Imbalanced Learning
·
处理类别不平衡数据的方法论与工具链,核心包:
imblearn(imbalanced-learn),与 scikit-learn 兼容。
问题定义
类别不平衡(Class Imbalance):数据集中各类别样本数量差距悬殊。常见于欺诈检测、医疗诊断、异常检测等场景。
直接危害:
- 准确率(Accuracy)失效——多数类占 99%,全猜多数类也有 99% 准确率
- 模型偏向多数类,少数类(正类)几乎学不到信号
- 交叉熵损失被多数类主导,梯度更新忽略少数类
评估指标
不平衡场景下,Accuracy 无用。使用:
| 指标 | 公式 | 适用场景 |
|---|---|---|
| Precision | TP / (TP + FP) | 误报代价高(推荐系统) |
| Recall | TP / (TP + FN) | 漏报代价高(疾病筛查) |
| F1-score | 2 * P * R / (P + R) | 综合平衡 |
| AUC-ROC | — | 排序能力,对不平衡不敏感 |
| AUC-PR | — | 极端不平衡时比 ROC 更真实 |
| MCC | — | 两分类都重要时的综合指标 |
Resampling 方法
1. 过采样(Oversampling)
增加少数类样本,直到类别平衡。
RandomOverSampler
直接复制少数类样本。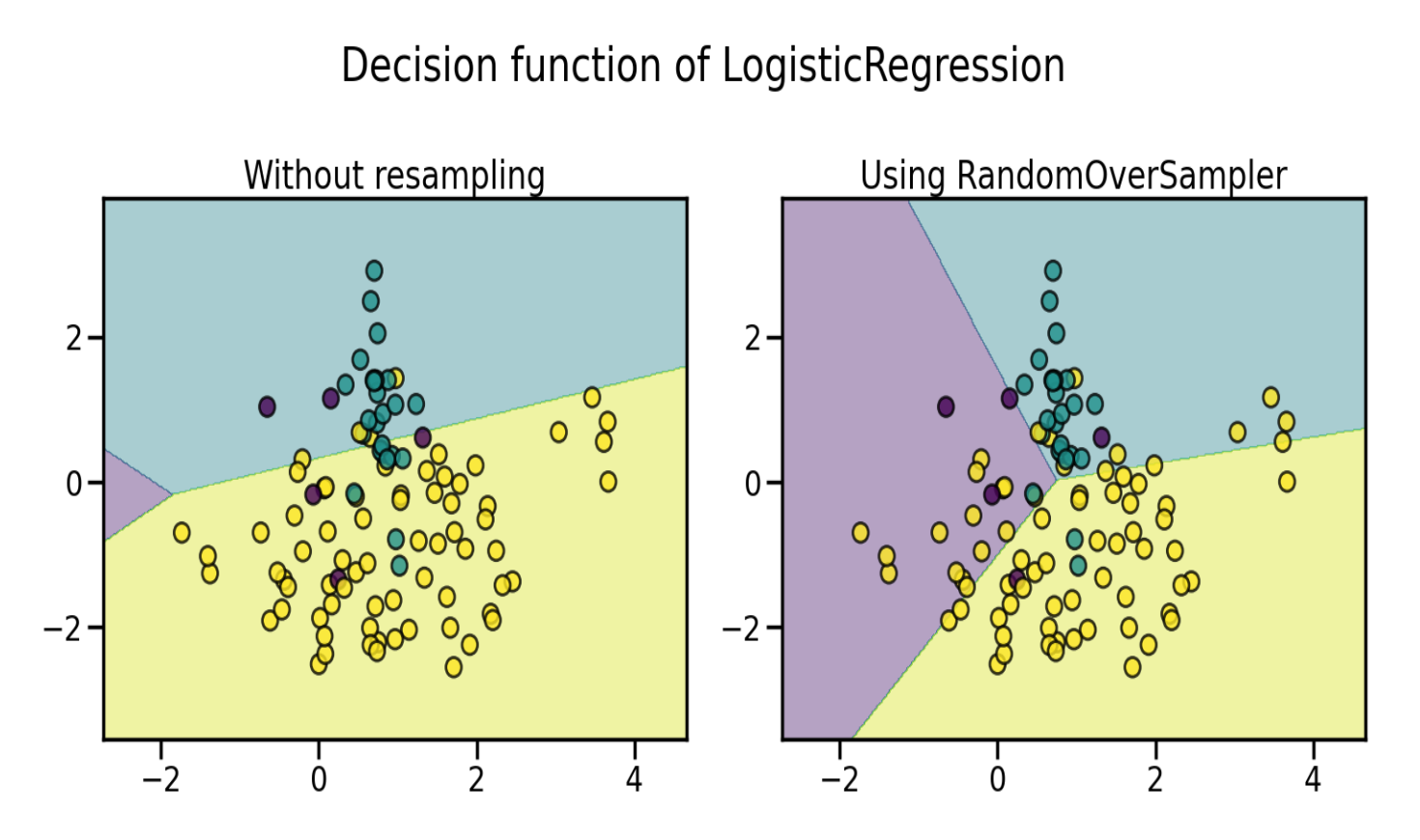
from sklearn.datasets import make_classification
from imblearn.over_sampling import RandomOverSampler
from collections import Counter
X, y = make_classification(
n_samples=5000, n_features=2, n_informative=2,
n_redundant=0, n_repeated=0, n_classes=3,
n_clusters_per_class=1,
weights=[0.01, 0.05, 0.94],
class_sep=0.8, random_state=0
)
ros = RandomOverSampler(random_state=0)
X_resampled, y_resampled = ros.fit_resample(X, y)
print(sorted(Counter(y_resampled).items()))
# [(0, 4674), (1, 4674), (2, 4674)]
缺点:简单复制 → 过拟合风险高,决策边界无变化。
SMOTE (Synthetic Minority Oversampling Technique)
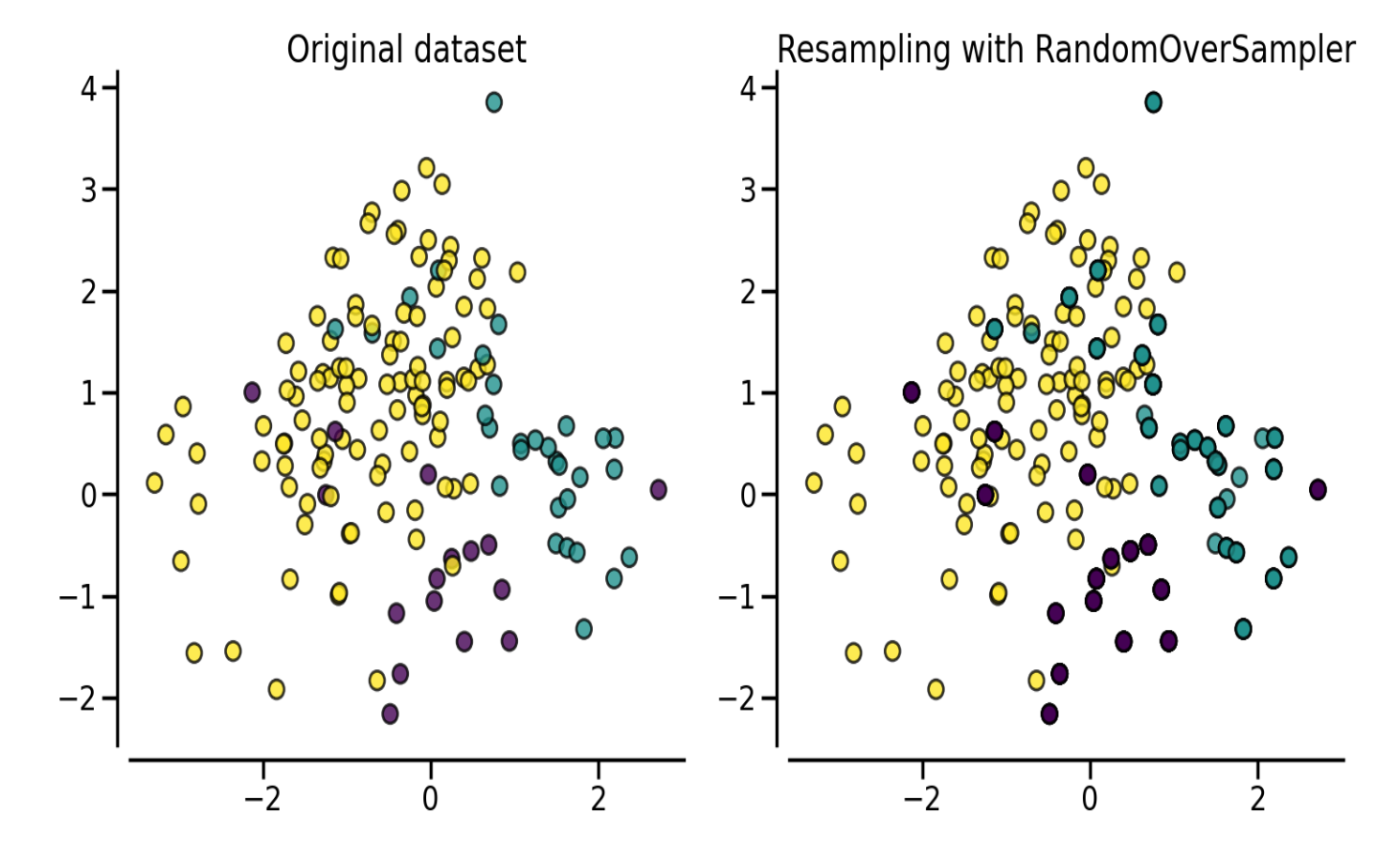
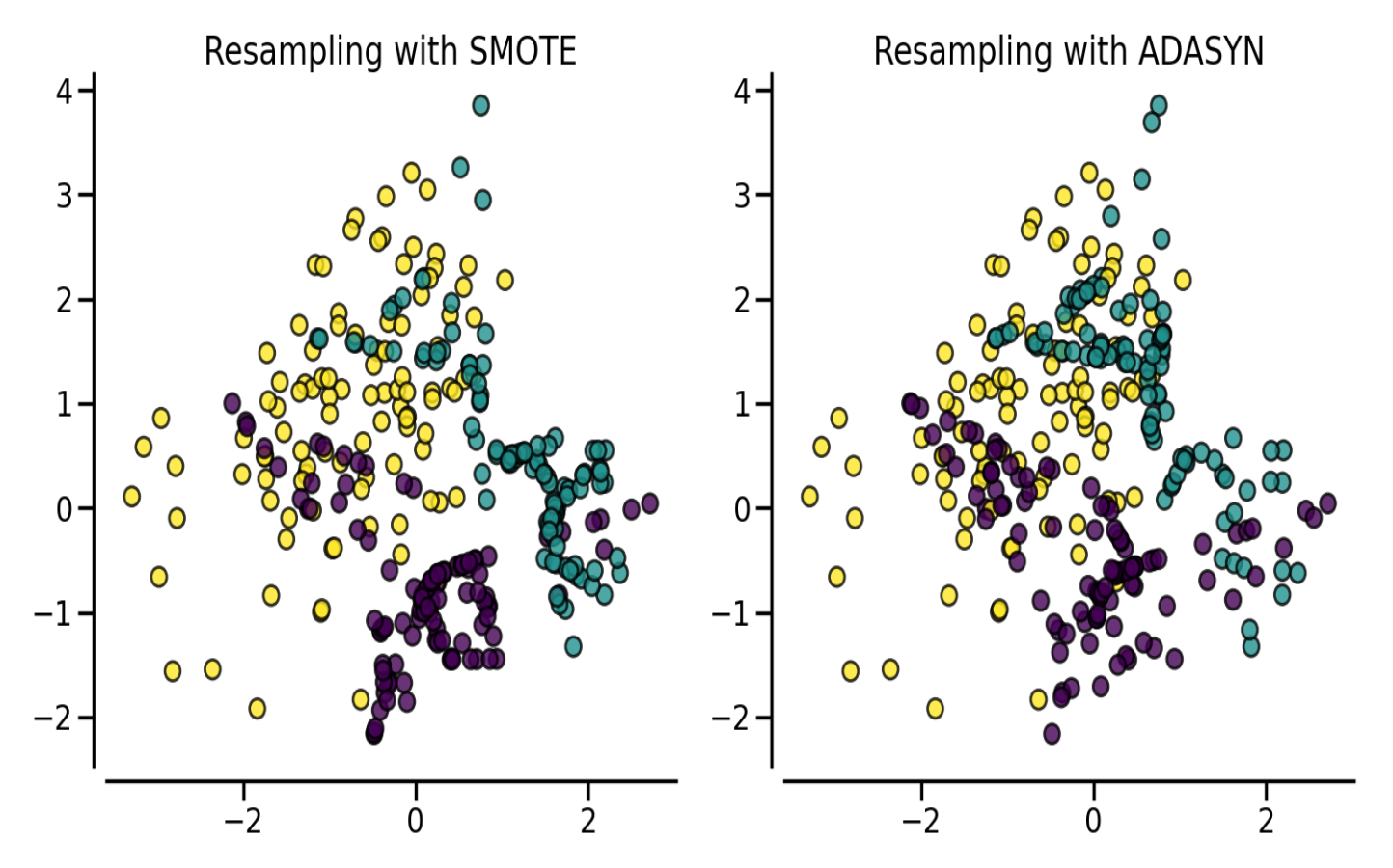
合成新样本而非复制。核心思想:对每个少数类样本,在其与 k 近邻的连线上随机插值。
from imblearn.over_sampling import SMOTE
smote = SMOTE(random_state=0)
X_resampled, y_resampled = smote.fit_resample(X, y)
变体:
| 方法 | 特点 |
|---|---|
| BorderlineSMOTE | 只在决策边界附近合成样本 |
| SVMSMOTE | 用 SVM 找支持向量,在支持向量附近合成 |
| ADASYN | 根据学习难度自适应分配合成数量 |
| KMeansSMOTE | 先聚类再在簇内合成,避免噪声传播 |
from imblearn.over_sampling import BorderlineSMOTE, ADASYN
# BorderlineSMOTE — 只在边界合成
bsmote = BorderlineSMOTE(random_state=0)
X_resampled, y_resampled = bsmote.fit_resample(X, y)
# ADASYN — 自适应合成
adasyn = ADASYN(random_state=0)
X_resampled, y_resampled = adasyn.fit_resample(X, y)
2. 欠采样(Undersampling)
减少多数类样本。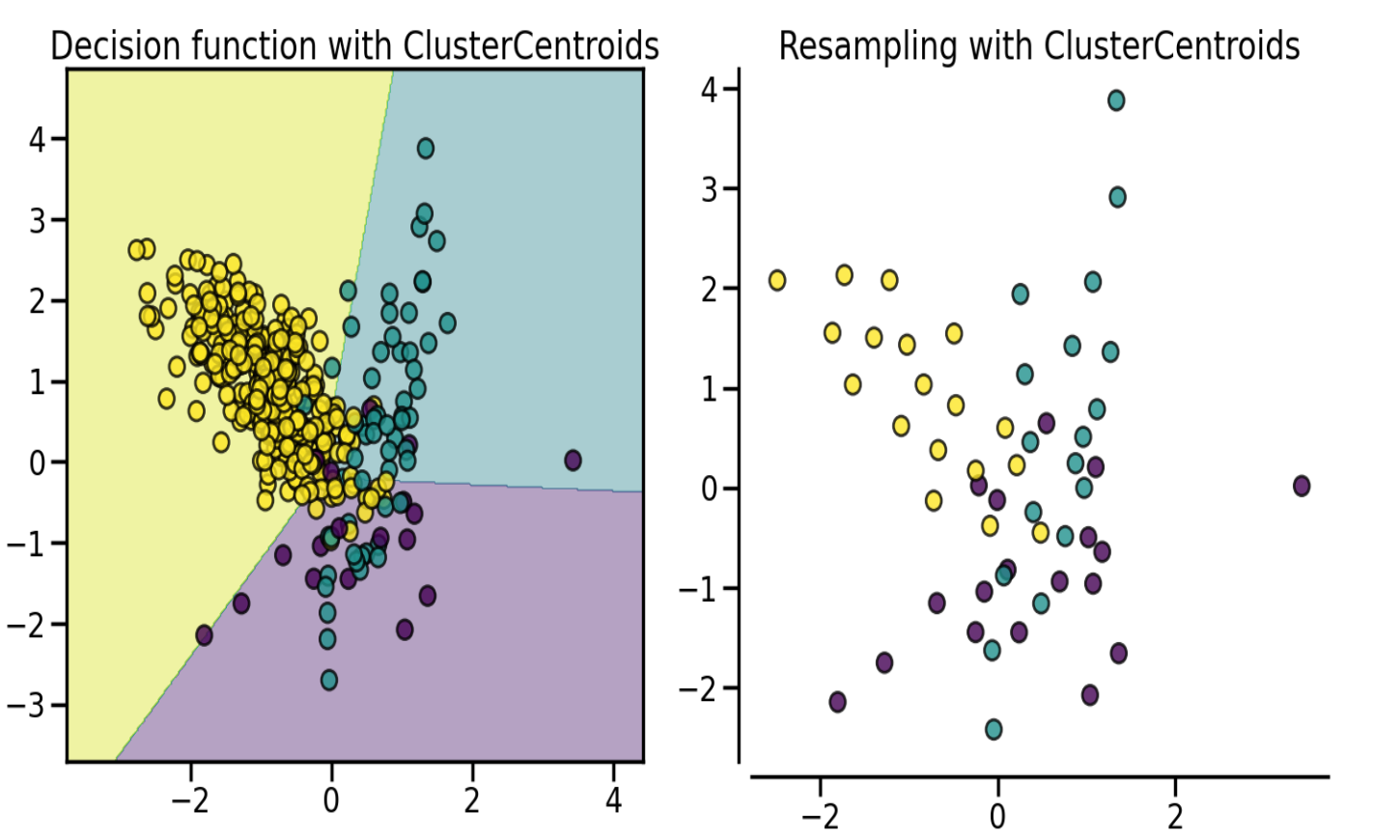
RandomUnderSampler
随机丢弃多数类样本。缺点:可能丢弃有信息量的样本。
from imblearn.under_sampling import RandomUnderSampler
rus = RandomUnderSampler(random_state=0)
X_resampled, y_resampled = rus.fit_resample(X, y)
基于近邻的欠采样
| 方法 | 原理 |
|---|---|
| NearMiss-1 | 保留与最近少数类样本距离最小的多数类样本 |
| NearMiss-2 | 保留与最近 3 个少数类样本平均距离最小的多数类样本 |
| NearMiss-3 | 每少数类保留最近的 M 个多数类样本 |
| TomekLinks | 移除互为最近邻但类别不同的多数类样本对 |
| EditedNearestNeighbours | 移除被 k 近邻多数投票误分类的样本 |
| RepeatedEditedNearestNeighbours | ENN 的多次迭代版 |
| AllKNN | 每轮增加 k 值做 ENN |
| CondensedNearestNeighbour | 保留能被 1-NN 正确分类的样本 |
| OneSidedSelection | TomekLinks + CNN |
| NeighbourhoodCleaningRule | ENN + k-NN 剔除 |
| InstanceHardnessThreshold | 用分类器估计每个样本的"硬度",移除高硬度样本 |
from imblearn.under_sampling import (
NearMiss, TomekLinks, EditedNearestNeighbours,
RepeatedEditedNearestNeighbours, AllKNN,
CondensedNearestNeighbour, OneSidedSelection,
NeighbourhoodCleaningRule, InstanceHardnessThreshold
)
# NearMiss
nm = NearMiss(version=1)
X_resampled, y_resampled = nm.fit_resample(X, y)
# TomekLinks — 清理边界噪声
tl = TomekLinks()
X_resampled, y_resampled = tl.fit_resample(X, y)
# EditedNearestNeighbours — 剔除被近邻误分的样本
enn = EditedNearestNeighbours(n_neighbors=3)
X_resampled, y_resampled = enn.fit_resample(X, y)
# InstanceHardnessThreshold — 用 RandomForest 估计样本难度
iht = InstanceHardnessThreshold(
estimator=RandomForestClassifier(random_state=0),
sampling_strategy='auto'
)
X_resampled, y_resampled = iht.fit_resample(X, y)
3. 组合采样(Combination)
过采样 + 欠采样,互相弥补。
from imblearn.combine import SMOTETomek, SMOTEENN
# SMOTE + TomekLinks: 合成样本后清理边界
smt = SMOTETomek(random_state=0)
X_resampled, y_resampled = smt.fit_resample(X, y)
# SMOTE + ENN: 合成后剔除噪声
senn = SMOTEENN(random_state=0)
X_resampled, y_resampled = senn.fit_resample(X, y)
Pipeline 封装:
from imblearn.pipeline import Pipeline as ImbPipeline
from sklearn.preprocessing import StandardScaler
from sklearn.ensemble import RandomForestClassifier
pipeline = ImbPipeline([
('scaler', StandardScaler()),
('sampler', SMOTETomek(random_state=0)),
('classifier', RandomForestClassifier(random_state=0))
])
pipeline.fit(X_train, y_train)
y_pred = pipeline.predict(X_test)
注意:用
imblearn.pipeline.Pipeline而非sklearn.pipeline.Pipeline,后者不会对fit_resample做正确路由。
算法级方法
不修改数据,修改算法本身。
类别权重(Class Weight)
在损失函数中对少数类样本赋予更高权重。
from sklearn.linear_model import LogisticRegression
from sklearn.ensemble import RandomForestClassifier
# LogisticRegression — 内置 class_weight
lr = LogisticRegression(class_weight='balanced', random_state=0)
lr.fit(X, y)
# RandomForest — 同样支持
rf = RandomForestClassifier(class_weight='balanced', random_state=0)
rf.fit(X, y)
# XGBoost
import xgboost as xgb
# scale_pos_weight = (负类数 / 正类数)
scale = len(y[y == 0]) / len(y[y == 1])
clf = xgb.XGBClassifier(scale_pos_weight=scale)
clf.fit(X, y)
Focal Loss
降低易分类样本的 loss 权重,让模型更关注难分类样本(通常就是少数类)。
FL ( p t ) = − α t ( 1 − p t ) γ log ( p t ) \text{FL}(p_t) = -\alpha_t (1 - p_t)^\gamma \log(p_t) FL(pt)=−αt(1−pt)γlog(pt)
- γ \gamma γ:聚焦参数,越大越关注难样本(常用 2)
- α t \alpha_t αt:类别权重因子
import torch.nn as nn
import torch.nn.functional as F
class FocalLoss(nn.Module):
def __init__(self, alpha=1, gamma=2):
super().__init__()
self.alpha = alpha
self.gamma = gamma
def forward(self, inputs, targets):
ce_loss = F.cross_entropy(inputs, targets, reduction='none')
pt = torch.exp(-ce_loss)
focal_loss = self.alpha * (1 - pt) ** self.gamma * ce_loss
return focal_loss.mean()
集成方法(Ensemble)
在集成框架中嵌入采样策略。
from imblearn.ensemble import (
BalancedRandomForestClassifier,
EasyEnsembleClassifier,
RUSBoostClassifier
)
# BalancedRandomForest: 每棵树的 bootstrap 做欠采样
brf = BalancedRandomForestClassifier(
n_estimators=100,
sampling_strategy='auto',
replacement=True,
random_state=0
)
# EasyEnsemble: 多个欠采样子集 + AdaBoost
ee = EasyEnsembleClassifier(random_state=0)
# RUSBoost: 欠采样 + AdaBoost
rusb = RUSBoostClassifier(random_state=0)
| 方法 | 原理 |
|---|---|
| BalancedBaggingClassifier | Bagging 中每轮对多数类欠采样 |
| BalancedRandomForest | RandomForest 中每棵树用欠采样后的训练集 |
| EasyEnsemble | 将多数类分 N 份,每份 + 全部少数类训练 AdaBoost,集成 |
| RUSBoost | 每轮 boosting 前随机欠采样多数类 |
实践建议
- 先设 baseline:用未处理的原始数据 + 带
class_weight='balanced'的模型跑一条 baseline - 指标选择:极度不平衡(1:1000+)用 AUC-PR,一般不平衡用 F1/AUC-ROC
- 过采样 vs 欠采样:数据量足够 → 欠采样(快);小样本 → 过采样(SMOTE)
- SMOTE 后加清理:SMOTETomek 通常比纯 SMOTE 好,可以清理边界噪声
- Pipeline:用
imblearn.pipeline.Pipeline而非 sklearn 的,避免采样在交叉验证中泄露 - 不要对测试集做采样:只在训练集上 resample,测试集保持原始分布
- 类别权重 + 采样可叠加:
class_weight='balanced'+ SMOTETomek 配合使用,效果常优于单独使用 - 极端不平衡考虑 anomaly detection:正类占比 < 0.1% 时,casting 为异常检测用 IsolationForest 等更合适
相关
- [[articles/ftrl-optimizer]] — FTRL 优化器,适合在线不平衡场景
- imbalanced-learn 官方文档

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 4
4 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)