K8s 集群 “3 节点 2 个 NotReady“ 故障排查全记录
K8s 集群 “3 节点 2 个 NotReady” 故障排查全记录
小刘运维的排错实战:从飞书搭机器人到修好整个 K8s 集群,再到产品化巡检工具
上周接了一个运维咨询的单子:客户有一套 3 节点的 K8s 集群(v1.27.16),运行了快一年,最近发现 node-2 和 node-3 双双 NotReady,只有 node-1 还在坚守岗位。
于是有了今天这场排错实战。
整个过程从调试巡检脚本开始,到发现根因并修复,最后把巡检工具产品化——推送到 GitHub、对接飞书机器人实现自动推送。记录成文,希望对同行有帮助。
一、问题现象
k8s集群3 个node节点,2 个 NotReady
kubectl get nodes
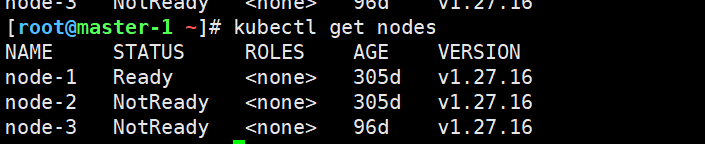
二、排查过程全记录
1: 看节点详情
kubectl describe node node-2 | grep -A 20 Conditions
输出显示所有 condition 全部显示 Unknown,最后一个心跳时间是 3 天前:
Ready Unknown ... Kubelet stopped posting node status.
MemoryPressure Unknown ... Kubelet stopped posting node status.
DiskPressure Unknown ... Kubelet stopped posting node status.
PIDPressure Unknown ... Kubelet stopped posting node status.
关键信息:Kubelet stopped posting node status — kubelet 还在跑,但连不上 API Server 了。
2: 查 kubelet 日志
journalctl -u kubelet --no-pager -n 20
日志里反复出现同一行错误:
dial tcp 192.168.91.254:6443: i/o timeout
kubelet 在尝试连接 API Server 的 VIP 192.168.91.254:6443,但全部超时。
3: 测试 VIP 连通性
从 master-1 测试:
[root@master-1 ~]# ping 192.168.91.254
64 bytes from 192.168.91.254: icmp_seq=1 ttl=64 time=0.414 ms ✅
[root@master-1 ~]# curl -sk https://192.168.91.254:6443/healthz
{"kind":"Status","code":401} # 401 是正常的,说明 API 可达 ✅
从 node-2 测试:
[root@node-2 ~]# ping 192.168.91.254
3 packets transmitted, 0 received, 100% packet loss ❌
[root@node-2 ~]# curl -sk https://192.168.91.254:6443/healthz
... 超时 ...
有意思了:master 能连 VIP,worker 不能。
4: ARP 探测发现关键线索
# 从 master-1 看 VIP 的 MAC
[root@master-1 ~]# ip neigh show 192.168.91.254
192.168.91.254 dev ens32 lladdr 00:0c:29:86:74:65 REACHABLE
# 从 node-2 看 VIP 的 MAC
[root@node-2 ~]# ip neigh show 192.168.91.254
192.168.91.254 dev ens32 lladdr 00:50:56:ec:2f:c0 REACHABLE
同一个 VIP,不同的 MAC 地址! 这显然有问题。
00:0c:29:86:74:65 是谁的 MAC?查一下:
[root@master-1 ~]# ssh root@192.168.91.20 ip link show ens32 | grep ether
link/ether 00:0c:29:86:74:65
原来是 master-3(192.168.91.20) 持有 VIP。而 00:50:56:ec:2f:c0 则是另一个未知设备在网络上"冒领"了 ARP 请求。
根因找到了:VIP 在 master-3 上,但 worker 节点解析到的 MAC 地址是错的,导致流量被引向一个不可达的设备。
5: 看看 keepalived 怎么回事
检查各 master 的 keepalived 状态:
ip addr show ens32 | grep 254
inet 192.168.91.254/24 scope global secondary ens32 ← VIP 在 master-3 上
keepalived 的 VRRP 协议用的是优先级选主,三个 master 优先级都是 100。同优先级时 IP 大的胜出,所以 VIP 总是在 master-3(192.168.91.20)上。
而 master-3 和 node-2/3 之间的网络存在 ARP 冲突——有一个设备在冒充 VIP 的 MAC 地址,导致 node-2/3 的流量被误引。
三、修复过程
1.修复方案
最简单的方案:让 VIP 漂到一个所有节点都能访问的 master 上。
停掉 master-3 的 keepalived:
systemctl stop keepalived
VIP 自动漂移到 master-2(192.168.91.19):
ip a | grep 254

2.验证修复效果
再次从 node-2 测试 VIP:
ping 192.168.91.254
64 bytes from 192.168.91.254: icmp_seq=2 ttl=64 time=0.465 ms ✅
[root@node-2 ~]# curl -sk https://192.168.91.254:6443/healthz
{"kind":"Status","code":401} ✅
节点状态检查:

Flannel 网络自动恢复(之前因为连不上 ClusterIP 10.0.0.1 而 CrashLoopBackOff):
kubectl get pods -n kube-flannel

至此,集群全面恢复。
四、复盘总结
1.根因图谱
keepalived VIP 在 master-3 上
↓
网络上存在 ARP 冲突(不明设备抢答 VIP 的 MAC)
↓
node-2/3 解析到错误的 MAC 地址
↓
kubelet 连不上 API Server(i/o timeout)
↓
NodeNotReady、Flannel CrashLoopBackOff
2.为什么 node-1 没事?
node-1 的 IP 是 192.168.91.21,恰好和 master-3 也有良好的网络连通性。所以同一个 ARP 问题只影响 node-2/3。
3.教训与改进
| 教训 | 改进措施 |
|---|---|
| 依赖 VIP 连接 API Server 有单点风险 | 每个节点 kubelet 配置多个 master IP 做 fallback |
| keepalived 主从策略不清晰 | 明确设置优先级,避免同优先级靠 IP 排序的隐性规则 |
| 没有巡检机制 | 部署巡检脚本,天级别健康检查 |
| 没有告警通知 | 对接飞书,出问题第一时间知道 |
五、附:巡检工具产品化
既然修好了,顺便做了产品化:
1. 巡检脚本 → GitHub 开源
仓库地址:https://github.com/liuxing141/k8s-health-check
一键运行,检查 9 大项:节点健康、Pod 状态、资源使用、异常事件、安全基线、Helm Release、TLS 证书等。
2. 对接飞书机器人
写了个 Python 脚本,跑完巡检自动推送到飞书:
python3 k8s-health-check-feishu.py
报告直接飞到手机,再也不用 SSH 上去看了。
3. 定时任务
30 9 * * * cd ~/k8s-health-check-repo && python3 k8s-health-check-feishu.py
每天早上 9 点半自动跑一遍,有问题第一时间知道。
六、总结
这次排错虽然花了不少时间,但收获很大:
- VIP ≠ 高可用,如果底层网络有问题,VIP 反而带来更多麻烦
- 巡检不是可有可无,如果没有巡检报告,出问题了只能被动等客户投诉
- 工具要产品化,同样的脚本能不能在下一个客户那直接用?能的话就是一杆枪
希望这篇文章对你的运维工作有帮助。有问题欢迎交流 🙌
作者:一名不想上班的 SRE
巡检工具:https://github.com/liuxing141/k8s-health-check

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 14
14 0
0- 0



 已为社区贡献8条内容
已为社区贡献8条内容

所有评论(0)