仅根据提供的资料作答,资料中没有的就说不知道”。这能像缰绳一样,将大部分幻觉拉回地面。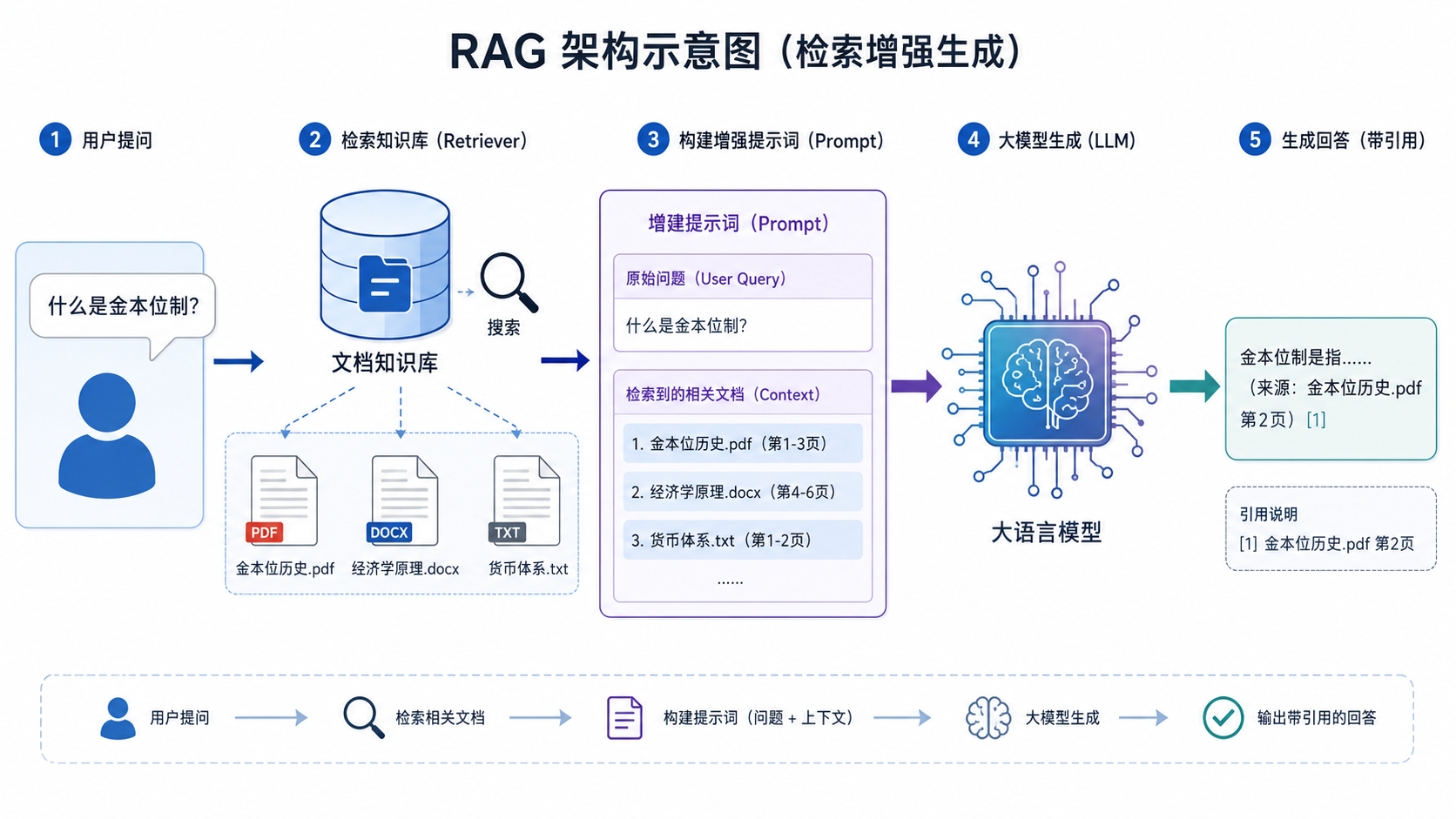
2. 思维链与自我反思
让模型一步步推理(Chain-of-Thought),并在过程中自己检查矛盾。再进阶一些是“思维树”或“验证链”,模型生成一个论断后,立刻让同一个模型扮演批评者角色,质问证据在哪,逻辑是否成立,直到达成自洽。
3. 多智能体辩论
构造多个AI角色,如“正方专家”“反方专家”“事实核查员”,就同一个问题展开多轮辩论,最终由裁判员AI给出融合结论并标注确定性。几篇顶会论文已证明,这能大幅降低虚构。
4. 知识编辑与参数级修正
直接定位并修改模型参数中存储的特定错误知识。比如发现模型对“英国首相”时效信息出错,就用KE(知识编辑)技术手术刀式修补,避免重新训练。难度高,但前景诱人。
5. 产品层面的兜底设计
在应用层面,可以给所有AI生成内容打上“可能不准确”标记;对高风险场景设置确定性阈值,低于阈值则拒答或转人工;输出格式要求强结构化和引用,比如必须标注章节、出处链接。
七、如何看待幻觉?它是缺陷,也是创造力的暗面
事情总有另一面。幻觉让大模型在法律、医疗领域极其危险,但同时,它也是故事创作、脑暴、设计灵感的源泉。没有“幻觉”能力,AI写不出“赛博朋克孙悟空大闹硅谷”,也画不出“梵高风格的微波炉”。从某种角度说,幻觉是LLM泛化能力的溢出效应。
未来的方向,不是彻底消灭幻觉——现阶段也做不到,而是可控幻觉:在需要事实严谨的场景(财经分析、医疗建议)把幻觉压到无限趋近于零;在需要创意发散的场景,释放它的造梦能力,并让用户清晰知晓“我正在创造而非陈述事实”。
八、结尾:与幻觉共存,做清醒的执缰人
回到开头那个令人脊背发凉的假设——千万别让AI给你的孩子看病。这不是说AI毫无用处,而是想告诉你,工具给我们力量的同时,也把辨别真伪的责任交到了我们手中。 AI可以帮你思考,但不能替你思考。
当你下次再听到某个AI信誓旦旦地给出一个药名、一组数据、一条法律条文时,请条件反射般地问自己一句:“这是真的吗?依据呢?” 那个会编造“牵牛花咖啡”的大脑,同样也会面不改色地编造出你孩子的用药剂量。这不是偶然,是统计学上的必然。
我是Qui Yu,一个跟你一样被AI惊艳也时常被它骗得晕头转向的观察者。如果你也被AI的神级脑洞骗过,欢迎在评论区分享你的经历,让大家一起笑一笑,也一起学聪明。下篇硬核长文见。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 1
1 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)